

Существует много технологий, которые позволяют сохранить важную информацию в случае выхода носителей из строя, а также ускорить доступ к важным данным. Но наше гиперконвергентное хранилище Virtuozzo Storage по ряду параметров опережает программно-определяемые решения с открытым исходным кодом, а также готовые системы SAN или NAS. И сегодня мы говорим об архитектуре системы и ее преимуществах.
Для начала стоит сказать о том, что же такое Virtuozzo Storage (в среде разработчиков — VZ Storage). Решение представляет собой распределенное хранилище, использующее ту же самую инфраструктуру, на которой работают ваши виртуальные машины и контейнеры (так называемую, гиперконвергентную инфраструктуру — hyper-converged). Изначально продукт развивался вместе с виртуализацией Virtuozzo. Однако, если вам не нужна полноценная система виртуализации, теперь проект доступен и в виде отдельного распределенного хранилища, которое может работать с любыми клиентами.
Если говорить в общем, то VZ Storage использует диски в тех же самых серверах, которые обслуживают систему виртуализации. Таким образом, у вас пропадает необходимость закупать отдельное оборудование, например, дорогостоящий контроллер SAN/NAS, чтобы создать сетевую среду хранения. Одна из отличительных особенностей VZ Storage заключается в выборе способа хранения данных (схему избыточности) для разных категорий данных. Временные логи, например, можно вообще не резервировать, а для важных данных предусмотрены различные технологии защиты – репликация (полное дублирование) или самовосстанавливающиеся коды (Erasure Coding).
Железо
Так как VZ Storage является гиперконвергентной системой хранения, она может быть развернута с использованием любых серверов стандартной архитектуры x86. Впрочем, чтобы работа системы была эффективной, в каждом сервере должно быть установлено как минимум три жестких диска не менее 100 Гб емкостью каждый, двухъядерный процессор (одно ядро отдаем хранилищу), и 2Гб оперативной памяти. В более мощных конфигурациях мы рекомендуем ставить одно процессорное ядро и 4ГБ памяти на каждые 8 жестких дисков. То есть, используя на узле, например, 15 дисков для создания хранилища, для поддержки работы кластера хранения вам потребуется всего 2 ядра и 8ГБ RAM.
Поскольку мы говорим о распределенном хранилище, серверы должны быть объединены в сеть. Теоретически можно использовать ту же самую сеть передачи данных, на которой работает кластер виртуализации, но намного эффективнее иметь второй сетевой адаптер с пропускной способностью не менее 1Гб/c, ведь скорость чтения и записи данных будет напрямую зависеть от характеристик сети. Кроме этого отдельная сеть будет полезна и с точки зрения безопасности.
Архитектура
Распределенная архитектура VZ Storage подразумевает, что мы устанавливаем разные компоненты системы на физические или виртуальные серверы: панель управления с графическим интерфейсом, сервер хранения данных (Chunk Server – CS), сервер метаданных (MetaData Server – MDS), монтирование хранилища для чтения/записи данных (Client). Один узел может запускать несколько компонент в любом сочетании. То есть, один сервер, например, может одновременно хранить и данные, и метаданные, и запускать виртуальные машины, и предоставлять панель управления кластером.

Все данные в кластере разбиваются на блоки фиксированного размера («chunks» — чанки). Для каждого «чанка» создается несколько реплик (его копий), причем размещаются они на различных машинах (чтобы обеспечить отказоустойчивость в случае выхода из строя целой машины). При установке кластера вы задаете параметр нормального и минимального количества реплик. Если какая-то машина выходит из строя или перестает работать диск, силами кластера все утраченные реплики будут воспроизведены на оставшихся – вплоть до параметра нормального количества (обычно 3). В это время система по-прежнему позволяет писать и часть данных без задержек. Но, если же из-за сбоя количество копий упало ниже минимального значения (обычно 2), то есть произошел одновременных отказ двух компонент, кластер позволяет только читать данные, а для записи клиентам придётся подождать пока не будет восстановлено хотя бы минимальное количество копий. Система восстанавливает такие чанки, с которыми идёт работа, с наивысшим приоритетом.
Количество CS и MDS на каждом сервере определяется количеством физических дисков. VZ Storage привязывает один компонент к одному накопителю, создавая тем самым четкое разделение ресурсов и реплик между разным физическим оборудованием.
В чем плюсы?
Мы немного познакомились со структурой и требованиями VZ Storage, и теперь возникает вопрос, зачем все это нужно? Какие плюсы дает система? Самое главное преимущество VZ Storage – это надежность. Используя то же самое оборудование (возможно, добавив в него сетевые контроллеры и диски), вы получаете высокоэффективную легко-масштабируемую систему с отлаженным механизмом работы с данными, метаданными. VZ Storage позволяет обеспечить постоянное и надежное хранение данных, включая диски ВМ и данные контейнерных приложений для Docker, Kubernetes или Rancher.
Второй плюс – это низкая стоимость владения (TCO). Кроме того, что для работы решения не нужно приобретать отдельное дорогостоящее «железо» и вы можете выбирать опции резервирования для различных данных, в VZ Storage имеется возможность использования erasure coding (кодов избыточности, таких как Reed-Solomon). Это позволяет снизить требования к общей емкости, сохраняя возможность восстановления данных в случае сбоя. Метод подходит для хранения больших объемов данных, когда высочайшая скорость доступа – это далеко не самое главное.
Какие именно плюсы дает erasure coding (EC)? Erasure codding позволяет значительно сократить расход использования дискового пространства. Достигается это счёт специальной обработки данных.
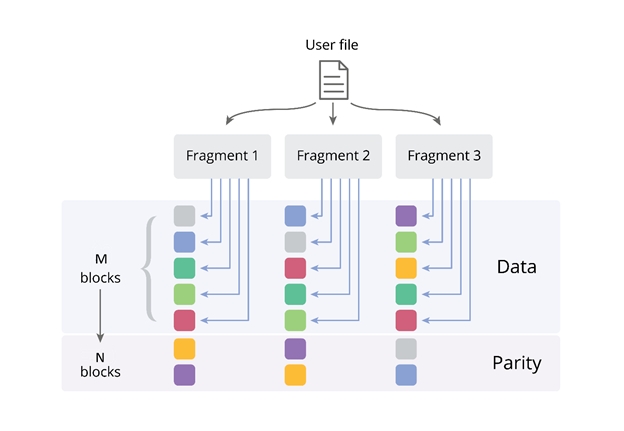
При формуле избыточности M+N[/X], EC позволяет использовать намного меньше дискового пространства. Если M – это количество блоков данных, N – количество блоков специальных контрольных сумм («Parity»), а X – параметр допустимости записи (он характеризуется тем, сколько узлов системы хранения могут быть недоступны, когда клиент по-прежнему может записывать данные в свои файлы). Чтобы система работала, минимальное количество узлов в VZ Storage должно составлять 5 (в этом случае M=3,N=2, или “3+2”). На картинке изображен пример, где M=5, N=2 или “5+2”.
На примере инсталляции системы с конфигурацией 5 + 2 и включенным EC, мы можем гарантировать дополнительную нагрузку на емкость лишь в 40%, создавая только 2Гб резервных данных на каждые 5Гб данных приложений).
В этом случае для защищенного хранения 100 Тб данных вам потребуется всего 140 Тб емкости. Такой подход помогает оптимизировать бюджет или обеспечить хранение больших объемов данных в тех случаях, когда в кластер уже физически нельзя установить больше дисков, в стойку – больше серверов, в серверную – больше стоек. При этом мы сохраняем высокую доступность данных – даже при выходе из строя двух элементов системы хранения, оставшиеся узлы системы позволят восстановить все данные вплоть до бита, не останавливая работу приложения. В таблице приведены значения резервной емкости, и, как вы можете видеть, результаты использования erasure coding оказываются действительно впечатляющими, когда в кластере используется много машин. Например, в конфигурации 17+3 с erasure coding резервная емкость составляет всего 18%

Другое дело – производительность. Конечно, erasure coding повышает нагрузку на ЦП, но совершенно незначительно. За счёт SSE инструкций на современных процессорах одно ядро может обрабатывать до ~2GB/s данных.
В том и плюс распределенной системы хранения, что вы можете задать разные типы резервирования для разных нагрузок. И в случае с прямыми репликами, кластер с большим количеством узлов, напротив, дает намного большую производительность. Впрочем, именно о производительности VZ Storage мы поговорим более подробно в следующем посте, так как измерения эффективности гиперконвергентной системы хранения данных зависят от огромного количества факторов, включая характеристики «железа», тип сетевой архитектуры, особенности нагрузки и так далее.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (24)

beho1der
02.08.2017 18:19интересна стоимость, есть калькуляторы, как вообще покупаются лицензии?

Gummio_7
04.08.2017 10:27Скачать можно бесплатно с официальной страницы: https://virtuozzo.com/products/virtuozzo-storage/ (только Storage без виртуализации) https://virtuozzo.com/products/virtuozzo/ (Storage+Виртуализация)
На почту придёт ссылка на iSO образ. Для тестирования можно использовать виртуальную машину.
Чтобы попробовать продукт лицензии не нужно. Без лицензии, прямо после установки с ISO, можно пользоваться полным функционалом до 1ТБ. Если хотите хранить больше 1ТБ, придётся приобрести лицензию через отдел продаж Virtuozzo.
Цены можно узнать на сайте www.virtuozzo.com — просто сделайте заявку и вас сориентируют.
Arxitektor
02.08.2017 21:10А от какого количества серверов у гиперконвергентных хранилищ начинается преимущество перед класическими схд? Или все как всегда зависит от задач?
Например задача тестовая среда. Штук 35-45 Виртуалок.
Количество серверов 4. Гипервизор Vmware.
На тестовой среде будет работать примерно 20 пользователей. Пользователи с использованием VGPU.
В инфраструктуре будет 2 карты Nvidia M60.Gummio_7
04.08.2017 10:30Зависит от задач и ресурсов на решение. Тут сложно дать универсальный рецепт. Если заходить в классические СХД начального уровня, то можно довольно быстро упереться в их лимит (например, большой down-time при падании одной «головы» СХД), и решением будет покупка СХД выше классом. В гиперконвергентной инфраструктуре рост происходит плавно (как технологически, так и финансово), и это одно из главных преимуществ.
По тестовой среде — это скорее сценарий VDI с виртуализацией GPU. То есть хранилище у вас тут как бы вторичную роль играет при описании задачи....


porutchik
03.08.2017 08:35+1Глючит как Virtuozzo 7?
Gummio_7
03.08.2017 08:58-3Уважаемый, VZ Storage поставляется в рамках платформы VZ 7, а также в виде standalone-продукта. А насчет глючит… не знаю, а вы гуляете по бабам, как все поручики? :)
porutchik
03.08.2017 15:48+2То есть вы не знаете, глючит или нет?
* PSBM-67300
Kernel crash (NULL pointer dereference) in list_lru_destroy().
* PSBM-67221
Kernel crash (general protection fault) in cleanup_timers().
* PSBM-67076
Kernel deadlocks in try_charge().Gummio_7
04.08.2017 09:54-1Я бы сказал, что и VZ 7 у множества клиентов не глючит. Вопрос настройки. Обратитесь в техподедржку — как мы можем это обудить здесь, на хабре?

ximik13
03.08.2017 08:46+1Вроде бы и есть раздел озаглавленный "Архитектура", а самой архитектуры почти и нет.
1) Какой размер чанка используется?
2) Какие метаданные хранят MDS? Что то вроде адресации расположения чанков, информация о монтировании логических томов и что еще (хотя бы крупными мазками)?
3) Сколько этих MDS рекомендовано и максимально возможно? В каком режиме они работают? Active-Active или Active-Passive? Какая защита от потери метаданных кластера?
4) Как организованы физические носители? Некий общий пул или как то иначе?
5) Как быть если есть SSD и не-SSD? Разные пулы? Или тиринг?
6) Если разные пулы, то есть возможность перемещать между ними логические тома? Что бы поднять например производительность для конкретного клиента? Online, т.е. прозрачно для клиента и без остановки I/O? Или нет?
7) Как выделяются логические тома (thin or thick)?
8) Как мапятся и монтируются логические тома к клиентам?
9) Есть снэпшотинг? Репликация?
А то статья больше на рекламу похожа.
Gummio_7
04.08.2017 10:39Ну что же, давайте разбираться. :)
1) Размер чанка по умолчанию — 256MB. Из большого размера чанка, видно, что система хранения ориентирована на большие файлы или volume, такие как образы виртуальных машин. Но размер чанка можно изменить, если потребуется. Либо мелкие файлы, такие как объекты в S3, упаковываются в большие файлы на уровне сервиса S3.
2) Про MDS уже ответили товарищу выше, но повторимся. Файлы разбиваются на чанки. CS хранят чанки (данные). MDS хранит информацию о чанках (метаданные). В метаданные входит следующая информация: таблица трансляции файла в реплики, набор чанков соответствующих репликам, местонахождение чанков, настройки домена отказоустойчивости, размер чанков и прочая информация. Также в функции MDS входит система lock’ов на запись в файл, система автоматического восстановления избыточности, балансировка данных на основании текущей нагрузки и заполненности дисков. MDS почти не принимает участие в I/O потоках, этот компонент просто управляет процессом.
Чтобы было понятнее: в случае запуска VM, открывается образ VM, то есть открывается файл на запись. Клиент (FUSE-mount) берёт lock на запись в этот файл. Если файл ещё нигде не открыт (VM нигде ещё не запущена) MDS разрешает эту операцию и отдаёт полный MAP на файл (информация о том, как файл разбит на куски и где они хранятся). Клиент, получив карту файла самостоятельно работает с CS-ами, читая и изменяя данные внутри чанков. Если файл вырос или уменьшился, клиент делает запрос к MDS на изменение MAP, в этом случае MDS освобождает свободные чанки или создает новые.
3) Рекомендации по MDS — иметь 5 штук. Их автоматическое восстановление и является защитой от потери метаданных.
4) Каждый физический носитель – это CS (chunk server).
5) Есть разные варианты. Можно использовать SSD для журналирования и кеширования данных, а можно, как вы предлашаете, выделить в отдельный тир или пул для работы с более "быстрыми" данными.
6) В системе есть tier'ы. Их всего 4. Они позволяют создать из более быстрых дисков более производительный сегмент хранилища. Вы в любой момент можете разместить на нем более ресурсоёмкую нагрузку, например, пользователя или базу данных.
7) Выделение томов происходит методом Thin provisioning. Все логические тома (как, например, iSCSI LUN) растут по мере фактического потребления емкости.
8) Про маппинг уже сказали выше
9) Что касается снэпшотов, они поисходят на уровне VM. На уровне файлов пока нет. такой функции, но она планируется. Возможность Гео-репликации поддерживается для хранилища S3.
edo1h
03.08.2017 08:54+1я думаю, что самый актуальный вопрос: чем оно лучше ceph? с первого взгляда то же самое, но за деньги.
Gummio_7
03.08.2017 08:55Дело в производительности и оптимизациях. Для отдельных задач уже проведены тесты, и разница — как минимум в производительности. Об этом будет следующий пост.
ximik13
03.08.2017 10:19+1С Ceph одна основная проблема. Если нет специалистов, способных с ним разобраться в компании, то и нет возможности его нормально использовать. Вендорские решения обычно не требуют глубоких знаний продукта для его разворачивания и использования, но стоят денег.
Есть еще одна проблема, что в случае Ceph вся ответственность за функционирование решения и сохранность данных лежит на IT-специалисте (или IT-отеделе) развернувшем Ceph. Не все IT-шники к такому готовы.
sabbak
04.08.2017 10:31какие диски/контроллеры поддерживаются? поддерживается ли конфигурация с избыточностью на кодах Р/С и магнитных дисках? локальные диски должны быть в райде?
Gummio_7
04.08.2017 10:41СХД организует избыточность на своём уровне (репликация/Erasure-coding). Рекомендуется использовать JBOD контроллер (pass-through), то есть подразумевается отсутствие RAID, и тут можно немного сэкономить.
Но если всё-таки используется RAID контроллер (например, если железо уже есть), все диски нужно сконфигурировать как отдельный RAID0-volume. Репликация/Erasure-coding на уровне СХД имеет такой параметр, как домен отказа (failure domain). Он может иметь значение: disk, host, rack, raw, room. То есть для одного nod можно задать failure domain disk и СХД будет раскладывать реплики (или Erasure-coding схему) по дискам, если rack, то система будет размещать не более одной реплики на стойку.
AlexBin
Расскажите подробнее зачем нужны MDS и как клиенты ищут адрес нужного чанка.
Gummio_7
Файлы разбиваются на чанки. CS хранят чанки (данные). MDS хранит информацию о чанках (метаданные). В метаданные входит следующая информация: таблица трансляции файла в реплики, набор чанков соответствующих репликам, местонахождение чанков, настройки домена отказоустойчивости, размер чанков и прочая информация. Также в функции MDS входит система lock’ов на запись в файл, система автоматического восстановления избыточности, балансировка данных на основании текущей нагрузки и заполненности дисков. MDS почти не принимает участие в I/O потоках, этот компонент просто управляет процессом.
Чтобы было понятнее: в случае запуска VM, открывается образ VM, то есть открывается файл на запись. Клиент (FUSE-mount) берёт lock на запись в этот файл. Если файл ещё нигде не открыт (VM нигде ещё не запущена) MDS разрешает эту операцию и отдаёт полный MAP на файл (информация о том, как файл разбит на куски и где они хранятся). Клиент, получив карту файла самостоятельно работает с CS-ами, читая и изменяя данные внутри чанков. Если файл вырос или уменьшился, клиент делает запрос к MDS на изменение MAP, в этом случае MDS освобождает свободные чанки или создает новые.
AlexBin
Спасибо за развернутость. Еще несколько вопросов:
— метаданные реплицируются между MDS?
— если да, то синхронно?
— если синхронно, то как это влияет на производительность при горизонтальном масштабировании MDS?
— сколько требуется серверов метаданных и для каких размеров кластера?