
Многие организации различных сфер деятельности, таких как энергетика, транспорт, ритейл, связь, ТЭК, банки, финансовые институты, атомная, горнодобывающая, металлургическая промышленность и компании из других отраслей, сталкиваются с необходимостью ввода в эксплуатацию одновременно большого количества новых информационных систем, включая их разработку и тестирование.
Ввод в эксплуатацию каждой новой информационной системы – корпоративного приложения, средства ИТ, решения по обеспечению информационной безопасности, различных разработанных приложений, всегда сопровождается процессом формирования тестовых сред и наполнения их тестовыми данными. Для этого компаниям приходится реплицировать базы данных для обеспечения процесса тестирования систем.
Для наглядности обозначим ключевые этапы проекта по внедрению информационной системы, где может понадобиться использование тестовых данных (рис.1).

Рис.1
Этап тестирования внедряемых информационных систем включает в себя:
• подготовку тестовых сред;
• внесение данных;
• проверку работоспособности внедряемой системы, верификацию и валидацию разрабатываемого ПО;
• исправление обнаруженных ошибок.
На данных этапах компании сталкиваются с организационными вопросами по получению тестовых данных для проведения работ по внедрению информационных систем как внутренними силами, так и силами привлеченных подрядных организаций. Основная проблема состоит в том, что копии рабочих данных часто содержат критически важную для компании информацию (рис.2), вследствие чего часто возникают внутренние конфликты между владельцами этих данных и лицами, которым они необходимы для тестирования, а также необходимостью соблюдения требований внутренних и внешних стандартов. Процесс согласования выдачи данных их владельцами и назначение ответственных лиц за процесс тестирования занимает неопределенное время, приходится ждать гораздо больше планируемого в рамках проекта времени. Все это затягивает сроки запуска систем в эксплуатацию и, соответственно, может привести к денежным и репутационным потерям.

Рис.2
В процессе внедрения нового решения в промышленную эксплуатацию могут принимать участие собственные сотрудники организации, временные работники, стажеры и сотрудники аутсорсинговых компаний/партнеров. Например, разработчики, программисты, аналитики, тестировщики, администраторы баз данных, а также сотрудники департаментов, контролирующих процесс (рис.3).

Рис.3
От участвующих в данном процессе исходит огромное количество запросов/вопросов, таких как (рис.4):
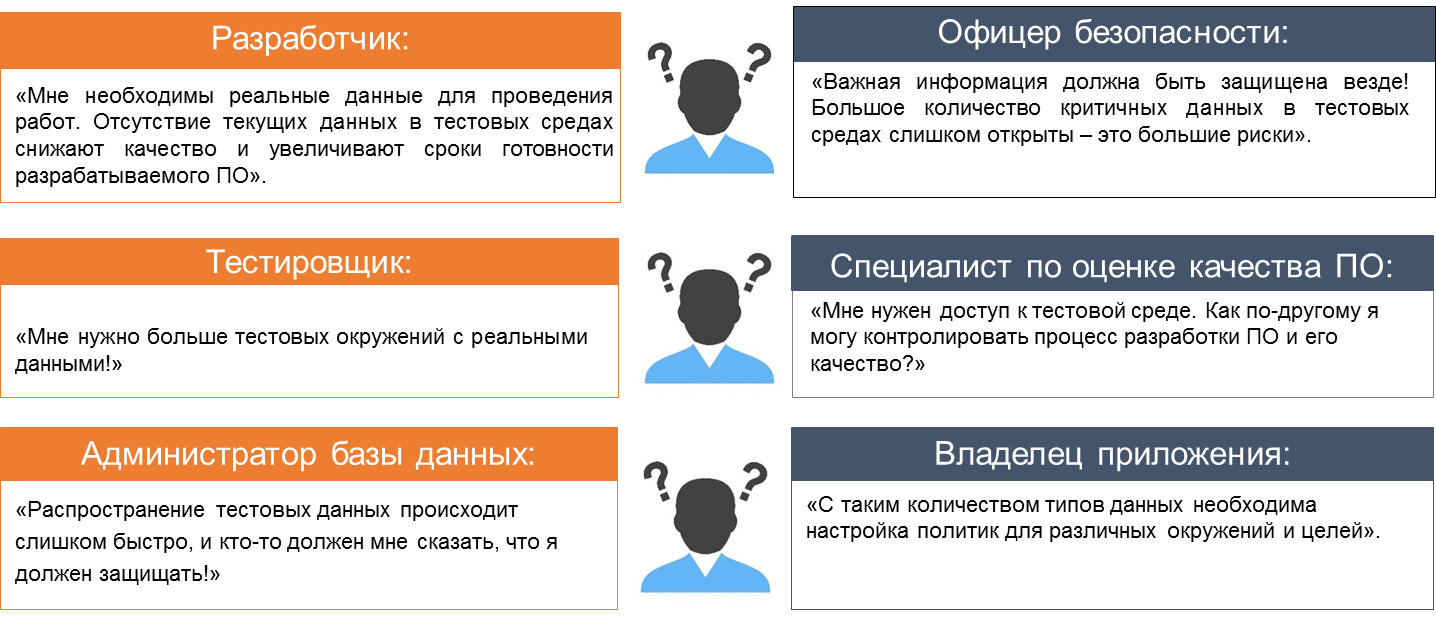
Рис.4
Также можно выделить следующие проблемы, возникающие при работе с тестовыми данными:
• несанкционированный доступ к данным большого количества людей без должных полномочий;
• отсутствие политик безопасности и средств защиты данных в тестовых окружениях и средах разработки;
• отсутствие процесса контроля передачи критичных данных сторонним компаниям (внешние разработчики, тестировщики/ партнеры);
• возможность использования полученной информации из тестовых систем для организации атак на продуктивную систему;
• процесс ручного или полуавтоматического обезличивания данных трудоемок и подвержен ошибкам;
• процесс ручного или полуавтоматического усечения базы данных для тестирования трудоемок и подвержен ошибкам.
Для исключения такого рода проблем и ускорения процесса получения доступа к тестовым данным, а также защиты информации от внешних и внутренних угроз, возникающих в тестовых окружениях, может помочь применение средств маскирования данных.
Маскирование данных – это технология, позволяющая предотвратить неправомерное использование критичных данных с помощью предоставления пользователям неверных/фиктивных данных, но выглядящих правдоподобно (далее – реалистичных), вместо реальных данных. Приведем наглядный пример, как же могут выглядеть маскированные данные (рис. 5).
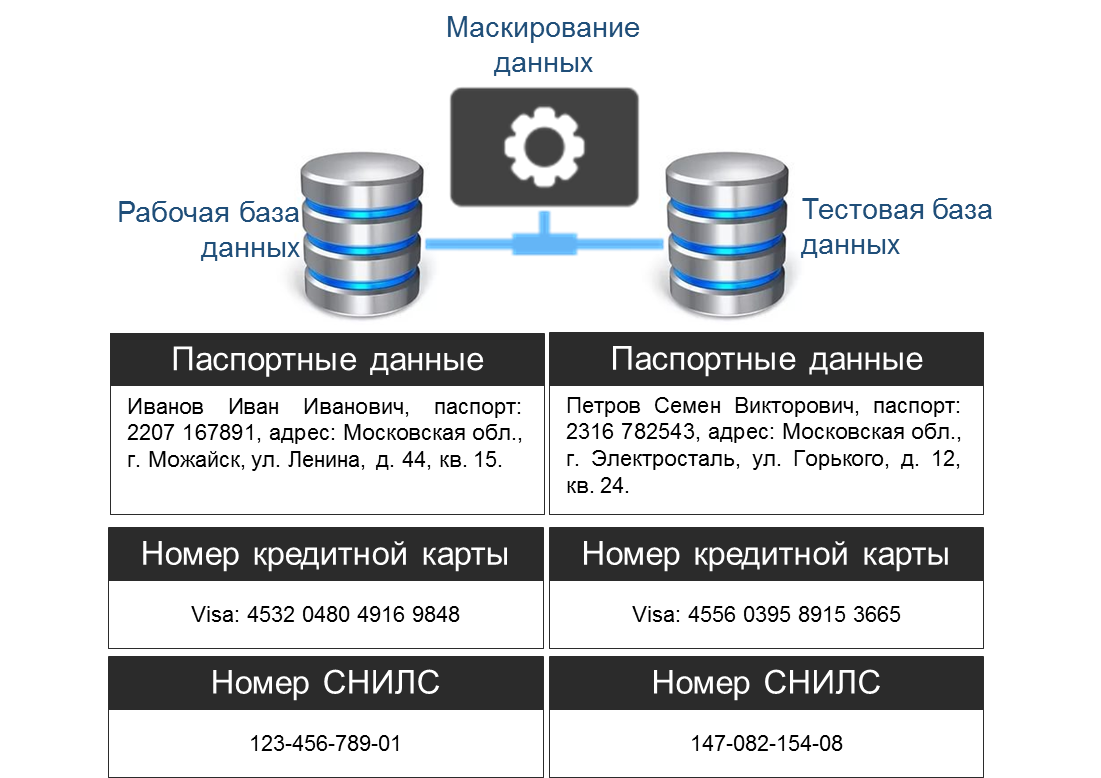
Рис.5
Существует несколько видов маскирования данных:
• статическое маскирование – используется для защиты данных, хранящихся в тестовых средах;
• динамическое маскирование – предусматривает подмену критичных данных в режиме реального времени при обращении к производственной базе данных. Реальные данные не покидают базу данных; они заменяются на этапе запроса, например, на полностью реалистичные, без промежуточной записи.
В данной статье мы рассмотрим применение метода статического маскирования, его преимущества и опишем возникающие проблемы при тестировании ПО без его применения.
Статическое маскирование – это необратимый процесс замены критичных данных на реалистичные, основанный на заданных правилах, при котором данные преобразуются в одном направлении, а первоначальные данные не могут быть получены, извлечены или восстановлены, в отличие от шифрования и токенизации, которые позволяют обратить процесс преобразования данных, тем самым увеличивая риск утечки критичной информации.
Процесс статического маскирования данных специализированными средствами выглядит так:
• создание копии производственной базы данных сотрудниками с соответствующими правами доступа;
• урезание объёма содержащихся в базе данных сведений по настроенным правилам (при необходимости);
• поиск критичных данных в копии БД на основании заданных шаблонов поиска;
• маскирование найденных критичных данных по настроенным шаблонам и правилам;
• предоставление замаскированной копии базы данных разработчикам/тестировщикам.
Статическое маскирование применяется для аналитики, проведения обучающих курсов, с необходимостью использования реалистичных данных, разработки ПО и тестирования приложений (Рис 6.).
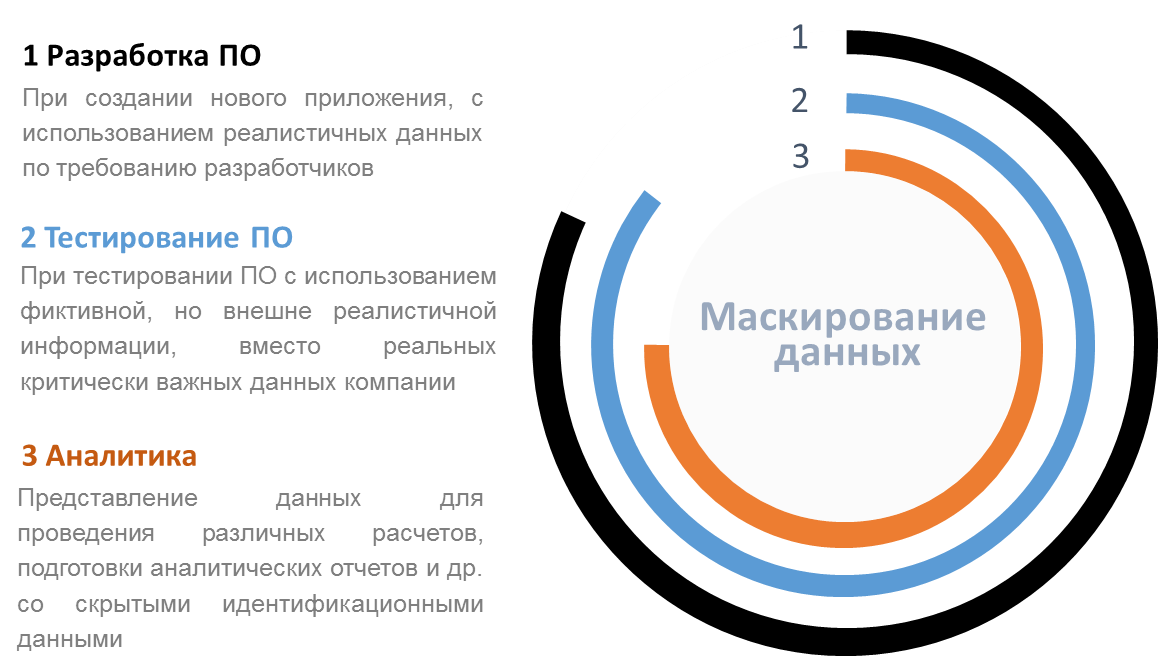
Рис.6
Применение средств статического маскирования данных может помочь предприятиям в снижении рисков потери критичных данных, их защите, а также соответствия требованиям внешних и внутренних регуляторов и стандартов ИБ (например, PCI DSS, ФЗ-152). Использование технологии статического маскирования данных гарантирует, что критичные данные не попадут в непроизводственные среды (среды разработки, тестирования), при этом возможность использования этих защищаемых данных в нужном объеме сотрудниками компании или привлекаемыми подрядными организациями сохранится.
Решения по статическому маскированию данных позволяют оперативно предоставлять защищенные копии в нужном количестве с реалистичными данными для передачи в тестовые окружения в соответствии с установленными правилами безопасности. Тем самым повышая эффективность работы администраторов баз данных при подготовке тестовых окружений, а также в дополнение, в зависимости от конкретного решения по статическому маскированию, сокращения объемов, хранимых данных путем корректного урезания баз данных при необходимости.
Ввод новых решений в эксплуатацию и их тестирование, а также разработка приложений и создание отчетов с применением решения по статическому маскированию данных занимает гораздо меньше времени: программисты, инженеры, тестировщики, разработчики могут быстро развертывать новые тестовые среды и проводить тестовые прогоны.
Благодаря этому, проекты выполняются в срок, без привлечения большого числа участников, в том числе к решению вопросов по выдаче прав доступа к данным, что позволяет компаниям минимизировать трудозатраты при вводе новой информационной системы в эксплуатацию, повышает производительность администраторов, устраняет ручные процессы и помогает последовательно применять политики информационной безопасности, тем самым снижая вероятность потери критичных данных в непроизводственных средах.
Автор: Яна Шевченко, менеджер отдела по продвижению решений компании «Информзащита», y.shevchenko@infosec.ru
Ввод в эксплуатацию каждой новой информационной системы – корпоративного приложения, средства ИТ, решения по обеспечению информационной безопасности, различных разработанных приложений, всегда сопровождается процессом формирования тестовых сред и наполнения их тестовыми данными. Для этого компаниям приходится реплицировать базы данных для обеспечения процесса тестирования систем.
Для наглядности обозначим ключевые этапы проекта по внедрению информационной системы, где может понадобиться использование тестовых данных (рис.1).
Рис.1
Этап тестирования внедряемых информационных систем включает в себя:
• подготовку тестовых сред;
• внесение данных;
• проверку работоспособности внедряемой системы, верификацию и валидацию разрабатываемого ПО;
• исправление обнаруженных ошибок.
На данных этапах компании сталкиваются с организационными вопросами по получению тестовых данных для проведения работ по внедрению информационных систем как внутренними силами, так и силами привлеченных подрядных организаций. Основная проблема состоит в том, что копии рабочих данных часто содержат критически важную для компании информацию (рис.2), вследствие чего часто возникают внутренние конфликты между владельцами этих данных и лицами, которым они необходимы для тестирования, а также необходимостью соблюдения требований внутренних и внешних стандартов. Процесс согласования выдачи данных их владельцами и назначение ответственных лиц за процесс тестирования занимает неопределенное время, приходится ждать гораздо больше планируемого в рамках проекта времени. Все это затягивает сроки запуска систем в эксплуатацию и, соответственно, может привести к денежным и репутационным потерям.
Рис.2
В процессе внедрения нового решения в промышленную эксплуатацию могут принимать участие собственные сотрудники организации, временные работники, стажеры и сотрудники аутсорсинговых компаний/партнеров. Например, разработчики, программисты, аналитики, тестировщики, администраторы баз данных, а также сотрудники департаментов, контролирующих процесс (рис.3).
Рис.3
От участвующих в данном процессе исходит огромное количество запросов/вопросов, таких как (рис.4):
Рис.4
Также можно выделить следующие проблемы, возникающие при работе с тестовыми данными:
• несанкционированный доступ к данным большого количества людей без должных полномочий;
• отсутствие политик безопасности и средств защиты данных в тестовых окружениях и средах разработки;
• отсутствие процесса контроля передачи критичных данных сторонним компаниям (внешние разработчики, тестировщики/ партнеры);
• возможность использования полученной информации из тестовых систем для организации атак на продуктивную систему;
• процесс ручного или полуавтоматического обезличивания данных трудоемок и подвержен ошибкам;
• процесс ручного или полуавтоматического усечения базы данных для тестирования трудоемок и подвержен ошибкам.
Для исключения такого рода проблем и ускорения процесса получения доступа к тестовым данным, а также защиты информации от внешних и внутренних угроз, возникающих в тестовых окружениях, может помочь применение средств маскирования данных.
Маскирование данных – это технология, позволяющая предотвратить неправомерное использование критичных данных с помощью предоставления пользователям неверных/фиктивных данных, но выглядящих правдоподобно (далее – реалистичных), вместо реальных данных. Приведем наглядный пример, как же могут выглядеть маскированные данные (рис. 5).
Рис.5
Существует несколько видов маскирования данных:
• статическое маскирование – используется для защиты данных, хранящихся в тестовых средах;
• динамическое маскирование – предусматривает подмену критичных данных в режиме реального времени при обращении к производственной базе данных. Реальные данные не покидают базу данных; они заменяются на этапе запроса, например, на полностью реалистичные, без промежуточной записи.
В данной статье мы рассмотрим применение метода статического маскирования, его преимущества и опишем возникающие проблемы при тестировании ПО без его применения.
Статическое маскирование – это необратимый процесс замены критичных данных на реалистичные, основанный на заданных правилах, при котором данные преобразуются в одном направлении, а первоначальные данные не могут быть получены, извлечены или восстановлены, в отличие от шифрования и токенизации, которые позволяют обратить процесс преобразования данных, тем самым увеличивая риск утечки критичной информации.
Процесс статического маскирования данных специализированными средствами выглядит так:
• создание копии производственной базы данных сотрудниками с соответствующими правами доступа;
• урезание объёма содержащихся в базе данных сведений по настроенным правилам (при необходимости);
• поиск критичных данных в копии БД на основании заданных шаблонов поиска;
• маскирование найденных критичных данных по настроенным шаблонам и правилам;
• предоставление замаскированной копии базы данных разработчикам/тестировщикам.
Статическое маскирование применяется для аналитики, проведения обучающих курсов, с необходимостью использования реалистичных данных, разработки ПО и тестирования приложений (Рис 6.).
Рис.6
Применение средств статического маскирования данных может помочь предприятиям в снижении рисков потери критичных данных, их защите, а также соответствия требованиям внешних и внутренних регуляторов и стандартов ИБ (например, PCI DSS, ФЗ-152). Использование технологии статического маскирования данных гарантирует, что критичные данные не попадут в непроизводственные среды (среды разработки, тестирования), при этом возможность использования этих защищаемых данных в нужном объеме сотрудниками компании или привлекаемыми подрядными организациями сохранится.
Решения по статическому маскированию данных позволяют оперативно предоставлять защищенные копии в нужном количестве с реалистичными данными для передачи в тестовые окружения в соответствии с установленными правилами безопасности. Тем самым повышая эффективность работы администраторов баз данных при подготовке тестовых окружений, а также в дополнение, в зависимости от конкретного решения по статическому маскированию, сокращения объемов, хранимых данных путем корректного урезания баз данных при необходимости.
Ввод новых решений в эксплуатацию и их тестирование, а также разработка приложений и создание отчетов с применением решения по статическому маскированию данных занимает гораздо меньше времени: программисты, инженеры, тестировщики, разработчики могут быстро развертывать новые тестовые среды и проводить тестовые прогоны.
Благодаря этому, проекты выполняются в срок, без привлечения большого числа участников, в том числе к решению вопросов по выдаче прав доступа к данным, что позволяет компаниям минимизировать трудозатраты при вводе новой информационной системы в эксплуатацию, повышает производительность администраторов, устраняет ручные процессы и помогает последовательно применять политики информационной безопасности, тем самым снижая вероятность потери критичных данных в непроизводственных средах.
Автор: Яна Шевченко, менеджер отдела по продвижению решений компании «Информзащита», y.shevchenko@infosec.ru