
Привет, Хабралюди!
Пролистав ленту статей с тегами, относящимся к ПЛИС, FPGA, цифровому дизайну, HDL понял, что их не густо. Будем исправлять это безобразие.
В этом посте я постараюсь доходчиво, коротко и понятно рассказать об архитектурах устройств программируемой логики. Затрону ключевые вопросы технологии их производства.
Поехали!
Начнем с физики процесса. Она разнится для каждого устройства программируемой логики(PLD). И для удобства понимания сведем различные технологии в эту замечательную табличку. Основа любого устройства, вне зависимости от технологии-матрица переключений, которая позволяет коммутировать электрические сигналы между её частями. А эта матрица есть ничто иное как схема памяти.
Итак обо всем по порядку.
В случае с fuse или PROM программирование или «прожиг» заключается в ликвидации плавкой перемычки путем расплавления импульсом тока большой длительности и амплитуды. Поэтому fuse-устройства относят к однократно программируемым. Перемычки бывают металлическими(нихром, титан-вольфрам) или поликристаллическими (поликремний).
В случае EPROM схема программируется электрически при помощи специального программатора и стирается облучением поверхности кристалла сильным ультрафиолетовым светом(например от ртутной лампы) через кварцевое окошко в корпусе.
Схемы EEPROM программируются и стираются электрически. Подробно об этом может рассказать статья из вики.
SRAM или же по-русски статическая оперативная память с произвольным доступом характеризуется низким потреблением, поэтому находит свое применение в FPGA. Ячейка данного вида памяти состоит из 6-8 транзисторов, отсюда низкая плотность записи и высокая стоимость хранения килобайта информации. В общем все достаточно просто и обыденно.
А вот antifuse — это самое интересное. Именно на них строятся те самые Rad-hard FPGA(RTAX и RTSX-SU) фирмы Actel, которые принесли ей такую известность. Как и в случае с fuse они однократно-пережигаемые(правда не всегда, но об этом ниже). Однако в конструкции есть принципиальное отличие — они образованы трехслойным диэлектриком из oxid-nitrid-oxid(ONO) и здесь все совсем наоборот.

В исходном состоянии такая перемычка имеет высокое сопротивление, достигающее нескольких миллионов Ом. При подаче напряжения между диффузионным слоем и кремниевой шиной(на рисунке — gate) приводит к возникновению в оксиде туннельного эффекта Фаулера-Нордгейма и прямого туннельного эффекта. Это приводит к возрастанию токов утечки и soft breakdown(обратимого пробоя). Если убрать электрическое поле, то сопротивление диэлектрика востановится. В противном случае токи будут возрастать и это приведет в конечном счете к тепловому(необратимому) пробою диэлектрика, образованию проводящего канала и резкому возрастанию тока через него. Этот сценарий носит в западной литературе название hard breakdown.
Параметры состояния перемычки после пробоя должны сохраняться около 40 лет. Малые сопротивления и малые паразитные емкости перемычек типа antifuse положительно влияют на скорости распространения сигналов в программируемых связях.
Под Mask имеется в виду программирование нанесением на кристалл-полуфабрикат 1-2 верхних слоя металлизации с последующим травлением.
А теперь после затянувшегося вступления перейдем, собственно, к теме обозначенной в заголовке. Устройства PLD в зависимости от количества вентилей, архитектуры и особенностей технологии программирования могут отнесены к классам, представленным на схеме ниже

В терминологии принятой на Западе известны также как HAL(Hard Array Logic) или же Structured ASIC. Что то среднее между заказными интегральными схемами и PLD. С первыми роднит то, что программирование осуществляется технологически. Со вторыми то, что на одном кристалле можно получить самые разные цифровые устройства.
Программирование осуществляется нанесением с последующим травлением 1-2 слоев металлизации на кристалл-полуфабрикат с нескоммутированными ячейками. Разработчики аппаратуры, построенной с применением FPGA имеют возможность их замены на БИС на основе БМК, получив при этом, в ряде случаев, заметный экономический эффект и увеличив плотность компоновки аппаратуры. Для обеспечения такой переработки производители разрабатывают САПРы, позволяющие производить автоматизированный перевод проектов, выполненных на ПЛИС в базис библиотек БМК.
Могут включать до 100 000 вентилей и работать на частотах до 50МГц. Операционный цикл составляет около 3-х месяцев.
В настоящее время почти полностью вытеснены FPGA и CPLD. Однако применяются в мелкосерийном производстве в виду своей дешевизны по отношению к заказным микросхемам. Выпускается отечественным ОАО Ангстрем, НПО Физика и некоторыми другими предприятиями.
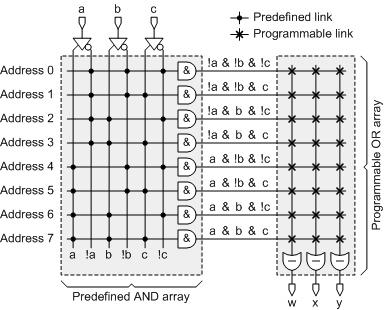
Так же называется Generic logic array(GAL). Впервые разработаны компанией Monolithic Memories(в настоящее время входит в Lattice Semiconductor) и появились на рынке аж в марте 1978.
Состоит из логики ввода-вывода и ядра, которое представляет из себя хорошо известную всем нам EPROM или EEPROM. Используются для создания кобинационных логичеких схем. Для проргаммрования PAL сущестовали специальные языки программирования как PALASM, ABEL, CUPL. Ранние PAL производились по биполярной технологии с однократным программированием посредством пережигания титано-вольфрамовых перемычек(fuses). Более поздние — по КМОП-технологии. Состоят из десятков-сотен вентилей.
Как и БМК в настоящее время вытеснены более совершенными устройствами, однако все еще применяется в изделиях специального назначения, например в военной технике. Выпускаются фирмой Atmel
Отличается от предыдущего класса тем, что в них программируется как массив OR, так и AND. Из за этого — более сложные схемы и стоимость выше, чем у PAL. В силу того, что программируются оба массива, скорость ниже, чем в случае PAL.
Технология программируемых логических устройств со сложностью, занимающей диапазон примерно между PAL (Programmable Array Logic) и FPGA (Field-programmable gate array), и с сочетанием их архитектурных особенностей.
Устройство CPLD включают в себя тысячи – десятки тысяч ячеек, имеют хорошо предсказуемые задержки прохождения сигнала. От FPGA отличает наличие энергонезависимой перепрограммируемой памяти, те для первоначальной загрузки не требуются микросхемы конфигурационной памяти, как в случае FPGA. Поэтому ресурс перепрограммирования меньше чем в случае последних(не менее 1 000 циклов запись/стирание для семейства Xilinx CoolRunner-II).
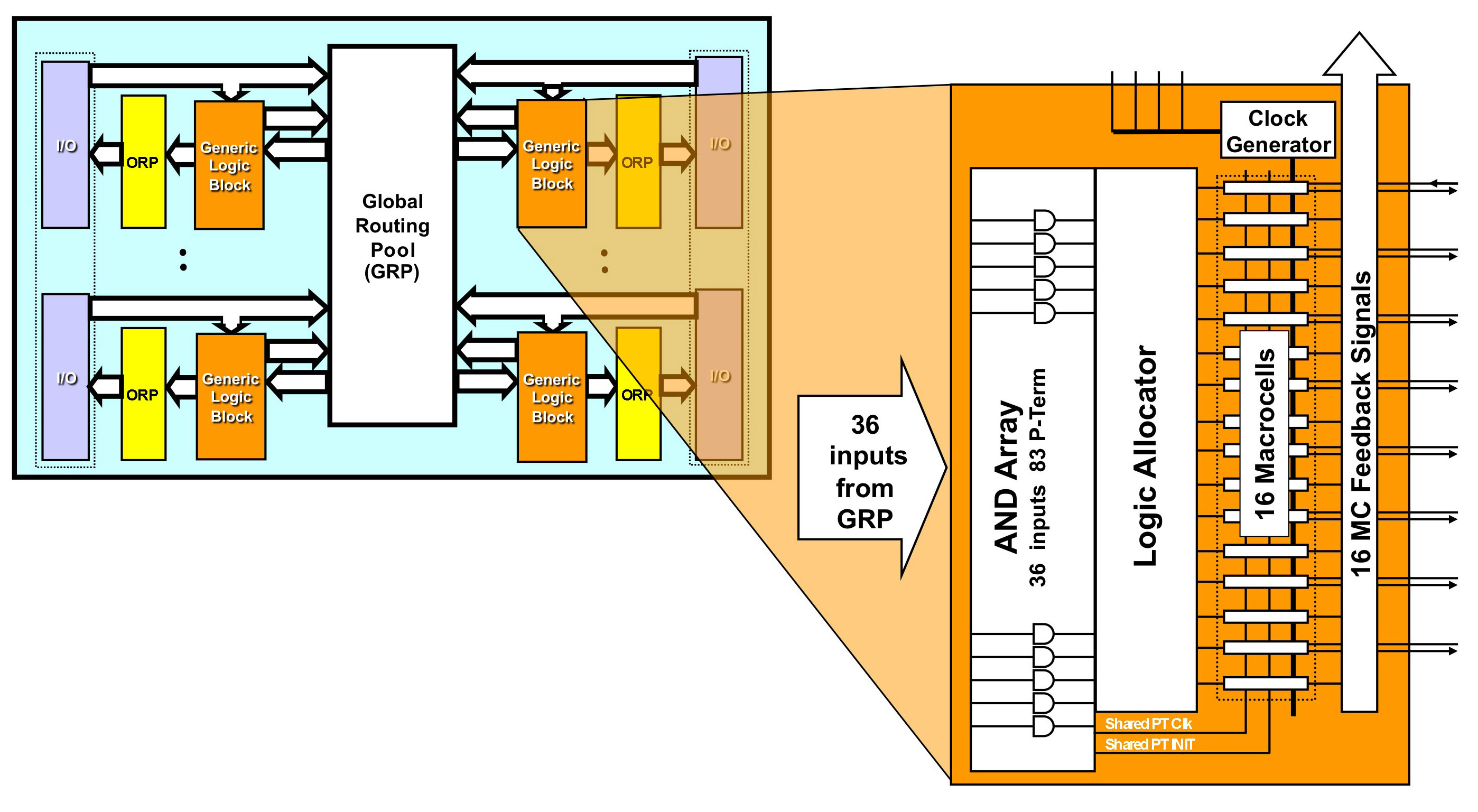
Структура CPLD представляет собой совокупность функциональных блоков, объединяемых матрицей переключений Global Routing Pool. Архитектура функциональных блоков(Generic Array Logic) во многом подобна архитектуре универсальных PAL. Отличия заключаются в том, что все выходные макроячейки(Macrocells) имеют две обратные связи, а промежуточные шины макроячейкам назначаются с помощью распределителя (Logic allocator). Некоторые макроячейки CPLD не имеют связи с внешним выводом. Такие макроячейки называются скрытыми. Скрытые макроячейки имеют только одну обратную связь.
Внешние выходы CPLD связываются с выходом макроячейки при помощи еще одной матрицы межсодинений ORP(Output Routing Pool). Эта же матрица связывает входную логику с GRP. Для уменьшения задержек в некоторых CPLD предусматриваются Direct input входы связанные напрямую со входами макроячеек.

Несмотря на различия между FPGA различных семейств и различных производителей, включенные в их состав вкусности вроде блоков DSP и процессорные ядра, общие принципы архитектуры FPGA остаются неизменными.
Основной функциональной единицей FPGA является CLB(Configurable Logic Block). Коммутация CLB осуществляются посредством S блоков и С блоков(connection box). CLB в свою очередь может включать в себя несколько LUT(Look-up table). У фирмы Xilinx CLB еще состоят из так называемых Slices, которые тоже в свою очередь состоят из LUTов. Зачем так все усложнять? Дело в том, что есть различные виды секций Slice, LUTы которых обладают различной функциональностью.
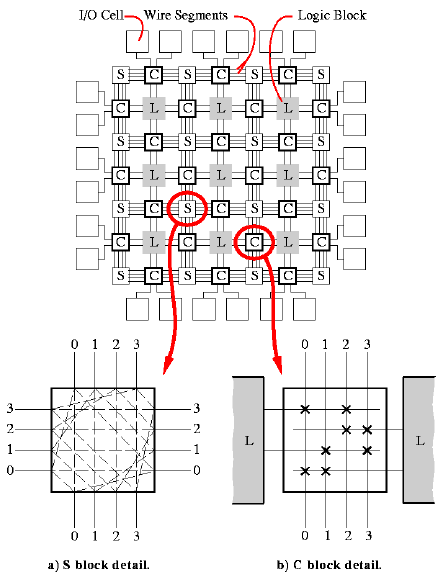
В FPGA семейств Virtex-6 и Spartan-6 CLB состоит из 2-х секций их 3 вида: SLICEM, SLICEL и SLICEX. В семействе Spartan-6 один CLB состоит из SLICEL и SCLCEX, а второй из SLICEL и SLICEM. У Virtex-6 все выглядит немного по-другому — один имеет в составе 2 секции SLICEL, а второй — SLICEL и SLICEM. При этом каждая секция в CLB подключена к отдельной цепи переноса.

Рассмотрим каждую из этих секций.
SLICEM состоит из 4 LUT, включает в себя логику ускоренного переноса, таблицы преобразования, конфигурируемые как распределенная память и SRL(Shift register lookup table), и мультиплексоры расширения количества булевых аргументов

SLICEL состоит из 4 LUT, включает в себя логику ускоренного переноса и мультиплексоры расширения количества булевых аргументов

SLICEX состоит из 4 LUT, только логика. Никакой распределенной памяти, цепей переноса и мультиплексоров расширения.

Как же все это соединить вместе? Для этого компания Xilinx разработала архитектуру ASMBL(Application Specific Modular Block Architecture). Если коротко, то одинаковые блоки, такие как DSP, блочная память, встроенные IP-блоки или логические секции располагаются в одном ряду. Путем комбинации таких рядов и получаются специализированные для различных применений FPGA(например, Virtex-6 бывают LXT, SXT и HXT).

Блоки ввода-вывода современных FPGA поддерживают свыше 40 разных протоколов с различными напряжениями, такие как: LVCMOS, LVDS, Bus LVDS, LVPECL, SSTL, HSTL, RSDS_25(point-to-point), PCI, I2C и другие. Выводы FPGA объединяются в банки по 30-80 выводов в каждом, выводы каждого банка могут поддерживать различные группы стандартов.
Использованные источники
Пролистав ленту статей с тегами, относящимся к ПЛИС, FPGA, цифровому дизайну, HDL понял, что их не густо. Будем исправлять это безобразие.
В этом посте я постараюсь доходчиво, коротко и понятно рассказать об архитектурах устройств программируемой логики. Затрону ключевые вопросы технологии их производства.
Поехали!
Начнем с физики процесса. Она разнится для каждого устройства программируемой логики(PLD). И для удобства понимания сведем различные технологии в эту замечательную табличку. Основа любого устройства, вне зависимости от технологии-матрица переключений, которая позволяет коммутировать электрические сигналы между её частями. А эта матрица есть ничто иное как схема памяти.
| Назавание | Возможность перепрограммирования | Энергозависимость | Технология | Размер ячейки |
| Fuse | Нет | Нет | Биполярная и CMOS | Нет данных |
| EPROM | Да | Нет | UVCMOS | 1X |
| EEPROM | Да(внтрисхемная) | Нет | EECMOS | 2X |
| SRAM | Да(внтрисхемная) | Да | CMOS | 5X |
| Antifuse | Нет | Нет | CMOS | 1X |
| Mask | Нет | Нет | TTL, CMOS, ECL | Зависит от технологии |
Итак обо всем по порядку.
В случае с fuse или PROM программирование или «прожиг» заключается в ликвидации плавкой перемычки путем расплавления импульсом тока большой длительности и амплитуды. Поэтому fuse-устройства относят к однократно программируемым. Перемычки бывают металлическими(нихром, титан-вольфрам) или поликристаллическими (поликремний).
В случае EPROM схема программируется электрически при помощи специального программатора и стирается облучением поверхности кристалла сильным ультрафиолетовым светом(например от ртутной лампы) через кварцевое окошко в корпусе.
Схемы EEPROM программируются и стираются электрически. Подробно об этом может рассказать статья из вики.
SRAM или же по-русски статическая оперативная память с произвольным доступом характеризуется низким потреблением, поэтому находит свое применение в FPGA. Ячейка данного вида памяти состоит из 6-8 транзисторов, отсюда низкая плотность записи и высокая стоимость хранения килобайта информации. В общем все достаточно просто и обыденно.
А вот antifuse — это самое интересное. Именно на них строятся те самые Rad-hard FPGA(RTAX и RTSX-SU) фирмы Actel, которые принесли ей такую известность. Как и в случае с fuse они однократно-пережигаемые(правда не всегда, но об этом ниже). Однако в конструкции есть принципиальное отличие — они образованы трехслойным диэлектриком из oxid-nitrid-oxid(ONO) и здесь все совсем наоборот.
В исходном состоянии такая перемычка имеет высокое сопротивление, достигающее нескольких миллионов Ом. При подаче напряжения между диффузионным слоем и кремниевой шиной(на рисунке — gate) приводит к возникновению в оксиде туннельного эффекта Фаулера-Нордгейма и прямого туннельного эффекта. Это приводит к возрастанию токов утечки и soft breakdown(обратимого пробоя). Если убрать электрическое поле, то сопротивление диэлектрика востановится. В противном случае токи будут возрастать и это приведет в конечном счете к тепловому(необратимому) пробою диэлектрика, образованию проводящего канала и резкому возрастанию тока через него. Этот сценарий носит в западной литературе название hard breakdown.
Параметры состояния перемычки после пробоя должны сохраняться около 40 лет. Малые сопротивления и малые паразитные емкости перемычек типа antifuse положительно влияют на скорости распространения сигналов в программируемых связях.
Под Mask имеется в виду программирование нанесением на кристалл-полуфабрикат 1-2 верхних слоя металлизации с последующим травлением.
А теперь после затянувшегося вступления перейдем, собственно, к теме обозначенной в заголовке. Устройства PLD в зависимости от количества вентилей, архитектуры и особенностей технологии программирования могут отнесены к классам, представленным на схеме ниже
Базовый матричный кристалл (БМК)
В терминологии принятой на Западе известны также как HAL(Hard Array Logic) или же Structured ASIC. Что то среднее между заказными интегральными схемами и PLD. С первыми роднит то, что программирование осуществляется технологически. Со вторыми то, что на одном кристалле можно получить самые разные цифровые устройства.
Программирование осуществляется нанесением с последующим травлением 1-2 слоев металлизации на кристалл-полуфабрикат с нескоммутированными ячейками. Разработчики аппаратуры, построенной с применением FPGA имеют возможность их замены на БИС на основе БМК, получив при этом, в ряде случаев, заметный экономический эффект и увеличив плотность компоновки аппаратуры. Для обеспечения такой переработки производители разрабатывают САПРы, позволяющие производить автоматизированный перевод проектов, выполненных на ПЛИС в базис библиотек БМК.
Могут включать до 100 000 вентилей и работать на частотах до 50МГц. Операционный цикл составляет около 3-х месяцев.
В настоящее время почти полностью вытеснены FPGA и CPLD. Однако применяются в мелкосерийном производстве в виду своей дешевизны по отношению к заказным микросхемам. Выпускается отечественным ОАО Ангстрем, НПО Физика и некоторыми другими предприятиями.
Programmable Array Logic(PAL)
Так же называется Generic logic array(GAL). Впервые разработаны компанией Monolithic Memories(в настоящее время входит в Lattice Semiconductor) и появились на рынке аж в марте 1978.
Состоит из логики ввода-вывода и ядра, которое представляет из себя хорошо известную всем нам EPROM или EEPROM. Используются для создания кобинационных логичеких схем. Для проргаммрования PAL сущестовали специальные языки программирования как PALASM, ABEL, CUPL. Ранние PAL производились по биполярной технологии с однократным программированием посредством пережигания титано-вольфрамовых перемычек(fuses). Более поздние — по КМОП-технологии. Состоят из десятков-сотен вентилей.
Как и БМК в настоящее время вытеснены более совершенными устройствами, однако все еще применяется в изделиях специального назначения, например в военной технике. Выпускаются фирмой Atmel
Programmable logic array(PLA)
Отличается от предыдущего класса тем, что в них программируется как массив OR, так и AND. Из за этого — более сложные схемы и стоимость выше, чем у PAL. В силу того, что программируются оба массива, скорость ниже, чем в случае PAL.
Complex Programmable Logic Device(CPLD)
Технология программируемых логических устройств со сложностью, занимающей диапазон примерно между PAL (Programmable Array Logic) и FPGA (Field-programmable gate array), и с сочетанием их архитектурных особенностей.
Устройство CPLD включают в себя тысячи – десятки тысяч ячеек, имеют хорошо предсказуемые задержки прохождения сигнала. От FPGA отличает наличие энергонезависимой перепрограммируемой памяти, те для первоначальной загрузки не требуются микросхемы конфигурационной памяти, как в случае FPGA. Поэтому ресурс перепрограммирования меньше чем в случае последних(не менее 1 000 циклов запись/стирание для семейства Xilinx CoolRunner-II).
Структура CPLD представляет собой совокупность функциональных блоков, объединяемых матрицей переключений Global Routing Pool. Архитектура функциональных блоков(Generic Array Logic) во многом подобна архитектуре универсальных PAL. Отличия заключаются в том, что все выходные макроячейки(Macrocells) имеют две обратные связи, а промежуточные шины макроячейкам назначаются с помощью распределителя (Logic allocator). Некоторые макроячейки CPLD не имеют связи с внешним выводом. Такие макроячейки называются скрытыми. Скрытые макроячейки имеют только одну обратную связь.
Внешние выходы CPLD связываются с выходом макроячейки при помощи еще одной матрицы межсодинений ORP(Output Routing Pool). Эта же матрица связывает входную логику с GRP. Для уменьшения задержек в некоторых CPLD предусматриваются Direct input входы связанные напрямую со входами макроячеек.
Field-Programmable Gate Array(FPGA)
Несмотря на различия между FPGA различных семейств и различных производителей, включенные в их состав вкусности вроде блоков DSP и процессорные ядра, общие принципы архитектуры FPGA остаются неизменными.
Основной функциональной единицей FPGA является CLB(Configurable Logic Block). Коммутация CLB осуществляются посредством S блоков и С блоков(connection box). CLB в свою очередь может включать в себя несколько LUT(Look-up table). У фирмы Xilinx CLB еще состоят из так называемых Slices, которые тоже в свою очередь состоят из LUTов. Зачем так все усложнять? Дело в том, что есть различные виды секций Slice, LUTы которых обладают различной функциональностью.
В FPGA семейств Virtex-6 и Spartan-6 CLB состоит из 2-х секций их 3 вида: SLICEM, SLICEL и SLICEX. В семействе Spartan-6 один CLB состоит из SLICEL и SCLCEX, а второй из SLICEL и SLICEM. У Virtex-6 все выглядит немного по-другому — один имеет в составе 2 секции SLICEL, а второй — SLICEL и SLICEM. При этом каждая секция в CLB подключена к отдельной цепи переноса.
Рассмотрим каждую из этих секций.
SLICEM состоит из 4 LUT, включает в себя логику ускоренного переноса, таблицы преобразования, конфигурируемые как распределенная память и SRL(Shift register lookup table), и мультиплексоры расширения количества булевых аргументов
SLICEL состоит из 4 LUT, включает в себя логику ускоренного переноса и мультиплексоры расширения количества булевых аргументов
SLICEX состоит из 4 LUT, только логика. Никакой распределенной памяти, цепей переноса и мультиплексоров расширения.
Как же все это соединить вместе? Для этого компания Xilinx разработала архитектуру ASMBL(Application Specific Modular Block Architecture). Если коротко, то одинаковые блоки, такие как DSP, блочная память, встроенные IP-блоки или логические секции располагаются в одном ряду. Путем комбинации таких рядов и получаются специализированные для различных применений FPGA(например, Virtex-6 бывают LXT, SXT и HXT).
Блоки ввода-вывода современных FPGA поддерживают свыше 40 разных протоколов с различными напряжениями, такие как: LVCMOS, LVDS, Bus LVDS, LVPECL, SSTL, HSTL, RSDS_25(point-to-point), PCI, I2C и другие. Выводы FPGA объединяются в банки по 30-80 выводов в каждом, выводы каждого банка могут поддерживать различные группы стандартов.
Использованные источники
- В. Соловьев, А. Климович, Введение в проектирование комбинационных схем на ПЛИС.
- Daniel Gomez-Prado, Maciej Ciselsky, A tutorial on FPGA routing.