
Вашему вниманию предлагаю перевод статьи Sacha Greif "Что же такое этот GraphQL?"
Если вы такой же, как и я, вы обычно проходите через три этапа, когда узнаёте о новой технологии:
- Отрицание Ещё одна JavaScript библиотека?! Зачем? У меня уже есть jQuery!
- Интерес Хм, наверное мне следует взглянуть на эту библиотеку...
- Паника Помогите! Мне нужно изучить эту библиотеку прямо сейчас, иначе мои знания устареют!
Есть одна хитрость для поддержания благоразумия в эпоху быстроразвивающихся технологий: изучать новые вещи между вторым и третьим этапом, как только интерес задет, но пока технология ещё не распространена повсеместно.
Именно поэтому сейчас самое время узнать, что же такое этот GraphQL, о котором вы повсюду слышите.
Основы
В двух словах, GraphQL это синтаксис, который описывает как запрашивать данные, и, в основном, используется клиентом для загрузки данных с сервера. GraphQL имеет три основные характеристики:
- Позволяет клиенту точно указать, какие данные ему нужны.
- Облегчает агрегацию данных из нескольких источников.
- Использует систему типов для описания данных.
Так с чего же начать изучение GraphQL? Как это выглядит на практике? Как начать его использовать? Читайте дальше чтобы узнать!

Задача
GraphQL был разработан в большом старом Facebook, но даже гораздо более простые приложения могут столкнуться с ограничениями традиционных REST API интерфейсов.
Например представьте, что вам нужно отобразить список записей (posts), и под каждым опубликовать список лайков (likes), включая имена пользователей и аватары. На самом деле, это не сложно, вы просто измените API posts так, чтобы оно содержало массив likes, в котором будут объекты-пользователи.

Но затем, при разработке мобильного приложения, оказалось что из-за загрузки дополнительных данных приложение работает медленнее. Так что вам теперь нужно два endpoint, один возвращающий записи с лайками, а другой без них.
Добавим ещё один фактор: оказывается, записи хранятся в базе данных MySQL, а лайки в Redis! Что же теперь делать?!
Экстраполируйте этот сценарий на то множество источников данных и клиентских API, с которыми имеет дело Facebook, и вы поймёте почему старый добрый REST API достиг своего предела.
Решение
Facebook придумал концептуально простое решение: вместо того, чтобы иметь множество "глупых" endpoint, лучше иметь один "умный" endpoint, который будет способен работать со сложными запросами и придавать данным такую форму, какую запрашивает клиент.
Фактически, слой GraphQL находится между клиентом и одним или несколькими источниками данных; он принимает запросы клиентов и возвращает необходимые данные в соответствии с переданными инструкциями. Запутаны? Время метафор!
Пользоваться старой REST-моделью это как заказывать пиццу, затем заказывать доставку продуктов, а затем звонить в химчистку, чтобы забрать одежду. Три магазина – три телефонных звонка.
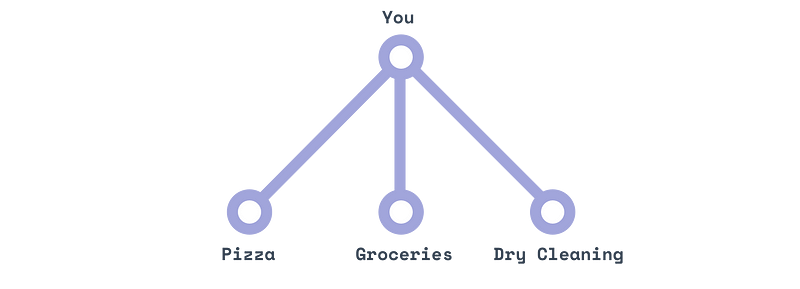
GraphQL похож на личного помощника: вы можете передать ему адреса всех трех мест, а затем просто запрашивать то, что вам нужно («принеси мне мою одежду, большую пиццу и два десятка яиц») и ждать их получения.
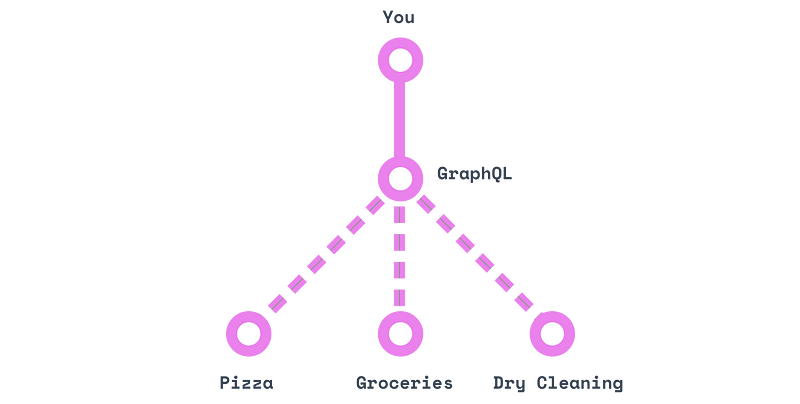
Другими словами, GraphQL это стандартный язык для разговора с этим волшебным личным помощником.

Согласно Google Images, типичный личный помощник это пришелец с восемью руками
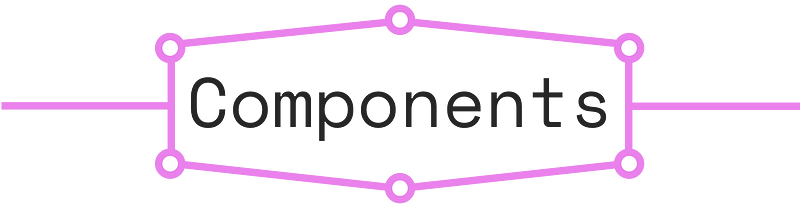
На практике GraphQL API построен на трёх основных строительных блоках: на схеме (schema), запросах (queries) и распознавателях (resolvers).
Запросы (queries)
(query и request одинаково переводится как "запрос". Далее будет подразумеваться query, если не указано иначе – прим. пер.)
Когда вы о чём-то просите вашего персонального помощника, вы выполняете запрос. Это выглядит примерно так:
query {
stuff
}Мы объявляем новый запрос при помощи ключевого слова query, также спрашивая про поле stuff. Самое замечательное в запросах GraphQL является то, что они поддерживают вложенные поля, так что мы можем пойти на один уровень глубже:
query {
stuff {
eggs
shirt
pizza
}
}Как можно заметить, клиенту при формировании запроса не нужно знать откуда поступают данные. Он просто спрашивает о них, а сервер GraphQL заботится об остальном.
Также стоит отметить, что поля запроса могут быть массивами. Например вот общий шаблон запроса списка сообщений:
query {
posts { # это массив
title
body
author { # мы может пойти глубже
name
avatarUrl
profileUrl
}
}
}Поля запроса также могут содержать аргументы. Например, если необходимо отобразить конкретный пост, можно добавить аргумент id к полю post:
query {
post(id: "123foo"){
title
body
author{
name
avatarUrl
profileUrl
}
}
}Наконец, если нужно сделать аргумент id динамическим, можно определить переменную, а затем использовать её в запросе (обратите внимание, также мы сделали запрос именованным):
query getMyPost($id: String) {
post(id: $id){
title
body
author{
name
avatarUrl
profileUrl
}
}
}Хороший способ попробовать все это на практике – использовать GraphQL API Explorer от GitHub. Например, давайте попробуем выполнить следующий запрос:
query {
repository(owner: "graphql", name: "graphql-js"){
name
description
}
}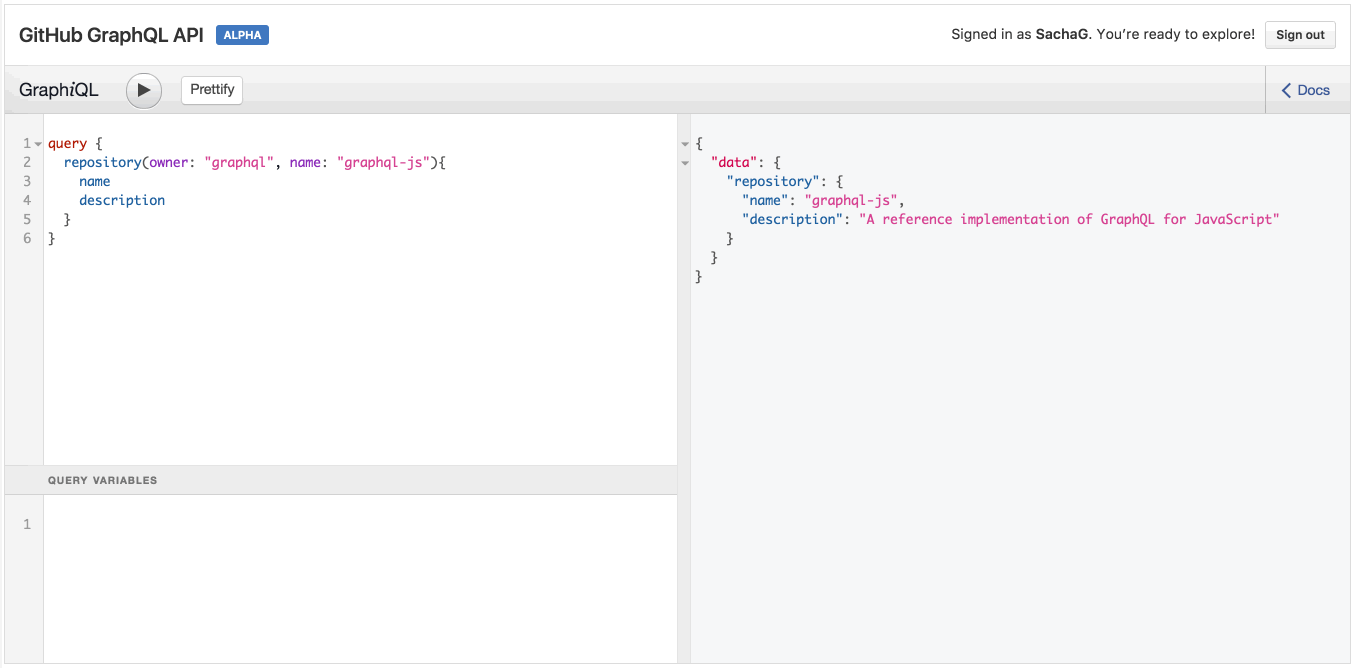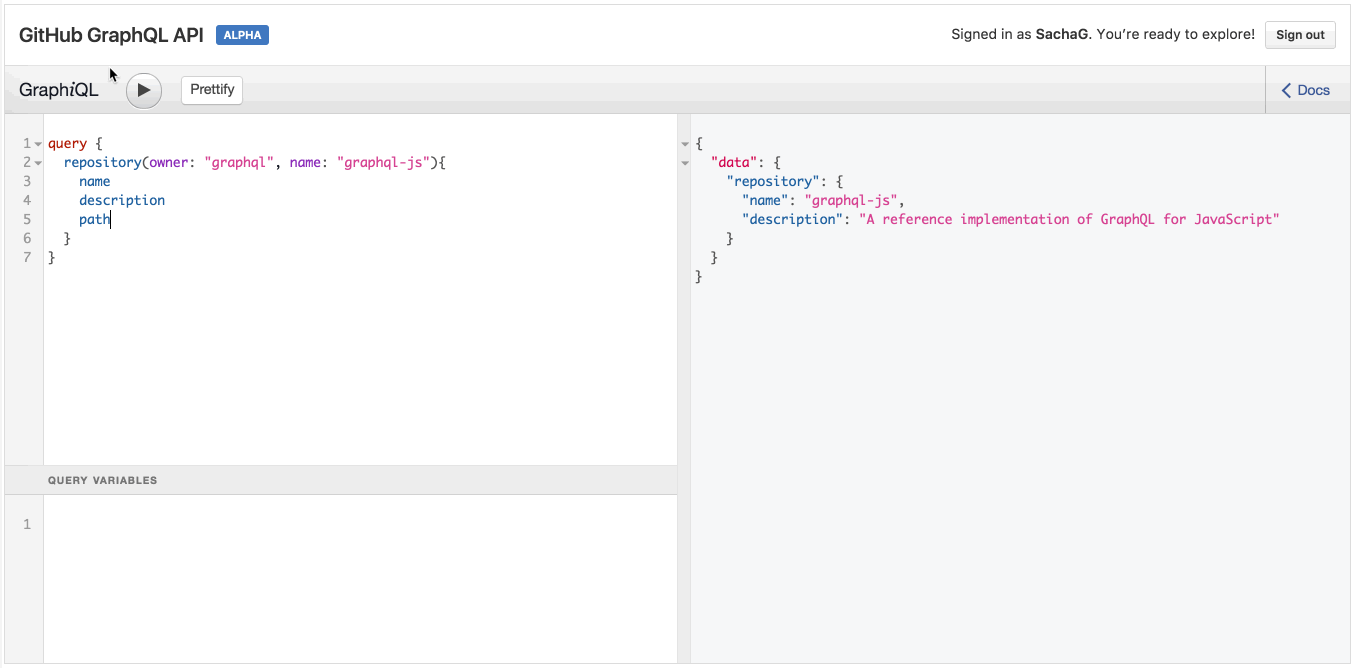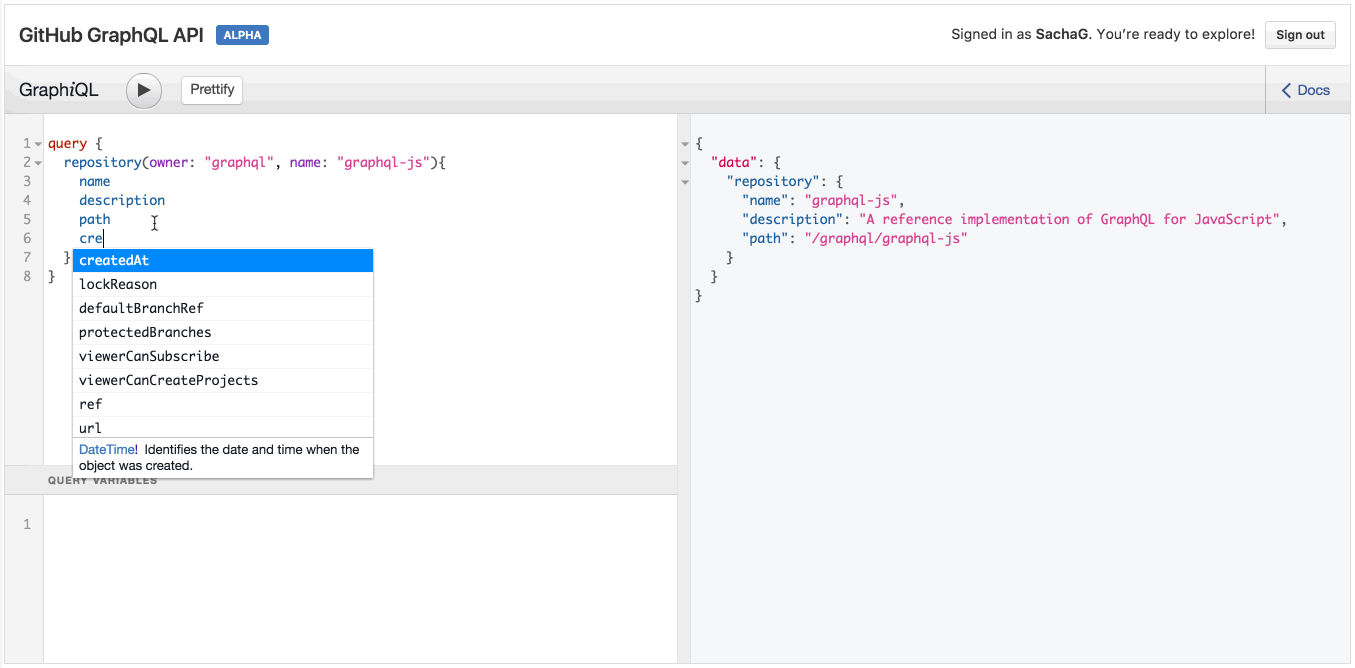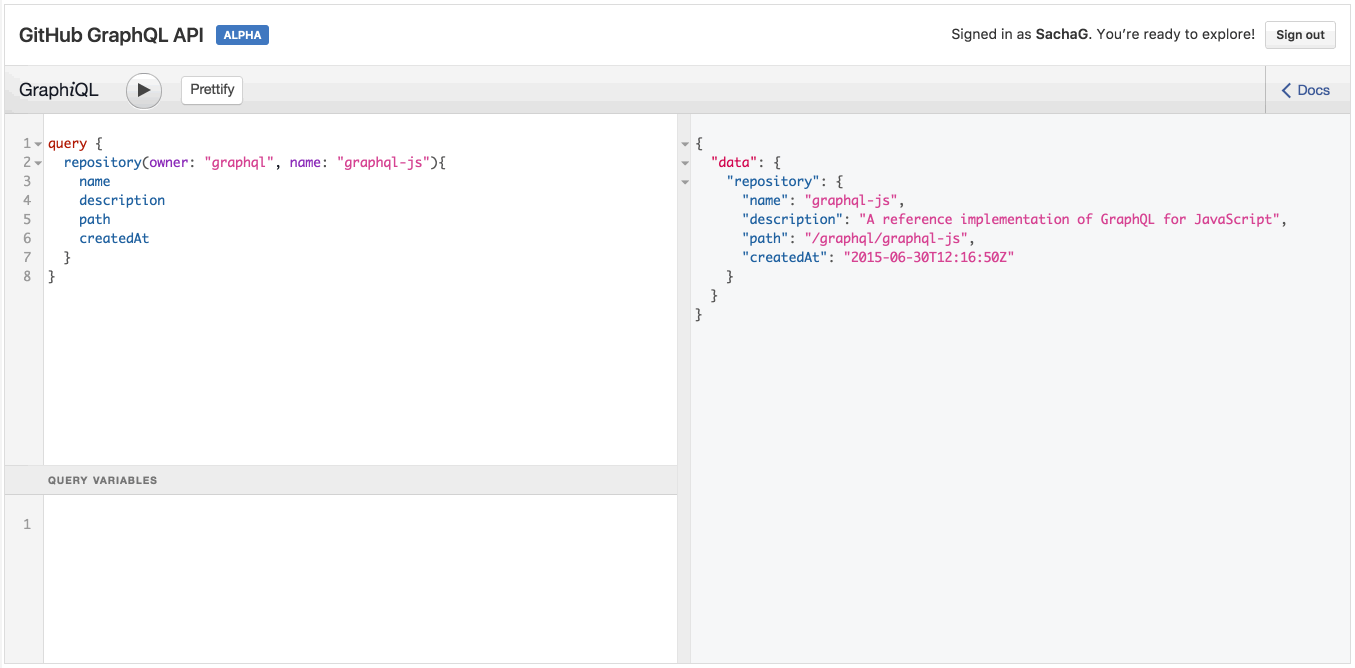
GraphQL и автодополнение в действии
Обратите внимание, когда вы вводите имя поля, IDE автоматически предлагает вам возможные имена полей, полученные при помощи GraphQL API. Ловко!
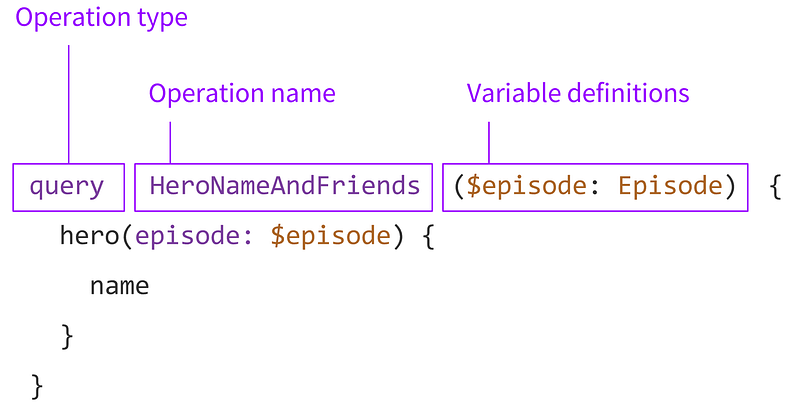
Анатомия запросов GraphQL (англ)
Вы можете узнать больше о запросах GraphQL в отличной статье "Анатомия запросов GraphQL" (англ).
Распознаватели (resolvers)
Даже самый лучший в мире личный помощник не сможет принести ваши вещи из химчистки если вы не дадите ему адрес.
Подобным образом, сервер GraphQL не может знать что делать с входящим запросом, если ему не объяснить при помощи распознавателя (resolver).
Используя распознаватель GraphQL понимает, как и где получить данные, соответствующие запрашиваемому полю. К примеру, распознаватель для поля запись может выглядеть вот так (используя генератор схемы (schema) из набора Apollo GraphQL-Tools):
Query: {
post(root, args) {
return Posts.find({ id: args.id });
}
}Мы помещаем наш распознаватель в раздел Query потому что мы хотим получать запись (post) в корне ответа. Но также мы можем создать распознаватели для подполей, как например для поля author:
Query: {
post(root, args) {
return Posts.find({ id: args.id });
}
},
Post: {
author(post) {
return Users.find({ id: post.authorId})
}
}Обратите внимание что ваши распознаватели не ограничены в количестве возвращаемых объектов. К примеру, вы захотите добавить поле commentsCount к объекту Post:
Post: {
author(post) {
return Users.find({ id: post.authorId})
},
commentsCount(post) {
return Comments.find({ postId: post.id}).count()
}
}Ключевое понятие здесь то, что схема запроса GraphQL и структура вашей базы данных никак не связаны. Другими словами, в базе данных может не существовать полей author или commentsCount, но мы можем "симулировать" их благодаря силе распознавателей.
Как было показано выше, вы можете писать любой код внутри распознавателя. Так что вы можете изменять содержимое базы данных; такие распознаватели называют изменяющими (mutation).
Схема (schema)
Все это становится возможным благодаря типизированной схеме данных GraphQL. Цель этой статьи дать скорее краткий обзор, чем исчерпывающее введение, так что в этом разделе не будет подробностей.
Я призываю вас заглянуть в документацию GraphQL (англ), если вы хотите узнать больше.

Часто задаваемые вопросы
Сделаем перерыв, чтобы ответить на несколько общих вопросов.
Эй, вы там, на задних рядах. Да вы. Я вижу, вы хотите что-то спросить. Идите вперед, не стесняйтесь!
Что общего у GraphQL и графовых баз данных?
Ничего общего. На самом деле, GraphQL не имеет ничего общего с графовыми БД типа Neo4j. Часть "Graph" отражает идею получения контента, проходя сквозь граф API, используя поля и подполя; часть "QL" расшифровывается как "query language" – "язык запросов".
Меня полностью устраивает REST, зачем мне переходить на GraphQL?
Если вы не достигли болевых точек REST API, решением которых является GraphQL, то можете не волноваться.
Использование GraphQL поверх REST вероятнее всего не заставит вас производить какие-то сложные изменения в остальном API и ломать накопившийся пользовательский опыт, так что переход не будет вопросом жизни и смерти в любом случае. Так что определенно стоит попробовать GraphQL в небольшой части проекта, если это возможно.
Могу ли я использовать GraphQL без React/Relay/имя_библиотеки?
Конечно! GraphQL это только спецификация, вы можете использовать его с любой библиотекой на любой платформе, используя готовый клиент (к примеру, у Apollo есть клиенты для web, iOS, Angular и другие) или вручную отправляя запросы на сервер GraphQL.
GraphQL был создан Facebook, а я не доверяю Facebook.
Ещё раз, GraphQL является всего лишь спецификацией, это значит что вы можете использовать его не используя ни одной строки кода, написанной Facebook.
Наличие поддержки Facebook это безусловно хороший плюс для экосистемы GraphQL. Но на данный момент сообщество достаточно большое чтобы поддерживать GraphQL даже если Facebook перестанет его использовать.
Как-то "позволить клиенту просить о тех данных, которые ему нужны" не выглядит безопасным
Так как вы пишете свои распознаватели, вы можете разрешать любые проблемы безопасности на этом уровне.
К примеру, если вы позволите клиенту использовать параметр limit для указания количества документов, которые он запрашивает, вы скорее всего захотите контролировать это число для избежания атак типа "отказ в обслуживании" когда клиент будет запрашивать миллионы документов снова и снова.
Так что же нужно чтобы начать?
На самом деле, необходимо всего два компонента чтобы начать:
- Сервер GraphQL для обработки запросов к API
- Клиент GraphQL, который будет подключаться к endpoint.

Теперь, когда вы понимаете как работает GraphQL, можно поговорить о главных игроках в этой области.
Серверы GraphQL
Первое что вам нужно для работы, это сервер GraphQL. Сам GraphQL это просто спецификация, так что двери открыты для конкурирующих реализаций.
GraphQL-JS (Node)
Это ссылка на оригинальную реализацию спецификации GraphQL. Вы можете использовать её с express-graphql для создания своего сервера API (англ).
GraphQL-Server (Node)
Команда Apollo имеет свою собственную реализацию GraphQL-сервера. Она ещё не настолько полна как оригинал, но очень хорошо документирована, хорошо поддерживается и быстро развивается.
Другие платформы
На официальном сайте есть список реализаций спецификации GraphQL для различных платформ (PHP, Ruby и другие).
Клиенты GraphQL
Конечно вы можете работать с API GraphQL напрямую, но специальная клиентская библиотека определённо может сделать вашу жизнь проще.
Relay
Relay это собственный инструментарий Facebook. Он создавался с учётом потребностей Facebook и может быть немного избыточным для большинства пользователей.
Клиент Apollo
Быстро занял своё место новый участник в этой области — Apollo. Типичный клиент состоит из двух частей:
- Apollo-client, позволяющий выполнять запросы GraphQL в браузере (также есть расширение для DevTools)
- Коннектор для frontend-фреймворка (React-Apollo, Angular-Apollo и другие)
По умолчанию Apollo-client сохраняет данных используя Redux, который сам является достаточно авторитетной библиотекой управления состоянием с богатой экосистемой.
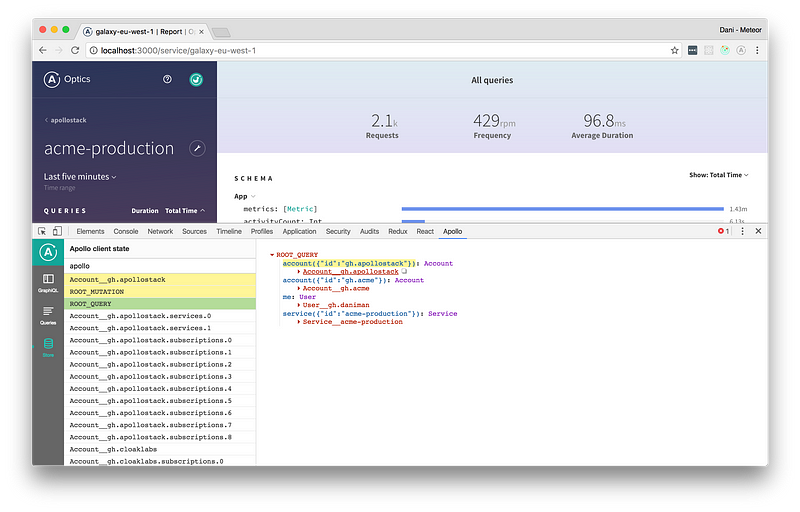
Расширение Apollo для Chrome DevTools
Приложения с открытым исходным кодом
Несмотря на то, что GraphQL это достаточно новая концепция, уже есть некоторые перспективные приложения с открытым исходным кодом, которые используют её.
VulcanJS

Я (автор оригинальной статьи — прим. пер.) являюсь ведущим разработчиком VulcanJS. Я создал его чтобы дать людям возможность попробовать силу стека React/GraphQL без необходимости писать много шаблонного кода. Вы можете воспринимать его как "Rails для современной web-экосистемы" потому что он позволяет создавать CRUD-приложения (клон Instagram например) в течение нескольких часов.
Gatsby
Gatsby это генератор статических сайтов для React, который начиная с версии 1.0 также использует GraphQL. Несмотря на то, что это можно показаться странным сочетанием на первый взгляд, это на самом деле довольно мощная идея. В процессе сборки Gatsby может извлекать данные из нескольких GraphQL API, затем используя их для создания полностью статического клиентского React-приложения.
Другие инструменты для работы с GraphQL
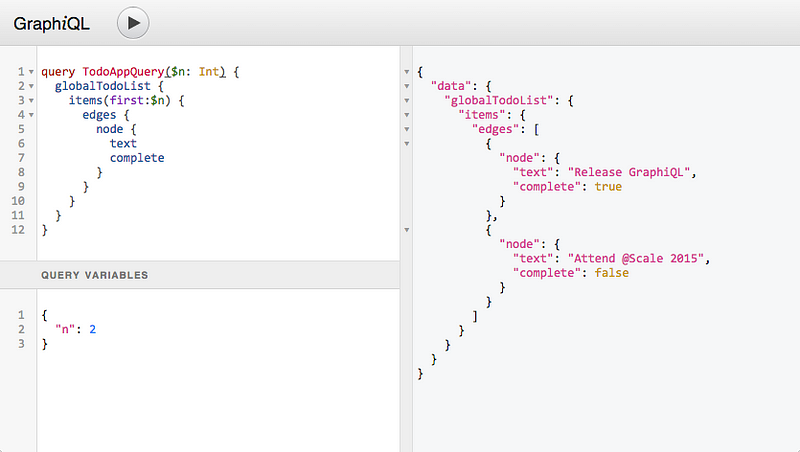
GraphiQL
GraphiQL это очень удобная браузерная IDE для создания и выполнения запросов к endpoint-ам GraphQL.
DataLoader
Из-за вложенной природы запросов GraphQL, один запрос может легко вызывать десятки обращений к базе данных. Для снижения нагрузки вы можете использовать инструменты кеширования наподобие разработанной Facebook библиотеке DataLoader.
Create GraphQL Server
Create GraphQL Server это консольная программа, позволяющая легко и быстро сгенерировать сервер на базе Node, использующий базу данных Mongo.
GraphQL-up
Аналогично Create GraphQL Server, GraphQL-up позволяет быстро создать GraphQL backend, но на базе сервиса Graphcool.
Сервисы GraphQL
Наконец, есть целый ряд компаний, предоставляющих "GraphQL-backend-как-сервис"; они сами позаботятся о серверной части для вас, и это может быть хорошим способом окунуться в экосистему GraphQL.
Graphcool
Гибкая backend-платформа, объединяющая GraphQL и AWS Lambda, имеющая бесплатный тарифный план для разработки.
Scaphold
Другой GraphQL-backend-как-сервис с бесплатным тарифным планом. Он предлагает много функций, подобных Graphcool.

Уже есть немало ресурсов по GraphQL.
(Также предлагайте ресурсы на русском языке в комментариях – прим. пер.)
GraphQL.org (англ)
На официальном сайте GraphQL есть замечательная документация чтобы начать.
LearnGraphQL (англ)
LearnGraphQL это интерактивный курс, созданный в компании Kadira.
LearnApollo (англ)
Хорошее продолжение LearnGraphQL, LearnApollo это бесплатный курс, созданный Graphcool.
Блог Apollo (англ)
Блог Apollo имеет массу подробных хорошо написанных постов о Apollo и GraphQL в целом.
GraphQL Weekly (англ)
Информационная рассылка о GraphQL, курируемая командой Graphcool.
Hashbang Weekly (англ)
Еще одна большая новостная рассылка, которая помимо GraphQL также охватывает React и Meteor.
Freecom (англ)
Серия руководств, описывающая как создать клон Интерком с помощью GraphQL.
Awesome GraphQL (англ)
Довольно исчерпывающий перечень ссылок и ресурсов по GraphQL.
Как же вы можете применить вновь приобретенные знания о GraphQL на практике? Вот несколько рецептов, которые можно попробовать:
Apollo + Graphcool + Next.js
Если вы уже знакомы с Next.js и React, этот пример позволит вам настроить GraphQL endpoint при помощи Graphcool и затем отправлять ей запросы при помощи Apollo.
VulcanJS
Учебник Vulcan (англ) поможет вам создать простой слой данных GraphQL на сервере и на клиенте. Поскольку Vulcan является платформой "все-в-одном", это хороший способ начать работу без каких-либо настроек. Если вам нужна помощь, не стесняйтесь обратиться в наш канал Slack (англ)!
Учебник GraphQL & React
В блоге Chroma есть руководство из шести частей (англ) по созданию приложения React/GraphQL используя компоненто-ориентированный подход к разработке.
Заключение
GraphQL поначалу может показаться сложным, потому что это технология, которая затрагивает многие области современной разработки. Но уделив время чтобы понять основные концепции, я думаю вы поймёте что многое из этого имеет смысл.
Решите ли вы использовать это или нет, я считаю что стоит потратить время чтобы ознакомиться с GraphQL. Все больше и больше компаний и структур начинают использовать его, и он вполне может в течение следующих нескольких лет стать одним из ключевых строительных блоков в веб-разработке.
Согласны? Не согласны? Вопросы? Дайте мне знать, здесь в комментариях.
Комментарии (43)

Alexeyco
20.04.2017 15:37А как быть с т.н. nested attacks? Когда вы делаете что-то типа:
{ authors { firstName posts { title author { firstName posts{ title author { firstName posts { title [n author] [n post] } } } } } } }
aliksend
20.04.2017 15:57Хороший вопрос.
Решение "в лоб" – ограничить уровень вложенности.
Более сложное – вычислять циклы, как это делает nodejs, когда вы делаете
> a = {number: 1} > a.me = a > console.log(a) { number: 1, me: [Circular] }
То есть просто не отдавать посты для автора, для которого посты уже были отданы
Alexeyco
21.04.2017 18:07На самом деле, я спросил уже зная ответ. Правильный ответ: а хрен его знает. Общего решения не существует, а частные случаи обуславливаются задачами. Я всего лишь хотел подчеркнуть то, что чуть не стало причиной массовой драки у нас в офисе при обсуждении GraphQL.
Чем привлекает GraphQL? Простотой. Взял монгу, связал сущности и вот тебе на — бэкенд поднят. Это значит, что не нужны ни реляционные СУБД, ни долгая работа над бэкендом. Фронтэндщики (наивные люди) думали, что это серебряная пуля. По крайней мере, в сравнении с Restful. В самом деле, ни тебе роутов, ни тебе схемы БД, ни миграций не надо — вообще почти ничего этого не надо.
Лично мое мнение: как общий подход и архитектурное решение GraphQL — неплох. Изящно. Но когда дело доходит до внедрения и повседневного использования, становится ясно — инструментам, которые реализуют GraphQL, нужно еще немного подрасти. Чтобы какая-нибудь компания героически бы прострелила себе ногу-другую, чтобы появились лучшие практики и т.д.

geshido
28.04.2017 09:40Для этого нужно не давать клиенту выполнять произвольные запросы, а только разрешать заранее определённые через их ID
hoarywolf
20.04.2017 16:10Предположим у вас интернет-магазин с graphql, и приходит запрос:
categories {
id
name
products {
id
name
picture
price
description
comments {
id
author {
id
city
name
}
message
}
}
}
то есть одним запросом скрапер вытаскивает у вас всю структуру, что вряд-ли хотелось бы вам, как владельцу. И вы начинаете придумывать как с этим бороться при помощи костылей, например, что бы при запросе категорий, выдавались только id и названия товаров, но не другие поля. Но потом пишете еще какую-нить фичу на сайт, где нужно, например, еще и цена, оно у вас глючит с предыдущим костылем, и тд.
То есть, если вы готовы, по-сути, отдать базу сайта всем желающим, то graphql вам с этим поможет.aliksend
20.04.2017 16:28Да, вы правы, с GraphQL действительно вытащить всю базу проще, чем используя, например, REST, где пришлось бы делать по запросу на категорию, потом по запросу на каждый товар и т.д.
Но и используя REST возможно это сделать. Как решается эта проблема? Самое простое решение – ограничивать число запросов с одного IP за какое-то время.
В случае GraphQL такое сделать сложнее, но всё же возможно: указывать максимальный limit для товаров и т.д. Я думаю что с распространением GraphQL будут разработаны методы защиты от таких атак.
Также, помня что эта технология была разработана Facebook, можно посмотреть как они борются с подобным (и борются ли вообще?)
hoarywolf
20.04.2017 16:43С трудом они борятся, по крайней мере на их сайте instagram.com, где grapql используется для ajax запросов, с помощью него можно вытащить за один запрос в разы больше информации, чем через официальное rest api. Последнее время они ввели лимит на время обработки запроса, но по-мне это крайне хреновое решение, чреватое для реальных пользователей.
Например, если вы хотели получить список публикаций по хештегу, а также комментарии к ним и профили комментаторов, то вам надо было:
запрос на rest api возвращающий список публикаций по хештегу
запрос на rest api на каждую публикацию возвращающий список комментариев
запрос на rest api на каждого комментатора возвращающий его профиль
через graphql это решается одним запросом
Лимиты на товары сделать можно, но это все равно не решит вопрос вложенностей запросов друг в друга и практически отсутствием контроля с вашей стороны, какие данные в какой ситуации вы отдаете.aliksend
20.04.2017 16:51В этом и прелесть GraphQL что можно вытащить всё необходимое одним запросом.
Да, где-то это будет уязвимостью, и методы защиты ещё не разработаны. Но я уверен, что вместе с распространением этой технологии сообщество (включая компании) найдут решение этой проблемы.hoarywolf
20.04.2017 16:57А зачем вам, как владельцу сайта или разработчику, нужно что бы все вытаскивалось одним запросом? Вот упомянутому выше инстаграму точно нигде не надо что бы вытаскивались список публикаций по хештегу, а также комментарии к ним и профили комментаторов
aliksend
20.04.2017 17:07Лично мне GraphQL нравится скорее за возможность указать какие поля в ответе нужны клиенту.
В реальном приложении я бы использовал ограничение количества документов и уровня вложенности: не более 2-3 уровней, я считаю хватит для большинства приложений, тем более если раньше вы работали с REST API, в котором уровень вложенности зачастую только один.hoarywolf
20.04.2017 18:01Вам это нравится как фронтэнд или как бекэнд разработчику?
Если как фронтэнд, то в общем верю, но если бекэнд, то парсинг этого запроса, проверка вложенностей и ограничений, преобразование в запросы к базам данных, особенно sql и тд, имхо, чуть более чем полностью нивелирует возможность указать какие поля в ответе нужны клиенту.
В rest уровень вложенности данных в ответе такой, который задан разработчиками заранее, не знаю, почему вы решили, что он один. У того же инстаграма при запросе через rest отдается несколько последних комментариев к публикации, это уже второй уровень и данные по автору комментария (айди, имя и аватарка), это уже третий уровень. Но то, что и в каком количестве в данном конкретном случае отдавать решают разработчики.aliksend
20.04.2017 18:15Парсинг можно отдать внешней библиотеке.
Проверять вложенность можно также доверить библиотеке или написать middleware который будет этим заниматься.
Работать с БД можно используя модели, отправляя запросы не напрямую с resolver-ов, а, как это показано в примере, делать что-то вроде
Posts.find({ id: args.id });
А модель Posts уже знает какой запрос нужно отправить и т.д.
В идеале даже не запрашивать данные сразу, а возвращать некие promises, которые будут оптимизированы и выполнены с минимальной нагрузкой уже после работы resolver-ов (т.е. не отправлять 10 запросов, а отдать 10 промисов и потом, перед отправкой, объединить их в один запрос, если это оказалось возможным). Но это только мои мысли, я не знаю систем, которые сейчас работают подобным образом.
Я писал про REST имея в виду каноничный REST, который в ответе на запрос объекта возвращает только объект и всё, без вложенных объектов. Разработчики backend, конечно, могут отправить данные, но, насколько я понимаю, REST задумывался именно так. Возможно конечно что я неправ.
hoarywolf
20.04.2017 18:30Вы хоть представляете себе, как сейчас вы парой обзацев настолько усложнили проект, что даже не можете сами толком представить, как оно должно работать?
Не встречал я описания такого канонического rest-а, особенно в плане что должен возращаться только объект и всё, без вложенных объектов. Можете дать ссылку на такое описание стандарта?aliksend
20.04.2017 18:58+2То, что я не представляю как должно работать – это только мои мысли, я думал о подобном ещё когда не знал ничего о GraphQL. Можно делать и без этого, сразу получая данные в resolver-е, как и описано в статье.
Остальное – библиотека для работы с GraphQL, алгоритм проверки вложенности – да, конечно это усложнение проекта, но если вы захотите подобное реализовать для REST архитектуры, вам тоже придётся усложнять ваш проект.
По поводу канонического REST – возможно действительно нигде не описано что должен возвращаться только этот объект. И я, создавая REST backend-ы, возвращал помимо полей объекта, хранящихся в БД, другие поля, вычисленные или полученные из других объектов.
Но наверное в любом руководстве к REST в качестве примера будет один возвращаемый объект, а не вложенные.
Возможно я неправ по поводу этого пункта, в любом случае это мало относится к GraphQL.

OlegZH
20.04.2017 16:46А что можно сделать предосудительное с полученной таким образом базой данных? Если предоставляется доступ, то, наверное, ничего критичного в базе данных нет. В обычной ситуации, Вы и так получаете доступ к базе данных, получая, например, список товаров (по определённым критериям), когда что-то ищите, чтобы купить. Что же может быть такого в структуре, компрометирующее владельца базы данных?
hoarywolf
20.04.2017 16:55Упрощение жизни скраперам, которых почему-то никто из делающих бизнес в инете не любит.

olegsoe
20.04.2017 19:42+1Всё это можно реализовать.
Хотите заверните в JWT, генерите сессию, разные query, ограничение на ip… и ещё масса вариантов.
Всё работает.
Очень даже приятный продукт.
Недостатки есть, но плюсов однозначно больше.

zelenin
20.04.2017 20:12+4собственно это не проблема graphql как спеки. Неразумно пенять на спецификацию, созданную для удобного доступа к данным, за удобный доступ к данным.
Серверную часть же вы пишете, в том числе ресолверы, валидацию помимо схемы, авторизацию/аутентификацию, рейт лимитинг. Не хотите скраперам отдавать данные — позаботьтесь об этом.

fukkit
20.04.2017 20:48Когда бэк умеет отдавать то, что не нужно фронту — это путь к проблемам.
aliksend
20.04.2017 20:49Backend будет отдавать только то, что вы его "научите" отдавать.
Frontend будет запрашивать только то, что ему нужно для отображения пользователю.fukkit
20.04.2017 20:59Насколько я понимаю, смысл технологии в том, чтобы научить его значительно большему количеству вещей, чем необходимо в моменте. И потом каждый раз не переучивать.
Подводные, очевидно, в потенциальных рисках по безопасности, лишней нагрузке на бэк и удешевлении кражи контента конкурентами.Alexeyco
24.04.2017 16:43Вот уж не думал, что в 2017 году фраза «а тогда у нас с сайта будет легко украсть контент» будет аргументом. Если контент можно отобразить в формализованной форме, тогда его можно украсть. И ничего с этим не сделать. Ничего. Может быть, так-то оно и лучше. Стянули весь контент разом и успокоились вместо того, чтобы мучить сервер. Все равно же сопрут.
fukkit
24.04.2017 20:09Ключевое слово — «удешевление». Аргумент не основной, но важный. Часть стоимости сайта — его база. Может ещё на гитхаб дампы выложить, ну чтобы сервера не мучать?
Alexeyco
28.04.2017 11:30Я много раз писал грабберы. Порой, это были кривые сайты. Иногда это были довольно приличные сайты, но никогда у меня не возникало проблем. Всегда хватало примерно дня на такую задачу. Даже если бы создатели ну вот просто упоролись на защите, я бы вытащил то, что мне было нужно. В любом случае.
Ключевой вопрос здесь — удешевление разработки. Только это имеет значение. Ну а если в вашем мире существует только две крайности, одна из которых предполагает размещение базы на гитхабе, то я даже знаю, какого специалиста посоветовать.

khrnsb4y
20.04.2017 23:05+2По поводу этапов — найдутся люди, у которых есть еще и четвертый — «Я так и не успел изучить эту библиотеку, но она уже устарела и у нее есть три замены».

SerafimArts
21.04.2017 00:35+1Упоминая GraphQL никто никогда не говорит о минусах, что очень странно:
1) Нет ничего, кроме жёсткого сравнения. Никаких "больше" или "меньше".
2) Нет описания ограничений запросов (лимиты и пагинация). Область ответственности ложится на Relay и прочие штуки. Только Relay реализация пагинации — это феерический трешак.
3) Нет возможности описать полиморфичные типы, например коллекцию A, которая может возвращать либо B, либо C. Т.е. нельзя описать тот же объект пагинации, данные внутри которого могут быть коллекцией из других сущностей.
4) Нет возможности совместить один элемент и коллекцию. Надо писать два эндпоинта (query) для получения коллекции, например "коллекции юзеров" и "одного юзера".
5) Любое обновление данных (mutations) — отдельный эндпоинт, т.е. для каждого "типа" обновления — отдельные точки входа. Т.е. в случае обновления данных — REST на несколько порядков удобнее.
Это то, что сходу вспомнилось.

VlastV
21.04.2017 13:02- ....
- http://graphql.org/learn/pagination/
- http://graphql.org/learn/schema/#union-types
- не совсем понял
- можно передавать несколько мутация в одном запросе
aliksend
21.04.2017 13:20Отвечаю с точки зрения GraphQL, а не конкретной библиотеки
Эта проблема однозначно решаема. Либо расширением спецификации, чтобы было возможно писать
query getMyPost($fromId: Int, $toId: Int) { post(id: {ge: $fromId, le: $toId}){ title } }
примерно как это реализовано в mongodb
либо даже без изменения спецификации:
query getMyPost($fromId: Int, $toId: Int) { post(fromId: $fromId, toId: $toId){ title } }
Лимиты и пагинация (видимо имеется в виду указание offset-а) могут быть также реализованы через аргументы и ограничены на backend-е до нужных значений (чтобы нельзя было запросить сразу миллион документов). Ну и документ по ссылке из сообщения VlastV
Также VlastV дал ссылку, там вроде то, что нужно
Можно создать endpoint
userи при запросе без аргументов отдавать всех пользователей (не больше определенного количества конечно), при указанииidвыдавать конкретного пользователя, при указании списка из несколькихidили ограничений (from..to) пользователей с соответствующимиid.
- Можно сделать один endpoint, через него получать данные, через него же и устанавливать (аргумент
set, например, будет устанавливать новое значение для поля). Это плохое решение, лучше разделять получение данных и установку (и запросы GET/POST), но технически можно сделать даже одним endpoint-ом.
SerafimArts
21.04.2017 15:14А я не спорю что решений нет, решения есть по всем вариантам. Но они костыльные все. А от пагинации в Relay стиле хочется плакать =)
Ну кроме п.3 — почему-то проглядел этот пункт в доках, мой косяк.
По поводу мутаторов — хотелось бы что-то более профитное, например:
query u { users(id: [1, 2, 3]) { id login is_active = true; } }
Получаем 3 юзера по их ID и активируем их.
SerafimArts
21.04.2017 15:21P.S. Пагинацию для себя сделал по другому, в таком виде:
query { users { id login } query2: users(_limit: 10) { id } paginate(query: "users") { total_count pages_count } paginate(query: "query2") { total_count pages_count } }
aliksend
21.04.2017 15:27Я бы всё-таки разделял получение данных и изменение: получать GET запросом, менять POST запросом. Так, мне кажется, безопаснее.
SerafimArts
21.04.2017 15:54Никто не мешает, к примеру, запрещать запись если запрос передаётся через GET.
Я просто озвучил один из вариантов, когда было бы на порядок удобнее, по-моему, т.е. именно так как мне хотелось бы чтобы оно работало. Жаль, что такой вариант не прокатит. Это требует модификации спецификации, а не простой надстройки над ней.
aliksend
21.04.2017 16:01В таком случае да, согласен, такой синтаксис был бы удобен. Можно начинать писать предложение, не мы первые кому не всё нравится в стандартной реализации.
VlastV
21.04.2017 16:58@SerafimArts, разве такая конструкция не решает вашу потребность?
mutation BatchUpdateProfile($id: [ID!]!, $profile: ProfileInput!) { batchUpdate(id: $id, profile: $profile) { id name } } input ProfileInput { active: Boolean! }SerafimArts
21.04.2017 18:49Ну…
1) Это слабочитаемо
2) Это всё же мутатор "batchUpdate" который придётся писать на сервере
3) Надо дублировать все селекторы из запросов в этот мутатор
Т.е. на сервере дофига копипасты. С таким же успехом можно использовать тот же самый rest — он будет проще, возможностей больше и меньше писанины на сервере.
В моём розовом и волшебном мире нет отличий между мутатором и селектором — это одно и тоже. Новые данные для выбранных элементов могут передаваться, а могут и нет. Вот и все отличия. Да и описывать всё это придётся один раз: "поле имеет тип блабла, нот нулл и риоднли", например.

TyVik
22.04.2017 22:55Я вот всё никак не пойму — первый пример (со списком полей) действительно настолько проблемный? Почему бы не указать нужные поля в качестве GET параметра, например: GET /api/v1/posts/?fields=author,text,likes.avatar.
Наша библиотека для построения REST такого из коробки не умела, но через пару часов был готов миксин с неограниченным уровнем вложенности.aliksend
23.04.2017 02:59Похожий подход используется в YouTube API кстати. Но видимо Facebook было этого мало.
Вообще, если смотреть на GraphQL и на такой способ определения необходимых полей, то создаётся впечатление, что это – урезанная версия GraphQL, ну или адаптация его под REST. Возможно что только у меня.
Ну и этот вариант не умеет в именованные запросы, параметры, типизацию и другое что умеет GraphQL
zelenin
23.04.2017 17:11Я вот всё никак не пойму — первый пример (со списком полей) действительно настолько проблемный
настолько или не настолько — не важно. есть пул проблем при работе с апи. ФБ их взял, переосмыслил и реализовал в единой спеке. Каждая проблема из этого пула имеет какую-либо сложность в реализации от простой до сильной, и в каких-либо спецификациях так или иначе решалась, но важно было подойти к вопросу комплексно.
fukkit
24.04.2017 20:17+1/get.php?q=select_*_from_users_left_join_comments_on_comment.userid=users.id
NographQL, скоро на экранах. Тёплый, ламповый, твой.
OlegZH
Огромное Вам спасибо за обзор, позволяющий войти в (новую) тему и узнать, куда (и зачем) следует обязательно заглянуть и что использовать. Ниже идут три вопроса, которые возникли у меня сразу по прочтении статьи:
Было бы любопытно взглянуть на архитектуру базы данных (или, даже, следует говорить уже об архитектуре системы управления базами данных?), которая оптимальным образом соответствует семантике GraphQL.
Alexeyco
aliksend
Нет, скорее речь идёт о замене/дополнению к REST API – своеобразной форме взаимодействия (язык общения, если угодно) между клиентом и сервером.
Знаю React поверхностно, так что могу быть неправ. Скорее всего автор имеет ввиду создание статических страниц (наподобие GitHub Gist), причём Gatsby собирает их на компьютере разработчика, делая запросы к БД при помощи GraphQL, собирая всё так, что при работе сайта БД уже не требуется, так как все необходимые данные были получены при сборке и были интегрированы в саму страницу.
Не понял вопроса. Теория – сама эта статья, есть примеры кода, есть ссылки на учебники, руководства. Или вы имеете ввиду что-то другое?
GraphQL не привязан к структуре базы: в базе данных может не существовать полей author или commentsCount – согласно примеру, посты могут храниться в postgres, поле commentsCount будет каждый раз подсчитываться:
Ещё какие-то вещи могут хранится в Redis и т.д., а GraphQL обеспечивает единый механизм доступа к этим данным и необходимую вложенность
OlegZH
Спасибо. Кое-что стало яснее.