
В завершающей статье цикла, посвящённого обучению Data Science с нуля, я делился планами совместить мое старое и новое хобби и разместить результат на Хабре. Поскольку прошлые статьи нашли живой отклик у читателей, я решил не откладывать это надолго.
Итак, на протяжении уже нескольких лет я в свободное время копошусь в вопросах, связанных с освещением и больше всего мне интересны спектры разных источников света, как «пращуры» производных от них характеристик. Но не так давно у меня совершенно случайно появилось еще одно хобби — это машинное обучение и анализ данных, в этом вопросе я абсолютный новичок, и чтобы было веселей делюсь периодически с вами своим обретенным опытом и набитыми «шишками»
Данная статья написана в стиле от новичка-новичкам, поэтому опытные читатели вряд ли, почерпнут для себя, что-то новое и если есть желание решить задачу классификации источников света по спектрам, то им есть смысл сразу взять данные из GitHub
А для тех, у кого нет за плечами громадного опыта, я предложу продолжить наше совместное обучение и в этот раз попробовать взяться за составление задачки машинного обучения, что называется «под себя».
Мы пройдем с вами путь от попытки понять где можно применить даже небольшие знания по ML (которые можно получить из базовых книг и курсов), до решения непосредственно самой задачи классификации и мыслей о том «что теперь со всем этим делать?!»
Милости прошу всех под кат.

Итак, коллеги перед нами очень важная миссия выяснить насколько опасен искусственный интеллект пора ли нам уже взрывать «Скайнет» или можно еще немного времени потратить на просмотр роликов с котиками.
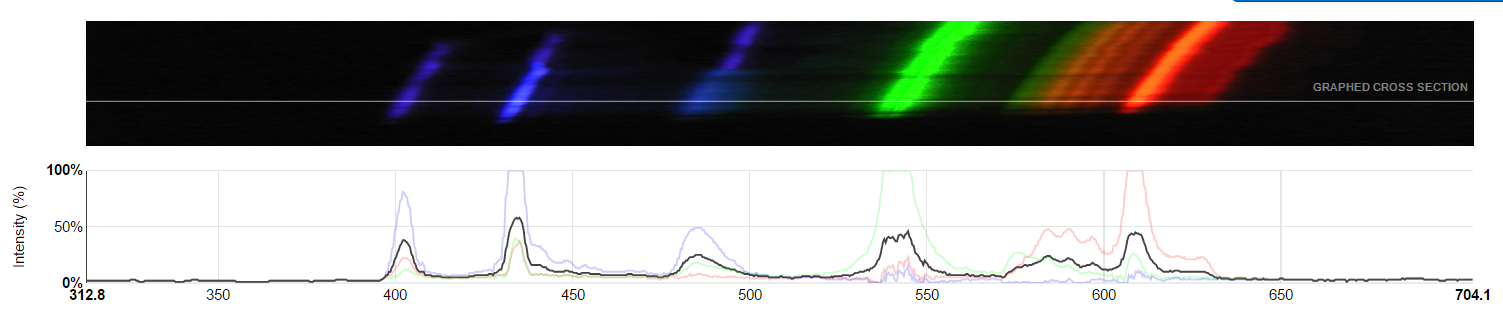
В данной статье мы будем на основании примерно таких картинок определять к какому типу относится лампа: люминесцентная или светодиодная, а может быть и вовсе свет солнца и неба.
Начнем с достаточно важного момента, а именно с требований к навыкам. Как и в предыдущих статьях, я делюсь с вами тем опытом, что успел получить сам и перед началом статьи важно понимать, что она может быть полезна людям со схожим опытом. Как я уже говорил раньше, матерым специалистам материал вряд ли будет полезен.
Хотя они безусловно могут найти какие-то ошибки в нем и рассказать мне об этом, чтобы я по возможности их исправил.
В этот раз для того, чтобы статья не вызвала у вас трудностей нам уже, потребуются некоторые базовые навыки, а именно:
Если вы прошли онлайн курсы или прочитали самоучитель, думаю этого будет вполне достаточно.
Второй важный момент понять зачем мы все это делаем?
Действительно если вы просто хотите потренироваться в анализе данных и решении задач машинного обучения, то существует множество замечательных задач на Kagle, в том числе подходящих для абсолютных новичков (например, про Титаник).
Скорее всего эти задачи будут корректней и в случаях с задачами для новичков вы наверняка найдете более удачные туториалы, чем в нашем случае, поэтому если у вас еще не чешутся руки «придумать свой велосипед», или не хватает навыков, то есть смысл потренироваться на Kagle (об этом я раньше писал).
В книге Data Science from Scratch, ближе к концу автор предлагал не останавливаться на материалах книги и придумать задачу самостоятельно, попутно делясь своими идеями, в тот момент я подумал: «Конечно, ты то вон какой умный, а я понятия не имею что делать!».
На мой взгляд эта мысль была весьма справедлива, потому, что по данной книге тяжело выучить, что-то сильно полезное на практике (подробней об этом в обзоре). Да и в конце концов прежде чем лепить пельмени, наверное, есть смысл их все же попробовать, причем желательно попробовать хорошие, чтобы было к чему стремится.
В Специализации «Машинное обучение и анализ данных», глазами новичка в Data Science» на Coursera (обзор), было что попробовать и на чем набить руку, и уже после ее прохождения появилась уверенность в том, что теперь пусть и не идеально, но уже можно собирать и анализировать данные самостоятельно.
Подводя итог главе хочу сказать, с педагогической точки зрения я считаю ОЧЕНЬ полезным и важным этап самостоятельной постановки задачи для машинного обучения пусть и сугубо «бутафорской». Именно поэтому я решил поделится своим примером с вами.
Давайте обратимся к вопросу откуда брать материал (данные) для наших исследований.
На мой взгляд, сам источник не так важен, главное, чтобы тематика была близка Вам и вы могли найти более менее достаточное количество достоверных данных.
Ну, например:
1. Вы можете классифицировать ваших друзей по текстам сообщений в соц. сетях (кто-то молчун, кто-то часто использует ключевые слова, кто-то ставит кучу смайликов и так далее)
2. Или вы можете на основании прошлых данных (ну, например, квитанций ЖКХ) предсказать, сколько горячей воды или электроэнергии вы потратите в этом ноябре)
3. А можете восстановить зависимость между рейтингом скачанного сериала и количеством «вкусняшек» которые вы съедаете при его просмотре.
4. Если вы очень злой человек, попробуйте решить задачу о количестве кошек у ваших одиноких подруг
5. Если с личным опытом дела обстоят туго и вы не храните архивы в пожелтевших папках посмотрите отечественные (ну или зарубежные) порталы открытых данных data.gov.ru или для Москвы data.mos.ru, ну например можно найти данные, для того, чтобы прогнозировать количество вызовов пожарных в тот или иной округ Москвы в будущем, а потом проверить через пару месяцев.
В нашем случае, мне за данными далеко ходить было не надо. Есть замечательный opensource проект Public Lab, в рамках которого есть подраздел посвящённый анализу спектра источников света.
Два слова про него:
Проект предлагает собрать из подручных средств спектроскоп (ну, например, из картона и DVD болванки) и фотографировать спектры.
После того как вы сделаете кучу снимков спектров, хорошо бы их изучить более детально, для этого у них на сайте есть web интерфейс, который позволяет вам загрузить и немного обработать ваш спектр, чтобы в итоге получить его цифровое представление (например, в виде таблицы).
Все данные находятся в открытом доступе, любой может, как загрузить спектр на портал, так и скачать данные. У этой открытости есть один большой недостаток, который нам нужно будет учесть, но о нем чуть позже (просто решил внести интригу в повествование).
На портале представлено множество снимков, правда важно помнить, что среди снимков не обязательно должны оказаться спектры лампочек, могут быть, например, спектры отражения света от материалов или спектры пропускания света различными жидкостями.
В любом случае у нас есть наглядные открытые данные, которые унифицированы, структурированы и главное их можно загрузить в удобном формате (например, .csv), о чем еще можно мечтать?
(кроме миллиона долларов и личного вертолета)
Рассмотрим данные которые имеем и что же мы хотим в итоге получить.
Здесь и далее я буду ориентироваться на фалы в формате csv
Итак мы имеем распределение мощности излучения (условной) по длине волн спектра (спектральное распределение плотности излучения).
В скачанных с Public Lab данных есть усреднённое значение а также разбитое по каналам R,G,B нас будет волновать только усредненное.
Если совсем упростить описание, то при прохождении через дифракционную решетку или призму свет распадается на радугу и если солнечный свет вам точно даст радугу как в поговорке про фазана, то свет некачественных люминесцентных ламп может быть похож на улыбку хоккеиста Овечкина (безусловно обаятельную, но с некоторыми пробелами).
Вот именно на основании этой структуры радуги мы и будем классифицировать спектры.
Поскольку все алгоритмы и библиотеки для машинного обучения пишут живые люди (пока еще), то во многом они являются формализацией тех вещей, которые мы часто делаем подсознательно при решении тех или иных задач.
С одной стороны, набор данных который я для вас составил очень простой — классы сбалансированы, признаки имеют более менее близкий масштаб, совсем очевидных выбросов нет, поэтому некоторые вещи, которые пишут в учебных материалах я вам на нем продемонстрировать не смогу.
С другой стороны, кто знает может быть мы все роботы? Поэтому я освещу пару моментов, которые важно было бы отметить, так как будто бы мы написали модель для сбора данных вместо того, чтобы делать это в ручную.
Для начала вспомним важные моменты, о которых часто говорят и пишут в учебных материалах:
Знание специфики
В учебных материалах пишут, что для машинного обучения важно владеть знаниями о сфере деятельности, для которой готовим модель. И с этим я полностью согласен, недостаточно знать все алгоритмы и методы, уметь пользоваться библиотеками. Незнание некоторых нюансов может накрыть вашу модель медным тазом и свеcти ее ценность к нулю.
Давайте обратимся к нашему случаю. Помните я говорил о БОЛЬШОМ минусе открытости платформы (при всех её плюсах). Так вот люди могут залить любые фотографии спектров, сделанные на приборах любого качества, а затем их обработать так как им взбредет в голову.
Самый важный момент, который нужно учесть это правильная калибровка спектра.
Механизм такой: вы фотографируете характерный объект (компактную люминесцентную лампу) и на основании него получаете шкалу вашего распределения (на основании двух пиков синего и зеленого цвета).
Звучит не очень сложно, но нужно немного набить руку, во-первых, не все владеют английским языком, во вторых не все любят читать инструкции поэтому, не смотря на то, что сейчас механизм еще упростили (добавив образец), но все равно есть риск наткнутся на неправильно калиброванные спектры. В конце концов спектры могут загружать дети и некоторым из них может быть тяжело разобраться самостоятельно.
Поэтому с одной стороны имеем много просто неоткалиброванных снимков, с другой стороны некоторое количество некорректно калиброванных, что уже намного хуже.
Например, есть фотография под ней есть график вроде более-менее осмысленный (без шума), но естественно это неверная калибровка (бирюзовый цвет должен быть в районе 500 нм, а оранжевый в районе 600 нм.)

Это не самый страшный пример, бывают случаи, где плохая калибровка присутствует, но существенно меньше бросается в глаза, просто я сейчас навскидку их не нашел.
Вторым моментом является, то что мы не знаем в действительности какие спектры (каких ламп), в каких условиях и чем их фотографировали пользователи, поэтому как минимум важно знать, что не стоит доверять данным на 100%. Иногда некоторые спектры вызывают подозрения.
Третий момент, важно помнить о технических ограничениях, в большинстве случаев данная измерительная схема сильно режет спектры в красном диапазоне света, поэтому, например, данные дальше 600 нм. могут оказаться менее достоверными и не факт, что будут соответствовать истинным спектрам. Похожая ситуация и с фиолетовым (ультрафиолетовым) светом.
Четвертый момент, часть излучения на спектрах может быть срезана, из-за высокой яркости снимков, это коверкает данные и иногда это тоже может быть важно. Может есть еще какие-то нюансы, о которых я не вспомнил или не знаю. Итак, не зная даже этих мелочей, можно было бы наделать ошибок при подготовке выборок.
Признаки и отбор данных
Касательно признаков, пусть сила излучения для каждой длинны волны и станет нашим признаком (feature) для будущей модели.
Учитывая сказанное выше становится ясно, что нам для класифкации нет особого смысла брать спектр, в диапазоне, который дает система (иногда чуть ли не от 200 до 1000 нм), возьмем диапазон по уже от 390 до 690 даже это немного избыточно (потому что не везде эти данные есть), но зато ничего значимого потерять мы вроде не должны.
Мы делим признаки с шагом в 1 нм. ну, например, 400, 401, 402… Можно было бы брать и шаг пореже, например, 10 нм., но у нас будет маленькая выборка и даже 301 признак не сильно перегрузит наш компьютер при расчётах. По идее увеличение шага уменьшает точность модели, но и сильное уменьшение шага, например, до 0.25 нм. нам сильно погоды не сделает, а машинные ресурсы съест.
Касательно отбора спектров
Изначально хотел сделать выборки побольше с большим количеством классов, но застопорился, как я говорил раньше не все снимки спектров можно было использовать из-за плохой калибровки, шума или сомнений в достоверности.
Поэтому в итоге мы ограничимся тремя классами: дневной свет (небо, солнце или всё вместе), люминесцентные лампы (и компактные и трубчатые), и светодиодные лампы (белые с люминофором и на основе RGB светодиодов).
Я надеюсь, что все что я вам собрал светит белым светом (различных оттенков и различного качества).
При сборе данных проблему с плохой калибровкой данных для люминесцентных ламп решить было просто, достаточно было откалибровать их самостоятельно. А вот с дневным светом и светодиодными лампами такой трюк не пройдет (там часто гладкий спектр), ну и на тот момент ламп накаливания (откалиброванных) я тоже в достаточном количестве не нашел, но там активно добавляются новые данные если сочтете нужным можете расширить выборку и сделать задачу интересней.
Чтобы было проще в итоге классифицировать я сделал выборку равномерной. В обучающем наборе по 30 записей каждого класса, в контрольной выборке по 11 записей.
И даже несмотря на то что я в конце немного устал и запутался, все же в выборке должны находится примеры разных источников света, разных ламп, разных светодиодов и т.п.
В данном случае я причесал выборку за Вас, но в реальной выборке возможно Вам придется обработать данные самостоятельно.
Еще один момент, касающийся выборки.
Есть в статистике такое понятие как ошибки первого рода и второго рода. В очень упрощенном изложении: Вы выдвигаете гипотезу о том, что в туалете есть бумага, а значит не берете ее с собой, так вот если в этой ситуации вы подстрахуетесь и напрасно прихватите с собой рулончик (ложное срабатывание – ошибка первого рода), то это не так страшно, как если вы рулончик не прихватите, а там будет только картонное колечко (ошибка второго рода).
Так вот, при выборе данных я старался минимизировать ошибку второго рода, нам было не очень страшно пропустить нормальный спектр, а вот случайно взять в выборку ошибочный спектр явно не то что нам надо.
Зато при решении непосредственно задачи классификации у нас любая из ошибок не имеет большего приоритета, при решении непосредственно задачи моделью нам важно чтобы абсолютно все было предсказано правильно и без перестраховок.
Именно этим и определяется достаточность метрики accuracy.
Ну что текста было много, давайте уже наконец перейдем по ближе к модели.
По адресу https://github.com/bosonbeard/ML_-spectrum_classification размещены:
Я подразумеваю, что у вас уже есть базовые знания и вам их будет достаточно, чтобы понять мой далекий от эталонного код.
Импортируем библиотеки:
Прочитаем данные:
В данном случае мы используем библиотеку pandas и ее класс dataframe, который если говорить совсем упрощенно дает нам те функции, которые дал бы Excel, то есть работу с таблицами.
Как я уже говорил раньше, в таблице 391 столбец соответствующий мощности излучения по длинам волн, а последний столбец это метка класса: 0 – СИД, 1 – люм. лампы. 2 – дневной свет.
Для дальнейшей работы сразу вырежем 391 столбец с признаками и последние столбцы с метками в отдельные переменные.
В нормальных работах обычно дальше идет достойный анализ исходных данных, но у нас особо нечего анализировать, как я уже говорил все классы сбалансированы и в принципе не сильно нуждаются в дополнительном масштабировании (хотя можете ради любопытства отмасштабировать).
Для проформы я вывел 2 графика, вы если хотите можете сделать что-нибудь еще.
Классификация
Построим нашу первую модель. Возьмём одну из самых популярных моделей – модель случайный лес (решающих деревьев).
Посмотрим результаты.
(предсказанные, фактические):
(2, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (1, 0), (0, 0), (2, 0), (2, 0), (2, 0), (1, 1), (1, 1), (1, 1), (1, 1), (0, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)
Точность предсказание (доля правильных ответов) = 0.8181818181818182
Получается мы можем надеется, что наша модель будет 8 из 10 спектров правильно классифицировать, что уже хорошо.
Для демонстрации, параметры этой модели мы специально взяли не самые лучшие, давайте попробуем перебрать модели с разными параметрами и выбрать лучшую по результатам перекрестной проверки.
Получаем следующие параметры:
{'max_depth': 6, 'n_estimators': 30} 0.766666666667
best accuracy on cv: 0.77
accuracy on test data: 0.87879
best params: {'max_depth': 6, 'n_estimators': 30}
(предсказанные, фактические):
[(0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (2, 0), (2, 0), (2, 0), (1, 1), (1, 1), (1, 1), (1, 1), (0, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)]
Wall time: 1min 6s
То есть увеличение max_depth на 1 повышает точность на 6%, что уже неплохо, при этом несмотря на то что модель числом деревьев (n_estimators), как «кашу маслом не испортишь», модель решила, что дальше увеличивать их число не стоит (это экономит ресурсы).
Я думаю можно добиться и лучших результатов если поискать больше параметров (или увеличить размер выборки), но в целях демонстрации чтобы расчёт сильно много времени не занимал, мы ограничимся тем что есть.
Итак, мы с вами можно так сказать начали с нашего более совершенного Т-1000, давайте попробуем заставить что-то классифицировать нашего «железного Арни» в качестве которого выступит более простая модель логистической регрессии (Logistic Regression).
Как и следовало ожидать, более простая модель с первого подхода дала результат немного хуже.
results (predict, real):
[(0, 0), (0, 0), (0, 0), (2, 0), (0, 0), (0, 0), (0, 0), (2, 0), (0, 0), (0, 0), (2, 0), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 2), (2, 2), (2, 2), (0, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)]
accuracy score= 0.7878787878787878
Можем опять поиграться с параметрами:
Результаты:
best accuracy on cv: 0.79
accuracy on test data: 0.81818
best params: {'C': 0.02, 'penalty': 'l1'}
(предсказанные, фактические):
[(0, 0), (0, 0), (0, 0), (2, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (2, 0), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 2), (2, 2), (2, 2), (0, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)]
Wall time: 718 ms
Итак, мы добились качества сопоставимого с Random forest без подгонки параметров, а вот времени мы затратили существенно меньше. Видно именно поэтому в книгах пишут, что логистическую регрессию часто используют на предварительных этапах, когда важно выявить общие закономерности, а 5-7% погоды сразу не сделают.
С одной стороны, на этом можно было бы и закончить, но давайте еще попробуем представить, что я как бесчестный человек дал вам данные без какого-либо описания и вам надо попробовать что-то понять, не имея меток классов.
Кластеризация
Для наглядности зададим цвета. Я все же немного лукавил, по-хорошему «мы не знаем» что классов у нас не больше трех, но мы же на самом то деле знаем, поэтому ограничимся тремя цветами.
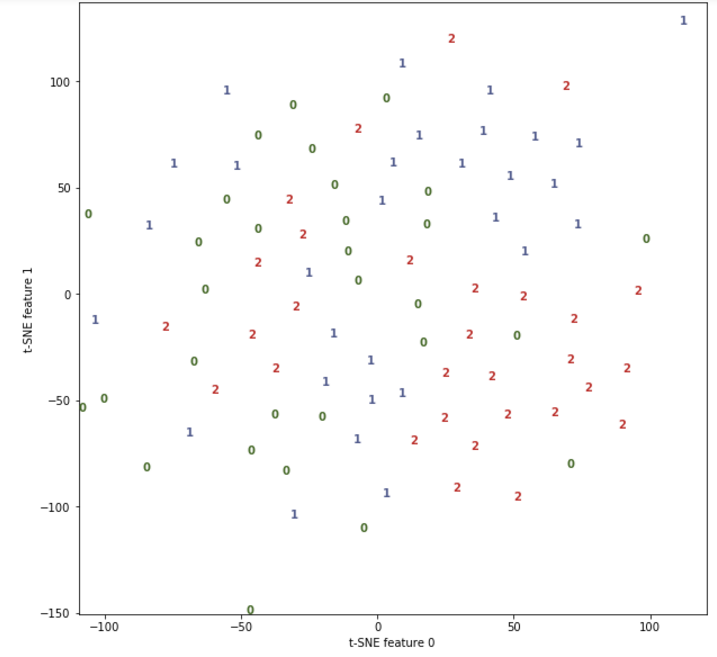
Для начала попробуем посмотреть на наши данные, у нас почти 400 признаков и на двухмерном листе бумаги их все наверное не смогут отобразить даже великие маги и волшебники Амаяк Акопян и Гарри Поттер, но слава богу у нас есть магия специальных библиотек.
Для начала воспользуемся популярным алгоритмом T-SNE (кому любопытно, что это, можно почитать тут).
Нам главное, что алгоритм отображает наши данные в двухмерной плоскости и если в реальности данные хорошо разделимы, то и в двухмерном виде тоже будут хорошо разделимы (можно будет линии прочертить и точно кучки разделить).
У нас к сожалению, не все так хорошо. Где-то данные кучкуются, но где-то и перемешиваются.
И в принципе это нормально, опять же мы же с вами знаем специфику вопроса, а значит догадываемся о том, что если лампы хорошие, то по своему свету они будут похожи на настоящий дневной свет, а значит и данные тяжело разделить.
Для подстраховки посмотрим на результаты алгоритма PCA (подробней тут).
Результаты похожи.

Ну а теперь займемся непосредственной кластеризацией, много есть алгоритмов, но мы для данного примера воспользуемся алгоритмом DBSCAN (подробности).
Данный алгоритм не требует задавать начальное количество классов и в некоторых случаях позволяет неплохо угадать, но забегая вперед мы же помним картинки сверху? В нашем случае это будет трудно. Вот вариант DBSCAN который находит три класса (можно 2 или 4).
Affiliation to clusters:
[-1 -1 0 -1 -1 0 0 -1 1 1 -1 2 2 -1 -1 -1 -1 -1 2 -1 2 -1 -1 1 -1
-1 1 1 1 -1 1 -1 1]
результаты (кластеризация, факт):
[(-1, 0), (-1, 0), (0, 0), (-1, 0), (-1, 0), (0, 0), (0, 0), (-1, 0), (1, 0), (1, 0), (-1, 0), (2, 1), (2, 1), (-1, 1), (-1, 1), (-1, 1), (-1, 1), (-1, 1), (2, 1), (-1, 1), (2, 1), (-1, 1), (-1, 2), (1, 2), (-1, 2), (-1, 2), (1, 2), (1, 2), (1, 2), (-1, 2), (1, 2), (-1, 2), (1, 2)]
accuracy_score:
0.0909090909091
Получаем ужасное значение точности около 9%. Что-то не так! Конечно, DBSCAN не знает какие метки мы давали классам, поэтому в нашем случае 1 это 2 и наоборот (a -1 это шум).
Меняем метки классов и получаем:
результаты (кластеризация, факт):
[(-1, 0), (-1, 0), (0, 0), (-1, 0), (-1, 0), (0, 0), (0, 0), (-1, 0), (2, 0), (2, 0), (-1, 0), (1, 1), (1, 1), (-1, 1), (-1, 1), (-1, 1), (-1, 1), (-1, 1), (1, 1), (-1, 1), (1, 1), (-1, 1), (-1, 2), (2, 2), (-1, 2), (-1, 2), (2, 2), (2, 2), (2, 2), (-1, 2), (2, 2), (-1, 2), (2, 2)]
accuracy_score:
0.393939393939
Другое дело, уже 39% что все равно лучше, чем если бы мы классифицировали случайным способом. Вот и все машинное обучение, но для терпеливых людей в конце статьи будет bonus.
Ну вот мы и прошли с вами нелегкий путь от постановки задачи до ее решения, подтвердили на практике некоторые истинны, которые встречаются в учебниках по Data Science.
На самом деле нам не обязательно было классифицировать именно по спектральному распределению, можно было и взять производные признаки, например, индекс цветопередачи и цветовую температуру, но это вы если захотите сделаете самостоятельно.
Также безусловно есть смысл добавить еще данных в обучающую и тестовую выборку, так как от этого весьма сильно зависит качество обучения модели (по крайней мере в данном случае разница между выборкой в 20 и 30 семплов была существенная).
Что же вам делать со своими исследованиями, когда вы их проведете? Ну во-первых, вы можете написать статью на Хабр :)
А можете и не ограничиваться Хабром, помню 4 года назад я писал статью, «Как перестать быть «блогером» и почувствовать себя «ученым».
Смысл ее заключался в том, что можно и не останавливаться на достигнутом, как правило если вы в состоянии написать статью на Хабр, то можете и написать в какой-нибудь научный журнал.
Зачем? Да просто потому что можете! Данная ситуация похожа на игру футбол, в РФПЛ человек 200 отечественных футболистов (это с потолка, но думаю не сильно больше), за границей наших играет и того меньше, но зато в целом в футбол по всей стране играет намного больше народа.
Ведь есть любительские лиги. Любители не получают зарплату, а играют часто ради удовольствия. Так и тут я предлагаю вам поиграть в «любительской» научной лиге.
В нашем случае, если у вас нет доступа к стоящим международным журналам, или хотя бы ВАКовским, не расстраивайтесь, даже после обвала РИНЦ есть места где вашу хорошую статью вполне примут, при соблюдении формальностей и научного стиля изложения например, на одной из конференций, входящих в РИНЦ, это как правило удовольствие платное, но весьма бюджетное.
Еще полезней будет участие в очной конференции, где вам придется отстоять живьем свою идею.
Кто знает может быть вы однажды набьете руку войдете во вкус и станете нашей новой надеждой человечества.
Есть и другое применение вашим талантам, можете анализировать данные бюджетных структур и участвовать в общественном контроле, наверняка если копнуть по глубже, то найдутся очевидные косяки в отчётности нечестных людей и организаций, и вы сможете сделать наш дом лучше (или нет)
А может быть вы найдете еще какое-то замечательное применение вашему хобби и обернете его в доход, все в ваших руках.
Вам не кажется, что в статье осталась небольшая недосказанность? Чего-то не хватает? Ну конечно надо провести эпичную битву человек-машина!
Посмотрим кто лучше классифицирует спектры.
Поскольку у меня нет этого волшебного кота, который все угадывает, придется все делать самому.

Напишем для этого небольшую функцию. И построим графики по которым я буду предсказывать.
Прим. за качество кода не ручаюсь
Вот кстати вам еще одна отсылка к сравнению человек-машина из 2-й главы. Честно признаюсь обычно я определяю спектры имея под рукой и фотографию спектра и сам график и тогда точность переваливает за 90 и близится к 100%, но нашей модели мы картинки спектров не давали, а значит нам придется быть с ней в равных условиях.
Данная ситуация чем-то похожа на ту, когда вы обучаете модель на одном наборе признаков, а потом в реальных данных (или контрольных) часть признаков отсутствует и прогнозирующая сила модели сильно снижается (снизилась и моя).
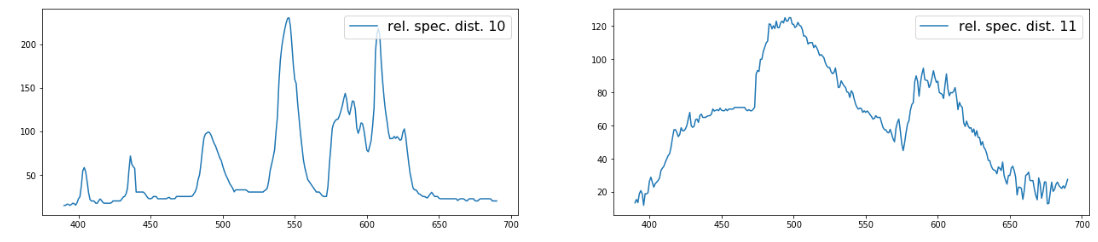
И так поверьте мне на слово (или запустите. ipynb файл с GitHub) у нас получается 33 графика из контрольной выборки, примерно таких:
Потом вводим вручную прогноз, возвращаем соответствие порядка меток и смотрим, что получилось.
Результат (мой прогноз, факт.):
[(0.0, 0), (0.0, 0), (0.0, 0), (1.0, 0), (0.0, 0), (0.0, 0), (0.0, 0), (0.0, 0), (0.0, 0), (0.0, 0), (0.0, 0), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (0.0, 2), (2.0, 2), (2.0, 2), (2.0, 2), (2.0, 2), (2.0, 2), (0.0, 2), (0.0, 2), (2.0, 2), (2.0, 2), (0.0, 2)]
accuracy score= 0.8484848484848485
Безусловно я ангажирован, как минимум потому что я знаю, что в контрольной выборке не больше 11 меток каждого класса, но я старался не жульничать.
Итак, в моей первой попытке получилось 84% с небольшим, что-то среднее между логистической регрессией и Random Forest, причем компьютер обошел меня в последней позиции.
Помните вначале статьи я упоминал, что часть спектров может быть срезана? Меня именно это и подвело, без фотографии я это не заметил и неправильно классифицировал срезанный спектр только по графику, а вот компьютер справился и получил свои 87%.
Если учесть, что я этому навыку определения спектров на глазок посветил не один день, а модель обучалась минуту с небольшим, то возможно уже пора боятся восстания машин?

Итак, на протяжении уже нескольких лет я в свободное время копошусь в вопросах, связанных с освещением и больше всего мне интересны спектры разных источников света, как «пращуры» производных от них характеристик. Но не так давно у меня совершенно случайно появилось еще одно хобби — это машинное обучение и анализ данных, в этом вопросе я абсолютный новичок, и чтобы было веселей делюсь периодически с вами своим обретенным опытом и набитыми «шишками»
Данная статья написана в стиле от новичка-новичкам, поэтому опытные читатели вряд ли, почерпнут для себя, что-то новое и если есть желание решить задачу классификации источников света по спектрам, то им есть смысл сразу взять данные из GitHub
А для тех, у кого нет за плечами громадного опыта, я предложу продолжить наше совместное обучение и в этот раз попробовать взяться за составление задачки машинного обучения, что называется «под себя».
Мы пройдем с вами путь от попытки понять где можно применить даже небольшие знания по ML (которые можно получить из базовых книг и курсов), до решения непосредственно самой задачи классификации и мыслей о том «что теперь со всем этим делать?!»
Милости прошу всех под кат.
Итак, коллеги перед нами очень важная миссия выяснить насколько опасен искусственный интеллект пора ли нам уже взрывать «Скайнет» или можно еще немного времени потратить на просмотр роликов с котиками.
В данной статье мы будем на основании примерно таких картинок определять к какому типу относится лампа: люминесцентная или светодиодная, а может быть и вовсе свет солнца и неба.
Часть 1. Брифинг
Начнем с достаточно важного момента, а именно с требований к навыкам. Как и в предыдущих статьях, я делюсь с вами тем опытом, что успел получить сам и перед началом статьи важно понимать, что она может быть полезна людям со схожим опытом. Как я уже говорил раньше, матерым специалистам материал вряд ли будет полезен.
Хотя они безусловно могут найти какие-то ошибки в нем и рассказать мне об этом, чтобы я по возможности их исправил.
В этот раз для того, чтобы статья не вызвала у вас трудностей нам уже, потребуются некоторые базовые навыки, а именно:
- Понимание, что такое Data Science и зачем оно нужно
- Минимальные навыки программирования на Python
Если вы прошли онлайн курсы или прочитали самоучитель, думаю этого будет вполне достаточно.
Второй важный момент понять зачем мы все это делаем?
Действительно если вы просто хотите потренироваться в анализе данных и решении задач машинного обучения, то существует множество замечательных задач на Kagle, в том числе подходящих для абсолютных новичков (например, про Титаник).
Скорее всего эти задачи будут корректней и в случаях с задачами для новичков вы наверняка найдете более удачные туториалы, чем в нашем случае, поэтому если у вас еще не чешутся руки «придумать свой велосипед», или не хватает навыков, то есть смысл потренироваться на Kagle (об этом я раньше писал).
В книге Data Science from Scratch, ближе к концу автор предлагал не останавливаться на материалах книги и придумать задачу самостоятельно, попутно делясь своими идеями, в тот момент я подумал: «Конечно, ты то вон какой умный, а я понятия не имею что делать!».
На мой взгляд эта мысль была весьма справедлива, потому, что по данной книге тяжело выучить, что-то сильно полезное на практике (подробней об этом в обзоре). Да и в конце концов прежде чем лепить пельмени, наверное, есть смысл их все же попробовать, причем желательно попробовать хорошие, чтобы было к чему стремится.
В Специализации «Машинное обучение и анализ данных», глазами новичка в Data Science» на Coursera (обзор), было что попробовать и на чем набить руку, и уже после ее прохождения появилась уверенность в том, что теперь пусть и не идеально, но уже можно собирать и анализировать данные самостоятельно.
Подводя итог главе хочу сказать, с педагогической точки зрения я считаю ОЧЕНЬ полезным и важным этап самостоятельной постановки задачи для машинного обучения пусть и сугубо «бутафорской». Именно поэтому я решил поделится своим примером с вами.
Часть 2. Не учите жить помогите материально.
Давайте обратимся к вопросу откуда брать материал (данные) для наших исследований.
На мой взгляд, сам источник не так важен, главное, чтобы тематика была близка Вам и вы могли найти более менее достаточное количество достоверных данных.
Ну, например:
1. Вы можете классифицировать ваших друзей по текстам сообщений в соц. сетях (кто-то молчун, кто-то часто использует ключевые слова, кто-то ставит кучу смайликов и так далее)
2. Или вы можете на основании прошлых данных (ну, например, квитанций ЖКХ) предсказать, сколько горячей воды или электроэнергии вы потратите в этом ноябре)
3. А можете восстановить зависимость между рейтингом скачанного сериала и количеством «вкусняшек» которые вы съедаете при его просмотре.
4. Если вы очень злой человек, попробуйте решить задачу о количестве кошек у ваших одиноких подруг
5. Если с личным опытом дела обстоят туго и вы не храните архивы в пожелтевших папках посмотрите отечественные (ну или зарубежные) порталы открытых данных data.gov.ru или для Москвы data.mos.ru, ну например можно найти данные, для того, чтобы прогнозировать количество вызовов пожарных в тот или иной округ Москвы в будущем, а потом проверить через пару месяцев.
В нашем случае, мне за данными далеко ходить было не надо. Есть замечательный opensource проект Public Lab, в рамках которого есть подраздел посвящённый анализу спектра источников света.
Два слова про него:
Проект предлагает собрать из подручных средств спектроскоп (ну, например, из картона и DVD болванки) и фотографировать спектры.
После того как вы сделаете кучу снимков спектров, хорошо бы их изучить более детально, для этого у них на сайте есть web интерфейс, который позволяет вам загрузить и немного обработать ваш спектр, чтобы в итоге получить его цифровое представление (например, в виде таблицы).
Все данные находятся в открытом доступе, любой может, как загрузить спектр на портал, так и скачать данные. У этой открытости есть один большой недостаток, который нам нужно будет учесть, но о нем чуть позже (просто решил внести интригу в повествование).
На портале представлено множество снимков, правда важно помнить, что среди снимков не обязательно должны оказаться спектры лампочек, могут быть, например, спектры отражения света от материалов или спектры пропускания света различными жидкостями.
В любом случае у нас есть наглядные открытые данные, которые унифицированы, структурированы и главное их можно загрузить в удобном формате (например, .csv), о чем еще можно мечтать?
(кроме миллиона долларов и личного вертолета)
Часть 3. Ты должен думать, как машина, жить как машина, ты сам должен стать машиной!
Рассмотрим данные которые имеем и что же мы хотим в итоге получить.
Здесь и далее я буду ориентироваться на фалы в формате csv
Итак мы имеем распределение мощности излучения (условной) по длине волн спектра (спектральное распределение плотности излучения).
В скачанных с Public Lab данных есть усреднённое значение а также разбитое по каналам R,G,B нас будет волновать только усредненное.
Если совсем упростить описание, то при прохождении через дифракционную решетку или призму свет распадается на радугу и если солнечный свет вам точно даст радугу как в поговорке про фазана, то свет некачественных люминесцентных ламп может быть похож на улыбку хоккеиста Овечкина (безусловно обаятельную, но с некоторыми пробелами).
Вот именно на основании этой структуры радуги мы и будем классифицировать спектры.
Поскольку все алгоритмы и библиотеки для машинного обучения пишут живые люди (пока еще), то во многом они являются формализацией тех вещей, которые мы часто делаем подсознательно при решении тех или иных задач.
С одной стороны, набор данных который я для вас составил очень простой — классы сбалансированы, признаки имеют более менее близкий масштаб, совсем очевидных выбросов нет, поэтому некоторые вещи, которые пишут в учебных материалах я вам на нем продемонстрировать не смогу.
С другой стороны, кто знает может быть мы все роботы? Поэтому я освещу пару моментов, которые важно было бы отметить, так как будто бы мы написали модель для сбора данных вместо того, чтобы делать это в ручную.
Для начала вспомним важные моменты, о которых часто говорят и пишут в учебных материалах:
Знание специфики
В учебных материалах пишут, что для машинного обучения важно владеть знаниями о сфере деятельности, для которой готовим модель. И с этим я полностью согласен, недостаточно знать все алгоритмы и методы, уметь пользоваться библиотеками. Незнание некоторых нюансов может накрыть вашу модель медным тазом и свеcти ее ценность к нулю.
Давайте обратимся к нашему случаю. Помните я говорил о БОЛЬШОМ минусе открытости платформы (при всех её плюсах). Так вот люди могут залить любые фотографии спектров, сделанные на приборах любого качества, а затем их обработать так как им взбредет в голову.
Самый важный момент, который нужно учесть это правильная калибровка спектра.
Механизм такой: вы фотографируете характерный объект (компактную люминесцентную лампу) и на основании него получаете шкалу вашего распределения (на основании двух пиков синего и зеленого цвета).
Звучит не очень сложно, но нужно немного набить руку, во-первых, не все владеют английским языком, во вторых не все любят читать инструкции поэтому, не смотря на то, что сейчас механизм еще упростили (добавив образец), но все равно есть риск наткнутся на неправильно калиброванные спектры. В конце концов спектры могут загружать дети и некоторым из них может быть тяжело разобраться самостоятельно.
Поэтому с одной стороны имеем много просто неоткалиброванных снимков, с другой стороны некоторое количество некорректно калиброванных, что уже намного хуже.
Например, есть фотография под ней есть график вроде более-менее осмысленный (без шума), но естественно это неверная калибровка (бирюзовый цвет должен быть в районе 500 нм, а оранжевый в районе 600 нм.)
Это не самый страшный пример, бывают случаи, где плохая калибровка присутствует, но существенно меньше бросается в глаза, просто я сейчас навскидку их не нашел.
Вторым моментом является, то что мы не знаем в действительности какие спектры (каких ламп), в каких условиях и чем их фотографировали пользователи, поэтому как минимум важно знать, что не стоит доверять данным на 100%. Иногда некоторые спектры вызывают подозрения.
Третий момент, важно помнить о технических ограничениях, в большинстве случаев данная измерительная схема сильно режет спектры в красном диапазоне света, поэтому, например, данные дальше 600 нм. могут оказаться менее достоверными и не факт, что будут соответствовать истинным спектрам. Похожая ситуация и с фиолетовым (ультрафиолетовым) светом.
Четвертый момент, часть излучения на спектрах может быть срезана, из-за высокой яркости снимков, это коверкает данные и иногда это тоже может быть важно. Может есть еще какие-то нюансы, о которых я не вспомнил или не знаю. Итак, не зная даже этих мелочей, можно было бы наделать ошибок при подготовке выборок.
Признаки и отбор данных
Касательно признаков, пусть сила излучения для каждой длинны волны и станет нашим признаком (feature) для будущей модели.
Учитывая сказанное выше становится ясно, что нам для класифкации нет особого смысла брать спектр, в диапазоне, который дает система (иногда чуть ли не от 200 до 1000 нм), возьмем диапазон по уже от 390 до 690 даже это немного избыточно (потому что не везде эти данные есть), но зато ничего значимого потерять мы вроде не должны.
Мы делим признаки с шагом в 1 нм. ну, например, 400, 401, 402… Можно было бы брать и шаг пореже, например, 10 нм., но у нас будет маленькая выборка и даже 301 признак не сильно перегрузит наш компьютер при расчётах. По идее увеличение шага уменьшает точность модели, но и сильное уменьшение шага, например, до 0.25 нм. нам сильно погоды не сделает, а машинные ресурсы съест.
Касательно отбора спектров
Изначально хотел сделать выборки побольше с большим количеством классов, но застопорился, как я говорил раньше не все снимки спектров можно было использовать из-за плохой калибровки, шума или сомнений в достоверности.
Поэтому в итоге мы ограничимся тремя классами: дневной свет (небо, солнце или всё вместе), люминесцентные лампы (и компактные и трубчатые), и светодиодные лампы (белые с люминофором и на основе RGB светодиодов).
Я надеюсь, что все что я вам собрал светит белым светом (различных оттенков и различного качества).
При сборе данных проблему с плохой калибровкой данных для люминесцентных ламп решить было просто, достаточно было откалибровать их самостоятельно. А вот с дневным светом и светодиодными лампами такой трюк не пройдет (там часто гладкий спектр), ну и на тот момент ламп накаливания (откалиброванных) я тоже в достаточном количестве не нашел, но там активно добавляются новые данные если сочтете нужным можете расширить выборку и сделать задачу интересней.
Чтобы было проще в итоге классифицировать я сделал выборку равномерной. В обучающем наборе по 30 записей каждого класса, в контрольной выборке по 11 записей.
И даже несмотря на то что я в конце немного устал и запутался, все же в выборке должны находится примеры разных источников света, разных ламп, разных светодиодов и т.п.
В данном случае я причесал выборку за Вас, но в реальной выборке возможно Вам придется обработать данные самостоятельно.
Еще один момент, касающийся выборки.
Есть в статистике такое понятие как ошибки первого рода и второго рода. В очень упрощенном изложении: Вы выдвигаете гипотезу о том, что в туалете есть бумага, а значит не берете ее с собой, так вот если в этой ситуации вы подстрахуетесь и напрасно прихватите с собой рулончик (ложное срабатывание – ошибка первого рода), то это не так страшно, как если вы рулончик не прихватите, а там будет только картонное колечко (ошибка второго рода).
Так вот, при выборе данных я старался минимизировать ошибку второго рода, нам было не очень страшно пропустить нормальный спектр, а вот случайно взять в выборку ошибочный спектр явно не то что нам надо.
Зато при решении непосредственно задачи классификации у нас любая из ошибок не имеет большего приоритета, при решении непосредственно задачи моделью нам важно чтобы абсолютно все было предсказано правильно и без перестраховок.
Именно этим и определяется достаточность метрики accuracy.
Часть 4. Т-800 и Т-1000
Ну что текста было много, давайте уже наконец перейдем по ближе к модели.
По адресу https://github.com/bosonbeard/ML_-spectrum_classification размещены:
- Файл обучающей выборки train.csv
- Файл контрольной выборки test.csv
- Два документа с именами файлов (вырезанные столбцы), они вам пригодятся если вы захотите меня и себя проверить, то может просто взять название файла подставив его к ссылке, например, spectralworkbench.org/spectrums/9740 (где 9740 — номер файла)
- И файл spectrum_classify_for_habrahabr.ipynb в котором представлен целиком, код, который мы сейчас с вами рассмотрим.
Я подразумеваю, что у вас уже есть базовые знания и вам их будет достаточно, чтобы понять мой далекий от эталонного код.
Импортируем библиотеки:
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sklearn.cluster import DBSCAN
from sklearn.metrics import accuracy_score
from IPython.display import display
%matplotlib inline
Прочитаем данные:
#reading data
train_df=pd.read_csv('train.csv',index_col=0)
test_df=pd.read_csv('test.csv',index_col=0)
print('train shape {0}, test shape {1}]'. format(train_df.shape, test_df.shape))
#divide the data and labels
X_train=np.array(train_df.iloc[:,:-1])
X_test=np.array(test_df.iloc[:,:-1])
y_train=np.array(train_df['label'])
y_test=np.array(test_df['label'])
В данном случае мы используем библиотеку pandas и ее класс dataframe, который если говорить совсем упрощенно дает нам те функции, которые дал бы Excel, то есть работу с таблицами.
Как я уже говорил раньше, в таблице 391 столбец соответствующий мощности излучения по длинам волн, а последний столбец это метка класса: 0 – СИД, 1 – люм. лампы. 2 – дневной свет.
Для дальнейшей работы сразу вырежем 391 столбец с признаками и последние столбцы с метками в отдельные переменные.
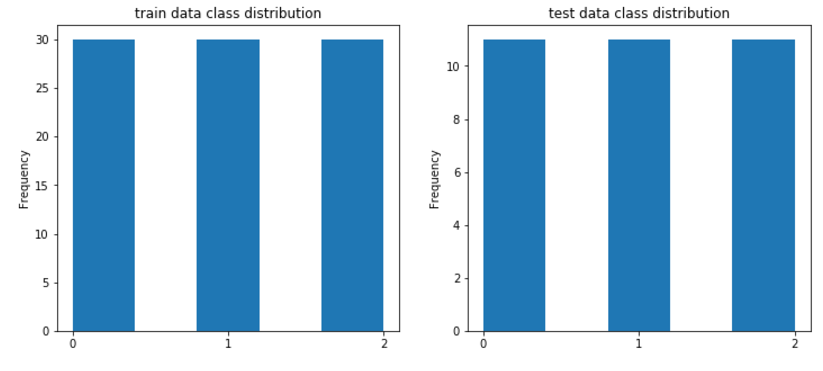
В нормальных работах обычно дальше идет достойный анализ исходных данных, но у нас особо нечего анализировать, как я уже говорил все классы сбалансированы и в принципе не сильно нуждаются в дополнительном масштабировании (хотя можете ради любопытства отмасштабировать).
#draw classdistributions
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12,5))
train_df.label.plot.hist(ax=axes[0],title='train data class distribution', bins=5,xticks=np.unique(train_df.label.values))
test_df.label.plot.hist(ax=axes[1],title='test data class distribution',bins=5,xticks=np.unique(test_df.label.values))
Для проформы я вывел 2 графика, вы если хотите можете сделать что-нибудь еще.
Классификация
Построим нашу первую модель. Возьмём одну из самых популярных моделей – модель случайный лес (решающих деревьев).
rfc = RandomForestClassifier(n_estimators=30, max_depth=5, random_state=42, n_jobs=-1)
rfc.fit(X_train, y_train)
pred_rfc=rfc.predict(X_test)
print("results (predict, real): \n",list(zip(pred_rfc,y_test)))
print("accuracy score= {0}".format(rfc.score(X_test,y_test)))
Посмотрим результаты.
(предсказанные, фактические):
(2, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (1, 0), (0, 0), (2, 0), (2, 0), (2, 0), (1, 1), (1, 1), (1, 1), (1, 1), (0, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)
Точность предсказание (доля правильных ответов) = 0.8181818181818182
Получается мы можем надеется, что наша модель будет 8 из 10 спектров правильно классифицировать, что уже хорошо.
Для демонстрации, параметры этой модели мы специально взяли не самые лучшие, давайте попробуем перебрать модели с разными параметрами и выбрать лучшую по результатам перекрестной проверки.
%%time
param_grid = {'n_estimators':[10, 20, 30, 40, 50], 'max_depth':[4,5,6,7,8]}
grid_search_rfc = GridSearchCV(RandomForestClassifier(random_state=42,n_jobs=-1), param_grid, cv=7)
grid_search_rfc.fit(X_train, y_train)
print(grid_search_rfc.best_params_,grid_search_rfc.best_score_)
print("best accuracy on cv: {:.2f}".format(grid_search_rfc.best_score_))
print("accuracy on test data: {:.5f}".format(grid_search_rfc.score(X_test, y_test)))
print("best params: {}".format(grid_search_rfc.best_params_))
print("results (predict, real): \n",list(zip(grid_search_rfc.best_estimator_.predict(X_test),y_test)))
Получаем следующие параметры:
{'max_depth': 6, 'n_estimators': 30} 0.766666666667
best accuracy on cv: 0.77
accuracy on test data: 0.87879
best params: {'max_depth': 6, 'n_estimators': 30}
(предсказанные, фактические):
[(0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (2, 0), (2, 0), (2, 0), (1, 1), (1, 1), (1, 1), (1, 1), (0, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)]
Wall time: 1min 6s
То есть увеличение max_depth на 1 повышает точность на 6%, что уже неплохо, при этом несмотря на то что модель числом деревьев (n_estimators), как «кашу маслом не испортишь», модель решила, что дальше увеличивать их число не стоит (это экономит ресурсы).
Я думаю можно добиться и лучших результатов если поискать больше параметров (или увеличить размер выборки), но в целях демонстрации чтобы расчёт сильно много времени не занимал, мы ограничимся тем что есть.
Итак, мы с вами можно так сказать начали с нашего более совершенного Т-1000, давайте попробуем заставить что-то классифицировать нашего «железного Арни» в качестве которого выступит более простая модель логистической регрессии (Logistic Regression).
logreg = LogisticRegression(penalty='l2',random_state=42, C=1, n_jobs=-1)
logreg.fit(X_train, y_train)
pred_logreg = logreg.predict(X_test)
print("results (predict, real): \n",list(zip(pred_logreg,y_test)))
print("accuracy score= {0}".format(logreg.score(X_test,y_test)))
Как и следовало ожидать, более простая модель с первого подхода дала результат немного хуже.
results (predict, real):
[(0, 0), (0, 0), (0, 0), (2, 0), (0, 0), (0, 0), (0, 0), (2, 0), (0, 0), (0, 0), (2, 0), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 2), (2, 2), (2, 2), (0, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)]
accuracy score= 0.7878787878787878
Можем опять поиграться с параметрами:
%%time
param_grid = {'C':[0.00020, 0.0020, 0.020, 0.20, 1.2], 'penalty':['l1','l2']}
grid_search_logr = GridSearchCV(LogisticRegression(random_state=42,n_jobs=-1), param_grid, cv=3)
grid_search_logr.fit(X_train, y_train)
print("best accuracy on cv: {:.2f}".format(grid_search_logr.best_score_))
print("accuracy on test data: {:.5f}".format(grid_search_logr.score(X_test, y_test)))
print("best params: {}".format(grid_search_logr.best_params_))
print("results (predict, real): \n",list(zip(grid_search_logr.best_estimator_.predict(X_test),y_test)))
Результаты:
best accuracy on cv: 0.79
accuracy on test data: 0.81818
best params: {'C': 0.02, 'penalty': 'l1'}
(предсказанные, фактические):
[(0, 0), (0, 0), (0, 0), (2, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (2, 0), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 2), (2, 2), (2, 2), (0, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)]
Wall time: 718 ms
Итак, мы добились качества сопоставимого с Random forest без подгонки параметров, а вот времени мы затратили существенно меньше. Видно именно поэтому в книгах пишут, что логистическую регрессию часто используют на предварительных этапах, когда важно выявить общие закономерности, а 5-7% погоды сразу не сделают.
С одной стороны, на этом можно было бы и закончить, но давайте еще попробуем представить, что я как бесчестный человек дал вам данные без какого-либо описания и вам надо попробовать что-то понять, не имея меток классов.
Кластеризация
Для наглядности зададим цвета. Я все же немного лукавил, по-хорошему «мы не знаем» что классов у нас не больше трех, но мы же на самом то деле знаем, поэтому ограничимся тремя цветами.
colors = ["#476A2A", "#535D8E", "#BD3430"]Для начала попробуем посмотреть на наши данные, у нас почти 400 признаков и на двухмерном листе бумаги их все наверное не смогут отобразить даже великие маги и волшебники Амаяк Акопян и Гарри Поттер, но слава богу у нас есть магия специальных библиотек.
Для начала воспользуемся популярным алгоритмом T-SNE (кому любопытно, что это, можно почитать тут).
Нам главное, что алгоритм отображает наши данные в двухмерной плоскости и если в реальности данные хорошо разделимы, то и в двухмерном виде тоже будут хорошо разделимы (можно будет линии прочертить и точно кучки разделить).
У нас к сожалению, не все так хорошо. Где-то данные кучкуются, но где-то и перемешиваются.
И в принципе это нормально, опять же мы же с вами знаем специфику вопроса, а значит догадываемся о том, что если лампы хорошие, то по своему свету они будут похожи на настоящий дневной свет, а значит и данные тяжело разделить.
#T-SNE
tsne = TSNE(random_state=42)
d_tsne = tsne.fit_transform(X_train)
plt.figure(figsize=(10, 10))
plt.xlim(d_tsne[:, 0].min(), d_tsne[:, 0].max() + 10)
plt.ylim(d_tsne[:, 1].min(), d_tsne[:, 1].max() + 10)
for i in range(len(X_train)):
# строим график, где цифры представлены символами вместо точек
plt.text(d_tsne[i, 0], d_tsne[i, 1], str(y_train[i]),
color = colors[y_train[i]],
fontdict={'weight': 'bold', 'size': 10})
plt.xlabel("t-SNE feature 0")
plt.ylabel("t-SNE feature 1")
Для подстраховки посмотрим на результаты алгоритма PCA (подробней тут).
#PCA
pca = PCA(n_components=2, random_state=42)
pca.fit_transform(X_train)
d_pca = pca.transform(X_train)
plt.figure(figsize=(10, 10))
plt.xlim(d_pca[:, 0].min(), d_pca[:, 0].max() + 130)
plt.ylim(d_pca[:, 1].min(), d_pca[:, 1].max() + 30)
for i in range(len(X_train)):
# строим график, где цифры представлены символами вместо точек
plt.text(d_pca[i, 0], d_pca[i, 1], str(y_train[i]),
color = colors[y_train[i]],
fontdict={'weight': 'bold', 'size': 10})
plt.xlabel("1-st main comp.")
plt.ylabel("2-nd main comp.")
Результаты похожи.
Ну а теперь займемся непосредственной кластеризацией, много есть алгоритмов, но мы для данного примера воспользуемся алгоритмом DBSCAN (подробности).
Данный алгоритм не требует задавать начальное количество классов и в некоторых случаях позволяет неплохо угадать, но забегая вперед мы же помним картинки сверху? В нашем случае это будет трудно. Вот вариант DBSCAN который находит три класса (можно 2 или 4).
#scale data
scaler = MinMaxScaler()
scaler.fit(X_test)
X_scaled = scaler.transform(X_test)
#clustering with DBSCAN
dbscan = DBSCAN(min_samples=2, eps=2.22, n_jobs=-1)
clusters = dbscan.fit_predict(X_scaled)
print("Affiliation to clusters:\n{}".format(clusters))
print("\n results (Clustering, real): \n",list(zip(clusters,y_test)))
print("\n accuracy_score: \n",accuracy_score(clusters,y_test))
Affiliation to clusters:
[-1 -1 0 -1 -1 0 0 -1 1 1 -1 2 2 -1 -1 -1 -1 -1 2 -1 2 -1 -1 1 -1
-1 1 1 1 -1 1 -1 1]
результаты (кластеризация, факт):
[(-1, 0), (-1, 0), (0, 0), (-1, 0), (-1, 0), (0, 0), (0, 0), (-1, 0), (1, 0), (1, 0), (-1, 0), (2, 1), (2, 1), (-1, 1), (-1, 1), (-1, 1), (-1, 1), (-1, 1), (2, 1), (-1, 1), (2, 1), (-1, 1), (-1, 2), (1, 2), (-1, 2), (-1, 2), (1, 2), (1, 2), (1, 2), (-1, 2), (1, 2), (-1, 2), (1, 2)]
accuracy_score:
0.0909090909091
Получаем ужасное значение точности около 9%. Что-то не так! Конечно, DBSCAN не знает какие метки мы давали классам, поэтому в нашем случае 1 это 2 и наоборот (a -1 это шум).
Меняем метки классов и получаем:
def swap_class(lst, number_one,number_two ):
"""
The function is exchanging num1 and num2 in list and return new array
"""
lst_new=[]
for val in lst:
if val == number_one:
val = number_two
elif val == number_two:
val = number_one
lst_new.append(val )
return np.array(lst_new)
y_changed=swap_class(clusters, 1,2)
print("\n results (Clustering, real): \n",list(zip(y_changed,y_test)))
print("\n accuracy_score: \n",accuracy_score(y_changed,y_test))
результаты (кластеризация, факт):
[(-1, 0), (-1, 0), (0, 0), (-1, 0), (-1, 0), (0, 0), (0, 0), (-1, 0), (2, 0), (2, 0), (-1, 0), (1, 1), (1, 1), (-1, 1), (-1, 1), (-1, 1), (-1, 1), (-1, 1), (1, 1), (-1, 1), (1, 1), (-1, 1), (-1, 2), (2, 2), (-1, 2), (-1, 2), (2, 2), (2, 2), (2, 2), (-1, 2), (2, 2), (-1, 2), (2, 2)]
accuracy_score:
0.393939393939
Другое дело, уже 39% что все равно лучше, чем если бы мы классифицировали случайным способом. Вот и все машинное обучение, но для терпеливых людей в конце статьи будет bonus.
Часть 5. Заключение
Ну вот мы и прошли с вами нелегкий путь от постановки задачи до ее решения, подтвердили на практике некоторые истинны, которые встречаются в учебниках по Data Science.
На самом деле нам не обязательно было классифицировать именно по спектральному распределению, можно было и взять производные признаки, например, индекс цветопередачи и цветовую температуру, но это вы если захотите сделаете самостоятельно.
Также безусловно есть смысл добавить еще данных в обучающую и тестовую выборку, так как от этого весьма сильно зависит качество обучения модели (по крайней мере в данном случае разница между выборкой в 20 и 30 семплов была существенная).
Что же вам делать со своими исследованиями, когда вы их проведете? Ну во-первых, вы можете написать статью на Хабр :)
А можете и не ограничиваться Хабром, помню 4 года назад я писал статью, «Как перестать быть «блогером» и почувствовать себя «ученым».
Смысл ее заключался в том, что можно и не останавливаться на достигнутом, как правило если вы в состоянии написать статью на Хабр, то можете и написать в какой-нибудь научный журнал.
Зачем? Да просто потому что можете! Данная ситуация похожа на игру футбол, в РФПЛ человек 200 отечественных футболистов (это с потолка, но думаю не сильно больше), за границей наших играет и того меньше, но зато в целом в футбол по всей стране играет намного больше народа.
Ведь есть любительские лиги. Любители не получают зарплату, а играют часто ради удовольствия. Так и тут я предлагаю вам поиграть в «любительской» научной лиге.
В нашем случае, если у вас нет доступа к стоящим международным журналам, или хотя бы ВАКовским, не расстраивайтесь, даже после обвала РИНЦ есть места где вашу хорошую статью вполне примут, при соблюдении формальностей и научного стиля изложения например, на одной из конференций, входящих в РИНЦ, это как правило удовольствие платное, но весьма бюджетное.
Еще полезней будет участие в очной конференции, где вам придется отстоять живьем свою идею.
Кто знает может быть вы однажды набьете руку войдете во вкус и станете нашей новой надеждой человечества.
Есть и другое применение вашим талантам, можете анализировать данные бюджетных структур и участвовать в общественном контроле, наверняка если копнуть по глубже, то найдутся очевидные косяки в отчётности нечестных людей и организаций, и вы сможете сделать наш дом лучше (или нет)
А может быть вы найдете еще какое-то замечательное применение вашему хобби и обернете его в доход, все в ваших руках.
Бонус. Прогноз вручную
Вам не кажется, что в статье осталась небольшая недосказанность? Чего-то не хватает? Ну конечно надо провести эпичную битву человек-машина!
Посмотрим кто лучше классифицирует спектры.
Поскольку у меня нет этого волшебного кота, который все угадывает, придется все делать самому.
Напишем для этого небольшую функцию. И построим графики по которым я буду предсказывать.
Прим. за качество кода не ручаюсь
def print_spec_rand(data):
"""
the function takes a DataFrame and returns in random order the x-coordinate (wavelength),
the power values for all light sources (the y-axis), and the matching to the original
DataFrame positions. Use it for manual prediction.
"""
x=data.columns.values[:-1]
data_y=data.values
y=list()
pos=list()
rows_count=data_y.shape[0]
index=range(0,rows_count+1)
while rows_count>1:
rows_count=data_y.shape[0]
i=np.random.randint(0,data_y.shape[0])
y.append(data_y[i][:-1])
pos.append(index[i])
data_y=np.delete(data_y, i, 0)
index=np.delete(index, i, 0)
#print (len(data_y,))
return x, y, pos
def get_match_labels(human_labels, pos_in_data_lebels):
"""
The function returns a match between the random data and the original DataFrame
"""
match=np.zeros(len(human_labels))
for h,p in zip (human_labels, pos_in_data_lebels):
match[p]=h
return matchВот кстати вам еще одна отсылка к сравнению человек-машина из 2-й главы. Честно признаюсь обычно я определяю спектры имея под рукой и фотографию спектра и сам график и тогда точность переваливает за 90 и близится к 100%, но нашей модели мы картинки спектров не давали, а значит нам придется быть с ней в равных условиях.
Данная ситуация чем-то похожа на ту, когда вы обучаете модель на одном наборе признаков, а потом в реальных данных (или контрольных) часть признаков отсутствует и прогнозирующая сила модели сильно снижается (снизилась и моя).
И так поверьте мне на слово (или запустите. ipynb файл с GitHub) у нас получается 33 графика из контрольной выборки, примерно таких:
Потом вводим вручную прогноз, возвращаем соответствие порядка меток и смотрим, что получилось.
# my prediction, as an example
man_ped=[0,1,2,0,1,1,2,0,0,1,0,1,1,2,0,0,2,1,1,0,1,1,0,0,0,0,1,2,1,0,2,0,2]
man_pred_trans=get_match_labels(man_ped, pos)
print("results (predict, real): \n",list(zip(man_pred_trans,y_test)))
print("accuracy score= {0}".format(accuracy_score(man_pred_trans,y_test)))Результат (мой прогноз, факт.):
[(0.0, 0), (0.0, 0), (0.0, 0), (1.0, 0), (0.0, 0), (0.0, 0), (0.0, 0), (0.0, 0), (0.0, 0), (0.0, 0), (0.0, 0), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (1.0, 1), (0.0, 2), (2.0, 2), (2.0, 2), (2.0, 2), (2.0, 2), (2.0, 2), (0.0, 2), (0.0, 2), (2.0, 2), (2.0, 2), (0.0, 2)]
accuracy score= 0.8484848484848485
Безусловно я ангажирован, как минимум потому что я знаю, что в контрольной выборке не больше 11 меток каждого класса, но я старался не жульничать.
Итак, в моей первой попытке получилось 84% с небольшим, что-то среднее между логистической регрессией и Random Forest, причем компьютер обошел меня в последней позиции.
Помните вначале статьи я упоминал, что часть спектров может быть срезана? Меня именно это и подвело, без фотографии я это не заметил и неправильно классифицировал срезанный спектр только по графику, а вот компьютер справился и получил свои 87%.
Если учесть, что я этому навыку определения спектров на глазок посветил не один день, а модель обучалась минуту с небольшим, то возможно уже пора боятся восстания машин?