

Нам, в команде платежного блокчейн-сервиса Wirex, на собственном опыте знакома необходимость постоянной доработки и совершенствования существующего технологического решения. Автор материала, приведенного ниже, рассказывает об истории эволюции развертывания кода известной социальной новостной платформы Reddit.
«Важно следить за направлением своего развития, чтобы иметь возможность вовремя направить его в полезное русло».
Команда Reddit постоянно развертывает код. Все члены команды разработки регулярно пишут код, который перепроверяется самим автором, проходит проверку со стороны, чтобы после отправиться в «продакшн». Еженедельно мы делаем не менее 200 «деплоев», каждый из которых обычно занимает в общей сложности менее 10 минут.
Система, которая обеспечивает все это, развивалась на протяжении многих лет. Давайте посмотрим, что изменилось в ней за все это время, а что осталось неизменным.
Начало истории: стабильные и повторяющиеся деплои (2007-2010)
Вся имеющаяся у нас сегодня система выросла из одного зернышка — Perl-скрипта под названием push. Он был написан давно, в совсем другие для Reddit времена. Вся наша техническая команда тогда была настолько мала, что спокойно помещалась в одну небольшую «переговорку». Мы тогда еще не пользовались AWS. Сайт работал на конечном количестве серверов, и любые дополнительные мощности надо было добавлять вручную. Все работало на одном крупном, монолитном Python-приложении под названием r2.
{kind=link}
Одна вещь за все эти годы осталась неизменной. Запросы проходили классификацию в балансировщике нагрузки и распределялись по «пулам», содержащим более или менее идентичные серверы приложений. К примеру, страницы списков тем и комментариев обрабатываются разными пулами серверов. На самом деле любой r2-процесс может обрабатывать любые типы запросов, однако разделение на пулы позволяет защитить каждый из них от резких скачков трафика в соседних пулах. Таким образом, в случае роста трафика отказ грозит не всей системе, а отдельным ее пулам.
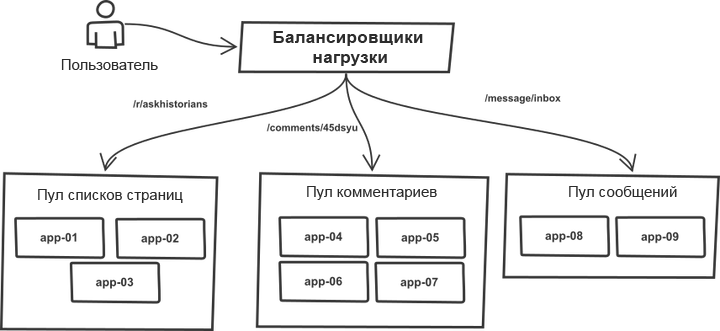
Список целевых серверов был прописан вручную в коде инструмента push, а процесс развертывания работал с монолитной системой. Инструмент пробегал по списку серверов, заходил по SSH, запускал одну из заранее заданных последовательностей команд, обновлявших текущую копию кода с помощью git, и перезапускал все процессы приложений. Суть процесса (код сильно упрощен для общего понимания):
# создаем статические файлы и помещаем их на выделенные под статику серверы
`make -C /home/reddit/reddit static`
`rsync /home/reddit/reddit/static public:/var/www/`
# проходим по всем app-серверам и обновляем на них текущие копии кода
# как только все готово, перезагружаем их
foreach $h (@hostlist) {
`git push $h:/home/reddit/reddit master`
`ssh $h make -C /home/reddit/reddit`
`ssh $h /bin/restart-reddit.sh`
}Развертывание происходило последовательно, один сервер за другим. При всей своей простоте схема имела важный плюс: она очень похожа на «канареечный деплой». Развернув код на нескольких серверах и заметив ошибки, вы сразу понимали, что баги есть, могли прервать (Ctrl-C) процесс и откатиться до того, как проблемы возникнут со всеми запросами сразу. Простота развертывания позволяла легко и без серьезных последствий проверять вещи в продакшене и откатываться если они не работали. Кроме того, было удобно определять какой именно деплой вызвал ошибки, где конкретно и что надо откатывать.
Такой механизм хорошо справлялся с обеспечением стабильности и контроля при развертываниях. Инструмент работал довольно быстро. Дела шли как надо.
В нашем полку прибыло (2011)
Потом мы наняли еще людей, разработчиков теперь было шестеро, а наша новая «переговорка» стала просторнее. Мы начали понимать, что процесс развертывания кода теперь нуждался в большей координации, особенно когда коллеги работали из дома. Утилита push была обновлена: теперь она объявляла о начале и завершении деплоев с помощью IRC чат-бота, который просто сидел в IRC и объявлял события. Выполняемые во время деплоев процессы не претерпели почти никаких изменений, однако теперь система делала все за разработчика и говорила всем остальным о внесенных модификациях.
С этого момента началось использование чата в рабочем процессе развертываний. В то время разговоры об управлении развертыванием из чатов были довольно популярны, однако поскольку мы использовали сторонние IRC-серверы, мы не могли довериться чату на все сто в деле управления продакшн средой, и потому процесс так и остался на уровне одностороннего потока информации.
По мере роста трафика на сайте, росла и поддерживающая его инфраструктура. Время от времени нам то и дело приходилось запускать новую группу серверов приложений и вводить их в строй. Процесс по-прежнему не был автоматизирован. В частности, список хостов в push все еще надо было обновлять вручную.
Мощность пулов обычно наращивали, добавляя в них по несколько серверов за раз. В результате последовательно пробегающий по списку push успевал накатить изменения на целую группу серверов в одном и том же пуле, не затронув при этом другие, то есть не было диверсификации по пулам.

Для управления процессами-воркерами использовался uWSGI и поэтому когда мы давали приложению команду на перезагрузку, оно убивало сразу все существующие процессы, заменяя их новыми. Новым процессам требовалось некоторое время чтобы приготовиться к обработке запросов. В случае с непреднамеренным перезапуском группы находящихся в одном пуле серверов сочетание этих двух обстоятельств серьезно сказывалось на способности этого пула обслуживать запросы. Так мы уперлись в ограничение по скорости безопасного развертывания кода на все серверы. С ростом количества серверов, росла и длительность всей процедуры.
Переработка инструмента деплоя (2012)
Мы основательно переработали инструмент развертывания. И хотя название его, несмотря на полную переделку, осталось прежним (push), на этот раз он был написан на Python. В новой версии были некоторые серьезные улучшения.
Прежде всего он забирал список хостов из DNS, а не из жестко прописанной в коде последовательности. Это позволяло обновлять только список, без необходимости обновления кода push. Появились зачатки системы обнаружения сервисов.
Чтобы решить проблему последовательных перезапусков, мы перемешивали список хостов перед развертываниями. Перетасовка снижала риски и позволяла ускорить процесс.

Первоначальный вариант каждый раз перемешивал список случайным образом, однако это осложняло быстрый откат, поскольку всякий раз список первой группы серверов был разным. Поэтому мы подправили перемешивание: оно теперь генерировало некий порядок, которым можно было пользоваться во время повторного деплоя после отката.
Еще одним небольшим, но важным изменением было постоянное развертывание некоторой фиксированной версии кода. Предыдущая версия инструмента всегда обновляла master-ветку на целевом хосте, но что будет, если master изменится прямо во время деплоя из-за того, что кто-то по ошибке запушил код? Развертывание некоторой заданной ревизии git вместо обращения по имени ветки, позволяло удостовериться, что на каждом продакшн-сервере была применена одна и та же версия кода.
И наконец, новый инструмент различал свой код (работал преимущественно со списком хостов и заходил на них по SSH) и исполняемые на серверах команды. Он все еще очень сильно зависел от потребностей r2, но имел что-то наподобие прототипа API. Это позволяло r2 следить за собственными шагами развертывания, что упрощало раскатывание изменений и освобождало поток. Далее пример команд, выполняемых на отдельном сервере. Код, опять же, не точный код, но в целом эта последовательность хорошо описывает рабочий процесс r2:
sudo /opt/reddit/deploy.py fetch reddit
sudo /opt/reddit/deploy.py deploy reddit f3bbbd66a6
sudo /opt/reddit/deploy.py fetch-names
sudo /opt/reddit/deploy.py restart allОсобенно стоит отметить fetch-names: эта инструкция уникальна именно для r2.
Автомасштабирование (2013)
Потом мы решили, наконец, перейти в облако с автоматическим масштабированием (тема для целого отдельного поста). Это позволило нам сэкономить целую кучу денег в те моменты, когда сайт не был загружен трафиком и автоматически наращивать мощность, чтобы справиться с любым резким ростом запросов.
Предыдущие усовершенствования, автоматически подгружавшие список хостов из DNS, превратили этот переход в нечто само собой разумеющееся. Список хостов менялся чаще чем раньше, но с точки зрения инструмента деплоя, это не играло никакой роли. Изменение, которое изначально было введено как качественное улучшение стало одним из ключевых компонентов, необходимых для запуска автомасштабирования.
Тем не менее автомасштабирование привело к появлению некоторых интересных пограничных случаев. Появилась потребность контролировать запуски. Что произойдет, если сервер запустится прямо во время деплоя? Нам надо было убедиться, что каждый новый запущенный сервер проверял наличие нового кода и забирал его, если таковой был. Нельзя было забывать и о серверах, уходящих в офлайн в момент разворачивания. Инструменту нужно было стать умнее и научиться определять, что сервер ушел в офлайн в рамках процедуры, а не в результате возникшей во время деплоя ошибки. В последнем случае он должен был громко предупредить всех причастных к проблеме коллег.
В то же время мы как бы между прочим и по самым разным причинам перешли с uWSGI на Gunicorn. Однако с точки зрения темы этого поста, подобный переход не привел к каким-либо значительным изменениям.
Так оно и работало какое-то время.
Слишком много серверов (2014)
Со временем количество серверов, необходимых для обслуживания пикового трафика, росло. Это приводило к тому, что деплои требовали все больше и больше времени. При худшем сценарии на один нормальный деплой уходил примерно час — плохой результат.
Мы переписали инструмент, чтобы тот мог поддерживать параллельную работу с хостами. Новая версия получила название rollingpin. Старой версии требовалось много времени на инициализацию ssh-соединений и ожидание завершения всех команд, поэтому распараллеливание в разумных пределах позволяло ускорить развертывание. Время развертывания снова снизилось до пяти минут.

Для уменьшения влияния одновременной перезагрузки множества серверов, перемешивающий компонент инструмента стал умнее. Вместо того чтобы выполнять перемешивание списка вслепую, он сортировал пулы серверов так, чтобы хосты из одного пула оказывались друг от друга максимально далеко.
Самым важным изменением в новом инструменте было то, что API между инструментом деплоя и инструментами на каждом из серверов были определены гораздо яснее и отделены от потребностей r2. Изначально это делалось из желания сделать код более ориентированным на open-source, однако вскоре этот подход оказался очень полезен и в другом отношении. Далее пример развертывания c выделением удаленно запускаемых API команд:

Слишком много людей (2015)
Внезапно наступил момент, когда над r2, как оказалось, работало уже очень много людей. Это было классно, и в том же время означало, что деплоев станет еще больше. Соблюдать правило одного деплоя за раз становилось все сложнее и сложнее. Разработчикам приходилось договариваться друг с другом о порядке выпуска кода. Чтобы оптимизировать ситуацию, мы добавили чат-боту еще один элемент, координирующий очередь развертываний. Инженеры запрашивали резерв деплоя и либо получали его, либо их код «вставал» в очередь. Это помогало упорядочивать развертывания, а желающие выполнить их могли спокойно ждать своей очереди.
Другим важным дополнением по мере роста команды было отслеживание развертываний в каком-то одном месте. Мы изменили инструмент деплоя, чтобы он отправлял метрики в Graphite. Это позволяло легко прослеживать корреляцию между развертываниями и изменениями метрик.
Много (два) сервиса (тоже 2015)
Так же внезапно наступил и момент выпуска в онлайн второго сервиса. Это была мобильная версия веб-сайта со своим, совершенно другим стеком, собственными серверами и процессом сборки. Это была первая реальная проверка разделенного API деплой-инструмента. Добавление в него возможности отрабатывать все этапы сборки в разных «локейшенах» для каждого проекта позволило ему выдержать нагрузку и справиться с обслуживанием двух сервисов в рамках одной системы.
25 сервисов (2016)
На протяжении следующего года мы стали свидетелями стремительного расширения команды. Вместо двух сервисов появились целые две дюжины, вместо двух команд разработчиков — пятнадцать. Большинство сервисов было собраны либо на Baseplate, нашем бекэнд-фреймворке, либо на клиентских приложениях по аналогии с мобильным вебом. Стоящая за деплоями инфраструктура едина для всех. Вскоре в онлайн выйдет множество других новых сервисов, и все это — во многом благодаря универсальности rollingpin’а. Она позволяет упростить запуск новых сервисов с помощью хорошо знакомых людям инструментов.
Подушка безопасности (2017)
По мере увеличения количества серверов в составе монолита, время развертывания росло. Мы хотели существенно увеличить количество параллельных деплоев, однако это вызвало бы слишком много одновременных перезагрузок серверов приложений. Такие вещи, естественно приводят к падению пропускной способности и потере возможности обслуживания входящих запросов в силу перегрузки остающихся в строю серверов.
Основной процесс Gunicorn использовал ту же самую модель, что и uWSGI, перезагружая всех воркеров одновременно. Новые процессы-воркеры были неспособны обслуживать запросы до тех пор, пока полностью не загрузятся. Время запуска нашего монолита варьировалось от 10 до 30 секунд. Это означало, что в этот промежуток времени мы вообще не смогли бы обрабатывать запросы. Чтобы найти выход из этой ситуации мы заменили основной процесс gunicorn менеджером воркеров Einhorn от Stripe, сохранив при этом HTTP-стек Gunicorn и контейнер WSGI. Во время перезагрузки Einhorn создает нового воркера, дожидается пока тот будет готов, избавляется от одного старого воркера и повторяет процесс до полного обновления. Это создает подушку безопасности и позволяет нам держать пропускную способность на уровне во время деплоев.
Новая модель создала другую проблему. Как уже упоминалось ранее, замена воркера на нового и полностью готового требовала до 30 секунд. Это означало, что при наличии в коде бага, он всплывал не сразу и успевал развернуться на множестве серверов, прежде чем был обнаружен. Для предотвращения этого, мы ввели механизм блокировки перехода процедуры развертывания на новый сервер, действовавшей до тех пор, пока все процессы воркеров не будут перезапущены. Реализовано это было просто — за счет опросов состояния einhorn и ожидания готовности всех новых воркеров. Чтобы сохранить скорость на прежнем уровне мы расширили количество параллельно обрабатываемых серверов, что было вполне безопасно в новых условиях.
Такой механизм позволяет нам проводить одновременное развертывание на гораздо большем количестве машин, а время деплоя, охватывающего примерно 800 серверов, снижается до 7 минут, с учетом дополнительных пауз на проверку наличия багов.
Оглядываясь назад
Описанная здесь инфраструктура деплоя — продукт, родившийся в результате многих лет последовательных улучшений, а не единоразового целенаправленного усилия. Отголоски принятых когда-то решений и достигнутых на ранних этапах компромиссов до сих пор дают о себе знать в текущей системе, и так было всегда и на всех этапах. В подобном эволюционном подходе есть свои плюсы и минусы: он требует минимум усилий на любом этапе, однако возникает риск рано или поздно зайти в тупик. Важно следить за направлением своего развития, чтобы иметь возможность вовремя направить его в полезное русло.
Будущее
Инфраструктура Reddit должна быть готова к постоянной поддержке команды по мере ее роста и запуска новых вещей. Скорость роста компании велика как никогда, и мы работаем над еще более интересными и крупными проектами, чем все, что мы делали ранее. Проблемы, с которыми мы сталкиваемся сегодня имеют двойственную природу: с одной стороны, это необходимость повышать автономность разработчиков, с другой — поддерживать безопасность инфраструктуры продакшена и улучшать подушку безопасности, позволяющую разработчикам быстро и уверено выполнять деплои.

Поделиться с друзьями