
Недавно, сидя на диване, я задумался о том, что хочется мне сделать своего паука, который что-то бы смог качать с веб сайтов. Но качать он должен был бы не простой загрузкой, а как настоящий милый добрый браузер (т.е. JavaScript чтобы исполнялся).
В моей голове всплыли такие интересные штуки, как Selenium, PhantomJS, Splash и всякое подобное. Все эти штуки были мне немного втягость. Вот какие причины я выявил:
- Дело в том, что я хотел бы писать на своем любимом питоне, потому что очень не люблю JavaScript, а это уже означает, что большая часть уже не работала бы (или пришлось их как-то склеивать, что тоже отстой).
- Еще эти безголовые браузеры обновляются как когда.
- Но вот Selenium очень милая штука, но я не нашел, как там отслеживать загрузку страниц, или хотя бы адекватного способа выдрать куку или задать её. Слышал, что многие любители селениума инжектят в страничку JavaScript, что для меня дико, потому что где-то полгода назад я делал сайтик, который отрывал любые JavaScript вызовы с сайта и потенциально мог определять моего паука. Мне бы очень не хотелось таких казусов. Хочется чтобы мой паук выглядел как браузер максимально точно.
Собственно, к делу. Недавно вышел Headless Chrome. Это означает, что теперь мы аж использовать хром, как кравлер (но это неточно). Однако, я не нашел нормальных утилит для использования его в качестве кравлера. Нашел только chrome-remote-interface из списка сторонних клиентов (остальные были крайне скучными и совсем непонятными на первый взгляд).
Пробежавшись по документации и готовому проекту, и убедившись что никто толком не реализовал клиент под Python, я решил сделать свой клиент.
Протокол у Chrome Remote Debug достаточно простой. Для начала нам надо запустить Chrome вот с такими параметрами:
chrome --incognito --remote-debugging-port=9222 --headless
Теперь у нас есть API, доступное, по адресу http://127.0.0.1:9222/json/, в котором я обнаружил такие методы как list, new, activate, version, которые используются для управления вкладками.
Также, если мы просто перейдем на http://127.0.0.1:9222/, то сможем перейти на прекрасный веб отладчик, который полностью имитирует стандартный. В нем очень удобно отслеживать как работают апишные методы хрома (окно отладки справа эмулируется внутри окна, а окно браузера — отрисовано на канвасе).
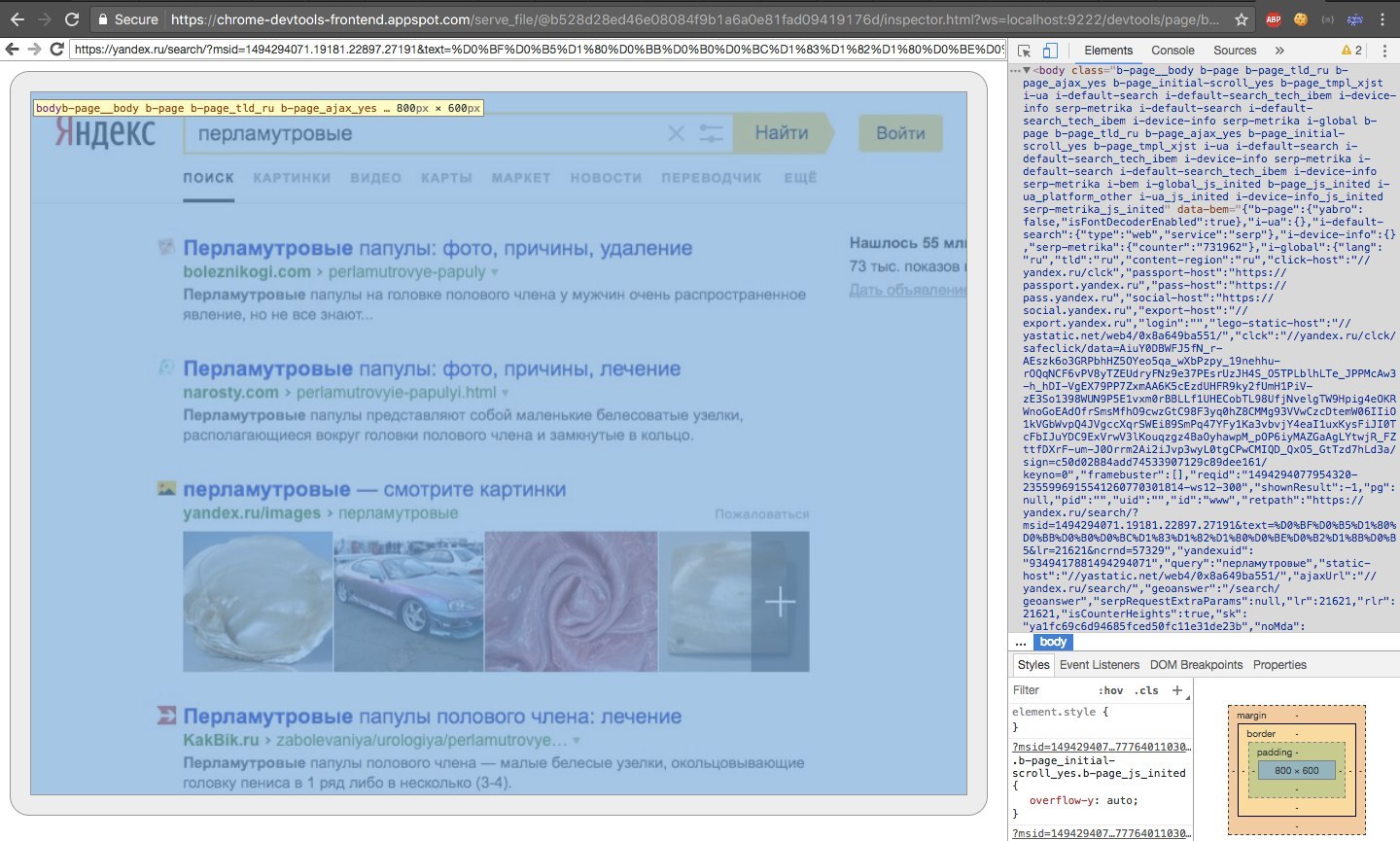
Собственно, перейдя на вкладку list, мы можем узнать, адрес вебсокета, с помощью которого мы сможем общаться с вкладкой.
Дальше мы подсоединяемся через вебсокет к желаемой вкладке, и общаемся с нею. Мы можем:
- Выполнить запрос
- Подписаться на события в вкладке
Спустя дни мучительного написания функционала для себя у меня получилась вот такая библиотека.
Что в ней есть:
- Автоматическая подкачка последней версии протокола
- Обертка протокола в питонистический вид
- Синхронный и асинхронный клиент (синхронный только для отладки)
- Надеюсь, удобная абстракция вкладок

Вот так выглядит прога, которая подгружает страничку и выдает длину каждого ответа на запрос:
import asyncio
import chrome_remote_interface
if __name__ == '__main__':
class callbacks:
async def start(tabs):
await tabs.add()
async def tab_start(tabs, tab):
await tab.Page.enable()
await tab.Network.enable()
await tab.Page.navigate(url='http://github.com')
async def network__loading_finished(tabs, tab, requestId, **kwargs):
try:
body = tabs.helpers.unpack_response_body(await tab.Network.get_response_body(requestId=requestId))
print('body length:', len(body))
except tabs.FailReponse as e:
print('fail:', e)
async def page__frame_stopped_loading(tabs, tab, **kwargs):
print('finish')
tabs.terminate()
async def any(tabs, tab, callback_name, parameters):
pass
# print('Unknown event fired', callback_name)
asyncio.get_event_loop().run_until_complete(chrome_remote_interface.Tabs.run('localhost', 9222, callbacks))Тут мы используем систему колбеков. Самые интересные: start и any:
- start(tabs, tab) — вызывается при старте.
- any(tabs, tab, callback_name, parameters) — вызывается, в случае если событие не нашлось в списке колбеков.
- network__response_received(tabs, tab, **kwargs) — пример библиотечного события Network.responseReceived.
Мне мой код показался достаточно элегантным, и я буду его использовать дальше, хоть протокол немного сыроват. Если кто-то хочет обсудить, то пишите сюда, в Github или мне на почту.
Однако, было одно но, из-за которого я все таки плачу. С помощью remote API нельзя производить перехват и модификацию запросов и ответов. Насколько я понял — это возможно через mojo, который позволяет использовать хром в качестве библиотеки.
Однако, я подумал, что компиляция нестабильного хрома и отсутствие Python прослойки для меня будет большим горем (сейчас есть C++ и JavaScript в процессе разработки).
Надеюсь, статья была полезной. Спасибо.

Комментарии (43)

medvoodoo
16.05.2017 16:55+3обидели мой любимый силениум и питончик:
import selenium.webdriver driver = selenium.webdriver.Firefox() driver.get("http://www.google.com") driver.get_cookies() # получаем куки
WebDriverWait — используется для гибкого задание времени ожидания загрузки страниц
mitinsvyat
16.05.2017 16:56Я точно не помню, но там разве не для текущего домена (и урла соответственно)?
mitinsvyat
16.05.2017 16:57Суть в том, что в этом же примере тебе пришлось перейти на гугл, чтобы получить куки.
А через апи и не надо как бы.
LenionNoinel
16.05.2017 19:03+1Скажу страшное, но я как-то реализовал подобное на стареньком vb6. Основные роботы работают через xmlhttprequest, а когда сайт на javascript, в фоновом режиме включается IE и прогружает страницу.
mitinsvyat
16.05.2017 19:21Такс.
Как понял:
- вы использовали какой-то фетчер, который что-то прогружал
- вы использовали IE как движок для джаваскрипта (результат его выполнения вы отправляли себе куда-то)
Так?
Тут немного иначе:
- мы используем хром, чтобы открыть страничку (т.е. открывается самая настоящая вкладка хрома)
- ну и соответственно джаваскрипт самый обычный и результат остается в браузере (конечно, это вытащить можно)
ВотLenionNoinel
16.05.2017 19:27Да, но там тоже прогружался полноценный IE, а потом прога просто забирала DOM в переменную. Другое дело, что медленновато было.

DaneSoul
16.05.2017 19:52А Scrapy не рассматривали?
Как раз web crawler на Python, более того, весьма известный и востребованный на рынке парсинга сайтов.mitinsvyat
16.05.2017 20:01Конечно, смотрел.
Собственно Scrapy используется для того, чтобы собирать однотипные данные (это не точно, но похоже на истину).
Ну и там джаваскрипта таки нету. В Scrapnghub (это их продукт) используют Splash, чтобы рендерить Javascript.
Т.е. Scrapy это немного другое.
Я думаю, что возможно внедрение хрома в тот же Scrapy по аналогии с Splash.
Мне же желательно сделать программу, которая будет бегать по сайтику, тыкать некоторые кнопки и еще что-то там.
Т.е. ближайшими аналогами для меня были: PhantomJS, Splash, Selenium все же.
inwady
16.05.2017 20:12Кстати, если нужно делать js на странице, то TamperMonkey может помочь чем-нибудь. Тут речь идет об исполнении js-кода на странице по фильтру.
Проект открытый, поэтому может написать расширение для перехвата fetch или подобного функционала? WebWorkers с этим вполне могут работать. Уверен, что Chrome на это способен.mitinsvyat
16.05.2017 20:37Как понял, вы хотите расширение использующее Service Workers для перехвата трафика (и подмены там).
Вообще, идея имеет место для жизни, но я все же бы это делал через Mojo, наверное (но это не точно).
veveve
16.05.2017 21:30+1PyQt, а именно QtWebEngine, наверное, и есть тот самый headless Chrome с готовым интерфейсом для Питона, нет?
mitinsvyat
16.05.2017 21:43Ну я его не использовал. Можешь расписать?
veveve
16.05.2017 23:05Взяли хромиум и сделали к нему апи для плюсов (чтобы загружать урлы, работать с html, управлять куками и т.п.). PyQt, соответственно, предоставляет возможность делать все это на питоне. Phantomjs, кстати, написан как раз поверх qt (только там управление js-ом и менее гибко чем при ручной работе с webengine).
Легче примеры погуглить. Вот, в частности, один старенький для получения скриншота страницы https://webscraping.com/blog/Webpage-screenshots-with-webkit/mitinsvyat
16.05.2017 23:31Как я понял, парни из QT взяли таки вебкит, но не хром и сделали вполне ничего такой браузер, который за одно можно запустить без головы. Только я не понял пока насколько полноценный. Т.е. поддерживает ли всякие сервис воркеры, стореджи всякие разные и т.д.
Ну а в хроме там 2 варика:
Mojo: оно работает как-то напрямую с хромом, и ты можешь юзать его как библиотечку. (Могу в чем-то ошибаться, поэтому почекай ссылку)
Ну и второй вариант: запускаем обычный хром с флагами, чтобы мы могли с ним общаться через вебсокет, как я и сделал. Апишки тут.
gearbox
16.05.2017 22:00нет. embedded chromium и headless chrome — это перпендикулярные вещи.
veveve
16.05.2017 23:08headless — это что? Браузер, только без окна и отрисовки страниц и, соответственно, накладных расходов с этим связанных. Webengine, на сколько помню, позволяет это.
gearbox
16.05.2017 23:30Да, но тем не менее хром и хромиум — две разные вещи.
Phantomjs прекращает разработку как раз ввиду выхода хрома с headless mode.
headless chrome
В хромиум тоже впилили, так что для этих целей лишняя прослойка в виде QT вряд ли нужна:
headless chromium
Хотя не уверен, может там интерфейс поинтереснее, не знаю. Я из мира ноды, у нас все сразу по людски делается.
alekciy
17.05.2017 09:08Phantomjs прекращает разработку как раз ввиду выхода хрома с headless mode.
А webdriver впили и на сколько адекватно?gearbox
17.05.2017 15:21так webdriver для хрома был (chromedriver), headless — всего лишь режим работы, с чего бы webdriver-у пропадать?
running selenium with headless chrome

alek0585
17.05.2017 13:25Особенно порадовала подкачка
Автоматическая подкачка последней версии протокола
marni
17.05.2017 13:47Интересная статья. Но есть вопрос к автору: ваше решение сможет обойти Distil? И ко всем: как вы решаете проблему с Distil? Спасибо
mitinsvyat
17.05.2017 13:54Такс. Distil я не использовал, и не знаю тамошние методы защиты. Мне кажется, это должно обходить примерно на том же уровне, что и селениум. Думаю, если напишешь поведение в браузере похоже на человеческое, то мож и не запалят.
Однако, кто-то должен это протестировать.marni
17.05.2017 14:22В зависимости от сайта, Distil палит селениум в лутшем случее через 30-50 запросов, в худшем через 1. Надо будет протестировать ваш вариант на досуге.
mitinsvyat
17.05.2017 15:57Ну надо повтыкать, что за трюки используются им, чтобы детектить
P.S. Замажь дефолтный User-Agent. Он там палевный :)
mitinsvyat
17.05.2017 19:01P.S. Если что-то не так у меня или непонятно — пиши, потому что я очень часто меняю что-то в проекте сейчас и он не сильно стабилен.
bfcmyxa
17.05.2017 13:55Ребята, подскажите пожалуйста, на чем сейчас проще всего написать бота, который будет парсить странчику и кликать когда спарсил то что ему надо? Естественно с поддерживанием хттп-запросов и чтобы подгружал javascript. Я посмотрел сплэш, но к моему сожалению я совершенно не знаю пайтон. Есть ли что-то подобное на js или php?
mitinsvyat
17.05.2017 14:08Но Splash же lua использует, вроде.
Ну используй PhantomJS или это (если хочешь попробовать использовать решение, которое в статье).
Если честно, я бы на твоем месте использовал PhantomJS, если что-то несложное или какой-нибудь кравлер на ноде.bfcmyxa
17.05.2017 17:07Спасибо за ответ, думаю самое подходящее для меня будет разобраться в PhantomJS.
selenite
17.05.2017 15:36У меня есть таск дёргать из dev tools хрома время и график загрузки страницы… я понимаю, что к этому окну можно получить доступ через эмуляцию f12, либо через иньекцию js в само окно браузера, но вот что-то ни один найденнй метод не работает. Идеи?
mitinsvyat
17.05.2017 16:07Стопе. В том, что я написал, не эмуляция F12, там апишки, с помощью которых, ты можешь проделать все тоже самое, чтобы ты мог делать через F12.
Ну и ты там можешь все это проследить.
Говорю, запусти хром с ключом --remote-debugging-port=9222, и подключись к хрому по адресу localhost:9222, потом открой вкладку и открой инспектор.
Получится такая веселая чепуха:
admmelit
19.05.2017 01:10Всем добрым людям привет!
Подскажите пжл тулзу, которая позволила бы парсить вэб страницу, но есть небольшое условие, но эти тулзы не должны требовать программирование?
mizhgun
Поздравляю, вам удалось достаточно близко подобраться к изобретению Splash.
mizhgun
Это к вопросу о том, что ни одним из перечисленных минусов Splash не обладает, и если цель действительно построить краулер, то проще и быстрее было научиться его готовить, чем велосипедить весьма сомнительное решение, недалеко ушедшее от селениума с фантомом и слабо пригодное для мало-мальски масштабного использования.
mitinsvyat
Суть в том, что я ничего особо не изобрел.
За меня все сделал Гугл, добавив headless режим в хром.
Я взял последнюю апишку хрома: https://chromedevtools.github.io/devtools-protocol/
Рано или поздно найдется умелец, который это нормально сделает все нативно через Mojo, и я почти уверен что все на это пересядут.
Ну а про то, что мне не нравится в селениуме с фантомом я же написал.
mizhgun
Я вам страшный секрет открою, большинство компаний, занимающихся скрапингом профессионально, либо уже давным-давно запилили что-то похожее на монструозном фантоме/каспере/чем-бы-то-ни-было-еще, либо — спасибо Скрапингхабу — сидят на Сплэше, поэтому заявление «все пересядут», мягко говоря, самоуверенно — ни в ресурсопотреблении, ни в быстродействии ваше решение ничем не выигрывает у Сплэша, будь хоть допиленное Моджой, хоть нет.
mitinsvyat
Мое решение Моджой быть допилено не может. Это другое решение. Это использование хрома в качестве библиотеки. Как тут быть медленным я не понимаю откровенно.
Еще ты упомянул, что у каждой компании есть своя переделка вебкита, который тоже во многом разработка Гугла. Думаю, им очень интересно что-то новое производить и поддерживать, большие компании вообще любят что-то свое пилить, деньги на это тратить. Ага.
Ну да, моя уверенность из пустого места пришла.
Конечно, я понимаю, что ты хвалишь разработки Скрейпингхаба. Мне они тоже очень нравятся (и сама деятельность их), но я просто пишу, про хорошую фичу хрома, которую ты почему-то очень агришь.
Ну правда хорошая фича.
joann
С каких пор вебкит «разработка Гугла»? вроде всегда была Apple, тока Blink Гугалавская замена вебкита.
mitinsvyat
Мне кажется, что не только Apple разрабатывало WebKit.
https://trac.webkit.org/wiki/Companies%20and%20Organizations%20that%20have%20contributed%20to%20WebKit