
Основной принцип программирования гласит: не изобретать велосипед. Но иногда, чтобы понять, что происходит и как использовать инструмент неправильно, нам нужно это сделать. Сегодня изобретаем паттерн многопоточного выполнения задач.
Представим, что у вас которая вызывает большую загрузку процессора:
public class Counter {
public Double count(double a) {
for (int i = 0; i < 1000000; i++) {
a = a + Math.tan(a);
}
return a;
}
}Мы хотим как можно быстрее обработать ряд таких задач, попробуем*:
public class SingleThreadClient {
public static void main(String[] args) {
Counter counter = new Counter();
long start = System.nanoTime();
double value = 0;
for (int i = 0; i < 400; i++) {
value += counter.count(i);
}
System.out.println(format("Executed by %d s, value : %f",
(System.nanoTime() - start) / (1000_000_000),
value));
}
}На моей тачке с 4 физическими ядрами использование ресурсов процессора top -pid {pid}:

Время выполнения 104 сек.
Как вы заметили, загрузка одного процессора на один java-процесс с одним выполняемым потоком составляет 100%, но общая загрузка процессора в пользовательском пространстве составляет всего 2,5%, и у нас есть много неиспользуемых системных ресурсов.
Давайте попробуем использовать больше, добавив больше рабочих потоков:
public class MultithreadClient {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService threadPool = Executors.newFixedThreadPool(8);
Counter counter = new Counter();
long start = System.nanoTime();
List<Future<Double>> futures = new ArrayList<>();
for (int i = 0; i < 400; i++) {
final int j = i;
futures.add(
CompletableFuture.supplyAsync(
() -> counter.count(j),
threadPool
));
}
double value = 0;
for (Future<Double> future : futures) {
value += future.get();
}
System.out.println(format("Executed by %d s, value : %f",
(System.nanoTime() - start) / (1000_000_000),
value));
threadPool.shutdown();
}
}Занятые ресурсы:
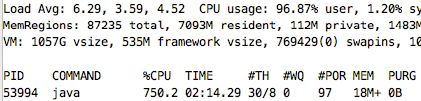
ThreadPoolExecutor
Для ускорения мы использовали ThreadPool — в java его роль играет ThreadPoolExecutor, который может быть реализован непосредственно или из одного из методов в классе Utilities. Если мы заглянем внутрь ThreadPoolExecutor, мы можем найти очередь:
private final BlockingQueue<Runnable> workQueue;в которой задачи собираются, если запущено больше потоков чем размер начального пула. Если запущено меньше потоков начального размера пула, пул попробует стартовать новый поток:
public void execute(Runnable command) {
...
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
...
if (isRunning(c) && workQueue.offer(command)) {
...
addWorker(null, false);
...
}
}Каждый addWorker запускает новый поток с задачей Runnable, которая опрашивает workQueue на наличие новых задач и выполняет их.
final void runWorker(Worker w) {
...
try {
while (task != null || (task = workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)) != null) {
...
task.run();
...
}ThreadPoolExecutor имеет очень понятный javadoc, поэтому нет смысла его перефразировать. Вместо этого, давайте попробуем сделать наш собственный:
public class ThreadPool implements Executor {
private final Queue<Runnable> workQueue = new ConcurrentLinkedQueue<>();
private volatile boolean isRunning = true;
public ThreadPool(int nThreads) {
for (int i = 0; i < nThreads; i++) {
new Thread(new TaskWorker()).start();
}
}
@Override
public void execute(Runnable command) {
if (isRunning) {
workQueue.offer(command);
}
}
public void shutdown() {
isRunning = false;
}
private final class TaskWorker implements Runnable {
@Override
public void run() {
while (isRunning) {
Runnable nextTask = workQueue.poll();
if (nextTask != null) {
nextTask.run();
}
}
}
}
}Теперь давайте выполним ту же задачу, что и выше, с нашим пулом.
Меняем строку в MultithreadClient:
// ExecutorService threadPool = Executors.newFixedThreadPool (8);
ThreadPool threadPool = new ThreadPool (8);Время выполнения практически одинаковое — 15 секунд.
Размер пула потоков
Попробуем еще больше увеличить количество запущенных потоков в пуле — до 100.
ThreadPool threadPool = new ThreadPool(100);Мы можем видеть, что время выполнения увеличилось до 28 секунд — почему это произошло?
Существует несколько независимых причин, по которым производительность могла упасть, например, из-за постоянных переключений контекста процессора, когда он приостанавливает работу над одной задачей и должен переключаться на другую, переключение включает сохранение состояния и восстановление состояния. Пока процессор ??занято переключением состояний, оно не делает никакой полезной работы над какой-либо задачей.
Количество переключений контекста процесса можно увидеть, посмотрев на csw параметр при выводе команды top.
На 8 потоках:
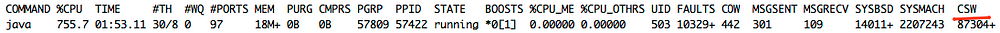
На 100 потоках:
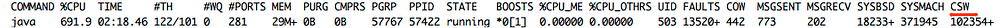
Как выбрать размер пула?
Размер зависит от типа выполняемых задач. Разумеется, размер пула потоков редко должен быть захардокожен, скорее он должен быть настраиваемый а оптимальный размер выводится из мониторинга пропускной способности исполняемых задач.
Предполагая, что потоки не блокируют друг друга, нет циклов ожидания I/O, и время обработки задач одинаково, оптимальный пул потоков = Runtime.getRuntime().availableProcessors() + 1.
Если потоки в основном ожидают I/O, то оптимальный размер пула должен быть увеличен на отношение между временем ожидания процесса и временем вычисления. Например. У нас есть процесс, который тратит 50% времени в iowait, тогда размер пула может быть 2 * Runtime.getRuntime().availableProcessors() + 1.
Другие виды пулов
Пул потоков с ограничением по памяти, который блокирует отправку задачи, когда в очереди слишком много задач MemoryAwareThreadPoolExecutor
- Пул потоков, который регистрирует JMX-компонент для контроля и настройки размера пула в runtime.
JMXEnabledThreadPoolExecutor
Исходный код можно найти здесь.
[*] — тест не является точным, для более точных тестов используйте: http://openjdk.java.net/projects/code-tools/jmh/
Комментарии (9)

aleksandy
12.04.2017 06:15+1А зачем isRunning статическая? Чтобы, выключая один пул, рубануть и все остальные?


freeart
12.04.2017 10:01+1Или это опечатка, или я запутался: время выполнения всех задач было 15 секунд, но потом «время выполнения уменьшилось до 28 секунд». Оно все-таки увеличилось? Или 15 секунд это было время выполнения одной задачи?
rraderio
12.04.2017 11:56Существует несколько независимых причин, по которым производительность могла упасть
rraderio
12.04.2017 11:51Существует несколько независимых причин, по которым производительность могла упасть
woodhead
13.04.2017 17:20+1В формуле вычисления оптимального пула потоков видимо должно быть не
, аRuntime.getRuntime().availProcessors ()
.Runtime.getRuntime().availableProcessors()
sergey-b
Я размер пула потоков подбираю методом научного тыка. Запускаю сначала Ncpu потоков, затем увеличиваю в два раза и сравниваю скорость. Если скорость работы упала, то уменьшаю, если возросла, то еще увеличиваю. И так нахожу оптимальный для данной задачи размер пула. Обычно хватает 4-5 пробных запусков по 5-10 минут.
Suvitruf
Это хорошо, если у вас приложение всего 1 задачу решает. Если же таких тяжёлых задач несколько, то методом тыка уже не выкрутитесь, нужно как-то шарить потоки между задачами, чтоб не было ситуации, когда одна задача забьёт весь пул, и остальные задачи будут простаивать в ожидании.