
Проблема
В декабре 2016 года я сменил работу и перешел в новую компанию. Новая контора находилась в стадии перехода от «отдел в полтора программиста на коленке лабает небольшой сервис для внутренних нужд» в «ИТ-компания в 100 человек разрабатывает ERP систему для нужд группы компаний и готовит продукт для внешних пользователей».
Естественно, в процессе этого перехода многие наколеночные «так принято» вещи становились серьезными и соответствующими разнообразным best practices. В частности, в компании появилась за несколько месяцев до моего прихода полноценная иерархия тестовых сред и отдел тестирования неуклонно боролся за соответствие тестовых сред — среде боевой.
Авторы унаследованной архитектуры исповедовали микросервисный подход, сроки были жесткими, процент джуниоров — большой. Тестеры при развертывании на тестовую среду столкнулись с тем, что внезапно микросервис А, развернутый на тестовой среде, мог вызывать микросервис Б прямо на проде. Смотрим в код — и видим — URL микросервиса Б зашит внутрь кода микросервиса А.
В процессе работы помимо проблемы «захардкоженная ссылка на микросервис» выявились и другие проблемы кода. Code-review check list все рос, ругань становилась все злее. Необходимо было решение, которое выявит все проблемы и предотвратит появление таких ситуаций в будущем.
Статические анализаторы
Новый компилятор языка C# — Roslyn — полностью open source и включает поддержку pluggable static analyzers. Анализаторы могут выдавать ошибки, предупреждения и хинты, работают как во время компиляции, так и в реальном времени в IDE.
Анализаторы имеют доступ к AST(абстрактному синтаксическому дереву) и могут подписываться на элементы определенного типа, например на числа или строки или на вызовы методов. В самом простом виде это выглядит как-то так:
private static void AnalyzeLiteral(SyntaxNodeAnalysisContext context)
{
if (syntaxNode is LiteralExpressionSyntax literal)
{
var value = literal.Token.ValueText;
if (value != "@" && value.Contains("@"))
{
context.ReportDiagnostic( Diagnostic.Create(Rule, context.Node.GetLocation(), value));
}
}(Это моя самая первая попытка написать анализатор для захардкоженных email).
По дереву можно ходить вверх, вниз и вбок, и нет необходимости отличать, скажем, комментарий от строкового литерала — парсер компилятора делает все это за нас. Впрочем, уровня синтаксиса может быть недостаточно. Например,
var guid = new Guid("...");На синтаксическом уровне мы не можем понять, конструктор какого типа мы вызываем. Скорее всего, это System.Guid. А что, если нет? На уровне синтаксического дерева это просто «конструктор класса с идентификатором, равным «Guid»». Для более точной диагностики нам нужно вызвать так называемую семантическую модель и получить у нее информацию о том, какому символу соответствует элемент синтаксического дерева.
private static void AnalyzeCtor(SyntaxNodeAnalysisContext context)
{
if (context.Node.GetContainingClass().IsProbablyMigration())
{
return;
}
if (context.Node is ObjectCreationExpressionSyntax createNode)
{
var type = context.SemanticModel.GetTypeInfo(createNode).Type as INamedTypeSymbol;
var guidType = context.SemanticModel.Compilation.GetTypeByMetadataName(typeof(System.Guid).FullName);
if (Equals(type, guidType))
{
..
}
}
}Семантическая модель — это промежуточные результаты компиляции. В отличие от синтаксиса, она может быть неполна (напоминаю, мы работаем в контексте IDE, программист может прямо сейчас писать анализируемый класс). Поэтому готовьтесь, методы семантической модели много и часто возвращают null.
Анализаторы ставятся в проект, как обычные NuGet пакеты. После перекомпиляции начинаются проявляться ошибки и предупреждения. Мы в конторе сделали внутренний NuGet пакет (у нас вообще вся сборка всего идет через пакеты), который ставит рекомендованную комбинацию анализаторов. Планируем еще туда дописать наши специфические конторские штуки, и туда же можно добавлять не наши пакеты (я например добавил AsyncFixer, очень удобная штука, всем рекомендую).
Вот так это выглядит в редакторе
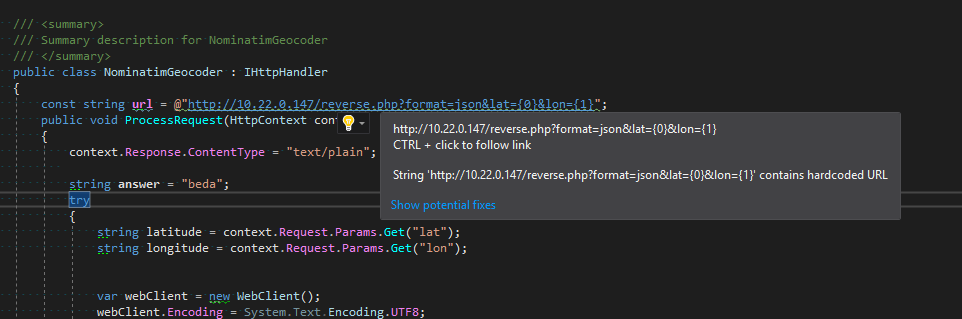
А так в итогах компиляции

Какие анализаторы мы сделали
Анализатор захардкоженных URL
Самый важный для нас анализатор. Тупо ищет все литералы с http, https, ftp и так далее. Список исключений довольно большой — в основном разнообразный автогенеренный код, SOAP атрибуты, namespace и все такое.
Анализатор захардкоженной ставки НДС
Редко, но метко встречающаяся в нашем коде проблема. Иногда «сумма с НДС» высчитывается из «суммы без НДС» умножением на 1.18. Это сразу две проблемы. Во-первых, ставка НДС может измениться, и искать все места в коде — большая проблема. Во-вторых, ставка НДС вообще-то — не константа, а атрибут конкретного заказа — он может быть со ставкой НДС 0% (такие юрлица часто бывают у перевозчиков), может относится к другой юрисдикции, наконец, при изменении ставки НДС она изменится для новых заказов, а для старых окажется прежней.
Поэтому никакого захардкоженного НДС!
В исключения тут попали в основном функции вырезания подстрок (substring). Иногда там имеет смысл передавать жестко прописанное 18. Приходится ловить по именам параметров метода.
Анализатор захардкоженного Guid
Мы часто из кода ссылаемся на id базы (у нас приняты Guid). Это плохо. Особенно мы страдаем из-за таблиц статусов, которым на самом деле стоило бы просто сделать enum (от них мы избавляемся, но они есть). Пока в качестве промежуточного решения мы договорились, что в коде могут встречать id, если они одинаковы во всех средах (значит, создаются миграциями) и если они располагаются непосредственно в коде соответствующей Entity (да, мы используем Entity Framework 6 и не стесняемся).
Что у нас в планах
— анализатор захардкоженных email
— анализатор, обязывающий писать методы контроллера асинхронными
Возникшие трудности и странные моменты
Общая библиотека
Естественным было разделить анализаторы по принципу 1 анализатор = 1 assembly = 1 nuget пакет. Дело в том, что все написанные нами анализаторы очень opinionated, и логично предоставить возможность подключать / отключать их по одному. В процесс написания анализаторов я стал активно выносить общий код из анализаторов в общую библиотеку и возникла проблема: если разные версии анализаторов загружены в студию — они не могут загрузить разные версии общей библиотеки. Самым простым решением оказалось сливать на этапе билда каждый анализатор с общей библиотекой в единый assembly. Для этого я воспользовался ILRepack, у которого есть удобный биндинг для MSBuild (ILRepack.MSBuild.Task). К сожалению, биндинг немного устарел, но это вроде бы пока не влияет.
Стандартные зависимости анализаторов (Microsoft.CodeAnalysis.*) таскать с собой не нужно, и зависеть от них NuGet тоже не должен. Visual Studio сама выдаст нам нужные библиотеки.
Сборка при помощи Appveyor
Я привык настраивать непрерывную сборку проектов с исходным кодом при помощи Appveyor. Собирать и публиковать NuGet он тоже умеет. Но анализаторы — особая магия. В частности, в плане структуры директорий внутри пакета, там все по-особому, нужно раскладывать в папку analyzers вместо стандартной lib. Я немного помучился и пришел к решению — в csproj как эта сборки прописан вызов Nuget.exe, который мы таскаем с собой в пакете. Некрасиво, как мне кажется, но более красивого решения я не нашел.
Написание юнит-тестов
Юнит-тесты для анализаторов — это супер классно и удобно. Я использовал стандартную MS обертку для юнит-тестов анализатора, любой false позитив тут же оформлял юнит-тестом. Классно! Гораздо приятнее, чем возиться с нечетким человеческим ТЗ.
Переход на .netstandard
Перейти на .netstandart мне пока не удалось. Попытка с ходу оказалась неудачной, официальный template все еще генерит portable class библиотеки. Ждем обновленного template и попробуем сделать по нему. https://github.com/dotnet/roslyn/issues/18414
Заключение
Буду рад пинкам по поводу моего подхода. Исходники можно посмотреть здесь.
Буду также рад, если кто-то посоветует хорошие опенсорсные C# проекты, на которых проверить анализаторы, или проверит у себя на своих (может даже не опенсорсных) и зарепортит баги.
Очень хотелось бы ссылок на другие полезные анализаторы, желательно не дублирующие функционал Resharper.
Комментарии (26)

ProgerMan
22.08.2017 14:24-1А не лучше ли сразу писать хорошо? Например, перетащить все константы в отдельный модуль.
Или это для тех, кто регулярками для поиска пользоваться не умеет, чтобы немного порефакторить?
leotsarev Автор
22.08.2017 14:33+8Да, конечно лучше бы сразу писать хорошо. Я выбрал анализаторы перед другим рассматриваемом вариантом «машина времени». Код по факту уже был написан так, когда мне достался.
Но и это еще не все. Вопрос в том, как добиться этого «сразу писать хорошо». Какие варианты? Изначально мы полагались на внедрение code review. Но вопрос в том, что code review требует времени ревьюеров. Если их мало, они становятся узким местом. Если много, то вопрос в том, как добиться унификации и соблюдения стандартов среди ревьюеров. Процесс распространения культурных изменений в компании — дело не одного дня, и часто — не одного месяца.
leotsarev Автор
22.08.2017 14:40+3Про рефакторинг. В принципе, для небольших проектов просто поискать по солюшену — не сложно. Для крупных — сложнее. Начинаешь утопать в false позитивах и допустимых случаях — в комментариях можно. В SoapDocumentMethodAttribute можно. Пропустить один — довольно легко.
К тому же анализаторы поддерживают однажды свершенные победы (выпилены все хардкоды URLов) в актуальном состоянии.


nixel
23.08.2017 09:52+1
Может интегрироваться в IDE — http://www.sonarlint.org
На работе пользуемся более чем для пяти языков, при необходимости сами пишем плагины и новые правила.

Andrey2008
23.08.2017 09:57Кстати, да. Хороший способ контролировать качество кода. Плюс, если есть желание искать не только запахи и частные случаи, можно добавить сторонние плагины. Я думаю вы знаете, что я рекомендую :).
Andrey2008
23.08.2017 09:53Идея искать особые случаи понятно. А не было ли желания, использовать ещё и полноценный анализатор кода (например, PVS-Studio) для поиска широкого спектра ошибок? При бурном развитии проекта и росте количества сотрудников, анализатор окажется хорошим помощником по контролю того, что творится в коде.
leotsarev Автор
23.08.2017 09:56Вообще на предыдущем месте работы мы попробовали PVS-Studio. Вывод был — хороший инструмент, но непонятно насколько много added value по сравнению с Resharper (который у нас все равно есть).
Впрочем, если пришлете тестовый ключ, попробую и на этой кодовой базе, она должна быть хуже. leo@bastilia.ruAndrey2008
23.08.2017 10:06+1Ключ отправил.
P.S. Отмечу, что попробовать PVS-Studio for Windows можно и без запроса лицензии. Скачиваем, устанавливаем, проверяем проект и рассматриваем ошибки.
Sinatr
23.08.2017 10:49В статье слишком много «захардкоженно». Можно было бы один раз написать что-то вроде «жестко вшитых» (в скобочках указать hardcoded) и не использовать этот термин больше.
eugenebb
23.08.2017 16:57Редко встречаемая, но очень полезных функция, это возможность игнорировать проблемы в старом коде, но падать на новом/измененном.
В легаси проектах невозможно починить всё сразу, но хочется чтобы новый код был хорошего качества. Мы так у себя сделали, помогает.Oxoron
23.08.2017 19:42А как вы отделяете новый код от старого? На уровне проектов, классов?
eugenebb
23.08.2017 20:00+1На уровне «магии», т.е. файлов.
Нам не надо отличать весь старый код от нового. Нам надо понять что присутсвуют проблемы которые у нас еще не добавленны в список известных и помеченных к игнорированию. По классам нам не подходит, есть завязки на JS код.
Можно делать как решарпер и т.д., т.е. добавлять комментирий с пометкой игнорирования, но тогда старый, проблемный код начинает пестрить ими как новогодняя ёлка, а если отключать на более высоком уровне то новый код также благополучно игнорируется.
Можно по diff из source control, но тогда сложнее идентифицировать только что изменённый код.Oxoron
23.08.2017 20:07Все равно не понимаю. Вы просто тянете дату последнего коммита, и если коммит старше 3 месяцев — помечаете файл как старый? Или какой-то кеш поддерживаете, куда изредка заносите новые файлы?
eugenebb
23.08.2017 20:47+1В момент «Х», прогоняем анализатор для файлов в проекте, весь вывод анализатора по каждому файлу сохраняем (в source control, чтобы синхронизировать в команде). Считаем что это «старые» ошибки и может их игнорировать.
Если сделали изменения в файле, прогоняем анализатор снова, сравниваем вывод анализатора с сохраненной копией (игнорируя номера строк, чтобы не срабатывать на добавление/удаление нерелевантного кода), если есть различия, сообщаем об этом и показываем.
Если решили что новые сообщения надо тоже игнорировать, то просто заменяем сохранённую копию текущим выводом.
Просто, но для нас работает. Можно конечно сделать более правильно, если у тебя это основной бизнес (как у PVS-Studio/Resharper).
leotsarev Автор
23.08.2017 22:40Я вот так хотел бы сделать с правилом «обязательно xmldoc ко всему публичному», но пока не разобрался, как.

alhimik45
23.08.2017 19:31Можно ли с помощью Roslyn написать например анализатор того, что в catch блоке программист не забыл залогировать ошибку? Основная проблема — логирование может быть вызвано не сразу, а например может быть вызван метод, который уже и залогирует. То есть нужно лезть внутрь по цепочке вызовов. Поможет ли в этом случае семантическая модель или roslyn не подходит для такого вида проверок?
Oxoron
23.08.2017 19:41+1Семантическая не факт что поможет. Синтаксическая с семантической — да. Только для средних-больших проектов не рекомендую делать именно анализатор, лучше Standalone tool — построение семантической модели может много времени занять.
eugenebb
23.08.2017 20:25+1Удобство анализаторов специфичных под конкретно Ваш проект заключается в том что скорее всего у вас всё сделано в одном (двух-трех-пяти-...) стиле(ях) и реализовать под этот стиль сильно проще, чем что-то общее, для всех случаев.
Плюс в проекте всегда можно договориться делаем вот так, всё что по другому, считаем ошибкой.
Мы хотели сделать автоматическое внедрение логики логирования и профилирования во все public/protected методы, но вместо этого используем AppDynamics и довольные как паравозы.
Так что иногда вопрос «какую проблему вы этим хотите решить?» гораздо лучше, чем «как понять что логирование не пропущено?»
leotsarev Автор
23.08.2017 22:38Чем перебирать весь стек вниз, я бы сделал так:
Опознавать вызовы нескольких стандартных библиотек для логирования;
Предоставить атрибут, которым можно пометить метод, чтобы он считался «логирующим». Тогда вы можете прометить им свои обертки.
Oxoron
github.com/icsharpcode/RefactoringEssentials
leotsarev Автор
Выглядит скорее как «open-source R#»
Вот еще в ту же степь https://github.com/JosefPihrt/Roslynator
Oxoron
Посмотрите тут, хотя я не уверен что автор открыл исходники.
Vadem
Вот тут ещё можно посмотреть github.com/Cybermaxs/awesome-analyzers