
Перевод. Автор оригинала Samer Buna. Оригинал статьи.
Когда я впервые узнал о GraphQL после долгого использования различных REST API, то не мог удержаться от твитов такого содержания:
Rest API превратился в REST-in-Peace API. Долгих лет жизни GraphQL
Примечание переводчика – Rest In Peace, RIP – распространенная эпитафия "Покойся с миром". Первое слово в ней пишется так же, как акроним REST.
Тогда это была попытка рассмешить, но сейчас я убеждаюсь в справедливости шутливого прогноза.
Поймите правильно. Я не собираюсь обвинять GraphQL в убийстве REST или чём-то таком. REST не умрет никогда, также как XML будет жить вечно. Но кто в здравом уме станет использовать XML вместо JSON? На мой взгляд, GraphQL сделает для REST то же самое, что JSON сделал для XML.
Эта статья не стопроцентная агитация в пользу GraphQL. За его гибкость приходится платить. Этому посвящен отдельный раздел.
Я поклонник подхода Начните с вопроса ЗАЧЕМ, поэтому так и поступим.
Вкратце: Зачем GraphQL?
Вот три наиболее важные проблемы, которые решает GraphQL:
Необходимость несколько раз обращаться за данными для рендеринга компонента. GraphQL позволяет получить все необходимые данные за один запрос к серверу.
Зависимость клиента от сервера. С помощью GraphQL клиент общается на универсальном языке запросов, который: 1) отменяет необходимость для сервера жестко задавать структуру или состав возвращаемых данных и 2) не привязывает клиента к конкретному серверу.
- Неэффективные способы разработки. На GraphQL разработчики описывают необходимые для интерфейса данные с помощью декларативного языка. Разработчики сосредоточены на том, что хотят получить, а не как это сделать. Данные, необходимые для UI, тесно связаны с тем, как эти же данные описываются в GraphQL.
Статья подробно рассказывает, как GraphQL решает эти проблемы.
Начнем с простого описания для тех, кто еще не знаком с GraphQL.
Чем является GraphQL?
GraphQL это язык. Если научить ему приложение, оно сможет декларативно сообщать о необходимых данных бекенду, который также понимает GraphQL.
Как ребенок познает язык в детстве, а взрослея вынужден прикладывать больше усилий для изучения, – так и GraphQL намного легче внедрить во вновь создаваемое приложение, чем интегрировать в отлаженный сервис.
Чтобы сервис понимал GraphQL, нужно создать отдельный уровень в стеке обработки запросов и открыть к нему доступ клиентам, которым требуется взаимодействие с сервисом. Этот уровень можно считать транслятором языка GraphQL, или GraphQL-понимающим посредником. GraphQL не является платформой хранения данных. Поэтому нам не достаточно просто понимать синтаксис GraphQL, нужно еще транслировать запросы в данные.
Уровень GraphQL, написанный на любом языке программирования, содержит схему (schema) на подобии графа или диаграммы связей, из которой клиенты узнают о возможностях сервиса. Клиентские приложения, знакомые с GraphQL, могут делать запросы по этой схеме в соответствии со своими собственными возможностями. Такой подход отделяет клиентов от сервера и позволяет им развиваться и масштабироваться независимо.
Запросы на языке GraphQL могут быть либо запросами данных – query (операция чтения), либо мутациями – mutation (операции записи). В обоих случаях запрос это обычная строка, которую GraphQL-сервис разбирает, выполняет и сопоставляет с данными в определенном формате. Распространенный формат ответа для мобильных и веб-приложений – JSON.
Чем является GraphQL? (объяснение на пальцах)
GraphQL не выходит за рамки обмена данными. Существует клиент и сервер, которым надо взаимодействовать. Клиент должен сообщить серверу, какие данные нужны, а сервер – закрыть эту потребность актуальными данными. GraphQL находится в середине взаимодействия.
Скриншот из моего обучающего курса на Pluralsight – Building Scalable APIs with GraphQL
Вы спросите, почему клиент не может общаться с сервером напрямую? Конечно, может.
Есть несколько причин использовать уровень GraphQL между клиентами и серверами. Возможно, самая популярная причина, – эффективность. Обычно клиент получает на сервере множество ресурсов, но сервер отдает один ресурс за раз. Поэтому клиент вынужден многократно обращаться к серверу, чтобы получить все необходимые данные.
GraphQL перекладывает сложность многократных запросов на плечи сервера, пусть этим занимается уровень GraphQL. Клиент отправляет единственный запрос к уровню GraphQL и получает единственный ответ, в котором содержится все, что клиенту нужно.
Есть много других достоинств GraphQL. Например, важное преимущество при взаимодействии с несколькими сервисами. Когда много клиентов запрашивают данные из многих сервисов, уровень GraphQL посередине упрощает и стандартизирует обмен данными.

Скриншот из моего обучающего курса на Pluralsight – Building Scalable APIs with GraphQL
Вместо того чтобы напрямую обращаться к двум сервисам (на предыдущем слайде), клиент взаимодействует с уровнем GraphQL, и уже тот получает данные у сервисов. Таким образом, GraphQL избавляет клиента от необходимости поддерживать разные API, преобразуя единственный запрос клиента в запросы к нескольким поставщикам данных на понятном им языке.
Представим трех человек, говорящих на трех разных языках, и у каждого есть некая информация. Если нужно задать вопрос, требующий объединить знания всех персон, то помощь переводчика, говорящего на всех трех языках, существенно упростит получение ответа. Именно этим занимается GraphQL.
Но компьютеры пока не столь умны, чтобы самостоятельно отвечать на произвольные вопросы, и где-то должны существовать алгоритмы. Вот почему на уровне GraphQL необходимо задать схему (schema), которую смогут использовать клиенты.
Схема в основе своей – это документ о возможностях, перечисляющий все вопросы, которые клиент может адресовать уровню GraphQL. Использовать схему можно довольно гибко, поскольку речь идет о графе (graph) узлов. В сущности, схема ограничивает то, что можно запросить на уровне GraphQL.
Не совсем понятно? Давайте взглянем на GraphQL, как на замену REST API, чем он в действительности является. Позвольте ответить на вопрос, который вы, наверняка, сейчас задаете.
Что не так с REST API?
Большая проблема REST API в многочисленности точек назначения (endpoints). Это вынуждает клиентов делать много запросов, чтобы получить нужные данные.
REST API представляет собой набор точек назначения, каждая из которых соответствует ресурсу. Если клиенту нужны разные ресурсы, приходится делать несколько запросов, чтобы собрать все необходимые данные.
REST API не предлагает клиенту язык запросов. Клиент не влияет на то, какие данные возвращает сервер. Просто нет языка, на котором клиент мог бы указать это. Точнее говоря, доступные клиенту средства влиять на сервер очень ограничены.
Например, точка назначения для операции READ позволяет сделать одно из двух:
- GET
/ResouceName– получить список записей; - GET
/ResourceName/ResourceID– получить запись по ID.
Клиент не может указать, например, какие поля записи хочет взять у данного ресурса. Эта информация зашита в самом REST-сервисе, и он всегда вернет все предусмотренные поля независимо от того, какие из них нужны клиенту. В GraphQL эта проблема называется перевыгрузкой (over-fetching) информации, которая не требуется. Перевыгрузка напрасно нагружает сеть и расходует память на стороне клиента и сервера.
Еще одна значимая проблема REST API – версионирование. Необходимость поддерживать несколько версий означает новые точки назначения. Это влечет дополнительные трудности в использовании и поддержке API и может стать причиной дублирования кода на сервере.
GraphQL призван решить указанные задачи. Конечно, это не все проблемы REST API, но я не хочу углубляться в то, чем REST API является или не является. Скорее, говорю об общепринятом ресурсо-ориентированном подходе к API на основе точек назначения HTTP. Со временем каждый такой API превращается в мешанину обычных точек назначения, как предписывает REST, и специальных, добавленных по соображениям производительности. И тут альтернатива в виде GraphQL выглядит намного лучше.
Что стоит за магией GraphQL?
GraphQL основан на разных идеях и архитектурных решений, но, пожалуй, наиболее важными являются следующие:
GraphQL-схема является строго типизированной. Чтобы создать схему, задают поля (fields) определенных типов (types). Эти типы могут быть примитивами или пользовательскими типами, но все в схеме типизировано. Развитая система типов открывает такие возможности, как интроспекция API, и позволяет создавать мощные инструменты для клиентской и серверной части.
GraphQL описывает данные в виде графа, поскольку фактически совокупность данных представляет собой граф. Когда нужно визуализировать данные, граф – наиболее подходящая структура. Исполняемый код GraphQL сохраняет это представление данных благодаря API, в котором форма запросов и ответов отражает присущую данным форму графа.
- В GraphQL принято декларативно выражать потребность в данных. Для этого клиенту дается декларативный язык. Природа декларативности изначально настраивает на такое понимание языка GraphQL, которое близко к способам думать о данных на родном языке. Это очень упрощает работу с GraphQL API по сравнению с другими подходами.
Благодаря последнему пункту я лично верю в превосходство GraphQL.
Все это высокоуровневые концепции. Рассмотрим чуть подробнее.
Для решения проблемы множественных запросов, GraphQL превращает сервер в единственную точку назначения. По сути, GraphQL абсолютизирует идею о настраиваемой точке назначения и делает весь сервер такой точкой, которая может ответить на любой запрос.
Другая важная идея – наличие развитого языка запросов, благодаря которому клиент может работать с единственной точкой назначения. Без такого языка не было бы смысла ограничивать количество точек назначения. Нужен язык для описания настраиваемых запросов и возврата данных.
С помощью языка запросов взаимодействием управляют клиенты. Они запрашивают, что им нужно, а сервер возвращает именно то, что запрошено. Это решает проблему перевыгрузки данных.
К версионированию GraphQL относится интересно. От версионирования можно полностью отказаться. По сути, можно добавлять поля, не удаляя существующие, ведь данные представляют собой граф, и можно как угодно наращивать на нем узлы. Поэтому можно оставить пути для старых API и ввести новые, не помечая их номерами версий. Просто API подрос.
Это особенно актуально для мобильных клиентов, поскольку невозможно прямо указать им, какую версию API использовать. Установленное мобильное приложение может использовать старую версию API на протяжении многих лет. Для веб этой проблемы нет, поскольку можно просто заменить код веб-приложения на сервере. Но это намного сложнее для мобильных приложений.
Все еще не убедил? Что если сравнить GraphQL и REST на конкретном примере?
RESTful API против GraphQL API?—?Пример
Допустим, разрабатывается интерфейс на тему фильма «Звездные войны» и его персонажей.
Первое, что нужно создать, – простой визуальный компонент для показа информации о каком-то одном персонаже Звездных войн. Возьмем Дарта Вейдера, который регулярно появляется на протяжении всего фильма. Компонент будет показывать имя, дату рождения, название планеты и названия всех фильмов, в которых участвует персонаж.
Звучит легко, но мы имеем дело с тремя различными ресурсами: Person, Planet и Film. Они достаточно просто взаимосвязаны, так что любой угадает структуру данных. Объект Person принадлежит планете и сам владеет от одного до нескольких объектов Film.
Данные для первого компонента выглядят так:
{
"data": {
"person": {
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planet": {
"name": "Tatooine"
},
"films": [
{ "title": "A New Hope" },
{ "title": "The Empire Strikes Back" },
{ "title": "Return of the Jedi" },
{ "title": "Revenge of the Sith" }
]
}
}
}Пусть с сервера приходит именно такая структура. Тогда можно визуализировать данные в React таким образом:
// The Container Component:
<PersonProfile person={data.person} ></PersonProfile>
// The PersonProfile Component:
Name: {person.name}
Birth Year: {person.birthYear}
Planet: {person.planet.name}
Films: {person.films.map(film => film.title)}Это простой пример, и поскольку нам, наверное, помогает знание Звездных войн, то связь между UI и данными очевидна. UI использует все придуманные нами ключи из JSON.
Посмотрим, как получить эти данные через RESTful API.
Сначала получим информацию о персонаже по ID. Ожидается, что RESTful API предоставляет ее так:
GET - /people/{id}Такой запрос вернет имя, дату рождения и прочую информацию о персонаже. Хороший RESTful API также сообщит ID планеты персонажа и ID всех фильмов с его участием.
Ответ JSON может выглядеть так:
{
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planetId": 1
"filmIds": [1, 2, 3, 6],
*** other information we do not need ***
}Затем получаем название планеты:
GET - /planets/1И затем получаем названия фильмов:
GET - /films/1
GET - /films/2
GET - /films/3
GET - /films/6И только после шести запросов мы можем собрать ответы и обеспечить компонент необходимыми данными.
Кроме шесть запросов для визуализации довольно простого компонента, это решение было императивным. Мы указали, как получить и обработать данные, чтобы их можно было передать компоненту.
Вы можете сами попробовать и увидеть, что я имею в виду. У Звездных войн есть RESTful API по адресу http://swapi.co/. Сконструируйте объект данных персонажа. Ключи могут называться чуть иначе, но урлы ресурсов будут те же. Вам потребуется ровно шесть запросов. Более того, вы получите избыточную информацию, не нужную для компонента.
Конечно, это одна из возможных реализаций RESTful API для этих данных. Можно представить реализацию лучше, которая упрощает задачу. Например, если в API доступны вложенные ресурсы и сервер знает о взаимосвязи персонажа и фильмов, можно получить фильмы так:
GET - /people/{id}/filmsНо простой RESTful API наверняка не имеет такой возможности, и придется просить бекенд-разработчиков создать для нас дополнительные точки назначения. Такова практика масштабирования RESTful API – приходится добавлять все новые точки назначения, чтобы соответствовать потребностям клиентов. Поддерживать эти точки довольно трудоемко.
Теперь взглянем на подход GraphQL. Сервер GraphQL по максимуму воплощает идею настраиваемой точки назначения, доводя идею до абсолюта. На сервере есть только одна точка назначения, и способ связи с ней не важен. Если обратиться по HTTP, то метод HTTP-запроса будет проигнорирован. Предположим, имеется точка назначения GraphQL, доступная на /graphql по HTTP.
Поскольку ставится задача получить все данные за раз, нужен способ указать серверу состав данных. Для этого служит запрос GraphQL:
GET or POST - /graphql?query={...}Запрос GraphQL – это просто строка, в которой указаны все необходимые данные. И здесь становится видна сила декларативности.
По-русски, потребность в данных выражается так: для указанного персонажа нужны имя, дата рождения, название планеты и названия всех его фильмов. В GraphQL это выглядит так:
{
person(ID: ...) {
name,
birthYear,
planet {
name
},
films {
title
}
}
}Сравните, как описана потребность в данных на человеческом языке и на GraphQL. Описания настолько близки, насколько возможно. Также сравните запрос GraphQL и тот JSON, с которого мы начали. Запрос в точности повторяет структуру ожидаемого JSON, не включая значения. Если провести параллель между запросом и ответом, то запрос является ответом без данных.
Если ответ выглядит так:
Ближайшая к солнцу планета – Меркурий.То вопрос можно представить тем же самым выражением, но без конкретного значения:
(Какая) ближайшая к солнцу планета?Таким же сходство обладает запрос GraphQL. Если взять результирующий JSON, убрать все «ответы» (значения), то получим запрос GraphQL, подходящий на роль вопроса о данном JSON.
Теперь сравним запрос GraphQL c декларативным кодом React UI, в котором описаны данные. Все, что указано в запросе GraphQL, используется в UI, и все используемое в UI присутствует в запросе.
Это отличный способ представлять модель данных GraphQL. Интерфейс знает, какие данные нужны, и получить их не составляет труда. Оформление запроса GraphQL – это простая задача по выявлению того, что используется в качестве переменных непосредственно в UI.
Если поменять местами части этой модели, она будет так же полезна. По запросу GraphQL легко представить, как используется ответ в UI, поскольку ответ имеет такую же «структуру», как запрос. Не нужно специально изучать ответ чтобы понять, как его использовать, и даже не нужна документация по API. Все внутри запроса.
У Звездных войн имеется GraphQL API по адресу. Попробуйте с его помощью получить данные о персонаже. Есть незначительные отличия, но в целом запрос для получения необходимых данных в этом API выглядит так (с Дартом Вейдером в качестве примера):
{
person(personID: 4) {
name,
birthYear,
homeworld {
name
},
filmConnection {
films {
title
}
}
}
}Запрос вернет структуру очень близкую к потребностям визуального компонента. Но главное, все данные получены за один раз.
Плата за гибкость GraphQL
Идеальное решение – миф. Вместе с гибкостью GraphQL приходят некоторые проблемы и заботы.
Одна из угроз, которой открыт GraphQL, это сетевые атаки на исчерпание ресурсов (типа Denial of Service). Сервер GraphQL может быть атакован избыточно сложными запросами, потребляющими все ресурсы. Легко запросить данные с глубокой вложенностью (пользователь –> друзья –> друзья друзей … ) или применить синонимы полей, чтобы принудить сервер получать одни и те же данные много раз. Хотя подобные атаки происходят не только на GraphQL, при работе с GraphQL нужно иметь их в виду.
Существует несколько противодействий. Можно анализировать стоимость каждого запроса перед выполнением и вводить ограничения на количество данных, которые может потреблять запрос. Можно ввести таймаут на прерывание слишком долгого запроса. Также, поскольку GraphQL лишь уровень, связывающий запрос с хранилищами данных, можно задавать ограничения на более глубоких уровнях под GraphQL.
Если GraphQL API не публичный и предназначен для внутренних клиентов (мобильных или веб), можно использовать списки доступа и предварительно одобренные запросы. Клиенты требуют сервер выполнить такие запросы, указывая вместо запроса его идентификатор. Кажется, Facebook применяет такой подход.
Еще один вопрос при работе с GraphQL – идентификация и авторизация пользователей. Когда выполнять ее – перед, во время или после обработки запроса на GraphQL?
Чтобы ответить на этот вопрос, будем считать, что GraphQL это DSL (domain specific language – язык предметной области) поверх обычной логики получения данных на бекенде. Действительно, это просто дополнительный уровень между клиентом и сервисом данных (или несколькими сервисами).
Другим уровнем будем считать идентификацию и авторизацию. GraphQL не оказывает содействия в реализации этих задач. Он не для того. Но если поместить этот уровень за GraphQL, можно использовать GraphQL для передачи токенов доступа между клиентами и той логикой, которая с ними работает. Примерно так же выполняется идентификация и авторизация в RESTful API.
В GraphQL сложнее кешировать данные на клиенте. С RESTful API это проще, поскольку он подобен словарю. Конкретный адрес возвращает конкретные данные. Можно непосредственно использовать адрес как ключ кеширования.
В GraphQL тоже можно использовать текст запроса в качестве ключа. Но этот подход не очень эффективен и может нарушить целостность данных. Результаты разных запросов могут пересекаться, и такое примитивное кеширование не подходит в этом случае.
Однако существует блестящее решение этой проблемы. Graph Query равно Graph Cache. Если нормализовать данные, которые сформировал GraphQL: превратить иерархическую структуру в плоский список записей и присвоить каждой записи уникальный идентификатор, – то можно легко кешировать записи по отдельности, вместо целого ответа.
Это не так просто реализовать. Существуют взаимозависимые записи, и приходится работать с зацикленными графами. Чтобы записать в кеш или прочитать из него, необходимо полностью разобрать запрос. Требуется дополнительный уровень логики для работы с кешем. Но этот метод намного превосходит кеширование на основе текста запроса. Фреймворк Relay.js реализует эту стратегию кеширования «из коробки».
Возможно, самая большая проблема при использовании GraphQL – так называемые N+1 SQL-запросы. В GraphQL поля запроса реализованы как обычные функции, отправляющие запросы к базе данных. Чтобы заполнить все поля данными, может потребоваться новый SQL-запрос на каждое поле.
В обычном RESTful API легко проанализировать, выявить и решить проблему N+1, просто улучшая сконструированные SQL-запросы. Но в GraphQL, который обрабатывает поля динамически, это сложнее. К счастью, Facebook одним из первых предложил решение этой проблемы – DataLoader.
Название намекает, что утилита DataLoader читает данные из базы и предоставляет функциям, обрабатывающим поля запроса GraphQL. Можно использовать DataLoader вместо прямого чтения данных из базы. Он действует как посредник, уменьшая фактически производимые нами SQL-запросы к базе.
Для этого DataLoader применяет кеширование и пакетное выполнение запросов. Если один клиентский запрос получает из базы ответы на несколько разных вопросов, DataLoader может объединить все эти вопросы и одним пакетом получить ответы. Он также кеширует ответы для ускорения обработки последующих запросов к тем же ресурсам.
...
Спасибо за внимание. Я также разработал онлайн-курсы на Pluralsight и Lynda. Самые последние курсы – Advanced React.js, Advanced Node.js и Learning Full-stack JavaScript.
Я провожу онлайн- и офлайн-тренинги для групп по JavaScript, Node.js, React.js и GraphQL от начального до продвинутого уровня. Напишите мне, если ищете преподавателя (англ.). Если возникли вопросы по данной статье или другим моим статьям, меня можно найти в этом аккаунте слак (принимаются приглашения самому себе) и задать вопрос в комнате #questions.
Автор оригинала Samer Buna
Оригинал статьи
Комментарии (132)

sopov
26.07.2017 15:24N+1 SQL-запросы можно фильтровать на уровне middleware в Express.js или по хэшу запроса и только для авторизованных пользователей.
Может кто поделится Best Practics?

a-bobkov
26.07.2017 15:31+9Было бы интереснее почитать сравнение GraphQL и ODATA (http://www.odata.org), которая давно решает эту же задачу.
Alexs177
26.07.2017 15:43+19И только после шести запросов мы можем собрать ответы и обеспечить компонент необходимыми данными.
Полнейший бред. Бэкенд может спокойно возвращать вложенный JSON. Сейчас бэкенд на .NET так работает, Django REST это умеет.
Т.е. вместо того чтобы найти нормального бэкенд разработчика предлагается ещё больше всё усложнить.DrFdooch
26.07.2017 18:51+1Проблема здесь не во вложенности JSON, а в том, что если мы делаем ресурс person, то запрос этого ресурса не должен возвращать что-то, кроме данных самого ресурса и гиперссылок на связанные ресурсы. Соответственно, чтобы вытащить какую-то незначительную информацию для отображения (имя связанного ресурса film, например), придется выполнять все эти дополнительные запросы. Я не большой знаток HATEOAS, но предполагаю что конкретно эту задачу в рамках RESTful архитектуры даже можно решить его средствами (доп. полем displayName).
В целом же я сторонник той трактовки REST, которая предполагает создание отдельного ресурса, возвращающего максимум информации минимумом запросов. В приведенном примере это был бы ресурс personRoot.
zelenin
26.07.2017 19:11+7запрос этого ресурса не должен возвращать что-то, кроме данных самого ресурса и гиперссылок на связанные ресурсы
это не так. существование ресурсов — вот парадигма rest. Должны ли вложенные документы быть или нет, rest не говорит. rest — это вообще не спека. Это набор общих принципов. Все, что в прицнипах не оговорено, ты волен делать сам. Одна из спек rest — jsonAPI — например описывает возможность вложенных полей.
DrFdooch
26.07.2017 19:35возможности опасны) вложенные сущности — это избыточность, которая не всегда нужна.
понятно, что нужно соблюдать баланс, но всё-таки в общем случае лучше иметь еще и расширенную версию ресурса, чем только одну, но перегруженную.zelenin
26.07.2017 19:40+6ну в graphql же у вас есть возможность вложенности. Опасно вам стало?
rest не описывает вложенность. но никому не мешает написать спеку с описанной вложеностью, и методами для частичного получения полей и документов.
А graphql это сделал, и сделал неплохо, и сделал досконально — в этом соль.DrFdooch
26.07.2017 20:00согласен. но изначальный комментарий про вложенность JSON для меня всё равно звучит странно)

enchantinggg
28.07.2017 01:07JSONAPI спецификация включает в себя возможность кастомного выбирания зависимостей. То есть если у нас есть endpoint, который возвращает пользователя, и мы хотим получить всех его друзей, то мы добавляем в параметр запроса `include=friends`, и JSONAPI возвращает relation объект, который описывается связь, а так же сами данные друзей в объекте `include`.
Самый большой гемор с JSONAPI — собирать все данные, на мобильных приложениях это оказывается довольно весомо, тем более на ReactNative, где код выполняется на JS'e и слегка подтормаживается. GraphQL очень хорош для мобильных приложений, где клиент должен быть максимально быстрым и тупым. Вся структура ответа изначально известна, красивая чистая верстка без мучений с линковкой данных.
itollu
28.07.2017 13:34Почему возможности опасны? Это один из базовых принципов построения архитектуры: ограничивать спектр возможностей, но не исключая их, оставляя выбор конкретных решений разработчикам этих решений, следующих данной архитектуре.
Ведь в конце концов, если вернуться к истокам этой аббревиатуры, REST — это архитектурный стиль. То бишь, поименованный набор архитектурных ограничений (см. диссертацию Филдинга). У этого архитектурного стиля есть определённый и хорошо описанный контекст, набор достоинств и отстоинств (в той же диссертации).
GraphQL — это же не архитектурный стиль. Почему мы их сравниваем? (Или я ошибаюсь?)
На мой взгляд, у REST есть ещё один замечательный юз-кейс в современных микросервисных системах, который на момент написания диссертации ещё не существовал. Если ввести дополнительное ограничение и оставить только безопасные и идемпотентные методы — тогда он отлично будет применим в CQRS/ES для моделей для чтения.
DrFdooch
28.07.2017 13:49Почему возможности опасны?
потому что ведут к разнообразию, а разнообразие в рамках одного проекта ведет к хаосу.
GraphQL — это же не архитектурный стиль. Почему мы их сравниваем? (Или я ошибаюсь?)
потому что GraphQL плохо вписывается в парадигму REST, и использование его как инструмента ведет к необходимости пересмотра архитектуры в целом.zelenin
28.07.2017 14:09+1архитекуры чего? только адаптеров клиентов к апи. graphql — это view. view не требует пересмотра архитектуры.
DrFdooch
28.07.2017 16:00архитектуры этого самого апи.
в вопросе противопоставления GQL и REST реализация REST предполагает наличие раздельных эндпоинтов для разных сущностей. соответственно, необходимости делать множество запросов к апи для получения множества связанных сущностей.
статья и большая часть обсуждения, действительно, не имеют смысла при наличии адаптеров между апи и потребителем. но адаптеры — это дополнительная сложность, которой стараются избежать, потребляя апи напрямую.
использование GQL напрямую с апи, очевидно, потребует изменений некоторых эндпоинтов. активное использование приведет к отказу от использования большинства эндпоинтов.zelenin
28.07.2017 16:04я не очень вас понимаю тогда:
потому что GraphQL плохо вписывается в парадигму REST, и использование его как инструмента ведет к необходимости пересмотра архитектуры в целом.
использование GQL напрямую с апи, очевидно, потребует изменений некоторых эндпоинтов. активное использование приведет к отказу от использования большинства эндпоинтов.да, graphql — это не rest, в нем один эндпойнт, и клиенты нужно будет переписать. это не плюс и не минус. Это миграция.
Alexs177
26.07.2017 20:30+2Что мешает создать endpoint на бэкенде, который будет возращать только нужную информацию?
Film возвращать как дочерний объект с полями ID и Name например.
Посыл статьи «не смогли реализовать REST API попробуем GraphQL».
Если уж хвалить GraphQL так за какие-то реальные преимущества, а не возможность решить надуманные проблемы.
Смотрю Graphene-Django, есть интересная фича фильтровать данные по параметру например, это реально полезно и может сэкономить время и силы.
В общем как с реактом, идея хорошая, ждём пока будет достойная реализация.dema
27.07.2017 11:15А потом еще один и еще один. И закончим с 20 endpoint'ами для вытаскивания одной и той же сущности с разным набором полей.GraphQL это скорее не о фильтрации данных, а о том, чтобы одним и тем же endpoint'ом вытаскивать разные наборы полей для данного конкретного фильтрованного запроса.
r-moiseev
27.07.2017 11:16+2Не сказал бы что они надуманные. Под конкретную задачу вы можете предусмотреть специальный запрос (который кстати нарушит REST). Что будет когда клиенту понадобиться ещё один такой?
Хорошо, вы можете предусмотреть inclusion на манер JSON-API. А если понадобиться больше чем один уровень вложенности?
Все это в лучшем случае ведёт к грязному апи. В худшем к необоснованной денормализации данных и страданиям.
timon_aeg
27.07.2017 12:19Что мешает создать endpoint на бэкенде, который будет возращать только нужную информацию?
Например, тот факт, что бэкенд делает другая команда со своими планами.
franzose
27.07.2017 13:19+1Обычно действия бекендщиков и фронтендщиков согласованы, иначе зачем это всё.

vanxant
27.07.2017 17:13С этими вашими облаками у вас есть куча крутых внешних сервисов (облачная бухгалтерия, облачная CRM, облачный склад, облачное все), каждый со своим бубном, а вам надо их друг с другом интегрировать.
franzose
28.07.2017 00:41+1Не совсем понимаю, как GraphQL решит проблему интеграции со сторонними сервисами. Так или иначе мы упрёмся в то, что абстрактный сторонний сервис обрабатывает конкретные GraphQL-запросы по своей спецификации, а не всё подряд.

teux
27.07.2017 12:23+2Что мешает создать endpoint на бэкенде, который будет возращать только нужную информацию?
Типичный ответ бекенд-разработчика: «Мне что пилить новую модель под каждую потребность?» И последующие объяснения, что наследование хоть и хорошо, но поддерживать большое количество моделей труднее, или надо их хачить в каждом отдельном сервисе и т.д. и т.п.Fortop
27.07.2017 19:37+1Да, именно на бэкенде и пилить. И буде выяснится необходимость наличия каких-то фильтров — то пилить еще и их.
GraphQL же предлагает выставить все внутренности наружу.
Условно говоря — выдавать сигареты из окошка киоска намного проще и более контролируемое действие, чем открыть двери нараспашку, а потом пытаться ограничить бесконтрольный вынос всего и вся из магазина.Encarmine
28.07.2017 09:52И тем не менее формат супермаркета практически полностью вытеснил формат ларьков.
Fortop
28.07.2017 15:07Формат супермаркета это именно расширенные API с множеством endpoints (касс)
GraphQL же предлагает все вывалить на станции метро в час пик.
И не предлагает решений и спецификаций как это ограничить за разумные деньги и усилия.zelenin
28.07.2017 16:10GraphQL же предлагает все вывалить на станции метро в час пик.
И не предлагает решений и спецификаций как это ограничить за разумные деньги и усилия.GraphQL предлашает спеку, как апи сделать удобным для фронта и не описывает серверную сторону. Серверные решения — за вами
rraderio
28.07.2017 16:24Т.е. это больше нужно фронтенду, но серверных решений не предлагают?
zelenin
28.07.2017 16:29это спецификация api. api — это о взаимотношениях клиент-сервер. То есть как клиент отправит запрос, что сервер ответит. Соответственно спека не описывает на каком языке будет клиент и не описывает как сервер будет подготавливать ответ.

sentyaev
27.07.2017 04:32+4REST может быть очень гибким.
Например для ресурса persons вы спокойно можете принимать/возвращать несколько разных моделей используя Content-Type и Accept.
curl -i -X POST -H 'Content-Type: application/vnd.person-ref+json' -d '{"name": "x"}' http://rest-api.io/persons curl -i -X GET -H 'Accept: application/vnd.person-ref+json' http://rest-api.io/persons curl -i -X GET -H 'Accept: application/vnd.full-profile+json' http://rest-api.io/persons
А можете сделать несколько ресурсов.
Еще можете сделать один ресурс /magic и он будет обрабатывать все что можно, напримр все json будут содержать поле «request-type».
То же касается стратегии версионирования.
И главное, что нет плохого или хорошего REST-API, есть api который работает или не работает.
С другой стороны, для любого API приходится писать wrapper, чтобы использовать его в приложении. Соответственно все «шероховатости» (а скорее всего то, что не нравится, например мне, в этом api) я могу немного сгладить. Да и такой wrapper в любом случае писать (даже если разработчики api его делают), он может быть еще и anti-corruption layer.
Ну и последнее, что хочу добавить, даже если использовать GraphQL все равно же придется писать обработчики (handlers или services), для query/mutation. Мы же не можем просто так данные в базе поменять, обычно нужно выполнить кучу бизнес-логики.
Т.к. если все настолько просто, что можно просто гонять данные туда-сюда и бизнес логики нету, то вообще ничего писать не нужно, можно просто сгенерить такой api по базе как вариант.teux
27.07.2017 10:28Проблему перевыгрузки данных это не решает. Данные придут в соответствии с моделью, заданной на сервере. Получается, хотели узнать возраст персоны, а до кучи получили результаты анализов.
sentyaev
27.07.2017 15:16Проблему перевыгрузки данных это не решает. Данные придут в соответствии с моделью, заданной на сервере.
Я не очень понял где сдесь проблема? Вы делаете клиента, я api, мы договариваемся о протоколе между вашим приложением и api. Зачем вам что-то другое?
Получается, хотели узнать возраст персоны, а до кучи получили результаты анализов.
А действительно ли это проблема? Как просядет производительность, тогда и будем решать, а пока она не просела, что страшного то? Ну будет лишних десяток полей гоняться.teux
27.07.2017 15:32+2Десяток лишних полей — не страшно, но и не нужно. Однако я встречал API, где речь шла не о десятках полей, а десятках лишних килобайтов, причем дублирующейся информации.
Мне кажется, лучше изначально применить архитектуру, исключающую избыточность, чем каждый раз ломать голову над дизайном моделей и коллекций, потом долго оптимизировать, подхачивая модели по месту.
Не отрицаю, можно построить великолепный RESTful API, снабдить его отличным свагером. Но так получается, что есть одно слабое место – избыточная выгрузка, другое – жестко заданные модели, которые не всегда легко подстроить под меняющиеся потребности, третье – версионность. В сумме это повышает вероятность зашить в API неисправимые дефекты, которые потом станут сакральными багами. Встречали такие? Это когда благодаря багу все более-мене работает на фронте. Стоит его пофиксить, и все развалится. Не отсюда ли пословица «работает — не трогай!» :)sentyaev
27.07.2017 16:05Мне кажется я вас понял)
Вы пытаетесь решить проблему контроля. Другими словами вы сами хотите контролировать данные с которыми работаете на фронте.
А на самом деле проблема еще глубже. Каждая команда хочет быть самой главной, вот и фронт потихоньку хочет стать драйвером всей разработки.
В итоге получается, что backend это просто прокинутая наружу база данных, это порождает anemic api, это в свою очередь дает все эти проблемы описанные в статье.
Это когда благодаря багу все более-мене работает на фронте.
Я это очень просто решил для себя. У меня есть api (их несколько). Для каждого api у меня написан объект wrapper (например BasketballApi, SecutiryApi). Вся работа с api инкапсулирована в эти wrapper's. Там же делается маппинг из в то представление которое нужно фронту.
Каждый wrapper покрыт e2e тестами. Т.е. при каждом коммити в api я запускаю эти тесты, т.е. тестирую взаимодействие моих wrapper's с реальным api. Так ловится каждый breaking change.teux
27.07.2017 16:47+1фронт потихоньку хочет стать драйвером всей разработки
Вы проницательны и частично правы. Но такое стремление фронта не от желания захватить мир.
Если свести дуализм проблемы REST–GQL к одной фразе, то эта фраза будет о том, кто лучше готовит view-оринтированные данные.
Любой API – это этап на пути трансформации данных во view-оринтированный формат. Отправная точка — БД. В ней данные разбиты на информационные сущности и, что важно, нормализованы и индексированы ради оптимального расходования места и скорости доступа (если говорить про реляционную БД). Замечу, ни у кого не вызывает сомнения необходимость нормализации ради компактности.
Но такие данные вряд ли годятся для визуализации. Потому API является не просто шлюзом к данным, но как-то трансформирует их под ту или иную задачу фронта. Поскольку задач у фронта много и они возникают иногда с пугающей скоростью, беку просто не угнаться за подготовкой данных под каждую задачу.
Все приходит к тому, что бек говорит, мол мы же дали вам два массива связанных данных, соберите из них, что вам конкретно нужно. И фронт каждый раз собирает. Каким бы мудрым не был API очень редко ответ сервер не требует дополнительного процессинга на фронте.
И тут появляется GraphQL, а вместе с ним возможность декларативно объявить и получить именно те данные, которые нужны компоненту. Конечно, такая плюшка притягательна для фронта. Представляет, сколько строк кода можно сэкономить повсеместно? Причем для бека сложность поддержки GQL вряд ли больше, чем поддержки REST. Поэтому фронт, как конечный потребитель данных, хочет быть услышан
TrogWarZ
28.07.2017 01:43+1Бекенд это не только «вью-интерфейс между базой и клиентом». Ради безопасности и избежания дублирования (когда клиентов много), внутри бекенда хранится вся доменная логика, разграничение прав и т.п.
Для проектов, где достаточно crud-like логики и апи есть смысл сделать анемичным – тут GQL выигрывает во всём. Но когда у вас добавляются пользовательские настройки, десяток ролей с разными уровнями доступа, фильтры по всему подряд и какая-нибудь god-like-табличка у пользователя с хитрыми формулами расчёта и тому подобным – любой endpoint, способный возвращать что угодно клиенту становится самым узким местом как в логике, так и в производительности.
Упомянутые выше RESTful + JsonData отлично справляются с задачами «не дублировать данные» и «дать свободу клиенту выбирать какие связанные данные нужны в ответе, а какие нет», при этом не ограничивая бекенд-разработчика и позволяя ему, например, оптимизировать дорогой запрос руками.
В случае же оптимизации GQL приходится с клиентами устанавливать негласные соглашения об ограничениях запросов в духе «да, ты можешь делать так, но это будет на порядок дольше чем вот так», – что, даже в случае наличия документации, не очевидно и не поддерживаемо.
Я, как бекендер, с удовольствием перейду на GQL когда (если!) появится вменяемая реализация, позволяющая решить проблемы выше (доступ, оптимизация). Для PHP я ни одной такой пока не нашёл, например.
dema
27.07.2017 11:12Это как раз изобретение своего собственного DSL аналогичного graphql. Прямо сейчас это список полей, потом понадобятся вложенные сущности и, в итоге, родится что-то похожее.
sentyaev
27.07.2017 14:42Прямо сейчас это список полей, потом понадобятся вложенные сущности и, в итоге, родится что-то похожее.
Ключевое слово — «потом». YAGNI же!r-moiseev
27.07.2017 14:51Вы не так понимаете YAGNI. Там нигде не говорится что надо пренебрегать масштабируемостью
dema
27.07.2017 15:14Так GraphQL — это как раз для тех случаев, когда уже понадобилось. Facebook его делал для унификации своего API между web-клиентом и мобильными клиентами.
serjoga
27.07.2017 10:10Единственное почему graphQL лучше за REST — это то что Вы можете запросить совсем не связанные ресурсы одним запросом.
Например, в блог приложении Вы можете единственным запросом:
- статьи из рубрики с учетом пагинации
- топ авторов
- топ статьи
- топ комментарии
Аналогично можно сохранить сразу пачку не связанных сущностей.
В остальном все то же самое можно сделать в REST. Как правильно упоминали в комментариях, еще в 2007 Microsoft придумало стандарт oData, который решает те же проблемы. Но почему-то такого ажиотажа, как c GraphQL — не было :)
Вот интересное сравнение — https://www.progress.com/blogs/rest-api-industry-debate-odata-vs-graphql-vs-ords
franzose
27.07.2017 13:21Например, в блог приложении Вы можете единственным запросом:
Почему нельзя то же самое сделать в REST?
serjoga
27.07.2017 14:27+1В REST URL является уникальным идентификатором для ресурса. Поэтому если у Вас на GET /articles можно запросить и еще кучу всего не связанного, то это уже не REST, так как теряется смысл урлов вообще. Ведь можно просто сделать GET /api, который по GET параметрах возвращает все что угодно. И тогда Ваш REST эволюционирует в oData или GraphQL :)
sentyaev
27.07.2017 15:00+1Как всегда нужно сначала задать вопрос — а зачем нам тянуть данные одним запросом? Какую проблему мы пытаемся решить и есть ли она вообще. Производительность? Удобство разработки? Что-то еще?
Вы говорите о проблеме 1 vs N запросов, предположу, что говорите о производительности.
Тут два варианта, если действительно это проблема, можно сделать специальный ресурс-аггрегатор.
А если производительность устраивает, то в чем проблема? Сделали четыре промиса и стрельнули одним махом.serjoga
27.07.2017 15:10Производительность имеет огромное значение, если Вы пишете мобильное приложение :) Вы же не хотите чтобы Ваши пользователи говорили что оно глючное (3G, покрытие и т.д.).
Поэтому 4 промиса решают проблему объединения данных, но Вы каждый раз будете тратить время на соединение, проверку CORS, авторизацию, права доступа и что там еще есть. А так — все за один раз.
Согласен на счет ресурса агрегатора, но это в том или ином виде получится GraphQL.
Кстати, я не думаю, что GraphQL полностью вытеснит REST. GraphQL очень хорошо работает для микросервисных архитектур как API Gateway наружу. А внутри проще использовать REST или RPC.
sentyaev
27.07.2017 15:24Производительность имеет огромное значение, если Вы пишете мобильное приложение :) Вы же не хотите чтобы Ваши пользователи говорили что оно глючное (3G, покрытие и т.д.).
Так я же вам не говорю, что производительность не важна. Я же как раз ставлю вопрос является ли производительность проблемой в конкретном случае.
Возможно что лучшем решением будет сначала запросить самый минимум данных, чтобы пользователь видел сразу что ему нужно, а уж потом коментарии и все что на первый экран не влезло.
Но тут мы уже с вами уходим от обсуждения REST/GrapgQL. Т.к. производительность приложений никак с этими технологиями не связана. Это уже зависит от кривизны наших рук.


Hypuk
26.07.2017 15:54+1Для тех кто хочет изучить GraphQL есть бесплатные видео уроки — www.howtographql.com
yurec_bond
26.07.2017 16:11+3Все эти GraphQL и ODATA хороши только тогда когда репозиторий умеет загружать данные с достаточной гранулярности.
Чаще всего оказывается что запрашивать данные с такой гранулярностью не получатся и начинается подход — «Загрузим все а потом отфильтруем в памяти».
Что напрочь убивает всю задумку.
arvitaly
27.07.2017 00:32Почему не получается? Как раз наоборот, очень удобно кэшировать маленькие кусочки, а доставать только запрашиваемые поля. К тому же, есть масса вариантов маппинга, для большинства простых запросов можно 1 к 1 сделать запрос в базу (и в реляционной, и в документоориентированной, и в граммовой СУБД).
Ну, или приведите пример, в каких случаях и что конкретно не получается.

Shatun
26.07.2017 16:48+13Везде так клево описывается graphql, но только со стороны фронтэнда. А ведь в реальности это мы уносим всю сложность с фронта на бэк, где нам нужно уметь разгрбеать эти запросы как-то. И общая сложность проекта в целом растет.
Поэтому для большинства проектов я бы сказал слишком громкий заголовок у статьи
viru0
26.07.2017 17:09Вот я тоже о том же подумал. Перепарсить из этого graphql в SQL, да еще и в какой то нормальный запрос к mongo — та еще задача.
Я в случае с mongo те-же 6 запросов в итоге будут, если films и persons в разных коллекциях лежат.
teux
26.07.2017 17:24Конечно, GraphQL не панацея. Но такого подхода определенно не хватало.
Есть также взгляд, что RESTful API можно делать поверх GrpahQL API
r4nd0m
27.07.2017 12:34Можно сделать простой бэкэнд прокси, который будет прослойкой между фронтэндом и mongodb. И слать через него абсолютно любые запросы (поддерживаемые mongodb), с любыми условиями и любыми возвращаемыми полями, вплоть до javascript-кода, исполняемого базой. С этой точки зрения GraphQL не только не панацея, а вообще ненужный костыль.
inf0man
26.07.2017 19:07+6Более того, почему-то GraphQL всегда рассматривается в контексте маппинга на sql-запросы. А если какая-то часть данных лежит в sql, какая-то — в другом хранилище, а остальная — в третьем. В этом случае сложность бэкенда перекроет все плюсы.
Вот реально, GraphQL продвигают фронтендеры, потому что упрощается их работа.teux
26.07.2017 19:27-5В этом случае сложность бэкенда перекроет все плюсы
Какую дополнительную сложность приносит GraphQL в подобной ситуации?
Мне кажется, не сильно усложняет, может и не усложняет вовсе. Но я не бекендер, мне не видно
Со стороны фронта, кончено, упрощение встретят «на ура». Но причина не в лени.
Какой проект не возьми, везде свои решения для запроса данных, кеширования, асинхронных уведомлений от сервера. Каждый раз думаешь, когда мы слезем с велосипеда в этой части?
И тягу к идеальному нельзя задвинуть. Оптимизация запросов на клиенте, отсутствие избыточного пейлоада, повышение отзывчивости – это хорошо, это правильно.
И к слову, чтобы все это применить на клиенте, тоже надо руки приложить. Особенно такой фреймворк,
как Relay Modern. По меньшей мере придется как следует разобраться с вебпаком, чтобы применить правильный лоадер для graphql-схемы, поставить плагин в бабель, изучить React, понять что есть HOC. Не скажу, что GraphQL это прямо подарок лентяю.sentyaev
27.07.2017 04:36Каждый раз думаешь, когда мы слезем с велосипеда в этой части?
Я хочу открыть вам секрет: никогда. /сарказм

AikoKirino
26.07.2017 17:13+3В очередной раз прочитав статью о хваленом GraphQL задаюсь вопросами:
Какие проблемы оно решает?
Чем лучше старого-доброго RPC?
Почему его сравнивают с REST?
powerman
27.07.2017 00:07+3Я тоже задаюсь этими вопросами. Пока что, исключительно для себя, ответы такие:
Какие проблемы оно решает?
Мы не знаем, какие данные и в каком виде нам потребуются на клиенте завтра, но мы хотим получать их максимально просто, быстро и эффективно — т.е. одним запросом и без "лишних" полей в ответе. Примерно так, как бэкенд может получать данные через SQL. При этом мы не хотим открывать клиенту полный доступ к базе (это небезопасно), и хотим избежать необходимости вносить изменения на бэкенде под каждый новый тип запросов, который понадобился клиенту (это ограничивает свободу творчества на клиенте и скорость его разработки).
Чем лучше старого-доброго RPC?
Формально это и есть один такой универсальный вызов RPC "считать/записать (почти) любые данные". Но по сути это лучше старого-доброго RPC тем, что это один вызов, который достаточно реализовать один раз, и нет необходимости добавлять новые вызовы на бэкенде под каждый новый тип запросов клиента.
Почему его сравнивают с REST?
Потому что в REST нет возможности "считать/записать (почти) любые данные" одним запросом, и REST клиенты страдают, реализуя этот функционал вручную, через кучку отдельных запросов. <sarcasm>Так что GraphQL "это как REST, только лучше".</sarcasm> На самом деле, конечно, ничего общего между REST и GraphQL нет.
Резюмируя всё это, моё личное мнение: корректно и полноценно реализовать GraphQL на сервере — крайне сложно. И я сейчас не про парсер GraphQL, который уже реализован в куче библиотек, а про бизнес-логику функций, которые получают/изменяют конкретные поля данных. В GraphQL слишком много от прямого доступа к данным, что сильно усложняет корректную реализацию бизнес-логики того, какие поля в каких ситуациях кому можно читать/писать. Так что требования к сложности, гибкости и разнообразию клиентских запросов должны быть поистине гигантскими (примерно масштабов фейсбука), чтобы вся эта сложность реализации GraphQL на бэкенде стала оправданной.
P.S. Думаю, в будущем мы увидим очень много примеров дыр нового типа GraphQL-injection, когда через специальным образом сформированные GraphQL-запросы можно будет считывать и изменять данные, к которым доступа у этого юзера быть вообще не должно.
http2
26.07.2017 17:16-9Что за хайп вокруг GraphQL?
REST — это не
GET — /people/{id}
:)
GraphQL — сам подмножество REST.
Безграмотность.

Alex_ME
26.07.2017 17:35Не совсем понимаю, какое правильно применения у этой технологии. Сам с REST API полноценно не работал (не создавал), и могу ошибаться по поводу того, как должно быть правильно и канонично.
Как я понимаю, чаще всего в реальном приложении, api представляет сложнее, чем простой CRUD, требующей выполнения какой-то логики на бэкенде для обработки запросов к endpoint'ам.
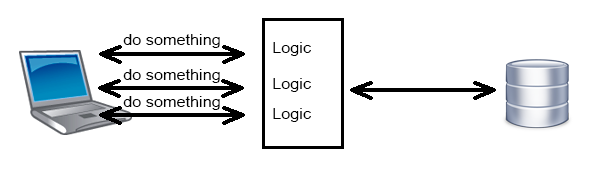
GraphQL выглядит как Data Access Level и неплохо ложиться на SQL и всякие ORM поверх него. Но где в таком случае сама логика? "Позади" GraphQL, т.е. GraphQL обращается не к данным из хранилища, а к бизнес логике?
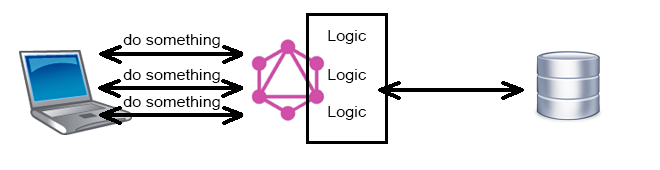
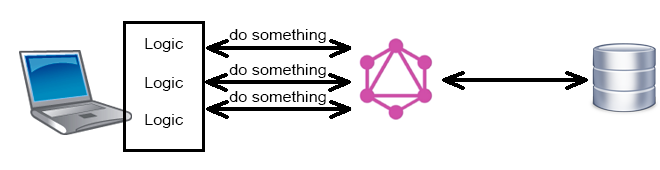
Но в таком случае скорее всего невозможна та гибкость, о которой пишут, ведь априори логика реализует какой-то ограниченный функционал.
Или может быть сейчас вообще всю логику переносят на клиент, оставляя на бэкенде лишь CRUD доступ к данным и авторизацию+аутентификацию?
teux
26.07.2017 18:03Как я понимаю (сам только начал изучать), логика запроса данных – в функциях-резолверах. Они связаны с полями и являются частью схемы GraphQL. Прочая бизнес-логика – в event-driven келбеках.
Например, на graph.cool для этих целей предлагается использовать функции. Они позволяют сделать что-то на разных этапах обработки запроса. На скриншоте показан выбор этапа при создании функции.

Сами функции могут хоститься на облачных сервисах типа AWS Lambda.
Если пишете свой GraphQL бекенд, то используете какую-то библиотеку. Она, наверняка, будет предлагать аналогичный механизм келбеков.DrFdooch
26.07.2017 18:25+1Ого. Но строить целую архитектуру проекта основываясь на языке запросов мне кажется неэффективным. Бизнес-логика и CUD пускай лучше остаются вне скоупа задач, решаемых с помощью GraphQL.
zelenin
26.07.2017 19:04не целую архитектуру, а взаимодействие с фронтэндом.
если предположить, что ваше приложение построено на некоем сервисном слое, то graphql — это то, что до сервисного слоя, и то, что после. Бизнес логика остается с вами.DrFdooch
26.07.2017 19:22и то, что после
Я правильно понял, вы предлагаете GQL использовать для доступа к сырым данным (это обычно БД)?
Но главное — это то, что GQL крут именно возможностью гибко запрашивать информацию целыми графами. Изменять состояние этими же целыми графами — очень нетривиальная задача, и я бы не рисковал реализовывать (или использовать реализованную в числе первых… ну миллиона) настолько сложную систему.
GQL — для чтения, REST/RPC/чтотоеще — для записи.zelenin
26.07.2017 19:48+1да, перечитал свой коммент и понял что неправильно сформулировал. Читать так:
если предположить, что ваше приложение построено на некоем сервисном слое, то graphql — это то, что до сервисного слоя во время реквеста, и то, что после во время респонса. Бизнес логика остается с вами.
request -> graphql -> сервисный слой -> бизнес-логика -> сервисный слой -> graphql -> response
DrFdooch
26.07.2017 19:58в моей практике большая часть БЛ приходится на флоу записи, а не чтения. соответственно, главный мой вопрос (к teux, в основном): вы предполагаете использовать GQL для записи?
zelenin
26.07.2017 20:04вы навреное не понимаете как graphql работает. graphql ничего сам не записывает и ничего не читает. он принимает запрос, валидирует его, роутит в определенный ресолвер, где вы чем хотите тем и обработаете. И после обработки выплюнет результат.
Обработка (чтение или запись) всегда остается на вашей совести.
teux
26.07.2017 20:47Вынужден слегка поправить ваш вопрос. С моей стороны нет каких-либо предложений, но GQL, как известно, используется для записи.
Мне кажется, вы видите проблему в том, что запись не может быть столь же произвольно безграничной, как получение данных. Блокировки–транзакции–индексирование на уровне БД ограничивают попытки менять данные произвольным образом. Все ради поддержания целостности и доступности данных.
Но GQL не дает абсолютной свободы ни в запросах, ни в мутации. Это только кажется, что любой путь в графе доступен. Представление данных в виде графа позволяет делать крутые оптимизации на фронте. Но на беке, чтобы путь в графе был доступен, он должен быть разрешен схемой.
Некоторые сервисы, например graph.cool, имеют два варианта API — упрощенный и полнофункциональный. В упрощенном API для всех типов данных неявно создаются разрешения на доступ к их полям, а если какое-то поле связано с другим типом, то и к узлам этого типа. В полном API ситуация строже — нужно самостоятельно определить разрешенные для чтения пути.
С мутациями все еще строже. Нет никакой произвольности. В схеме должны определять доступные мутации. Каждая мутация – это функция, которая может проверить входные данные и сделать нужные запросы к БД. Клиенту доступна та или иная мутация, он может вызывать ее с разными параметрами, но он не может через GQL менять любые данные в графе, как заблагорассудится.
PS. На мое знание GQL пока нельзя полагаться – только недавно стал изучать GQL и больше со стороны фронта.

QuickJoey
26.07.2017 18:25Есть такая штука , которая делает очень удобным вызов функций (любых, выборка, или изменение данных) из GraphQL. Если предположить, что вся бизнес-логика построена на функциях и триггерах Postgres, получается законченное решение.
p. s. Я не веб-программист, если порю чушь, извините.

hVostt
26.07.2017 19:17+5ИМХО, чтобы GraphQL взлетел, надо написать очень много мощных tool для бекенда, которые будут обеспечивать то, что называется «говорить на нескольких языках».
Представьте себе, что сегодня изобрели язык SQL, но ещё нет ни одной СУБД, которая с ним работает. Какой смысл в SQL тогда? Никакого. Что с этим языком можно делать обычному программисту? Ничего.
Собственно, пока не будет развитой системы библиотек, поддерживающих GraphQL нативно, чтобы действительно можно было заниматься решением непосредственных задач, а не тратить всё время на то, чтобы это хоть как-то шевелилось, во имя далёкого светлого будущего, использование GQL остаётся больше академической задачей, чем практической.
madkite
26.07.2017 19:36Та вроде бы уже хватает библиотек, хотя всё же заметен перекос в сторону ноды.
hVostt
26.07.2017 19:47+2На сколько я вижу, эти библиотеки пока что, грубо говоря, из области «парсинг SQL» :)
Могу ошибаться, но профита для себя (и для нашей компании) пока не вижу.
Но интерес присутствует, наблюдаю уже давно.zelenin
26.07.2017 19:59На сколько я вижу, эти библиотеки пока что, грубо говоря, из области «парсинг SQL»
поясните фразу.
GraphQL никак не относится с sql, и все что там парсится — это json-оподобный язык запросов фронта.hVostt
26.07.2017 20:07+2Я и не говорил, что относится. Просто привёл пример, представим, что сегодня изобрели SQL, но ещё ни одна СУБД не поддерживает SQL. Какой от него прок? Даже если сам по себе как язык SQL замечательный. Но потом вы говорите, вон же библиотеки есть. Я говорю, вижу, уровень этих библиотек «парсинг SQL» в контексте приведённого мною примера.
Если я захочу использовать GQL, то у меня 80% времени (если не все 100) уйдёт тупо на обеспечение его поддержки, собственными костылями и подпорками в виде тех библиотек.
Возьмём для сравнения OData. Я, как программист на .NET, имея под рукой любую СУБД, сложную и развитую схему данных, Entity Framework, подключаю OData и получаю полностью работоспособного сервера, который может обрабатывать OData-запросы с клиентов, отдавать мета-данные и схему, делать фильтрацию по любым полям, сортировку, агрегацию, запрашивать за один round-trip целые графы данных и это будет транслироваться в очень эффективные SQL.
GQL на сегодняшний день может похвастаться только идеей. Но не реализацией. И пока вчистую проигрывает той же OData по всем фронтам. Это не значит, что его время не наступит. Но чтобы его двигать, надо получать пользу прямо сейчас, а не когда мы перепишем весь свой код под GQL, навтыкаем костылей и заставим шевелиться, то тогда может быть, должно быть, всё вообще станет радужно и прекрасно.
RomanPokrovskij
27.07.2017 10:04Хочу спросить и уточнить, что такое «имея EntityFramework… подключаю OData»? Создаете сервис унаследованный от EntityFrameworkDataService? Его нет в EF Core.
vorona_net
29.07.2017 11:32Позволяет выставлять наружу контекст, работает с Ef Core OdataToEntity
RomanPokrovskij
31.07.2017 21:18Cпасибо. Это круто, многих звездочек в ГитХабе достойно.
А можете в readme.md показать все с обвязкой в Startup.сs (Microsoft.AspNetCore), т.е. как вы переправляете запросы типа http://MyService/OData/Orders?$select=Name на ваш обработчик-parser? Чтобы понять время жизни объектов.vorona_net
31.07.2017 22:50В readme написано
Example Asp.Net Core OData service in \sln\OdataToEntityCore.Asp.sln, client Microsoft.OData.Client in \sln\OdataToEntity.AspClient.sln
Startup
madkite
27.07.2017 13:14Не стоит так категорично за все библиотеки говорить. Relay — довольно продвинутый фреймворк, а не только парсинг синтаксиса GraphQL. Ну а .NET — да… там исторически сложилось, что всё очень консервативно (enterprise как-никак), всё новомодное в нормальной имплементации появляется почти самым последним и часто только с пинка Microsoft.

jreznot
26.07.2017 21:34В платформе, которую мы разрабатываем, есть похожий механизм с названием Views. Для запросов можно указать дерево требуемых полей и связей (а точнее имя одного из представлений, зарегистрированных на сервере). Front-end разработчики довольны и могут вытаскивать из REST-API данные с нужной детализацией.
Пример в доке: https://doc.cuba-platform.com/manual-6.5/rest_api_v2_ex_get_entities_list.html
Так что совсем не обязательно внедрять GraphQL, можно использовать существующие языки, дополнительно лишь описывая требования к глубине детализации.

DarkOrion
27.07.2017 10:23-1А когда я был маленьким было принято бить по рукам за прямые *QL запросы с клиента на сервер :) Инъекции, вот это всё.
Оказывается надо было просто заменить S на Graph.
Чем это вообще лучше простого SQL с экранированием?
teux
27.07.2017 12:40+3Почему GQL встречает такое сопротивление? Объяснение приходит, когда смотришь на зависимость членов команды друг от друга.
Фронтендер зависит от бекендера, чего не скажешь об обратном. По этой причине фронтендер так или иначе вникает в проблемы бека, но не всегда бывает наоборот.
Если бекендер вложил массу времени и сил в изучение архитектурных подходов REST, а затем свел руки вместе, поднял над собой и сказал: «Я в домике», – то фронтендеру остается с грустным видом удалиться, волоча на шнурке какой-нибудь GraphQL.
Но если смотреть на сервис как на конечный продукт и понимать проблемы фронтенда (к слову, современный фронтенд вряд ли уступает по сложности бекенду), то GraphQL будет выглядеть незаменимым инструментом для решения многих проблем:
1. Уменьшение количества запросов и пейлоада, о чем говорилось в статье.
2. Обновление состояния приложения на сообщениях от сервера на основе subscriptions.
3. Оптимальное кеширование. Оба популярных клиентских фреймворка – Relay и Apoll реализуют его из коробки.
4. Проблема начального этапа разработки, когда отсутствие эндпоинтов вынуждает мокать данные, писать обертки в коде. Вместо этого фронтенд может воспользоваться BaaS-сервисами типа graph.cool и scaphold для быстрого и бесплатного прототипирования, а когда будет готов свой бекенд, – просто поменять адрес сервера.
5. Декларативность кода. Лично у меня давно возникает диссонанс от необходимости писать модуль fetch с retry, создавать словари для разных ресурсов и HTTP-методов. По сравнению с подходом того же Redux, это кажется громоздким, бессмысленным, ибо повторяется из проекта в проект, не соответствующем времени.
GraphQL не только язык. Как бывает с удачными подходами — они вдохновляют на создание целой экосистемы инструментов, решающих основную и сопутствующие проблемы. Такими инструментами являются упомянутые клиентские фреймворки Relay и Apollo. Да, их применение требует изменить многое на бекенде, и тут могут быть сложности.
Но сложность связана с новизной, с необходимостью бекен-разработчика изучать новые подходы, когда он столько сил потратил на изучение старых. Это понятно и оправдано. Но в конечном счете, общее дело делаем. И вы правда считаете REST вершиной эволюции? Уверены, что через 10 лет кто-то будет вспоминать про REST? Как бы не оказаться в хвосте очередиr4nd0m
27.07.2017 15:34+3Почему GQL встречает такое сопротивление?
Потому что приходит кто-то и говорит: «Вы используете REST? А я вам вот GraphQL принёс! Вы с ним сможете делать такие же проекты, как с REST, только без REST. Теперь ваш REST мертвый. Давайте переучивайтесь поскорей.»
И дело даже не в банальной вежливости (я, например, больше 10 лет использую технологию, которая «мертва» уже 20 лет, и каждый раз когда мне об этом напоминают, я только улыбаюсь). Дело в том, что вы не Гугл и не Facebook, где внедрение такой технологии сэкономит терабайты трафика. И то, что вам кажется сопротивлением — всего лишь трезвый взгляд на новую вещь.teux
27.07.2017 15:45-1Это и прекрасно! Считаю, никакая новая технология не должна пойти в массы, не пройдя сопротивление легасевых (читай, традиционных) технологий. Естественный отбор. И любая легасевая технология живет, пока есть хоть один ее адепт.
Но и сводить достоинства GQL к экономии трафика не совсем верно. У него гораздо больше плюсов. Да, их получаю в основном фронтенд-разработчики. При правильной организации, плюсы получит сервис в целом (надеюсь). Непосредственно со стороны бекенд-разработчика, возможно, плюсов не так много.
S_A
27.07.2017 12:41Я вот до этой статьи думал, что GraphQL такая крутая штука вообще… что действительно убьет REST API всякие.
А по факту я вовсю давно пользуюсь loopback (на node.js), который все может (определять поля в ответе, вкладывать связанные сущности, генерировать модели по json'у, выдавать результаты реактивно по подпискам и кучу всего разного), причем имеет коннекторы ко всем распространенным базам, и их в проекте может быть сколько задашь.
И еще из коробки: ставить хуки на запросы, управлять доступом, смотреть апи через эксплорер, имеет SDK для Android, iOS и angular…
Подожду loopback на GraphQL, пожалуй.zelenin
27.07.2017 14:15суть не в том, что кто-то чего-то умеет — почитайте комменты, так или иначе многие решали у себя в проектах проблемы, решаемый grapqhl.
суть в том, что теперь не надо самому придумывать велосипед разной степени качества и готовности — написана отличная спецификация и куча реализаций на разных языках.S_A
27.07.2017 15:37Насколько я в данный момент понял, аналогов loopback с graphql пока нет (или хотя бы как ParseServer). И пока не будет, в продакшн с graphql я пока не полезу — за свой счет праздники серверного программирования некогда устраивать. В комменте об этом как раз суть.
zelenin
27.07.2017 15:45я не работал с loopback. Выделите несколько ключевых особенностей, чтобы понять зачем вообще аналог нужен с graphql.
Graphql уже есть, и есть реализации на многих языках как серверной части, так и клиентской.S_A
28.07.2017 03:26В начальном комменте я уже описал в принципе, но кратко если, loopback — это сервер API, который генерируется по JSON-описанию моделей и имеет возможность подключать самые разные источники данных (и автоматически эти данные мигрировать) — базы (postgres, mysql, mongodb, и другие, коннекторов много). То есть создаешь модели данных, связи между ними, а тебе loopback выдает сервер API на node.js (с полным набором crud для каждой сущности + запросы со связанными). Причем не просто REST API, а с поддержкой фильтров полей, элементов, вложения подчиненных…
К нему легко подцепляются EventSource и socket.io.
Есть кстати у loopback даже discover — построение моделей по уже существующей базе. То есть взял базу, и через 20 минут у тебя к ней REST API (с пользователями и настройками ролей/доступов).
С другой стороны есть вообще замечательный parse-serer, который из коробки дает интерфейс создания произвольных моделей, тоже может уведомлять с сервера (у него есть т.н. LiveQuery), одно но — он работает только с MongoDB.
Я ничего против graphql не имею, просто не знаю, есть ли готовые универсальные решения по типу описанных с ним, или нет. И пока думаю что нет. Знаю что meteor вроде собирался поддерживать graphql, но на метеоре я считаю имеет смысл делать только проекты с небольшим числом пользователей (до 1000 скажем).
S_A
28.07.2017 03:31Хотя я что-то натупил… ой натупил. Зашел в npm, нашел кучку пакетов, которые подключают graphql к loopback (с волшебным словом apollo). В следующем проекте поверчу какой-нибудь.
rraderio
27.07.2017 15:09Зависимость клиента от сервера.… 2) не привязывает клиента к конкретному серверу.
М, это как? Я смогу отпрвить тот-же запрос к Github например?zelenin
27.07.2017 15:51имеется в виду, что для каждого конкрентого случая вам надо писать более высокоуровневый клиент апи на основе низкоуровневых, т.к. реализация rest не специфицирована.
Для GraphQL же есть готовые клиенты — relay или apollo — которым нужно скормить схему и поехали.
rraderio
27.07.2017 15:27-1в одно случае вам понадобится 2 поля
в другом три поля
в итоге не закешировать ничего. или же придется хранить по 100500 разных копий одинаковых данных — тем самым ваша якобы оптимизация сводится на нет.
а когда запрос на 1 набор данных — можно закешировать.zelenin
27.07.2017 15:57+1два поля и три поля — это поля одного набора данных, который и нужно кэшировать.
rraderio
27.07.2017 15:37+1Если GraphQL API не публичный и предназначен для внутренних клиентов (мобильных или веб), можно использовать списки доступа и предварительно одобренные запросы. Клиенты требуют сервер выполнить такие запросы, указывая вместо запроса его идентификатор. Кажется, Facebook применяет такой подход.
Зачем тут GraphQL?
предварительно одобренные запросы
Так это и есть RPC
Если вы делаете публичный API может и есть смысл, если же API предназначен для внутренних клиентов RPC самое оно.
sentyaev
27.07.2017 16:14-2У REST есть одна киллер фича. Он работает нативно. Не нужны библиотеки, фреймворки.
Просто отправил HTTP запрос на сервер, получил в ответ, например, json и все.
json тоже нативно в js работает.
Т.е. получаем:
1. На фронте и так все работает.
2. На сервере написать handler это тривиальнейшая задача.
А GraphQL… неужели люди пытаются с помощью технологии решить проблему коммуникации между фронт и бэк командами?zelenin
27.07.2017 17:12+1Просто отправил HTTP запрос на сервер, получил в ответ, например, json и все.
json тоже нативно в js работает.graphql тоже так работает.

x07
27.07.2017 19:55-1А что мешает создать конкретный метод person, дать ему параметр query и перечислить все что нужно там? Вы говорит что по старому доброму ресту грузятся лишние данные, а по новому grafql типа нет? В Реале Тоже самое, если не больше.
zelenin
27.07.2017 20:09+1А что мешает создать конкретный метод person, дать ему параметр query и перечислить все что нужно там?
вот так graphql и поступил
Вы говорит что по старому доброму ресту грузятся лишние данные, а по новому grafql типа нет? В Реале Тоже самое, если не больше.
не будьте голословными, опровергая.
rraderio
28.07.2017 10:38Чем GraphQL лучше чем частичный ответ?
Частичный ответ позволяет разработчикам запросить только ту информацию, которая им нужна. Например, запросы к некоторым API могут вернуть кучу лишней информации, которая почти не используется: всякие таймстампы, метаданные и т.д. Чтобы не запрашивать лишнюю информацию, в Google придумали частичный ответ.
Linkedin /people: (id, first-name, last-name, industry)
Facebook /joe.smith/friends?fields=id,name,picture
Google ?fields=title, media:group(media:thumbnail)zelenin
28.07.2017 14:15Чтобы не запрашивать лишнюю информацию, в Google придумали частичный ответ.
вы комменты почитывайте. Про частичный ответ здесь кто только не упомянул. Все его юзают.
rraderio
01.08.2017 13:15+1Чем GraphQL лучше SQL?
franzose
01.08.2017 15:00Это совершенно никак не связанные вещи.

Amareis
01.08.2017 15:16Тут вы неправы. Оба два — это языки запросов, что следует прямо из их названия, при этом GraphQL ещё и транслируется в SQL по достаточно очевидному алгоритму.
Я бы сказал что GraphQL это просто синтаксический сахар над SQL. Не писать лишний раз несколько ключевых слов вроде SELECT, FROM и WHERE… Да и всё, пожалуй. Ну, хотя, ещё структуру ответа он сам подгоняет к JSON требуемой формы.franzose
01.08.2017 15:31То, что GraphQL это язык запросов, не говорит о том, что он напрямую связан с SQL-запросами и базами данных. Откуда данные возвращаются, уже другой вопрос.
Amareis
01.08.2017 16:33Ну да, никто и не говорит что он напрямую со SQL работает. Там может быть и монга отвечать, суть не меняется.
Только вот и SQL и GraphQL всё равно — языки запросов. И они очень даже взаимозаменяемы.
{ person(personID: 4) { name, birthYear, homeworld { name }, filmConnection { films { title } } } }
Вот такой вот запрос на GraphQL мог бы быть заменён на вот такой в SQL:
SELECT p.name, p.birthYear, h.name, array_agg(SELECT f.title FROM p LEFT JOIN persons_films AS pf ON p.id=pf.person_id LEFT JOIN films AS f ON pf.film_id = f.id) FROM persons AS p, planets AS h WHERE p.id = 4 AND h.id = p.homeworld_id
Ну, условно, потому что SQL я не пользовался очень давно. Тут можно отметить что GraphQL запрос куда более прост для составления (никаких больше явно прописываемых джойнов!), но при этом менее гибок (хотя это скорее потому что в сравнении со SQL что угодно покажется дубовым).
И, вообще-то, SQL тоже не налагает никаких ограничений на то, откуда именно берутся данные — он лишь говорит какие именно данные ему нужны, точно так же как и GraphQL. И это крайне логично, ведь, повторюсь, оба они есть лишь языки запросов — то есть, способ запросить данные у провайдера, не завязываясь на том, как именно они у него хранятся. Так что SQL запрос тоже не обязан совершаться как выборка данных из БД.
franzose
02.08.2017 09:45Так что SQL запрос тоже не обязан совершаться как выборка данных из БД.
FROM persons AS p, planets AS h
А как быть с этим?
Amareis
02.08.2017 11:31-1А что с этим? Это всего лишь названия коллекций, которые присутствуют и в GraphQL запросе. Я даже немного перепишу запрос для наглядности:
SELECT p.name, p.birthYear, (SELECT h.name FROM planets AS h WHERE h.id = p.homeworld_id), array_agg(SELECT f.title FROM p LEFT JOIN persons_films AS pf ON p.id=pf.person_id LEFT JOIN films AS f ON pf.film_id = f.id) FROM persons AS p WHERE p.id = 4
Всё что делает GraphQL — это несколько упрощает написание запроса, беря на себя менеджмент отношений one2many и many2many, хотя при этом быстродействие значимо не повышается (сами посмотрите список возможных проблем, там в том числе указана и DoS атака с запросом множественно вложенных сущностей). Ну и лексика у него более компактна, что конечно достаточно большой плюс с одной стороны… А с другой — ну вот сколько таких запросов может быть в типичной приложухе? Десятки? Несерьёзно, GraphQL слой можно настраивать куда дольше чем времени будет потеряно на десятке-другом SELECT, FROM, WHERE и JOIN. Но при этом если кто-нибудь увидит что из приложения я отсылаю на сервер SQL запросы, со мной потом за руку здороваться перестанут, а скорее даже к дому с факелами, смолой и перьями придут. А GraphQL запросы — это ничего, это нормально, стильно, модно и молодежно :)
franzose
02.08.2017 13:39-2Смотря на сравнение выше SQL и GraphQL лично я вижу, что SQL не инкапсулирует логику выборок, тогда как за запросом GraphQL могут быть какие угодно джойны, присоединения таблиц и т.д.
rraderio
01.08.2017 15:22Оба QL.
franzose
01.08.2017 15:32То, что это языки запросов не означает, что они связаны напрямую. GraphQL-запрос может совершаться не только как выборка данных из БД. Теоретически — откуда угодно.
Shatun
01.08.2017 17:39теоретически и sqlем данные могут доставаться откуда угодно, точно так же можно с фронта на бэк посылать sql-запросы, а GraphQL прицепить реализовать на уровне бд.
franzose
02.08.2017 09:43SQL всё-таки это не DSL, он заточен под базы данных. А GraphQL — это как доктриновский DQL, только для фронтенда.
rraderio
02.08.2017 09:28Если GraphQL API не публичный и предназначен для внутренних клиентов (мобильных или веб), можно использовать списки доступа и предварительно одобренные запросы. Клиенты требуют сервер выполнить такие запросы, указывая вместо запроса его идентификатор. Кажется, Facebook применяет такой подход.
Где можно об это почитать?
rraderio
02.08.2017 12:50К версионированию GraphQL относится интересно. От версионирования можно полностью отказаться. По сути, можно добавлять поля, не удаляя существующие, ведь данные представляют собой граф, и можно как угодно наращивать на нем узлы. Поэтому можно оставить пути для старых API и ввести новые, не помечая их номерами версий. Просто API подрос.
Ок, но мы ведь будем и удалять поля? Как клиенты об этом узнают?
Amareis
Вот только вчера потыкал палочкой гитхабовский GraphQL, остался доволен, особенно explorer порадовал.
Вообще, с подобными технологиями скоро уже действительно будет всё выглядеть так, что изменение одного поля в БД точечно изменяет строчку в компоненте на экране тысяч пользователей по всему миру (ну и в обратную сторону, конечно). Разработчику останется только писать словарики, прокидывающие названия полей)
avdept
Такое и сейчас везде где программист не настолько ленив что бы поднять вебсокеты для реалтайма и уведомлять клиентов об изменении.
marshinov
Но таких систем все-же очень мало. В основном это чаты.