
ETL и 1С. Извлечение данных
Первый взгляд
Если вы, как ETL-специалист столкнулись с необходимостью получать данные из 1С, то это первое, что вы можете увидеть, попытавшись разобраться со структурой БД (это из случае MSSQL, для других СУБД картинка аналогичная):
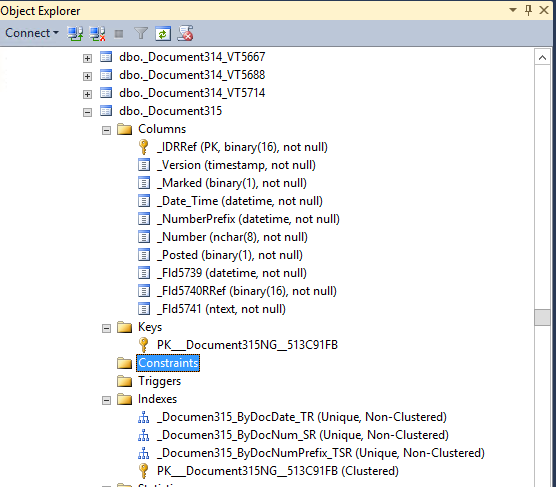
Бизнес-смысл в наименованиях таблиц и полей отсутствует, внешних ключей нет.
Пару ласковых о самой 1С. Реальные таблицы СУБД в ней скрыты за объектами, которые видит разработчик, который часто не догадывается о реальной структуре базы. Да… И весь код на русском языке. Кроме того, есть перечисления, строковые представления которых с помощью SQL получить практически невозможно. Об этом подробнее здесь.
Есть случаи, когда БД нет (и 1С в файловой версии), но это, разумеется ориентирует вас на интеграцию без использования средств СУБД.
Однако, не стоит впадать в отчаяние, поскольку все не так плохо, как кажется.
Внимательный взгляд
Для захвата данных из 1С у вас есть 2 пути:
Реализация «высокоуровневого» интерфейса
Вы можете воспользоваться файловыми выгрузками, web/json сервисами и прочими возможностями 1С, которые окажутся совместимы с вашим ETL.
+
- Вам не придется лезть в 1С. Все, что на стороне 1С должны сделать 1Сники
- Вы никак не нарушаете лицензионную политику 1С
—
- Появляется еще один источник для ошибок в виде дополнительных выгрузок-загрузок,
расписаний, роботизации - Это будет работать существенно медленнее из-за особенностей интерфейсов 1С
- При любых изменениях в захватываемых данных, вам придется вносить изменения в выгрузки (но это можно обойти настроечной системой)
- Это вызовет больше ошибок в целостности данных, чем работа напрямую с СУБД
Реализация на СУБД
+
- Работает быстрее
- Позволяет гарантировать полноту данных в хранилище при правильном подходе
—
- Нарушает лицензионное соглашение с 1С
Итак, взвесив за и против, вы решаете строить интеграцию через СУБД, ну или хотя бы
подумать, как вы будете это делать дальше.
Data mapping
Для того, чтобы связать бизнес-данные, как их понимают на стороне 1С с реальными таблицами БД, вам потребуется выполнить немного магии в самой 1С, а именно получить описание метаданных 1С в пригодном для использования виде (в связи бизнес-объектов и таблиц).
Опять же есть, как минимум, целых 3 подхода:
- Используя com-соединение, web/json сервис получить таблицу соответствия из 1С
- Сделать то же самое на стороне 1С, сформировав таблицу метаданных
- Разобрать бинарный файл, который хранится в той же БД
3-й путь мне кажется несколько рискованным в силу того, что 1С имеет привычку вносить изменения в свои внутренности без предупреждения. И, при этом, довольно сложным.
Выбор между 1 и 2 не столь очевиден, но на мой вкус использовать заранее сформированную таблицу гораздо удобнее, и надежнее в ежедневном использовании и нет нужды задействовать что-то, кроме чистого SQL.
Хранить и поддерживать актуальность таблицы удобнее при помощи 1С, обновляя после каждого обновления конфигурации. При этом, ETL может пользоваться View, который покажет данные уже в более удобоваримой форме.
Подготовка таблицы метаданных
Создать в 1С объект, который содержит метаданные конфигурации (к сожалению, скриптом это не сделать, но можно отдать инструкцию 1С-нику)
РегистрСведений.СтруктураКонфигурации
Поля:
ИмяТаблицыХранения
ИмяТаблицы
СинонимТаблицы
Назначение
ИмяПоляХранения
СинонимПоля
Все строки 150 символов
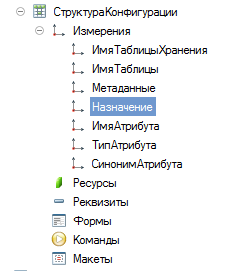
Получается денормализованно, но довольно удобно и просто.
Код 1С для заполнения структуры:
СтруктураБД = ПолучитьСтруктуруХраненияБазыДанных(,истина);
ЗаписиСтруктура = РегистрыСведений.СтруктураКонфигурации.СоздатьНаборЗаписей();
Для каждого СтрокаСтруктуры Из СтруктураБД Цикл
Для каждого СтрокаПолей Из СтрокаСтруктуры.Поля Цикл
Запись = ЗаписиСтруктура.Добавить();
Запись.ИмяТаблицыХранения = СтрокаСтруктуры.ИмяТаблицыХранения;
Запись.ИмяТаблицы = СтрокаСтруктуры.ИмяТаблицы;
Запись.СинонимТаблицы = Метаданные.НайтиПоПолномуИмени(СтрокаСтруктуры.Метаданные);
Запись.Назначение = СтрокаСтруктуры.Назначение;
Запись.ИмяПоляХранения = СтрокаПолей.ИмяПоляХранения;
Запись.СинонимПоля = Метаданные.НайтиПоПолномуИмени(СтрокаПолей.Метаданные);
КонецЦикла;
Конеццикла;
ЗаписиСтруктура.Записать(истина);
Опять же все довольно просто и очевидно, несмотря на русский язык. Нужно выполнять этот код при каждом обновлении конфигурации. Делать это можно руками в обработке или при помощи регламентного задания.
Таблицу можно просматривать как в режиме клиента, так и со стороны SQL, зная их имена.
SELECT * FROM _InfoReg27083 ORDER BY _Fld27085(_InfoReg27083 — имя, которое 1С дала таблице регистра со структурой, _Fld27085 — имя поля с именем таблицы хранения)
Можно сделать View, чтобы было удобнее.
Если нет возможности вносить изменения в конфигурацию, можно сделать таблицу, соединившись через com, или дописав в обработке выгрузку в таблицу базы, которая задействована в ETL.
А здесь про то, какие есть типы таблиц, и зачем они нужны (нужен доступ к ИТС 1C).
Следующий шаг — составить карту данных и описание трансформации.
| Field | Field1C | Transformation | ... |
|---|---|---|---|
| _Fld15704 | Документ.РеализацияТоваровУслуг.Вес | Check >=0, round(10,2),… | ... |
Вот мы получили таблицу маппинга, которую можно использовать в дальнейшей работе.
Захват изменений данных
Теперь с точки зрения стратегии захвата изменений данных. Здесь опять есть несколько вариантов. Проще забирать таблицы целиком, что, разумеется может стоить серверу существенных дополнительных расходов.
Однако, есть и другие способы:
- Использовать версии объектов
- Использовать план обмена
Использовать версии объектов
Для объектов «ссылочного» типа 1С поддерживает версии. Номер версии объекта записывается в бинарное поле _version, аккуратно обновляющееся при каждом обновлении записи. На MSSQL, например, это поле типа timestamp. Версии поддерживаются для объектов типа «Документ»,«Справочник»,«Бизнес-процесс»,«Задача»,«План счетов»,«План видов характеристик», «Константы». Использовать версию довольно просто, сохранив у себя в staging area значение последней версии для объекта, и при следующем обновлении выбрав объекты, большие по значению поля версии. Вместе с «основным» объектом нужно не забыть забрать его табличные части (см. Назначение — «Табличная часть») в структуре (поле вида _DocumentXXX_IDRRef или _ReferenceXXX_IDRRef — ссылка на основную таблицу).
Использовать план обмена
Для не ссылочных типов такой подход не годится, но можно воспользоваться объектом «план обмена». В таблице структуры их назначение = 'РегистрацияИзменений'. Для каждого объекта конфигурации создается отдельная таблица плана обмена.
На уровне БД это таблица, вот такой структуры:
_NodeTRef, — идентификатор типа «узла» плана обмена. Он нам не очень интересен
_NodeRRef, — идентификатор узла плана обмена
_MessageNo, — номер сообщения
Дальше идут поля ключа «основной» таблицы. Они различаются в зависимости от типа таблицы, с которой связана таблица плана обмена:
_IDRRef — в данном случае ID справочника или документа
может быть вот так вот:
_RecorderTRef
_RecorderRRef
Это будет таблица изменений регистра накопления, регистра сведений, подчиненного регистратору, или регистра бухгалтерии. Так же может быть ключ таблицы регистра сведений, если он не подчинен регистратору.
Для того, чтобы такая таблица регистрации изменений существовала, нужно включить в конфигураторе 1С нужный нам объект в план обмена. Кроме того, нужен быть создан узел плана обмена, идентификатор (_IDRRef) которого наим нужно будет использовать.
Таблицу плана обмена можно найти в структуре (см. выше). Т.к. в плане обмена регистрируются изменения для всех узлов, а не только для хранилища, нам нужно ограничить выборку нужным нам _NodeRRef. План обмена можно использовать и для ссылочных объектов, но на мой взгляд это бессмысленный расход ресурсов.
Как забирать данные через план обмена:
Для начала мы пишем update к плану обмена, где ставим произвольный _MessageNO (лучше всегда 1).
Например
UPDATE _DocumentChangeRec18901 set _MessageNO = 1 WHERE _NodeRRef = @_NodeRRefДалее выбираем данные из таблицы данных, связав ее по ключу с таблицей плана обмена
SELECT [fieldslist] FROM _Document18891 inner join _DocumentChangeRec18901 ON _Document18891._IDRRef = _DocumentChangeRec18901._IDRRef and _MessageNO = 1 AND _NodeRRef = @_NodeRRefИ подтверждаем забор изменений, удалив записи таблицы изменений
DELETE FROM _DocumentChangeRec18901 WHERE _MessageNO = 1 AND _NodeRRef = @_NodeRRefИтого: Мы научились читать на стороне ETL метаданные 1С, научились выполнять захват данных. Остальные шаги процесса ETL достаточно хорошо известны. Например, можно почитать здесь.
Комментарии (17)

Melex
03.08.2017 17:36А еще есть odata, причем по всем стандартам, и эксель и павер би с ней отлично работают.
Так что если цель стоит «забирать» максимально «правильно», то или одата, или внешние источники.
Вы куда то не туда пошли копать, если надо забирать изменения — то только через саму 1С, когда она пишет данные в нужную вам на скуле таблицу.smirnovhi Автор
03.08.2017 17:51Есть вариант использовать внешние источники. Тогда больше логики придется реализовать 1С + автоматизация процесса выгрузки средствами 1С. Согласен, что имеет право на существование, как подход. Но я бы не сказал, что он единственно верный из возможных. Из минусов — мы опять же не можем использовать версии объектов, только планы обмена и онлайновая запись, что получается дороже. И хуже контроль над процессом со стороны ETL.
Melex
03.08.2017 18:27Версии объектов появятся в 8.3.11, плюс есть SQL версионники, если вам нужны версии — используйте их.
На счет того, что хуже контроль со стороны ETL — поспорю.
1С намного проще определить — менялось что-то ключевое или нет. А саму выгрузку можно делать регламентом.
Так что тут очень много НО.
Все зависит от задачи. Какую цель преследуете именно вы?
lash05
03.08.2017 22:23+3Опять же все довольно просто и очевидно, несмотря на русский язык.
— может, благодаря русскому языку?

ZEEGIN
03.08.2017 22:46+1Самое главное не написали:
Реализация «высокоуровневого» интерфейса
- После обновления конфигурации 1С или внесения в нее доработок или внесения доработок в ETL изменения в формат высокоуровневой выгрузки требуется внести только в случае, когда: были изменены синхронизируемые таблицы, при этом если изменения такие, что их можно привести к формату пакета обмена (DTO), то изменения вносятся только на той стороне, в которой они были внесены. Изменение самого формата DTO требуется в крайне редких случаях.
От чего прозрачная поддержка и адаптируемость к новым требованиям на будущее.
Реализация на СУБД
- После внесения любого изменения в 1С, даже не сильно связанного с вашим обменом, а так же при простых операциях, как реиндексация или реструктуризация данных, что в 1С доступно вообще из административного режима, может формат хранения данных в СУБД измениться. В первую очередь 1С запрещает обращаться к таблицам СУБД как раз из-за того, что это может нарушить работу самого 1С. Если чтение данных — это еще допустимо (образно), то запись непосредственно в базу — полный отказ от гарантий. Соответственно использование данного подхода — постоянный риск привести в неработоспособное состояние обмен с ETL и как следствие постоянные часы внеплановых доработок обмена.
Вопрос с же с производительностью всегда является спорным, при оптимизации запросов чтения и формирования DTO пакетов, определения оптимального размера самого пакета данных, выбором периодичности сообщений обмена, можно даже на медленном сервере с большой базой данных добиться хорошей производительности.
- После обновления конфигурации 1С или внесения в нее доработок или внесения доработок в ETL изменения в формат высокоуровневой выгрузки требуется внести только в случае, когда: были изменены синхронизируемые таблицы, при этом если изменения такие, что их можно привести к формату пакета обмена (DTO), то изменения вносятся только на той стороне, в которой они были внесены. Изменение самого формата DTO требуется в крайне редких случаях.
ZEEGIN
03.08.2017 23:17+1На самом деле, вся проблема в том, что Вы предлагаете использовать ПолучитьСтруктуруХраненияБазыДанных не по назначению. Полагаться на результат работы данного метода для разработки непосредственных обращений — неправильное решение.
Данный метод существует непосредственно для самих 1Сников. Можно подумать, "Зачем 1Сникам знать низкоуровневую структуру базы данных, если вы все работаете с объектной моделью?". Так вот, он и сделан для того, что бы 1Сники не задумывались об этой низкоуровневой структуре. Так зачем же он нужен?
Запросы в 1С — тоже объектно ориентированные, и работают с типизированными данными, фактически это значит, что по значению колонки, если знать какой тип объекта в ней хранится, можно получить данные вложенного объекта по ссылке, при этом будет неявно выполнено соединение с таблицей, хранящей вложенный объект.
Само собой такие запросы просто так на СУБД не выполняются, предварительно они транспонируются в такой запрос, который понимает СУБД. Но проблема в том, что каждая СУБД может по своему понимать один и тот же запрос 1С. Да еще и перед выполнение запроса СУБД строит план выполнения запроса, который рассчитывается динамически от состава запрашиваемых данных, текущего объема таблиц, и еще множества разных факторов (составы индексов, кластерный индекс, знание о количестве выбираемых строк и.т.д.). Как следствие в некоторых случаях планы выполнения запроса к реляционным таблицам могут быть не оптимальны.
1С позволяет записывать в технологический журнал информацию о том, для какого запроса какой план выполнения был получен у СУБД, а этот план строится самой СУБД и в нем фигурируют именно имена таблиц самой СУБД. Вот для восстановления реальных имен объектов 1С для анализа запросов и их оптимизации и есть метод ПолучитьСтруктуруХраненияБазыДанных.
- Написали и выполнили запрос
- Получили журнал регистрации
- Восстановили реальные имена объектов
- Построили граф выполнения плана запроса
- Выполнили оптимизацию запроса
Примерно так это все выглядит. Специальные инструменты разработчика, как та же "Консоль запросов", запускаемая в режиме 1С: Предприятие и входящая в состав поставки Библиотеки Стандартных Подсистем, является примером.

gremlin_boloto
04.08.2017 16:38+1Начиная с 8.2 на стороне 1С можно разрабатывать XDTO-сервисы которые смогут отдавать вам все что захотите.

EvilBeaver
04.08.2017 20:16+2Отличная статья «как не надо делать» Если не знаешь 1С можно же позвать тех, кто знает, а не создавать еще одно порожденте кровавого энтерпрайза

kxl
04.08.2017 23:08+1Такая хрень была еще оправдана с 7.7 поскольку вариантов особо не было… Но! Не нужно делать это с 8.2 и старше! Как сказано выше — сервисы ваше всё. А так — любое изменение структуры базы в конфигураторе приведет к переписыванию подобного кода.
Dementor
05.08.2017 11:12+1Согласен с коллегами, которые отписались выше. У вас изначально были неправильные предпосылка и потому вы пошли не тем путем.
Для захвата данных из 1С у вас есть 2 пути:
То, что вы описали как четыре минуса для получения данных с помощью стандартных средств 1С (SOAP, OData или HTTP-сервисы с XML/JSON), вообще к ним не относятся.
Появляется еще один источник для ошибок в виде дополнительных выгрузок-загрузок,
расписаний, роботизации
Расписания выгрузок/загрузок и прочая «роботизация» находится на вашей стороне, а 1С при таком подходе выступает как сервер данных: вы сделали запроса и получили ответ. Формально это даже не минус, а просто реалии вашей работы как «ETL-специалиста» с любым источником данных.
Это будет работать существенно медленнее из-за особенностей интерфейсов 1С
Что же это за особенности? У меня уже есть ряд мобильных разработок для удаленной работы с базами 1С и они работают довольно шустро даже в сценариях, когда требуется полная и актуальная НСИ. В первом варианте происходит быстрая выборка, сериализация в нужный формат и возврат веб-сервером. Во втором варианте перед запросом нужно каждый раз актуализировать информацию по меппингу и только затем уже можно выбирать данные и преобразовывать в тот вид, с которым вы будете далее работать.
При любых изменениях в захватываемых данных, вам придется вносить изменения в выгрузки
В первом подходе никаких изменений вносить не требуется, а при непосредственном доступе к СУБД из-за изменения структуры и названия таблиц эти изменения постоянны.
Это вызовет больше ошибок в целостности данных, чем работа напрямую с СУБД
Тут даже комментировать особо нечего. Весь контроль целостности находится на стороне платформы, которая гарантирует в 99,9% случаев успешные чтение и запись (еще есть редкие случаи сбоев самой СУБД на которые 1С влиять не может). А вот бездумный INSERT/UPDATE/DELETE напрямую в СУБД может натворить делов… Но вы же в статье только про получение информации говорите? Тогда какая к черту целостность? Скорее тут вопрос в согласованности данных! В режиме 1С вы получаете гарантированно цельный и согласованный объект, а в режиме СУБД можете напутать с версиями и JOIN-ми табличных частей. Не говоря уже о том, что легко нарваться на грязное чтение.
Dementor
05.08.2017 11:31+1Еще один комментарий, но уже без цитат.
1) Вы предлагаете снимать программу с поддержки и писать данные по конфигурации напрямую в конфигурацию. Для Бухгалтерий, которые регулярно самостоятельно обновляются без участия «программиста» — это не выход из-за поломки такого автообновления и вам выше правильно напомнили про возможность создать сервис с помощью расширения, который будет выдавать нужную информацию.
2) И еще вы совершенно верно указали, что названия таблиц при реструктуризации изменяются. Так от куда у вас взялась идея, что ваша таблица с метаданными ВСЕГДА будет называться _InfoReg27083? Ее название тоже может легко изменится при обновлении, когда изменится состав дерева метаданных (или при переходе на новую версию платформы). Т.е. вместо того, что бы просто брать готовые данные, вы сами себя обрекаете на перепроверку и возможное переписывание ваших скриптов для каждой из попыток загрузки.
*) И сколько можно про русский язык? Если вы не знаете русского языка, то пишите код на английском. Есть целые линейки программ из серии «1С: Предприятие», которые ориентированы на внешний рынок и написаны полностью на английском языке без единого русского слова (есть даже две типовые конфигурации, которые пишет сама компания 1С, а не ее партнеры — Small Business и Accounting Suite). Вот только на русскоязычной территории СНГ и ближнего зарубежья (Прибалтика, Молдова и пр.) предпочитают именно русский язык и это является конкурентным преимуществом при распространении.
smirnovhi Автор
06.08.2017 01:50В общем, согласен почти со всеми комментариями, кроме некоторых моментов. Например — по поводу грязного чтения. Сама 1С использует read uncommited в полный рост).
И еще один важный момент — реальная практика показывает, что это работает. Работает стабильно. Годами. Со всеми версиями, начиная от 8.1.
VVizard
Как вариант (если «Нарушает лицензионное соглашение с 1С» не останавливает) можно сгенерировать View с нормальными (Бизнес-смысл в наименованиях) именами таблиц.
Есть готовые инструменты:
https://infostart.ru/public/352750/ (Первая кнопка).
https://infostart.ru/public/394013/
Эти view так же нужно будет постоянно обновлять при изменении конфигурации, но зато не требуется доп. регистр.
Для новых версий 8.3.9 и выше более правильно будет разработать расширение (плагин) которое будет содержать в себе WEB или HTTP сервис к которому будет обращаться внешня система для получения данных. И в нем будет логика получения изменных данных.
Общение через формализованный интерфейс всегда лучше чем просто лазить в чужую базу данных. Именно поэтому 1С запрещает обращаться к SQL напрямую.
Тем более что 1С это не только SQL но и Oracle, Postgresql, DB2, собственная файловая СУБД.
smirnovhi Автор
Не очень понимаю, почему использование View не нарушает лицензионное соглашение?
Разумеется. И в любой из этих СУБД, кроме файловой, предложенные методы работают.Предложенные средства работают, но решают немного другую задачу. Наша задача — получение измененных данных из 1С. Статья в первую очередь о правильном заборе данных из 1С средствами СУБД.
Спасибо за комментарий)
VVizard
Нарушает, я об этом и написал.
Вариант с генерацией View решает задачу забора данных из СУБД.
В этом случае SQL запросы выглядят как то так:
т.е. все то же самое что у вас в статье только вместо того что бы создавать регистр, обработка генерирует (И выполняет) SQL скрипт создания VIEW, примерно такой:
И так для каждого объекта метаданных. В итоге все объекты (включая и таблицы регистрации изменений) доступны как View с понятными именами, и к ним можно делать запросы.
smirnovhi Автор
Моя статья не о том, как сгенерировать View, которые будут смотреть в базу.
Когда есть задача забрать данные, и сделать это достаточно оптимально, не вытягивая таблицы целиком, можно воспользоваться версиями объектов или планами обмена.
И эту задачу указанные генераторы не решают. И, конечно, это можно завернуть в еще одну удобную обертку в виде View.