
Celesta (челеста) — «движок» бизнес-логики на языке Jython, встраиваемый в Java-приложения. Flute (флейта) — компонент, который позволяет работать челесте как сервису. Сначала мы расскажем о том, зачем такое вообще бывает нужно, но если вы хотите пропустить вступление и перейти сразу к технической части, то вам — в Часть II.
Часть I, вводная
Для чего нужна Celesta?
Решаемая проблема такова: как встроить бизнес-логику в Java-приложение или, шире, в приложение, работающее в Java-экосистеме.
Казалось бы, зачем тут изобретать очередной «велосипед»? Ведь мы знаем, что есть специальные системы для работы с бизнес-логикой и написания бизнес-приложений. Самая распространённая в России — «1C», есть Microsoft Dynamics, SAP и многие другие. Причём в работе с подобными программными продуктами задействовано, судя по всему, не меньше половины всех ИТ-специалистов по всему миру. По крайней мере, основатель «1C» утверждает, что из миллиона ИТ-специалистов в России треть — специалисты «1С».
В то же время, всегда есть более локальные задачи, где привлечение подобных систем проблематично. Допустим, имеется интернет-магазин, а «позади» него должна стоять некоторая бизнес-логика, обрабатывающая заказы. Можно ли поставить для обработки бизнес-логики одну из вышеперечисленных больших систем? Вполне. Но неудобство заключается в том, что если весь магазин, допустим, написан в Java-экосистеме, то система создания бизнес-приложений — уже совсем не в Java-экосистеме, что затрудняет интеграцию. Система дорога в лицензировании и поддержке, требует особых специалистов. А задачи, которые в этих случаях возлагаются на данную систему, не такие уж глобальные. Цена вопроса оказывается неоправданно высокой, и решение калибра Celesta может выглядеть неплохой альтернативой.
Очень часто возникают задачи, связанные с реализацией какого-либо процесса работы с документом. Например, согласование договора или заявки на оплату. Классическим решением является использование систем типа Documentum, Alfresco и т.п. (часто используется термин CMS + BPM, т.е. Управление контентом + Управление бизнес-процессами). Однако, это все довольно сложные инфраструктурные системы. Имеет смысл их использовать, если необходимо обеспечивать работу с большим количеством документов разного типа и поддерживать много бизнес-процессов. А если не хочется выходить за рамки конкретного проекта? Celesta + Activiti прекрасно решат задачу. Celesta при этом обеспечит содержательную работу с документом, а Activiti будет показывать, что и в каком порядке должно выполняться.
Поэтому мы решили создать решение, которое позволило бы нам, не выходя за пределы Java-экосистемы, и не вводя новые большие составляющие в инфраструктуру, создавать вполне эффективные модули, управляющие бизнес-логикой, необходимые нашему заказчику.
За несколько лет работы мы внедрили решения на базе нашей платформы в достаточно многих организациях, некоторые из которых перечислены на сайте платформы.
Чем «бизнес-логика» отличается от просто логики?
Почему вообще нужны особенные системы для бизнес-логики? Почему «нельзя просто взять» и написать на Java, скажем, учёт финансов или товарных остатков? Ведь, казалось бы, какая разница, где складывать денежные суммы — в Java или в 1C (в Java, причём, вычисления-то наверняка побыстрее будут). Почему же у нас есть 1C, SAP и им подобные платформы?
Проблема в первую очередь заключается в изменчивости логики системы. Бизнес-приложение невозможно создать «раз и навсегда»: изменения в требования к бизнес-приложению поступают непрерывным потоком на всех этапах его жизненного цикла: разработки, внедрения, эксплуатации — потому что живёт и развивается бизнес-процесс, который приложение должно автоматизировать. Можно подумать, что такое количество изменений — результат неправильного первоначального анализа или плохой организации всего процесса. Но нет, это объективное свойство реальной жизни, причём не только в коммерческих организациях. Например, в государственных структурах требования по сути определяются нормативными документами (законами, постановлениями, приказами и т.п.). Бывает так, что проект для государственной структуры надо сдавать к некоторой дате, но до последнего момента неизвестно, подпишет или не подпишет премьер-министр постановление, от которого будут зависеть функциональные требования к системе, неизвестно бывает и его точное содержание.
Другая специфическая черта бизнес-приложений — потребность в обеспечении целостности данных. Если у нас учтена продажа, она должна отразиться во всех необходимых книгах операций. Если, скажем, продажа, отражаясь в подсистеме, ответственной за логистику, не отражается в бухгалтерском балансе — это приведет к большим проблемам.
Третья специфическая особенность — невозможность спрогнозировать требования доступа к данным. На начальном этапе даже бывает невозможно чётко определить, в каком формате данные потребуются на выходе, как они будут сегментированы, в каких документах. Необходимо закладывать такую систему, чтобы вывод данных можно было изменять достаточно быстро, на ходу.
Как обычно решения для бизнес-логики справляются с этими задачами?
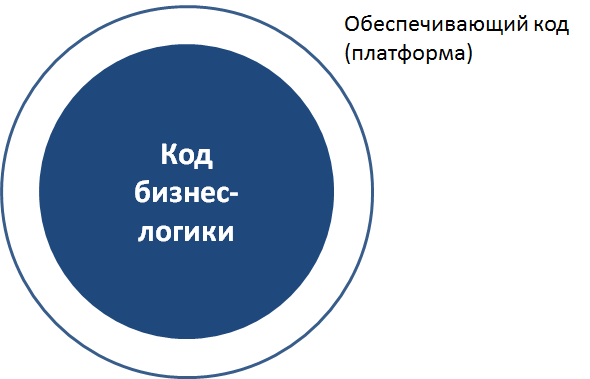
Во-первых, за счёт разделения кода на платформу и бизнес-логику. Это применяется во всех системах такого класса. Есть код платформы, обеспечивающий базовые вещи, и есть код бизнес-логики, который пишется чаще всего на специализированном языке: например, 1C, Microsoft Dynamics и SAP предлагают собственные языки для написания бизнес-логики.
Код платформы, решающий самые базовые задачи, производят авторы платформы и изменяют его только вместе с выходами новых версий платформы. Код бизнес-логики изменяется разработчиками бизнес-логики постоянно.
Во-вторых (в наше время это особенно приходится подчеркнуть) – использование реляционных СУБД. Несмотря на сильное развитие NoSQL-баз, для решения задач построения бизнес-логики на сегодня лучшим инструментом остаются реляционные СУБД. Лучшим — хотя бы потому, что это более старые, более зрелые проекты. Все основные преимущества реляционных СУБД, не присутствующие во многих из NoSQL-баз, остаются востребованными. Это и атомарность операций — возможность в случае ошибки откатить транзакцию с большим количеством изменений, так, как будто она и не начиналась. Это и изоляция. Это и обеспечение целостности через внешние ключи. И возможность обеспечить быстрое извлечение данных в произвольном формате. Не забудем также о необходимости интеграции с огромным количеством legacy-систем, данные которых находятся в реляционных СУБД. В общем, реляционные СУБД были и остаются главным инструментом хранения данных в подобных системах.
Чем создание бизнес-логики не отличается от «обычного» кодирования?
С вещами, делающими разработку бизнес-логики «особенной», понятно. Чем же она похожа на весь остальной программный код — будь то игры или операционные системы?
- Прежде всего, мы должны иметь стандартные инструменты контроля кода, управления версиями. Сегодня все используют Git — пусть это будет Git. Появится еще более удобный «Git++», значит пусть это будет еще более удобный «Git++». Удивительно, но у многих «больших» платформ создания бизнес-логики этот вопрос не решён: например, в системе Microsoft Dynamics код хранится непосредственно в базе данных, отсутствует даже элементарный контроль версий!
- Должен быть удобный IDE, желательно, тот, к которому все привыкли и умеют продуктивно работать: в Java-мире это IDEA или Eclipse. Производители «больших» платформ, создавая свои языки программирования, зачастую не уделяют удобству IDE должного внимания.
- Должна существовать удобная возможность тестирования кода, должны быть легко доступны модульные тесты, должна существовать возможность осуществлять test-driven development. Как и любые другие приложения, бизнес-приложения не должны ошибаться.
Где здесь место для Celesta?
На практике совместить платформу разработки бизнес-логики и перечисленные требования практически нельзя. Мы имеем две крайности.
Одна крайность – тотальное использование крупной системы типа 1C, Microsoft Dynamics, SAP и т. п. для решения вообще любых задач. Зачастую эти системы сковывают разработчиков, лишают их привычных инструментов и методов разработки (например, нельзя стандартными инструментами произвести автоматизированное тестирование), это повышает стоимость и удлиняет сроки разработки. Для типовых задач большого масштаба это оправдано, однако для небольших задач этот подход может оказаться губительным.
Противоположная крайность заключается в том, чтобы браться за любую задачу на системе разработки общего назначения. Открываем IDEA, создаём новый Java-проект, а там посмотрим — удастся или нет нам реализовать, например, для системы онлайн-продаж финансовый учёт и оборотно-сальдовую ведомость. Что в этом сложного? На первый взгляд ничего, пока не начнёте делать и не убедитесь в том, что без трудоёмкой реализации специальных паттернов и подходов сделать это нельзя, и что это отнимает все ваши ресурсы. Мы не утверждаем, что так добиться успеха невозможно, но есть определённые вещи, за которые браться не стоит.
Celesta здесь занимает промежуточное положение. Будучи Java-библиотекой (celesta.jar), она является «движком» бизнес-логики. Это «движок», который либо встраивается в Java-приложение, либо с помощью модуля Flute существует самостоятельно и обеспечивает возможность быстрой и правильной реализации бизнес-логики.
Сама Celesta написана на Java, а бизнес-логика пишется на языке Jython. Jython – это Java-реализация Python. Сейчас она имеется для версии Python 2.7. Изящность Python-кода, лёгкость освоения играли не последнюю роль при выборе языка для бизнес-логики, и он с нами уже несколько лет.
Однако мы не привязываемся к Python/Jython так уж сильно. Нам годится любой скриптовый язык, в последнее время мы присматриваемся к тому, чтобы встроить в Celesta Groovy.
Часть II, техническая
Что такое Celesta и что она умеет?
Место платформы Celesta как промежуточного слоя между реляционной базой и кодом бизнес-логики на общей картинке можно изобразить так:
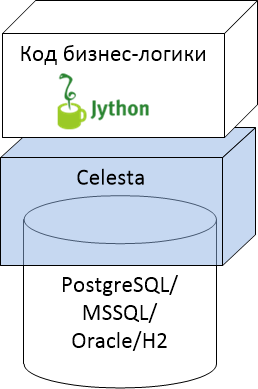
Мы поддерживаем четыре типа реляционных БД и код бизнес-логики на Jython. При этом Celesta немного присутствует и внутри базы данных, создавая для себя служебные объекты и триггеры.
Основные функциональные возможности Celesta:
- Принцип, очень похожий на основной принцип Java: «Write once, run on every supported RDBMS». Код бизнес-логики не знает, на каком типе базы данных он будет исполняться. Вы можете написать код бизнес-логики и запускать его в MS SQL Server, потом перейти на PostgreSQL, и это произойдет без осложнений (ну, почти :)
- Автоматическое изменение структуры на «живой» базе данных. Большая часть жизненного цикла Celesta-проектов происходит, когда уже база данных есть, когда она уже наполняется реальными продуктивными данными, которые нельзя просто так куда-то деть, выкинуть и начать с нового листа. При этом необходимо менять постоянно структуру. Одна из ключевых возможностей — Celesta сама автоматически «подгоняет» структуру БД под вашу модель данных.
- Тестирование. Большое внимание мы уделили тому, чтобы код под Celesta был тестируемым, чтобы мы могли автоматически тестировать процедуры, изменяющие данные в базе, делая это легко и изящно, без использования внешних инструментов типа DbUnit и контейнеров.
- Легкое разворачивание изменений на «живой» системе. Мы работаем с постоянно используемой системой, и ситуация такова, что иногда какие-то исправления приходится в самый разгар работы делать и включать. Удобно, когда всё разворачивание сводится к простой подмене исходников на скриптовом языке, т. е. когда скрипт и является тем артефактом, который можно поставить на машину, избегая необходимости что-то компилировать и упаковывать.
- Модульность решений, то есть возможность переноса какого-то стандартного куска функциональности между разными проектами. Всегда или очень часто у заказчиков есть повторяющиеся от раза к разу требования. Например, что система должна поддерживать распределение прав доступа, она должна интегрироваться с LDAP, она должна записывать все изменения, производимые в некоторых критически важных таблицах, выполнять аудит успешных/неуспешных входов. Все это настолько стандартные, частые требования, что хорошо, когда платформа их реализует раз и навсегда. Разработчик бизнес-логики использует стандартные модули и даже не думает о том, чтобы в который раз собирать «велосипед».
Для чего нужна независимость от типа СУБД?
Независимость кода бизнес-логики от типа СУБД мы поставили первым пунктом не случайно: код, написанный для Celesta, вообще не знает, на какой СУБД он исполняется. Зачем это сделано?
Во-первых, из-за того, что выбор типа СУБД – это вопрос не технологический, а политический. Приходя к новому заказчику, мы чаще всего обнаруживаем, что у него уже есть Oracle или SQL Server, в который инвестированы средства, и заказчик хочет видеть и другие решения на существующей инфраструктуре. Технологический ландшафт постепенно меняется: в госструктурах и частных компаниях все больше встречается PostgreSQL, хотя ещё несколько лет назад в нашей практике превалировал MS SQL Server. Celesta поддерживает наиболее часто встречающиеся СУБД, и нас эти изменения не тревожат.
Во-вторых, код, уже созданный для решения стандартных задач, хотелось бы переносить от одного заказчика другому, создавать переиспользуемую библиотеку. Вещи вроде иерархических справочников или модулей рассылки уведомлений на email по сути своей стандартны, и зачем нам поддерживать несколько версий под заказчиков с разными реляционками?
В-третьих — последнее по порядку, но не важности — возможность запуска модульных тестов без использования DbUnit и контейнеров с использованием базы данных H2, работающей в режиме in-memory. В этом режиме база H2 запускается моментально. Celesta очень быстро создаёт в ней схему данных, после чего можно провести необходимые тесты и «забыть» базу. Так как код бизнес-логики действительно не знает, на какой базе он бежит, то соответственно, если он без ошибок отрабатывает на H2, то без ошибок он будет работать и на PostgreSQL. Конечно, в задачу разработчиков самой системы Celesta входит сделать все тесты с задействованием подъема реальных СУБД, чтобы убедиться, что наша платформа одинаково свой API выполняет на разных реляционках (и мы это делаем). Но разработчику бизнес-логики этого уже не требуется.
CelestaSQL
За счет чего достигается «кроссбазданческость»? Конечно, за счёт того, что с данными можно работать только через специальный API, изолирующий логику от любой специфики БД. Celesta кодогенирирует Python-классы для доступа к данным, с одной стороны, и SQL-код и некоторые вспомогательные объекты вокруг таблиц, с другой стороны.
Celesta не предоставляет object-relational mapping в чистом виде, потому что при проектировании модели данных мы исходим не от классов, а от структуры базы данных. Т. е. сначала выстраиваем ER-модель таблиц, а затем на основе этой модели Celesta сама генерирует классы-курсоры для доступа к данным.
Достигнуть одинаковой работы на всех поддерживаемых СУБД можно только лишь для той функциональности, которая приблизительно одинаково реализована в каждой из них. Если условно в виде «кругов Эйлера» изобразить множества функциональных возможностей каждой из поддерживаемых нами баз, то получается такая картина:

Если мы обеспечиваем полную независимость от типа БД, то те функциональные возможности, которые мы открываем программистам бизнес-логики, должны лежать внутри пересечения по всем базам. На первый взгляд кажется, что это существенное ограничение. Да: какие-то специфические возможности, допустим, SQL Server мы не можем использовать. Но все без исключения базы поддерживают таблицы, внешние ключи, представления, SQL-запросы с JOIN и GROUP BY. Соответственно, мы можем дать эти возможности разработчикам. Мы предоставляем разработчикам «обезличенный SQL», который называем «CelestaSQL», а в процессе работы мы модифицируем SQL-запросы для диалектов соответствующих баз.
У каждой базы данных есть свой набор типов данных. Т. к. мы работаем через язык CelestaSQL, у нас тоже есть свой набор типов. Их всего семь, вот они и их сопоставление с реальными типами в базах:
| CelestaSQL | Microsoft SQL Server | Oracle | PostgreSQL | H2 | |
| Integer (32-bit) | INT | INT | NUMBER | INT4 | INTEGER |
| Floating point (64-bit) | REAL | FLOAT(53) | REAL | FLOAT8 | DOUBLE |
| String (Unicode) | VARCHAR(n) | NVARCHAR(n) | NVARCHAR2(n) | VARCHAR(n) | VARCHAR(n) |
| Long string (Unicode) | TEXT | NVARCHAR (MAX) |
NCLOB | TEXT | CLOB |
| Binary | BLOB | VARBINARY (MAX) |
BLOB | BYTEA | VARBINARY (MAX) |
| Date/Time | DATETIME | DATETIME | TIMESTAMP | TIMESTAMP | TIMESTAMP |
| Boolean | BIT | BIT | NUMBER CHECK IN (0, 1) |
BOOL | BOOLEAN |
Может показаться, что всего семь типов — это мало, но на самом деле это те самые типы, которых всегда достаточно, чтобы хранить финансовую, торговую, логистическую информацию: строк, целых чисел, дробных, дат, boolean-значений и BLOB-ов всегда хватит для представления таких данных.
Сам язык CelestaSQL описан в документации с большим количеством диаграмм Вирта.
Модификация структуры базы данных. Идемпотентный DDL
Еще одна ключевая функциональная возможность Celesta – это подход к модификации структуры, которая должна происходить на «живой» базе данных.
Какие вообще имеются возможные подходы к решению задачи контроля изменений структуры базы данных?
Есть очень распространенный подход, который можно условно назвать «лог изменений». Liquibase — наиболее известный в Java-мире инструмент, который решает задачу таким образом. В Python-мире тем же самым занимается фреймворк Django. Этот подход заключается в постепенном наращивании лога изменений базы данных, database change log. По мере того, как в структуре базы надо производить изменения, вы добавляете к этому логу инкрементные change set-ы. Постепенно ваш лог изменений накапливается, вбирая в себя всю историю модификаций вашей БД: ошибочных, исправляющих, рефакторингов и т. п. Через какое-то время изменений становится настолько много, что понять текущую структуру таблиц непосредственно по логу становится невозможно.
Хотя на сайте системы Liquibase и пишут, что их подход обеспечивает рефакторинг и контроль версий структуры базы данных — ни то, ни другое по-настоящему при помощи database change log-а не достигается. Понять это довольно просто, сравнив с тем, как вы выполняете рефакторинг обычного кода. Если, например, вам необходимо добавить какие-то методы в класс, то вы их добавляете непосредственно в определение класса, а не дописываете в change log код вроде «alter class Foo add method bar {....}». То же и с контролем версий: при работе с обычным кодом сама система контроля версий создаёт для вас лог изменений, а не вы дописываете changeset-ы в конец какого-нибудь журнала.
Понятно, что для структуры базы данных так делается неспроста: причина в том, что в таблицах базы уже существуют данные, и change set призван конвертировать не только структуру, но и ваши данные. Таким образом change log как будто дает уверенность в том, что вы всегда сможете обновиться с его использованием с любой версии базы данных. Но на самом деле это ложная уверенность. Ведь если вы протестировали код модификации ваших данных на какой-то копии базы данных и он сработал, нет гарантии, что он же сработает на базе с какими-то другими данными, где могут быть какие-то особые случаи, которых вы не учли в вашем changeset-е. Самое неприятное, что может случиться с такой системой — это changeset, отработавший наполовину и закоммитивший часть изменений: база оказывается «посередине» между версиями, и потребуется ручное вмешательство, чтобы исправить ситуацию.
Есть другой подход, условно назовем его «configuration management-подход» или иначе — «идемпотентный DDL».
По аналогии с тем, как configuration management системах типа Ansible у вас есть идемпотентные скрипты, которые говорят не «сделай что-то», а «приведи что-то к желаемому состоянию», точно так же и мы, когда пишем на CelestaSQL следующий текст:
CREATE TABLE OrderLine(
order_id VARCHAR(30) NOT NULL,
line_no INT NOT NULL,
item_id VARCHAR(30) NOT NULL,
item_name VARCHAR(100),
qty INT NOT NULL DEFAULT 0,
cost REAL NOT NULL DEFAULT 0.0,
CONSTRAINT Idx_OrderLine PRIMARY KEY (order_id, line_no)
);
— этот текст интерпретируется Celesta не как «создай таблицу, а если таблица уже есть, то выдай ошибку», а «приведи таблицу к желаемой структуре». То есть: «если таблицы нет — создай, если таблица есть, посмотри, какие в ней поля, с какими типами, какие индексы, какие внешние ключи, какие default-значения и т. п. и не надо ли что-то изменить в этой таблице, чтобы привести её к нужному виду».
При таком подходе мы достигаем настоящего рефакторинга и настоящего контроля версий на наших скриптах определения структуры базы:
- Мы видим в скрипте текущий «желаемый образ» структуры.
- Что, кем и почему в структуре изменялось со временем, мы можем посмотреть с помощью системы контроля версий.
- Что до ALTER-команд, то их автоматически, «под капотом» формирует и выполняет Celesta по мере необходимости.
Может возникнуть вопрос: а как же быть с трансформацией данных, ведь простого ALTER не всегда достаточно? Да, действительно это работает не всегда в автоматическом режиме. Например, если мы добавим в непустую таблицу NOT NULL-поле и не снабдим его DEFAULT-значением, то Celesta не сможет добавить поле: она просто не знает, какие данные туда подставить для существующих строк, и база данных не даст такое поле создать. Но в этом нет ничего страшного. Во-первых, Celesta сигнализирует, что такой-то апдейт она выполнить полностью не сумела по такой-то причине, с такой-то ошибкой БД. В отличие от «changelog»-систем, апдейты, не выполненные до конца, для Celesta не являются проблемой, т. к. для генерации ALTER-команд она сравнивает текущее фактическое состояние базы с желаемым, и изменения, не выполненные при одной попытке, она будет пытаться доделать в другой. Вы, со своей стороны, можете сделать ad hoc скрипт, трансформирующий данные и «помогающий» Celesta выполнить апдейт. Этот скрипт можно отладить на тестовой базе, выполнить на продуктовой базе, закончить апдейт Celesta — после чего ваш ad hoc скрипт можно просто выкинуть, потому что больше он вам не понадобится никогда! Ведь ваша рабочая база уже находятся в нужном вам состоянии по структуре, а если вы задумаете делать новую базу «с нуля», то тогда вам не надо заставлять базу проходить весь тот путь, который вы прошли, дорабатывая её структуру в процессе разработки.
На практике, создание «вспомогательных» скриптов требуется нечасто. Абсолютное большинство изменений (добавление полей, перестройка индексов, изменение views) производятся в Celesta автоматически «на ходу».
Структура проекта Celesta. Гранулы
Для того, чтобы начать пользоваться Celesta, нужно понять, как устроен Celesta-проект с бизнес-логикой.
Совокупность всей бизнес-логики мы называем «score» («партитура»), внутри «score» находятся «grains» — гранулы, они же модули:
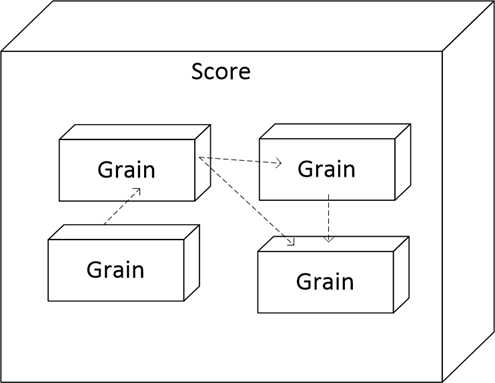
Здесь пунктирными стрелками показаны зависимости, то есть гранулы могут использовать объекты из других гранул. И эти зависимости могут быть сложными, но главное ограничение состоит в том, чтобы зависимости по внешним ключам не были циклическими — это нужно для обеспечения успешного обновления структуры БД по гранулам, когда Celesta начинает с того, что выбирает правильный порядок обновления.
Что такое гранула?
С точки зрения исходных кодов, гранула – это папка. Требования к папке следующие:
- в ней находится CelestaSQL файл, называющийся как сама гранула, с символом подчёркивания в начале (так сделано, чтобы этот особо важный файл оказывался наверху в файловом менеджере при сортировке по имени)
- содержимое этого файла начинается с декларации гранулы — её имени и версии — с помощью выражения create grain … version …;
- в этом файле содержится DDL со структурой таблиц гранулы
С точки зрения базы данных гранула превращается в схему. Все таблицы, определённые в грануле foo, в итоге окажутся в SCHEMA foo.
С точки зрения Python (или Jython в нашем случае) гранула — это пакет, в котором будут находиться сгенерированные классы доступа к данным, и в котором можно будет создать свои модули с кодом бизнес-логики. Поэтому также в папке гранулы должен находиться файл с именем __init__.py
Запуск Celesta и синхронизация структуры базы
При запуске Celesta занимается синхронизацией структуры базы данных. Примерная последовательность шагов такова:
- Выполняется топологическая сортировка списка гранул по foreign key-зависимостям, чтобы выполнить обновление в порядке, не приводящем к конфликтам.
- Контрольная сумма DDL-скрипта гранулы сравнивается с контрольной суммой последнего успешного апдейта, сохранённой в служебной таблице. Если эти суммы совпадают — Celesta считает, что можно пропустить этап сверки структуры таблиц, чтобы ускорить запуск.
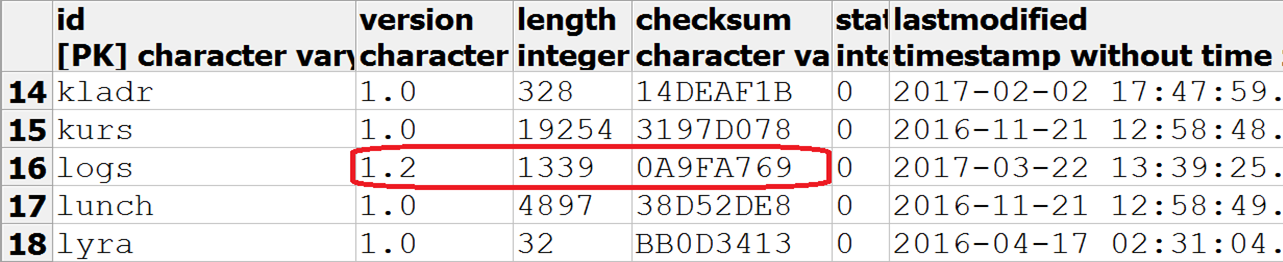
- Если контрольная сумма изменилась, а версия — осталась прежней или выросла, то Celesta начинает обходить все объекты гранулы и исследовать, какие из метаданных разошлись. Если метаданные разошлись, тогда генерируются и выполняются CREATE и ALTER-команды, которые в абсолютном большинстве случаев проходят без проблем и ручного вмешательства.
- Параллельно по необходимости генерируются или пересоздаются Python-модули с классами доступа к данным — по одному классу на каждую таблицу.
Это весьма краткий пересказ того, что происходит на многоэтапном процессе запуска, включающем в себя и генерацию классов для доступа к данным, и инициализацию пакетов гранул. Более детально процесс запуска описан на этой странице документации.
Создание модели данных и базы данных в Celesta
Давайте посмотрим, как в Celesta можно создавать модель данных и разворачивать базу данных.
Допустим, мы делаем проект для компании интернет-торговли, которая недавно объединилась с другой компанией. У каждой есть своя база данных. Они собирают заказы, но пока они не слили свои базы данных воедино, нужна единая точка входа для того, чтобы собирать заказы, поступающие извне.
Для начала нам надо создать структуру таблиц, хранящих заказы. Заказ, как известно, сущность составная: он состоит из заголовка, где хранится информация о клиенте, дате заказа и прочих атрибутов заказа, а также из множества строк (товарных позиций).
Итак, за дело: создаём
- папку score,
- в ней гранулу — папку orders,
- в папку orders вставляем пустой файл __init__.py (благодаря этому файлу Python будет воспринимать данную папку как пакет)
- в папке orders создаём файл _orders.sql следующего содержания:
CREATE GRAIN orders VERSION '1.0';
-- ТАБЛИЦЫ
/**Заголовок заказа*/
CREATE TABLE OrderHeader(
id VARCHAR(30) NOT NULL,
date DATETIME,
customer_id VARCHAR(30),
/**Имя клиента*/
customer_name VARCHAR(50),
CONSTRAINT Pk_OrderHeader PRIMARY KEY (id)
);
/**Строка заказа*/
CREATE TABLE OrderLine(
order_id VARCHAR(30) NOT NULL,
line_no INT NOT NULL,
item_id VARCHAR(30) NOT NULL,
item_name VARCHAR(100),
qty INT NOT NULL DEFAULT 0,
cost REAL NOT NULL DEFAULT 0.0,
CONSTRAINT Idx_OrderLine PRIMARY KEY (order_id, line_no)
);
ALTER TABLE OrderLine ADD CONSTRAINT fk_OrderLine FOREIGN KEY (order_id) REFERENCES OrderHeader(id);
/*ПРЕДСТАВЛЕНИЯ*/
CREATE VIEW OrderedQty AS
SELECT item_id, sum(qty) AS qty FROM OrderLine GROUP BY item_id;
Здесь мы описали две таблицы, соединённые внешним ключом, и одно представление, которое будет возвращать сводное количество по товарам, присутствующим во всех заказах. Как видим, это не отличается от обычного SQL, за исключением команды CREATE GRAIN, в которой мы задекларировали версию гранулы orders. Но есть и особенности. Например, все имена таблиц и полей, которые мы используем, могут быть только такими, чтобы их можно было превратить в допустимые в языке Python имена классов и переменных. Поэтому пробелы, спецсимволы, нелатинские буквы исключены. Ещё можно заметить, что комментарии, которые мы поставили над названиями таблиц и некоторых из полей, мы начали не с /*, как обычно, а с /**, как начинаются комментарии JavaDoc — и это неспроста! Комментарий, определённый над некоторой сущностью, начинающийся с /**, будет доступен во время исполнения в свойстве .getCelestaDoc() данной сущности. Это бывает полезно, когда мы хотим снабдить элементы базы дополнительной мета-информацией: например, human readable названиями полей, информацией о том, как представлять поля в пользовательском интерфейсе и т. п.
Первый этап сделан: модель данных построена в первом приближении, и теперь нам хотелось бы применить её к базе данных. Для этого мы создаём пустую базу данных и напишем простое Java-приложение, использующее Celesta.
Используем Maven-dependency для Celesta (актуальную версию можно взять на сайте corchestra.ru):
<dependency>
<groupId>ru.curs</groupId>
<artifactId>celesta</artifactId>
<version>6.0RC2</version>
<scope>compile</scope>
</dependency>
Создаём boilerplate-код и запускаем его:
public class App
{
public static void main( String[] args ) throws CelestaException
{
Properties settings = new Properties();
settings.setProperty("score.path", "c:/path/to/score");
settings.setProperty("pylib.path", "d:/jython2.7.1b3/Lib") ;
settings.setProperty("rdbms.connection.url", "jdbc:postgresql://localhost:5432/mytest");
settings.setProperty("rdbms.connection.username", "postgres");
settings.setProperty("rdbms.connection.password", "123");
Celesta.initialize(settings);
Celesta c = Celesta.getInstance();
}
}
Через объект Properties передаются базовые настройки Celesta, такие как путь к папке score (её подпапкой должна быть /orders), путь к стандартной библиотеке Jython (Jython должен быть установлен на вашей машине!) и параметры JDBC-подключения к базе данных. Полный перечень параметров Celesta приведён в wiki-документации.
Если параметры заданы правильно и всё прошло успешно, то можно посмотреть, что случилось с базой данных mytest. Мы увидим, что в базе появилась схема orders с нашими таблицами «OrderHeader» и «OrderLine», а также представление «OrderedQty». Теперь допустим, что спустя какое-то время мы решили изменить нашу модель данных. Допустим, мы хотим в заголовке заказа расширить поле с именем клиента до 100 символов и добавить поле с кодом менеджера. Сделать это мы можем прямым редактированием определения таблицы в файле _orders.sql, буквально изменив одну строку и и дописав другую:
customer_name VARCHAR(100),
manager_id VARCHAR(30),
Запустив приложение ещё раз, мы можем убедиться, что структура базы данных изменилась, чтобы отвечать новой модели.
Помимо схемы orders, в базе данных создаётся служебная схема celesta. Полезно заглянуть в таблицу grains, чтобы увидеть в ней запись о грануле orders, её статусе и контрольной сумме скрипта _orders.sql.
Создание Celesta-процедур: контексты сессии и вызова, запуск «hello, world!»
Разобравшись с созданием структуры базы данных, можно приступать к написанию бизнес-логики.

Для того, чтобы можно было реализовать требования распределения прав доступа и логирования действий, любая операция над данными в Celesta производится от имени некоторого пользователя, «анонимных» операций быть не может. Поэтому любой Celesta-код выполняется в некотором контексте вызова, который, с свою очередь, существует в контексте сессии.
Появление и удаление контекста сессии через методы login/logout позволяют осуществлять аудит входов-выходов. Привязка пользователя к контексту определяет разрешения на доступ к таблицам, а также обеспечивает возможность логирования изменений, производимых от его имени.
Чтобы убедиться, что мы можем запускать код Celesta-процедур как таковой, для начала рассмотрим пример «Hello, world», а потом построим менее тривиальную систему, которая будет модифицировать данные в базе и использовать модульные тесты для проверки своей корректности.
Вернёмся в папку score/orders и создадим в ней Python-модуль hello.py следующего содержания:
# coding=UTF-8
def run(context, name):
print u'Привет, %s' % name
Любая Celesta-процедура должна своим первым аргументом иметь context, который является экземпляром класса ru.curs.celesta.CallContext — в нашем примитивном примере он не требуется, но как мы увидим далее, он играет ключевую роль. Кроме того, Celesta-процедуры могут иметь произвольное количество других дополнительных параметров (в том числе не иметь вовсе). В нашем примере присутствует один дополнительный параметр name.
Чтобы запустить Celesta-процедуру, её нужно идентифицировать по трехкомпонентному имени. Внутри гранулы orders у нас находится питоновский модуль hello, внутри которого находится функция run — значит, трёхкомпонентное имя нашей процедуры будет orders.hello.run. Если бы мы использовали несколько вложенных питоновских модулей, тогда их имена также можно было бы перечислить через точку, например: orders.subpackage.hello.run.
Модифицируем немного наш код на Java, дописав создание контекстов сессии и вызова и, собственно, запуск процедуры:
Celesta c = Celesta.getInstance();
String sessionId = String.format("%08X", (new Random()).nextInt()); //разнообразия ради
c.login(sessionId, "super"); //super -- создаваемый по умолчанию пользователь со всеми правами
c.runPython(sessionId, "orders.hello.run", "Ivan");
c.logout(sessionId, false);
Запустив Java-программу, мы получим приветствие от питоновского кода, который выполняется из-под Celesta.
Привет, Ivan
Создание Celesta-процедур: модификация данных, защита от race conditions и транзакции
Теперь мы покажем, как написать на Celesta код, читающий и изменяющий данные в базе. Для этого мы используем так называемые курсоры — классы, которые Celesta сгенерировала для нас. Мы можем увидеть что они из себя представляют, зайдя в папку с гранулой orders: т. к. мы уже запускали Celesta, то кодогенерация была выполнена, и в папке orders будет находиться файл _orders_orm.py.
Внутри него обнаружатся классы курсоров OrderHeaderCursor, Order LineCursor и OrderedQtyCursor. Как видим, по одному классу создано на каждый из объектов гранулы – на две таблицы и одно представление. И теперь эти классы мы можем использовать для доступа к объектам базы данных в нашей бизнес-логике.
Чтобы создать курсор на таблицу заказов и выбрать первую запись, нужно написать такой Python-код:
header = OrderHeaderCursor(context)
header.tryFirst()
После создания объекта header мы можем получить доступ к полям записи таблицы через переменные:
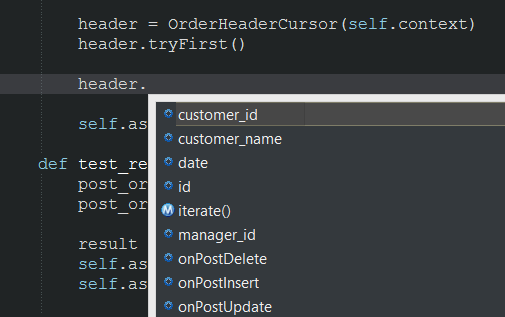
Как мы уже говорили, первым аргументом любой Celesta-процедуры является контекст вызова, и этот контекст мы обязаны передать в качестве первого аргумента конструктора любого курсора — это единственный способ создать курсор. Контекст вызова несёт в себе информацию о текущем пользователе и его правах доступа.
С объектом-курсором мы можем производить разные вещи: фильтровать, переходить по записям, а также, естественно, вставлять, удалять и обновлять записи. Весь API курсоров подробно описан в документации.
Например, код нашего примера можно было бы развить следующим образом:
def run(context, delta):
header = OrderHeaderCursor(self.context)
header.setRange('city', 'MSK')
header.tryFirst()
header.counter = orderHeader.counter + delta
header.update()
В этом примере мы выставляем фильтр по полю city, затем находим первую запись методом tryFirst.
В момент срабатывания tryFirst переменные курсора заполняются данными одной записи, мы можем читать и присваивать им значения. А когда данные в курсоре полностью подготовлены, мы выполняем update(), и он сохраняет содержимое курсора в базе данных.
Какой проблеме может быть подвержен этот код? Конечно же, возникновению race condition/lost update! Потому что между моментом, когда мы получили данные в строке с «tryFirst», и моментом, когда мы пытаемся обновить эти данные в точке «update», кто-то другой уже может получить, изменить и обновить эти данные. После того, как данные прочитаны, курсор никаким образом не блокирует их использование другими пользователями! Потерянные обновления были бы большой проблемой в такой системе, но Celesta содержит защиту, основанную на проверке версий данных. В каждой таблице по умолчанию Celesta создаёт поле recversion, и на уровне ON UPDATE-триггера выполняет инкремент номера версии и проверяет, что обновляемые данные имеют ту же версию, что и в таблице. Если произошла проблема — выбрасывает исключение. Подробнее об этом можно прочитать в статье документации «защита от потерянных обновлений».
В случае, если выход из Celesta-процедуры происходит по необработанному исключению, Celesta откатывает неявную транзакцию, которую она начинает перед выполнением процедуры. Важно понимать, что call context — это не только контекст вызова, но ещё и транзакция. Если Celesta-процедура заканчивается успешно, тогда происходит commit. Если Celesta-процедура заканчивается с необработанным исключением, тогда происходит rollback.
Специалист, который пишет бизнес-логику, может не знать всех тонкостей, происходящих «за кулисами»: он просто пишет бизнес-логику, а система обеспечивает консистентность данных. Если ошибка происходит в какой-то сложной процедуре — откатывается вся связанная с контекстом вызова транзакция, как будто бы мы ничего и не начинали делать с данными, данные не испорчены. Если же зачем-то нужен commit в середине, допустим, какой-то большой процедуры, то явный commit можно выполнить, вызвав context.commit().
Создание Celesta-процедур: модульное тестирование
Давайте рассмотрим более продвинутый пример.
Допустим, у нас имеются вот JSON-файлы, которые мы хотим класть в базу данных, состоящую из
request1 = {
'id': 'no1',
'date': '2017-01-02',
'customer_id': 'CUST1',
'customer_name': u'Василий',
'lines': [
{'item_id': 'A',
'qty': 5
},
{'item_id': 'B',
'qty': 4
}
]
}
request2 = {
'id': 'no2',
'date': '2017-01-03',
'customer_id': 'CUST1',
'customer_name': u'Андрей',
'lines': [
{'item_id': 'A',
'qty': 3
}
]
}
В каждом из этих JSON у нас есть поля, относящиеся к заголовку заказа, и есть массив, относящийся к его строкам. Как быстро и надёжно создать приложение, которое обрабатывает эти данные и укладывает в СУБД? Конечно, через тестирование!
Начнём с того, что создадим класс модульного теста, который наследуем от CelestaUnit. В свою очередь, CelestaUnit является наследником unittest.TestCase системы PyUnit:
#coding=utf-8
from celestaunit.celestaunit import CelestaUnit, clean_db
from basic_operations import post_order, get_aggregate_report
from _orders_orm import OrderHeaderCursor
class test_basic_operations(CelestaUnit):
request1 =....
request2 = ...
def setUp(self):
CelestaUnit.setUp(self)
clean_db(self.context)
И напишем модульный тест для проверяемой процедуры:
def test_document_is_put_to_db(self):
#Вызываем тестируемую процедуру (она пока не реализована)
post_order(self.context, test_basic_operations.request1)
#Проверяем, что данные попали в базу
header = OrderHeaderCursor(self.context)
header.tryFirst()
#Мы знаем, что вставляемый документ имеет id='no1'
self.assertEquals('no1', header.id)
Обратите внимание на то, что мы имеем возможность писать модульные тесты в предположении, что к моменту их выполнения база данных будет абсолютно пустой, но со структурой, которая нам нужна, а после их выполнения мы можем не заботиться о том, что мы оставили «мусор» в базе. Более того: используя импорт CelestaUnit, мы можем вовсе не заботиться о том, чтобы хоть какая-то БД стояла у нас на рабочей машине. CelestaUnit поднимает H2 in-memory базу и все конфигурирует за нас, а нам остаётся только брать из self готовый контекст вызова и пользоваться им для создания курсоров.
Если запустить этот тест сразу, то он не сработает, т. к. мы не реализовали тестируемый метод. Напишем его:
def post_order(context, doc):
header = OrderHeaderCursor(context)
line = OrderLineCursor(context)
#заполняем заголовок
header.id = doc['id']
header.date = datetime.datetime.strptime(doc['date'], '%Y-%m-%d')
header.customer_id = doc['customer_id']
header.customer_name = doc['customer_name']
header.insert()
lineno = 0
#заполняем строки в цикле
for docline in doc['lines']:
lineno += 1
line.line_no = lineno
line.order_id = doc['id']
line.item_id = docline['item_id']
line.qty = docline['qty']
line.insert()
Снова запустим тест в IDE и ура:
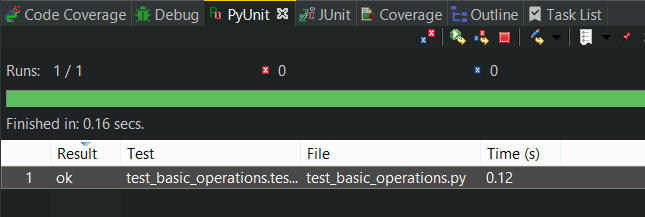
Мы также можем добавить в тест какие-то более сложные проверки, например, что строки заказа вставились, что их ровно две и т. д.
Давайте создадим вторую процедуру, возвращающую JSON с агрегированными значениями, показывающими, сколько каких товаров заказали у нас.
Тест записывает в базу два заказа, после чего проверяет суммарное значение, возвращаемое новым методом get_aggregate_report:
def test_report_returns_aggregated_qtys(self):
post_order(self.context, test_basic_operations.request1)
post_order(self.context, test_basic_operations.request2)
result = get_aggregate_report(self.context)
#Первого товара 8 штук: 5 в 1м заказе и 3 во 2м
self.assertEquals(8, result['A'])
#Второго товара 4 штуки во 2м заказе
self.assertEquals(4, result['B'])
Для реализации метода get_aggregate_report мы воспользуемся представлением OrderedQty, которое, напомню, в CelestaSQL-файле выглядит так:
create view OrderedQty as
select item_id, sum(qty) as qty from OrderLine group by item_id;
Запрос стандартный: мы суммируем строки заказов по количеству и группируем по коду товара. Для представления уже создался курсор OrderedQtyCursor, которым мы можем воспользоваться. Мы объявляем этот курсор, итерируем по нему и собираем нужный JSON:
def get_aggregate_report(context):
result = {}
ordered_qty = OrderedQtyCursor(context)
for ordered_qty in ordered_qty.iterate():
result[ordered_qty.item_id] = ordered_qty.qty
return result
Материализованные представления Celesta
Чем плохо использование представления для получения агрегированных данных? Этот подход вполне работоспособен, но в действительности он подкладывает бомбу замедленного действия под всю нашу систему: ведь представление, которое является SQL-запросом, выполняется все медленнее и медленнее по мере накопления данных в системе. Ему придется суммировать и группировать все больше строк. Как этого избежать?
Celesta старается все стандартные задачи, с которыми постоянно сталкиваются программисты бизнес-логики, реализовать на уровне платформы.
В MS SQL Server есть прекрасная концепция материализованных (индексированных) представлений, которые хранятся как таблицы и быстро обновляются по мере того, как изменяются данные в исходных таблицах. Если бы мы работали в «чистом» MS SQL Server, то для нашего случая замена представления на индексированное была бы как раз то, что надо: извлечение агрегированного отчёта не замедлялось бы по мере накопления данных, а работа по обновлению агрегированного отчёта выполнялась бы в момент вставки данных в таблицу строк заказа и также не сильно увеличивалась бы при росте числа строк.
Но мы работаем с PostgreSQL через Celesta. Что мы можем сделать? Переопределим представление, добавив слово materialized:
create materialized view OrderedQty as
select item_id, sum(qty) as qty from OrderLine group by item_id;
Запустим систему и посмотрим, что сделалось с базой данных.
Мы заметим, что представление OrderedQty исчезло, а вместо него появилась таблица OrderedQty. При этом, по мере наполнения данными таблицы OrderLine, в таблице OrderedQty будет «волшебным образом» обновляться информация, так, как будто бы OrderedQty являлось бы представлением.
Никакого волшебства тут нет, если мы взглянем на триггеры, построенные на таблице OrderLine. Celesta, получив задачу создать «материализованное представление», проанализировала запрос и создала триггеры на таблице OrderLine, обновляющие OrderedQty. Вставкой единственного ключевого слова — materialized — в CelestaSQL-файл мы решили проблему деградации производительности, а код бизнес-логики даже не потребовалось изменять!
Естественно, этот подход имеет свои, и довольно жёсткие, ограничения. «Материализованными» в Celesta могут становиться только представления, построенные на одной таблице, без JOIN-ов, с агрегацией по GROUP BY. Однако этого достаточно для того, чтобы строить, например, ведомости остатков средств по счетам, товаров по ячейкам склада и т. п. часто встречающиеся на практике отчёты.
Flute: REST-endpoints, расписания, очереди и т. п.
В конце нашего введения в Celesta остаётся обсудить, как код, который мы запускали в IDE как модульный тест «связать с внешним миром», превратить в работающий сервис.
Например, это можно сделать, взяв Maven-зависимость Celesta в ваш Java-проект и запуская нужные методы через Celesta.getInstance().runPython(<трёхкомпонентное имя процедуры>).
Но можно обойтись и вовсе без Java-программирования. У нас есть модуль, называемый Flute (он же — «Флейта»), который устанавливается как сервис на Windows и Linux. Он использует Celesta и реализует много способов, которые позволят ваши скрипты «проигрывать». Вот эти способы:
- поднимать REST-сервис и мапить запуск задач на URL-ы
- подхватывать задачи из очереди Redis или SQL-таблицы
- выполнять процедуры по CRON-расписанию
- выполнять процедуры раз за разом в бесконечном цикле с заданной паузой между выполнениями
Каким образом создаётся REST-endpoint во «Флейте»? Примерно так же, как в Spring, в Java:
# coding=utf-8
from flute.mappingbuilder import mapping
@map('/foo')
def processor(context, request, response):
# whatever
В данном случае декоратор map указывает системе Flute, с каким URL-ом будет связан данный код.
Модуль Flute конфигурируется через файл flute.xml примерно следующего содержания:
<config>
<!--общие параметры подключения к базе данных-->
<dbconnstring>jdbc:postgresql://127.0.0.1:5432/celesta</dbconnstring>
<dbuser>postgres</dbuser>
<dbpassword>123</dbpassword>
<!--Если используем Redis, то задаём его здесь-->
<redishost>localhost</redishost>
<redisport>6379</redisport>
<!--Самое главное: путь к папке Celesta score-->
<scorepath>D:/score2</scorepath>
<!--Порт, на котором будут работать REST-сервисы-->
<restport>8888</restport>
...
<!--имя очереди Redis-->
<redisqueue>
<queuename>q1</queuename>
</redisqueue>
<!-- задача, выполняющаяся по CRON-расписанию каждые пять минут-->
<scheduledtask>
<schedule>5 * * * *</schedule>
<script>foo.module.script</script>
</scheduledtask> ... </config>
Подробное описание возможностей Flute приведено в документации.
Заключение
Мы пробежались по основным возможностям системы Celesta и Flute. Если вас заинтересовала наша технология — добро пожаловать к нам на сайт и в нашу wiki. А также приходите в сентябре на встречу jug.msk.ru, где мы всё покажем «вживую» и ответим на все вопросы!
Комментарии (5)

IvanPonomarev Автор
07.09.2017 14:211. Вы не первый, кто указывает на эту проблему. С хранением времени у нас пока костыльно. Сейчас всё время мы при записи в БД сводим к московскому, в т. ч. для систем, работающих по всей России. Мы однако ж постоянно улучшаемся, поэтому скоро, думаю, этот вопрос будет проработан.
2. :-) Тем, что для обновления своего содержимого он требует REFRESH MATERIALIZED VIEW. Рефрешить нельзя после каждой операции на зависимой таблице, т. к. это дорого обойдётся. Рефрешить периодически раз в сутки? — мы имеем неактуальные данные в сводном представлении.
3. То, что Вы описали, действительно имеет место в Indexed Views для SQL Server, и тем они хороши. Не знаю, как обстоит дело в Materialized views для PostgreSQL сегодня, но кажется ещё несколько лет назад у них этого не было и там то ли собирались внедрить это, то ли это существовало с какими-то ограничениями. Если говорить об обычном, не материализованном view вида select sum..group by, то он будет деградировать по мере роста количества записей.

ahdenchik
08.09.2017 10:08Ок, ещё вопрос: Celesta внутри себя содержит свои собственные реализации триггеров, курсоров, serializable транзакций?
ahdenchik
Спасибо, интересная идея и продукт. Я как раз из стана людей готовых «браться за любую задачу на системе разработки общего назначения», но уже наелся полной ложной этого подхода.
Вопросы:
1. Почему для хранения времени используется только TIMESTAMP? Единственный тип (по крайней мере, в Postgres), который позволяет безопасно хранить время в моменты переводов стрелок часов назад это timestamp with timezone.
2. В PostgreSQL тоже существует MATERIALIZED VIEW — чем он не подошёл?
3.
Тут что-то не то! Насколько я понимаю, если правильно расставить индексы то такого происходить не должно, потому что движок БД группирует запрос с тем, который записан в VIEW, а не парсит полностью весь VIEW целиком внешним SQL-запросом. То есть, тормозить не должно…
IvanPonomarev Автор
см. ответ ниже
fiddle-de-dee
Конечно, движок БД работает именно так, как Вы пишите, и получает агрегаты максимально быстро с учетом всех индексов и его понимания требуемого порядка выполнения операций над данными. Но получение агрегатов — это в любом случае затратная операция. Как ни крути, цифры (пусть даже только те, что нужно и без лишних отягощений) надо считать и сложить.