

Всем привет! Сегодня мы продолжим рассказывать про облачное хранилище Техносерв Cloud, но уже с точки зрения эксплуатации. Ни одна ИТ-инфраструктура не обходится без инструментов мониторинга и управления, и наше облако не исключение. Для решения повседневных задач, связанных с мониторингом, мы используем продукты с открытым исходным кодом, одним из которых является стек ELK. В этой статье мы расскажем, как в нашем облаке устроен мониторинг журналов, и как ELK помог нам пройти аудит PCI DSS.
Задача централизованного сбора и анализа логов может возникнуть на любом этапе жизненного цикла продукта. В случае с облачным хранилищем Техносерв Cloud необходимость единой консоли для просмотра журналов стала очевидной еще до запуска решения в эксплуатацию, уже на старте проекта требовался инструмент, позволяющий быстро выявить проблемы в используемых системах. В качестве такого инструмента был выбран стек ELK – простой в настройке и эксплуатации продукт с открытым исходным кодом и возможностью масштабирования.
ELK – основной инструмент наших инженеров для просмотра логов платформы: в Elasticsearch собираются записи журналов со всех эксплуатируемых серверов и сетевого оборудования. Мы убеждены, что логов много не бывает, поэтому наши системы делают записи в журналы с максимальным уровнем отладки. Для получения событий используется Beats: filebeat и winlogbeat, syslog и SNMP трапы. С сетевых устройств также собирается информация о трафике по протоколу Netflow. На сегодняшний день наш стек ELK обрабатывает около 1000 входящих записей в секунду с пиками до 10000 записей, при этом выделенных ресурсов по предварительным прогнозам должно хватить на 2-/3-кратное увеличение потока логов.
Архитектура
Надежность – одно из ключевых требований, предъявляемых к используемым системам. По этой причине ELK был установлен в отказоустойчивой конфигурации: нам важно быть уверенными, что логи продолжат собираться в случае недоступности части серверов.
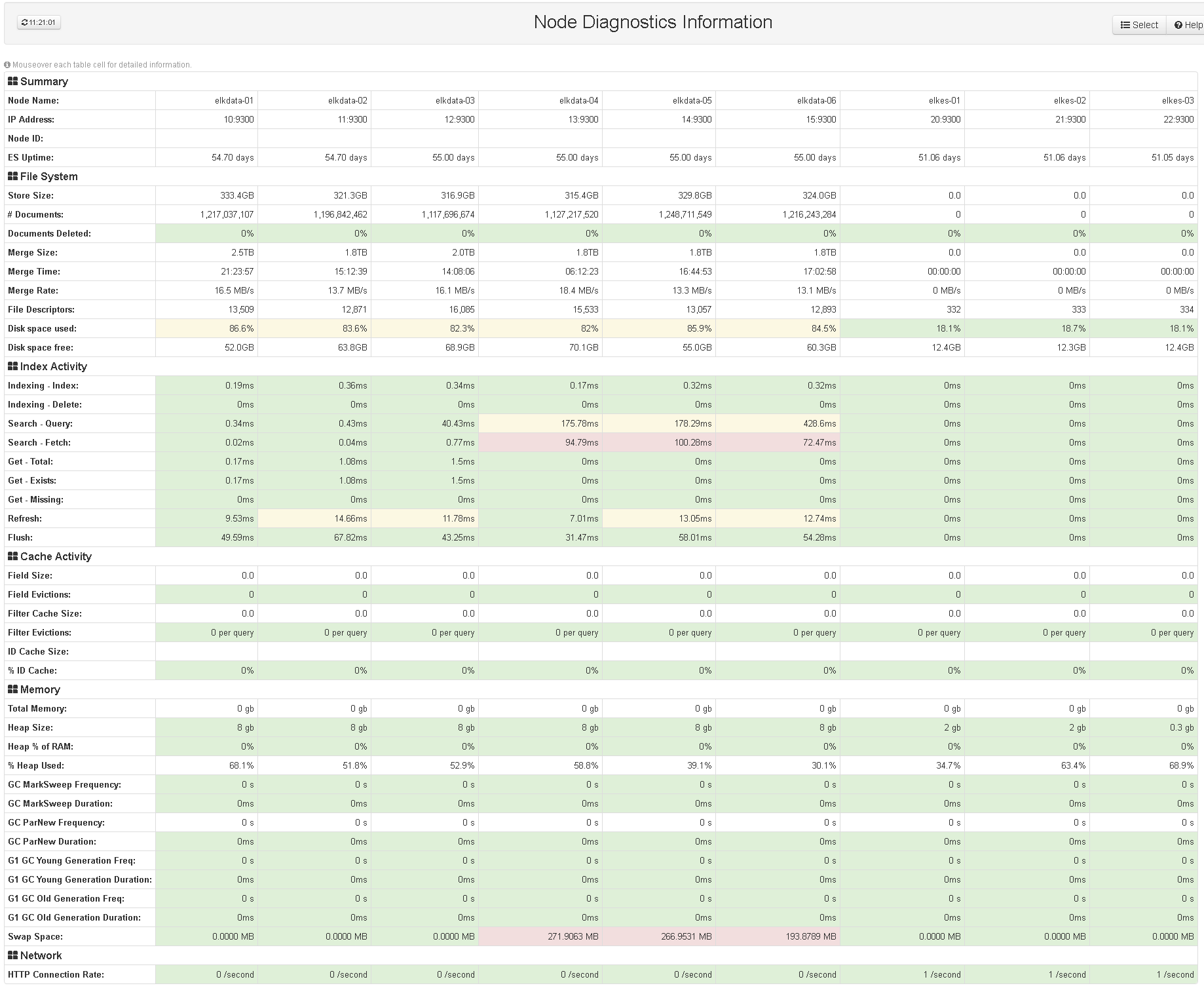
| Количество VM | Назначение | Используемое ПО |
|---|---|---|
| 2 | Балансировщики нагрузки | Keepalived + HAproxy + nginx |
| 4 | Получение и обработка входящих журналов | Logstash |
| 3 | Master-ноды кластера Elasticsearch | Elasticsearch |
| 6 | Data-ноды кластера Elasticsearch | Elasticsearch |
| 1 | Пользовательский интерфейс | Kibana |
Так выглядит архитектура нашей инсталляции ELK:

Реализация
В качестве балансировщиков трафика используются HAproxy и nginx, их отказоустойчивость достигается при помощи keepalived – приложения, реализующего протокол маршрутизации VRRP (Virtual Router Redundancy Protocol). Keepalived настроен в простой конфигурации из master и backup нод, таким образом, входящий трафик приходит на ноду, которой в настоящий момент принадлежит виртуальный IP адрес. Дальнейшая балансировка трафика в Logstash и Elasticsearch осуществляется по алгоритму round-robin (все так же используем простые решения).
Для Logstash и Elasticseach отказоустойчивость достигается избыточностью: система продолжит корректно работать даже в случае выхода из строя нескольких серверов. Подобная схема проста в настройке и позволяет легко масштабировать каждый из установленных компонентов стека.
Сейчас мы используем четыре Logstash сервера, каждый из которых выполняет полный цикл обработки входных данных. В ближайшее время планируем разделить сервера Logstash по ролям Input и Filter, а также добавить кластер RabbitMQ для буферизации данных, отправляемых из Logstash. Использование брокера сообщений позволит исключить риски потери данных в случае разрыва соединения между Logstash и Elasticsearch.
Конфигурация Elasticsearch у нас также проста, мы используем три master ноды и шесть data нод.
Kibana – единственный компонент, который не резервируется, так как выход «кибаны» из строя не влияет на процессы сбора и обработки логов. Для ограничения доступа к консоли используется kibana-auth-plugin, а при помощи плагина Elastic HQ мы можем наблюдать за состоянием кластера Elasticsearch в веб-интерфейсе.
Netflow
Как было отмечено выше, помимо логов, мы собираем статистику Netflow при помощи коробочного плагина logstash. Настроенные представления помогают дежурным администраторам получать актуальные данные о трафике. Для диагностики сетевых проблем это важный инструмент, так как Netflow позволяет получить детальную информацию о потоках трафика внутри сети в тех случаях, когда логов сетевого оборудования недостаточно. На скриншоте ниже видно представление Kibana для Netflow: диаграммы показывают адреса, участвующие в обмене трафиком, и объем принятых/переданных данных.

Контроль событий ИБ
В мае текущего года мы решали задачу прохождения сертификации PCI DSS — стандарту безопасности данных индустрии платежных карт. Одним из требований соответствия данному стандарту является наличие системы контроля событий информационной безопасности. На момент прохождения сертификации стек ELK уже работал и собирал данные с большей части эксплуатируемого оборудования, поэтому было принято решение использовать его в качестве системы контроля событий ИБ. В ходе подготовки к аудиту, для всех системных компонентов Техносерв Cloud была настроена отправка в ELK событий безопасности, в том числе следующих:
• любой доступ к данным заказчиков;
• все действия, совершенные с использованием административных полномочий, на серверах и сетевом оборудовании облачной платформы;
• любой доступ к журналам регистрации событий системных компонентов Техносерв Cloud;
• любой доступ пользователей к системным компонентам платформы;
• добавление, изменение и удаление учетных записей;
• запуск и остановка системных компонентов платформы;
• создание и удаление объектов системного уровня.
Для демонстрации наличия перечисленных выше событий в системе были подготовлены представления Kibana. На скриншотах ниже видны попытки доступа пользователей на наши сервера и записи о выполнении команд из-под sudo.

Зафиксированные неуспешные попытки доступа
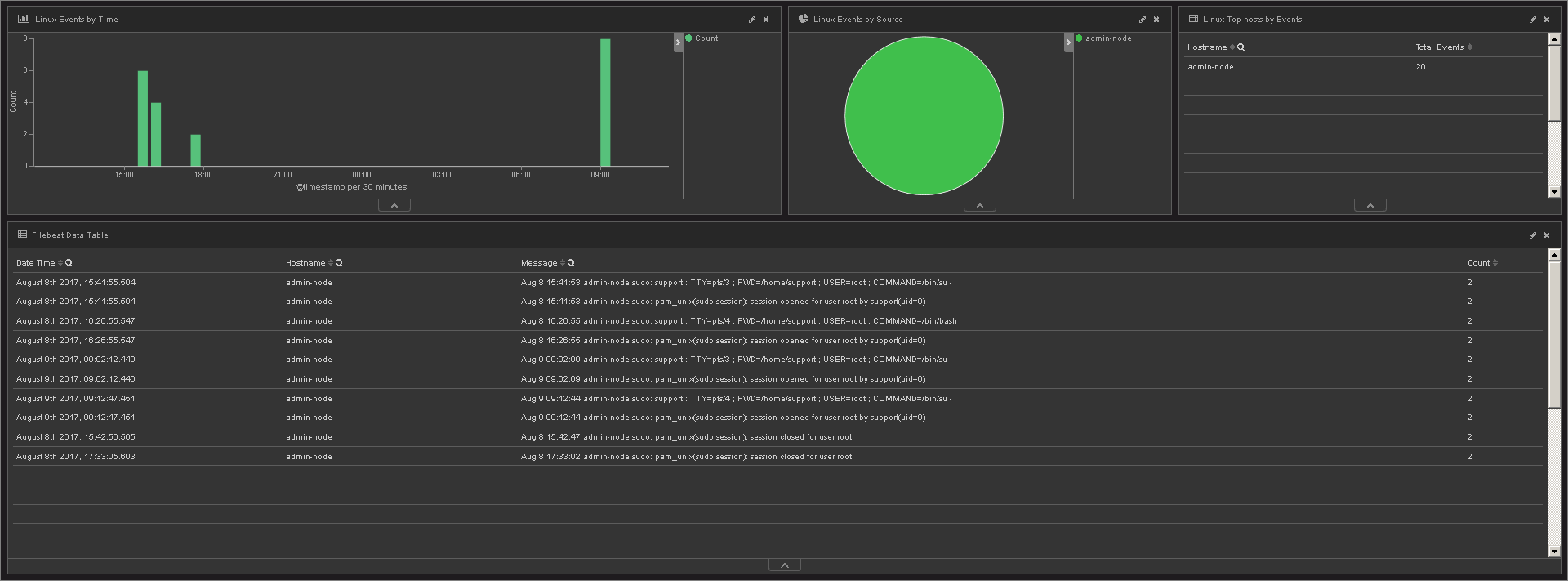
Выполнение команд от имени суперпользователя
Подводя итоги
Централизованная консоль для работы с событиями позволяет эффективно управлять IT инфраструктурой. В нашем случае с ELK мы достигли следующих целей:
• используя единую консоль для работы с записями журналов, сократили время на диагностику проблем и, следовательно, уменьшили время недоступности сервисов;
• с помощью представлений Kibana получили информацию о работе платформы в целом;
• реализовали требования PCI DSS по регистрации и хранению событий безопасности.
Комментарии (14)

Hardened
29.08.2017 16:11Облачное хранилище в заголовке упомянуто для чего? Непонятно какие преимущества для хранения и обработки его логов дал ELK…

acherlyonok
29.08.2017 16:54Может у вас реализована какая-нибудь нотификация в случае возникнования записей с различными level? Например лог запись с level: ERROR/WARNING с уведомлением на email или например slack.

TS_Cloud Автор
29.08.2017 17:10Нотификация настроена по некоторым query, которые мы из Zabbix делаем. Рассылка – в телеграм через бота + почта.
kataklysm
29.08.2017 16:54А почему вы выбрали связку ELK, а не Graylog например? И как вы делаете бекапирование вашей системы?
Спасибо за ответы.
P.S Не ради троллинга.TS_Cloud Автор
29.08.2017 17:32kataklysm, не страшно, даже если ради него)). Резервное копирование мы делаем с помощью elasticdump. Данные планируем хранить глубиной на полгода, потом будем удалять раз в неделю на полгода + неделю, и хранить в архиве. Архивы – раз в неделю глубиной в неделю. (Храним данные в объектном хранилище, о котором писали в предыдущих постах).

amarao
29.08.2017 17:20Я терпеть не могу кибану, но из доступных решений, это единственное, достаточно универсальное. К EL части нареканий меньше, а вот адекватизация кибаны — это острейшая задача. В ней можно сделать всё, но всё, что в ней можно сделать, делается неудобно.
Hixon10
29.08.2017 22:53Можете немного расписать, что именно вам не нравится в кибане? Использую её ежедневно, вроде все мои запросы удовлетворяются.
amarao
30.08.2017 11:00Отсутствие параметризации/шаблонов как в grafana. Например, три типовых поля, по которым мы фильтруем: syslog_hostname, syslog_program и syslog_severity. Я бы хотел их прибить drop box'ами или другими тривиальными элементами управления. Как такое сделать я не нашёл. На выходе — несколько мучительных кликов с раздумием и чтением кучи надписей чтобы сделать очевидное и частое действие.
LighteR
29.08.2017 19:02А почему у вас входными нодами для запросов являются master-ноды, а не coordinating-ноды?
cooper051
Выбор сразу пал на ELK или еще что-то рассматривали?
TS_Cloud Автор
cooper051, да, конечно, мы рассматривали и сравнивали разные системы — и IBM QRadar, и Solarwinds, Splunk, HP ArcSight. В нашем случае (для наших задач) ELK оказался максимально функциональным и соответствующим требованиям к стоимости. При этом мы не рассматриваем ELK как полноценную замену SIEM и сами в перспективе планируем запускать SOС. В данном примере ELK это именно система управления логами.