

Раньше, когда нужно было что-то разграничить (например, сервера с обработкой платежей и терминалы юзеров офиса), просто строили две независимых сети с мостом-файерволом в середине. Это просто, надёжно, но дорого и не всегда удобно.
Позже появились другие виды сегментации, в частности, по правам на основе карты транзакций. Параллельно развивались ролевые схемы, где машине, человеку или сервису назначаются свои конкретные права. Следующий логический виток — микросегментация в виртуальных инфраструктурах, когда DMZ ставится вокруг каждой машины.
В России пока есть единичные внедрения подобных защитных построений, но скоро их точно будет больше. А потом мы, возможно, не будем даже понимать, как можно было жить без такого. Давайте рассмотрим сценарии атак на такую сеть и как она на это реагирует.
Что такое микросегментация
Микросегментация — это метод безопасности, который позволяет назначать приложениям центра обработки данных микрополитики безопасности, вплоть до уровня рабочей нагрузки. В более прикладном применении — это модель обеспечения безопасности центров обработки данных. Применение политик сетевой безопасности обеспечивают брандмауэры, интегрированные в гипервизоры, которые уже присутствуют в ЦОД. Это обеспечивает повсеместность защиты. Кроме того, политики безопасности можно удобно изменять, в том числе автоматически, и динамически адаптировать с учётом изменений рабочих нагрузок.
Как это было раньше
Вот «каменный век» современных сетей — неуправляемые сети:
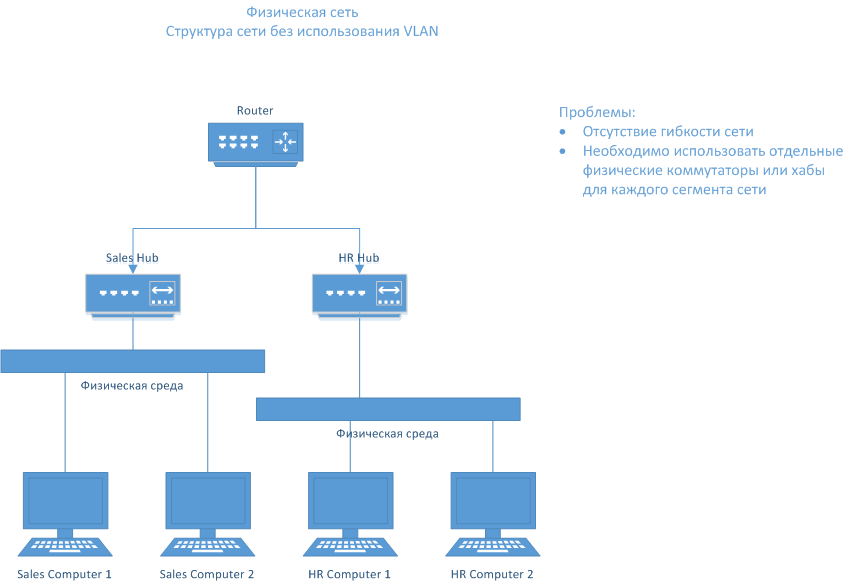
Точнее, каменным веком это было бы, если бы сети были вообще физически разделены отсутствием линков. Но здесь они соединены роутером и защищены аппаратными файерволами на месте пересечений. Это хороший вариант ровно до тех пор, пока вы не попадёте в реальный мир.
Вот следующий виток эволюции защиты:
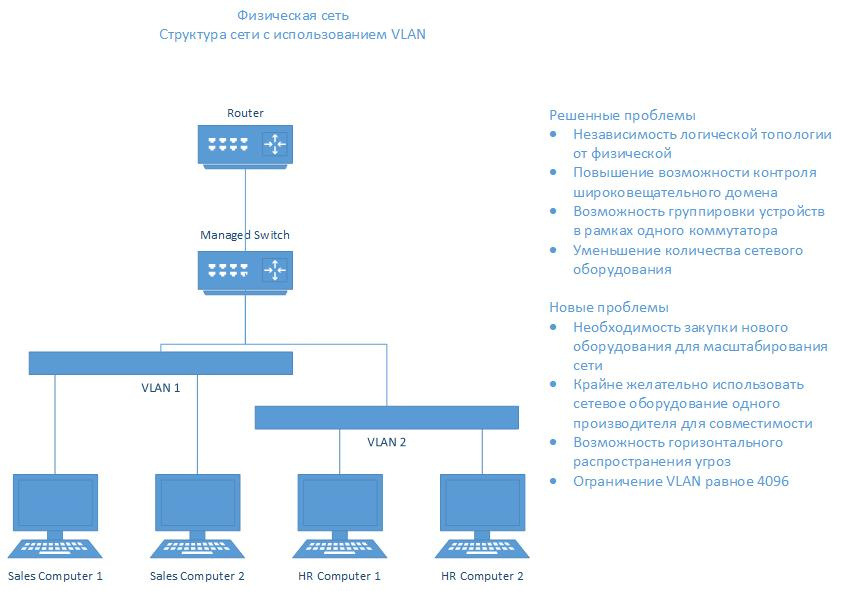
Сегодня большинство компаний используют кластеры серверов для того, чтобы крутить свою инфраструктуру в целом. Вот пример «Аэроэкспресса» — там, по сути, один кластер и две виртуальных подсети — для офисов продаж (обычные пользователи) и для банкинга, то есть расчётов по билетам. До внедрения сеть была одна, и в теории кассир мог банально подосить сервер с выдачей билетов. Следующий логический шаг после такого разделения — ещё большая виртуализация и построение микросегментов, но не на уровне железа, а на уровне гибких прав сервисов. Это очень облегчает администрирование в сравнении с классической задачей мелкого разделения по 2–3 машины и очень упрощает жизнь в плане надёжности защиты в кластере. Каждый микросегмент смотрит на соседний как на внешний мир, а не как на заведомо доверенный.
Это одна из самых простых схем, где в зависимости от задач используются пересечения разных периметров. Это может выглядеть как на схеме ниже.
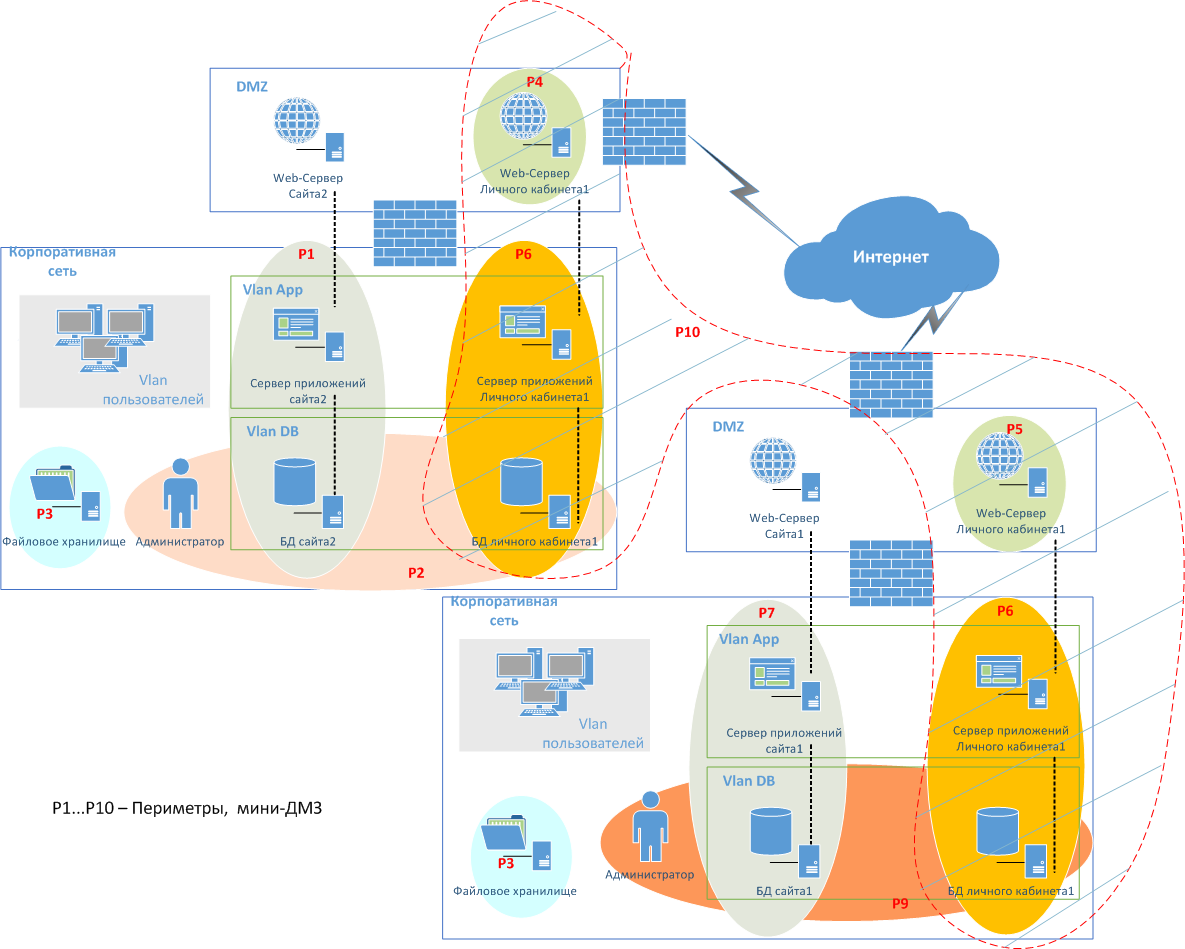
На этой схеме, как видите, решённые проблемы масштабирования компонентов сети (производится развёртыванием новых VM), есть возможность использовать любое сетевое оборудование, есть возможность контроля горизонтального распространения трафика ВМ, VLAN заменены VxLAN, ограничение которых составляет около 16 млн интерфейсов. Более того, если посмотреть на цветовое разграничение схемы, на примере Личного кабинета — 1 можно увидеть следующие сценарии:
- Серверы приложений, находящиеся на разных физических площадках, расположены в одной логической сети Р6 (оранжевые овалы);
- При этом Web-серверы того же Личного кабинета — 1 находятся уже в разных логических сетях (зелёные овалы Р4 и Р5);
- Все серверы, реализующие Личный кабинет — 1, в свою очередь находятся в единой логической сети Р10 (выделенная пунктиром зона).
Возможно, вы уже всё поняли и теперь хотите узнать, насколько сложно это поддерживать. Так вот, в новых версиях гипервизоров такие структуры поддерживаются «из коробки».
Самая главная тема таких внедрений микросегментации — защита критичных сервисов в контексте кластерных и персональных облачных технологий.
Пример: есть рабочая машина бухгалтера, на которой при обычной повседневной работе применяются политики вроде «АРМ Бухгалтерии», при которых можно осуществлять выход в Интернет и к общим инфраструктурным сервисам. При запуске же банк-клиента политики сразу же будут в приоритете обрабатывать правила, связанные именно с трафиком банк-клиента, и его трафик будут пропускать только на заданный IP/DNS сервера банка, при этом в обязательном порядке пропускать такой трафик через дополнительные средства защиты информации (к примеру, DPI-сервер). Банк-клиент закрыт — снова становится «АРМ Бухгалтерии».
Из чего состоит одна из платформ для микросегментации NSX?
Вот основные компоненты:
| Коммутация |
Логическое наложение уровня 2 обеспечивается по всей коммутируемой матрице уровня 3 внутри и вне ЦОД. Поддержка наложения сетей на основе VXLAN. |
| Маршрутизация |
Динамическая маршрутизация между виртуальными сетями выполняется ядром гипервизора распределённо, поддерживается горизонтальное масштабирование с аварийным переключением типа «активный-активный» на физические маршрутизаторы. Поддерживаются протоколы статической и динамической маршрутизации (OSPF, BGP). |
| Распределённый брандмауэр |
Распределённые службы брандмауэра с сохранением состояния, встроенные в ядро гипервизора, с пропускной способностью до 20 Гбит/с на сервер гипервизора. Поддержка Active Directory и мониторинга действий. Кроме того, NSX обеспечивает вертикальный брандмауэр с помощью NSX Edge. |
| Балансировка нагрузки |
Балансировка нагрузки для уровней |
| VPN |
Удалённый доступ через VPN и VPN-подключение типа «среда-среда», неуправляемый VPN для служб облачных шлюзов. |
| Шлюз NSX |
Поддержка мостов между сетями VXLAN и VLAN обеспечивает оптимальное подключение к физическим рабочим нагрузкам. Этот компонент встроен в платформу NSX, а также поддерживается надстоечными коммутаторами, поставляемыми партнёрами по экосистеме. |
| NSX API |
Поддерживаются API-интерфейсы на базе REST для интеграции с любыми платформами управления облаком или пользовательскими |
А теперь рассмотрим сценарии разных угрожающих событий, чтобы стало окончательно понятно.
Сценарий 1: малвара
Пути проникновения и заражения в крупных компаниях примерно одинаковые: фишинг, направленные атаки, «дорожные яблоки» в виде подброшенных флешек. Как правило, зловред заражает одно из автоматизированных рабочих мест (например, приходя с письмом), а затем внутри периметра может делать что угодно до обнаружения. Недавно я видел ситуацию в банке. Надо сказать, у них серьёзные люди и серьёзная безопасность, но внутри сети ситуация была такая, что развёрнутый тестовый зловред (без пейлоада) «пробил» тестовую среду и заразил несколько филиалов, пока его не увидела система защиты. У некоторых пользовательский сегмент вообще не отделён от критичного, и юзеры радостно вешают зловредов на сервера 1С, на машины с финансовыми транзакциями, на веб-сервера, сервера обновлений и так далее.
В нашей парадигме защита такая: микросегментация на уровне серверов, сервисов, пользователей. Отделяем каждую группу периметрами (как на картинке выше). Заражается, как правило, одна виртуальная машина, которая детектится антивирусом, работающим с высоты гипервизора. Машина при нетипичной активности тут же автоматически помещается в карантин — специальный сегмент, куда попадают все те, кто делает что-то не совсем обычное.
К этому всему могут быть прикручены и стандартные меры — например, типовая песочница.
Современные зловреды затихают на единичном АРМ, посылают очень маленький сигнал на сервер управления или разворачивают второй блок, который уже несёт на себе «полезную» нагрузку. В случае чего детектится именно второе поколение зловреда — первый «затихший» остаётся в системе. Антивирус, может, задетектит и убьёт даже оба блока, если повезёт, но скорее всего, это произойдёт уже на границе сетей, и после этого придётся делать огромную работу по отслеживанию ущерба. Да и сама интеграция антивируса без уровня гипервизора несколько сложнее.
17 марта 2017 года Касперский обновил «защиту без агента» для NSX.
Сценарий 2: направленная атака на критичный сервис
Атака на особо критичные компьютеры и серверы (бухгалтерия, машины с доступом к SWIFT, процессинговые серверы) чаще всего начинается как DDoS, продолжается проносом зловреда «под шумок». Решается просто: создаётся ещё одна (две, три, сколько надо) DMZ внутри вашей группы серверов для полной отсечки. Разумеется, об этом надо думать заранее.
У нормального админа, естественно, сети и так разделены, просто поддерживать это без дырок в течение долгих лет сложнее. Ну и без централизации. И при переносе сети или виртуалки могут появиться дырки, а в случае микросегментации — вероятность куда меньше.
Сценарий 3: случайная неверная миграция или упрощённая инициализация сети
Только треть потерь данных связана с действиями злоумышленников. Остальное — банальный недосмотр или просто идиотизм. Яркий пример — очень часто случающиеся изменения в сети, например, миграция машины или группы машин из одной подсети в другую (из более защищённой в менее защищённую, из-за чего мигрированная машина оказывается «голой» перед угрозами).
Решение — микросегментация и присвоение профиля машине или группе машин. Таким образом, настройки безопасности и все нужные файерволы (реализуемые гипервизором) будут оставаться на ВМ вне зависимости от того, как и куда её мигрируют.
Мой любимый пример — в одной розничной сети были неверно оценены риски. Кассы мигрировали в пользовательскую зону (точнее, права пользователей поменялись через полгода). Кто-то что-то забыл при очередном патче — и их выставили голой базой данных наружу.
Сценарий 4: особо удачный пентест
Это реально отдельный сценарий, потому что за такие косяки очень больно бьют по рукам. Особенно в финансовой сфере. Я видел очень простую историю: банк заказал проникновение на определённую группу ВМ (в тестовой среде). Пентестеры взяли флаг, но немного увлеклись, проковыряли тестовую среду, вышли в основной сегмент и положили на сутки сервер АБС. Это просто абзац!
В общем, микросегментация помогает сделать так, чтобы сети «физически» не видели друг друга, как если бы они были не соединены вообще никак. На уровень гипервизора всё равно не пройдут (ну, по крайней мере без 0-day мирового уровня). Если вдруг что-то получит админские права и будет распространяться — гипервизор отловит. И виртуальные машины на порядок легче откатывать.
Сценарий 5: атака на смотрящий наружу сервис, что ведёт к проблемам внутренней сети
В рознице есть веб-сервер. Фронт стоит, а между фронтом и вебом открытые порты.
Подидосили его, заодно в конечном итоге легла и линия касс. Админ ищет новую работу уже на следующий день. В общем, суть атаки — атакующий использует уязвимость сервера приложений или веб-сервера, доступного из Интернета, и получает доступ внутрь корпоративной инфраструктуры к критичным серверам и базам данных. Ну, или просто кладёт всё внутри дидосом.
В парадигме предполагается микросегментация каждого сервера сервиса таким образом, что для каждого сервера, выполняющего свою роль, будут определённые настройки безопасности. Настраивается при помощи профилей.
Другие сценарии
В общем, примерно похожим образом отрабатываются другие сценарии. Например, с нашей точки зрения, инсайдер — это просто заражённая АРМ. И неважно, сам он действует, или просто у него увели учётку. Нетипичная активность — карантин — разбирательство и последующий откат затронутой ВМ.
Как переходить
Давайте расскажу на примере одного из практических случаев:
- Провели обследование. В ходе обследования зафиксировали топологию сети, архитектуру виртуальной инфраструктуры, типы развёрнутых систем и сервисов. На этом этапе определяются и фиксируются все информационные потоки (пользовательские, сервисные, трафик управления, трафик мониторинга и обновления).
- Производится анализ и проектирование изменений виртуальной инфраструкутры, в том числе сетевой, с учётом выявленных на этапе обследования групп сервисов по критичности и предоставляемым функциям.
- Производится первоначальная настройка профилей (групп ВМ, ролей, настроек безопасности, настроек МСЭ, настроек доступа групп пользователей) для тестовой группы ВМ.
- Сформированные профили применяются, мониторится работа. При необходимости вносятся корректировки. Действует модель «zero-trust» при внедрении микросегментации. При такой модели мы изначально ничему не доверяем, а разрешаем только проверенное и доверенное взаимодействие.
- Решение масштабируется на всю инфраструктуру.
Дальше вся инфраструктура поддерживается и управляется централизованно из единой консоли минимальным количеством привлекаемого персонала. Формируются группы и профили, их назначение производится достаточно быстро. Назначенные профили работают везде в рамках одной виртуальной инфраструктуры. Помимо управления МСЭ и параметрами безопасности, также централизованно управляются процессы миграции, обновления, ввода и вывода серверов и сервисов из эксплуатации.
Важные моменты конкретно для упомянутого решения NSX:
- Необходимость замены межсетевого экрана Cisco ASA 5520.
- Возможность разбиения ЦОДа на отдельные сегменты независимо от подсети и VLAN.
- Применение политики к ВМ в соответствии с ОС и её именем.
- Поддержка решением протокола IPsec для связи с удалёнными филиалами.
Была вот такая сеть:
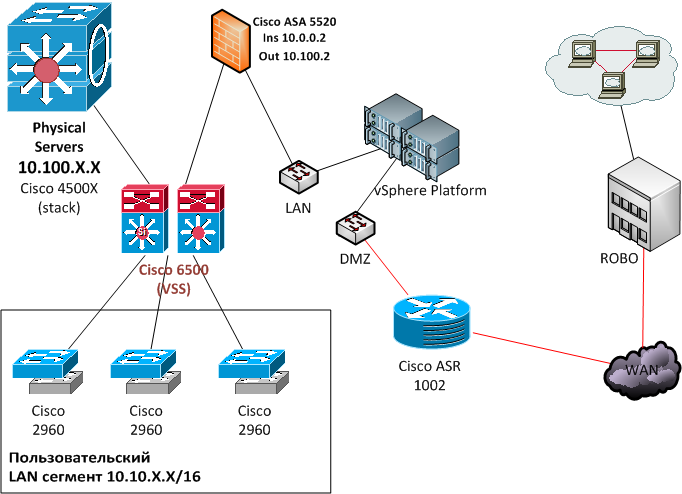
Перед внедрением мы провели аудит, чтобы понять, как «ходит» трафик в виртуальном ЦОДе с использованием утилиты VMware vRealize Network Insight. Она как раз помогает настроить правила микросегментации. Получается что-то вроде этого:
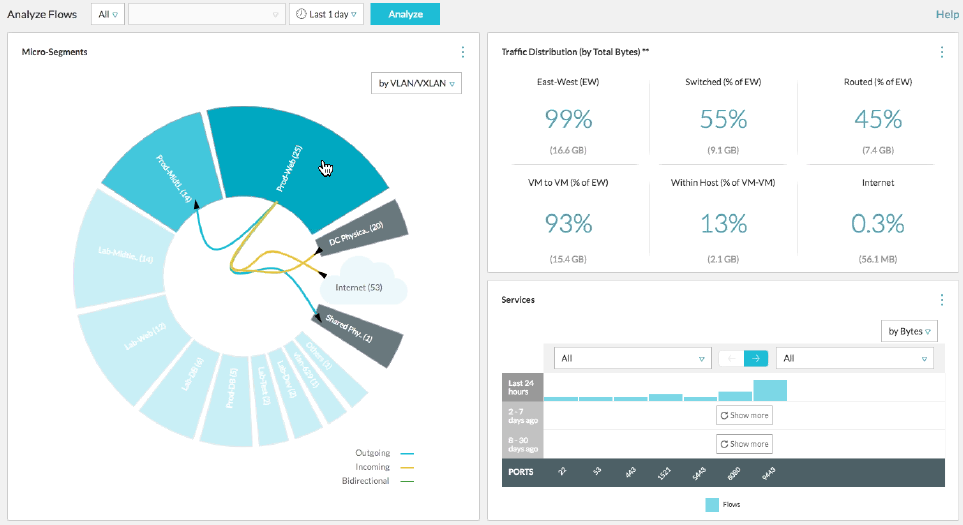
Источник
И сравнили интересующие заказчика параметры (так, одной из задач была замена VPN):
| Cisco ASA 5520 |
Cisco ASA |
Cisco ASA 1000V |
Cisco ASA |
VMware NSX Edge |
|
| Тип |
Физическое устройство |
Физическое устройство |
Виртуальная машина |
Физическое устройство |
Виртуальная машина |
| Максимальная пропускная способность межсетевого экрана (макс.) |
0.4 Гбит/с |
1.2 Гбит/с |
1.2 Гбит/с |
4 Гбит/с |
9 Гбит/с |
| Максимум одновременных сессий |
280,000 |
245,000 |
200,000 |
1,000,000 |
1,000,000 |
| Максимум соединений в секунду |
N/A |
6000 |
10,000 |
50,000 |
131,000 |
| Пропускная способность VPN |
250 Mbps |
250 Mbps |
200 Mbps |
700 Mbps |
2 Gbps |
| Максимальное кол-во IPsec-туннелей |
750 |
250 |
750 |
5,000 |
6,000 |
| Максимальное кол-во SSL-туннелей |
750 |
250 |
750 |
5,000 |
6,000 |
Параллельно построили схему сети из физического оборудования. Ключевое для нас — это понять движение трафика внутри ЦОДа для настройки политик. Его сняли, применим сразу. Если что-то будет резаться — просто добавим позже. Недели-двух хватает для построения хорошей карты и определения всех сервисов.
У нас была довольно простая инсталляция, и мы её разместили на 2 блейдах. Затраты:
| Компонент |
Кол-во |
?ОЗУ (ГБ) |
?vCPU |
?HDD (GB) |
| NSX Manager |
1 |
16 |
4 |
60 |
| NSX Controller |
3 |
12 |
12 |
60 |
| NSX DLR |
2 |
4 |
8 |
3 |
| NSX EDGE |
1 |
2 |
4 |
2 |
У заказчика уже была среда виртуализации VMware vSphere, поэтому мы просто купили лицензии для NSX. В то время ещё не было редакций NSX, они появились практически через месяц после закупки лицензий. Сам продукт лицензируется по сокетам.
Разделили машины по группам и назначили им теги, перенесли правила файервола с ASA на распределённый файервол и проверили ещё раз vRealize Network Insight., что мы верно указали потоки трафика и ничего не забыли.
PROFIT!
Ссылки
- Официальное
- Интеграция с антивирусным продуктом Касперского
- Очень хорошая англоязычная статья о том, из чего состоит VMware NSX и как он работает
- Ликбез о не совсем известных решениях для защиты ИТ-инфраструктуры бизнеса
- Моя почта для вопросов — afeoktistov@croc.ru
Комментарии (10)

Pave1
19.05.2017 09:37Спасибо большое за очень интересную статью!
Очень интересно было бы почитать, что именно из функций NGFW/IPS умеет фаервол NSX и с чем из классических решений его можно позиционировать по функционалу?
alxspb
25.05.2017 09:09NSX DFW даёт базовую 5-tuple stateful инспекцию (L2-L4), + ALG для типовых приложений. Для NGFW/IPS можно сверху добавить через Network Introspection API одного из 3rd-party (Check Point, Palo Alto, Fortinet, etc.)

navion
19.05.2017 09:52+1Хорошо, когда можно просто купить NSX Advanced (с distributed firewall) по $5500 за сокет.

SeasoneWolf
19.05.2017 13:33В IT-сферу «углубился» по настоящему только год назад и с того момента не могу оторваться от изучения всего: от языков программирования до защитных методик. Особенно заинтересовала ваша статья.

storm1kk
19.05.2017 13:58Можно ли как-то получить лицензию NSX для тестирования?

AFeokt
19.05.2017 15:04Можно воспользоваться вот такими лабораторными вендора по продукту. Если этого недостаточно или будут какие-то проблемы, готов помочь по почте.

GORrand
26.05.2017 13:16При этом Web-серверы того же Личного кабинета — 1 находятся уже в разных логических сетях (зелёные овалы Р4 и Р5);
Все серверы, реализующие Личный кабинет — 1, в свою очередь находятся в единой логической сети Р10 (выделенная пунктиром зона).
Возможно, глупый вопрос, но я не понял, как эти два пункта действуют одновременно?
И ещё вопрос, как это применимо к сетям вне ЦОДов, н-р локальным «офисным» сетям? Вместо ядра сети использовать кластер с NSX?
heleo
У вас во втором примере в решаемых проблемах написано «независимость логической топологии от логической». Имелось ввиду от физической?
AFeokt
Спасибо большое! имелось ввиду — от физической. Обновил картинку.