
Это третья публикация в рамках помощи участникам конкурса «SAP Кодер-2017».
Каждое предприятие в процессе своей жизнедеятельности генерирует значительное количество данных, как «больших», так и не очень. Эти данные часто можно использовать для получения нового знания, которое, в свою очередь может оказать существенное влияние на стратегию развития бизнеса или тактику поведения в некоторые локальные моменты работы. Сейчас, в связи с развитием вычислительной техники и ростом объема накопленных данных, большое развитие получили численные методы, позволяющие извлекать полезную информацию из массива «сырых» данных и использовать ее в различных бизнес-сценариях.

SAP Cloud Platform имеет, наряду с другими встроенными сервисами, инструментарий предиктивной аналитики, позволяющий строить и использовать построенные модели в созданных на платформе (и вне ее) бизнес-задачи. Набор прогнозных инструментов, входящий в сервис на дату публикации поста, состоит из следующих элементов:
- Clustering – классический кластерный анализ и сегментация базы объектов с большим количеством атрибутов-классификаторов;
- Forecasts – построение прогнозов на базе временных рядов;
- Key Influencers – поиск наиболее влияющих на целевую функцию параметров;
- Outliers – поиск нестандартных паттернов в наборе данных (выявление мошенничеств, ошибок ввода и пр.);
- Recommendation – построение моделей продуктовых рекомендаций на базе истории покупок (чеков);
- Scoring Equation – построение и экстракция уравнения, позволяющего вычислять целевую функцию аналитически и встраивать ее в собственное приложение;
- What If – анализ «что-если», позволяющий предполагать последствия совершения тех или иных действий, базируясь на истории поведения объекта
Актуальный список методов и их описание можно посмотреть по ссылке.
Одна из задач на конкурс SAP Кодер предполагает использование модели рекомендаций. Здесь мы расскажем, как построить подобную модель в Predictive сервисе SCP. Первое, с чего стоит начать – это подготовка данных для «тренировки» модели. В случае сервиса Recommendation под тренировкой подразумевается поиск пар товаров (продающихся вместе) и построение списка рекомендаций конкретным клиентам (например, участникам программы лояльности).
Исходные данные
Исходные данные для построения модели просты – это кассовые чеки магазина. Они должны содержать следующие параметры:
- userID – номер участника программы лояльности (уникальный идентификатор покупателя)
- itemID – код товара (SKU)
- purchaseDate – дата транзакции (чека)
Загрузить эти данные в систему, не имея доступа к файловой системе сервера, проще всего через функцию Import/Export в HANA Studio (Eclipse). Для этого необходимо:
- Подготовить данные в файле формата CSV.
- Создать на SCP новую базу данных HANA MDC. В нашем случае она называется h1
- Создать схему данных, в которой мы будем проводить наши эксперименты. Мы создали схему PROBA
- Создать таблицу для помещения исходных данных, здесь PROBA.SALES_DATA. В таблице должно быть несколько ключевых полей, в нашем случае это RID – номер участника программы лояльности, RDATE, TRIME, RDATETIME – дата и время транзакции в разных форматах, важна только RDATETIME, SKU – артикул товара.

Дополнительно в нашей базе данных содержится таблица PRODUCTS – из двух полей – код и название товара.
- Выгрузить таблицу SALES_DATA на локальный диск с помощью функции Export. Спуститься по структуре каталогов до файлов с описанием экспорта
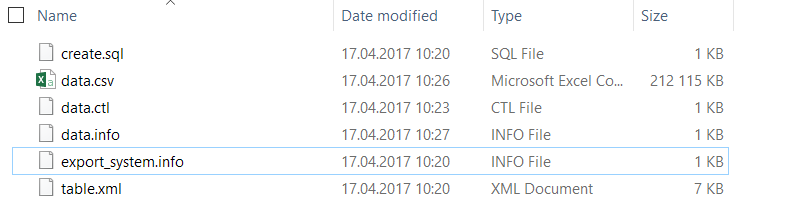
- В файл data.csv поместить данные в формате CSV
- В файле data.ctl поменять разделитель полей CSV на необходимый
- В файле data.info изменить данные о размере файла data.csv и количестве строк в нем
- Загрузить данные с помощью функции Import с заменой существующего объекта в базе данных
Настройка сервиса
Прежде, чем приступить к построению модели, необходимо произвести базовые настройки сервиса Predictive. По умолчанию сервис выключен, первое, что надо сделать – включить сервис
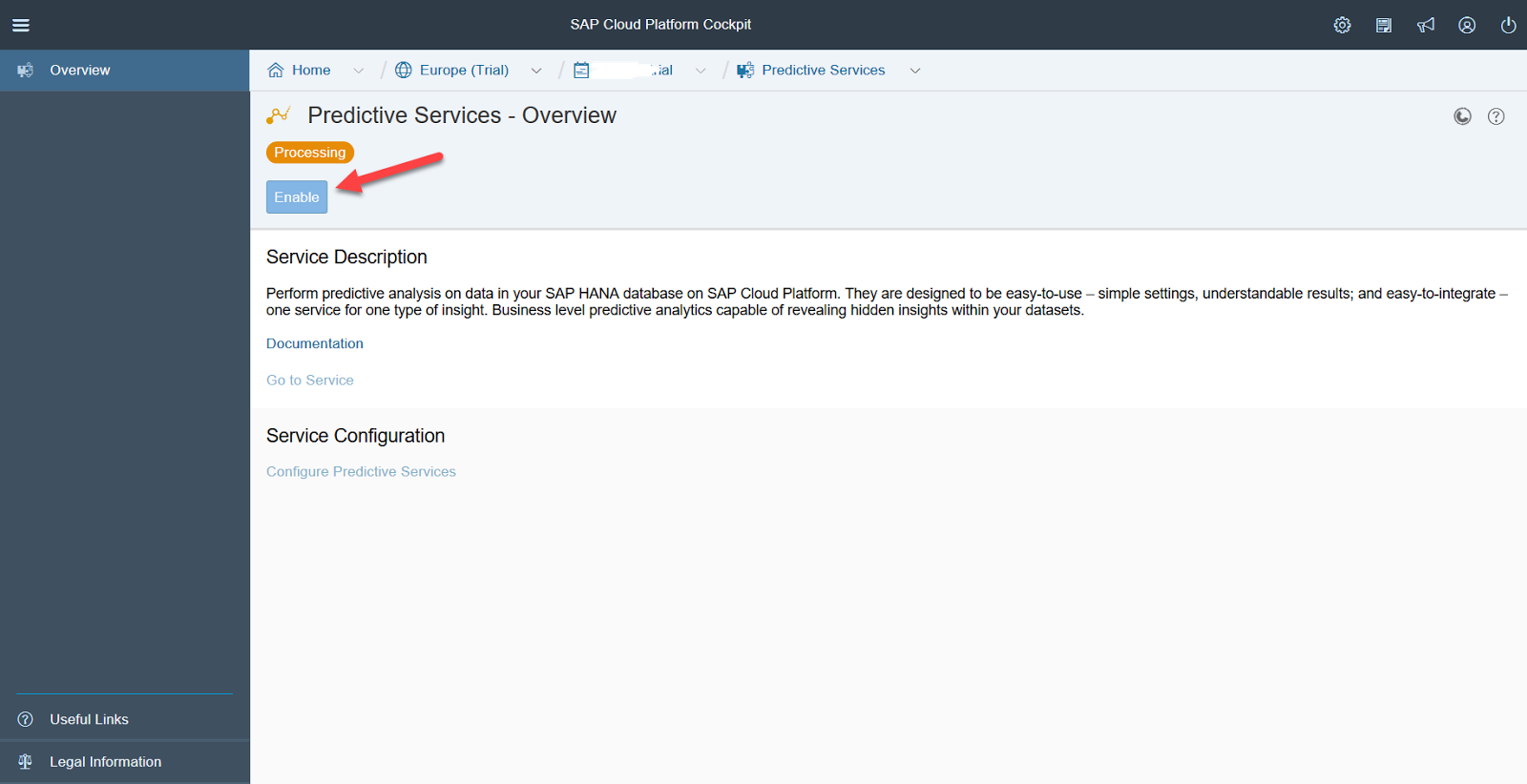
Система спросит, стоит ли устанавливать обновления. Правильный ответ – да. После этого необходимо развернуть сервис на вашем эккаунте пользователя, для этого необходимо ввести логин и пароль, используемые для входа на SCP.
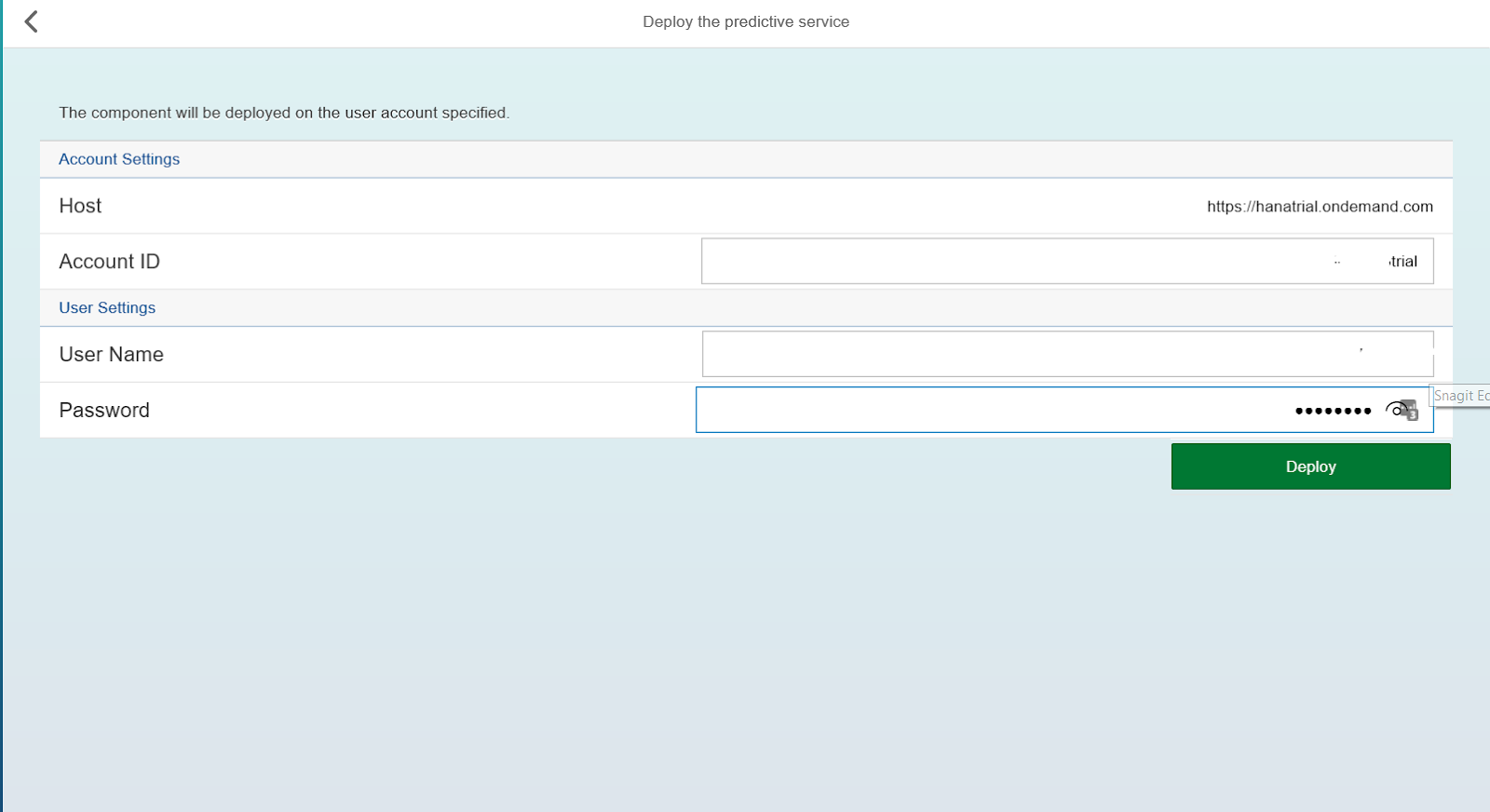
После разворачивания сервиса нажимаем на ссылку Java Dashboard
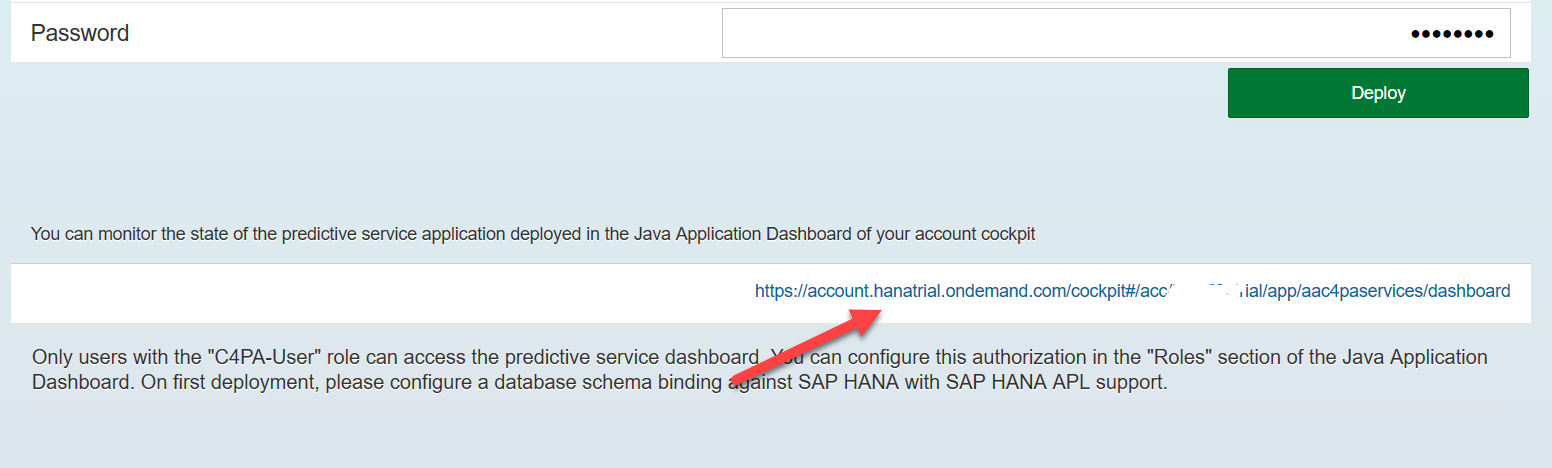
И присваиваем своему пользователю-разработчику обе указанные роли: C4PA-User, C4PA-Admin

Следующим шагом мы должны привязать SCP Predictive service к нашей базе данных
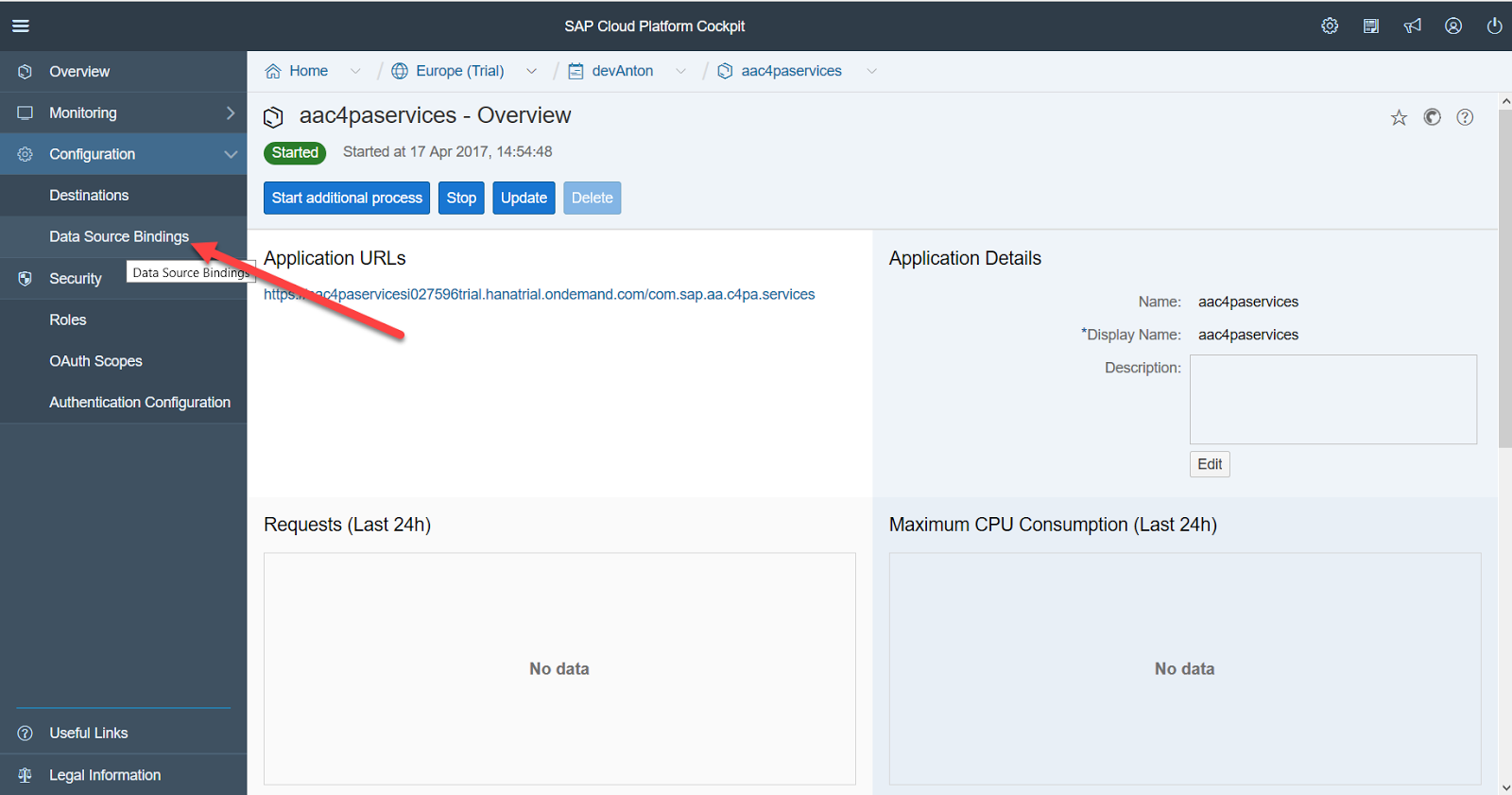
Для этого в базе данных желательно создать технического пользователя, в нашем случае PROBA_U
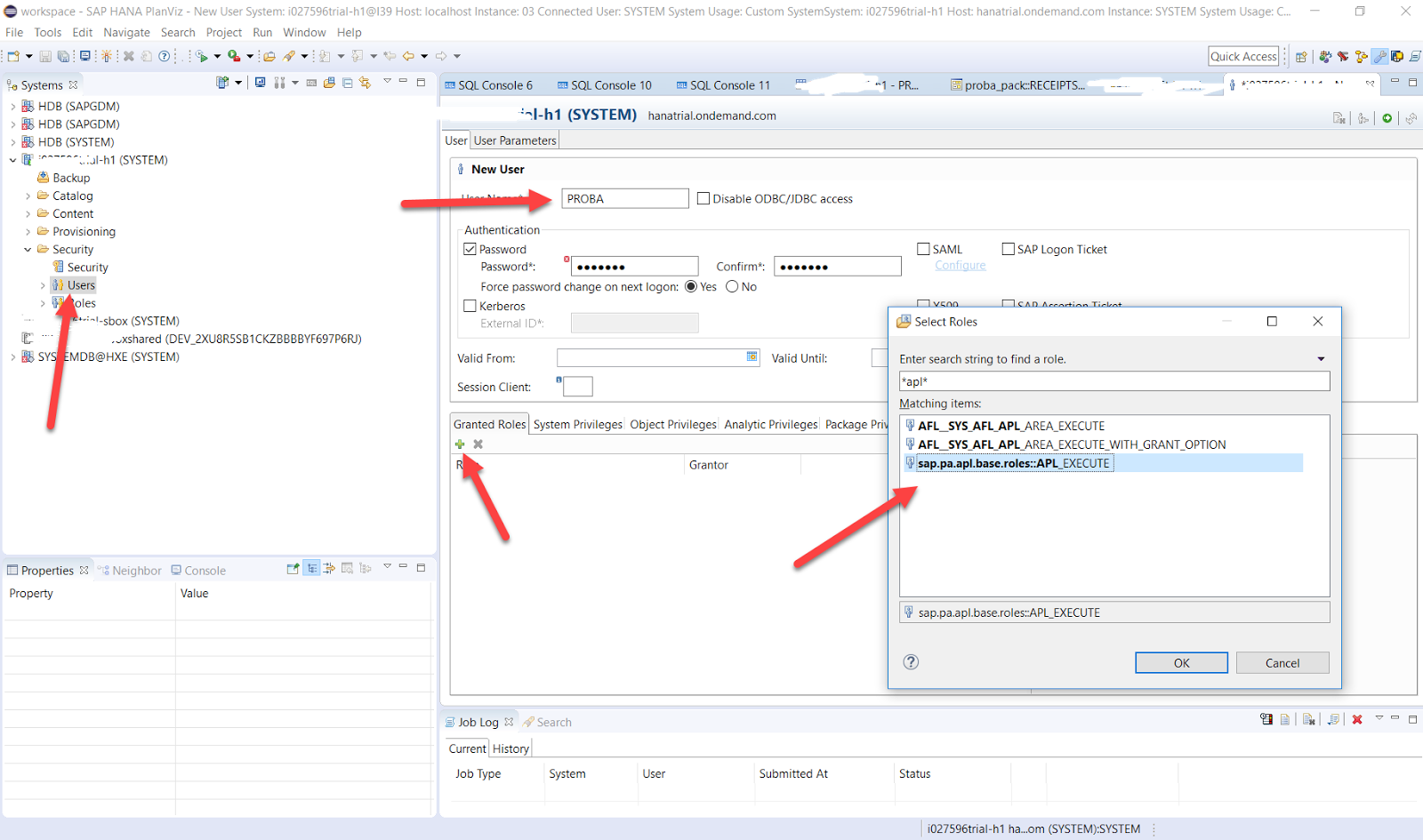
и присвоить ему необходимые для запуска предиктивного сервиса полномочия. При создании пользователя HANA спросит начальный пароль, чтобы изменить его (и входить в базу автоматически от имени Predictive Service), необходимо один раз войти в систему от имени этого пользователя. Для этого надо создать новое подключение к облачному источнику данных в HANA Studio и войти в базу данных, изменив начальный пароль.
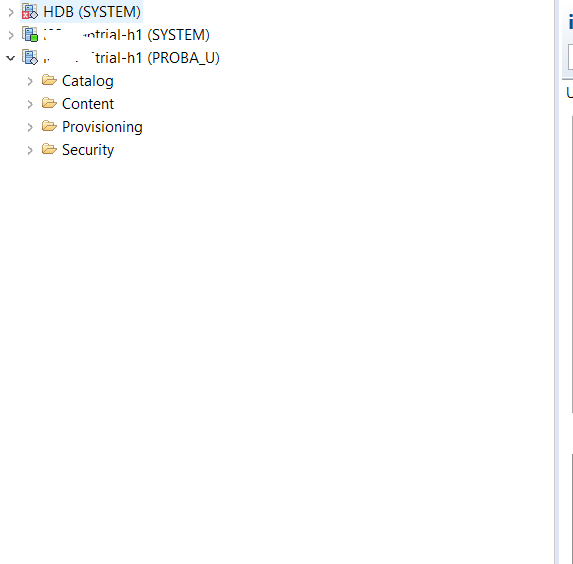
После создания технического пользователя (или решения использовать существующего) привязываем сервис к конкретной схеме базы данных.
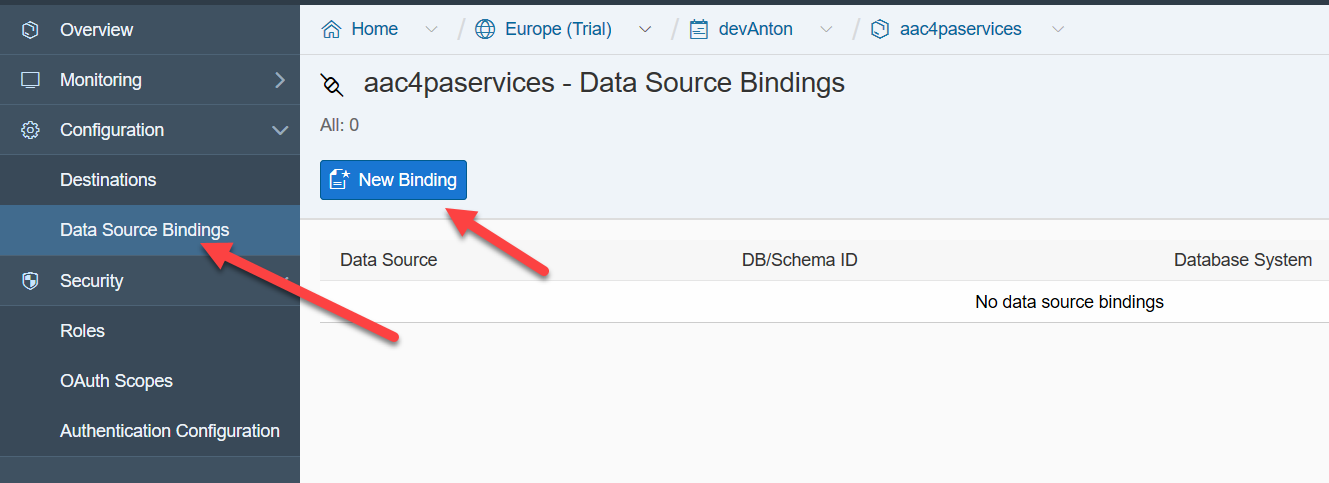
При этом используем данные технического пользователя, Data Source оставляем по умолчанию — .
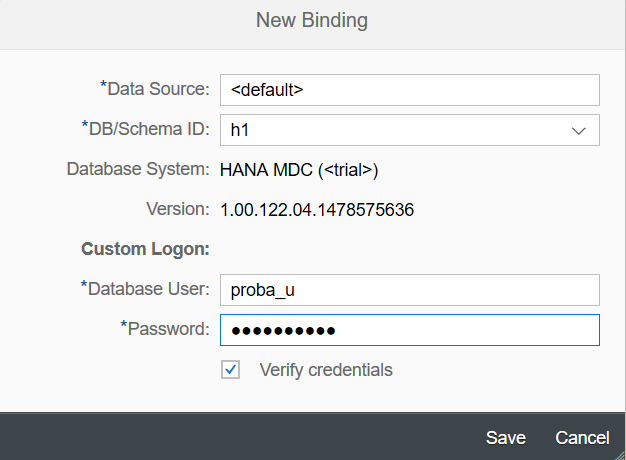
После разворачивания сервиса на эккаунте разработчика и привязки базы данных рестартуем сервис – последовательно нажимаем кнопки Stop и Start.
После перезапуска сервиса появится ссылка на java-приложение, позволяющее управлять сервисом, контролировать его и использовать в разработке приложений
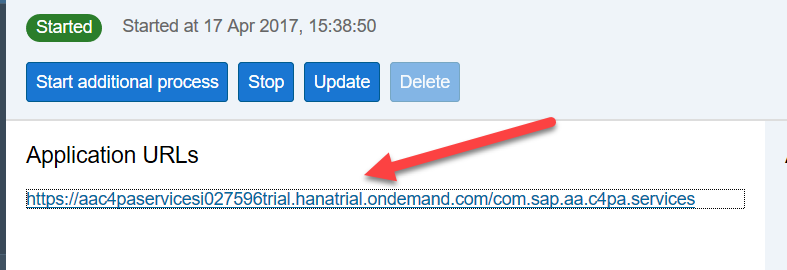
После вызова ссылки система предлагает нам две панели, одна для разработки, другая для мониторинга сервиса
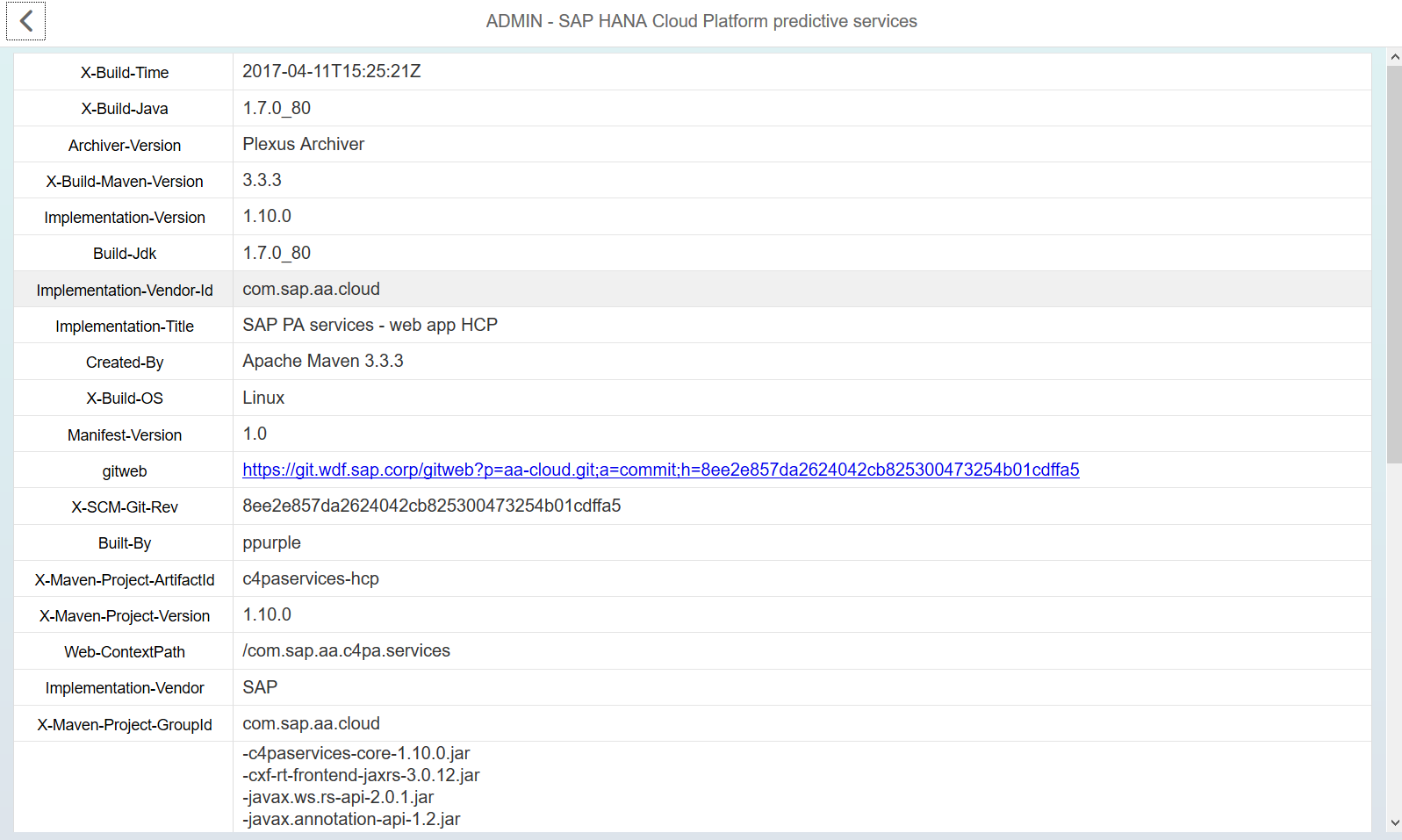
При нажатии на панель Administration, приложение выдает массу мониторинговой информации о Predictive service, которую можно использовать для анализа, однако для нашего случая основной панелью является «Predictive Services API Documentation»
Построение и использование модели рекомендаций
Посмотрим на наши чеки в более приспособленном для человеческого взгляда виде. Для этого создадим представление данных в виде
CREATE VIEW "PROBA"."SALESWPROD" ( "RID",
"USER_ID",
"RDATE",
"RTIMESTAMP",
"ITEMS",
"SKU_ID",
"SKU_NAME" ) AS SELECT
T0."RID" ,
t0."USER_ID",
T0."RDATE",
TO_TIMESTAMP(T0."RDATETIME"),
T0."ITEMS",
T0."SKU",
T1."SKU_NAME"
from "PROBA"."SALES_DATA" T0
inner join "PROBA"."PRODUCTS" T1 on T0."SKU" = T1."SKU_ID" WITH READ ONLY
Это view не нужно нам для решения нашей задачи, но позволяет наглядно увидеть чеки с позициями продаж (SKU)

Запускаем «Predictive Services API Documentation». На этой странице приложения Predictive Service собраны все включенные в него математические методы и точки доступа к каждому из них (endpoints).
Начнем с создания источника данных для предиктивной модели. Для этого нажимаем на закладку POST у точки доступа /api/analytics/dataset
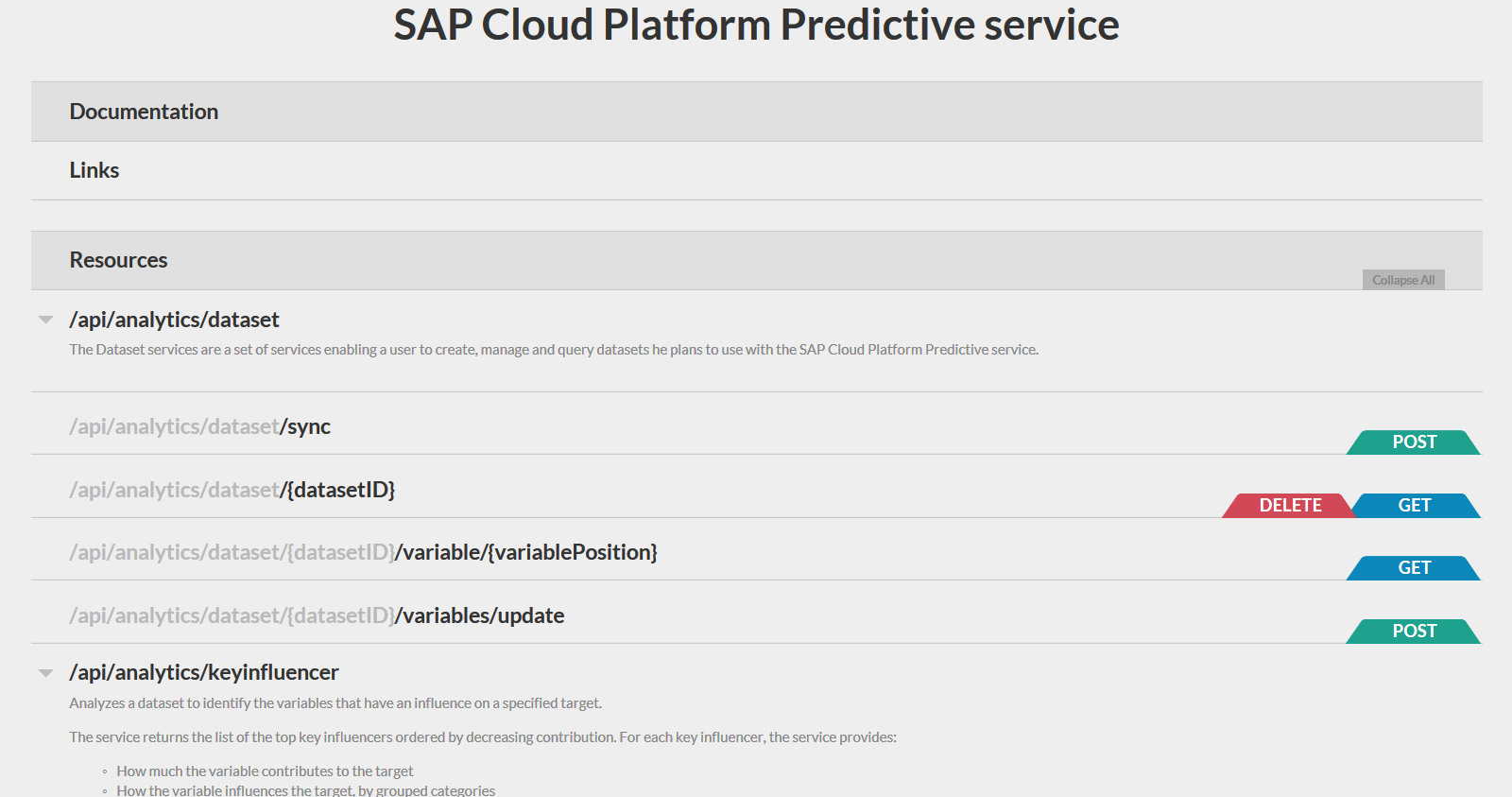
и меняем параметр hanaURL в JSON-шаблоне, с помощью которого передаются все параметры в Perdictive service. Нажимаем POST, дожидаемся ответа сервера со статусом 200. В ответ сервер возвращает также JSON-файл, в котором сообщает информацию о подключенном источнике (количество строк, количество и тип поле и т.д., и, главное, ID датасета. Этот ID нам надо запомнить, в дальнейшем мы будем использовать его при создании модели рекомендации. Закрываем данную форму нажатием кнопки close в правом верхнем углу.
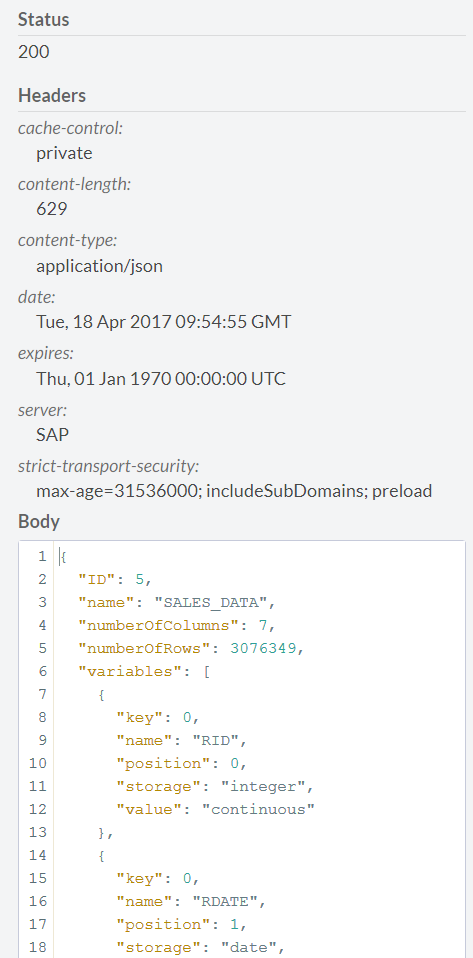
Возвращаемся на основную страницу Predictive Service и переходим к созданию модели. Для этого нажимаем закладку POST у ссылки /api/analytics/recommendations/recommender. Открывается страница настройки модели рекомендаций. Параметры построения будущей модели задаются в JSON-формате. Все возможные параметры модели описаны в документации по адресу https://help.hana.ondemand.com/c4pa/frameset.htm?ee805144d197482abef88bfad8d895da.html.
Это
- UserColumn – поле с номером участника программы лояльности
- itemColumn – SKU
- dateColumn – дата транзакции
- startDate – дата начала данных для расчета
- endDate – дата окончания данных для расчета
Дополнительно можно менять параметры, описывающие математику модели. Для нашей модели мы возьмем следующие параметры:
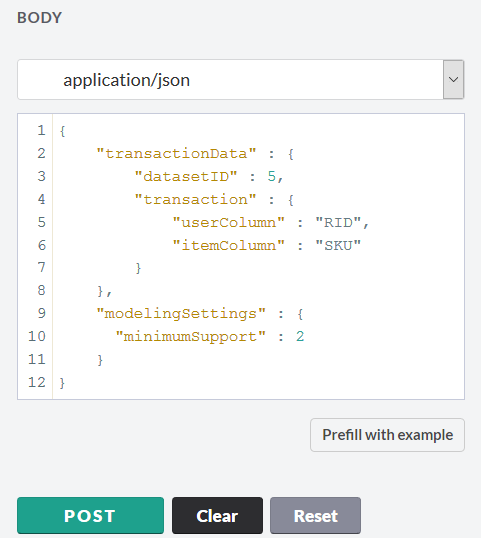
Запускаем построение модели и получаем отклик. Ключевой момент – записать ID модели
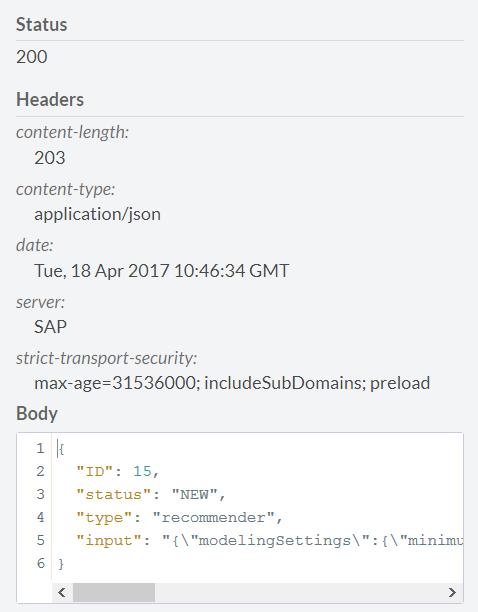
С помощью ссылки /api/analytics/recommendations/recommender/{jobID} можно посмотреть статус построенной модели, указав 15 в качестве ID. Для нашей модели статус следующий
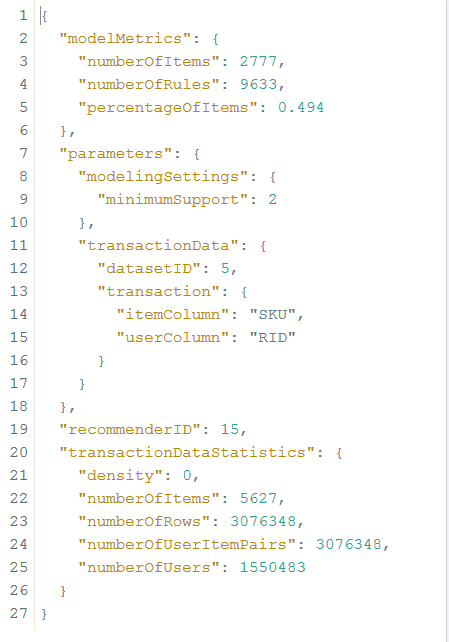
Видим, что количество SKU, встречающихся в одной корзине с другими составляет 2777 штук, на базе чего удалось найти 9633 правил рекомендаций. С помощью ссылки /api/analytics/recommendations можно протестировать полученную модель. Здесь необходимо ввести следующие параметры:
- itemList – SKU, уже лежащие в корзине
- maxItems – максимальное количество возвращаемых рекомендаций
- recommenderID – ID модели, построенной на предыдущем шаге
- userID – номер участника программы лояльности
Указывать можно либо оба параметра itemList и userID, либо только один из них. При указании только одного параметра система выдаст предупреждение, но позволит продолжить работу.
Проверим модель с SKU 5000267097428
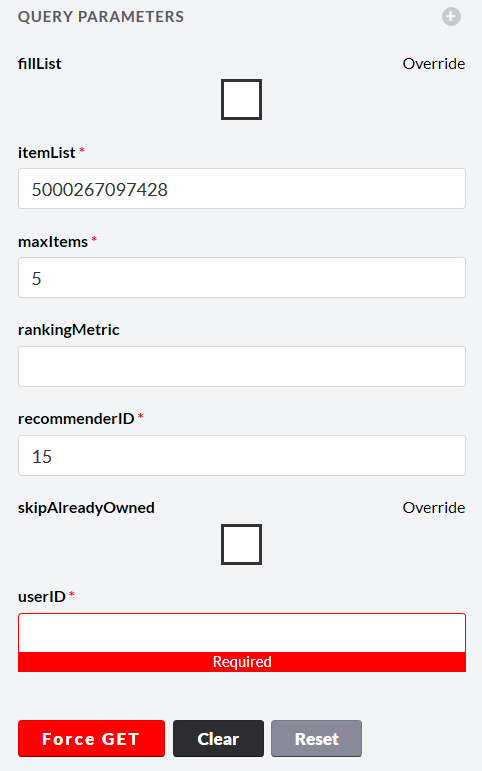
в ответ получаем
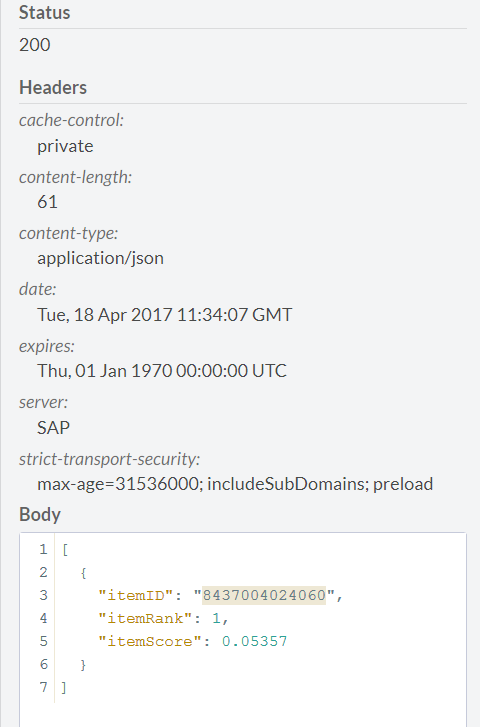
Посмотрим, что это такое
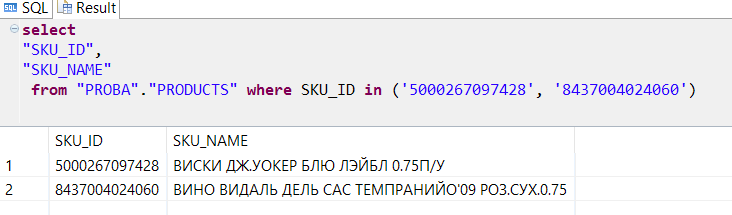
Таким образом, получаем, что при покупке виски неплохо бы порекомендовать покупателю еще и сухого вина.
Рекомендательная модель может также быть запущена в пакетном режиме, сгенерировав таблицу рекомендаций для всех пользователей программы лояльности. Для этого нажимаем закладку POST на ссылке /api/analytics/recommendations/batch

Затем указываем таблицу, в которую надо поместить наши рекомендации

И запускаем расчет. Сервис создает таблицу и для каждого пользователя рассчитывает рекомендованный товар, который может быть приобретен с большей вероятностью.
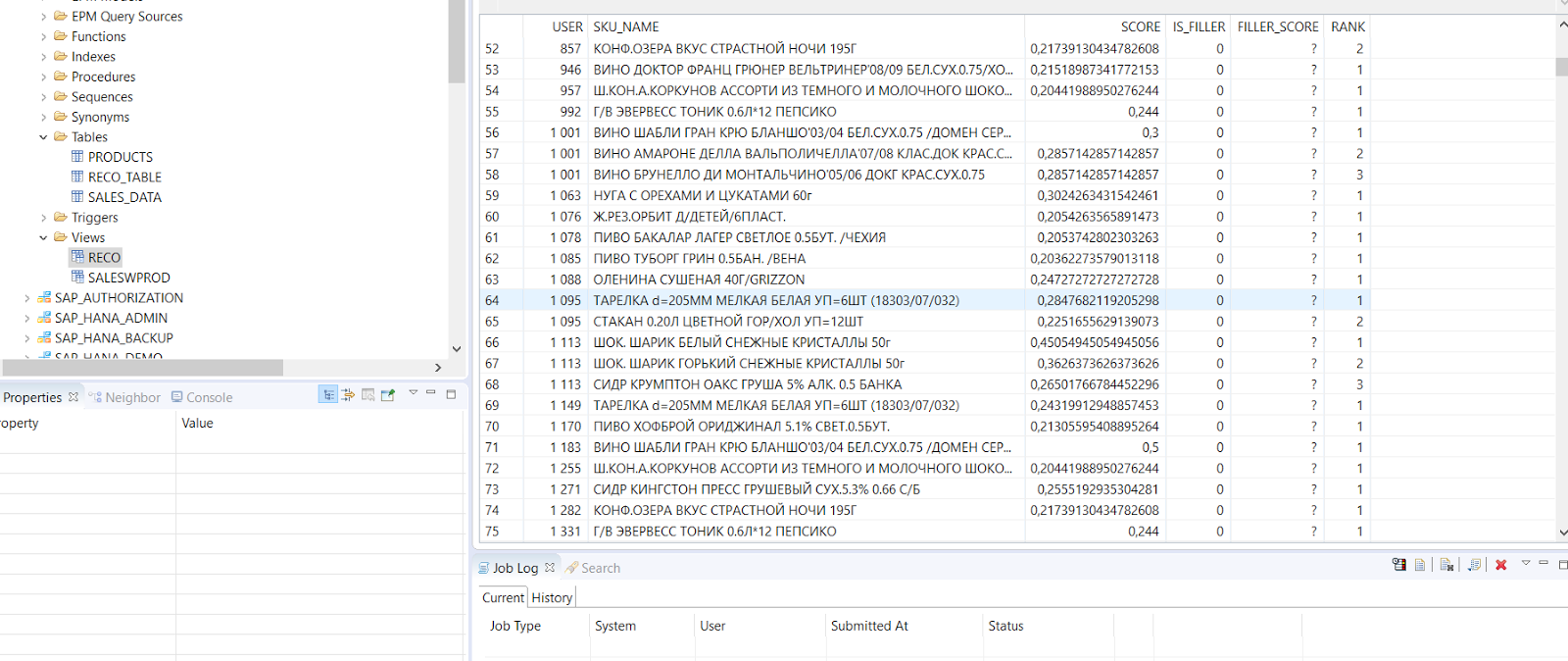
Таки образом, Predictive service позволяет очень быстро настроить и использовать некоторые наиболее часто употребляемые математические методы для построения предиктивных моделей, годных к применению в реальном бизнесе.
Поделиться с друзьями