
Современные операционные системы и микропроцессоры уже давно поддерживает многозадачность и вместе с тем, каждая из этих задач может выполняться в несколько потоков. Это дает ощутимый прирост производительности вычислений и позволяет лучше масштабировать пользовательские приложения и сервера, но за это приходится платить цену — усложняется разработка программы и ее отладка.

В этой статье мы познакомимся с POSIX Threads для того, чтобы затем узнать как это все работает в Linux. Не заходя в дебри синхронизации и сигналов, рассмотрим основные элементы Pthreads. Итак, под капотом потоки.
Общие сведения
Множественные нити исполнения в одном процессе называют потоками и это базовая единица загрузки ЦПУ, состоящая из идентификатора потока, счетчика, регистров и стека. Потоки внутри одного процесса делят секции кода, данных, а также различные ресурсы: описатели открытых файлов, учетные данные процесса сигналы, значения umask, nice, таймеры и прочее.

У всех исполняемых процессов есть как минимум один поток исполнения. Некоторые процессы этим и ограничиваются в тех случаях, когда дополнительные нити исполнения не дают прироста производительности, но только усложняют программу. Однако таких программ с каждым днем становится относительно меньше.
В чем польза множественных потоков исполнения? Возьмем какой-нибудь загруженный веб сервер, например habrahabr.ru. Если бы сервер создавал отдельный процесс для обслуживания каждого http запроса, мы бы ожидали вечно пока загрузится наша страница. Создания нового процесса — дорогостоящее удовольствие для ОС. Даже учитывая оптимизацию за счет копирования при записи, системные вызовы fork и exec создают новые копии страниц памяти и списка файловых описателей. В целом ядро ОС может создать новый поток на порядок быстрее, чем новый процесс.
Ядро задействует копирование при записи для страниц с данными, сегментов памяти родительского процесса содержащие стек и кучу. Вследствие того, что процессы часто выполняют вызов fork и сразу после этого exec, копирование их страниц во время выполнения вызова fork становится ненужной расточительностью — их все равно приходится отбрасывать после выполнения exec. Сперва записи таблицы страниц указывают на одни и те же страницы физической памяти родительского процесса, сами же страницы маркируются только для чтения. Копирование страницы происходит ровно в тот момент, когда требуется ее изменить.
Таблицы страниц до и после изменения общей страницы памяти во время копирования при записи.
Существует закономерность между количеством параллельных нитей исполнения процесса, алгоритмом программы и ростом производительности. Это зависимость называется Законом Амдаля.
Закон Амдаля для распараллеливания процессов.

Используя уравнение, показанное на рисунке, можно вычислить максимальное улучшение производительности системы, использующей N процессоров и фактор F, который указывает, какая часть системы не может быть распараллелена. Например 75% кода запускается параллельно, а 25% — последовательно. В таком случае на двухядерном процессоре будет достигнуто 1.6 кратное ускорение программы, на четырехядерном процессоре — 2.28571 кратное, а предельное значение ускорения при N стремящемся к бесконечности равно 4.
Отображение потоков в режим ядра
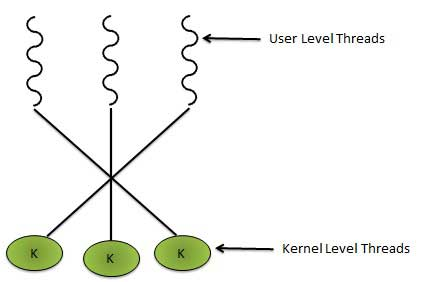
Практически все современные ОС — включая Windows, Linux, Mac OS X, и Solaris — поддерживают управление потоками в режиме ядра. Однако потоки могут быть созданы не только в режиме ядра, но и в режиме пользователя. При использовании этого уровня ядро не знает о существовании потоков — все управление потоками реализуется приложением с помощью специальных библиотек. Пользовательские потоки по разному отображаются на потоки в режиме ядра. Всего существует три модели, из которых 1:1 является наиболее часто используемой.
Отображение N:1
В данной модели несколько пользовательских потоков отображаются на один поток ядра ОС. Все управление потоками осуществляет особая пользовательская библиотека, и в этом преимущество такого подхода. Недостаток же в том, что если один единственный поток выполняет блокирующий вызов, то тогда тормозится весь процесс. Предыдущие версии Solaris OS использовали такую модель, но затем вынуждены были от нее отказаться.

Отображение 1:1
Это самая проста модель, в которой каждый поток созданный в каком-нибудь процессе непосредственно управляется планировщиком ядра ОС и отображается на один единственный поток в режиме ядра. Чтобы приложение не плодило бесконтрольно потоки, перегружая ОС, вводят ограничение на максимальное количество потоков поддерживаемых в ОС. Данный способ отображения потоков поддерживают ОС Linux и Windows.

Отображение M:N
При таком подходе M пользовательских потоков мультиплексируются в такое же или меньшее N количество потоков ядра. Преодолеваются негативные эффекты двух других моделей: нити по-настоящему исполняются параллельно и нет необходимости в ОС вводить ограничения на их общее количество. Вместе с тем данную модель довольно трудно реализовать с точки зрения программирования.
Потоки POSIX
В конце 1980-х и начале 1990-х было несколько разных API, но в 1995 г. POSIX.1c стандартизовал потоки POSIX, позже это стало частью спецификаций SUSv3. В наше время многоядерные процессоры проникли даже в настольные ПК и смартфоны, так что у большинства машин есть низкоуровневая аппаратная поддержка, позволяющая им одновременно выполнять несколько потоков. В былые времена одновременное исполнение потоков на одноядерных ЦПУ было лишь впечатляюще изобретательной, но очень эффективной иллюзией.
Pthreads определяет набор типов и функций на Си.
pthread_t— идентификатор потока;pthread_mutex_t— мютекс;pthread_mutexattr_t— объект атрибутов мютексаpthread_cond_t— условная переменнаяpthread_condattr_t— объект атрибута условной переменной;pthread_key_t— данные, специфичные для потока;pthread_once_t— контекст контроля динамической инициализации;pthread_attr_t— перечень атрибутов потока.
В традиционном Unix API код последней ошибки errno является глобальной int переменной. Это однако не годится для программ с множественными нитями исполнения. В ситуации, когда вызов функции в одном из исполняемых потоков завершился ошибкой в глобальной переменной errno, может возникнуть состояние гонки из-за того, что и остальные потоки могут в данный момент проверять код ошибки и оконфузиться. В Unix и Linux эту проблему обошли тем, что errno определяется как макрос, задающий для каждой нити собственное изменяемое lvalue.
Из man errno
Переменная errno определена в стандарте ISO C как изменяемое lvalue int и не объявляемая явно; errno может быть и макросом. Переменная errno является локальным значением нити; её изменение в одной нити не влияет на её значение в другой нити.
Создание потока
В начале создается потоковая функция. Затем новый поток создается функцией pthread_create(), объявленной в заголовочном файле pthread.h. Далее, вызывающая сторона продолжает выполнять какие-то свои действия параллельно потоковой функции.
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start)(void *), void *arg);При удачном завершении pthread_create() возвращает код 0, ненулевое значение сигнализирует об ошибке.
- Первый параметр вызова
pthread_create()является адресом для хранения идентификатора создаваемого потока типаpthread_t. - Аргумент
startявляется указателем на потоковуюvoid *функцию, принимающей бестиповый указатель в качестве единственной переменной. - Аргумент
arg— это бестиповый указатель, содержащий аргументы потока. Чаще всегоargуказывает на глобальную или динамическую переменную, но если вызываемая функция не требует наличия аргументов, то в качествеargможно указатьNULL. - Аргумент
attrтакже является бестиповым указателем атрибутов потокаpthread_attr_t. Если этот аргумент равенNULL, то поток создается с атрибутами по умолчанию.
Рассмотрим теперь пример многопоточной программы.
#include <pthread.h>
#include <stdio.h>
int count; /* общие данные для потоков */
int atoi(const char *nptr);
void *potok(void *param); /* потоковая функция */
int main(int argc, char *argv[])
{
pthread_t tid; /* идентификатор потока */
pthread_attr_t attr; /* отрибуты потока */
if (argc != 2) {
fprintf(stderr,"usage: progtest <integer value>\n");
return -1;
}
if (atoi(argv[1]) < 0) {
fprintf(stderr,"Аргумент %d не может быть отрицательным числом\n",atoi(argv[1]));
return -1;
}
/* получаем дефолтные значения атрибутов */
pthread_attr_init(&attr);
/* создаем новый поток */
pthread_create(&tid,&attr,potok,argv[1]);
/* ждем завершения исполнения потока */
pthread_join(tid,NULL);
printf("count = %d\n",count);
}
/* Контроль переходит потоковой функции */
void *potok(void *param)
{
int i, upper = atoi(param);
count = 0;
if (upper > 0) {
for (i = 1; i <= upper; i++)
count += i;
}
pthread_exit(0);
}Чтобы подключить библиотеку Pthread к программе, нужно передать компоновщику опцию -lpthread.
gcc -o progtest -std=c99 -lpthread progtest.cО присоединении потока pthread_join расскажу чуть позже. Строка pthread_t tid задает идентификатор потока. Атрибуты функции задает pthread_attr_init(&attr). Так как мы не задавали их явно, будут использованы значения по умолчанию.
Завершение потока
Поток завершает выполнение задачи когда:
- потоковая функция выполняет
returnи возвращает результат произведенных вычислений; - в результате вызова завершения исполнения потока
pthread_exit(); - в результате вызова отмены потока
pthread_cancel(); - одна из нитей совершает вызов
exit() - основная нить в функции
main()выполняетreturn, и в таком случае все нити процесса резко сворачиваются.
Синтаксис проще, чем при создании потока.
#include <pthread.h>
void pthread_exit(void *retval);Если в последнем варианте старшая нить из функции main() выполнит pthread_exit() вместо просто exit() или return, то тогда остальные нити продолжат исполняться, как ни в чем не бывало.
Ожидание потока
Функция pthread_join() ожидает завершения потока обозначенного THREAD_ID. Если этот поток к тому времени был уже завершен, то функция немедленно возвращает значение. Смысл функции в том, чтобы синхронизировать потоки. Она объявлена в pthread.h следующим образом:
#include <pthread.h>
int pthread_join (pthread_t THREAD_ID, void ** DATA);При удачном завершении pthread_join() возвращает код 0, ненулевое значение сигнализирует об ошибке.
Если указатель DATA отличается от NULL, то туда помещаются данные, возвращаемые потоком через функцию pthread_exit() или через инструкцию return потоковой функции. Несколько потоков не могут ждать завершения одного. Если они пытаются выполнить это, один поток завершается успешно, а все остальные — с ошибкой ESRCH. После завершения pthread_join(), пространство стека связанное с потоком, может быть использовано приложением.
В каком-то смысле pthread_joini() похожа на вызов waitpid(), ожидающую завершения исполнения процесса, но с некоторыми отличиями. Во-первых, все потоки одноранговые, среди них отсутствует иерархический порядок, в то время как процессы образуют дерево и подчинены иерархии родитель — потомок. Поэтому возможно ситуация, когда поток А, породил поток Б, тот в свою очередь заделал В, но затем после вызова функции pthread_join() А будет ожидать завершения В или же наоборот. Во-вторых, нельзя дать указание одному ожидай завершение любого потока, как это возможно с вызовом waitpid(-1, &status, options). Также невозможно осуществить неблокирующий вызов pthread_join().
Досрочное завершение потока
Точно так же, как при управлении процессами, иногда необходимо досрочно завершить процесс, многопоточной программе может понадобиться досрочно завершить один из потоков. Для досрочного завершения потока можно воспользоваться функцией pthread_cancel.
int pthread_cancel (pthread_t THREAD_ID);При удачном завершении pthread_cancel() возвращает код 0, ненулевое значение сигнализирует об ошибке.
Важно понимать, что несмотря на то, что pthread_cancel() возвращается сразу и может завершить поток досрочно, ее нельзя назвать средством принудительного завершения потоков. Дело в том, что поток не только может самостоятельно выбрать момент завершения в ответ на вызов pthread_cancel(), но и вовсе его игнорировать. Вызов функции pthread_cancel() следует рассматривать как запрос на выполнение досрочного завершения потока. Поэтому, если для вас важно, чтобы поток был удален, нужно дождаться его завершения функцией pthread_join().
Небольшая иллюстрация создания и отмены потока.
pthread_t tid;
/* создание потока */
pthread_create(&tid, 0, worker, NULL);
…
/* досрочное завершение потока */
pthread_cancel(tid);Чтобы не создалось впечатление, что тут царит произвол и непредсказуемость результатов данного вызова, рассмотрим таблицу параметров, которые определяют поведение потока после получения вызова на досрочное завершение.

Как мы видим есть вовсе неотменяемые потоки, а поведением по умолчанию является отложенное завершение, которое происходит в момент завершения. А откуда мы узнаем, что этот самый момент наступил? Для этого существует вспомогательная функция pthread_testcancel.
while (1) {
/* чего-то там делаем */
/* пам-парам-пам-пам */
/* не пора-ли сворачиваться? */
pthread_testcancel();
}Отсоединение потока
Любому потоку по умолчанию можно присоединиться вызовом pthread_join() и ожидать его завершения. Однако в некоторых случаях статус завершения потока и возврат значения нам не интересны. Все, что нам надо, это завершить поток и автоматически выгрузить ресурсы обратно в распоряжение ОС. В таких случаях мы обозначаем поток отсоединившимся и используем вызов pthread_detach().
#include <pthread.h>
int pthread_detach(pthread_t thread);При удачном завершении pthread_detach() возвращает код 0, ненулевое значение сигнализирует об ошибке.
Отсоединенный поток — это приговор. Его уже не перехватить с помощью вызова pthread_join(), чтобы получить статус завершения и прочие плюшки. Также нельзя отменить его отсоединенное состояние. Вопрос на засыпку. Что будет, если завершение потока не перехватить вызовом pthread_join() и чем это отлично от сценария, при котором завершился отсоединенный поток? В первом случае мы получим зомбо-поток, а во втором — все будет норм.
Потоки versus процессы
Напоследок предлагаю рассмотреть несколько соображений на тему, следует ли проектировать приложение многопоточным или запускать его в несколько процессов с одним потоком? Сперва выгоды параллельных множественных потоков.
В начальной части статьи мы уже указывали на эти преимущество, поэтому вкратце их просто перечислим.
- Потоки довольно просто обмениваются данными по сравнению с процессами.
- Создавать потоки для ОС проще и быстрее, чем создавать процессы.
Теперь немного о недостатках.
- При программировании приложения с множественными потоками необходимо обеспечить потоковую безопасность функций — т. н. thread safety. Приложения, выполняющиеся через множество процессов, не имеют таких требований.
- Один бажный поток может повредить остальные, так как потоки делят общее адресное пространство. Процессы более изолированы друг от друга.
- Потоки конкурируют друг с другом в адресном пространстве. Стек и локальное хранилище потока, захватывая часть виртуального адресного пространства процесса, тем самым делает его недоступным для других потоков. Для встроенных устройств такое ограничение может иметь существенное значение.
Тема потоков практически бездонна, даже основы работы с потоками может потянуть на пару лекций, но мы уже знаем достаточно, чтобы изучить структуру многопоточных приложений в Linux.
Использованные материалы и дополнительная информация
- Michael Kerrisk The Linux Programming Interface.
- Abraham Silberschatz, Peter B. Galvin Greg Gagne, Operating System Concepts 9-th ed.
- Николай Иванов Самоучитель программирования в Linux 2-t издание.
- Эндрю Таненбаум Архитектура компьютера.
Комментарии (25)

x893
22.04.2017 23:14Простенько и со вкусом. Отлаживать можно через gdbserver из Visual Studio 2015/17. Хотя и через Eclipse никто не запрещает.

pfactum
22.04.2017 23:33-7В Линуксе всё — процессы. То, что вы называете потоками — это те же процессы, которые делят между собой некоторые ресурсы, например, адресное пространство.
man 2 clone, например, CLONE_VM.splav_asv
22.04.2017 23:45+1Вопрос терминологии. «Если это выглядит как утка, плавает как утка и крякает как утка, то это, возможно, и есть утка.» А как это уже внутри ядра реализвано это отдельный вопрос. Если реализация поменяется — название тоже менять?
pfactum
23.04.2017 00:26В ядре реализацию никто не будет менять, т.к. это вопрос обратной совместимости. В ядре с этим строго.
splav_asv
23.04.2017 00:32Всегда есть возможность оставить слой совместимости, возможно появление параллельно другой реализации потоков. Да, такие вещи делают только в исключительных случаях. Но исключать возможность я бы не стал.

lieff
23.04.2017 00:50+4В ядре какой системы? POSIX и pthreads же не привязан к одному линуксу, а речь про них. В терминах ядра линукса вы абсолютно правы, но речь не про ядро линукса.
lieff
22.04.2017 23:48Вопрос терминологии, можно сказать что clone() c флагами CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SYSVSEM | CLONE_SIGHAND | CLONE_THREAD | CLONE_SETTLS | CLONE_PARENT_SETTID | CLONE_CHILD_CLEARTID — метод создать тред в терминах сисколов ядра линукса. Здесь же речь про pthreads, а в нем это тред называется.

sens_boston
23.04.2017 06:16-8
предельное значение ускорения при N стремящемся к бесконечности равно 4.
Это неверно. Надеюсь, остальное в вашей статье не так ошибочно…sens_boston
23.04.2017 06:22-6Поправлюсь (хабр не дал возможность изменить комментарий — что за идиотские правила?!):
это верно только для соотношения 0.25/0.75 (потому, что 1/4 :) ), но, если величина параллельного кода > 99%, то тогда пресловутая формула стремится к 100 (при бесконечном числе процессоров).
Что, с «точки зрения банальной эрудиции» (а также формальной логики) есть полный бред — получается прямо какая-то скорость света в вакууме. Возможно, я и ошибаюсь, но мне кажется, что ускорить вычисления более чем в сто раз вполне реально.khim
23.04.2017 09:34+2Поправлюсь (хабр не дал возможность изменить комментарий — что за идиотские правила?!):
Правила как раз нормальные. А то появятся всякие «владельцы своего слова»: захотел — дал, захотел — забрал. А так — сразу видно кто — думает при написании комментариев, кто — нет.
Возможно, я и ошибаюсь, но мне кажется, что ускорить вычисления более чем в сто раз вполне реально.
Если у вас есть один процент, который обязательно нужно исполнять последовательно — то нет. А если такого участка кода нет, то да, разумеется — и закону Амдала это никак не противоречит…
это верно только для соотношения 0.25/0.75 (потому, что 1/4 :) ), но, если величина параллельного кода > 99%, то тогда пресловутая формула стремится к 100 (при бесконечном числе процессоров).
Если процент параллелизуемого кода > 99%, то формула может стремиться и к тысяче и к миллиону — посчитайте.
P.S. Если уж так хотелось написать «аффтар — дурак, статья — равно», то вы бы уж лучше придрались к тому, что он «закон Амдала» называет «закон Амдала». Выглядело бы всё равно не так жалко, как то, что вы тут изобразили…

Deosis
24.04.2017 07:24+3Например 75% кода запускается параллельно, а 25% — последовательно.
Пропустить важное уточнение и ругать на основе этого статью?
Получается как в анекдоте про аквариум и логику.
D_T
23.04.2017 15:37Что будет, если завершение потока не перехватить вызовом pthread_join() и чем это отлично от сценария, при котором завершился отсоединенный поток?
Если это повторить много раз, то pthread_create() перестанет создавать потоки.



S_o_T
23.04.2017 17:11+1Было бы полезно, если на хабре появится актуальная статья про std::thread (в сравнении с pthread), с оглядкой на кроссплатформеность и состояние реализаций на разных платформах.

FuryaevStanislav
23.04.2017 20:28Объясните, пожалуйста, зачем в таких функциях, как pthread_create() передается указатель на переменную, куда записать номер потока. Почему нельзя просто вернуть этот номер из функции?
pthread_t thread = pthread_create();hdfan2
23.04.2017 22:00+1Потому что при ошибке она возвращает код ошибки. Всяко лучше, чем через errno.

netch80
24.04.2017 09:03+2Потому что все функции pthread API сделаны так, чтобы не пришлось ходить к нему же для получения errno (errno в многонитевом режиме это что-то вроде (*__errno_ptr()), где функция errno_ptr находит thread-local storage (TLS) данной нити и возвращает адрес errno в нём). Коды ошибки универсально возвращаются из функции, 0 означает отсутствие ошибки, другой код — конкретный номер ошибки.
И этот код надо проверять — несоздание нити в случае переполнения чего-нибудь это вполне обычная ситуация. Поэтому он возвращается напрямую, а идентификатор созданной нити — по указателю.

zuko3d
24.04.2017 09:35+1Потому что мы хотим узнать, отработала ли функция нормально (в данном случае — удалось ли создать поток). Т.е. pthread_create() возвращает код ошибки (или 0 в случае успеха). Если его не возвращать, то требовалось бы либо передавать этот код через одну из переменных, либо через какое-то глобальное значение. Возвращать статус исполнения — самый частый подход, поэтому его придерживались и здесь тоже.
stDistarik
24.04.2017 09:35Вы предлагаете подключать библиотеку так:
-lpthread
А если подключать так (без l вначале):
-pthread
Тогда подключатся потоко-безопасные функции…
man gcc
-pthread
Adds support for multithreading with the pthreads library. This option sets flags for both the preprocessor and linker.
Иными словами — -pthread == -D_REENTRANT -lpthread
khim
24.04.2017 17:00А вот, кстати, интересно что со всем этим делать. Когда-то, давным-давно, на всяких AIX'ах и HP-UX'ах это было реально важно. Но сегодня — что в GNU/Linux, что в MacOS, что в Android нет никакой разницы.
Так стоит ли про это помнить или нет?
Иными словами — -pthread == -D_REENTRANT -lpthread
Не совсем так. На OpenBSD оно будет пределять -D_POSIX_THREADS, на AIX — -D_THREAD_SAFE, на FreeBSD — будет, ко всему прочему, использовать не libc.so, а libc_r.so и так далее. Сейчас посмотрел: на HP-UX'е нужно определять всё сразу: и -D_REENTRANT -D_THREAD_SAFE и ещё -D_POSIX_C_SOURCE=199506L!
Но вот конкретно на большинстве операционок на основе Linux'а — разницы нет!
Spiritschaser
24.04.2017 18:15Кажется, у вас есть неточности:
Solaris использовал M:N
M:N сейчас используется в DragonflyBSD: да, у нас теоретически неограниченное число тредов (как когда-то в солярке).khim
24.04.2017 19:01да, у нас теоретически неограниченное число тредов (как когда-то в солярке).
Неправда ваша, тётенька. Количество тредов — всегда ограничено, так как каждому положен свой стек. С учётом того, что в Linux в ядре только ядрёный стек новому треду и положен, больше ничего — практическая разница невелика. Ах, да, ещё номера могут для них кончится раньше, если на машине более 64TiB памяти… не знаю — такие системы, хотя бы в теории, DragonflyBSD поддерживает???
afiskon
Спасибо за статью. Стоит добавить, что pthreads также предлагает примитивы синхронизации, в частности мьютексы — см man pthread_mutex_init и далее по ссылкам.