
Изложение материала хотелось бы разбить на две части: в первой графически показать непосредственно статистику, собираемую ^mgstat, а во второй — рассмотреть, как именно эта статистика собирается. Если коротко, то используются $zu-функции. Однако к большинству собираемых параметров есть и объектный интерфейс через классы пакета SYS.Stats. И далеко не все параметры, которые можно собрать, показываются в ^mgstat. В дальнейшем мы попробуем все их отобразить на Grafana-дашбоардах. В этот же раз покажем только то, что нам предоставляет сам ^mgstat. Кроме того, попробуем на вкус Docker-контейнеры.
Ставим Docker
В первой части рассказывается, как инсталлировать Prometheus и Grafana из тарболлов. Покажем, как можно запустить тот же мониторинговый сервер, используя возможности Docker. Демонстрационная хост-машина:
# uname -r
4.8.16-200.fc24.x86_64
# cat /etc/fedora-release
Fedora release 24 (Twenty Four)
Будут задействованы еще две виртуальные машины (192.168.42.131 и 192.168.42.132) в среде VMWare Workstation Pro 12.0, обе с Cache на борту. Их мы и будем мониторить. Версии:
# uname -r
3.10.0-327.el7.x86_64
# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.2 (Maipo)
…
USER>write $zversion
Cache for UNIX (Red Hat Enterprise Linux for x86-64) 2016.2 (Build 721U) Wed Aug 17 2016 20:19:48 EDT
На хост-машине поставим Docker и запустим его:
# dnf install -y docker
# systemctl start docker
# systemctl status docker
? docker.service — Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; disabled; vendor preset: disabled)
Active: active (running) since Wed 2017-06-21 15:08:28 EEST; 3 days ago
...
Запускаем Prometheus в Docker-контейнере
Загрузим последний образ Prometheus:
# docker pull docker.io/prom/prometheus
Если мы посмотрим на Docker-файл, то увидим, что образ читает конфиг из своего файла /etc/prometheus/prometheus.yml, а собранные метрики сохраняет в каталог /prometheus:
…
CMD [ "-config.file=/etc/prometheus/prometheus.yml", \
"-storage.local.path=/prometheus", \
...
При запуске Prometheus в Docker-контейнере укажем конфигурационный файл и базу данных для метрик брать с хост-машины. Это позволит нам «пережить» рестарт контейнера. Создадим на хост-машине каталоги для Prometheus:
# mkdir -p /opt/prometheus/data /opt/prometheus/etc
Создадим конфигурационный файл Prometheus:
# cat /opt/prometheus/etc/prometheus.yml
global:
scrape_interval: 10s
scrape_configs:
- job_name: 'isc_cache'
metrics_path: '/mgstat/5' # Tail 5 (sec) it's a diff time for ^mgstat. Should be less than scrape interval.
static_configs:
- targets: ['192.168.42.131:57772','192.168.42.132:57772']
basic_auth:
username: 'PromUser'
password: 'Secret'
Теперь можно запустить контейнер с Prometheus:
# docker run -d --name prometheus \
--hostname prometheus -p 9090:9090 \
-v /opt/prometheus/etc/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /opt/prometheus/data/:/prometheus \
docker.io/prom/prometheus
Проверим, что он запустился нормально:
# docker ps --format "{{.ID}}: {{.Command}} {{.Status}} {{.Names}}"
d3a1db5dec1a: "/bin/prometheus -con" Up 5 minutes prometheus
Запускаем Grafana в Docker-контейнере
Для начала качаем себе последний образ:
# docker pull docker.io/grafana/grafana
Затем запускаем его, указав, что базу данных Grafana (по умолчанию, это SQLite) будем хранить на хост-машине. Также делаем линк на контейнер с Prometheus, чтобы можно было из контейнера с Grafana ссылаться на контейнер с Prometheus:
# mkdir -p /opt/grafana/db
# docker run -d --name grafana \
--hostname grafana -p 3000:3000 \
--link prometheus \
-v /opt/grafana/db:/var/lib/grafana \
docker.io/grafana/grafana
# docker ps --format "{{.ID}}: {{.Command}} {{.Status}} {{.Names}}"
fe6941ce3d15: "/run.sh" Up 3 seconds grafana
d3a1db5dec1a: "/bin/prometheus -con" Up 14 minutes prometheus
Используем Docker-compose
Оба контейнера у нас запущены по одному. Более удобным способом запуска сразу нескольких контейнеров представляется использование Docker-compose. Поставим его, остановим текущие оба контейнера, сконфигурируем их запуск через Docker-compose и запустим заново.
# docker stop $(docker ps -a -q)
# docker rm $(docker ps -a -q)
# mkdir /opt/docker-compose
# cat /opt/docker-compose/docker-compose.yml
version: '2'
services:
prometheus:
image: docker.io/prom/prometheus
container_name: prometheus
hostname: prometheus
ports:
- 9090:9090
volumes:
- /opt/prometheus/etc/prometheus.yml:/etc/prometheus/prometheus.yml
- /opt/prometheus/data/:/prometheus
grafana:
image: docker.io/grafana/grafana
container_name: grafana
hostname: grafana
ports:
- 3000:3000
volumes:
- /opt/grafana/db:/var/lib/grafana
# docker-compose -f /opt/docker-compose/docker-compose.yml up -d
# # Выключить и удалить оба контейнера можно командой:
# # docker-compose -f /opt/docker-compose/docker-compose.yml down
# docker ps --format "{{.ID}}: {{.Command}} {{.Status}} {{.Names}}"
620e3cb4a5c3: "/run.sh" Up 11 seconds grafana
e63416e6c247: "/bin/prometheus -con" Up 12 seconds prometheus
Постинсталляционные процедуры
После запуска Grafana в первый раз нужно еще сделать две вещи: поменять пароль админа на веб-интерфейс (по умолчанию, логин/пароль — это admin/admin) и добавить Prometheus в качестве источника данных. Это можно сделать либо из веб-интерфейса, либо путем прямого редактирования базы данных Grafana SQLite (она по умолчанию лежит в файле /opt/grafana/db/grafana.db), либо путем REST-запросов.
-H "Content-Type:application/json" \
-d '{"oldPassword":"admin","newPassword":"TopSecret","confirmNew":"TopSecret"}'
Если пароль был изменен успешно, придет ответ:
{"message":"User password changed"}
Ответ типа:
curl: (56) Recv failure: Connection reset by peer
означает, что сервер Grafana еще не до конца стартовал и нужно подождать еще немного, после чего повторить предыдущую команду. Подождать можно, например, так:
# until curl -sf admin:admin@localhost:3000 > /dev/null; do sleep 1; echo "Grafana is not started yet";done; echo "Grafana is started"
После успешной смены пароля добавим источник данных Prometheus:
# curl -XPOST "admin:TopSecret@localhost:3000/api/datasources" \
-H "Content-Type:application/json" \
-d '{"name":"Prometheus","type":"prometheus","url":"http://prometheus:9090","access":"proxy"}'
Если источник данных был добавлен успешно, придет ответ:
{"id":1,"message":"Datasource added","name":"Prometheus"}
Создаем аналог ^mgstat
^mgstat пишет вывод в файл и в интерактивном режиме на терминал. Нам вывод в файл не нужен. Поэтому с помощью Студии создадим и скомпилируем в области USER программу ^mymgstat.int, с урезанным кодом ^mgstat.
mgstat(dly)
/*
Edited version of ^mgstat for Prometheus monitoring
Changes:
- Variables cnt, reqname and pagesz are deleted as well as all code connected to them;
- Output procedure was overwritten;
- Unused procedures were deleted.
*/
;
;
n dly
d init
d loop
q
init
s prefix="isc_cache_mgstat_"
s $zt="initerr" ; for class errors mainly??? the vers exist in 4.1
d GetVersionInfo(.Majver,.Minver,.OS)
i Majver<5 w "Sorry, this won't work on this version of Cache",! q // not supported on pre-5.0 systems.
s (odly,dly)=$g(dly,2) i dly>10 s dly=10
; set common memory offsets
s jrnbase=$ZU(40,2,94),maxval4=4294967295
s wdwchk=$ZU(40,2,146),wdphaseoff=$ZU(40,2,145)
s wdcycle=$ZU(79,1),stilen=$zu(40,0,1),szctrs=1
s (globufs,glostr)=$v($ZU(40,2,135),-2,stilen)/512 f i=1:1:5 { s tmp=$v($ZU(40,2,135)+(i*stilen),-2,stilen)*(2**(1+i))/1024,globufs=globufs+tmp,glostr=glostr_"^"_tmp } s globufs=globufs_"MB:"_glostr
if Majver>2008||((Majver=2008)&&(Minver>1)) { s roustr=$tr($system.Util.RoutineBuffers(),",","^"),roubufs=0 f i=1:1:$l(roustr,"^") { s roubufs=roubufs+$p(roustr,"^",i) } s roubufs=roubufs_"MB:"_roustr }
else {
i (Majver=5)&&(Minver<1) { s rbufsiz=32,rbstr=",routinebuffersize=assumed 32K" } else { s rbufsiz=$v($zu(40,2,164),-2,4)+240\1024,rbstr=",routinebuffersize="_rbufsiz_"K" }
s roubufs=$fn($V($zu(40,2,26),-2,stilen)*rbufsiz/1024,"",0)_"MB"_rbstr
}
s ncpus=$system.Util.NumberOfCPUs()
if Majver>2000 { // really > 5.2
s sznames="Global,ObjClass,Per-BDB",sztag="Gbl,Obj,BDB",szstr=$$GetSzctr(sznames) // seize statistics
if Majver>2008 {
if Majver>2009 {
s szctrs=$zu(69,74) ;0 for off, 1 for on - new in 2010.x - chg for API in 2011
}
s $zt="initcpuerr"
s ncpus=ncpus_":"_$$GetArchChipsCores() ;Arch^Chips^Cores
initcpuerr ;
k n
s $zt=""
}
} else {
s szstr="4,2,14",sztag="Gbl,Rou,Obj" // 5.2 and lower - glo,rou,obj
}
i szstr="" { s nszctrs=0 } else { s nszctrs=szctrs*$l(szstr,",") }
s numsz=nszctrs*3 // Sz, Nsz, Asz for each one.
; decide on offsets where they move between versions...
i (Majver=5)&&(Minver<1) {
;5.0 specific - no zu190!!! - oldstyle gather() and wd info
s getwdq="getwdinf50()",maxvalglo=maxval4,glocnt=11,gmethod=0,roubase=$zu(40,2,1)
s bdb0off=$ZU(40,2,128),bdbbase=$V($ZU(40,2,21),-2,"P"),bdbsiz=$ZU(40,29,0),wdqsizoff=$ZU(40,29,2),off=$V(bdb0off,-2,4),vwlocn=bdbbase+wdqsizoff
s ppgstats=0
} else {
s getwdq="getwdinfzu()",numbuff=$zu(190,2),ijulock=1,glocnt=$l($zu(190,6,1),","),gmethod=1
s ppgstats=glocnt'<20
i $zu(40,0,76)=4 { s maxvalglo=maxval4 } else { s maxvalglo=18446744073709551610 }
; wij only appears in >= 5.1... but handled by glocnt
; routine cache misses appears in >= 2007.1 but handled by glocnt
i glocnt>14 s glocnt=14
}
s ecpconncol=glocnt+numsz+2,alen=ecpconncol+5,maxeccon=$system.ECP.MaxClientConnections() i 'maxeccon s alen=ecpconncol-1
q
initerr
; handle init errs
q
loop
d gather(.oldval,gmethod)
h dly
d gather(.newval,gmethod)
d diffandfix()
d output
gather(array,usezu)
i usezu {
s zustats1=$zu(190,6,1) ; glostat
For i=1:1:glocnt S array(i)=$P(zustats1,",",i)
} else { ; old (5.0) glostat, gloref,glorefclient,logrd,phyrd,phywr,gloset,glosetclient,roulines
for i=1:1:glocnt s array(i)=$v((i-1)*4+roubase,-2,4) ;;;incomplete!!???10/22
}
d @getwdq,getwdp()
s i=glocnt,array($i(i))=$v(jrnbase,-2,4) ; jrnwrites
for jsz=1:1:nszctrs { s j=$p(szstr,",",jsz),szstat=$zu(162,3,j),array($i(i))=$p(szstat,","),array($i(i))=$p(szstat,",",2),array($i(i))=$p(szstat,",",3) }
i maxeccon s estats=$p($system.ECP.GetProperty("ClientStats"),",",1,21),array($i(i))=+$system.ECP.NumClientConnections(),array($i(i))=$p(estats,",",2),array($i(i))=$p(estats,",",6),array($i(i))=$p(estats,",",7),array($i(i))=$p(estats,",",19),array($i(i))=$p(estats,",",20)
i ppgstats s array($i(i))=$p(zustats1,",",20),array($i(i))=$p(zustats1,",",21)
q
diffandfix() ; note - this does not work if someone zeroed the counters manually
f i=1:1:glocnt {
i newval(i)<oldval(i) {
s dispval(i)=(maxvalglo-oldval(i)+newval(i))\dly
i dispval(i)>1000000000 s dispval(i)=newval(i)\dly
} else {
s dispval(i)=(newval(i)-oldval(i))\dly
}
s oldval(i)=newval(i)
}
s rdratio=$s(dispval(8)=0:0,1:$num(dispval(7)/dispval(8),2))
s grratio=$s(dispval(6)=0:0,1:$num(dispval(5)/dispval(6),2))
i maxeccon s dispval(ecpconncol)=newval(ecpconncol)
f i=glocnt+1:1:ecpconncol-1,ecpconncol+1:1:alen+$s(ppgstats:2,1:0) {
i newval(i)<oldval(i) {
s dispval(i)=(maxval4-oldval(i)+newval(i))\dly
i dispval(i)>1000000000 s dispval(i)=newval(i)\dly
} else {
s dispval(i)=(newval(i)-oldval(i))\dly
}
s oldval(i)=newval(i)
}
if nszctrs>0 {
f i=glocnt+2:3:glocnt+numsz-1 {
i 'dispval(i) {
s (dispval(i+1),dispval(i+2))="0"
} else {
s dispval(i+1)=$num(dispval(i+1)/dispval(i)*100,2)
s dispval(i+2)=$num(dispval(i+2)/dispval(i)*100,2)
}
}
}
q
output
s nl=$c(10)
w prefix_"global_refs "_dispval(5)_nl
w prefix_"remote_global_refs "_dispval(6)_nl
w prefix_"global_remote_ratio "_grratio_nl
w prefix_"physical_reads "_dispval(8)_nl
w prefix_"read_ratio "_rdratio_nl
w prefix_"global_updates "_dispval(10)_nl
w prefix_"remote_global_updates "_dispval(11)_nl
w prefix_"routine_refs "_dispval(1)_nl
w prefix_"remote_routine_refs "_dispval(2)_nl
w prefix_"routine_loads_and_saves "_dispval(3)_nl
w prefix_"remote_routine_loads_and_saves "_dispval(4)_nl
w prefix_"physical_writes "_dispval(9)_nl
w prefix_"write_daemon_queue_size "_wdqsz_nl
w prefix_"write_daemon_temp_queue "_twdq_nl
w prefix_"write_daemon_phase "_wdphase_nl
i glocnt>12 w prefix_"wij_writes "_dispval(13)_nl
i glocnt>13 w prefix_"routine_cache_misses "_dispval(14)_nl
w prefix_"journal_writes "_dispval(glocnt+1)_nl
s icnt=1
f i=1:1:numsz {
; global/rou/obj nseize/aseize are nodisp-100+
; and start at dispval(glocnt+2) and go up...
s rsc=$p(sztag,",",i)
w prefix_rsc_"seizes "_dispval(i+glocnt+1)_nl
s icnt=icnt+1
}
s ecpnames=$lb("act_ecp","add_blocks","purge_buffers_local","purge_server_remote","bytes_sent","bytes_received")
s icnt=0,ecnt=1
f i=glocnt+numsz+2:1:alen {
; ECP are nodisp 19-24 and start at glocnt+numsz+1 and go up...
w prefix_$lg(ecpnames,ecnt)_" "_dispval(i)_nl
s icnt=icnt+1
s ecnt=ecnt+1
}
i $d(ijulock) {
w prefix_"write_daemon_pass "_wdpass_nl
w prefix_"iju_count "_ijucnt_nl
w prefix_"iju_lock "_ijulock_nl
}
s ppgnames=$lb("process_private_global_refs","process_private_global_updates")
i ppgstats {
; PPG are nodisp 28,29 and start at alen+1
f i=0,1 w prefix_$lg(ppgnames,i+1)_" "_dispval(alen+i+1)_nl
}
w nl
q
getwdinfzu()
s twdq=0 f b=1:1:numbuff { s twdq=twdq+$p($zu(190,2,b),",",10) }
s wdinf=$zu(190,13),wdpass=$p(wdinf,","),wdqsz=$p(wdinf,",",2),twdq=twdq-wdqsz i twdq<0 s twdq=0
s misc=$zu(190,4),ijulock=$p(misc,",",4),ijucnt=$p(misc,",",5)
q
getwdinf50()
s wdqsz=0,last=maxval4
f i=0:1:5 d q:off=maxval4
. s off=$V(bdb0off+(i*4),-2,4)
. q:(off=last)!(off=maxval4)
. s wdqsz=wdqsz+$V(vwlocn+off,-3,4)
. s last=off
Q
getwdp()
s wdphase=0 q:'$V(wdwchk,-2,4)
q:'wdphaseoff
s wdphase=$V(wdphaseoff,-2,4)
Q
GetArchChipsCores() private { ;Returns <Arch>^<# Chips>^<# Cores>
if $D(^oddDEF("%SYSTEM.CPU")) {
s n=##class(%SYSTEM.CPU).%New()
s Arch=n.Arch
s nChips=n.nChips
s nCores=n.nCores
} else {
; These are all here in case we want more later
Set Arch=$zu(204,1)
Set Model=$zu(204,2)
Set Vendor=$zu(204,3)
Set nThreads=$zu(204,4)
Set nCores=$zu(204,5)
Set nChips=$zu(204,6)
Set nThreadsPerCore=$zu(204,7)
Set nCoresPerChip=$zu(204,8)
Set MTSupported=$zu(204,9)
Set MTEnabled=$zu(204,10)
Set MHz=$zu(204,11)
}
quit Arch_"^"_nChips_"^"_nCores
}
GetVersionInfo(majver,minver,os) PRIVATE {
if $D(^oddDEF("%SYSTEM.CPU")) {
s majver=$System.Version.GetMajor()
s minver=$System.Version.GetMinor()
s os=$System.Version.GetCompBuildOS()
} else {
s zv=$ZV
s majver=$p($p($p(zv,") ",2)," ",1),".",1)
s minver=$p($p($p(zv,") ",2)," ",1),".",2)
If zv["Windows" {
Set os="Windows"
} elseif zv["UNIX" {
Set os="UNIX"
} elseif zv["VMS" {
Set os="VMS"
} else {
Set os="N/A"
}
}
}
GetSzctr(Longnames) private {
s allsznames=$zu(162,0)_",",zuctr=""
f i=1:1:$l(Longnames,",") {
s ctr=$p(Longnames,",",i)
continue:(ctr="")||(ctr="Unused")
s nctr=$l($e(allsznames,1,$find(allsznames,ctr)),",")-1
continue:nctr=0
i zuctr="" {
s zuctr=nctr
} else {
s zuctr=zuctr_","_nctr
}
}
quit zuctr
}Чтобы можно было вызвать программу ^mymgstat через REST, делаем для нее в области USER класс-обертку.
Class my.Mgstat Extends %CSP.REST
{
XData UrlMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
<Routes>
<Route Url="/:delay" Method="GET" Call="getMgstat"/>
</Routes>
}
ClassMethod getMgstat(delay As %Integer = 2) As %Status
{
// By default, we use 2 second interval for averaging
do ^mymgstat(delay)
quit $$$OK
}
}Создаем ресурс, пользователя и веб-приложение
Теперь, когда у нас есть класс, отдающий метрики, мы можем создать RESTfull веб-приложение. Как и в первой статье, присвоим этому веб-приложению ресурс и создадим пользователя, который сможет этим ресурсом воспользоваться и от имени которого Prometheus будет собирать метрики. Дадим пользователю еще права на определенные базы. По сравнению с первой статьей, добавлено право на запись в базу CACHESYS (чтобы избежать ошибки <UNDEFINED>loop+1^mymgstat *gmethod") и добавлена возможность использовать ресурс %Admin_Manage (чтобы избежать ошибки <PROTECT>gather+10^mymgstat *GetProperty,%SYSTEM.ECP"). Проделаем указанные шаги на двух виртуальных серверах, 192.168.42.131 и 192.168.42.132. Предварительно, естественно, зальем наш код, программу ^mymgstat и класс my.Mgstat, в область USER на том, и на другом сервере (код есть на github).
# wget https://github.com/myardyas/prometheus/raw/master/mgstat/cos/mymgstat.xml
# wget https://github.com/myardyas/prometheus/raw/master/mgstat/cos/Mgstat.xml
#
# # Если на серверах нет доступа к Интернету, скопируйте программу и класс локально, а затем воспользуйтесь scp.
#
# csession <instance_name> -U user
USER>do $system.OBJ.Load("/tmp/mymgstat.xml*/tmp/Mgstat.xml","ck")
USER>zn "%sys"
%SYS>write ##class(Security.Resources).Create("PromResource","Resource for Metrics web page","")
1
%SYS>write ##class(Security.Roles).Create("PromRole","Role for PromResource","PromResource:U,%Admin_Manage:U,%DB_USER:RW,%DB_CACHESYS:RW")
1
%SYS>write ##class(Security.Users).Create("PromUser","PromRole","Secret")
1
%SYS>set properties("NameSpace") = "USER"
%SYS>set properties("Description") = "RESTfull web-interface for ^mymgstat"
%SYS>set properties("AutheEnabled") = 32 ; See description
%SYS>set properties("Resource") = "PromResource"
%SYS>set properties("DispatchClass") = "my.Mgstat"
%SYS>write ##class(Security.Applications).Create("/mgstat",.properties)
1
Проверяем доступность метрик с помощью curl
# curl --user PromUser:Secret -XGET http://192.168.42.131:57772/mgstat/5
isc_cache_mgstat_global_refs 347
isc_cache_mgstat_remote_global_refs 0
isc_cache_mgstat_global_remote_ratio 0
…
# curl --user PromUser:Secret -XGET http://192.168.42.132:57772/mgstat/5
isc_cache_mgstat_global_refs 130
isc_cache_mgstat_remote_global_refs 0
isc_cache_mgstat_global_remote_ratio 0
...
Проверяем доступность метрик из Prometheus
Prometheus у нас слушает порт 9090. Сначала проверяем состояние Targets:

Затем смотрим на любую из метрик:

Отображаем одну метрику
Покажем теперь одну метрику, например, isc_cache_mgstat_global_refs, в виде графика. Нам нужно будет добавить панель и вставить в нее график. Идем в Grafana (http://localhost:3000, логин/пасс — admin/TopSecret) и добавляем панель:

Добавляем график:

Редактируем его, нажав «Panel title», затем «Edit»:
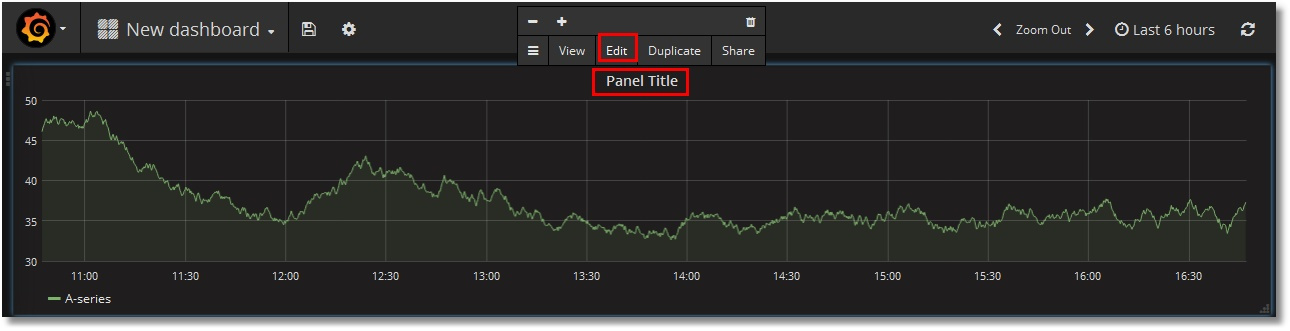
Указываем в качестве источника данных Prometheus и выбираем нашу метрику isc_cache_mgstat_global_refs. Разрешение выберем 1/1:

Даем имя графику:

Добавляем легенду:

Нажимаем сверху кнопку «Save» и даем имя дашбоарду:

Получаем что-то такое:

Отображаем все метрики
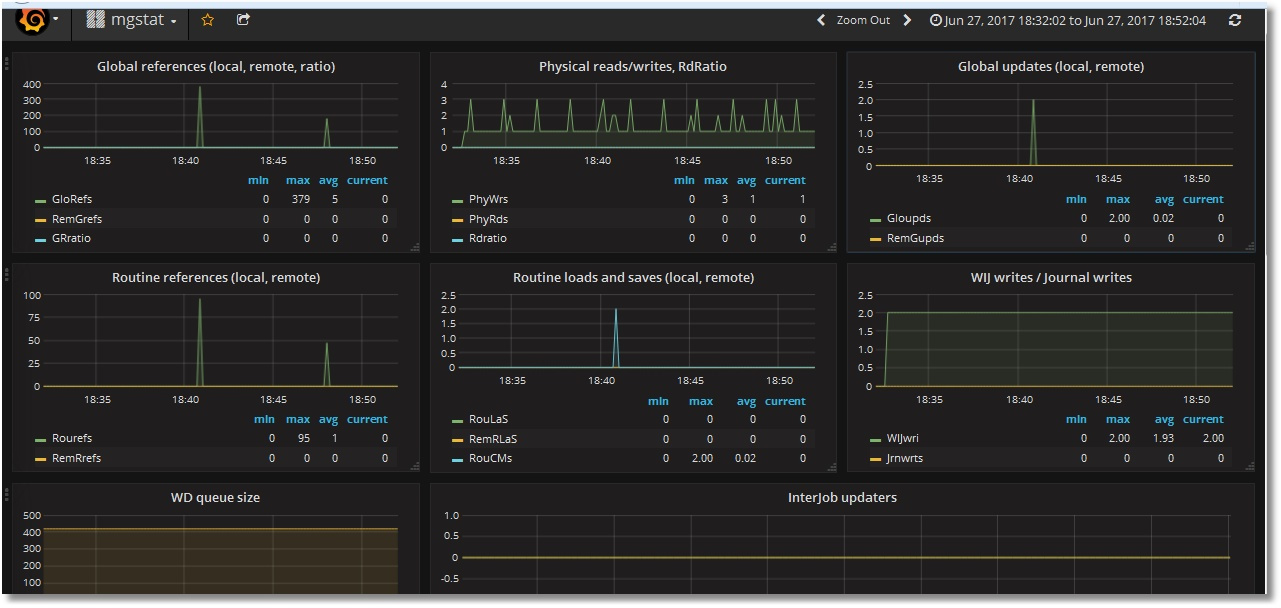
Аналогично накинем остальные метрики. В их числе будут две текстовые метрики — Singlestat. Получим такой дашбоард (показаны верхняя и нижняя части):


Сразу мешают два нюанса:
— скроллы в легенде (с увеличением числа серверов скроллить придется дольше);
— отсутствие данных в Singlestat-панелях (которые, естественно, предполагают единственное значение). У нас сервера два, вот и значения два.
Добавляем использование шаблона
Попробуем победить данные замечания введением шаблона инстансов. Для этого нам понадобится создать переменную, хранящую значение инстанса, и немного подредактировать запросы к Prometheus, согласно имеющимся правилам. То есть, вместо запроса "isc_cache_mgstat_global_refs" нам следует написать "isc_cache_mgstat_global_refs{instance="[[instance]]"}", предварительно создав переменную instance.
Создаем переменную:


В запросе к Prometheus указываем выбирать значения меток instance из каждой метрики. В нижней части наблюдаем, что значения наших двух инстансов определились. Нажимаем кнопку «Add»:

В верхней части дашбоарда появилась переменная с вариантами значений:

Теперь добавим использование этой переменной в запросы для каждой панели на дашбоарде, то есть, запросы типа "isc_cache_mgstat_global_refs" превратим в "isc_cache_mgstat_global_refs{instance="[[instance]]"}". Получим такой дашбоард (возле легенд имена инстансов оставлены специально, для проверки):

Singlestat-панели уже работают:

Скачать шаблон данного дашбоарда можно на github. Процедура его импорта в Grafana описана в первой части.
Напоследок сделаем сервер 192.168.42.132 ECP-клиентом для 192.168.42.131 и посоздаем глобалы для порождения ECP-трафика. Видим, что мониторинг ECP-клиента работает:

Итоги
Мы можем заменить отображение результатов работы утилиты ^mgstat в Excel он-лайн отображением в виде довольно симпатичных графиков. Минусом является то, что для этого нужно использовать альтернативную версию ^mgstat. В принципе, код исходной утилиты может меняться, что нами не учитывается. Однако мы получаем удобство наблюдения за происходящим в Cache.
Спасибо за внимание!
Продолжение следует ...
P.S.
Демо-стенд (для одного инстанса) доступен для просмотра здесь. Вход без логина/пароля.
Комментарии (14)

doublefint
03.07.2017 12:00Большое спасибо за обе статьи!
«отсутствие данных в Singlestat-панелях (которые, естественно, предполагают единственное значение). У нас сервера два, вот и значения два.» — делаем отдельную строку, определяем дополнительную переменную с именами серверов, в панели используем опцию «повторить для переменной». Вот тут пример
Замечание к реализации странице выдачи метрик — программа ( программа, Карл! ) и класс. Имхо класса более чем достаточно. Перед взятием метрик по коду размазана проверка версии сервера — если что, в каше есть режимы генерации кода
myardyas
03.07.2017 12:50Спасибо за комментарий!
По поводу решения для Singlestat-панелей. На community Murray Oldfield задавал вопрос о шаблонах. Поэтому сделал через шаблоны в качестве ответа. Надеюсь, статья будет переведена на английский и выложена там.
Как по мне, слова «рутина» и «программа» взаимозаменяемы.
Насчет размазанности проверки версий — это к ISC -). Взял код ^mgstat и оставил/заменил в нем нужное мне.
В следующий раз планирую вообще не использовать ^mgstat и брать метрики напрямую из SYS.Stats. Надо только внимательно сравнить выдачу SYS.Stats и всяких там $zu(190,2,1) и т.п. Жаль, далеко не все $zu описаны. Придется либо искать по коду, либо спрашивать у саппорта.doublefint
03.07.2017 13:25Поэтому сделал через шаблоны в качестве ответа
Так я же предлагаю улучшить их использование — переменные шаблона можно использовать для генерации панелей SingleStat.
слова «рутина» и «программа» взаимозаменяемы.
Замечание было не про термины рутина — программа, а про способ организации кода. Зачем вы используете дополнительный модуль ( рутина, программа ) с кодом, когда у вас есть класс, в который это все можно было сложить, задокументировать, покрыть тестами ( ыы :). Зачем в 2017 году использовать рутины-программы, когда у вас есть более удобная высокоуровневая абстракция — класс.
Насчет размазанности проверки версий — это к ISC -).
Нет, к вам. Это вы так организовали код, что одни и те же проверки многоратно повторяются. Принцип «Однажды и только однажды»?.. В Каше есть всё, чтобы переписать ваш код более лаконично и наглядно.
и брать метрики напрямую из SYS.Stats
Я попался с такой попыткой на версии 2014.1.4 — там баг для класса SYS.Stats.Dashboard. Имхо, более старые низкоуровневые функции работают надежней. Ну или тесты ;)myardyas
03.07.2017 13:53Так я же предлагаю улучшить их использование — переменные шаблона можно использовать для генерации панелей SingleStat.
Принимается как вариант улучшения.
Зачем вы используете дополнительный модуль
Тоже принимается. Это статья о возможности. К следующему разу будет реализация напрямую в классе. Тестов не обещаю -)
проверки многоратно повторяются.
Принимается в том смысле, что код альтернативной рутины выложен мной, стало быть, и «пахнет» по моей вине.
старые низкоуровневые функции работают надежней
Тоже попался на, кажется, 15-й версии. Но ISC рекомендует избавляться от использования $zu — раз. Лучше задокументировано — два. Ошибка исправлена — три.
В принципе, с glostats и diskstats полями в $zu уже разобрался, как и со статистикой по WD. С чем пока затык — это со статистикой по ECP. Назначение многих метрик буду выпытывать к саппорта.
Будет интересно продолжение (AlertManager, автообнаружение + больше метрик (взятых, возможно, действительно из $zu))?
Ну или какие темы, по-вашему, еще стоит осветить, если стоит?
doublefint
03.07.2017 16:08Думаю будет интересно, если поделитесь прикладным опытом исходя из типового сценария — вот «у одного моего знакомого» был grafana-дашборд для cache-сервера, в нем объединены метрики из ( node_exporter || wmi_exporter ) && cache_exporter… Какие именно метрики наиболее полезны и почему, куда смотреть в первую очередь, куда потом, куда копать глубже, как настроили для себя alert ы и примеры как справлялись с проблемными ситуациями
myardyas
03.07.2017 16:22Вас понял. Спасибо за ответ! Попробую что-то подобное подготовить. Есть как раз «одни мои знакомые» на винде. Посмотрю на них wmi_exporter. Знакомых, работающих на контейнерах, пока нет. Хотелось бы в деле посмотреть еще cadvisor_exporter. Тут есть мысль перевести сборку на Jenkins докер. Появится «знакомый». Недавно была хорошая статья по контейнеризации Cache. Также есть ваша статья по сборке на Jenkins. Сборкой на Jenkins уже давно пользуемся. Теперь еще один шаг вперед.
doublefint
03.07.2017 16:56Попробуйте также сборку на Gitlab, мне очень нравится
myardyas
03.07.2017 17:03Спасибо, попробуем. Также один очень хороший специалист, работающий ныне в TeamCity, хвалил TeamCity. Хотя последний, вроде как, проигрывает gitlab'у -)
osigida
Я конечно извиняюсь, но уникального материала здесь ровно 4 строки.
К чему это нужно? Показать что в докер можно завернуть почти все, а графана в связке с прометеусом умеет отображать графики?
myardyas
Цель была показать, как конкретно вывод ^mgstat можно показать наглядно. Про Docker тут сказано коротко, самое нужное для понимания. Остальной материал полностью мой, но если покажете, где что слизал касательно ^mgstat, буду благодарен.
osigida
Отчего-ж, именно по ^mgstat материал уникален, спору нет.
А вот пошаговая инструкция, по запуску докера и настройки борды в графане, уже несколько не в тренде.
myardyas
Соглашусь, что, возможно, некоторые шаги можно было просто упомянуть, не описывая. Однако еще одной своей задачей ставил изложение достаточно понятное даже для тех, кто докером и графаной до сих пор не пользовался. Ну ок, попробую учесть на будущее. Про SYS.Stats материал будет интересен?
osigida
не знаю что это, значит должно быть интересно узнать :-)
myardyas
Это набор классов внутри Cache, которые позволяют собрать тонны статистики о работе систем на платформе InterSystems. Еще насчет связки Prometheus-Grafana. AlertManager, Consul, PushGateway, Prometheus remote systems — считаем известными или же стоит уделить внимание? )