

Источник
{kind=link}
Я работаю системным инженером группы облачной интеграции компании «Онланта». Одно из направлений моей деятельности — это исследовательские работы (R&D) по изучению и сравнению новых технологий, которые могли бы помочь нам повысить качество и снизить стоимость облачных услуг OnCloud.ru, предоставляемых «Онлантой». С результатами такого сравнения SDS-решений вы познакомитесь в этой статье.
Тренд к снижению стоимости владения ИТ-инфраструктурой
В крупных организациях системы хранения данных занимают значительную долю стоимости ИТ-инфраструктуры (по оценкам специалистов – до 25%). Эта цифра может существенно вырасти. Причины – рост объема данных и увеличение потребности в емкостях систем хранения данных (СХД), в том числе из-за законов, которые обязывают эти данные хранить. В то же время компании активно стараются экономить ИТ-бюджеты, что вынуждает их находиться в постоянном поиске наиболее выгодных технологических решений, которые бы позволили сократить эти расходы не в ущерб качеству сервиса. Это же относится к хранению и обработке данных.
Требования заказчиков к снижению стоимости владения ИТ-инфраструктурой заставляют поставщиков инвестировать в разработки и предлагать новые технологии. Одна из них — программно-определяемые системы хранения данных (Software-Defined Storage, SDS). Компании начинают задумываться о внедрении SDS, когда процедуры работы с данными становятся неэффективными и их поиск отнимает много времени.

Источник
{kind=link}
Концепция SDS позволяет получить такие преимущества, как:
- абстрагирование от нижнего уровня (аппаратной платформы),
- масштабируемость,
- упрощенная инфраструктура хранения,
- низкая стоимость решений.
Благодаря технологиям SDS можно значительно снизить стоимость СХД и их администрирования. По прогнозам Gartner, к 2020 году 70–80% неструктурированных данных будут храниться на недорогих системах, управляемых с помощью SDS, а уже к 2019 году 70% существующих массивов хранения станут доступны в полностью программной версии.
Когда и зачем нужна SDS
ПО управления СХД должно обеспечивать гибкую организацию хранения данных, а также:
- дедупликацию,
- репликацию данных,
- динамическое выделение емкости,
- снимки данных,
- соблюдение политик хранения.

Источник
{kind=link}
SDS определяют в Storage Networking Industry Association (SNIA, Ассоциация производителей и потребителей систем хранения) как виртуализированную среду хранения данных с интерфейсом управления сервисами, которая должна включать в себя:
- автоматизацию — упрощенное управление, снижающее издержки на обслуживание инфраструктуры хранения данных;
- стандартные интерфейсы — API для управления, выделения и освобождения ресурсов, обслуживания сервисов и устройств хранения;
- виртуализацию путей доступа к данным — блочный, объектный и файловый доступ в соответствии с интерфейсами приложений;
- масштабируемость — изменение инфраструктуры хранения без снижения требуемого уровня доступности или производительности;
- прозрачность — мониторинг потребляемых ресурсов хранения, управление ими и контроль их стоимости.
Отмечу, что для SDS нужен стандартизированный интерфейс управления – такой, как SNIA Storage Management Initiative Specification (SMI-S). Он является составной частью концепции программно-определяемых дата-центров (SDDC). Эта программная логика облачной инфраструктуры хранения и облачных аппаратных платформ может быть элементом и традиционных ЦОД. Сервисы хранения и обработки данных могут выполняться на серверах, специализированных устройствах хранения (storage appliance) или на обеих этих платформах, устраняя традиционные границы.
Сравниваем SDS-решения
Software-Defined Storage предлагают многие вендоры:
- Dell EMC (решения Dell Nexenta, EMC ScaleIO),
- HPE (решение StoreVirtual VSA),
- IBM (решение Spectrum Storage),
- NetApp (решение ONTAP Select),
- VMware (решение vSAN),
- Red Hat (решение Red Hat Storage),
- StoneFly (решения SCVM, SDUS),
- DataCore (решение SANsymphony),
- SwiftStack,
- Pivot3 и др.
Уточню, что решение RedHat Storage представлено двумя продуктами: RedHat Ceph Storage и RedHat Gluster Storage (RH Storage Server). Здесь они подразумеваются оба, но в приведенном ниже сравнении они не участвовали, так как значительно отличаются от других упомянутых решений.
Ceph — не совсем коробочный продукт. Его использование без штата разработчиков достаточно затруднительно, что сделало его неинтересным для нашей компании. Поэтому этого решения нет в сравнительной таблице.
Условно все SDS-решения можно разделить на три категории:
- классические (CEPH, Red Hat Storage Server, EMC ScaleIO),
- на основе традиционных систем хранения (NetApp ONTAP Select, HPE StoreVirtual VSA),
- в составе вычислительных комплексов (VMware vSAN).
Некоторые производители предлагают как комплексные решения, так и программную часть (Huawei, Dell EMC). Это позволяет гибко подходить к подбору продуктов и использовать унаследованное «вычислительное» оборудование для решения менее ресурсоемких задач хранения данных. Еще одной заслугой SDS стала возможность применения в некоторых классических СХД виртуализации дисковых массивов.
Решения архитектурно строятся по двум принципам:
- слабо связанные,
- распределенные (без общих элементов).
В первом случае отказоустойчивость обеспечивается за счет распределенных копий данных, но из-за избыточности коммуникаций между узлами (нодами) снижается скорость записи. Критичным местом является сеть передачи данных, поэтому такие решения обычно реализованы на основе InfiniBand. По такому принципу построены решения VMware vSAN, HPE StoreVirtual VSA, Dell EMC ScaleIO.
В системах без общих элементов данные записываются на один узел, а потом с заданной периодичностью копируются на другие для обеспечения отказоустойчивости. При этом записи не являются транзакционными. Такой подход наиболее дешев. Чаще всего в качестве интерконнекта в нем используется Ethernet. Данная архитектура удобна с точки зрения масштабируемости. Яркий ее представитель — CEPH.
Сейчас многие компании занимаются разработкой как программной SDS (например, Atlantis Computing, Maxta, StarWind, DataCore Software, Sanbolic, Nexenta, CloudByte), так и выпуском комплексных решений (Dell EMC, IBM) или специализированных устройств (Tintri, Nimble, Solidfire).

Из наиболее известных на рынке мы выбрали для сравнения семь решений, которые интереснее всего для задач «Онланты». Это:
- VMware vSAN,
- HPE StoreVirtual VSA,
- NetApp ONTAP Select,
- EMC ScaleIO,
- Huawei Fusion Storage,
- StarWind Virtual SAN,
- Datacore SANsymphony.
В этой таблице мы сравнили их основные характеристики.
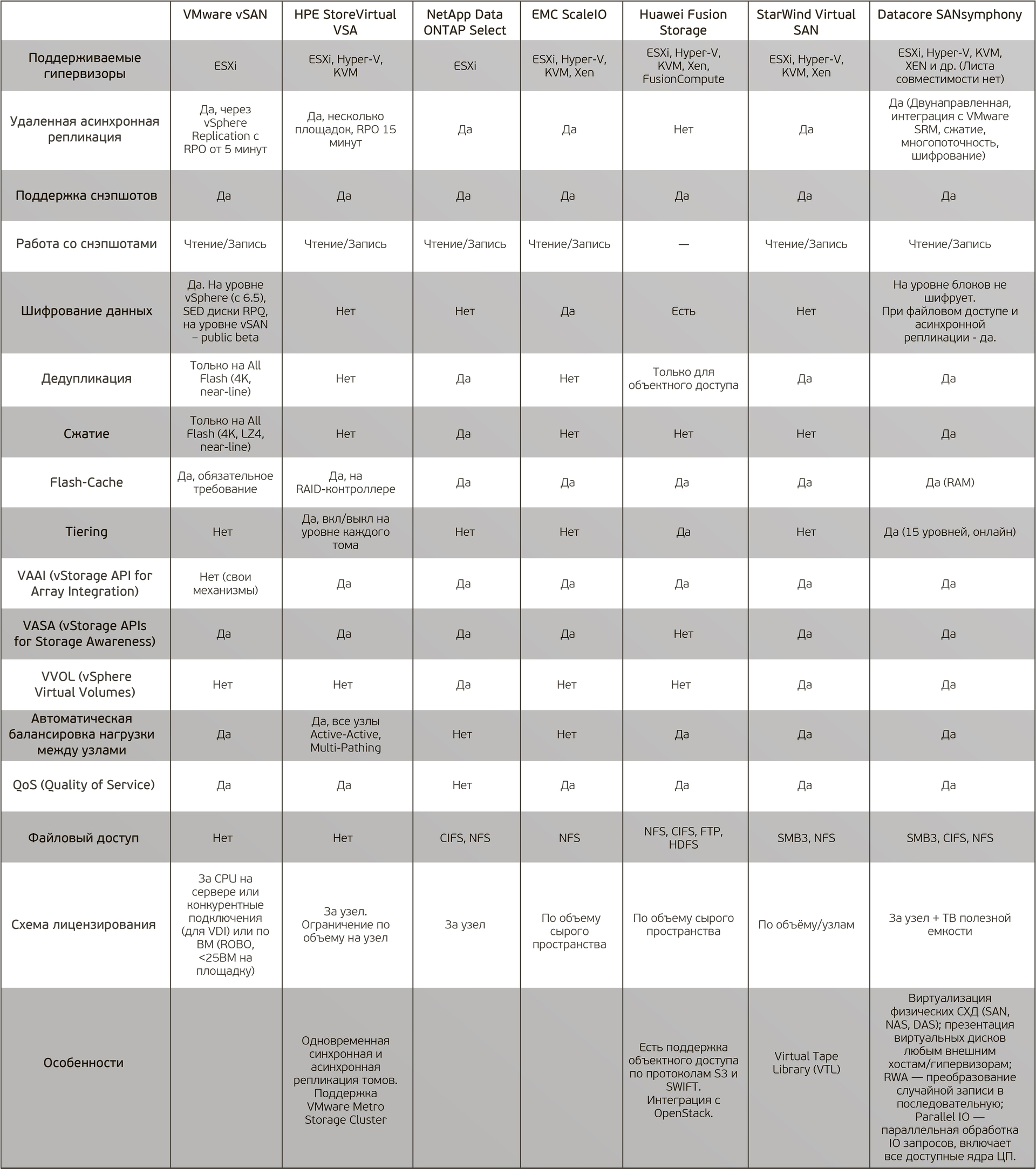
Кликните, чтобы увеличить таблицу
Инструмент будущего
Технология SDS начала развиваться еще в начале 2000-х, но пока не смогла заменить классические СХД по целому ряду причин — сейчас мы их обсуждать не будем. Но производители активно занимаются развитием своих продуктов и интерес к технологиям SDS растет. По нашим оценкам, в ближайшее время они станут тем инструментом, который позволит сокращать стоимость ИТ-инфраструктуры при росте потребности в увеличении емкости СХД.

В заключение отмечу, что в настоящем материале я не пытался предложить варианты выбора подходящего для вас решения. Такое решение нужно выбирать, исходя из нагрузки, SLA и т.д. В предлагаемой таблице сравниваются лишь возможности решений, и не сравниваются производительность, скорость репликации, время переключения нод и др. Т.е. это именно сравнительный анализ возможностей, а не продуктивное тестирование.
После тщательного знакомства с продуктами SDS мы пришли к выводу, что в текущей своей реализации под наши задачи они подходят не очень хорошо. Для себя мы все же выбрали классическое решение, внедрением которого мы в данный момент занимаемся, и о чём, возможно, в ближайшее время вам расскажем.
Но надеюсь, что представленные результаты сравнения помогут вам сориентироваться, сэкономят время и облегчат задачу выбора, какое решение подходит в вашем случае.
Если кто-то из читателей сочтёт возможным поделиться какой-либо дополнительной информацией по обсуждаемому предмету, а возможно, и рассказать о своем выборе, было бы очень интересно.
Комментарии (19)

SinTeZoiD
16.03.2017 14:45+6Как же это люди живут с CEPH без команды разработчиков? Ну да ладно.
А где MS SS Direct? А где ScaleIO? А где нут от нутаникс?
Пост выглядит так, будто вендоры вам прислали свои материалы и вы из них сделали сводную таблицу и из этого написали пост на хабр.
Где тесты отзывы, стенды и прочее? Грустно как-то.
KorP
16.03.2017 15:03+2Как же это люди живут с CEPH без команды разработчиков?
На наш взгляд — это так. Но у всех разные задачи и потребности. Но в любом случае, назвать Ceph «коробочным» решением, как то очень сложно.
А где MS SS Direct?
Ещё сыровато, как говорит сам МС — ещё не для продакшена. Но мы уже посматриваем и в его сторону.
А где ScaleIO?
Эм...4-й столбец.
Где тесты отзывы, стенды и прочее?
Последний блок текста ответит на ваш вопрос.
Грустно как-то.
Печеньку? :)
kataklysm
16.03.2017 16:16+3Ceph — не совсем коробочный продукт. Его использование без штата разработчиков достаточно затруднительно, что сделало его неинтересным для нашей компании.
У меня довольно большой опыт работы с Ceph(три года) и смело могу заявить, что в штате разработчики не нужны вообще. Нужно только хорошо понимать архитектуру и принципы его работы, ну и конечно же читать и анализировать рассылку и http://tracker.ceph.com
При этом записи не являются транзакционными.… Яркий ее представитель — CEPH.
Почему же запись в CEPH не является транзакционным? Вполне себе является транзакционным и даже с учетом количества его репликаций.KorP
16.03.2017 16:19-2Вполне себе является транзакционным и даже с учетом количества его репликаций.
Готовы вас выслушать, а лучше — получить ссылку на доку, где это описано. Возможно, мы действительно имеем мало опыта с Ceph.
пс первый каммент за 6 лет? Видимо мы сильно вас задели? :)kataklysm
16.03.2017 16:59+3Это написано в их главной архитектурной документации :).
Replication…
The client writes the object to the identified placement group in the primary OSD. Then, the primary OSD with its own copy of the CRUSH map identifies the secondary and tertiary OSDs for replication purposes, and replicates the object to the appropriate placement groups in the secondary and tertiary OSDs (as many OSDs as additional replicas), and responds to the client once it has confirmed the object was stored successfully.KorP
16.03.2017 18:11Я вот такую вещь вот читал http://docs.ceph.com/docs/hammer/dev/filestore-filesystem-compat/
kataklysm
16.03.2017 20:45KorP это проблема не существует года так 3-4, исправилась она с появлением расширенного xattr.
Собственно ссылкаKorP
16.03.2017 21:02Спасибо, за информацию, буду знать. А вообще жду курс по теме от Радика Юсупова. По опен стэку у него был неплохой курс, и обещал в обозримом будущем по Ceph

navion
16.03.2017 20:23А где IBM Spectrum Accelerate и что-то от Хапе?
KorP
16.03.2017 21:06+1С IBM у нас, к сожалению, как то не задаются отношения. То у нас с тсм их не вяжется, то предлагали в тест объектный сторадж Cleversafe, который мы от них ожидаем до сих пор и тд… А что касается HPE… при всём моём к ним уважении и любви, у меня с железным StoreVirtual перед новым годом сложилась очень странная ситуация, которая не знаю, решилась уже или нет, но впечатление оставила не очень положительное, да и VSA как то особо не выделяется, что бы прям сильно захотелось его внедрить.
leahch
16.03.2017 21:48+4Тоже три года работы с ceph, никаких разработчиков держать не нужно. Вполне коробочный продукт, типа glusterfs или gpfs, в понимании их инсталляции под линукс, через использование которых прошли. Все работает и ставится из пакетов, настраивается достаточно просто и очень гибко. Ну а если нужен gui, то и этого навалом. Да и данные добываются просто, если вдруг по криворукости развалите, как мы на заре использования, неправильно настроив multipath на паре массивов :-)
На мой взгляд, одна из лучших систем для хранения данных на данный момент, а я их немного повидал разных.
Используем и под виртуализацию и для отдачи по nfs, и для прямого подключения как дисков.
Вот хотим на cephfs перейти для хранения файлов пользователей.o_serega
17.03.2017 06:14+2Интересен вопрос, как Вы вытаскивали данные при развалившемся кластере, интересует реальный опыт? Ну и для ясности, Вы использовали только реплика- фактор или коды избыточности?
leahch
17.03.2017 07:20+2Используем только реплику. А восстанавливали так. По этой статье узнали формат хранения rbd http://www.sebastien-han.fr/blog/2014/09/08/analyse-ceph-object-directory-mapping-on-disk/
Далее написали програмку на питоне, которая доставала кусочки с дисков и сливала их в один файл, после чено просто этот файл подмонтировали, получилось со второго раза и за 3 дня работы программы.kataklysm
17.03.2017 08:09+1Так же существует скрипт на bash, которым раз пользовался.
o_serega
17.03.2017 14:20А не пробовали вытащить данные из волума радосгетвея? На сколько успешно все прошло? Спасибо за полезную информацию
kataklysm
17.03.2017 14:36данные из волума
вы имеете ввиду pool?
Я сам лично не пробовал, но сама логика сборки файлов будет аналогичной. Восстановление данные из RGW требует больших временных ресурсов.o_serega
17.03.2017 14:39Да именно, спасибо за наводку. Почему задался вопросом опыта восстановления данных, есть опыт развалить кластер на этапе ребилда его, когда начинают каскадно вылетать старые диски и кластер больше не собирается)
msolovyev
За велосипеды лайк :)