
Хранение резервных копий является неотъемлемой частью процедуры резервного копирования. Традиционно для этого использовались два уровня хранения: диски + ленты. Но заказчики при строительстве новых инфраструктур и обновлении старых отказываются от использования ленточных библиотек в пользу только дисковых систем. Это связано не столько с понижением стоимости дисков, сколько с повышением эффективности хранения виртуальных инфраструктур за счёт дедупликации и сжатия, интеграции процесса резервного копирования виртуальных сред с системами хранения, на которых размещаются виртуальные среды, а также за счет возможности практически мгновенного восстановления виртуальных машин напрямую из резервной копии, лежащей на дисковой библиотеке.

СХД для резервного копирования — это программно-аппаратный комплекс. Главная особенность данных массивов — дедупликация и сжатие данных. При этом, у нас появляется возможность хранить на дисках больше резервных копий, увеличивая глубину хранения на более быстрых носителях, чем ленты. Мы получаем возможность полностью отказаться от ленточных носителей в пользу дисков за исключением тех случаев, когда требуются отчуждаемые носители.
Также очень важной особенностью является то, что мы имеем возможность приобрести отдельно именно программную часть этого комплекса в качестве виртуальной системы (Virtual Server Appliance (VSA) у HPE и Virtual Edition (VE) у Dell/EMC), который вы можете развернуть в собственной виртуальной инфраструктуре и использовать уже имеющуюся СХД или любую другую по вашему выбору. К слову сказать, использование виртуальной системы не накладывает каких-то ограничений на используемую СХД и совершенно не важно, как она подключена к нему: по FC или iSCSI. Традиционно для этих задач используют недорогие NL-SAS диски. Они достаточно объёмны и дёшевы для этих целей и кроме того обеспечивают высокую скорость на последовательных операциях записи/чтения, которыми и характеризуется процесс резервного копирования.
Нашей целью было исследование решений с точки зрения возможностей сжатия и дедупликации данных. Мы не ставили задачу тестировать производительность. При этом тестирование проводилось на продуктивных виртуальных машинах Linux и Windows, которые располагаются в нашем облаке.
Но окунёмся немного в историю. В 2001 году была создана компания Data Domain, которая занялась созданием дискового хранилища, которое бы обладало возможностями по сжатию данных и при этом превосходило по своим характеристикам ленточные библиотеки. Продукт получился настолько интересным и качественным, что такие ведущие вендоры, как NetApp и EMC, захотели компанию Data Domain приобрести. В итоге в 2009 году ставка EMC оказалась выше, и она приобрела компанию Data Domain. В дальнейшем компания EMC полностью интегрировала Data Domain в свою платформу Data Protection Suite.
Компания HPE пошла иным путём и в 2010 году представила собственный подход к дедупликации на конференции HP Technology Forum. Технология была разработана подразделением HPE Labs и названа StoreOnce. Она применялась в массивах того времени — StorageWorks D2D, в которых до этого использовалось ПО сторонних разработчиков. В 2012 году линейку StorageWorks D2D заместили линейкой с одноимённым названием StoreOnce, под которым она существует и по сей день.
К слову, на рынке дисковых библиотек есть ещё и компания Quantum, у которой есть линейка продуктов DXi-V. Она существует только в виде программно-аппаратного комплекса, и поэтому в нашем сегодняшнем сравнении не участвует. Также есть компания ExaGrid, которая ещё с 2002 года занимается разработкой подобных решений с собственным протоколом, но на российском рынке практически не представлена.
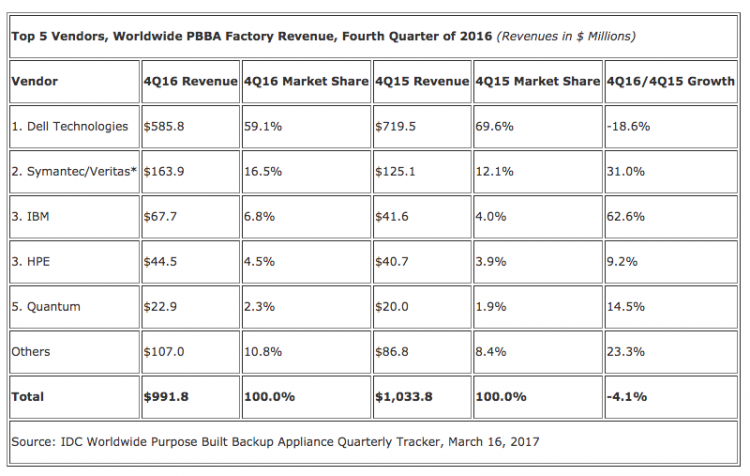
По данным IDC на конец 2016 года, компания Dell/EMC занимала около 60% мирового рынка систем резервного копирования, что в несколько раз превосходит показатели основных конкурентов.

Источник
{kind=link}
Основные результаты проделанной нами работы по сравнению функциональных возможностей виртуальных систем компаний Dell/EMC и HPE представлены в таблице.

Хочется сразу отметить, что больший максимальный объём виртуальной системы у Dell/EMC является плюсом. Конечно, вы можете приобрести и развернуть их несколько, но дедупликация будет работать только в рамках одной виртуальной системы. Поэтому её больший объём является несомненным преимуществом в данном случае. Это позволит экономить место ещё более эффективно.
Если же у вас не очень большие объёмы данных резервных копий или вы хотите развернуть виртуальную систему в качестве тестового стенда, то тут уже более интересно решение от HPE, ввиду того, что бесплатный объём его составляет 1Tb и по условиям лицензионного соглашения может использоваться в продуктивных средах (но без возможности его обновления). В свою очередь Dell/EMC предоставляет только 500Gb бесплатного объёма (во всех случаях речь идёт о полезном объёме) и не может использоваться в продуктивных коммерческих средах. Версия на 50Tb от HPE доступна для тестирования в течение 60 дней.
Также эти системы позволяют организовать многоуровневое хранение данных посредством перемещения резервных копий в облако. Cloud Tier от компании Dell/EMC позволяет расширить объём системы в несколько раз, при этом поддерживает шифрование. Может работать как с облачными сервисами от самой Dell/EMC, так и с Amazon S3 и Azure Storage. Подробнее об этом можно узнать из ролика Dell/EMC.
Аналогичный функционал от HPE называется HPE StoreOnce CloudBank и работает с облаками Azure и Amazon. Рекомендую ознакомиться с их роликом.
Если вы планируете использовать аппаратное решение от HPE или Dell/EMC, вендор очень рекомендует использовать виртуальную систему в тестовых целях, для понимания какой уровень дедупликации/компрессии вы сможете получить именно на ваших продуктивных данных. Это нужно и для понимания эффективности решения в вашей среде в целом, и для более точного сайзинга системы.
Основной killer-фичей данных решений является наличие протокола передачи данных, позволяющего дедуплицировать данные на сервере резервного копирования, и тем самым передавать только уникальные блоки данных.

Это позволяет увеличивать общую скорость резервного копирования, т.к. не уникальные блоки просто не передаются на массив. Эта возможность требует отдельной лицензии как у HPE, так и у Dell/EMC.
Мы развернули на нашем тестовом стенде Data Domain Virtual Edition и HPE StoreOnce Virtual Storage Appliance. В качестве датасторов для этих виртуальных систем у нас служил lun (лун) на массиве IBM Storwize V7000 с NL-SAS дисками, подключенный к хосту гипервизора по протоколу Fibre Channel. Наша виртуальная инфраструктура построена на базе VMware, с нодами нашего кластера виртуальные системы связывались через LAN.
Еще раз отмечу, что в данном случае мы не ставили перед собой цель получить максимальную производительность. Нас интересовал именно уровень экономии дискового пространства за счет дедупликации и сжатия, т.к. имеющаяся в нашем распоряжении тестовая среда не совсем подходит для поиска максимальной производительности системы резервного копирования.
Сравнивать будем между собой три варианта:
- ПО для резервного копирования Veeam + СХД DataDomain по протоколу DDBoost,
- ПО для резервного копирования Veeam + СХД StoreOnce по протоколу Catalyst,
- Veeam с собственной встроенной дедупликацией.
Почему был выбран Veeam в качестве ПО для резервного копирования? Я работаю с этим продуктом уже около трех лет: компания «Онланта» имеет партнёрский статус Veeam. Также это ПО крайне просто разворачивать, и без какого-либо дополнительного тюнинга оно способно выдавать максимальную скорость, в чём мы уже убеждались на собственном опыте. Да и качество работы службы поддержки Veeam всегда было на высоте.

Скорость резервного копирования в SAN-сети 8 Гб/с
Вообще третий вариант добавлен больше для показательности эффективности дедуплицирующих средств хранения в принципе. Никто и не надеется, что Veeam будет на уровне HPE или Dell/EMC. Но мне было интересно сравнить между собой и различные уровни сжатия, которых в Veeam всего пять, начиная от полного отключения и заканчивая Extreme. Следует также отметить, что Veeam выполняет дедупликацию в рамках одной сессии, что, естественно, менее эффективно. Мы выполняли полное резервное копирование, потом несколько дней инкрементальное копирования и затем снова полное.
Тест: Базы данных
Мы взяли несколько продуктивных виртуальных машин с различными базами данных на Windows и Linux. Общий объём виртуальных машин составил 2,5 Тбайт.

Тест: Терминальные серверы
Здесь ситуация аналогична предыдущему тесту. Только все серверы соответственно были на Windows платформе. Общий объём VM составил 2,2 Тбайт.

Как и ожидалось, эффективность виртуальной системы оказалась выше, чем у Veeam. 1:5 — вполне неплохой показатель, тем более что он достаточно стабильный на сжимаемых типах данных. Естественно, при большей глубине хранения резервных копий этот показатель будет расти ещё выше.
Ещё из приятного
Помимо того, что оба этих продукта могут работать с традиционными системами резервного копирования, они также могут взаимодействовать через плагины и с некоторыми системами напрямую. К таким относятся:
- Oracle RMAN,
- MS SQL,
- SAP HANA,
- SAP w/Oracle.
Это и удобно, и экономично, и исключает лишнее ПО, участвующее в процессе резервного копирования.
Отказоустойчивость
Во время тестирования мы проверяли системы в том числе и на отказ в случае потери хранилища, на котором они располагались. В результате обе VM «упали» и после перезагрузки не поднялись. Вероятнее всего, отказ связан с потерей Write-back кэша массива из-за его горячего отключения.
Скриншоты ошибок после перезагрузки
DataDomain

StoreOnce

У нас есть три варианта решения проблемы отказоустойчивости.
- Самый дорогой — переход на аппаратную реализацию, которая лишена проблемы потери/неконсистентности данных в случае пропадания питания. Диски находятся непосредственно в самой системе, а не реализованы внешними решениями.
- Самый простой — снепшоты VM или резервное копирование. Тут всё просто — сломалась виртуалка, откатили, продолжили работать. Но в данном случае мы теряем информацию о бэкапах, сделанных с момента последнего бэкапа самой виртуальной системы.
- Репликация на второй массив. Т.е разворачиваем две виртуальные копии системы, которые будут жить на разных стораджах, выполняем репликацию между ними. Здесь может быть и «гибридный» вариант и одна из систем, участвующих в репликации может быть физической. Таким образом можно организовать централизование надёжное хранение резервных копий филиалов в надёжном цоде.
На мой взгляд, именно репликация является наилучшим способом защиты данных. Их можно и стоит разнести не просто по разным вычислительным кластерам и разным СХД, но и по разным площадкам. В итоге у нас будет три копии данных, которые позволят восстановиться в случае любых проблем.
В заключение стоит подчеркнуть, что я сознательно не делаю выводов, какое решение лучше, какое выбрать. Продукты очень сильно похожи, и их исследование дало очень близкие конечные результаты. Стоит отталкиваться от конечной цены продуктов, от тех массивов, что у вас уже имеются в инфраструктуре, от ПО для резервного копирования, которое вы уже используете (не все продукты поддерживают оба протокола) и от личных предпочтений или знакомства с оборудованием вендора.
Надеюсь сегодняшний обзор помог вам лучше познакомиться с данным типом устройств и понять их необходимость в вашей инфраструктуре.
Комментарии (32)

lovecraft
14.06.2017 13:48Вероятнее всего, отказ связан с потерей Write-back кэша массива из-за его горячего отключения
Простите, то есть кэш на запись есть. а его батарейной защиты нет?
KorP
14.06.2017 13:53Батарейки в массиве конечно же есть. Честно сказать — расследования, что именно привело к отказу виртуалки никто не проводил, да и суть была не в этом, а в том, что бы понять — какими средствами можно защитить данную систему от выхода из строя.

Tomatos
16.06.2017 20:58Упала виртуальная машина, причем, из-за отвала SAN-диска, чем тут батарейка поможет?

evros
14.06.2017 14:46-1Юзаем DD2200, есть там DD VTL
KorP
14.06.2017 14:47В статье говорится о DD VE, который не поддерживает VTL, аппаратные же решения — да, поддерживают.
FlashHaos
15.06.2017 00:25Стоит уточнить это в названии поста, ведь вы не сравнивали настоящие дд со сторвансом на самом деле.
KorP
15.06.2017 05:59С точки зрения вендора — они самые настоящие :) Просто есть разница между аппаратной реализацией и программной. Ну а в посте ни слова не сказано о железе и указано что именно мы разворачивали для тестирования.

krids
14.06.2017 18:55+1Спасибо за интересный пост.
Кстати, у DellEMC для DD VE есть готовые конфигурации на базе сервера R730 c локальными HDD. Выглядит интересно. Дюже любопытно было бы у видеть тест производительности по сравнению с железным DD в одинаковой конфигурации по дискам.
Есть еще IBM ProtectTIER, но он, похоже, «скорее мертв, чем жив». А виртуальной его версии IBM так и не сподобилась сделать.
Смущает во всей этой дедупликационной идеологии РК один момент (если я все правильно понимаю): получается, что мы целиком и полностью зависим от самого первого бекапа. Если его по какой-то причине профукали, то никаких бекапов по сути больше нет. Это так? Есть ли в таких дедупликаторах возможность делать независимые «настоящие» фулл-бекапы, скажем, по требованию?
А вариант отдельно стоящей и доступной по NFS СХД Netapp c инлайн-дедупом и компрессией стоит рассматривать как альтернативу DD/StoreOnce?Tomatos
16.06.2017 21:03Кажется, вы перепутали инкрементальный бэкап с дедупликацией. Дедупликация никак не влияет на содержимое бэкапа — это лишь способ его хранения.
По поводу НетАпп-а тоже было бы интересно посмотреть сравнение — очень они хвалят свою дедупликацию.Tomas_Torquemada
19.06.2017 08:38+1По поводу НетАпп-а тоже было бы интересно посмотреть сравнение — очень они хвалят свою дедупликацию.
Не бекап — работающие виртуальные машины на All-Flash'е NetApp'овском. Но для примера пойдёт, думаю.
Datastore Cluster : *****_AFF
Capacity (GB) : 9600
Used Space (GB) : 27816,58
Provisioned Space (GB) : 28130,67
Provisioned / Capacity ratio : 2,93
Storage Overcommit (%) : 193,03
Tomas_Torquemada
19.06.2017 08:43Сорри, посчитал криво.
Вот правильные цифры:
По поводу НетАпп-а тоже было бы интересно посмотреть сравнение — очень они хвалят свою дедупликацию.
Не бекап - работающие виртуальные машины на All-Flash'е NetApp'овском. Но для примера пойдёт, думаю.
Datastore Cluster : *****_AFF
Capacity (GB) : 4802
Used Space (GB) : 27816,58
Provisioned Space (GB) : 28130,67
Provisioned / Capacity ratio : 5,85
Storage Overcommit (%) : 585,81
kaza4len
19.06.2017 12:12не думаю, что есть смысл сравнивать All-Flash Netapp с данными продуктами. Тут уместнее брать аналогичную поделку от Нетаппа — Altavault
Tomas_Torquemada
19.06.2017 12:43Я ничего не сравниваю — просто показал на живом примере, какого коэффициента дедупликации удаётся достичь на работающих ВМ, лежащих на NetApp'е.
На Altavault, как и нам любом современном DD, полагаю, будут больше значения — там оффлайновые данные, которые сам девайс порубит на удобные ему блоки.
KorP
14.06.2017 19:01Дюже любопытно было бы у видеть тест производительности по сравнению с железным DD в одинаковой конфигурации по дискам.
Я бы не отказался, но пока моё сотрудничество с Dell/EMC не очень перспективно, к сожалению.
Есть еще IBM ProtectTIER, но он, похоже, «скорее мертв, чем жив».
Я пока вообще не очень представляю перспективы IBM. Watson — да, ПО вокруг него — да, что то иное — под вопросом.
зависим от самого первого бекапа
Если мы говорим с точки зрения ПО для РК, то да, если мы говорим с точки зрения хранения блоков данных на таких массивах, то в них имеются технологии, отвечающие за целостность данных (блоков) и тут можно не переживать. С точки зрения ПО для РК — никто не запрещает делать постоянно фульники, с учётом как раз Catalyst/DDboost — это очень эффективно, т.к. передадутся и запишутся только уникальные блоки. Да, такая процедура РК будет проходить дольше, чем инкрементные, но и надёжность выше.
А вариант отдельно стоящей и доступной по NFS СХД Netapp c инлайн-дедупом и компрессией стоит рассматривать как альтернативу DD/StoreOnce?
Я бы не стал этого делать по двум причинам — скорее всего нетап окажется дороже, тк нужен минимум FAS серии, во-вторых уровень инлайн-дедупа и компрессии там будет ниже (1:2-1:3 по нашим наблюдениям).
crodger
14.06.2017 20:37+1Интересная статья, особенно, полезно, на мой взгляд, было включение в сравнение встроенной дедупликацию средствами самого Veeam. Это хорошая фича для небольших объемов, но результаты на практике показывают, что специализированные устройства (или их виртуальные версии), как Store Once или Data Domain все же работают существенно эффективнее.
По методике тестирования — в случае с терминальными серверами после четвертого инкрементального бэкапа Data Domain сделал очистку — это несколько искажает результаты, тем более, что у HPE он не работал. Не принципиально на таких объемах, но все же.
К разговору про остальные решения на рынке:
Quantum DXi V-Series это как раз и есть виртуальная версия их аппаратного решения DXi. Было бы интересно увидеть их в сравнении, хотя скорее всего значения дедупликации будут примерно теми же.
Есть еще FalconStor VTL (есть в виде виртуальной машины), Hitachi Protection Platform (вроде нет в виде виртуальной машины).serg11
15.06.2017 18:46+1Про остальные решения:
Есть еще одно интересное GRID решение NEC HYDRAstor, которое также имеет виртуальную версию HS VA и свой протокол с дедупликацией на стороне источника UEIO.

Dorlas
15.06.2017 05:31Примерно полгода назад сравнивал Online-дедупликацию HP StoreOnce Virtual Appliance и Offline-дедупликацию на Windows Server 2012 R2.
Хотелось понять — при разном подходе к задаче, какой коэффициент дедупликации я получу на одинаковод наборе данных (дедуплицировал 350 гб образов виртуальных машин в первом тесте, и 220 гб дистрибутивов (ISO-файлы)).
На обоих наборах данных я получал похожие цифры (разница была 3-5%, не более. Но HP StoreOnce VSA сжимал чуть чуть лучше).
Первый набор (виртуалки) у меня сжался в 7,5 раз. Второй (ISO) — в 2,5 раза.
Вообще дедупликацию от Microsoft хорошо использовать для долгосрочного (от полугода) хранения хорошо дедуплицируемых данных. Например — оба описанных набора данных я храню в VHDX-файлах, внутри которых отработала дедупликация.
Пример скрипта, который делает такое, тут:
How-to-store-183-GB-of-VMs-in-a-16-GB-file-using-PowerShell
В случае необходимости — на сервере монтирую VHDX файл, шарю каталог — и мне становятся доступны мои данные. Плюс раз в полгода можно файл обновить и снова дедуплицировать.

ustas33
15.06.2017 15:47Проще на NAS с дедупом и компрессией по NFS бакапить.
Vilko
15.06.2017 20:13+1Объяснять про разницу source и target депупликации и влияние их на загрузку канала нужно?
ustas33
15.06.2017 21:03Дедупить на источнике умеет любой вменяемый софт резервного копирования. Причем тут NAS?
Но это не означает что backup агенты нужно везде рассовывать. По хорошему NAS тоже должен уметь жать и дедупить.KorP
15.06.2017 21:12Такое ощущение, что вы или не читали статью или не поняли весь смысл таких вещей, как Data Domain, StoreOnce и иже с ними. То, что ПО для РК делает хуже, чем специалиализированные средства — статья показывает наглядно. Да и нет ничего хорошего в том, что у вас одни и те же данные дедупятся и жмутся несколько раз разными средствами.
Либо мы говорим просто по совершенно разные объёма РК, раз вас устраивает NAS.ustas33
15.06.2017 21:28В курсе, как работает HPE catalyst, и Data Domain Boost.
Сделать Scalable NAS давно не проблема.
На своём веку я видел в ЦОД десятки заброшенных backup appliance, в том числе DD, без купленных подписок, с старым ПО как дерьмо мамонта.
Меня малость настораживает, зачем облачный провайдер с остервенением тащит в свой ЦОД проприетарщину? Кто будет оплачивать банкет? Госсектор, российский true bloody enterprise?
KorP
15.06.2017 21:35Сделать Scalable NAS давно не проблема.
Никто и не говорил, что это проблема — выгода в этом какая? Чего можно добиться с его помощью?
На своём веку я видел в ЦОД десятки заброшенных backup appliance, в том числе DD, без купленных подписок, с старым ПО как дерьмо мамонта.
Мне кажется, что не только заброшенных backup appliance удалось повидать, но это не имеет никакого отношению к ПО или железу и его эффективности/стоимость/etc., а лишь к его эксплуататорам.
Меня малость настораживает, зачем облачный провайдер с остервенением тащит в свой ЦОД проприетарщину?
Всем срочно перейти на open source и супермикру? :)
Tomas_Torquemada
Настройки Compession Level и Storage Optimization в тестовых заданиях у вас остались по умолчанию?
KorP
Когда вы создаёте задание на РК в Veeam и в качестве целевого устройства указываете сторадж на StoreOnce или DataDomain — он предлагает использовать «оптимальные» для этих стораджей параметры, которые вы тем не менее менять как вам угодно.
Tomas_Torquemada
Вы можете сказать, какие настройки были в тестовых заданиях, результаты которых приведены здесь?
KorP
Compession Level — None, Storage Optimization — Local target (16+)
Tomas_Torquemada
Ясно, спасибо.