
Предисловие от переводчика: Эта неделя ознаменовалась выходом Linkerd 1.0, что является отличным поводом рассказать не только об этом продукте, но и о самой категории такого программного обеспечения — service mesh (дословно переводится, как «сетка для сервисов»). Тем более, что авторы Linkerd как раз опубликовали соответствующую статью.
tl;dr: Service mesh — это выделенный слой инфраструктуры для обеспечения безопасного, быстрого и надёжного взаимодействия между сервисами. Если вы создаёте приложение для запуска в облаке (т.е. cloud native), вам нужен service mesh.
За прошедший год service mesh стал критически важным компонентом в облачном стеке. Компании с большим трафиком, такие как PayPal, Lyft, Ticketmaster и Credit Karma, уже добавили service mesh в свои приложения в production, а в январе Linkerd — Open Source-реализация service mesh для облачных приложений — стал официальным проектом фонда Cloud Native Computing Foundation (в этот же фонд недавно передали containerd и rkt, а ещё он известен как минимум по Kubernetes и Prometheus — прим. перев.). Но чем же является service mesh? И почему он стал внезапно необходим?
В этой статье я дам определение service mesh и прослежу его происхождение через изменения в архитектуре приложений, произошедшие за последнее десятилетие. Я отделю service mesh от связанных, но отличающихся концепций: шлюза API, edge proxy, корпоративной сервисной шины. Наконец, я опишу, где нужен service mesh, и что ожидать от адаптации этой концепции в мире cloud native.
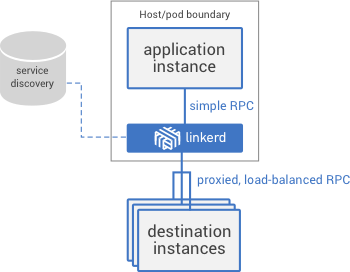
Service mesh — это выделенный слой инфраструктуры для обеспечения взаимодействия между сервисами. Он отвечает за надёжную доставку запросов через сложную топологию сервисов, составляющих современное приложение, созданное для работы в облаке. На практике service mesh обычно реализуется как массив легковесных сетевых прокси, которые деплоятся вместе с кодом приложения, без необходимости приложению знать об этом. (Но мы увидим, что у этой идеи есть разные вариации.)
Концепция service mesh как отдельного слоя связана с ростом приложений, создаваемых специально для облачных окружений. В такой облачной модели единое приложение может состоять из сотен сервисов, у каждого сервиса могут быть тысячи экземпляров, и у каждого экземпляра могут быть постоянно изменяющиеся состояния в зависимости от динамического планирования, осуществляемого инструментом для оркестровки вроде Kubernetes. В этом мире взаимодействие сервисов оказывается не просто очень сложным процессом, но и повсеместной, фундаментальной частью поведения исполняемой среды. Управление им очень важно для поддержания производительности и надёжности.
Да, service mesh — это сетевая модель, находящаяся на уровне абстракции выше TCP/IP. Подразумевается, что нижележащая сеть L3/L4 представлена и способна передавать байты от точки до точки. (Также подразумевается, что эта сеть, как и все другие аспекты окружения, не является надёжной; service mesh должен обеспечивать обработку сетевых отказов.)
В некоторых смыслах service mesh аналогичен TCP/IP. Как TCP-стек абстрагирует от механики надёжной передачи байтов между конечными сетевыми точками, так и service mesh абстрагирует от механики передачи запросов между сервисами. Как и TCP, service mesh не придаёт значения действующей нагрузке и тому, как она закодирована. У приложения есть задача высокого уровня («отправить что-то из A в B»), и работа service mesh, как и в случае TCP — решить эту задачу, обрабатывая любые встречающиеся по пути проблемы.
В отличие от TCP, у service mesh есть значительная цель помимо «просто заставить что-то работать» — предоставить унифицированную точку входа для всего приложения, обеспечив видимость и контроль его исполняемой среде. Прямая цель service mesh — вынести взаимодействие между сервисами из области невидимой, предполагаемой инфраструктуры, предложив ему роль полноценного участника экосистемы, где всё подлежит мониторингу, управлению, контролю.
Надёжная передача запросов в приложении для облачной инфраструктуры может быть очень сложной. И service mesh вроде Linkerd разбирается с этой сложностью с помощью набора действенных техник: предохранения от проблем в работе сети, балансировки нагрузки с учётом задержек, обнаружения сервисов (по модели согласованности в конечном счёте), повторных попыток и дедлайнов. Все эти возможности должны работать совместно, а взаимодействия между ними и среда, в которой они оперируют, могут быть весьма непростыми.
Например, когда делается запрос в сервисе через Linkerd, очень упрощённая последовательность событий выглядит следующим образом:
И это только упрощённая версия: Linkerd также может инициировать и завершать TLS, выполнять обновления протокола, динамически переключать трафик, выполнять переключение между дата-центрами.

Важно заметить, что эти возможности предназначены для обеспечения устойчивости и на уровне конечной точки, и на уровне приложения в целом. Распределённые системы больших масштабов вне зависимости от их архитектуры обладают одной определяющей характеристикой: существует много возможностей для того, чтобы малые, локальные падения превратились в катастрофические для всей системы. Поэтому service mesh должен быть спроектирован так, чтобы обеспечить защиту от подобных проблем, снижая нагрузку и быстро падая, когда нижележащие системы достигают своих лимитов.
Service mesh — это, конечно, не предоставление новой функциональности, а скорее сдвиг в том, куда это функциональность помещена. Веб-приложения всегда были вынуждены тянуть ношу взаимодействия между сервисами. Происхождение модели service mesh можно проследить в эволюции этих приложений на протяжении последних 15 лет.
Представьте типичную архитектуру веб-приложения средних размеров в 2000-х: это 3 уровня. В такой модели логика приложения, логика отдачи контента и логика хранилища — отдельные слои. Взаимодействие между этими уровнями является сложным, но ограничено в масштабах — ведь тут всего два транзитных участка. Нет никакой «сетки» (т.е. mesh) — только взаимодействие логики между транзитными участками, осуществляемое в коде каждого слоя.
Когда этот архитектурный подход достиг очень большого масштаба, он начал ломаться. Компании вроде Google, Netflix и Twitter столкнулись с необходимостью обслуживания большого трафика, реализация которой стала предшественником облачного (cloud native) подхода: слой приложения был разбит на множество сервисов (иногда называемых микросервисами), и уровни стали топологией. В этих системах обобщённый слой для взаимодействия быстро стал необходимостью, но обычно принимал форму библиотеки «толстого клиента»: Finagle у Twitter, Hystrix у Netflix, Stubby у Google.
Во многих смыслах эти библиотеки (Finagle, Stubby, Hystrix) стали первыми «сетками для сервисов». Пусть они были заточены для работы в своей специфичной среде и требовали использования конкретных языков и фреймворков, однако уже представляли собой выделенную инфраструктуру для управления взаимодействием между сервисами и (в случае Open Source-библиотек Finagle и Hystrix) применялись не только в компаниях, которые их разработали.
Последовало быстрое движение навстречу современным приложениям, создаваемых для запуска в облаках. Модель cloud native сочетает микросервисный подход из множества маленьких сервисов с двумя дополнительными факторами:
Эти три компонента позволяют приложениям адаптироваться естественным образом к масштабированию под нагрузкой и обрабатывать присутствующие всегда частичные сбои в облачном окружении. Но с сотнями сервисов и тысячами экземпляров, да ещё и слоем оркестровки для планирования запуска экземпляров, путь единого запроса, следующего по топологии сервисов, может быть невероятно сложным, и, поскольку контейнеры упростили возможность создания сервисов на любых различных языках, подход с библиотекой перестал быть практичным.
Комбинация сложности и критической важности привела к необходимости выделенного слоя для взаимодействия между сервисами, отделённого от кода приложения и способного справляться с очень динамичной природой нижележащего окружения. Этим слоем и является service mesh.
Пока идёт быстрый рост адаптации service mesh в облачной экосистеме, обширную и захватывающую дорожную карту [дальнейшего развития этой концепции и её реализаций — прим. перев.] ещё только предстоит открыть. Требования, предъявляемые к вычислениям без серверов (например, Amazon Lambda), отлично укладываются в модель service mesh по наименованию и связыванию [компонентов], что формирует естественное расширение его применения в облачной экосистеме. Роли удостоверения служб и политик доступа всё ещё очень молоды в облачных окружениях, и здесь service mesh хорошо подойдёт, чтобы стать фундаментальной составляющей такой потребности. Наконец, service mesh, как и TCP/IP раньше, продолжит своё проникновение в нижележащую инфраструктуру. Как Linkerd эволюционировал из систем вроде Finagle, продолжит свою эволюцию и текущая реализация service mesh как отдельного прокси в пользовательском пространстве, которая может быть добавлена в облачный стек.
Service mesh — критически важный компонент стека категории cloud native. Linkerd, появившись чуть более 1 года назад, является частью Cloud Native Computing Foundation и получил растущее сообщество контрибьюторов и пользователей. Его пользователи разнообразны: от стартапов вроде Monzo, разрушающих банковскую индустрию Великобритании [это полностью цифровой банк, предлагающий разработчикам API для доступа к финансовым данным, — прим. перев.], до интернет-компаний больших масштабов вроде PayPal, Ticketmaster и Credit Karma, а также компаний с бизнес-историей в сотни лет вроде Houghton Mifflin Harcourt.
Open Source-сообщество пользователей и контрибьюторов Linkerd ежедневно демонстрируют ценность модели service mesh. Мы преданы созданию отличного продукта и продолжающемуся росту нашего сообщества.

P.S. Автор статьи — William Morgan, один из создателей Linkerd в 2015 году, учредитель и CEO в Buoyant Inc (компания-разработчик, передавшая Linkerd в CNCF).
tl;dr: Service mesh — это выделенный слой инфраструктуры для обеспечения безопасного, быстрого и надёжного взаимодействия между сервисами. Если вы создаёте приложение для запуска в облаке (т.е. cloud native), вам нужен service mesh.
За прошедший год service mesh стал критически важным компонентом в облачном стеке. Компании с большим трафиком, такие как PayPal, Lyft, Ticketmaster и Credit Karma, уже добавили service mesh в свои приложения в production, а в январе Linkerd — Open Source-реализация service mesh для облачных приложений — стал официальным проектом фонда Cloud Native Computing Foundation (в этот же фонд недавно передали containerd и rkt, а ещё он известен как минимум по Kubernetes и Prometheus — прим. перев.). Но чем же является service mesh? И почему он стал внезапно необходим?
В этой статье я дам определение service mesh и прослежу его происхождение через изменения в архитектуре приложений, произошедшие за последнее десятилетие. Я отделю service mesh от связанных, но отличающихся концепций: шлюза API, edge proxy, корпоративной сервисной шины. Наконец, я опишу, где нужен service mesh, и что ожидать от адаптации этой концепции в мире cloud native.
Что такое service mesh?
Service mesh — это выделенный слой инфраструктуры для обеспечения взаимодействия между сервисами. Он отвечает за надёжную доставку запросов через сложную топологию сервисов, составляющих современное приложение, созданное для работы в облаке. На практике service mesh обычно реализуется как массив легковесных сетевых прокси, которые деплоятся вместе с кодом приложения, без необходимости приложению знать об этом. (Но мы увидим, что у этой идеи есть разные вариации.)
Концепция service mesh как отдельного слоя связана с ростом приложений, создаваемых специально для облачных окружений. В такой облачной модели единое приложение может состоять из сотен сервисов, у каждого сервиса могут быть тысячи экземпляров, и у каждого экземпляра могут быть постоянно изменяющиеся состояния в зависимости от динамического планирования, осуществляемого инструментом для оркестровки вроде Kubernetes. В этом мире взаимодействие сервисов оказывается не просто очень сложным процессом, но и повсеместной, фундаментальной частью поведения исполняемой среды. Управление им очень важно для поддержания производительности и надёжности.
Является ли service mesh сетевой моделью?
Да, service mesh — это сетевая модель, находящаяся на уровне абстракции выше TCP/IP. Подразумевается, что нижележащая сеть L3/L4 представлена и способна передавать байты от точки до точки. (Также подразумевается, что эта сеть, как и все другие аспекты окружения, не является надёжной; service mesh должен обеспечивать обработку сетевых отказов.)
В некоторых смыслах service mesh аналогичен TCP/IP. Как TCP-стек абстрагирует от механики надёжной передачи байтов между конечными сетевыми точками, так и service mesh абстрагирует от механики передачи запросов между сервисами. Как и TCP, service mesh не придаёт значения действующей нагрузке и тому, как она закодирована. У приложения есть задача высокого уровня («отправить что-то из A в B»), и работа service mesh, как и в случае TCP — решить эту задачу, обрабатывая любые встречающиеся по пути проблемы.
В отличие от TCP, у service mesh есть значительная цель помимо «просто заставить что-то работать» — предоставить унифицированную точку входа для всего приложения, обеспечив видимость и контроль его исполняемой среде. Прямая цель service mesh — вынести взаимодействие между сервисами из области невидимой, предполагаемой инфраструктуры, предложив ему роль полноценного участника экосистемы, где всё подлежит мониторингу, управлению, контролю.
Что же service mesh делает?
Надёжная передача запросов в приложении для облачной инфраструктуры может быть очень сложной. И service mesh вроде Linkerd разбирается с этой сложностью с помощью набора действенных техник: предохранения от проблем в работе сети, балансировки нагрузки с учётом задержек, обнаружения сервисов (по модели согласованности в конечном счёте), повторных попыток и дедлайнов. Все эти возможности должны работать совместно, а взаимодействия между ними и среда, в которой они оперируют, могут быть весьма непростыми.
Например, когда делается запрос в сервисе через Linkerd, очень упрощённая последовательность событий выглядит следующим образом:
- Linkerd применяет динамические правила маршрутизации, определяя, к какому сервису предназначен запрос. Запрос должен быть передан сервису в production или staging? Сервису в локальном дата-центре или в облаке? Самой последней версии сервиса, которая была протестирована, или более старой версии, проверенной в production? Все эти правила маршрутизации конфигурируются динамически, могут применяться глобально или для выбранных срезов трафика.
- Найдя нужного получателя, Linkerd запрашивает подходящий пул экземпляров у службы обнаружения соответствующей конечной точки (их может быть несколько). Если эта информация расходится с тем, что Linkerd видит на практике, он принимает решение, какому источнику информации доверять.
- Linkerd выбирает экземпляр, который скорее всего вернёт быстрый ответ, основываясь на ряде факторов (включая задержку, зафиксированную для недавних запросов).
- Linkerd пытается отправить запрос экземпляру, записывая результат операции (задержку и тип ответа).
- Если экземпляр упал, не отвечает или не может обработать запрос, Linkerd пробует этот запрос на другом экземпляре (только в том случае, если знает, что запрос является идемпотентным).
- Если экземпляр постоянно возвращает ошибки, Linkerd убирает его из пула балансировки нагрузки и будет периодически проверять его в дальнейшем (экземпляр может испытывать кратковременный сбой).
- Если дедлайн для запроса достигнут, Linkerd превентивно возвращает ошибку запроса, а не добавляет нагрузку с повторными попытками его выполнения.
- Linkerd учитывает каждый аспект описанного выше поведения в виде метрик и распределённого отслеживания — все эти данные отправляются в централизованную систему метрик.
И это только упрощённая версия: Linkerd также может инициировать и завершать TLS, выполнять обновления протокола, динамически переключать трафик, выполнять переключение между дата-центрами.
Важно заметить, что эти возможности предназначены для обеспечения устойчивости и на уровне конечной точки, и на уровне приложения в целом. Распределённые системы больших масштабов вне зависимости от их архитектуры обладают одной определяющей характеристикой: существует много возможностей для того, чтобы малые, локальные падения превратились в катастрофические для всей системы. Поэтому service mesh должен быть спроектирован так, чтобы обеспечить защиту от подобных проблем, снижая нагрузку и быстро падая, когда нижележащие системы достигают своих лимитов.
Почему service mesh нужен?
Service mesh — это, конечно, не предоставление новой функциональности, а скорее сдвиг в том, куда это функциональность помещена. Веб-приложения всегда были вынуждены тянуть ношу взаимодействия между сервисами. Происхождение модели service mesh можно проследить в эволюции этих приложений на протяжении последних 15 лет.
Представьте типичную архитектуру веб-приложения средних размеров в 2000-х: это 3 уровня. В такой модели логика приложения, логика отдачи контента и логика хранилища — отдельные слои. Взаимодействие между этими уровнями является сложным, но ограничено в масштабах — ведь тут всего два транзитных участка. Нет никакой «сетки» (т.е. mesh) — только взаимодействие логики между транзитными участками, осуществляемое в коде каждого слоя.
Когда этот архитектурный подход достиг очень большого масштаба, он начал ломаться. Компании вроде Google, Netflix и Twitter столкнулись с необходимостью обслуживания большого трафика, реализация которой стала предшественником облачного (cloud native) подхода: слой приложения был разбит на множество сервисов (иногда называемых микросервисами), и уровни стали топологией. В этих системах обобщённый слой для взаимодействия быстро стал необходимостью, но обычно принимал форму библиотеки «толстого клиента»: Finagle у Twitter, Hystrix у Netflix, Stubby у Google.
Во многих смыслах эти библиотеки (Finagle, Stubby, Hystrix) стали первыми «сетками для сервисов». Пусть они были заточены для работы в своей специфичной среде и требовали использования конкретных языков и фреймворков, однако уже представляли собой выделенную инфраструктуру для управления взаимодействием между сервисами и (в случае Open Source-библиотек Finagle и Hystrix) применялись не только в компаниях, которые их разработали.
Последовало быстрое движение навстречу современным приложениям, создаваемых для запуска в облаках. Модель cloud native сочетает микросервисный подход из множества маленьких сервисов с двумя дополнительными факторами:
- контейнеры (например, Docker), обеспечивающие изоляцию ресурсов и управление зависимостями;
- слой оркестровки (например, Kubernetes), абстрагирующийся от аппаратного обеспечения и предлагающий единый пул.
Эти три компонента позволяют приложениям адаптироваться естественным образом к масштабированию под нагрузкой и обрабатывать присутствующие всегда частичные сбои в облачном окружении. Но с сотнями сервисов и тысячами экземпляров, да ещё и слоем оркестровки для планирования запуска экземпляров, путь единого запроса, следующего по топологии сервисов, может быть невероятно сложным, и, поскольку контейнеры упростили возможность создания сервисов на любых различных языках, подход с библиотекой перестал быть практичным.
Комбинация сложности и критической важности привела к необходимости выделенного слоя для взаимодействия между сервисами, отделённого от кода приложения и способного справляться с очень динамичной природой нижележащего окружения. Этим слоем и является service mesh.
Будущее service mesh
Пока идёт быстрый рост адаптации service mesh в облачной экосистеме, обширную и захватывающую дорожную карту [дальнейшего развития этой концепции и её реализаций — прим. перев.] ещё только предстоит открыть. Требования, предъявляемые к вычислениям без серверов (например, Amazon Lambda), отлично укладываются в модель service mesh по наименованию и связыванию [компонентов], что формирует естественное расширение его применения в облачной экосистеме. Роли удостоверения служб и политик доступа всё ещё очень молоды в облачных окружениях, и здесь service mesh хорошо подойдёт, чтобы стать фундаментальной составляющей такой потребности. Наконец, service mesh, как и TCP/IP раньше, продолжит своё проникновение в нижележащую инфраструктуру. Как Linkerd эволюционировал из систем вроде Finagle, продолжит свою эволюцию и текущая реализация service mesh как отдельного прокси в пользовательском пространстве, которая может быть добавлена в облачный стек.
Вывод
Service mesh — критически важный компонент стека категории cloud native. Linkerd, появившись чуть более 1 года назад, является частью Cloud Native Computing Foundation и получил растущее сообщество контрибьюторов и пользователей. Его пользователи разнообразны: от стартапов вроде Monzo, разрушающих банковскую индустрию Великобритании [это полностью цифровой банк, предлагающий разработчикам API для доступа к финансовым данным, — прим. перев.], до интернет-компаний больших масштабов вроде PayPal, Ticketmaster и Credit Karma, а также компаний с бизнес-историей в сотни лет вроде Houghton Mifflin Harcourt.
Open Source-сообщество пользователей и контрибьюторов Linkerd ежедневно демонстрируют ценность модели service mesh. Мы преданы созданию отличного продукта и продолжающемуся росту нашего сообщества.
P.S. Автор статьи — William Morgan, один из создателей Linkerd в 2015 году, учредитель и CEO в Buoyant Inc (компания-разработчик, передавшая Linkerd в CNCF).
Поделиться с друзьями
shuron
Интересная тема. На вскидку не нагуглил ничего о том можно ли ейто как-то привязать к AWS ECS. Было бы помоему очень полезно ибо из коробки у ECS куча недоделок в этом направлении