
Java*
Как это работает в мире java. ConcurrentMap +35
Основной принцип программирования гласит: не изобретать велосипед. Но иногда, чтобы понять, что происходит и как использовать инструмент правильно, нам необходимо это делать. Сегодня изобретаем ConcrurrentHashMap.
Сперва нам понадобятся 2 вещи. Начнем с 2х тестов — первый скажет, что у нашей реализации нет data races (на самом деле нам нужно проверить, правилен ли наш тест также путем тестирования заведомо некорректной реализации), второй тест мы будем использовать для тестирования производительности с точки зрения throughput.
Рассмотрим только несколько методов из интерфейса Map:
public interface Map<K, V> {
V put(K key, V value);
V get(Object key);
V remove(Object key);
int size();
}Thread-safety correctness test
Практически невозможно написать тест безопасности потоков достаточно исчерпывающе, вам необходимо принять во внимание все аспекты, определенные в главе 17 JLS, более того, в большой степени тест зависит от модели аппаратной памяти или реализации JVM.
Для thread-safe correctness теста используем одну из готовых библиотек стресс-тестов, такую как jcstress, которая будет запускать ваш код, пытаясь найти несогласованность данных. Хотя jcstress все еще отмечен, как экспериментальный, это лучший выбор. Почему сложно написать собственный тест на параллелизм — посмотрите лекцию Шипилева.
Я использую для запуска jstress jcstress-gradle-plugin. Полный исходный код можно найти how-it-works-concurrent-map.
public class ConcurrentMapThreadSafetyTest {
@State
public static class MapState {
final Map<String, Integer> map = new HashMap<>(3);
}
@JCStressTest
@Description("Test race map get and put")
@Outcome(id = "0, 1", expect = ACCEPTABLE, desc = "return 0L and 1L")
@Outcome(expect = FORBIDDEN, desc = "Case violating atomicity.")
public static class MapPutGetTest {
@Actor
public void actor1(MapState state, LongResult2 result) {
state.map.put("A", 0);
Integer r = state.map.get("A");
result.r1 = (r == null ? -1 : r);
}
@Actor
public void actor2(MapState state, LongResult2 result) {
state.map.put("B", 1);
Integer r = state.map.get("B");
result.r2 = (r == null ? -1 : r);
}
}
@JCStressTest
@Description("Test race map check size")
@Outcome(id = "2", expect = ACCEPTABLE, desc = "size of map = 2 ")
@Outcome(id = "1", expect = FORBIDDEN, desc = "size of map = 1 is race")
@Outcome(expect = FORBIDDEN, desc = "Case violating atomicity.")
public static class MapSizeTest {
@Actor
public void actor1(MapState state) {
state.map.put("A", 0);
}
@Actor
public void actor2(MapState state) {
state.map.put("B", 0);
}
@Arbiter
public void arbiter(MapState state, IntResult1 result) {
result.r1 = state.map.size();
}
}
}В первом тесте MapPutGetTest у нас есть два потока, выполняющих одновременно методы actor1 и actor2, соответственно, оба они кладут некоторое значение в map и проверяют их обратно, если нет гонки данных, оба потока должны видеть заданные значения.
Во втором MapSizeTest мы одновременно помещаем два разных ключа в map и после проверки размера — если нет гонки данных — ожидаемый результат должен быть = 2.
Для того, чтобы проверить корректность теста, выполним его на заведомо потоконебезопасном HashMap — мы должны наблюдать нарушение атомарности. Если запустить тест на потокобезопасном ConcurrentHashMap — мы не должны видеть нарушение консистентности.
Результаты с HashMap:
[FAILED] ru.skuptsov.concurrent.map.test.ConcurrentMapTest.MapPutGetTest
Observed state Occurrences Expectation Interpretation
-1, 1 293,867 FORBIDDEN Case violating atomic
0, -1 282,190 FORBIDDEN Case violating atomic
0, 1 28,013,763 ACCEPTABLE return 0 and 1
[FAILED] ru.skuptsov.concurrent.map.test.ConcurrentMapTest.MapSizeTest
Observed state Occurrences Expectation Interpretation
1 1,434,783 FORBIDDEN size of map = 1 race
2 11,733,097 ACCEPTABLE size of map = 2В потоконебезопасном HashMap мы видим некоторое статистическое количество несогласованных результатов, оба тесты не прошли.
Результаты с потокобезопасными ConcurrentHashMap:
[OK] ru.skuptsov.concurrent.map.test.ConcurrentMapTest.MapPutGetTest
Observed state Occurrences Expectation Interpretation
0, 1 20,195,000 ACCEPTABLE
[OK] ru.skuptsov.concurrent.map.test.ConcurrentMapTest.MapSizeTest
Observed state Occurrences Expectation Interpretation
2 6,573,730 ACCEPTABLE size of map = 2ConcurrentHashMap прошел тест, по крайней мере мы можем признать, что наш тест может обнаружить некоторые простые проблемы параллелизма. Такие же результаты можно проверить и для Collection.synchronizedMap и HashTable.
Fitst ConcurrentHashMap attempt
Первый наивный подход — просто синхронизировать каждый доступ к внутренним структурам — массиву бакетов.
Фактически, мы можем написать некоторую параллельную оболочку над переданным map провайдером. Точно так же действует java.util.Collections.synchronizedMap, Hashtable и гуавовский synchronizedMultimap.
public class SynchrinizedHashMap<K, V> extends BaseMap<K, V> implements Map<K, V>, IMap<K, V> {
private final Map<K, V> provider;
private final Object monitor;
public SynchronizedHashMap(Map<K, V> provider) {
this.provider = provider;
monitor = this;
}
@Override
public V put(K key, V value) {
synchronized (monitor) {
return provider.put(key, value);
}
}
@Override
public V get(Object key) {
synchronized (monitor) {
return provider.get(key);
}
}
@Override
public int size() {
synchronized (monitor) {
return provider.size();
}
}
}Изменения в non-volatile map-провайдере будут видны между потоками, согласно документации:
Second, when a synchronized method exits, it automatically establishes a happens-before relationship with any subsequent invocation of a synchronized method for the same object. This guarantees that changes to the state of the object are visible to all threads.
Наша простейшая реализация проходит параллельные тесты, но по какой цене? В каждом методе может быть только один поток в одно и то же время, даже если мы работаем с разными ключами, поэтому при многопоточной нагрузке мы не должны ожидать высокой производительности. Давайте измерим это.
Тест производительности
Для тестирования производительности мы будем использовать библиотечку jmh.
@State(Scope.Thread)
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(3)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(MICROSECONDS)
public class ConcurrentMapBenchmark {
private Map<Integer, Integer> map;
@Param({"concurrenthashmap", "hashtable", "synchronizedhashmap"})
private String type;
@Param({"1", "10"})
private Integer writersNum;
@Param({"1", "10"})
private Integer readersNum;
private final static int NUM = 1000;
@Setup
public void setup() {
switch (type) {
case "hashtable":
map = new Hashtable<>();
break;
case "concurrenthashmap":
map = new ConcurrentHashMap<>();
break;
case "synchronizedhashmap":
map = new SynchronizedHashMap<>(new HashMap<>());
break;
}
}
@Benchmark
public void test(Blackhole bh) throws ExecutionException, InterruptedException {
List<CompletableFuture> futures = new ArrayList<>();
for (int i = 0; i < writersNum; i++) {
futures.add(CompletableFuture.runAsync(() -> {
for (int j = 0; j < NUM; j++) {
map.put(j, j);
}
}));
}
for (int i = 0; i < readersNum; i++) {
futures.add(CompletableFuture.runAsync(() -> {
for (int j = 0; j < NUM; j++) {
bh.consume(map.get(j));
}
}));
}
CompletableFuture.allOf(futures.toArray(new CompletableFuture[1])).get();
}
}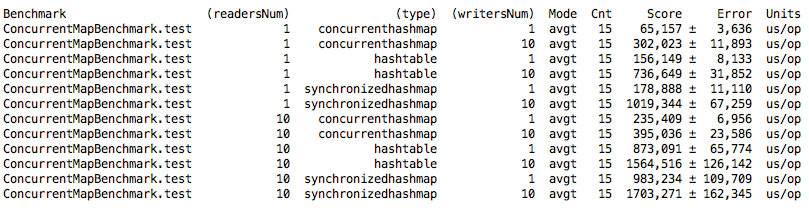
Мы убедились, что производительность нашей SynchronizedHashMap практически схожа с java-s HashTable, и она в 2 раза хуже, чем ConcurrentHashMap. Попробуем улучшить производительность.
Lock-striping ConcurrentHashMap attempt
Первое улучшение может быть основано на идее, что вместо блокирования доступа ко всей map лучше синхронизовать доступ только если потоки обращаются к одному и тому же бакету, где индекс бакета = key.hashCode ()% array.length. Этот метод называется lock striping или fine-grained synchronization, см. Искусство многопроцессорного программирования.
Для массива бакетов нам понадобится массив блокировок, при старте размер массива блокировок должен быть равен внутреннему размеру массива — это важно, потому что мы не хотим ситуации, когда 2 locka отвечают за один бакет массива.
Для простоты рассмотрим map с неизменяемым массивом бакетов — это означает, что мы не сможем расширить начальную емкость (если N >> initialCapacity мы потеряем O (1) map гарантию вставки доставания элементов. Также нам не нужен loadFactor). Расширяемая cocurrent map это отдельная большая тема.
public class LockStripingArrayConcurrentHashMap<K, V> extends BaseMap<K, V> implements Map<K, V> {
private final AtomicInteger count = new AtomicInteger(0);
private final Node<K, V>[] buckets;
private final Object[] locks;
@SuppressWarnings({"rawtypes", "unchecked"})
public LockStripingArrayConcurrentHashMap(int capacity) {
locks = new Object[capacity];
for (int i = 0; i < locks.length; i++) {
locks[i] = new Object();
}
buckets = (Node<K, V>[]) new Node[capacity];
}
@Override
public int size() {
return count.get();
}
@Override
public V get(Object key) {
if (key == null) throw new IllegalArgumentException();
int hash = hash(key);
synchronized (getLockFor(hash)) {
Node<K, V> node = buckets[getBucketIndex(hash)];
while (node != null) {
if (isKeyEquals(key, hash, node)) {
return node.value;
}
node = node.next;
}
return null;
}
}
@Override
public V put(K key, V value) {
if (key == null || value == null) throw new IllegalArgumentException();
int hash = hash(key);
synchronized (getLockFor(hash)) {
int bucketIndex = getBucketIndex(hash);
Node<K, V> node = buckets[bucketIndex];
if (node == null) {
buckets[bucketIndex] = new Node<>(hash, key, value, null);
count.incrementAndGet();
return null;
} else {
Node<K, V> prevNode = node;
while (node != null) {
if (isKeyEquals(key, hash, node)) {
V prevValue = node.value;
node.value = value;
return prevValue;
}
prevNode = node;
node = node.next;
}
prevNode.next = new Node<>(hash, key, value, null);
count.incrementAndGet();
return null;
} ...
}
}
private boolean isKeyEquals(Object key, int hash, Node<K, V> node) {
return node.hash == hash &&
node.key == key ||
(node.key != null && node.key.equals(key));
}
private int hash(Object key) {
return key.hashCode();
}
private int getBucketIndex(int hash) {
return hash % buckets.length;
}
private Object getLockFor(int hash) {
return locks[hash % locks.length];
}
private static class Node<K, V> {
final int hash;
K key;
V value;
Node<K, V> next;
Node(int hash, K key, V value, Node<K, V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
}Важно, чтобы все поля класса были final — это гарантирует safe-publication и что никто не вызовет методы до окончательного создания объекта — нам это важно, потому что у нас есть некая инициализация в конструкторе.
Исходный код можно найти здесь.
Результаты тестов:

Мы видим, что fine-grained synchronization реализация лучше, чем общая блокировка. Результаты, при одном читателе и одном писателе, по сравнению с ConcurrentHashMap практически одинаковы, но когда число потоков увеличивается, разница больше, особенно там, где много читателей.
Lock free concurrent hash map attempt
Честно говоря, синхронизация не является методом параллельного программирования, потому что она выставляет потоки в последовательной очереди, заставляя ждать завершения другого потока. И дополнительная стоимость синхронизации контекста системы возрастает с увеличением числа ожидающих потоков, но все, что мы хотим сделать — это небольшое количество инструкций для изменения значения ключа map.
Определим некоторые требования к новой реализации hashmap, которые по идее должны улучшить нашу реализацию. И требования следующие:
- Если мы имеем 2 потока, которые работают с разными ключами (запись или чтение), мы не хотим какой-либо синхронизации между ними (word tearing в java запрещен — доступ к двум различным полям массива потоко-безопасен)
- Если несколько потоков работают с одним и тем же ключом (запись и чтение), мы не хотим реордеринга операций (подробнее о причинах проблем в структуре современого кэша) и нуждаемся в happens-before гарантии между потоками, иначе один поток может не заметить измененное значение другим потоком. Но мы не хотим блокировать поток чтения и ждать завершения потока записи.
- Мы не хотим блокировать несколько читателей по одному ключу, если среди них нет одного пишущего потока.
Давайте сконцентрируемся на пунктах 2 и 3. На самом деле мы можем сделать операцию чтения map полностью свободной от блокировки, если мы сможем сделать (1) volatile read array of buckets, а затем пройти внутри bucket-а с (2) volatile read следующего узла связанного списка пока не найдем нужный и volatile read самого значения узла.
Для (2) мы можем просто пометить в Node поля next и value как volatile.
Для (1) не существует такой вещи, как volatile array, даже если массив объявлен ??как volatile, это не обеспечивает volatile семантику при чтении или записи элементов, при одновременном доступе к k-му элементу массива требуется внешняя синхронизация, volatile является только сама ссылка на массив. Мы можем использовать AtomicReferenceArray для этой цели, но он принимает только массивы Object[]. В качестве альтернативы рассмотрим использование Unsafe для volatile array read и lock-free write. Тот же метод используется в AtomicReferenceArray и ConcurrentHashMap.
@SuppressWarnings("unchecked")
// read array value by index
private <K, V> Node<K, V> volatileGetNode(int i) {
return (Node<K, V>) U.getObjectVolatile(buckets, ((long) i << ASHIFT) + ABASE);
}
// cas set array value by index
private <K, V> boolean compareAndSwapNode(int i, Node<K, V> expectedNode, Node<K, V> setNode) {
return U.compareAndSwapObject(buckets, ((long) i << ASHIFT) + ABASE, expectedNode, setNode);
}
private static final sun.misc.Unsafe U;
// Node[] header shift
private static final long ABASE;
// Node.class size shift
private static final int ASHIFT;
static {
try {
// get unsafe by reflection - it is illegal to use not in java lib Constructor<Unsafe> unsafeConstructor = Unsafe.class.getDeclaredConstructor();
unsafeConstructor.setAccessible(true);
U = unsafeConstructor.newInstance();
} catch (NoSuchMethodException | InstantiationException | InvocationTargetException | IllegalAccessException e) {
throw new RuntimeException(e);
}
Class<?> ak = Node[].class;
ABASE = U.arrayBaseOffset(ak);
int scale = U.arrayIndexScale(ak);
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
}В volatile getNode мы теперь можем безопасно без блокировок читать значения.
Давайте теперь напишем lock-free V get (Object key):
public V get(Object key) {
if (key == null) throw new IllegalArgumentException();
int hash = hash(key);
Node<K, V> node;
// volatile read of bucket head at hash index
if ((node = volatileGetNode(getBucketIndex(hash))) != null) {
// check first node
if (isKeyEquals(key, hash, node)) {
return node.value;
}
// walk through the rest to find target node
while ((node = node.next) != null) {
if (isKeyEquals(key, hash, node))
return node.value;
}
}
return null;
}В первой попытке был большой memory-overhead с пулом блокировок — на самом деле мы можем использовать тот же fine-grained подход без дополнительной памяти — просто заблокироваться на первом node в бакете, если он существует. Если он не существует — мы не можем блокироваться на несуществующем элеменет и нуждаемся в некотором lock-free методе для установки header node — мы уже написали этот метод выше — метод compareAndSwapNode.
@Override
public V put(K key, V value) {
if (key == null || value == null) throw new IllegalArgumentException();
int hash = hash(key);
// no resize in this implementation - so the index will not change
int bucketIndex = getBucketIndex(hash);
// cas loop trying not to miss
while (true) {
Node<K, V> node;
// if bucket is empty try to set new head with cas
if ((node = volatileGetNode(bucketIndex)) == null) {
if (compareAndSwapNode(bucketIndex, null,
new Node<>(hash, key, value, null))) {
// if we succeed to set head - then break and return null
count.increment();
break;
}
} else {
// head is not null - try to find place to insert or update under lock
synchronized (node) {
// check if node have not been changed since we got it
// otherwise let's go to another loop iteration
if (volatileGetNode(bucketIndex) == node) {
V prevValue = null;
Node<K, V> n = node;
while (true) {
... simply walk through list under lock and update or insert value...
}
return prevValue;
}
}
}
}
return null;
}Полный исходный код здесь.
Давайте протестируем его производительность:
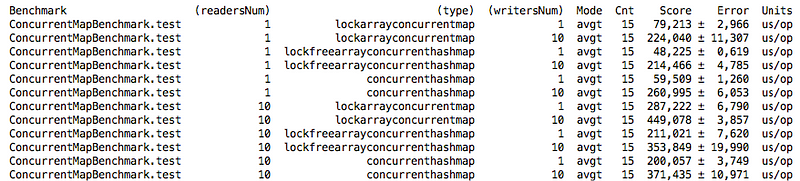
В некоторых случаях мы даже лучше, чем ConcurrentHashMap, но это не совсем честное сравнение. Потому что ConcurrentHashMap делает ленивую инициализацию таблицы во время загрузки и по крайней мере один раз происходит resize на граничном элементе threshold=initialCapacity*loadFactor. Если мы снова запустим тест с инициализированными элементами initialCapacity! = N (= N / 6), результаты будут несколько отличаться:

Это произошло из-за того, что в ConcurrentHashMap происходит увеличение начального размера массива бакетов и на получение элементов по ключу тратится меньше времени, из-за уменьшения длинны связного списка в бакете.
Нужно отметить, что мы получили не full-non-bloking структуру данных — так же, как и ConcurrentHashMap, хотя все, что нам нужно, — это просто связанный список без блокировок, но с изменением размера и одновременным модифицированием данных эта задача не такая простая — читайте здесь.
Оригинальная java 8 ConcurrentHashMap имеет ряд улучшений, о которых мы не упоминали, например:
- Ленивая инициализация таблицы бакетов, которая минимизирует memory footprint до первого использования
- Concurrent resizing массива бакетов
- Подсчет элементов с использованием LongAdder.
- Специальные типы nodes (начиная с 1.8) — TreeBins, если длина списка внутри бакета вырастет больше, чем TREEIFY_THRESHOLD = 8 — бакет становится сбалансированным деревом с наихудшим поиском по ключу (O (log (Nbucket_size)))
Нужно отметить, что реализация ConcurrentHashMap в Java 1.8 была существенно изменена с 1.7. В 1.7 это была идея сегментов, где число сегментов равно уровню параллелизма. В java 8 массив бакетов представляет собой единый массив.
Поделиться с друзьями
Комментарии (3)

lany
24.04.2017 17:58Тесты производительности замеряют не только собственно производительность, но и создание/планировку/сбор результатов CompletableFuture. Пробовали
@Group,@GroupThreads?
sshikov
Эк вы бодро так скипнули описание сути метода ) Тут было бы неплохо хоть два слова сказать, что именно вы используете из Unsafe, и почему/как это решает проблему отсутствия volatile для массивов. А то это далеко не очевидная штука, далеко не каждый пользовался Unsafe хотя бы раз в жизни.
lany
Вообще можно было и на VarHandle написать, Unsafe как-то выходит из моды ;-)