
В моей прошлой статье посвящённой освоению науки о данных (или по заграничному — Data Science) с абсолютного нуля (даже ниже чем -273 градуса по Кельвину) я обещал, что подготовлю материал о том, как я осваивал kaggle (буду писать с маленькой буквы, как у них на логотипе).
Для тех, кто так же, как и я только начинает знакомится с данным вопросом, поясню что как я понял kaggle это сайт, посвящённый соревнованиям и в некоторой степени обучению в области Data Science, где каждый может совершенно бесплатно и используя любые доступные инструменты, сделать прогноз по той или иной задаче.
Если вам интересно что же в итоге у меня из всего это вышло прошу под кат.
UPD: На свежую голову добавил небольшие пояснения про вкладку «данные» и про переобучение модели.

По доброй традиции начну статью, с описания своих навыков, чтобы начинающий читатель мог понять, что знаний у меня практически нет и тоже воодушевился.
Итак, мои знания о том, что такое Data Science и с чем его едят базируются на курсах от Cognitive class (СС) и на самоучителе Наука о данных с нуля (Data Science from Scratch) (по ссылкам мое мнение об этих ресурсах).
Чтобы вам было не обязательно тратить свое время, кратко резюмирую:
Поэтому не смотря на знание о некоторых концепциях в области Data Science открыв первую и похоже самую популярную задачку про Титаник, я оказался по сути «один в чистом поле», а вокруг были какие-то рейтинги, «блокноты» с решениями и люди, которые явно что-то знают…
Подозреваю, что моя статья про kaggle не первая и при желании можно найти разную информацию о том, что это и как начать с ним работать, но я все же хотел бы поделится своим опытом вхождения в этот удивительный мир.
Итак, как я уже сказал в самом начале kaggle это портал, посвященный соревнованиям в области науки о данных. Регистрация на портале совершенно бесплатна, представленный инструментарий, вроде бы тоже (если там есть, что-то платное напишите пожалуйста в комментариях я обновлю статью).
Соревнования на портале делятся на разные категории, за призовые места на некоторых дают деньги, некоторые задачи просто ради интереса, безусловно есть задачи ориентированы на новичков (как я понял, в них регулярно чистятся рейтинги), ну и есть какие-то полузакрытые соревнования, видимо как-то связанные с другими порталами.
Насколько я понял портал предназначается для того, чтобы пользователи могли посоревноваться в прогнозировании и похвастаться перед коллегами и работодателями высокими местами в таблицах лидеров, ну а компании возможно могут решить какие-то свои задачи в области исследований или даже найти сотрудников (на сайте есть такой раздел).
Портал представлен на английском языке так что, если вы им совсем не владеете возможно вам будет тяжело («спасибо КЭП!»).
Помню, когда регистрировался очень хотел спать, поэтому ничего не понял и плюнул, но надо отдать должное команде проекта, утром мне пришло письмо с приветствием и предложением начать знакомство с курса Titanic: Machine Learning from Disaster и ведь убедили «чертяки», я не смог им отказать.
Как мне показалось, задача с определением числа выживших на Титанике похоже — самая избитая и упоминается, наверное, в половине всех курсов по Data Science
(вот кстати отличная задачка для аналитики, узнать, как часто в курсах и книгах по Data Science упоминается задачка про Титаник и как часто будет упоминаться в будущем, если кто-то владеет данными, пишите в комментариях, по горячим следам обновлю статью)
На странице «Overview» соревнования есть описательная часть и требования к загружаемым вами результатам анализа, если вы на kaggle первый раз, то более полезными окажутся страницы с FAQ и Tutorials. Надо отметить, что последние две вкладки на задачах для опытных пользователей вполне могут (и скорей всего будут) отсутствовать.
FAQ: для данного соревнования поведает нам следующие ключевые вещи.
Tutorials: Для новичка жизненно необходимая вкладка, если вы зашли «с улицы» и ничего не понимаете, то вам (и мне) как раз туда. Учебные материалы можно поделить на 3 типа:
Блокноты и интерактивные туториалы представлены для языков R и Python. А в текстовых статьях к ним даже добавляется инструкция, о том как обработать данные с помощью Excel.
Есть и другие полезные страницы, например, «Data». На данной странице можно скачать файлы учебной и тестовой выборок, а также посмотреть пример, того как должен выглядеть файл, загружаемый на портал для оценки. Помимо прочего, на данной вкладе есть описание данных, расшифровка сокращений и пояснения, так что советую заглянуть.
Надо отметить, что при создании блокнота (вкладка «Kernels»), можно одним кликом загрузить набор данных из уже существующего соревнования.
Другие вкладки предлагаю вам изучить самостоятельно.
С чего начал я?
В начале статьи я ссылался на курсы СС (которые были больше ориентированы на R) и самоучитель (ориентированный на Python), поскольку книжка мне понравилась больше, то я выбрал Python.
Блокнотов на Python оказалось много, какие-то были по проще, какие-то наоборот содержали много развернуто изложенного материала, я понял, что вот так сразу не готов «с места в карьер» и начал с интерактивного туториала.
Хорошо тому, кто знает, а мне — плохо, поэтому без туториала было никак. Итак ссылка привела меня к этому курсу: "Kaggle Python Tutorial on Machine Learning". Курс бесплатный (хотя есть назойливый нюанс).
Что представляет из себя курс? Если кто-то сталкивался с codecademy, то вам все будет привычно. Слева описание и цели, справа код задачи и консоль Python. Сложностей почти не возникает, задания простые, отправлять код можно сколько угодно раз пока не получится, а если надоело, то можно взять подсказку или получить готовый ответ (если, конечно вы не жуткий фанат РПГ и вам не жалко баллов опыта)
Курс состоит из трех глав:
Туториал — несложный и проходится в течение часа, ну максимум двух.
Заметил, что при прохождении курса после завершения каждой главы у меня всплывало окно с предложением получить платный аккаунт и только после этого продолжить курс (кнопку закрытия я не заметил, может она и есть), если вам оно будет мешать то его можно удалить с помощью инструмента «просмотр кода элемента» (есть почти в любом современном браузере), удалить надо Div с классом который будет содержать слово «modal», ну например «modal-container», после того как окно пропадет, можно будет спокойно отправить результаты и перейти к следующей главе.
Не могу сказать, что курс очень информативный, но самые минимальные (прям крошечные) представления о библиотеках для анализа данных на Python дает, когда экспериментировал со своим блокнотом (о чем ниже), многие приёмы у них заимствовал.
Пройдя интерактивный курс, я решил, что не буду себя уважать, если отправлю те наборы данных, что он предлагает, даже не попытавшись поковыряться в блокнотах.
К слову сказать, платформа позволяет «форкнуть» понравившийся блокнот и в нем поэкспериментировать или же просто скачать себе код, чтобы поковырять его на своем компьютере.
Как я уже говорил, блокнотов много, я решил выбрать тот что выглядел попроще в освоении (переводить, большую «портянку» текста на английском в два часа ночи не хотелось чуть меньше чем совсем). Итак, я решил позаимствовать код из "Machine Learning from Start to Finish with Scikit-Learn", автор не обещает высокой точности предсказания, но ведь главное не победа, а участие.
Честно скажу воспользоваться хоть одним решением в его изначальном виде у меня рука не поднялась, и я попытался, хоть немного поковырять код и попробовать написать пару строчек своими руками, поэтому у меня получился жуткий монстр из кода интерактивного туториала и этого блокнота
Итак, код я решил править у себя на компьютере (ну не просто же так я ставил в прошлой статье Anaconda). Выкладывать свой код целиком не буду, уж очень позорно вышло, если кто-то захочет это вбить в свой блокнот Jupyter, то каждая секция кода, вставляется у меня в отдельную ячейку (но лучше не надо, он то предупреждения выдаст, то еще что-нибудь, это плохой пример для подражания).
Первым делом я в наглую спер фрагмент объявления данных
Затем позаимствовал код для построения пары диаграмм, которые у автора получились вполне наглядными. Одна показывала связь между выживаемостью мужчин и женщин из разных точек отправления:
второй график показывал туже связь, но уже относительно, к классам в которых жили пассажиры.
Графики есть в исходном блокноте, поэтому выкладывать картинки не буду.
Потом я решил, что я ничуть не хуже и тоже попробовал придумать свою диаграмму.
Я решил проверить, влияет ли как-то статус сопровождающего и класс пребывания на вероятность выживания ребенка до 18 лет.
Поскольку эта выборка для баловства и в расчетах не участвует, я сделал копию данных и преобразовал данные в нужный мне формат.
В итоге получилось, что-то. Эта диаграмма либо говорит, нам о том, что дети во 2-м пассажирском классе у которых был родитель вместо няньки выживали намного чаще, либо не говорит ни о чем кроме того, что я ошибся потому что за пять дней не реально освоить анализ данных =)
Перейдем к расчётной части. Забегая вперед скажу, что я залил свое решение на kaggle 2 раза, чтобы проверить изменения.
Итак, я понял, что вариант кода из интерактивного туториала не очень удобный и чтобы не плодить кучу одинакового кода, я решил позаимствовать у автора блокнота, вариант с написанием функций:
Функции преобразуют данные в цифровой формат, чтобы потом их можно было «скормить дереву».
Дальше эти функции я применил для обучаемой модели (data_train) и для тестовой (data_test)
назначил для дерева цель
дальше действия разделились
Вариант для первой модели. Я не полностью осознаю, что тут происходит, видимо можно понять, какое дерево он создал и какие параметры вносят больший вклад в прогноз.
Теперь создадим предсказание для тестового набора данных для первой модели и сохраним его в csv:
Забираем из папки .csv, возвращаемся на kaggle жмем «Submit Predictions» и получаем 0.689 достоверности. Не могу сказать, что это хорошо, но зато это же ПЕРВОЕ ПРЕДСКАЗАНИЕ! После такого, можно пойти работать в популярные ТВ шоу про экстрасенсов.
По причинам, о которых я расскажу в заключительной части, я не стал сильно беспокоится о качестве модели и не стал применять техники ее улучшения из интерактивного курса Data Camp (а они там есть).
Тем не менее, чтобы статья была наглядней давайте разберем одно небольшое улучшение.
Выше по тексту я предлагал код с комментарием: «# В2. ячейка для второй модели идет перед тем кодом, что будет после (в первой модели не применялась)» две строчки кода после комментария можно вставить и сразу (вреда не будет, но и пользы тоже).
Для чего нудны нам эти строчки? Это я решил проверить, как наличие семьи (сестер, братьев, родителей и т.п.) повлияет на выживаемость (идея во многом взята из интерактивного туториала). Так объединив поля «спутники» и «родственники» (мой вольный перевод), я получил поле «семья»
Заменим строки features = data_train[[«Pclass», «Sex», «Age», «Fare»]].values и test_features = data_test[[«Pclass», «Sex», «Age», «Fare»,«Family»]].values на:
В них добавился наш параметр влияния семьи, а в остальном все останется без изменений.
Как я понял команда print(d_tree.feature_importances_) показывает нам степень вклада каждого из параметров в итоговый результат модели.
Получим следующее:
1.[ 0.08882627 0.30933519 0.23498429 0.29841084 0.06844342].
2. 0.982042648709 — Похоже, что это точность подгонки модели
В строке 1 позиции в массиве соответствуют «Pclass», «Sex», «Age», «Fare»,«Family». Итак мы видим, что наш пункт про семью особо погоды не делает, но для любопытства все же зальем обновленный результат на kaggle.
И обнаружим, что наша модель, самую малость увеличила точность предсказания, теперь она составляет 0.72727. и этот результат уже в районе 6800 места в рейтинге =)
У вас может возникнуть вопрос, как же так точность прогнозирования в строке 2 была аж целых 0.98 с лишним почему в итоге на тестовой выборке получилось 0.72? По всей видимости, причина кроется в том, что модель «переобучена», то есть слишком сильно заточена, на предсказание выборки по набору данных data_train и при проверке набора data_test не проявляет должной гибкости. Эта проблема должна решаться настройками параметров нашего «дерева», об этом говорится в интерактивном курсе упомянутом ранее, я в рамках данной статьи не стал этого делать. Мы люди простые, нам и 0.72 хватит, поэтому перейдем к заключительной части.
Никогда бы не подумал, но искать зависимости в данных и пытаться делать прогнозы, оказывается – увлекательное и вполне себе азартное занятие! Несмотря на то, что с нуля начать тяжело, и как я понимаю практически полное отсутствие навыков в области мат. анализа, статистики и применения теории вероятности, еще не раз мне аукнется, в целом на начальном этапе процесс затягивает.
Как видите на примере трех статей, я показал, что с абсолютного нуля, можно вполне заинтересоваться предметом, причем если вы фанат Python, то вариант с Cognitive Class можно вполне пропустить без особого ущерба для понимания общих концепций (хотя он бесплатный и в принципе можно день два на него потратить, посмотреть инструменты).
Тем не менее в процессе подготовки материалов для этих трех статей, я понял, что для того чтобы не было мучительно больно, надо перейти к более качественной ступени обучения.
Поэтому, я думаю, что есть смысл зарегистрироваться на курс «Специализация Машинное обучение и анализ данных размещенный на Coursera», по крайней мере он на русском, так что не придется ломать голову над переводом непонятных терминов.
Вот так случайное любопытство грозит перерасти во что-то более серьезное, через пару месяцев, когда закончу курс поделюсь с уважаемыми читателями своим впечатлением о нем.
Всем добра! Удачно вам напрячь извилины!
Для тех, кто так же, как и я только начинает знакомится с данным вопросом, поясню что как я понял kaggle это сайт, посвящённый соревнованиям и в некоторой степени обучению в области Data Science, где каждый может совершенно бесплатно и используя любые доступные инструменты, сделать прогноз по той или иной задаче.
Если вам интересно что же в итоге у меня из всего это вышло прошу под кат.
UPD: На свежую голову добавил небольшие пояснения про вкладку «данные» и про переобучение модели.
Часть 1. «Белеет мой парус такой одинокий…» — немного о навыках
По доброй традиции начну статью, с описания своих навыков, чтобы начинающий читатель мог понять, что знаний у меня практически нет и тоже воодушевился.
Итак, мои знания о том, что такое Data Science и с чем его едят базируются на курсах от Cognitive class (СС) и на самоучителе Наука о данных с нуля (Data Science from Scratch) (по ссылкам мое мнение об этих ресурсах).
Чтобы вам было не обязательно тратить свое время, кратко резюмирую:
- Cognitive class – рассказал мне о том что такое Data Science и бегло продемонстрировал некоторый набор применяемых практик и инструментов, однако после прохождения курса ничего путного самостоятельно я делать не научился.
- Самоучитель – провел для меня беглую экскурсию в мир науки о данных, показал основные приемы и дал отсылки к базовым знаниям, однако из-за того, что в книге все функции для анализа были написаны с нуля, то пользоваться реальными библиотеками, (например, pandas) я так и не научился, ну а краткого курса Python представленного в книге, хватило ровно настолько чтобы сильно не «пучеглазить» при виде учебного кода из туториалов kaggle (о чем позже).
Поэтому не смотря на знание о некоторых концепциях в области Data Science открыв первую и похоже самую популярную задачку про Титаник, я оказался по сути «один в чистом поле», а вокруг были какие-то рейтинги, «блокноты» с решениями и люди, которые явно что-то знают…
Часть 2. «…На фоне стальных кораблей» — немного о kaggle и соревновании про Титаник
Подозреваю, что моя статья про kaggle не первая и при желании можно найти разную информацию о том, что это и как начать с ним работать, но я все же хотел бы поделится своим опытом вхождения в этот удивительный мир.
Итак, как я уже сказал в самом начале kaggle это портал, посвященный соревнованиям в области науки о данных. Регистрация на портале совершенно бесплатна, представленный инструментарий, вроде бы тоже (если там есть, что-то платное напишите пожалуйста в комментариях я обновлю статью).
Соревнования на портале делятся на разные категории, за призовые места на некоторых дают деньги, некоторые задачи просто ради интереса, безусловно есть задачи ориентированы на новичков (как я понял, в них регулярно чистятся рейтинги), ну и есть какие-то полузакрытые соревнования, видимо как-то связанные с другими порталами.
Насколько я понял портал предназначается для того, чтобы пользователи могли посоревноваться в прогнозировании и похвастаться перед коллегами и работодателями высокими местами в таблицах лидеров, ну а компании возможно могут решить какие-то свои задачи в области исследований или даже найти сотрудников (на сайте есть такой раздел).
Портал представлен на английском языке так что, если вы им совсем не владеете возможно вам будет тяжело («спасибо КЭП!»).
Помню, когда регистрировался очень хотел спать, поэтому ничего не понял и плюнул, но надо отдать должное команде проекта, утром мне пришло письмо с приветствием и предложением начать знакомство с курса Titanic: Machine Learning from Disaster и ведь убедили «чертяки», я не смог им отказать.
Как мне показалось, задача с определением числа выживших на Титанике похоже — самая избитая и упоминается, наверное, в половине всех курсов по Data Science
(вот кстати отличная задачка для аналитики, узнать, как часто в курсах и книгах по Data Science упоминается задачка про Титаник и как часто будет упоминаться в будущем, если кто-то владеет данными, пишите в комментариях, по горячим следам обновлю статью)
На странице «Overview» соревнования есть описательная часть и требования к загружаемым вами результатам анализа, если вы на kaggle первый раз, то более полезными окажутся страницы с FAQ и Tutorials. Надо отметить, что последние две вкладки на задачах для опытных пользователей вполне могут (и скорей всего будут) отсутствовать.
FAQ: для данного соревнования поведает нам следующие ключевые вещи.
- Что есть публичная таблица рейтинга, которая получена на основании загруженной вами оценки тестовой выборки и является лишь верхушкой айсберга *ba-dum-tss*.

- Вторая часть оценок скрыта от пользователя и проявит себя только после подведения итогов. И как я понял именно скрытые 50% являются ключевыми для определения победителя и похоже аналогичный подход, но с разным процентным соотношением характерен для многих других соревнований.
- В данном учебном соревновании рейтинг чистится раз в два месяца, это значит, что все ваши загрузки старше двух месяцев потеряют свой статус (как я понял), так что задача про Титаник не «для резюме», а именно для наработки навыков.
- Kaggle нам сообщит, о том что при желании вам не придется ставить себе что-либо на рабочую машину инструменты для анализа есть у kaggle в облаке.
Tutorials: Для новичка жизненно необходимая вкладка, если вы зашли «с улицы» и ничего не понимаете, то вам (и мне) как раз туда. Учебные материалы можно поделить на 3 типа:
- Хорошо задокументированные блокноты (других пользователей), в которых по шагам описаны варианты готового решения и изложена логика, которой руководствовался автор исследования.
- Ссылки на интерактивные туториалы от DataCamp
- Просто статьи.
Блокноты и интерактивные туториалы представлены для языков R и Python. А в текстовых статьях к ним даже добавляется инструкция, о том как обработать данные с помощью Excel.
Есть и другие полезные страницы, например, «Data». На данной странице можно скачать файлы учебной и тестовой выборок, а также посмотреть пример, того как должен выглядеть файл, загружаемый на портал для оценки. Помимо прочего, на данной вкладе есть описание данных, расшифровка сокращений и пояснения, так что советую заглянуть.
Надо отметить, что при создании блокнота (вкладка «Kernels»), можно одним кликом загрузить набор данных из уже существующего соревнования.
Другие вкладки предлагаю вам изучить самостоятельно.
С чего начал я?
В начале статьи я ссылался на курсы СС (которые были больше ориентированы на R) и самоучитель (ориентированный на Python), поскольку книжка мне понравилась больше, то я выбрал Python.
Блокнотов на Python оказалось много, какие-то были по проще, какие-то наоборот содержали много развернуто изложенного материала, я понял, что вот так сразу не готов «с места в карьер» и начал с интерактивного туториала.
Часть 3. «Хорошо тому, кто знает…» — Интерактивный туториал для решения задачи на Python
Хорошо тому, кто знает, а мне — плохо, поэтому без туториала было никак. Итак ссылка привела меня к этому курсу: "Kaggle Python Tutorial on Machine Learning". Курс бесплатный (хотя есть назойливый нюанс).
Что представляет из себя курс? Если кто-то сталкивался с codecademy, то вам все будет привычно. Слева описание и цели, справа код задачи и консоль Python. Сложностей почти не возникает, задания простые, отправлять код можно сколько угодно раз пока не получится, а если надоело, то можно взять подсказку или получить готовый ответ (если, конечно вы не жуткий фанат РПГ и вам не жалко баллов опыта)
Курс состоит из трех глав:
- Самые базовые основы синтаксиса и принципов анализа;
- Получение грубой модели на основе дерева принятия решений (Decision Trees). В принципе после этой главы у вас будет готовое решение, которое можно скачать и залить на kaggle;
- В третьей главе вы с помощью Random Forest улучшите свои предсказания. Эту модель так же можно будет залить на kaggle;
Туториал — несложный и проходится в течение часа, ну максимум двух.
Заметил, что при прохождении курса после завершения каждой главы у меня всплывало окно с предложением получить платный аккаунт и только после этого продолжить курс (кнопку закрытия я не заметил, может она и есть), если вам оно будет мешать то его можно удалить с помощью инструмента «просмотр кода элемента» (есть почти в любом современном браузере), удалить надо Div с классом который будет содержать слово «modal», ну например «modal-container», после того как окно пропадет, можно будет спокойно отправить результаты и перейти к следующей главе.
Не могу сказать, что курс очень информативный, но самые минимальные (прям крошечные) представления о библиотеках для анализа данных на Python дает, когда экспериментировал со своим блокнотом (о чем ниже), многие приёмы у них заимствовал.
Часть 4. «…Как опасен в океане» — человек с «блокнотом» на Python
Пройдя интерактивный курс, я решил, что не буду себя уважать, если отправлю те наборы данных, что он предлагает, даже не попытавшись поковыряться в блокнотах.
К слову сказать, платформа позволяет «форкнуть» понравившийся блокнот и в нем поэкспериментировать или же просто скачать себе код, чтобы поковырять его на своем компьютере.
Как я уже говорил, блокнотов много, я решил выбрать тот что выглядел попроще в освоении (переводить, большую «портянку» текста на английском в два часа ночи не хотелось чуть меньше чем совсем). Итак, я решил позаимствовать код из "Machine Learning from Start to Finish with Scikit-Learn", автор не обещает высокой точности предсказания, но ведь главное не победа, а участие.
Честно скажу воспользоваться хоть одним решением в его изначальном виде у меня рука не поднялась, и я попытался, хоть немного поковырять код и попробовать написать пару строчек своими руками, поэтому у меня получился жуткий монстр из кода интерактивного туториала и этого блокнота
Итак, код я решил править у себя на компьютере (ну не просто же так я ставил в прошлой статье Anaconda). Выкладывать свой код целиком не буду, уж очень позорно вышло, если кто-то захочет это вбить в свой блокнот Jupyter, то каждая секция кода, вставляется у меня в отдельную ячейку (но лучше не надо, он то предупреждения выдаст, то еще что-нибудь, это плохой пример для подражания).
Первым делом я в наглую спер фрагмент объявления данных
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import tree
%matplotlib inline
data_train = pd.read_csv('data/train.csv')
data_test = pd.read_csv('data/test.csv')
data_train.sample(5)Затем позаимствовал код для построения пары диаграмм, которые у автора получились вполне наглядными. Одна показывала связь между выживаемостью мужчин и женщин из разных точек отправления:
sns.barplot(x="Embarked", y="Survived", hue="Sex", data=data_train);
второй график показывал туже связь, но уже относительно, к классам в которых жили пассажиры.
sns.pointplot(x="Pclass", y="Survived", hue="Sex", data=data_train,
palette={"male": "blue", "female": "red"},
markers=["*", "o"], linestyles=["-", "--"]);
Графики есть в исходном блокноте, поэтому выкладывать картинки не буду.
Потом я решил, что я ничуть не хуже и тоже попробовал придумать свою диаграмму.
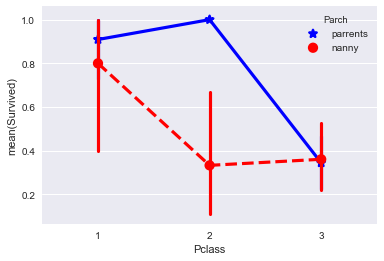
Я решил проверить, влияет ли как-то статус сопровождающего и класс пребывания на вероятность выживания ребенка до 18 лет.
Поскольку эта выборка для баловства и в расчетах не участвует, я сделал копию данных и преобразовал данные в нужный мне формат.
data_train2=data_train.copy()
data_train2=data_train2[data_train2["Age"] <= 18]
data_train2.Parch = data_train2.Parch.fillna("nanny")
data_train2["Parch"][data_train2["Parch"] != 0] = 'parrents'
data_train2["Parch"][data_train2["Parch"] != 'parrents'] = 'nanny'
В итоге получилось, что-то. Эта диаграмма либо говорит, нам о том, что дети во 2-м пассажирском классе у которых был родитель вместо няньки выживали намного чаще, либо не говорит ни о чем кроме того, что я ошибся потому что за пять дней не реально освоить анализ данных =)
Перейдем к расчётной части. Забегая вперед скажу, что я залил свое решение на kaggle 2 раза, чтобы проверить изменения.
Итак, я понял, что вариант кода из интерактивного туториала не очень удобный и чтобы не плодить кучу одинакового кода, я решил позаимствовать у автора блокнота, вариант с написанием функций:
def simplify_Age (df):
df.Age = data_train.Age.fillna(0)
def simplify_Sex (df):
df["Sex"][df["Sex"] == 'male'] = 0
df["Sex"][df["Sex"] == 'female'] = 1
def simplify_Embarked (df):
df.Embarked = df.Embarked.fillna(0)
df["Embarked"][df["Embarked"] == "S"] = 1
df["Embarked"][df["Embarked"] == "C"] = 2
df["Embarked"][df["Embarked"] == "Q"] = 3
def simplify_Fares(df):
df.Fare = df.Fare.fillna(0)
Функции преобразуют данные в цифровой формат, чтобы потом их можно было «скормить дереву».
Дальше эти функции я применил для обучаемой модели (data_train) и для тестовой (data_test)
simplify_Age(data_train)
simplify_Sex(data_train)
simplify_Embarked(data_train)
simplify_Fares(data_train)
simplify_Age(data_test)
simplify_Sex(data_test)
simplify_Embarked(data_test)
simplify_Fares(data_test)
назначил для дерева цель
target = data_train["Survived"].values
дальше действия разделились
# В2. ячейка для второй модели идет перед тем кодом, что будет после (в первой модели не применялась)
data_train["Family"]=data_train["Parch"]+data_train["SibSp"]
data_test["Family"]=data_test["Parch"]+data_test["SibSp"]
Вариант для первой модели. Я не полностью осознаю, что тут происходит, видимо можно понять, какое дерево он создал и какие параметры вносят больший вклад в прогноз.
#строку с features мы после немного модернизируем.
features = data_train[["Pclass", "Sex", "Age", "Fare"]].values
d_tree = tree.DecisionTreeClassifier()
d_tree = d_tree.fit(features, target)
print(d_tree.feature_importances_)
print(d_tree.score(features, target))
Теперь создадим предсказание для тестового набора данных для первой модели и сохраним его в csv:
# эту строку тоже
test_features = data_test[["Pclass", "Sex", "Age", "Fare"]].values
prediction = d_tree.predict(test_features)
submission = pd.DataFrame({
"PassengerId": data_test["PassengerId"],
"Survived": prediction
})
print(submission)
submission.to_csv(path_or_buf='data/prediction.csv', sep=',', index=False)
Забираем из папки .csv, возвращаемся на kaggle жмем «Submit Predictions» и получаем 0.689 достоверности. Не могу сказать, что это хорошо, но зато это же ПЕРВОЕ ПРЕДСКАЗАНИЕ! После такого, можно пойти работать в популярные ТВ шоу про экстрасенсов.
По причинам, о которых я расскажу в заключительной части, я не стал сильно беспокоится о качестве модели и не стал применять техники ее улучшения из интерактивного курса Data Camp (а они там есть).
Тем не менее, чтобы статья была наглядней давайте разберем одно небольшое улучшение.
Выше по тексту я предлагал код с комментарием: «# В2. ячейка для второй модели идет перед тем кодом, что будет после (в первой модели не применялась)» две строчки кода после комментария можно вставить и сразу (вреда не будет, но и пользы тоже).
Для чего нудны нам эти строчки? Это я решил проверить, как наличие семьи (сестер, братьев, родителей и т.п.) повлияет на выживаемость (идея во многом взята из интерактивного туториала). Так объединив поля «спутники» и «родственники» (мой вольный перевод), я получил поле «семья»
Заменим строки features = data_train[[«Pclass», «Sex», «Age», «Fare»]].values и test_features = data_test[[«Pclass», «Sex», «Age», «Fare»,«Family»]].values на:
features = data_train[["Pclass", "Sex", "Age", "Fare","Family"]].values
test_features = data_test[["Pclass", "Sex", "Age", "Fare","Family"]].values
В них добавился наш параметр влияния семьи, а в остальном все останется без изменений.
Как я понял команда print(d_tree.feature_importances_) показывает нам степень вклада каждого из параметров в итоговый результат модели.
Получим следующее:
1.[ 0.08882627 0.30933519 0.23498429 0.29841084 0.06844342].
2. 0.982042648709 — Похоже, что это точность подгонки модели
В строке 1 позиции в массиве соответствуют «Pclass», «Sex», «Age», «Fare»,«Family». Итак мы видим, что наш пункт про семью особо погоды не делает, но для любопытства все же зальем обновленный результат на kaggle.
И обнаружим, что наша модель, самую малость увеличила точность предсказания, теперь она составляет 0.72727. и этот результат уже в районе 6800 места в рейтинге =)
У вас может возникнуть вопрос, как же так точность прогнозирования в строке 2 была аж целых 0.98 с лишним почему в итоге на тестовой выборке получилось 0.72? По всей видимости, причина кроется в том, что модель «переобучена», то есть слишком сильно заточена, на предсказание выборки по набору данных data_train и при проверке набора data_test не проявляет должной гибкости. Эта проблема должна решаться настройками параметров нашего «дерева», об этом говорится в интерактивном курсе упомянутом ранее, я в рамках данной статьи не стал этого делать. Мы люди простые, нам и 0.72 хватит, поэтому перейдем к заключительной части.
Часть 5. «Айсберг встречным кораблям» — Заключение
Никогда бы не подумал, но искать зависимости в данных и пытаться делать прогнозы, оказывается – увлекательное и вполне себе азартное занятие! Несмотря на то, что с нуля начать тяжело, и как я понимаю практически полное отсутствие навыков в области мат. анализа, статистики и применения теории вероятности, еще не раз мне аукнется, в целом на начальном этапе процесс затягивает.
Как видите на примере трех статей, я показал, что с абсолютного нуля, можно вполне заинтересоваться предметом, причем если вы фанат Python, то вариант с Cognitive Class можно вполне пропустить без особого ущерба для понимания общих концепций (хотя он бесплатный и в принципе можно день два на него потратить, посмотреть инструменты).
Тем не менее в процессе подготовки материалов для этих трех статей, я понял, что для того чтобы не было мучительно больно, надо перейти к более качественной ступени обучения.
Поэтому, я думаю, что есть смысл зарегистрироваться на курс «Специализация Машинное обучение и анализ данных размещенный на Coursera», по крайней мере он на русском, так что не придется ломать голову над переводом непонятных терминов.
Вот так случайное любопытство грозит перерасти во что-то более серьезное, через пару месяцев, когда закончу курс поделюсь с уважаемыми читателями своим впечатлением о нем.
Всем добра! Удачно вам напрячь извилины!
Поделиться с друзьями
GolosCD
ОО титаник. Мы крутили вертели фичи и получили точность 0,77 это 3500 место.
Спасибо за статью.
BosonBeard
На здоровье, ну а касательно точности и рейтингов, судя по тому, что там у лидеров точность прогноза 100%, то видимо, все пути идеально предсказать данные, наверняка известны, так что пример, скорее нужен чтобы поверить себя и как раз «покрутить фичи» :)