
Сегодня нас окружает огромное количество неструктурированных данных, которые до недавнего времени было немыслимо обработать. Примером таких данных могут служить, например, данные метеодатчиков, используемые для точного прогноза погоды. Более структурированные, но не менее массивные датасеты – это, например, спутниковые снимки (алгоритмам обработки снимков c помощью машинного обучения даже посвящен ряд статей у сообщества OpenDataScience). Набор снимков высокого разрешения, допустим, на всю Россию занимает несколько петабайт данных. Или история правок OpenStreetMap — это терабайт xml. Или данные лазерного сканирования. Наконец, данные с огромного количество датчиков, которыми обвешано множество техники – от дронов до тракторов (да, я про IoT). Более того, в цифровую эпоху мы сами создаем данные, многие из которых содержат в себе информацию о местоположении. Мобильная связь, приложения на смартфонах, кредитные карты – все это создает наш цифровой портрет в пространстве. Множества этих портретов создают поистине монструозные наборы неструктурированных данных.
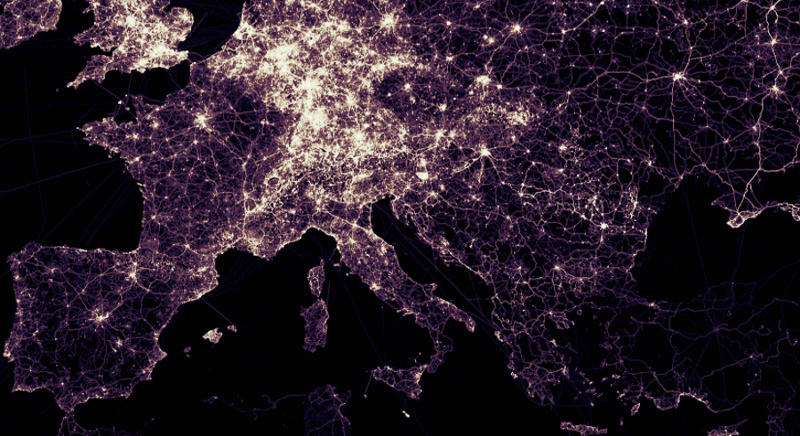
На рисунке — визуализация треков OpenStreetMap с помощью GeoWave
Где стык ГИС и распределенных вычислений? Что такое «большие геоданные»? Какие инструменты помогут нам?
Здесь к месту упомянуть немного заезженный, но все еще не лишившийся смысла термин BigData, Большие Данные. Расшифровка этого термина зачастую зависит от личного мнения расшифровывающего, от того, какие инструменты и в какой сфере он использует. Часто BigData используется как всеохватывающий термин для описания технологий и алгоритмов для обработки больших массивов неструктурированных данных. Часто основная идея – это скорость обработки данных за счет использования алгоритмов распределенных вычислений.
Помимо скорости обработки и объема данных, существует еще аспект «сложности» данных. Как разделить сложные данные на части, «партиции» для параллельной обработки? Геоданные изначально относились к сложным данным, и с переходом к «большим геоданным» эта сложность возрастает практически экспоненциально. Соответственно, важной становится не просто обработка миллиардов записей, а миллиардов географических объектов, которые являются не просто точками, но линиями и полигонами. К тому же, зачастую требуется вычисление пространственных взаимоотношений.
Пространственное партицирование
На помощь нам приходит пространственная индексация, и зачастую классические методы индексации здесь слабо применимы. Для индексации двумерного и трехмерного пространства существует немало подходов. Например, знакомые многим геодезические сети, деревья квадрантов, R-деревья:
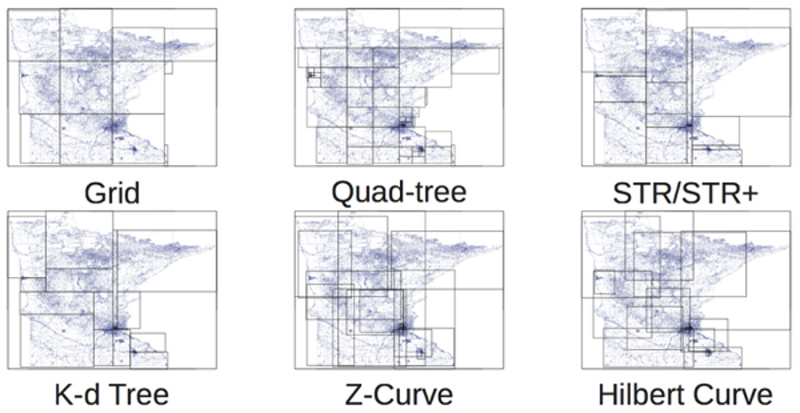
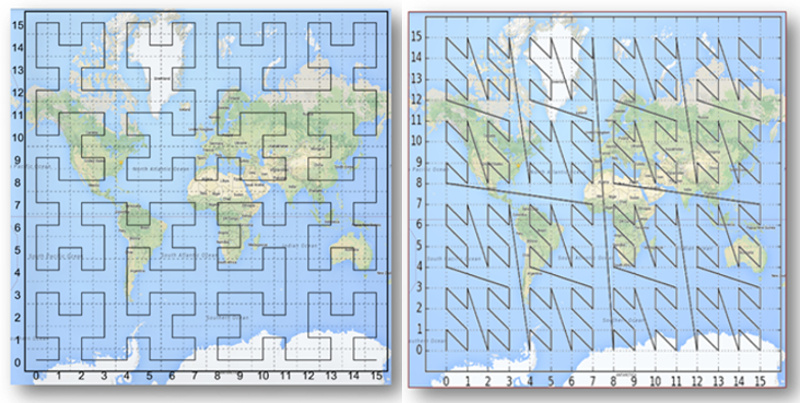
Одним из наиболее интересных методов является многообразие «заполняющих пространство кривых», Z-Curve и Gilbert Curve на рисунке выше. Первооткрывателем этих кривых был Джузеппе Пеано. Основная идея заключается в том, чтобы превратить многомерное пространство в одномерное с помощью кривой, которая фрактально заполняет собой все пространство. Вот, например, так кривая Гильберта заполняет собой плоскость:

А вот так эти кривые выглядят на земной поверхности:
Взяв на вооружение эти индексы, мы можем, наконец, прийти к партицированию геоданных. Нужно ли нам заново изобретать методики? К счастью, нет! На помощь нам приходят уже существующие фреймворки. Их немало, каждый из них имеет свою применимость и свои сильные стороны. Ниже я расскажу о наиболее примечательных.
GeoJinni (в прошлом SpatialHadoop)

GeoJinni (прежде называвшийся SpatialHadoop) – крайне интересное расширение для Hadoop, добавляющее геопространственные функции в различные слои и компоненты Hadoop для хранения, обработки и индексации больших геоданных. Если быть точным, то расширение затрагивает слои MapReduce и хранения, а также добавляет свой собственный операционный слой.
На самом нижнем уровне добавляется новый тип данных, позволяющий хранить и обрабатывать геоданные как ключ-значение. Также добавляются инструменты для загрузки и выгрузки различных форматов геоданных. В противовес классической структуре (точнее, ее отсутствию) хранилища Hadoop, GeoJinni создает два слоя индексного пространства, локальный и глобальный. Глобальный индекс позволяет партицировать данные по нодам кластера, локальный же отвечает за партиции на каждый ноде. Эта концепция позволяет использовать три типа индексов – Grid, R-tree и R+-tree. Все индексы строятся по запросу пользователя и размещаются непосредственно в HDFS.
GeoJinni устанавливается как расширение к уже существующему кластеру Hadoop, что не требует сборки кластера заново. Расширение может быть без проблем установлено в различных дистрибутивах Hadoop, например, Apache Hadoop, Cloudera или Hortonworks.
GeoMesa

Основой для хранения массивных наборов данных являются распределенные колоночные типы хранение, такие как Accumulo, HBase, Google Bigtable. Это позволяет быстро обращаться к этим данным через запросы с использованием расстояний и площадей. Также GeoMesa позволяет обрабатывать данные практически в реальном времени через специальный слой для системы потоковых сообщений Apache Kafka.
Наконец, с помощью подключения к ГИС-серверу GeoServer GeoMesa предоставляет доступ к своим потоковым сервисам через OGC протоколы WFS и WMS, что дает большой простор для пространственно-временных анализа и визуализации, от карт до графиков.
GeoWave

Предоставляет для Accumulo мультипространственные индексы, стандартные географические типы и операции, а также возможность обработки облаков точек PDAL. Обработка данных происходит через расширения для MapReduce, а визуализация через плагин к GeoServer.
Очень похож в своей концепции с GeoMesa, использует те же хранилища, но сосредоточен не на пространственно-временных выборках, а на визуализации многомерных массивов данных.
GeoTrellis

GeoTrellis отличается от своих собратьев. Он задумывался не как инструмент для работы с большими массивами геоданных, а как возможность утилизации распределенных вычислений для максимальной скорость обработки даже стандартных объемов геоданных. В первую очередь, речь идет об обработки растров, но за счет эффективной системы партицирований стало возможно выполнять и пространственные операции, и конвертацию данных. Основными инструментами разработки являются Scala и Akka, инструментом распределенной аналитики – Apache Spark.
Глобальная цель проекта – предоставление отзывчивого и богатого инструментария на уровне веб-приложения, что должно изменить пользовательский опыт в использовании систем распределенных вычислений. В конечном итоге, развитие экосистемы открытых геотехнологий, где GeoTrellis дополнит PostGIS, GeoServer и OpenLayers. Основными целями команда разработки ставит следующие:
- Создание масштабируемых высокопроизводительных веб-геосервисов
- Создание распределенных геосервисов для обработки «больших геоданных»
- Максимальная параллелизация процессов обработки данных
GeoTrellis – прекрасный фреймворк для разработчиков, предназначенный для создания отзывчивых и простых REST-сервисов для обращения к моделям геопроцессинга. Оптимизация и параллелизация производится самим фреймворком.
GIS Tools for Hadoop

Наборы инструментов от Esri хотя формально и являются открытыми, но их применение имеет смысл в первую очередь с продуктами Esri. По концепции очень схожи с GeoJinni.
Инструменты разделены на три уровня
- Esri Geometry API for Java. Библиотека для расширения Hadoop геопространственными абстракциями и операциями
- Spatial Framework for Hadoop. Расширение для использования геопространственных запросов в Hive Query Language
- Geoprocessing Tools for Hadoop. Непосредственно средства интеграции Hadoop и ArcGIS, позволяющие выполнять операции распределенного пространственного анализа в настольном и серверном приложениях.
Что дальше?
Геоданные всегда были где-то рядом с большими данными, и приход инструментов распределенных вычислений позволяет делать действительно интересные вещи, позволяя не только географам, но и аналитикам данных (или как их модно называть, Data Science), совершать новые открытия в области анализа данных. Мгновенные моделирование затоплений, создание линий горизонта, пространственная статистика, анализ населения, создание трехмерных моделей из облаков точек, анализ спутниковых снимков.
Следующие статьи я посвящу инструментам и сфере их применения. Ваши комментарии могут помочь нам в проработке тем для следующих статей.
- О каком из фреймворков вы бы хотели прочитать первым?
- О каком применении распределенных вычислений вы бы хотели узнать подробнее?
Комментарии (10)

Oberst
14.06.2017 14:59+1Не совсем ясно, почему геоданные отнесены автором к «неструктурируемым». По-моему, более структурированную информацию, чем массивы координат, придумать сложно: ограниченное количество форматов, строгая кластрификация и другие формальные вещи существенно облегчают работу с ними.

fall_out_bug
14.06.2017 15:13К «неструктурируемым» данным относятся не сами «координаты», а организация исследуемых процессов в пространстве, топология массивов координат, отношения и связи. Имея разнородные датчики в метеоданных, мы должны аккуратно совместить данные (а они могут быть еще и в разных структурах) и провести интерполяцию исследуемых параметров.
Более того, описание координат сложных объектов (линия, полигон, мультиобъекты, подписи, составные объекты) имеет различие в разных форматах передачи геоданных. В csv-файле сложно передать линии и полигоны, shp-файлы не содержат подписи и отношения, формат sxf (Панорама) представляет объектную структуру с отдельно описываемым «классификатором», а gdb-файлы (ArcGIS) являются классическими реляционными базами. Структура OSM еще более отличается от данных Панорамы и ArcGIS.
И я не говорю про системы координат, это дивный мир без гарантий соответствия обратного пересчета пар координат :)Oberst
14.06.2017 15:23Пересчёт координат с гарантированной точностью определяется ГОСТ Р 51794-2008. Я пользовался, пока не подводил.
А усложнить самому себе можно любую задачу, было бы желание :).fall_out_bug
14.06.2017 15:31Так вот именно, что при использовании этих формул образовывается погрешность, и при обратном пересчете можно и не получить те же самые исходные координаты. А если речь идет о других референц-эллипсоидах?..
Предпосылки к переходу на распределенное хранение и вычисление должны быть весьма весомыми. Задачи попадаются разные, я и не говорю о том, что gpx-треки с бытового навигатора надо сразу на HDFS кидать :)Oberst
14.06.2017 16:15За точность пересчёта координат по ГОСТ отвечает его разработчик: 29 НИИ Минобороны. А за ошибки при использовании других подходов отвечает тот, кто использует непроверенные разработки :(
fall_out_bug
14.06.2017 16:19В самом ГОСТе есть оговорка о погрешностях пересчета. Пересчет координат один-в-один туда-обратно никто не гарантирует, увы.
Contrius
15.06.2017 12:21+1Не совсем понятно почему были выбраны именно эти продукты и решения из всей массы. В этой подборке есть безусловные лидеры для решения узких задач, а есть некие рудименты. И несколько хороших продуктов осталось за бортом
fall_out_bug
15.06.2017 12:22Это довольно популярные решения, и ни одно из них я бы не назвал рудиментом. Можно примеры хороших продуктов, оставшихся «за бортом»?
Zverik
Не очень понятен смысл статьи и для кого она написана. Если коротко, она сводится:
— OpenStreetMap — это терабайт xml.
— С пространственными BigData работать сложнее, чем с обычными.
— Есть шесть алгоритмов пространственного партицирования, два из них интересны, но к чёрту подробности.
— Есть пять фрейморков для обработки данных, но вместо предметного сравнения вот список слов латиницей для каждого.
— Хотите ещё одну такую же статью? Выберите случайное слово.
На мой взгляд, в этой статье четыре-пять полноразмерных статей схлопнуты до состояния каши из терминов. Мне интересна обработка геопространственных больших данных, но даже после второго перечитывания я всё равно ничего не понимаю.
fall_out_bug
Ты абсолютно прав, это сжатая обзорная статья. Это разведка :) Со временем как раз и будут 4-5 статей. Напиши, о чем тебе интереснее почитать в первую очередь?