
Алексей и его коллеги занимаются профессиональным обслуживанием бизнесов, работающих с платформой 1С. Они обучают клиентов, как эффективно использовать 1C на связке PostgreSQL + Linux. Оказывается, что очень часто проблема заключается не в самой платформе, а в неумелой эксплуатации. На PG Day'17 Russia Алексей проведет мастер-класс по переходу на PostgreSQL для 1С под кодовым названием Борьба со страхами.
В рамках сегодняшней публикации, Алексей наглядно покажет, почему методология, которую они предлагают, является успешной. И не менее подробно объяснит, какие именно практические навыки вы приобретете на мастер-классе.
 PG Day: Алексей, расскажите о себе. Кто вы, чем занимаетесь, как пришли к своей специализации?
PG Day: Алексей, расскажите о себе. Кто вы, чем занимаетесь, как пришли к своей специализации?Алексей: Я называю себя евангелистом Automation Driven Development. Это такая концепция “от автоматизации деятельности айтишников”, чтобы разработчики и инфраструктурщики избавлялись от рутины и освобождали время для интересной работы. Последние четыре года стараюсь подружить два мира с помощью концепции CICD (Continuous Integration и Continuous Delivery): разработчиков и инфраструктурщиков. Ради этого и была организована наша команда. Причем основной приоритет именно на “мир 1С”, как наименее автоматизированный с точки зрения процесса.
Как мы к этому пришли? В больших компаниях очень много регламентов. Чтобы их соблюдать, требуется ручной процесс. Для этого выделяют «ручных» людей. Когда мы приходим на крупные предприятия с аудитом, обнаруживаем, что 80-90% времени сотрудников тратится вот на эту рутину: обновить базу, измерить производительность, помониторить, сделать выводы, тесты ручные провести. 80% времени совершенно неэффективной работы. Она обоснована с точки зрения рисков предприятия, с этим соглашусь. Мы же понимаем, что в большой компании такое количество регламентов родилось как ответ на какие-то аварии и всё остальное. Только вот эти 80% – явный кандидат на автоматизацию.
Кстати, “айтишники” почему-то часто считаются обслуживающим подразделением, а не зарабатывающим. Никто не думает, что, сократив рутину, можно начать делать интересные вещи. Более эффективно бизнес автоматизировать, придумать что-то прорывное для собственного стартапа – новую гипотезу проверить или бабла срубить.
От этого “отпрыгивает всё”, что мы делаем руками.
Для бизнеса, еще с 2000-х годов наиболее эффективной считается платформа 1С, которая, начиная со старой версии 7.7, работает на контуре Microsoft и на СУБД MS SQL. У меня есть некое свое видение, почему так происходит. Изначально Microsoft был достаточно прорывной технологией в мире СУБД. Postgres тогда был уделом Linux (8 редакция и так далее), и, наверно, самой компании 1С был не очень интересен. Тогда главное было получить быстрый результат. Это MS SQL делал. Принято считать, что MS SQL стабилен для 1С. В целом, это, наверное, так. Его оптимизатор запросов начинает справляться, и не показывает ошибки в проектировании таблиц и связей между ними. Логически ошибочный проект на 1С в связке с MS SQL, запускаемый на каком-то минимальном объеме данных, начинает сбоить только после определенных порогов. А в Postgres эти ошибки выявляются еще на начальном этапе старта информационной системы – логические ошибки в структуре СУБД сразу вылетают, ты тут же видишь непонятки, все работает медленно. Поэтому обычно все начинают ругать Postgres, никто никогда не ругает разработчиков.
Я говорю так: 1С и Postgres работают хорошо! Проблема не в них, проблема в компетентности владельцев контура. Даже на больших объемах баз данных есть прецеденты. Например, когда общий объем баз данных со сжатием – терабайт и более (есть и такие инсталляции). Но, как показывает практика, они прямо пропорциональны уровню компетентности владельцев этого контура – разработчиков и devops. Уровень компетенции их намного выше, чем тех, кто владеет такой же инсталляцией с таким же объемом данных и транзакций в секунду на MS SQL. Там можно посадить непонятных товарищей, и они будут что-то кодить, низкий уровень их компетентности компенсирует сам MS SQL. Разница не в Postgres и MS SQL – разница только в компетентности.
Отсюда вся история с курсами, github-аккаунтами и различными публикациями скриптов. Лично моя социальная цель такова – чтобы эксперты по производительности в 1С-мире (на самом деле, системные администраторы, которые администрируют весь контур – и сервер приложения 1С, и СУБД) повышали свой уровень компетентности.
Как я к этому пришел? Представьте, что у вас двести 1С-ников в обучении, и задача – запустить хотя бы 100 информационных систем на linux. Последние пять лет назад у меня был такой волшебный опыт: надо было сместить стратегический фокус с MS SQL контура на Postgres. В 2006 году в рамках «Инфостарта» мы организовали сообщество 1C+Postgres (рассчитанное больше на гиков). Нам поставили задачу смигрировать хотя бы часть систем на Postgres. Выяснилось, что проблема вообще не в Postgres и не в 1С. Проблема именно в уровне компетентности администраторов, которые ответственны за СУБД, и 1С-ников, и разработчиков, и так далее. Они просто не умеют проверять свои гипотезы, когда в качестве СУБД используется PostgreSQL. Им кажется, что развернут быстренько на продуктиве – и все само заработает. Потом только останется что-нибудь подкрутить. С Postgres так нельзя.
Ну и про себя могу сказать. Раз я евангелист инженерных практик DevOps, мне приходится руками доказывать, что это работает. Я не могу просто ходить с флагом «Postgres – наше всё». Мне говорят: «Докажи». Сажусь совместно с командой (нас не очень много, кстати), и мы через вагранты, докеры, всякие автоматизированные скрипты доказываем, что правы. Убеждаем, что мы не просто популисты.
PG Day: Вы затронули интересную тему – проблематику перехода с платформы Windows MsSQL на Linux с Postgres. Какие советы, исходя из вашей практики, вы даете для устранения этих проблем, когда вас просят помочь с осуществлением такого перехода?
Алексей: У нас выстроен некий чек-лист, называется «борьба с возражениями при переходе». 1С производят типовые информационные системы. Сейчас же обычно как: если хочешь развернуть комплексную автоматизацию предприятия (начиная с зарплаты и заканчивая финансовым учетом). Инсталлируй 1С – получишь полную ERP и вперед, занимайся бизнесом, не заморачивайся автоматизацией. В таком случае ты выигрываешь.
Но когда «бизнесменишь», то вынужден дорабатывать под себя, «подрихтовывать». Приходится нанимать разработчиков и инфраструктурщиков разного уровня. И они тебе «допиливают». За последние пятнадцать лет 95% инсталляций 1С – нетиповые. Есть статистика, что в России существует около полумиллиона различных нетиповых инсталляций. Их «допиливали» какие-то товарищи под конкретного бизнесмена, с разным уровнем качества. Если «материнская» компания выпускает информационную систему, в которой структура таблиц более-менее отлажена (потому что внутри компании 1С отладка моделей все-таки идет: и IDEF-диаграммы, и ERwin, наверное – там всё нормально работает). Когда оно приходит к конкретному бизнесмену, разработчики «допиливают», и могут ничего не знать ни про модель данных, ни про теорию множеств. Могут накатать схему данных просто невозможную.
Поэтому первое возражение, с которым мы боремся, – запустится ли система вообще. Приходится сначала просто показать. Можно всю информационную систему выгрузить и загрузить в другой контур СУБД, это у них такая классная фишка в мире 1С: можно сделать перенос не с помощью pg_dump или бекапов MS SQL, а собственным внутренним инструментом. Так вот, берешь и переносишь на контур Postgres.
Однако там есть одна особенность – 1С-сервер лучше ставить все-таки не на Linux, а на Windows – из-за проблем с active directory и kerberos-библиотекой. Это связано не с Postgres, а с особенностью статической линковки библиотеки kerberos под CentOS, под Ubuntu и не только. Вообщем, есть такая рекомендация, что на Linux ставишь только Postgres. При этом очень сильно сопротивляешься, чтобы не запустить его на Windows. Windows-сервер оставляешь под управлением 1С и переносишь базу. Замеряешь сколько времени будет переноситься база – развертываться из бэкапа и переходить в продуктивное состояние. Если база у тебя – терабайт, то наш волшебный замер – 36 часов. Сторонними средствами, когда из MS SQL в Postgres, – конечно, получилось бы быстрее. Но, все-таки, мы выбираем штатный инструмент, он хоть и дольше, но наименее рискованный.
Разворачиваешь и запускаешь тупые вещи – какой-нибудь отчет, например. Это самое показательное. Отчеты начинают работать быстрее на 15-20%. Это доказуемо. Ты берешь на одном контуре и на втором, запускаешь, и у тебя на 20% отчеты формируются быстрее. Это первый такой wow-эффект. Кстати, известна даже причина, почему так происходит. В итоге – это доказывает, что “оно” работает.
Все обычно боятся Linux, от слова «совсем». Ты им развернул Postgres, доказал, что он работает быстрее на некоторых операциях, но они все равно продолжают боятся Linux. Приходится убеждать, что здесь нет Linux, здесь есть Postgres. Есть установленный пакет и несколько команд – apt-get install или yum. Ты обучаешь администратора базовым командам – что тут есть блочные устройства, они немножко по-другому выглядят, чем в Windows, и это скриптуешь в виде vagrant-файла. Показываешь ему, как это работает, чтобы он мог виртуальную машину с Linux для игр развернуть в виде vagrant, который примерно повторяет его настройки Postgres в продуктиве. И он начинает с ним играться: запускает различные команды Linux, смотрит, как вообще апдейты работают, как работать с бэкапами, с консольным pg_dump и еще с чем-то.
Обычно администраторы – выходцы из Windows-мира, которые раньше “админили” MS SQL. Они говорят: «А как бэкапить?» (ведь у него есть некий Maintenance Plan, который принят в MS SQL). Готовишь ему табличку, которая показывает, как он это делал на MS SQL, и как это делается на Postgres: как пересчитывать статистику (и как она вообще в PostgreSQL называется), как посмотреть план запроса косячного длинного и так далее. Она обычно состоит из 15 – 20 основных пунктов. В итоге, ему перестает быть страшно – всё, что он делал раньше, в той или иной степени присутствует и в контуре PostgreSQL.
А потом начинаешь веселиться с Postgres-контуром. Это тоже основная беда, когда ты объясняешь, что, на самом деле, нет принятого в Microsoft «мышководства». У тебя есть либо nano, либо vim, и ты меняешь параметры. Причем, если есть возможность запустить более новую версию, то уже показываешь ему конструкцию alter system. Для большинства DBA это понятная конструкция – что можешь поменять системные переменные, почти что но, конечно, не совсем) аналог trace flag MS SQL. Показываешь, как память рассчитывать, учишь, как рассчитывать в Excel объем коннектов, считаешь транзакции в секунду, вообщем, учишь работать с Postgres-контуром, что это не магия никакая. Естественно, тут же даешь ссылки на видео Бартунова или каких-то открытых тренингов Postgres Pro. Достаточно быстро группируешь список из небольших 5-6 вебинаров – и они проникаются тем, как это всё работает. Ссылки, опять же, на Github даешь.
А эксперименты, я напомню, проводятся на vagrant. Один из примеров: тормозит СУБД (1С и СУБД расположены на нескольких инфраструктурных серверах), все привыкли, что это якобы 1С, и никто ничего не делает. А когда ты на Postgres запускаешь – сразу видно, что есть проблемы по сетевой инфраструктуре. Тебе надо померять ее iperf’ом и еще какими-то инструментариями Linux. Так часто выявляется наличие странных сетевых маршрутов между выделенной инфраструктурой. Получается проблема не в 1С и не в MS SQL, а проблема – в сети между ними, но MS SQL как-то жил, а на PG уже так нельзя. Странные прыжки, переходы между непонятными узлами – это тоже достаточно быстро выявляется. Почему-то средства мониторинга Postgres настолько веселые и низкоуровневые, что показывают эти цифры достаточно быстро. Такую магию начинаешь ребятам рассказывать про инфраструктуру, они быстро проникаются. Вот и всё.
Основная цель же – перевести базу и научиться ею владеть в продуктиве. Продуктивный контур они настраивают сами, повторяют скрипты, которые сделали на vagrant. В продуктив мы не лезем – такова наша методика. Фактически это получается их продуктив. Если они не уверены в том, что мы им показали, значит, продолжаем обучение, доказательства и так далее.
А поддержкой продуктива мы не занимаемся, кстати. Есть люди, которые делают это более профессионально – мы лучше порекомендуем их. Они прям админы. В мире Postgres всем известно, кто и на чем специализируется – мы специализируемся на общем контуре и на vagrant, то есть на приемочных контурах Postgres и 1С. Но как только идет передача в продуктив, я говорю: «Ребята, вот список людей кто специализируется на PG в продуктиве – туда все вопросы. Не верите российским – пожалуйста, обращайтесь к 2ndQuadrant». Там есть люди, которые сразу родились с бородой и с клавиатурой, заточенной под vim, в одной руке. При этом ночью они мысленно пересобирают ядра Linux. Поэтому в продуктив я с командой не лезу, хотя мониторинг оттуда забираю, чтобы выявить проблемы разработчиков тем же pgBadger, который, кстати, я всем рекомендую.
Это киллер-фича из мира Postgres для инфраструктурщиков: покажет, как живет твоя БД с репликами. В этот отчет можно “погрузиться на месяц” и исследовать. Да, в MS SQL есть такие штуки, но они стоят очень дорого. А здесь прямо с коробки github docker, почти как инсталлятор: запустил и забыл.
Если подытожить – берешь и пошагово борешься “со стандартными возражениями”. Показываешь, что на Postgres – работает, а в некоторых сценариях работает быстрее, и показываешь сам сценарий.
Борьба с возражениями против Linux происходит так: 1С сервер оставляешь на привычной им винде, а Postgres делаешь на Linux. Так закрываешь первое возражение – типа, не-не-не, не всё на Linux, только Postgres! Чуть-чуть Linux.
Запустил, немножко добавил Linux, продемонстрировал, что это всё работает и выделил – на каких сценариях быстрее. Сначала показал экосистему, где почерпнуть бесплатную информацию, если понадобится, затем подключенные расширения, которые позволяют более комфортно всем этим делом управлять. Далее последовательно – показал как работает оптимизатор, восстановил план обслуживания, чтобы это было понятно. Все делаешь последовательно, чтобы убедить, что Postgres – это не страшно, это легко.
Задача – погрузить в принципы, которые приняты при владении контуром Postgres, чтобы было понятно, где брать информацию и как ее отлаживать. Работаем в парадигме – на продуктиве ничего не меняем, сначала смотрим, потом применяем.
Доказательством у нас являются скрипты на github. Это тоже такая позиция – выкладывать даже первоначальные наработки в открытый доступ.
PG Day: Расскажите подробнее про cвой workshop на конференции. Как будет строиться работа? Предубеждения касательно эксплуатации 1С на платформе будут решаться по такому вот чек-листу, про который вы рассказывали?
Алексей: Да, идеология будет такая: разверните контур Postgres – появится несколько боксов в режиме «стоковый». У нас есть специнструмент, который показывает результаты – он, например, показывает, как ведет себя 1С на стоковом Postgres Pro, без ничего, без базовых настроек, в режиме “микроволновки”.
Потом разделяем работу на 4 раздела: данные, логи PostgreSQL, WAL и pg_dump. И смотрим результаты на тех же сценариях, которые были перед этим. После этого третий бокс настраивается уже в postgres.conf, именно под типовых пользователей в тестовом контуре, с их обычной нагрузкой. Они рассчитывают регистры, отчетики запускают, справочники пишут, читают их активно и так далее. Отчет покажет, по каким принципам живет наш проверочный контур, чтобы каждый потом сам мог повторить. После этого покажем результаты правильной настройки базовой инфраструктуры postgres.conf.
Затем следующий раздел – как увидеть основные «грабли» в 1С, основные ошибки? Это про то, какими экстеншенами вы можете увидеть типовые ошибки программистов 1С (причем на типовых конфигурациях ЗУП, УТ и так далее). Они известны, – это веселая работа с temp каталогом, с временными таблицами во вложенных запросах (1С-ники любят так ошибаться), непонятные составные джойны, когда у тебя неявный джойн 1С преобразовывает и идет классическое непопадание в индекс (это прямо беда 1С, 1С-программисты «терпеть ненавидят» ставить индексы и в них попадать). Как это выявить быстро, как увидеть, где ошибся разработчик – это мы показываем во втором разделе.
То есть у нас есть сценарий, как ведет себя 1С, и как посмотреть, как выявить, найти место. В 1С есть штатный инструмент, но он платный. Поэтому рекламировать его не будем, все 1С-ники и так знают, что это Центр управления производительностью, он парсит планы запросов. Но есть бесплатный, он называется «инструмент разработчика». Запускаешь и смотришь план запроса с Postgres и участок кода в 1С, который его вызвал. Если знаешь критерии запроса, который тебя волнует, то можешь найти проблемное место бесплатно. Тебе не нужно покупать за 300 тысяч корпоративный инструментальный пакет. Соответственно, выдать рекомендации. Либо, если ты сам разраб… Бывает такое, что ты эксперт по производительности, имеешь доступ к Postgres и сам же эту конфу пилишь (в мире 1С такое очень часто случается), то можешь сам поправить. Становится понятно, где ошибся.
Следующий раздел: как собирать экстеншены из внешних исходников, и, вообще, как собрать свою версию Postgres, например, под Alpine, для 1С – где патчи найти, где их применить, какие контрибы нужны и так далее. Как это вообще выстроить. Скрипты тоже передаем. Это уже четвертый раздел, когда начинается низкоуровневый тюнинг, уже на уровне ядра, и опять же для 1С. Всё это через призму того, как меняется поведение 1С при применении этих настроек.
Кстати, по модели нагрузки, “1С” очень много пишет и тут же очень много читает. Он дает гибридную нагрузку. Там нет нагрузки OLAP или OLTP. Они могут писать сразу массово по 2,5 тысячи записей за транзакцию – и тут же их читать в следующей транзакции. Причем транзакция в данном контексте подразумевается как “бизнес-транзакция”.
Это надо просто посмотреть. Проведение одного документа в 1С вырождается в огромное количество последовательных запросов. Пользователь нажал одну кнопку, а сервер приложений сформировал много служебных вызовов на уровне СУБД. Это важно понимать, потому что там могут неожиданно создаваться временные таблицы, хотя ты их не создавал кодом. Может произойти массовая вставка, тут же распухание. То есть при записи одного документа сразу сработает bloat. Вакуум не отработает – не успеет. Он тут же запишет, следующую итерацию начнет читать. Прямо видно, как происходит фактически версионирование записей на 1С. Будет расти распухание таблиц. Автовакуум нужен, но он не всегда отрабатывает под высокой нагрузкой 1С. Это воспроизводимо визуально.
Вот такие разделы.
Последнее, что я бы хотел донести до людей, которые придут на мастер-класс. Postgres – охрененная штука. Но, чтобы нормально им владеть, нужно еще кучу всего дополнительно изучить. Поставить, как MS SQL, и забыть – не получится. С Postgres ты живешь в комьюнити, с экстеншенами, расширениями, дополнительным инструментарием (в основном, открытым, в исходниках). Это прямо комьюнити с микроинструментами для каждой мелкой задачи. Хочется донести, что MS SQL можно повторить полнофункционально и добиться охрененных результатов. Но ты должен понимать, что не будет одного инсталлятора. Не будет от слова «совсем».
Я по программе пробежался примерно. Будем идти вот так.
PG Day: На самом деле, очень подробное и отличное описание. Наверное, лучшее, которое я получил от ведущего мастер-класса за весь прошедший опыт, за последние два месяца. Спасибо, Алексей!
Комментарии (19)

fishca
23.06.2017 03:11-2Отчеты начинают работать быстрее на 15-20%
Прямо на одном и том же железе? За счет чего? Как-то не очень в это верится что постгрес уделывает на чтение мсскуль. Можно какие-то конкретные примеры привести, если есть такая возможность?
alexey-lustin
23.06.2017 11:30Выгрузи через DT скажем БУХ 3.0 и запусти скажем универсальную оборотку http://infostart.ru/public/377955/
Будешь приятно удивлен.
Только APDEX не забудь включить — чтобы замеры были одинкаовые

Siemargl
23.06.2017 10:13Великолепная статья — демотиватор. Занесу в избранное показывать всяким «оптимизаторам»-экономистам

1c80
23.06.2017 20:54а вот интересно, когда в очередной раз окажется, что что-то внезапно случилось с какой то таблицей, в мс скл,
то предложит ли постгри инструмент по мощности аналогичный мс студии?
надо к примеру таблицы просмотреть, может перенести что выборочно к примеру, как это делать и чем в постгри?alexey-lustin
24.06.2017 16:17что-то внезапно случилось с таблицей
очень интересное замечание — особенно применительно к 1С решениям. Если что-то внезапно случилось с таблицей — проблема то не в MSSQL или PG, а кажется в другом месте.
Если я правильно понимаю — то разговор идет про вот это https://ru.wikipedia.org/wiki/SQL_Server_Management_Studio?
Мы с командой используем сейчас в работе последний pgAdmin в режиме Docker — очень удобно
docker run --name some-pgadmin4 \
--link some-postgres:postgres \
-p 5050:5050 \
-d fenglc/pgadmin4Что касается PG — то dump табличек и перенос их в другую БД — операция явно из разряда "реакция на аварии" — но в pgAdmin есть "правая кнопка мыши" на схеме данных и таблице.
1c80
25.06.2017 13:32да по ссылке приведён именно тот инструмент про который я спрашивал.
как то не очень он внушительно выглядит этот pgadmin4 на картинке, откроется ли на базе под терабайт?
в яндексе если набрать pgAdmin так то не очень оптимистично, то тормозит, то не запускается, в выдаче светятся такие подсказки.
были ли сравнения производительности постгри и мс-скл на решениях где базы больше 100 гб?
и где при этом для мс-скл делается хотя бы тот регламент, что описано на сайте 1с?
==
и потом 1с пишется под мс-скл на сколько я знаю, не боитесь где-нибудь серьёзно вляпаться с постгри?
ведь работаете то с ним не напрямую, а через 1с божка, в который уже не влезть если что не так пойдет,
а такие случае на ранних этапах были.
там в статье есть предложение использовать сервер предприятия для виндовс, это связано только с тем, что клиенты боятся линукс или есть ещё какие то причины?
может есть информация о скорости работы приложения в зависимости от того на какой ос расположен сервер предприятия?alexey-lustin
27.06.2017 15:24Пока коротко отвечу:
- pgAdmin приложение на Node.JS насколько я помню — в докере работает хорошо, главное не ставить на сам сервер СУБД. интернет действительно пестрит описанием недовольства — но мы используем год: все необходимые операции он позволяет выполнить.
- сравнение наверное есть — но тут есть момент c двумя вещами: со сжатием: как верно заметили ниже MSSQL 2016 Standart уже поддерживает компрессию (фишка Enterprise 2012 b ниже), что несколько меняет отношение к размеру базы — 100Gb MSSQL база данных в сжатии, на самом деле без сжатия уже 230 гигабайт, и второй — есть же хохма с бенчмаркнгом — его лучше делать свой, на своих мощностях
что касается вляпаться — уже разбиралось неоднократно: давайте без этого, давайте конкретно: были проблемы с закрытием temp соединений, были проблемы с вложенными запросами в ЗУП особенно — чинились они либо вендором либо кодером. А с MSSQL были же проблемы с неявными джоинами составных типов. Много чего было — на buboard.1с можно много чего найти.
Предложение использовать сервер 1С на Windows связан не с PG, а c Active Directory и kerberos — а также любовью многих программистов 1С работать с путями файлов "как в Windows" явно прописывая в коде что-нибудь типа "Z:\FileShare\Диск для файлов ERP" и удивлятся потом что такой код на сервере lInux не работает
Что касается скорости работы сервера или кластера под linux — информация в основном опять же закрытая и соответствует замерам конкретного администратора на конкретной инфраструктуре… Но я вынужден сказать что не все из этих "замеряторов" могут запустить sudo atop и посмотреть irq прерывания, но проверку производительности производят и еще и выводы делают.

agens
23.06.2017 21:44Интересно, эффект Write amplification не мешает?
В базе, наверное, много часто обновляемых данных, в таблицах с несколькими индексами…alexey-lustin
24.06.2017 16:45Не скажу что мешает прям критично, но мешает. Старшие товарищи говорят что надо ждать пока пройдет ревью https://commitfest.postgresql.org/14/775/
Хотя честно скажу — WAF это уже слишком на низком уровне, 80% проблем решится если к СКД относится правильно и писать асинхронно в режиме отложенных проведений документов.
Типовая нагрузка выглядит вот так — и это обычно для 1С (Документооборот — недельная активность, 60 пользователей)
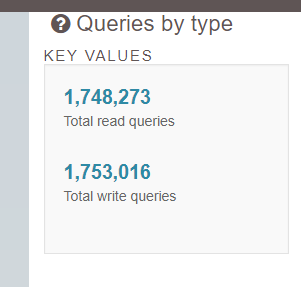
Поэтому не скажу что много — просто половина обычно, про обновление, причем в общем случае преобладает именно UPDATE и INSERT INTO temp

Dr_Wut
25.06.2017 19:28согласен с товарищами — а откуда 20% ускорения? И опять же, нет нигде конкретики Постгри может быть последний, а mssql — 2008 какой-нибудь. Да еще и без обновлений, на винде крутиться 100500 дополнительных сервисов.
В целом еще возникает вопрос совокупной стоимости владения. Найти толкового товарища по MSSQL тяжело, а по постгрее вообще реально? И сколько он будет стоить? А сколько будет нанять толкового программиста чтобы не говнокодил?
Вот и получается что в большенстве случаев платность MSSQL и Windows растворяются в дешевезне их сопровождения…
Varim
25.06.2017 19:33уверен что любой DB developer разберется хоть в MSSQL хоть в Postgres за несколько дней/недель
Dr_Wut
26.06.2017 00:48Позвольте поинтересоваться, а что вы подразумеваете под «разбереться»? Сумеет производить какие-то минимальные действия — однозначно да. Быстро решать какие-то глубокие проблемы — однозначно нет. Ведь БД это не только сам движек, а еще и окружение. Виндовый админ будет долго и муторно гуглить как посмотреть хотя бы логи. А уж про тонкую настройку я вообще молчу. (Ровно так же linux-админ мало эффективен в windows-окружении).
В общем повторюсь — все красиво до тех пор пока не начинают появляться нюансы.
1c80
26.06.2017 10:02а с чем там планируете разбираться, если не секрет?
на выходе готовый запрос, который смастерил сервер предприятия 1с,
что там кроме индексов и статистики можно менять при такой модели работы?
Alexeyco
Конечно, руками. А то все только языком да языком.
alexey-lustin
Работаем — куда деваться.