
Спустя некоторое время я все же выделил себе время изучить этот вопрос более детально, а наблюдениями хочу поделиться с вами.
Зачем?
Этот вопрос задаст любой уважающий себя программист. Вести проект на двух различных языках – дело очень сомнительное, тем более неуправляемый код действительно сложен в реализации, отладке и поддержке. Но лишь сама возможность реализовать функционал, который будет работать быстрее, уже достойна рассмотрения, особенно в критически важных участках или в высоко нагруженных приложениях.
Другой возможный ответ: функционал уже реализован в unamaged виде! Зачем переписывать решение целиком, если можно не очень большими затратами обернуть все в .NET и использовать оттуда?
В двух словах – такое действительно встречается. А мы лишь посмотрим, что да как.
Лирика
Весь код писался в Visual Studio Community 2015. Для оценки я использовал свой рабоче-игровой компьютер, с i5-3470 на борту, 12-ю гигабайтами 1333MHz двухканальной оперативной памяти, а также жестким диском на 7200 rpm. Замеры производились с помощью System.Diagnostics.Stopwatch, который точнее DateTime, потому что реализован поверх PerformanceCounter. Тесты запускались на Release вариантах сборок, чтобы исключить возможность того, что в действительности все будет немного иначе. Версия фрэймворка .NET 4.5.2, а C++ проект компилировался с флагом /TC (Compile as C).
Заранее прошу прощения за обилие кода, но без него будет сложно понять, чего именно я добивался. Большую часть слишком нудного или незначительного кода я вынес в спойлеры, а другую и вовсе вырезал из статьи (изначально она была еще длиннее).
Вызов функций
Свое исследование я решил начать именно с замера скорости вызова функций. Причин на это было несколько. Во-первых, функции все равно придется вызывать, а вызываются функции из загружаемых dll не очень быстро, в сравнении с кодом в том же модуле. Во-вторых, примерно таким образом реализовано большинство существующих C#-оберток поверх любого неуправляемого кода (напр. sharpgl, openal-cs,
Перед тем как начать непосредственно измерения, нужно подумать, как мы будем хранить и оценивать результаты наших измерений. «CSV!», подумал я, и написал простенький класс для хранения данных в этом формате:
public class CSVReport : IDisposable
{
int columnsCount;
StreamWriter writer;
public CSVReport(string path, params string[] header)
{
columnsCount = header.Length;
writer = new StreamWriter(path);
writer.Write(header[0]);
for (int i = 1; i < header.Length; i++)
writer.Write("," + header[i]);
writer.Write("\r\n");
}
public void Write(params object[] values)
{
if (values.Length != columnsCount)
throw new ArgumentException("Columns count for row didn't match table columns count");
writer.Write(values[0].ToString());
for (int i = 1; i < values.Length; i++)
writer.Write("," + values[i].ToString());
writer.Write("\r\n");
}
public void Dispose()
{
writer.Close();
}
}Не самый функциональный вариант, но для моей цели пойдет с лихвой. А для тестирования было принято решение написать простой класс, который умеет лишь суммировать числа и хранить результат. Вот так он выглядит:
class Summer
{
public int Sum
{
get; private set;
}
public Summer()
{
Sum = 0;
}
public void Add(int a)
{
Sum += a;
}
public void Reset()
{
Sum = 0;
}
}Но это управляемый вариант. Нам же нужен еще неуправляемый. Поэтому создаем шаблонный dll проект и сразу же добавляем туда файл, например, api.h, в который запихиваем определения экспорта:
#ifndef _API_H_
#define _API_H_
#define EXPORT __declspec(dllexport)
#define STD_API __stdcall
#endifРядышком положим summer.c, и реализуем весь необходимый нам функционал:
#include "api.h"
int sum;
EXPORT void STD_API summer_init( void )
{
sum = 0;
}
EXPORT void STD_API summer_add( int value )
{
sum += value;
}
EXPORT int STD_API summer_sum( void )
{
return sum;
}Теперь нам нужен класс-обертка над этим безобразием:
class SummerUnmanaged
{
const string dllName = @"unmanaged_test.dll";
[DllImport(dllName)]
private static extern void summer_init();
[DllImport(dllName)]
private static extern void summer_add(int v);
[DllImport(dllName)]
private static extern int summer_sum();
public int Sum
{
get
{
return summer_sum();
}
}
public SummerUnmanaged()
{
summer_init();
}
public void Add(int a)
{
summer_add(a);
}
public void Reset()
{
summer_init();
}
}В итоге получилось именно то, чего я и хотел. Есть две совершенно одинаковые для использования реализации: одна на C#, вторая на Си. Теперь можно и посмотреть, что из этого выйдет! Напишем код, который замерит время выполнения n вызовов одного и другого класса:
static void TestCall()
{
Console.WriteLine("Function calls...");
Stopwatch sw = new Stopwatch();
Summer s_managed = new Summer();
SummerUnmanaged s_unmanaged = new SummerUnmanaged();
Random r = new Random();
int[] data;
CSVReport report = new CSVReport("fun_call.csv", "elements", "C# managed", "C unmanaged");
data = new int[1000000];
for (int j = 0; j < 1000000; j++)
data[j] = r.Next(-1, 2); // Генерируем мусор
for (int i=0; i<100; i++)
{
// Чтобы не ждать у консоли погоды
Console.Write("\r{0}/100", i+1);
int length = 10000*i;
long managedTime = 0, unmanagedTime = 0;
Thread.Sleep(10);
s_managed.Reset();
sw.Start();
for (int j = 0; j < length; j++)
{
s_managed.Add(data[j]);
}
sw.Stop();
managedTime = sw.ElapsedTicks;
sw.Reset();
sw.Start();
for(int j=0; j<length; j++)
{
s_unmanaged.Add(data[j]);
}
sw.Stop();
unmanagedTime = sw.ElapsedTicks;
report.Write(length, managedTime, unmanagedTime);
}
report.Dispose();
Console.WriteLine();
}Осталось только вызвать эту функцию где-нибудь в мэйне, да поглядеть отчет в fun_call.csv. Для наглядности я не буду приводить скучные и сухие цифры, а выведу лишь график. По вертикали – время в тиках, по горизонтали – количество вызовов функции.
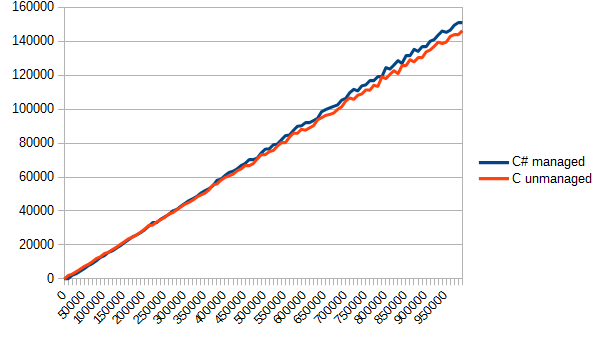
Результат меня немного удивил. C# явно был фаворитом в данном тесте. Все-таки, тот же модуль, да и возможность инлайнить… но в результате оба варианта оказались приблизительно одинаковыми. Собственно, в данном случае такое разделение кода оказалось бессмысленным – ничего не выиграли, а проект усложнили.
Массивы
Размышления о результатах были не долгими, и я тут же понял – нужно отсылать данные не по одному элементу, а массивами. Настало время модернизировать код. Допишем функционал:
public void AddMany(int[] data)
{
int length = data.Length;
for (int i = 0; i < length; i++)
Sum += i;
}И, собственно, Си часть:
EXPORT int STD_API summer_add_many( int* data, int length )
{
for ( int i = 0; i < length; i++ )
sum += data[ i ];
} [DllImport(dllName)]
private static extern void summer_add_many(int[] data, int length);
public void AddMany(int[] data)
{
summer_add_many(data, data.Length);
}Соответственно, пришлось переписать и функцию измерения производительности. Полная версия в спойлере, а в двух словах: теперь мы генерируем массив из n случайных элементов и вызываем функцию их сложения.
static void TestArrays()
{
Console.WriteLine("Arrays...");
Stopwatch sw = new Stopwatch();
Summer s_managed = new Summer();
SummerUnmanaged s_unmanaged = new SummerUnmanaged();
Random r = new Random();
int[] data;
CSVReport report = new CSVReport("arrays.csv", "elements", "C# managed", "C unmanaged");
for (int i = 0; i < 100; i++)
{
Console.Write("\r{0}/100", i+1);
int length = 10000 * i;
long managedTime = 0, unmanagedTime = 0;
data = new int[length];
for (int j = 0; j < length; j++) // Генерируем мусор
data[j] = r.Next(-1, 2);
s_managed.Reset();
sw.Start();
s_managed.AddMany(data);
sw.Stop();
managedTime = sw.ElapsedTicks;
sw.Reset();
sw.Start();
s_unmanaged.AddMany(data);
sw.Stop();
unmanagedTime = sw.ElapsedTicks;
report.Write(length, managedTime, unmanagedTime);
}
report.Dispose();
Console.WriteLine();
}Запускаем, проверяем отчет. По вертикали все еще время в тиках, по горизонтали – количество элементов массива.
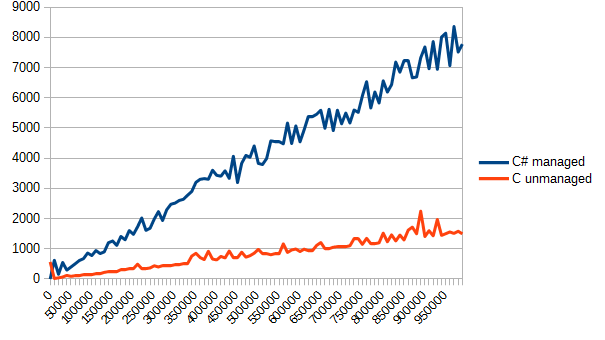
Видно невооруженным глазом — Си значительно лучше справляется с банальной обработкой массивов. Но это и есть цена за «управляемость» – в то время, как управляемый код в случае переполнения, выхода за границы массива,
Чтение файла
Убедившись, что обрабатывать крупные массивы данных в Си быстрее, я решил — надо читать файлы. Это решение было вызвано желанием проверить, насколько шустро код сможет общаться с системой.
Для этих целей я сгенерировал стопку файлов (конечно же, линейно возрастающих в своем размере)
static void Generate()
{
Random r = new Random();
for(int i=0; i<100; i++)
{
BinaryWriter writer = new BinaryWriter(File.OpenWrite("file" + i.ToString()));
for(int j=0; j<200000*i; j++)
{
writer.Write(r.Next(-1, 2));
}
writer.Close();
Console.WriteLine("Generating {0}", i);
}
}В итоге самый большой файл получился 75 мегабайт, чего было вполне себе достаточно. Для теста я не стал выделять отдельный класс, а на
static int FileSum(string path)
{
BinaryReader br = new BinaryReader(File.OpenRead(path));
int sum = 0;
long length = br.BaseStream.Length;
while(br.BaseStream.Position != length)
{
sum += br.ReadInt32();
}
br.Close();
return sum;
}Как видно из кода, задачу я поставил следующую: просуммировать все целые числа из файла. Соответствующая реализация на Си:
EXPORT int STD_API file_sum( const char* path )
{
FILE *f = fopen( path, "rb" );
if ( !f )
return 0;
int sum = 0;
while ( !feof( f ) )
{
int add;
fread( &add, sizeof( int ), 1, f );
sum += add;
}
fclose( f );
return sum;
}Теперь осталось циклически прочитать все файлы, да измерить скорость работы каждой реализации. Код функции замера приводить не буду (его можно составить и самому) и перейду сразу к наглядным демонстрациям.
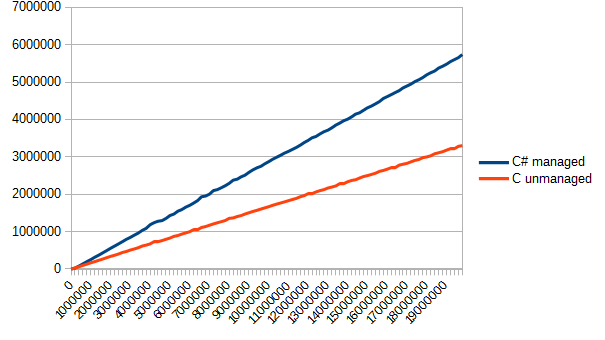
Как видно из данного графика, Си оказался немного быстрее (примерно в полтора раза). Но выигрыш есть выигрыш.
Где-то на этом моменте меня понесло немного в степь (или куда-то еще), но не поделиться этими размышлениями я не могу. Любопытных прошу в спойлер, а всех остальных прошу перейти к следующей части моих исследований.
long length = br.BaseStream.Length;
byte[] buffer = new byte[100000*4];
while(br.BaseStream.Position != length)
{
int read = br.Read(buffer, 0, 100000*4);
for(int i=0; i<read; i+=4)
{
sum += BitConverter.ToInt32(buffer, i);
}
} int sum = 0;
int *buffer = malloc( 100000 * sizeof( int ) );
while ( !feof( f ) )
{
int read = fread( buffer, sizeof( int ), 100000, f );
for ( int i = 0; i < read; i++ )
{
sum += buffer[ i ];
}
}Этот тест я не захотел включать в «основу» статьи, и на то была одна причина: тест не совсем справедливый. Си явно лучше подходил для такой задачи, потому что может писать что угодно и куда угодно, а вот в C# пришлось дополнительно конвертировать все побайтово, из-за чего я получил то, что получил:
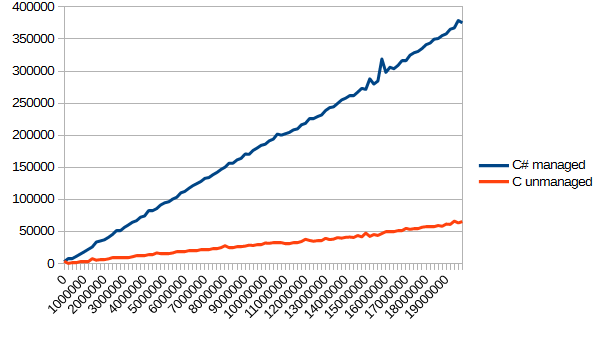
Я склонен думать, что такая разница в производительности вызвана именно необходимостью дополнительно конвертировать байты в слова. Вообще, эта тема заслуживает отдельной статьи, которую я может быть даже напишу.
Возвращение массивов
Следующим шагом в замерах производительности стало возвращение более сложных типов, потому что общаться числами целыми и с плавающей точкой будет не всегда удобно. Поэтому нужно проверить, насколько быстро можно приводить неуправляемые области памяти к управляемым. Для этого было принято решение реализовать простую задачу: чтение файла целиком и возвращение его содержимого в виде массива байтов.
На чистом C# такая задача реализуется весьма просто, но чтобы связать Си код с C# кодом в данном случае придется сделать кое-что еще.
Для начала, решение на C#
static byte[] FileRead(string path)
{
BinaryReader br = new BinaryReader(File.OpenRead(path));
byte[] ret = br.ReadBytes((int)br.BaseStream.Length);
br.Close();
return ret;
}И соответствующее решение на Си:
EXPORT char* STD_API file_read( const char* path, int* read )
{
FILE *f = fopen( path, "rb" );
if ( !f )
return 0;
fseek( f, 0, SEEK_END );
long length = ftell( f );
fseek( f, 0, SEEK_SET );
read = length;
int sum = 0;
uint8_t *buffer = malloc( length );
int read_f = fread( buffer, 1, length, f );
fclose( f );
return buffer;
}Для успешного вызова такой функции из C# нам придется написать обертку, которая вызовет эту функцию, скопирует данные из неуправляемой памяти в управляемую, да освободит неуправляемый участок:
static byte[] FileReadUnmanaged(string path)
{
int length = 0;
IntPtr unmanaged = file_read(path, ref length);
byte[] managed = new byte[length];
Marshal.Copy(unmanaged, managed, 0, length);
Marshal.FreeHGlobal(unmanaged); // Мы же не желаем протекать?
return managed;
}В функции замера изменились только соответствующие вызовы измеряемых функций. А результат выглядит вот так:
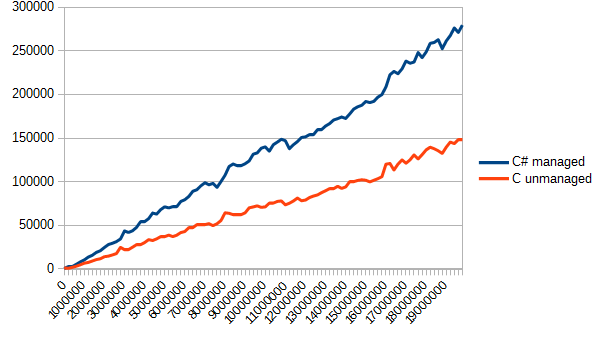
Даже с потерями времени на копирование памяти Си снова оказался в лидерах, выполняя поставленную задачу примерно в 2 раза быстрее. Честно говоря, я ожидал немного других результатов (учитывая данные второго теста). Скорее всего из-за того, что чтение данных даже крупной пачкой в C# происходит достаточно медленно. В Си же потрея времени идет при копировании неуправляемой памяти в управляемую.
Реальная задача
Логическим заключением всех проведенных мною тестов было таким: реализовать какой-нибудь полноценный алгоритм на C# и на Си. Быстродействие оценить.
За алгоритм я принял чтение несжатого TGA файла с 32 битами на пиксель, да приведение его в
struct Color
{
public byte r, g, b, a;
}Реализация алгоритма довольно емкая, да и вряд ли интересна. Поэтому она вынесена в спойлер, чтобы не мозолить глаза тем, кому не интересно.
static Color[] TGARead(string path)
{
byte[] header;
BinaryReader br = new BinaryReader(File.OpenRead(path));
header = br.ReadBytes(18);
int width = (header[13] << 8) + header[12]; // Небольшая магия, чтобы получить short
int height = (header[15] << 8) + header[14]; // Little-Endian, сначала младшие разряды
byte[] data;
data = br.ReadBytes(width * height * 4);
Color[] colors = new Color[width * height];
for(int i=0; i<width*height*4; i+=4)
{
int index = i / 4;
colors[index].b = data[i];
colors[index].g = data[i + 1];
colors[index].r = data[i + 2];
colors[index].a = data[i + 3];
}
br.Close();
return colors;
}
static Color[] TGAReadUnmanaged(string path)
{
int width = 0, height = 0;
IntPtr colors = tga_read(path, ref width, ref height);
IntPtr save = colors;
Color[] ret = new Color[width * height];
for(int i=0; i<width*height; i++)
{
ret[i] = Marshal.PtrToStructure<Color>(colors);
colors += 4;
}
Marshal.FreeHGlobal(save);
return ret;
}
И Сишный вариант:
#include "api.h"
#include <stdlib.h>
#include <stdio.h>
// Ведет к беде, если структура выровняется
// не по 4 байтам
typedef struct {
char r, g, b, a;
} COLOR;
// Костыль, чтобы читать структуру целиком
#pragma pack(push)
#pragma pack(1)
typedef struct {
char idlength;
char colourmaptype;
char datatypecode;
short colourmaporigin;
short colourmaplength;
char colourmapdepth;
short x_origin;
short y_origin;
short width;
short height;
char bitsperpixel;
char imagedescriptor;
} TGAHeader;
#pragma pack(pop)
EXPORT COLOR* tga_read( const char* path, int* width, int* height )
{
TGAHeader header;
FILE *f = fopen( path, "rb" );
fread( &header, sizeof( TGAHeader ), 1, f );
COLOR *colors = malloc( sizeof( COLOR ) * header.height * header.width );
fread( colors, sizeof( COLOR ), header.height * header.width, f );
for ( int i = 0; i < header.width * header.height; i++ )
{
char t = colors[ i ].r;
colors[ i ].r = colors[ i ].b;
colors[ i ].b = t;
}
fclose( f );
return colors;
}Теперь дело осталось за малым. Нарисовать простое TGA изображение и загружать его n раз. Результат получился таким (по вертикали как обычно, по горизонтали – количество чтений файла).
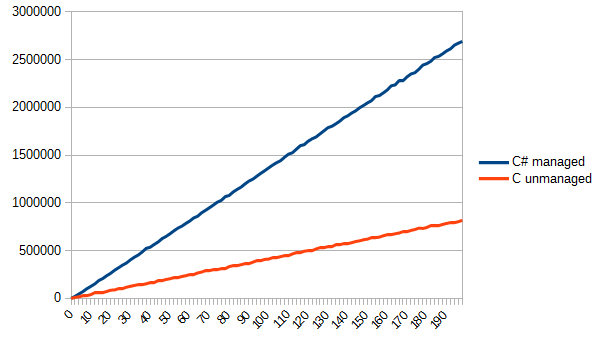
Тут нужно отметить, что я нагло использовал возможности Си в его пользу. Читать из файла прямо в структуры существенно облегчило жизнь (а в случае, когда структуры выровняются не по 4 байтам, будет веселая отладка). Однако результатом я доволен. Такой вот незамысловатый алгоритм получилось эффективно реализовать на Си, и эффективно его же использовать в C#. Соответственно, я получил ответ на изначальный вопрос: выиграть действительно можно, но не всегда. Иногда можно выиграть незначительно, иногда не выиграть вовсе, а иногда выиграть в несколько и больше раз.
Сухой остаток
В целом, сама идея выносить реализацию чего-то на другой язык сомнительна, как я и написал в самом начале. В конце концов, применения такому способу ускорения кода можно найти достаточно мало. Если открытие файла начинает вешать UI – можно вынести загрузку в отдельный фоновый поток, и тогда загрузка даже в секунду не вызовет ни у кого серьезных затруднений.
Соответственно, так извращаться стоит только тогда, когда производительность действительно необходима, и добиться ее другими путями уже не получается (а в таких случаях обычно пишут сразу на Си или С++). Или если уже есть готовый алгоритм, который можно использовать, а не изобретать велосипед.
Хочется отметить, что простая обертка над неуправляемой dll особого выигрыша в производительности не даст, и вся «шустрость» неуправляемых языков начинает раскрываться только при обработке достаточно больших объемов данных, так что на это тоже стоит обратить внимание. Однако и от использования такой обертки хуже не станет.
C# очень хорошо справляется с передачей управляемых ресурсов неуправляемому коду, но обратное превращение происходит не так быстро, как хотелось бы. Поэтому частого преобразования данных желательно избегать и держать неуправляемые ресурсы в неуправляемом коде. Если нет необходимости эти данные править / читать в управляемом коде, то можно использовать IntPtr для хранения указателей, а оставшуюся работу вынести целиком в неуправляемый код.
Конечно, можно (и даже нужно) провести дополнительные исследования перед принятием окончательного решения о переносе кода в неуправляемые сборки. Но и с текущей информацией можно принять решение о целесообразности таких действий.
А на этом у меня все. Спасибо, если дочитали до конца!
Комментарии (67)

maaGames
07.04.2017 18:52+3А теперь перепишите с указателями, вместо счётчика цикла. Я про С.

Videoman
07.04.2017 18:58+1И ничего не будет. Только замусорится семантика. Может быть будет даже хуже.
maaGames
07.04.2017 19:00+1Если оптимизирующий компилятор сам не заменил индекс на указатель, то очень даже будет.
Более того, итератор гораздо более семантически «чист», чем индекс массива.Videoman
07.04.2017 19:07+3При работе со значениями у оптимизатора гораздо больше уверенности при оптимизации и руки развязаны. Когда вы применяете указатели, вы легко его можете запутать и он пессимизирует оптимизацию. На сомом деле, в коде с указателями невозможно понять (за исключение ну уж совсем тривиальных случаев) ссылаются ли два указателя на один объект или на два разных. Я всегда применяю магию с указателям, когда не хочу чтобы компилятор выкинул «мертвый», по его мнению код. Стоит только выкинуть указатели, и оптимизатор начинает выкидывать методы пачками.
maaGames
07.04.2017 19:13+1Сумма значений в массиве. Тут целый один итератор, плюс ещё один указатель на конец массива. Запутаться может только неосилятор, но никак не компилятор. На мой взгляд, в данной конкретной ситуации с указателями код гораздо проще, чем с индексом. Не говоря о том, что это «более STL-ориентированно».) Индексы нужны только в том случае, если обработка происходит не последовательно, а с шагом не равным единице. Или если цикл хочется распараллелить. Называть инкремент указателя магией… Впрочем, для C# программистов указатели и впрямь могут казаться магией…
Videoman
07.04.2017 22:53+3Запутаться может только неосилятор, но никак не компилятор.
Чем меньше вариантов и чем лучше вы конкретизируете что вы хотите выразить в коде, тем больше шансов на оптимизацию. «Запутаться» тут просто фигура речи. Давайте рассмотрим классический пример:
*dst++ = *src++; // Copy buffer
Даже в таком простейшем случае компилятор не сможет заменить код на оптимизированный std::memcpy, если не будет уверен что эти указатели не перекрываются. В случае с индексами и массивами у вас больше шансов:
dst[n++] = src[m++]; // Copy buffer
Чего уж говорить про более сложные случаи.maaGames
08.04.2017 06:25int * restrict dst = ...; int * restrict src = ...; *dst = *src; ++dst; ++src;
Кстати, про memcpy. У меня были реальные ситуации, когда копирование в цикле было несколько эффективнее memcpy. Я сильно не вдавался, скорее всего из-за того, что memcpy работает на уровне байт, а в цикле копировалось по 4-8 байт и профит был за счёт меньшего числа итераций. Экономия на инкрементах xD.
И ещё раз про memcpy. Вы точно не перепутали его с memmove? memcpy это просто цикл, на инлайн ассемблере (по крайней мере так было в MSVC лет пять назад), там нет требований по непересекаемости областей памяти.Videoman
08.04.2017 12:13скорее всего из-за того, что memcpy работает на уровне байт
Это не так. Можете сами убедиться. MSVC копирует самими широкими словами, которые есть в его распоряжении.
вы точно не перепутали его с memmove
Точно. У memmove вообще не бывает проблем с перекрытием, она для этого и предназначена.maaGames
08.04.2017 12:25> MSVC копирует самими широкими словами, которые есть в его распоряжении.
Значит, они уже улучшили функцию, разбив цикл копирования на две части: копирование DWORD'ами (QWORD'ами) и добивание оставшегося числа байт по одному. Именно такой алгоритм у меня работал быстрее стандартного memcpy в 2005 студии, или примерно в те года.Videoman
08.04.2017 12:33Шире… они уже копируют SSE регистрами, не помню какого размера, по-моему 128 бит.
maaGames
08.04.2017 12:35Да, я уже в исходниках глянул. Выровненную часть через XMM и прочие регистры пытаются. Для х64 отдельные оптимизации. Теперь уже точно не придётся вручную копирование оптимизировать.

Siemargl
07.04.2017 21:46Это неверное утверждение
Videoman
07.04.2017 22:53Сильный аргумент.
Siemargl
07.04.2017 23:32ОК, утверждающий доказывает.
Приведи пример, где итератор (указатель) дает худшую оптимизацию, чем индекс
Более того, итератор гораздо более семантически «чист», чем индекс массива.
Речь об этом твоем утвержденииVideoman
08.04.2017 00:58Вот только не надо меня брать на понт, хорошо.
Более того, итератор гораздо более семантически «чист», чем индекс массива.
Я это не утвеждал или вы непонятно объясняете о чем речь.
С точки зрения производительности, я уверен что современный компилятор построит абсолютно идентичный код и для указателей и для индексов (это в случае если код нельзя выбросить и его нужно выполнять в лоб, а нужно исполнить механически). А вот если у вас мало мальски сложный код, да еще и на шаблонах, то указатели могут помешать выкинуть неиспользуемый код или оптимизировать его для конкретного частного случая. Для демонстрации рабочего примера нужно проделать много работы, что бы вычленить минимально рабочий пример, а это не тот случай, или искать в интернете, так что ограничимся простейшим:
uint8_t buf[100]; void IndexFill() { for (uint_t n = 0; n < 100; n++) buf[n] = 255; } void PointerFill() { uint8_t* bufp = buf; for (uint_t n = 0; n < 100; n++) *bufp++ = 255; } int main(int argc, char_t* argv[]) { IndexFill(); PointerFill(); return 0; }
VS2013 в первом случае выбрасывает вызов IndexFill() так как результат нигде не используется, а во втором случае PointerFill() честно заполняет массив, так как указатель сбивает ее с толку.Siemargl
08.04.2017 09:10Именно. Просто не попал в нужное сообщение, это maaGames бред пишет.
Указатели всегда сложнее оптимизатору чем простые индексы.
maaGames
08.04.2017 06:32Это было моё утверждение.
Поясню. Итератор (== указатель) по определению обозначает последовательный обход контейнера. При помощи индекса обход может быть хоть последовательный, хоть случайный, хоть какой. Т.е. если используется итератор, код сам говорит о том, что требуется пройти по всем элементам контейнера. Я не беру в расчёт говнокод, когда обращение по индексу заменяют на *(ptr+10), это уже на совести программиста пусть остаётся. Так же итераторы позволяют легко заменить тип контейнера, если это потребуется, практически не изменяя кода.Videoman
08.04.2017 12:06Ок. Давайте уточним кто какую оптимизацию имеет ввиду, а то тут уже полезли итераторы, которые являются указателями только семантически. Итераторы, зто просто не плохая идея (абстракция) для архитектуры стандартной библиотеки. «Не плохая», потому что ranges намного лучше.
Теперь, если компилятор «тупой» (80-е годы) и процессор «тупой» (какой-нибудь DSP простенький), то никто не спорит, что указатели будут быстрее. Я сам начинал писать с PDP-11 ассемблера и очень хорошо представляю что там под капотом. Но время идет и прогресс не стоит на месте. Современные компиляторы в состоянии понять что доступ к индексам последовательный и заменять все умножения на последовательные сложения. Процессоры теперь также имеют множество блоком ALU и могут выполнять сразу много сложений и умножений за один такт, регистры становятся все шире и шире.
Сейчас предпочтительней писать более понятный код, как можно яснее выражать семантику операции и свои намерения. Не нужно заниматься ручной оптимизацией. В случае микрооптимизаций (в пределах одной функции), указатели все еще могут дать выигрыш, но в глобальной оптимизации они только мешают (если мы передаем указатели на данные и объекты из функции в функция или из одного модуля в другой), особенно в ситуации с шаблонами С++, где оптимизатор порой, просто творит чудеса.maaGames
08.04.2017 12:13А я на 100% согласен. Поэтому и написал, что нужно изучать дизассемблированный код в каждом конкретном случае. Если из управляемого кода вызывают модули С/С++, то явно нужно выжать каждую каплю и хочешь или нет, но придётся изучать код, генерируемый компилятором. Просто написать два варианта и измерить скорость — не имеет смысла, т.к. бинарный код может оказаться идентичным. Поэтому, каждый конкретный случай рассматривается индивидуально и не только от используемой платформы и версии компилятора, но даже в каждом конкретном месте использования может разный код генерироваться.
> уже полезли итераторы, которые являются указателями только семантически.
Ну, вот, вы подтвердили моё утверждение про семантическую «чистоту» указателей.) Для итерации по массиву указатель(он же итератор) более семантически «чист» чем индекс.Videoman
08.04.2017 12:35Просто написать два варианта и измерить скорость — не имеет смысла
Согласен, не имеет. Просто я, примерно, видя код уже могу сказать что выигрыша не будет просто исходя из опыта. Часто приходится иметь дело с оптимизацией и все эти штуки MSVC уже знаешь.
Ну, вот, вы подтвердили моё утверждение про семантическую «чистоту» указателей
Я и не спорю. Я правда не уверен что вы имеете ввиду под «чистотой». Если более сильную абстракцию, как и я, то это хорошо только для архитектуры, но в тоже время плохо для оптимизации, где чем более специфический и конкретный будет оператор тем лучше.maaGames
08.04.2017 12:38На самом деле, я не имею в виду ничего.) Вы написали, что указатели замусоривают семантику (ваш первый комментарий в этой ветке). На мой взгляд, в конкретном случае указатели ничего не замусоривают. На мой взгляд даже более чётко говорят о намерениях. Но я говорю только об этом случае, а не о вообще.

GrimMaple
07.04.2017 19:45+4Заморочился, переписал:
int* end = data + length; while ( data != end ) sum += *data++;
Результат не изменился почти никак, как и отметил Videoman

Как-то так. Но идея была интересная.maaGames
08.04.2017 06:16+1В данном случае нужно ещё дизассемблер сравнивать, чтобы убедиться, что компилятор разный код для этих реализаций создавал. Потому что тело цикла элементарно и на поддержку индекса требуется больше работы, чем на сами вычисления. Т.е. инкремент указателя, разыменование и добавление к числу это быстрее, чем инкремент индекса, умножение индекса на размер типа, сдвиг указателя на результат этого произведения, разыменование и добавление к сумме. Вопрос лишь в том, на сколько именно они различаются. Когда речь идёт об оптимизирующем компиляторе, то нужно смотреть в дизассемблированный листинг, чтобы убедиться, что код получился не идентичным.
Ну и на втором графике видим бОльшую стабильность, график более гладкий. Тоже плюс, наверное.)
crea7or
07.04.2017 19:22Я для того же делал два проекта for fun при поиске совпадений степеней по теореме Эйлера, ну c# проигрывает с++, но не сказать чтобы прямо очень.

voidnugget
07.04.2017 21:03+4Есть очень много особенностей и ограничений целевых компиляторов, а также отсутствие вменяемой оптимизации в случае с Сишкой на форточках. В llvm этот вопрос решён хоть как-то, но по уровню оптимизации сишка уступает тому же rust'у. По этому от фронтенда до фронтенда один и тот же биткод (они решили отличиться) будет оптимизирован по разному.
На практике большая часть существующих оптимизаций:
• разворачивание циклов для последующего использования SIMD операций
• комбинирование макро команд для выполнение за один такт процессора (mov, test, cmp etc).
• контроль заполнения очереди комманд
• принудительная подчистка кэша
• контроль глубины ветвлений
• минимизация количества операций со стэком
• использование регистровой памяти для передачи аргументов функций
не применяются вообще, особенно в форточках, либо применяются довольно криво...
У ABI cишки слишком много консервативных и устаревших ограничений для сохранения портабельности, которые нынче не то что не нужны, а просто ставят крест на вертикальном масштабировании большинства решений.
В примерах со статьи — имеет смысл использовать SSE2/SSE4 и AVX2 операции.
Даже банальные strstr / strcmp имеют ассемблерные SIMD аналоги выполняющиеся ровно за один такт, а если правильно чистить кэш и предовращать ITLB/DTLB miss, то и по 4 штуки за такт (по 64/128 байт).
Приложения со статьи получат на выходе приблизительно одинаковый листинг ассемблерных инструкций без каких либо вменяемых оптимизаций, по этому сравнивать их не совсем корректно и целесообразно. Особенно что касается скорости системных вызовов I/O — это просто не самая удачная метрика.
Также есть специализированное File mapping API — аналог
mmapPosix вызова.
exchg
07.04.2017 22:05У ABI cишки слишком много консервативных и устаревших ограничений для сохранения портабельности, которые нынче не то что не нужны, а просто ставят крест на вертикальном масштабировании большинства решений.
Можете привести пример какие такие сишные ABI?
exchg
07.04.2017 22:55а также отсутствие вменяемой оптимизации в случае с Сишкой на форточках
Вменяемой оптимизации по сравнению с чем?
но по уровню оптимизации сишка уступает тому же rust'у.
ну там же сам автор признал, что первая попытка была неверная и написал специально второй пост в котором ему также указали, что для получения схожего эффекта есть ключевое слово restrict.
По этому от фронтенда до фронтенда один и тот же биткод (они решили отличиться) будет оптимизирован по разному.
Да что уж там, один и тот же байткод будет отличатся от компилятора к компилятору ну и что?
voidnugget
07.04.2017 23:18какие такие сишные ABI?
Например вот это нечто пожирающее стэк без острой необходимости.
оптимизации по сравнению с чем?
С официальным гайдом по оптимизации.
ну там же сам автор признал
Действительно плохой пример. Просто на практике сталкивался с подобными вещами довольно часто, чаще чем хотелось бы.
Да что уж там, один и тот же байткод будет отличатся от компилятора к компилятору ну и что?
Есть micro и macro fusion операции внутри самого блока трансляции процессора… различие в результирующем коде означает что везде они будут применяться по разному, и зависеть от солнечной радиации и положения звёзд на небе… как и производительность результирующего кода.
exchg
07.04.2017 23:42+1Например вот это нечто пожирающее стэк без острой необходимости.
И какое отношение это имеет к "сишичке"? Изначальное утверждение было о том, что сишные ABI консервативны устаревши и ставят крест на вертикальной масштабируемости, вот я и спрашиваю какие такие сишные ABI?
С официальным гайдом по оптимизации.
Не совсем понял, какой-то компилятор генерирует код под форточки, который противоречит этому ману? Или тут упор на то, что ручная оптимизация качественней чем автоматическая?
Кстати современные (условно, примерно лет 15 последних) оптимизирующие компиляторы делают порой чудные оптимизации до которых так просто и не додумаешся. Не говоря о том, что код на "сишичке" нужно грамотно расхинтовать для началу,
voidnugget
08.04.2017 00:02И какое отношение это имеет к "сишичке"?
Прямое, это и есть сишное ABI, — унифицированная конвенция вызова сишных функций в форточках на x64 системах.
Какой-то компилятор генерирует код под форточки, который противоречит этому ману?
Не один существующий компилятор не генерирует код который ему следует.
… до которых так просто и не додумаешся
Не используется многопроходный GA.
Оно не сможет эффективно использовать большую часть существующих SIMD инструкций и менять последовательности команд в различных оптимизационных целях… приходится самому всегда колупаться в intrinsics'ах. Даже полигидральные плюшки не решают этот вопрос.exchg
08.04.2017 00:27Прямое, это и есть сишное ABI, — унифицированная конвенция вызова сишных функций в форточках на x64 системах.
Т.е. сишное это то, которое может использоваться в си? Сами по себе ни Си ни С++ не определяют никаких ABI. Ну и каким образом это соглашение о вызове ставит крест на вертикальной масштабируемости?
Оно не сможет эффективно использовать большую часть существующих SIMD инструкций и менять последовательности команд в различных оптимизационных целях
Так оно же мысли читать не умеет, компилятору без хинта не понятно нужно считывать все время значение по адресу или программист задумал, что значение меняться не будет и можно закешировать значение в регистре.
Оно не сможет эффективно использовать большую часть существующих SIMD инструкций и менять последовательности команд в различных оптимизационных целях…
Ну допустим пока не сможет, хотя верится слабо, зачем тогда нужен программист? )
voidnugget
08.04.2017 00:58Какой смысл в компиляторе, который не может полноценно использовать весь набор инструкций процессора, и требует что бы программист сам вставлял их где это нужно ?
exchg
08.04.2017 13:30Да может он использовать весь набор. -mach=native и в перед.
voidnugget
08.04.2017 20:44Собственно речь о том что если бы умели нормально их утилизировать — не нужны были бы специфические оптимизации на основе параметрических многогранников и прочего, а так для каждой SIMD инструкции или подчистки кэша надо лезть в Intrinsics интерфейс...

lieff
08.04.2017 00:44Я пытался использовать rust для производительного кода, увы, пока не все так гладко. Вот вам обратный пример, нету alloca.
Пример что вы привели правильно говорит что некоторые случаи в расте для оптимизитора лучше, но это не значит что на си нельзя оптимизировать чтобы было так же.
Такую же функцию, чтобы получилась 1 асм инструкция легко сделать и на си, более того многие inrinsic функции так и сделаны в системных инклудах, и принимать они могут на вход и выход любые регистры, несмотря на ABI.
Дело вот в чем, в расте просто все функции fn foo() по дефолту скрытые и не имеют привязки к ABI. Как только вы делаете функцию публичной pub extern «C» fn foo() и доступной извне, она приобретает ABI. В си же не имеют привязки статические функции, инлайновые и при использовании whole programm optimization(или и использованием профайловой оптимизации), которые не экспортируются (соответственно ABI им не нужен). Соответственно точно так же можно промаркировать интерфейсные функции торчащие наружу, а остальные скрыть и они будут оптимизироваться как угодно. Так что с ABI пример плохой.voidnugget
08.04.2017 01:03rust использует llvm… и к форточкам это не имеет никакого отношения.
Любая C/С++ функция под форточками будет использовать существующее ABI — там нет понятия "whole program optimization" так как подобные оптимизации могут быть выполнены только во время линковки, и они не реализованы в существующих линковщиках.lieff
08.04.2017 01:07Это давно умеет и llvm (-flto) и msvc (/GL) и gcc (-flto). Так что не будет, я под всеми этими компиляторами это проделывал и специально смотрел асм что все как надо оптимизировалось. Так же это давно используют крупные проекты как firefox, chrome итд.
voidnugget
08.04.2017 01:13Про эти оптимизации во время линковки я в курсе…
Не знаю, не смотрел что на выходе получается, но вряд ли они будут ломать существующее глючное ABI.lieff
08.04.2017 01:20Для интерфейсных функций что торчат наружу — не будут, как и раст не будет. Для внутренних — как угодно в каких угодно регистрах, есть даже ключи компиляции (-fvisibility=hidden) чтобы скрыть все функции по дефолту аля раст, а интерфейсные придется помечать __attribute__((visibility(«default»))). И скрипотм линкера тоже можно скрыть все кроме того что указано (-Wl,--version-script=$(TARGET_EXE).exports). И тогда компилер для внутренних функций ABI не соблюдает, я проверял, даже баг постил на это тему в gold/ld линкер.
voidnugget
08.04.2017 13:34Это радует.
Правда на форточках пока мною замечено не было.lieff
08.04.2017 14:03На форточках это появилось раньше чем в gcc (в llvm было изначально). Просто компилируйте с WPO\PGO, это в любом случае полезно и включает массу других оптимизаций, вот например описания что включают WPO и PGO.
То про что вы говорите это:If the compiler can identify all of the call sites of a function, the compiler ignores explicit calling-convention modifiers on a function and tries to optimize the function's calling convention:
И это только один из пунктов. Собственно rust использует абсолютно те же механизмы llvm что и си.voidnugget
08.04.2017 20:41+1WPO/PGO не означает что MSVC откажется от существующих x64 ABI и начнёт их ломать в угоду утилизации регистровой памяти. К сожалению WPO/PGO не приводят к ожидаемому вами эффекту на х64'ой платформе, а на x86 просто подбирается наиболее эффективная конвенция вызовов, но существующее ABI сохраняется.
С MSDN'a:
When /LTCG is used to link modules… following optimizations are performed:
• Cross-module inlining
• Interprocedural register allocation (64-bit operating systems only)
• Custom calling convention (x86 only)
• Small TLS displacement (x86 only)
• Stack double alignment (x86 only)
• Improved memory disambiguationRegister Allocation вставляет хинты на подобие
USESв MASM'е для резервирования регистровой памяти.lieff
08.04.2017 22:12Нет, не сохраняется, x86 тут скорее всего имеется ввиду не ARM компилятор, который у msvc теперь тоже есть. Я это видел своими глазами, Custom calling convention работает, так же как и в llvm. При этом и при инлайне оно произвольные регистры использует (это и используется когда интринзики не внутри компилятора, а в h файлах, состоящие из одноасмовых инструкций, или комплексный интринзик из нескольких одноасмовых), и при генерации внутренней функции. В любом случае прямым текстом написано что компилер умеет понимать что нашел все точки вызова фкнкции, соответственно дальше он делает лучшее на что способен, если бы llvm не умел Custom calling convention, этого бы небыло что в си что в rust. Так что все же с ABI пример плохой.
DistortNeo
08.04.2017 23:00Мне кажется, основной выигрыш в производительности достигается за счёт инлайнинга, а не оптимизации соглашения о вызовах. А для x64 нет смысла менять конвенцию — параметры и так передаются через регистры.
DistortNeo
08.04.2017 00:33Есть очень много особенностей и ограничений целевых компиляторов, а также отсутствие вменяемой оптимизации в случае с Сишкой на форточках.
Как это нету? А Intel Compiler?
voidnugget
08.04.2017 01:11У ICC в целом есть пару особенностей — он обычно мелочёвку оптимизирует на много лучше GCC/LLVM (20-30% компактнее и шустрее), но любые сложные вещи любит раздувать до непонятных размеров (почти в 3 раза). По этому у него свои, особенные глюки с оптимизациями… Для научных вычислений и прочего он подходит лучше чем GCC/LLVM, но любые пользовательские приложения он будет раздувать до совсем несуразных размеров.

apro
08.04.2017 07:35В llvm этот вопрос решён хоть как-то, но по уровню оптимизации сишка уступает тому же rust'у.
По приведенной ссылке:
Update Actually as dbaupp points out, this optimization example is not specific to Rust. In fact, LLVM is doing it via local > analysis (the sort I mentioned above), and clang++ produces the same results for the equivalent C++ code. In fact Rust > in general would need to preserve references because you can convert a reference to a raw pointer and compare them > for equality.

Razaz
07.04.2017 21:59+7Для работы с массивами рекомендую посмотреть на Span. Потом заглянуть сюда — System.Buffers.
Ну и stackalloc до кучи.
Так же в CoreFX появилось много других плюшек для более эффективной работы с памятью.
Ну и это все в unsafe сделать. Страшного тут ничего нет ;)
Пример кода со всякими интересными штуками можно глянуть тут.
Ну и не использовать уже 4.5.2. Хотя бы 4.6.2, а лучше 4.7, если вам именно .Net нужен. Про BenchmarkDotNet вам уже сказали ;)
VMAtm
08.04.2017 17:13+1А ещё можно попробовать .Net Native или пре-компиляцию библиотек в C#.
Razaz
09.04.2017 00:18+1Ну это пока в основном на UWP упор.
Вот еще заинтересованным почитать Safe Systems Programming in C# and .NET.
gturk
08.04.2017 02:48+7В c# есть оптимизация при работе с массивами, если в качестве верхней границы цикла использовать не переменную length, а именно array.Length, то он выкинет проверку выхода за границы массива. Это же справедливо и для конструкции foreach.
Можете сделать соответсвующие замеры?GrimMaple
10.04.2017 09:33Учитывая количество предложений, которые были высказаны в комментариях, да и желание проверить еще парочку вещей — я думаю погонять еще кое-какие тесты, а результаты вынести в отдельную статью. Соответственно, эти примеры могу тоже посмотреть и расписать :)

PsyHaSTe
13.04.2017 20:49Не забудьте битность тоже проверять, х64 JIT написан намного умнее и может сделать пару очень приятных оптимизаций. Не потому, что там размер слова другой, а просто потому что качество самого компилятора выше.

masha_kupina
08.04.2017 22:05Спасибо, уважаемый! Очень интересная статья и полезная тема, комменты тут — просто клад для новичка)

alz72
09.04.2017 20:13У C# есть одно из неоспоримых достоинств — мультиплатформенность ( хоть и не так уж давно появившееся). Поэтому было бы интересно проверить быстродействие Си с использованием мультиплатформенных библиотек типа Qt.
Siemargl
09.04.2017 23:16Да не так все печально было. Около 30-50% проигрыша на вычислительных тестах С#.vs.C
Разве что время загрузки учитывается
Oxoron
Why not BenchmarkDotNet?
GrimMaple
Потому что до этого комментария не знал о существовании такого инструмента. Теперь знаю, спасибо :)