
В этой статье я расскажу, как использовать описанные в прошлой статье инструменты для исследования игры Felix The Cat для NES. Моя первоначальная цель была, как обычно, разобрать формат уровней игры и добавить её в свой универсальный редактор уровней CadEditor, однако в ходе изучения игры обнаружилось, что описание уровней сжато (это редкость для NES-игр!), поэтому я также разобрал формат компрессии данных, и написал компрессор, позволяющий сжимать отредактированные уровни так же, как это делали разработчики игры.
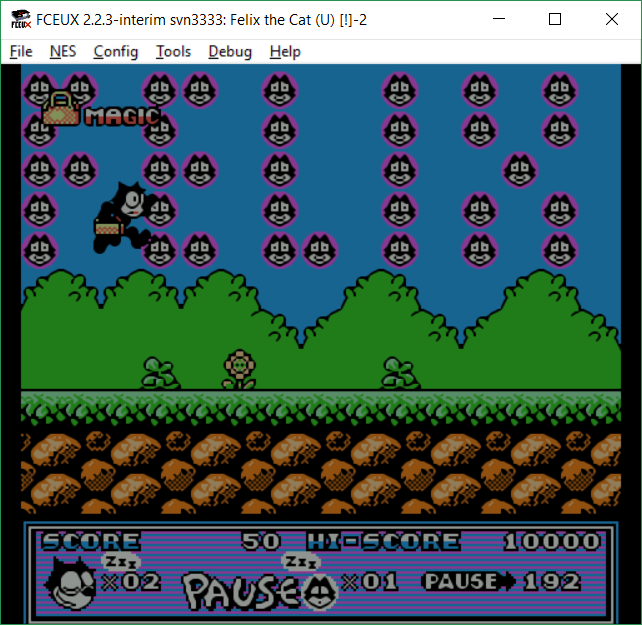
Первым делом проверяем, какие блоки используются в игре. Для этого можно воспользоваться утилитой автоматического поиска блоков NesBlockFinder. Всё, что необходимо сделать – скормить ей дамп видеопамяти загруженного уровня (детальная инструкция, как это сделать, подробнее останавливаться в статье не буду, чтобы быстрее дойти до основной темы – разбора компрессии). NesBlockFinder выдаёт такие результаты:

Как видим, программа обнаружила в ROM-файле блоки размером 2x2, описанные отдельными 4 массивами по 128 байт, и предположила адрес начала первого массива 0x17D2D.
Теперь можно изменить байты, составляющие один из блоков целиком, в эмуляторе, чтобы убедиться в изменении блоков на экране:

Наглядно видно, что зеленый блок внутри кустов изменился.
Следующий шаг – обозначить начало и конец массивов описания блоков. Для этого можно просто поменять байты перед обнаруженным блоком, а также учесть то, что в большинстве игр первый блок состоит из одних нулей (для этого нет никакой особенной причины, однако это встречается почти во всех играх). Так обнаруживается адрес начала массивов описания блоков — 0x17D2A (и соотвественно, адреса 0x17DAA, 0x17E2A, 0x17EAA для массивов следующих четвертей блоков). Конец массива вычисляется также легко – размер каждой из частей известен (128 байт), так что конец последнего массива будет расположен по адресу 0x17F2A.
Графика на NES устроена так, что кроме описания номеров тайлов блоков разработчикам необходимо хранить атрибуты блоков (индексы цветов палитры), поэтому следует всегда внимательно изучать данные перед массивом блоков и сразу за ним – чаще всего атрибуты блоков будут описаны там. Это верно и для нашей Felix The Cat, за массивом описания блоков лежит массив из 128 байт, в котором для каждого блока указаны его атрибуты палитры (в старших двух битах), и физические свойства (в младших шести битах). Это продемонстрировано на скриншоте:

На нём выделена область атрибутов и изменены старшие биты для того, чтобы поменять цвет тестового блока.
Используя полученные адреса, можно взять дамп банка видеопамяти и палитры (подробно, как это сделать в статье, раздел «Шаг 6. Нахождение адреса банка видеопамяти и палитры уровня»), чтобы построить все блоки, используемые на уровне.
Для отрисовки всех блоков, я использовал язык Python и Jupyter-ноутбуки, а также C#-модули построения NES-графики из редактора CadEditor (для склейки Python и C# я взял модуль clr, который позволяет загружать .NET-сборки из Python и вызывать код из них).
Основной код построения блоков выглядит просто:
Получаем вот такой результат:

> Откомментированный ноутбук
Теперь, когда у нас есть блоки, необходимо узнать, как из них собирается уровень. Для этого воспользуемся скриптом NesAutoСorrupter. По работе со старой версией скрипта я писал целую статью на хабре, с тех пор я значительно улучшил его (теперь он работает в десятки раз быстрее и требует всего лишь двух сохранений игры, без необходимости ручных расчётов), но подробную документацию по новой версии пока не подготовил, поэтому ограничусь кратким описанием работы с ним.
Необходимо выполнить скрипт autocorrupter4.lua в эмуляторе FCEUX, подготовить 2 файла сохранения (непосредственно перед загрузкой уровня и сразу после загрузки) и просто нажать клавишу «E» для начала работы. Скрипт получает все необходимые данные из этих файлов и поочерёдно меняет каждый байт, который был использован между двумя сохранениями, а затем проверяет, изменилось ли изображение на экране. Изменённые версии скрипт сохраняет в файлы, в имени которых указан адрес изменённого байта.
Рассмотрим результат работы скрипта для Felix The Cat. Картинки изменения байт с адресами 0x1B940, 0x1B942, 0x1B944 и т.д с шагом 2, я собрал для наглядности в gif-картинку:
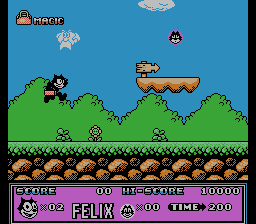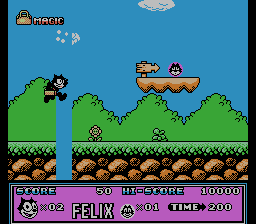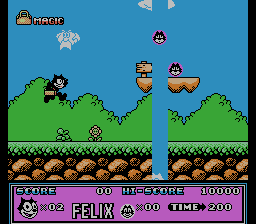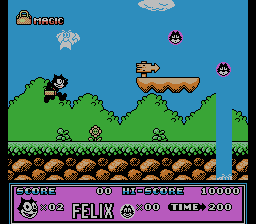
Из неё следует вывод, что уровень описывается вертикальными линиями, а шаг в 2 байта свидетельствует о том, что по этим адресам идут не просто индексы, а адреса (поинтеры) на линии.
Также представляет интерес адрес 0x1A904, изменение которого приводит к изменению ровно одного блока во второй линии, следовательно, это зона описания массива самих линий:

Теперь, тыкая на байты в окрестностях этих адресов и анализируя результат, приходим к таким интересным выводам о строении уровня:
Для примера рассмотрим декомпрессию первой линии.
Описание сжатой линии:

Таким образом можно уже написать расжатие всех линии:
И отобразить их в редакторе уровней CadEditor:

Мы получили возможность распаковать уровень и отредактировать его, но для вставки обратно в игру необходим также обратный алгоритм, который будет сжимать данные, причём будет делать это не хуже, чем компрессор от разработчиков, иначе они не поместятся в отведённое место. Можно, конечно, модифицировать поинтеры на данные так, чтобы разместить их в отдельном банке и вообще не использовать сжатие, но это не всегда возможно, да и соревнование за качество компрессии с разработчиками игры представляет собой слишком интересную задачу, чтобы проходить мимо неё – если для расшифровки декомпрессора можно использовать готовый словарь, полученный неизвестным образом, то для компрессора необходимо научиться составлять словарь сжатия самому.
Первая идея составления словаря, которая пришла мне в голову – просто записать список всех найденных RLE-цепочек и отсортировать его по ценности замены. Ценность замены подсчитать довольно просто: надо вычислить, сколько байт сэкономится на одной замене (длина цепочки минус 1 байт) и умножить на количество возможных замен.
Такой алгоритм дал результат в 3879 байт против 3740 байт в оригинале (проигрыш на ~2%). Мне показалось этого недостаточно, и я стал размышлять, как у разработчиков получилось лучше.
Второй идеей было после каждой замены наиболее выгодной цепочки сразу вставлять на её место слово из словаря. Результат получился 4695 байт, намного хуже того, который был. Я понял, что нельзя заменять цепочку до полного заполнения словаря – возможно, в дальнейшем найдётся более выгодная в конкретном случае (но менее ценная с точки зрения всего архива) замена.
Таким образом, необходимо скрестить оба алгоритма – держать в памяти полный словарь, но при реальной замене обновлять ценность всех остальных замен и снова сортировать его по обновлённой ценности (если мы заменили, например, цепочку из 16-ти нулей на слово в словаре, то все более короткие цепочки из нулей встретятся теперь на 1 раз меньше).
Однако такая реализация показалась мне слишком сложной и вместо этого я просто сделал алгоритм итеративным – на каждом шаге составляется полный возможный словарь, и затем данные сжимаются им с пометками, какое слово сколько раз реально использовалось. После этого словарь сортируется по реальной, а не предполагаемой ценности, и из него составляется запретный словарь из слов, которые ни разу не использовались (или их использование принесло наименьшую ценность). Дальше цикл повторяется, но так, чтобы в потенциальный словарь уже не попадали слова из запретного словаря. Операцию улучшения можно повторять до тех пор, пока запретный словарь не перестанет пополнятся. Далее останется лишь взять из реального словаря максимально допустимое количество значений (128 слов) – это и будет наилучший словарь для сжатия. Таким образом, наконец, получилось «догнать» разработчиков, и получить те же самые 3740 сжатых данных, как и у них. С остальными уровнями ситуация повторилась – результаты пережатых данных полностью совпали с оригинальными, хотя мой словарь несколько отличался.
Итоговая функция построения словаря (несколько запутанная оттого, что я экспериментировал с разными параметрами и динамической ценностью замены). В параметр forbiddenArr передаётся словарь «запретных» значений.
Немного обидно, что после различных экспериментов и улучшений алгоритма я наткнулся на оптимальный способ, который использовали и разработчики, но, по крайней мере, мой компрессор работал не хуже, чем у них. Для всех уровней, кроме второго, результаты пережатия получились одинаковыми, однако со вторым обнаружился интересный момент – декомпрессор ломался на нём. Оказалось, что авторы игры для уровня внутри пирамиды (2-2 и 2-3), использовали для сжатия мозаики на стенах пирамид дополнительный вид компрессии, который заключается в использовании «базовых линий».
Последние 4 значения блоков 0xFC-0xFF используются для кодирования особых команд.
В этом случае в начале линии может использоваться команда из двух байт (номер_базовой_линии, кол-во блоков из базовой линии). На уровне используется 4 базовые линии (их номера кодируются от 0xFC до 0xFF). Первые несколько блоков берутся из этой линии, а затем нижняя часть дорисовывается обычным способом.
Пример таких начал линий на скриншоте:

На нём выделены рамками повторяющиеся базовые линии. Этот способ сжатия работает и на других уровнях, однако для них не описаны базовые линии (общие верхушки линий), поэтому разработчики не использовали его, но он позволил бы сэкономить ещё несколько байт, не дающих практической пользы, но символичных в мысленном соревновании с разработчиками игры.
Итоговый комментированный ноутбук с тестами декомпрессии и компрессии для всех уровней, который можно использовать для непосредственной компрессии данных и вставки в ROM-файл.
Таким образом, использование сжатия с помощью RLE-словаря, а также сохранение индексов повторяющихся линий, позволяют сжимать описания уровней размером в 18 килобайт (256 x 3 x 24 блоков) до 4-5 килобайт.
Поиск блоков
Первым делом проверяем, какие блоки используются в игре. Для этого можно воспользоваться утилитой автоматического поиска блоков NesBlockFinder. Всё, что необходимо сделать – скормить ей дамп видеопамяти загруженного уровня (детальная инструкция, как это сделать, подробнее останавливаться в статье не буду, чтобы быстрее дойти до основной темы – разбора компрессии). NesBlockFinder выдаёт такие результаты:
Как видим, программа обнаружила в ROM-файле блоки размером 2x2, описанные отдельными 4 массивами по 128 байт, и предположила адрес начала первого массива 0x17D2D.
Теперь можно изменить байты, составляющие один из блоков целиком, в эмуляторе, чтобы убедиться в изменении блоков на экране:
Наглядно видно, что зеленый блок внутри кустов изменился.
Следующий шаг – обозначить начало и конец массивов описания блоков. Для этого можно просто поменять байты перед обнаруженным блоком, а также учесть то, что в большинстве игр первый блок состоит из одних нулей (для этого нет никакой особенной причины, однако это встречается почти во всех играх). Так обнаруживается адрес начала массивов описания блоков — 0x17D2A (и соотвественно, адреса 0x17DAA, 0x17E2A, 0x17EAA для массивов следующих четвертей блоков). Конец массива вычисляется также легко – размер каждой из частей известен (128 байт), так что конец последнего массива будет расположен по адресу 0x17F2A.
Графика на NES устроена так, что кроме описания номеров тайлов блоков разработчикам необходимо хранить атрибуты блоков (индексы цветов палитры), поэтому следует всегда внимательно изучать данные перед массивом блоков и сразу за ним – чаще всего атрибуты блоков будут описаны там. Это верно и для нашей Felix The Cat, за массивом описания блоков лежит массив из 128 байт, в котором для каждого блока указаны его атрибуты палитры (в старших двух битах), и физические свойства (в младших шести битах). Это продемонстрировано на скриншоте:
На нём выделена область атрибутов и изменены старшие биты для того, чтобы поменять цвет тестового блока.
Используя полученные адреса, можно взять дамп банка видеопамяти и палитры (подробно, как это сделать в статье, раздел «Шаг 6. Нахождение адреса банка видеопамяти и палитры уровня»), чтобы построить все блоки, используемые на уровне.
Рендер блоков
Для отрисовки всех блоков, я использовал язык Python и Jupyter-ноутбуки, а также C#-модули построения NES-графики из редактора CadEditor (для склейки Python и C# я взял модуль clr, который позволяет загружать .NET-сборки из Python и вызывать код из них).
Основной код построения блоков выглядит просто:
#Функция CadEditor для загрузки конфига блоков из файла
Globals.loadData(romName, dumpName, configName)
#Создаём экземляр плагина для отрисовки NES-графики
video = Video()
#clr не понимает перегруженных функций, поэтому явно задаём прототип функции, которую хотим вызвать
#Bitmap[] makeObjects(byte videoPageId, byte tilesId, byte palId, float scale, MapViewType drawType, int constantSubpal = -1);
makeObjects = video.makeObjects.Overloads[System.Byte, System.Byte, System.Byte, System.Single, MapViewType, System.Int32]
bb = makeObjects(0x90, 0, 0, 2.0, MapViewType.Tiles, -1)
#Немного магии для конвертации Python-массивов в C#-массив
blocks = System.Array[System.Drawing.Image](bb)
fn = picPath+"blocks0.png"
#Склейка блоков в прямоугольное изображение
UtilsGDI.GlueImages(blocks, 16, 8).Save(fn)
#Функция IPython для отображения сохранённой картинки в ноутбуке
display(Image(filename=fn))
Получаем вот такой результат:
> Откомментированный ноутбук
Формат описания уровня
Теперь, когда у нас есть блоки, необходимо узнать, как из них собирается уровень. Для этого воспользуемся скриптом NesAutoСorrupter. По работе со старой версией скрипта я писал целую статью на хабре, с тех пор я значительно улучшил его (теперь он работает в десятки раз быстрее и требует всего лишь двух сохранений игры, без необходимости ручных расчётов), но подробную документацию по новой версии пока не подготовил, поэтому ограничусь кратким описанием работы с ним.
Необходимо выполнить скрипт autocorrupter4.lua в эмуляторе FCEUX, подготовить 2 файла сохранения (непосредственно перед загрузкой уровня и сразу после загрузки) и просто нажать клавишу «E» для начала работы. Скрипт получает все необходимые данные из этих файлов и поочерёдно меняет каждый байт, который был использован между двумя сохранениями, а затем проверяет, изменилось ли изображение на экране. Изменённые версии скрипт сохраняет в файлы, в имени которых указан адрес изменённого байта.
Рассмотрим результат работы скрипта для Felix The Cat. Картинки изменения байт с адресами 0x1B940, 0x1B942, 0x1B944 и т.д с шагом 2, я собрал для наглядности в gif-картинку:
Из неё следует вывод, что уровень описывается вертикальными линиями, а шаг в 2 байта свидетельствует о том, что по этим адресам идут не просто индексы, а адреса (поинтеры) на линии.
Также представляет интерес адрес 0x1A904, изменение которого приводит к изменению ровно одного блока во второй линии, следовательно, это зона описания массива самих линий:
Теперь, тыкая на байты в окрестностях этих адресов и анализируя результат, приходим к таким интересным выводам о строении уровня:
- По адресу 0x1B940 расположен большой массив поинтеров на линии, из которых строятся все три стартовых уровня (1-1, 1-2, 1-3). Использование указателей, а не индексов позволяет описывать более 256 линий (а именно 256x3 = 768 линий). Чтобы перейти от поинтера (указатель в адресном пространстве CPU NES) к абсолютному адресу в ROM, необходимо прибавить к поинтеру адрес начала банка, в котором он лежит (0x10010 для первого уровня, другие уровни используют другие банки).
- Поинтер на первый столбец = 0xA8ED, в переводе на абсолютный адрес – 0x1A8FD, с этого адреса и далее подряд идёт описание линий, высота каждой линии 24 байта (это константа для всех уровней игры).
- Исследуем описание одной из линии и замечаем, что если номер блока в ней от 0x00 до 0x80, то в итоговую линию вставляется непосредственно блок с соотвествующем номером; если же номер больше 0x80, то вставляется целая полоска из разного количества каких-нибудь блоков. Отсюда следует интересный вывод – игра использует RLE-сжатие для описания цепочек идущих подряд одинаковых блоков, причём эти цепочки собраны в словарь, и кодируются индексами в этом словаре!
- Адрес RLE-словаря для первого уровня: 0x1B799. По этому адресу записаны пары байт (количество повторяющихся блоков, номер блока-повтора).
Для примера рассмотрим декомпрессию первой линии.
Описание сжатой линии:
[81 30 82 07 4C 83]И словарь:
[(24, 0x0) (17, 0x0) (2, 0x3) (2, 0x78)]Первый байт 81 – кодирует первое значение из словаря «взять 17 раз блок 0», далее следует блок 30, затем байт 82, который означает взятие второго значения из словаря – «взять 2 раза блок 3», далее следуют блоки 07 и 4С, и напоследок, значение 83 – третье слово из словаря «взять 2 раза блок 78». На выходе получается линия:
[00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 30 03 03 07 4C 78 78]Вот визуальное пояснение к этой разжатой линии:
Таким образом можно уже написать расжатие всех линии:
def decompressLine(d, addr, LINE_HEIGHT = 24):
ans = []
while len(ans) < LINE_HEIGHT:
v = d[addr]
#обычный тайл
if v < 0x80:
ans.append(v)
#значение из RLE-словаря
else:
cv = v & 0x7F
repeatCount, repeatTile = compressedArr[cv]
ans.extend([repeatTile]*repeatCount)
addr += 1
return ans
И отобразить их в редакторе уровней CadEditor:
Компрессор
Мы получили возможность распаковать уровень и отредактировать его, но для вставки обратно в игру необходим также обратный алгоритм, который будет сжимать данные, причём будет делать это не хуже, чем компрессор от разработчиков, иначе они не поместятся в отведённое место. Можно, конечно, модифицировать поинтеры на данные так, чтобы разместить их в отдельном банке и вообще не использовать сжатие, но это не всегда возможно, да и соревнование за качество компрессии с разработчиками игры представляет собой слишком интересную задачу, чтобы проходить мимо неё – если для расшифровки декомпрессора можно использовать готовый словарь, полученный неизвестным образом, то для компрессора необходимо научиться составлять словарь сжатия самому.
Первая идея составления словаря, которая пришла мне в голову – просто записать список всех найденных RLE-цепочек и отсортировать его по ценности замены. Ценность замены подсчитать довольно просто: надо вычислить, сколько байт сэкономится на одной замене (длина цепочки минус 1 байт) и умножить на количество возможных замен.
Такой алгоритм дал результат в 3879 байт против 3740 байт в оригинале (проигрыш на ~2%). Мне показалось этого недостаточно, и я стал размышлять, как у разработчиков получилось лучше.
Второй идеей было после каждой замены наиболее выгодной цепочки сразу вставлять на её место слово из словаря. Результат получился 4695 байт, намного хуже того, который был. Я понял, что нельзя заменять цепочку до полного заполнения словаря – возможно, в дальнейшем найдётся более выгодная в конкретном случае (но менее ценная с точки зрения всего архива) замена.
Таким образом, необходимо скрестить оба алгоритма – держать в памяти полный словарь, но при реальной замене обновлять ценность всех остальных замен и снова сортировать его по обновлённой ценности (если мы заменили, например, цепочку из 16-ти нулей на слово в словаре, то все более короткие цепочки из нулей встретятся теперь на 1 раз меньше).
Однако такая реализация показалась мне слишком сложной и вместо этого я просто сделал алгоритм итеративным – на каждом шаге составляется полный возможный словарь, и затем данные сжимаются им с пометками, какое слово сколько раз реально использовалось. После этого словарь сортируется по реальной, а не предполагаемой ценности, и из него составляется запретный словарь из слов, которые ни разу не использовались (или их использование принесло наименьшую ценность). Дальше цикл повторяется, но так, чтобы в потенциальный словарь уже не попадали слова из запретного словаря. Операцию улучшения можно повторять до тех пор, пока запретный словарь не перестанет пополнятся. Далее останется лишь взять из реального словаря максимально допустимое количество значений (128 слов) – это и будет наилучший словарь для сжатия. Таким образом, наконец, получилось «догнать» разработчиков, и получить те же самые 3740 сжатых данных, как и у них. С остальными уровнями ситуация повторилась – результаты пережатых данных полностью совпали с оригинальными, хотя мой словарь несколько отличался.
Итоговая функция построения словаря (несколько запутанная оттого, что я экспериментировал с разными параметрами и динамической ценностью замены). В параметр forbiddenArr передаётся словарь «запретных» значений.
def rebuildCompress(screen, forbiddenArr, maxCompressSize = 256, LINE_LEN=24):
fullAns = [(0,0)]*maxCompressSize
lines = list(chunks(screen, LINE_LEN))
x = 0
while x < maxCompressSize:
ans = {}
for line in lines:
repeats = [list(g) for _, g in groupby(line)]
repeats = [(g[0],len(g)) for g in repeats]
for (tileNo,tileCount) in repeats:
#for tc in xrange(tileCount, tileCount+1):
for tc in xrange(2,tileCount+1):
compressPair = tileNo, tc
if compressPair in ans:
ans[compressPair] += 1
else:
ans[compressPair] = 1
#рассчёт ценности замены - длины цепочки * частоты её встречаемости
def calcPoints(v):
(t,c), cnt = v
return -(c-1)*cnt
ans = sorted(ans.iteritems(), key = calcPoints)
#filter and reverse values
newAns = []
for a in ans:
if (a[0][0]) < 0x80:
newAns.append((a[0][1],a[0][0]))
newAns = filter(lambda v: v not in forbiddenArr, newAns)
if len(newAns) == 0:
break
#HINT!!! if first results are similar in points, then we can use it's all
ansValue = newAns[0][1]
#newAns = filter(lambda x: x[1]==ansValue, newAns) #comment this for best results!
#newAns = sorted(newAns, key = lambda x: -x[0])
#print newAns
similar, maxSimilar = 0, 256
while len(newAns) > 0 and x < maxCompressSize and similar < maxSimilar:
curAns = newAns[0]
lines, findAtLeastOneReplace = compressorReplace(lines, curAns, x)
fullAns[x] = curAns
x += 1
similar += 1
newAns = newAns[1:]
return fullAns
Второй тип компрессии
Немного обидно, что после различных экспериментов и улучшений алгоритма я наткнулся на оптимальный способ, который использовали и разработчики, но, по крайней мере, мой компрессор работал не хуже, чем у них. Для всех уровней, кроме второго, результаты пережатия получились одинаковыми, однако со вторым обнаружился интересный момент – декомпрессор ломался на нём. Оказалось, что авторы игры для уровня внутри пирамиды (2-2 и 2-3), использовали для сжатия мозаики на стенах пирамид дополнительный вид компрессии, который заключается в использовании «базовых линий».
Последние 4 значения блоков 0xFC-0xFF используются для кодирования особых команд.
В этом случае в начале линии может использоваться команда из двух байт (номер_базовой_линии, кол-во блоков из базовой линии). На уровне используется 4 базовые линии (их номера кодируются от 0xFC до 0xFF). Первые несколько блоков берутся из этой линии, а затем нижняя часть дорисовывается обычным способом.
Пример таких начал линий на скриншоте:
На нём выделены рамками повторяющиеся базовые линии. Этот способ сжатия работает и на других уровнях, однако для них не описаны базовые линии (общие верхушки линий), поэтому разработчики не использовали его, но он позволил бы сэкономить ещё несколько байт, не дающих практической пользы, но символичных в мысленном соревновании с разработчиками игры.
Итоговый комментированный ноутбук с тестами декомпрессии и компрессии для всех уровней, который можно использовать для непосредственной компрессии данных и вставки в ROM-файл.
Таким образом, использование сжатия с помощью RLE-словаря, а также сохранение индексов повторяющихся линий, позволяют сжимать описания уровней размером в 18 килобайт (256 x 3 x 24 блоков) до 4-5 килобайт.
Поделиться с друзьями
Комментарии (5)

igordata
12.05.2017 20:58Спасибо за статью!
Очень интересно. Не думал, что в этой игре такие хитрые внутренности.
А сколько байт на всю игру экономит компрессия? Сколько бы занял несжатый образ?


VBKesha
14.05.2017 00:16Спасибо за статью!
Интересно было бы ещё глянуть на устройство уровней Dizzy.
igordata
Ого, какая штука! Про это можно наверное отдельную статью запилить.