
Постановка вопроса
Недавно, во время собеседования в одну крупную компанию мне задали простой вопрос, что такое Load Average. Не знаю, на сколько правильно я ответил, но лично для себя пришло осознание, что точного ответа я на самом деле и не знаю.
Большинство людей наверняка знают, что Load Average — это среднее значение загрузки системы за некоторый период времени (1, 5 и 15 минут). Так же можно узнать некоторые подробности из данной статьи, про то, как этим пользоваться. В большинстве случаев этих знаний достаточно для того, что бы по значению LA оценивать загрузку системы, но я по специальности физик, и когда я вижу «среднее за промежуток времени» мне сразу становится интересна частота дискретизации на данном промежутке. А когда я вижу термин «ожидающие ресурсов», становится интересно, каких именно и сколько времени надо ждать, а так же сколько тривиальных процессов надо запустить, что бы получить за короткий промежуток времени высокий LA. И главное, почему ответы на эти вопросы не дает 5 минут работы с гуглом? Если вам данные тонкости так же интересны, добро пожаловать под кат.
Что-то здесь не так...
Для начала определимся с тем, что мы знаем. В общем виде Load Average это среднее количество ожидающих ресурсов ЦПУ процессов за один из трех промежутков времени. Так же нам известно, что это значение в нормальном состоянии находится в диапазоне от 0 до 1, и единица соответствует 100% загрузке одноядерной системы без перегруза. В дальнейшем я буду рассматривать систему как одноядерную, поскольку это проще и показательней.
Что здесь не так?
Во первых, все мы знаем, что среднее арифметическое нескольких величин равно сумме этих величин, деленной на их количество. Из той информации, что у нас есть абсолютно непонятно это самое количество. Если мы считаем ожидающие процессы в течении всей минуты, то среднее значение будет равно количеству процессов за минуту, деленному на единицу. Если будем считать каждую секунду — то и количество процессов в каждом подсчете уменьшится с диапазоном, и делить будем на 60. Таким образом чем выше частота дискретизации при наборе данных, тем меньшее среднее значение мы получим.
Во вторых что значит «ожидающий ресурсов процесс»? Если мы запустим большое количество быстрых процессов разом, то все они встанут в очередь, и по логике на короткий промежуток времени LA должен вырасти до совершенно неприемлемых величин, и при продолжительном мониторинге должны наблюдаться постоянные скачки, чего, в нормальной ситуации, нет.
В третьих, одноядерная система при 100% загрузке должна давать Load Average равный 1. Но здесь нет никакой зависимости от параметров этого ядра, хотя количество процессов может отличаться в разы. Данный вопрос может быть снят либо корректным определением «ожидающего ресурсов процесса», либо наличием какой-то нормировки на параметры ядра.
Литература
Найти ответы на поставленные вопросы оказалось не так уж и сложно. Правда только на английском языке, и не все так сходу стало понятно. Конкретно были найдены две статьи:
«Examining Load Average»
«UNIX Load Average»
Пользователь Rondo так же предложил вторую часть статьи с более подробным рассмотрением математического аппарата: «UNIX Load Average. Part 2»
А так же небольшой тест для тех, кто и так все понимает, указанный во второй статье.
Интересующимся я бы советовал прочитать обе статьи, хотя в них описаны очень близкие вещи. В первой описывается в общем виде много разных интересных подробностей работы системы, а во второй более подробно разбирается непосредственно расчет LA, приводятся примеры с нагрузкой и комментарии специалистов.
Немного ядерной магии
Из данных материалов можно узнать, что каждому вызываемому процессу дается ограниченный промежуток времени на использование CPU, в стандартной архитектуре intel этот промежуток равен 10мс. Это целая сотая доля секунды и в большинстве случаев процессу столько времени не нужно. Однако, если какой-то процесс использовал все отведенное ему время, то вызывается аппаратное прерывание и система возвращает себе управление процессором. Помимо этого каждые 10мс увеличивая счетчик тиков (jiffies counter). Данные тики считаются с момента запуска системы и каждые 500 тиков (раз в 5 секунд) рассчитывается Load Average.
Код непосредственно расчета находится в ядре в файле timer.c (код приведен для версии 2.4, в версии 2.6 все это несколько рассредоточено, но логика не изменилась, дальше, надеюсь, тоже существенных изменений нет, но, честно говоря, последние релизы не проверял):
646 unsigned long avenrun[3];
647
648 static inline void calc_load(unsigned long ticks)
649 {
650 unsigned long active_tasks; /* fixed-point */
651 static int count = LOAD_FREQ;
652
653 count -= ticks;
654 if (count < 0) {
655 count += LOAD_FREQ;
656 active_tasks = count_active_tasks();
657 CALC_LOAD(avenrun[0], EXP_1, active_tasks);
658 CALC_LOAD(avenrun[1], EXP_5, active_tasks);
659 CALC_LOAD(avenrun[2], EXP_15, active_tasks);
660 }
661 }
Как видно, рассчитываются по очереди те самые три значения LA, однако не указано, что именно считается, и как именно считается. Это тоже не проблема, код функции count_active_tasks() находится в том же файле, чуть выше:
625 static unsigned long count_active_tasks(void)
626 {
627 struct task_struct *p;
628 unsigned long nr = 0;
629
630 read_lock(&tasklist_lock);
631 for_each_task(p) {
632 if ((p->state == TASK_RUNNING ||
633 (p->state & TASK_UNINTERRUPTIBLE)))
634 nr += FIXED_1;
635 }
636 read_unlock(&tasklist_lock);
637 return nr;
638 }
А CALC_LOAD лежит в sched.h вместе с несколькими интересными константами:
61 #define FSHIFT 11 /* nr of bits of precision */
62 #define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point */
63 #define LOAD_FREQ (5*HZ) /* 5 sec intervals */
64 #define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
65 #define EXP_5 2014 /* 1/exp(5sec/5min) */
66 #define EXP_15 2037 /* 1/exp(5sec/15min) */
67
68 #define CALC_LOAD(load,exp,n) 69 load *= exp; 70 load += n*(FIXED_1-exp); 71 load >>= FSHIFT;
Из всего вышеперечисленного можно сказать, что раз в 5 секунд ядро смотрит, сколько всего процессов находится в состоянии RUNNING и UNINTERRUPTIBLE (кстати в других UNIX системах это не так) и для каждого такого процесса увеличивает счетчик на FIXED_1, что равняется 1<<FSHIFT, или 1<<11, что равносильно 2^11. Сделано это для симуляции расчета с плавающей точкой при использовании стандартных int переменных длинной 32 бита. Смещая после расчетов результат на 11 бит вправо мы отбросим лишние порядки. Из того же sched.h:
49 /*
50 * These are the constant used to fake the fixed-point load-average
51 * counting. Some notes:
52 * - 11 bit fractions expand to 22 bits by the multiplies: this gives
53 * a load-average precision of 10 bits integer + 11 bits fractional
54 * - if you want to count load-averages more often, you need more
55 * precision, or rounding will get you. With 2-second counting freq,
56 * the EXP_n values would be 1981, 2034 and 2043 if still using only
57 * 11 bit fractions.
58 */
Немного ядерного распада
Нет, тут не распадается ядро системы, просто формула CALC_LOAD, по которой считается Load Average основана на законе радиоактивного распада, или просто экспоненциального затухания. Данный закон есть не что иное, как решение дифференциального уравнения
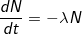 , то-есть каждое новое значение рассчитывается из предыдущего и скорость уменьшения количества элементов напрямую зависит от количества элементов.
, то-есть каждое новое значение рассчитывается из предыдущего и скорость уменьшения количества элементов напрямую зависит от количества элементов.Решением данного дифференциального уравнения является экспоненциальный закон:
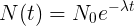
Фактически Load Average не является средним значением в обычном понимании среднего арифметического. Это дискретная функция, периодически рассчитываемая с момента запуска системы. При этом значение функции есть количество отрабатывающих в системе процессов в условиях экспоненциального затухания.
Такую конструкцию мы наблюдаем, переписав расчетную часть CALC_LOAD математическим языком:
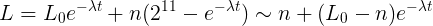
2^11 для нас в данному случае равносильно единице, мы ее зафиксировали изначально и добавляли везде, количество новых процессов так же рассчитывается в этих величинах. А
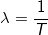 , где T — интервал измерения (1, 5 или 15 минут).
, где T — интервал измерения (1, 5 или 15 минут).Стоит заметить, что при фиксированном временном интервале и фиксированном времени между измерениями значения экспоненты вполне могут быть посчитаны заранее и использоваться как константа, что в коде и делается. Последняя операция — смещение вправо на 11 бит дает нам искомое значение Load Average с отбрасыванием нижних порядков.
Выводы
Теперь, понимая, как расчитывается LA можно попробовать ответить на вопросы, поставленные в начале статьи:
1) Среднее значение не является средним арифметическим, а есть среднее значение функции, которая рассчитывается каждые 5 секунд с момента старта системы.
2) «Ожидающими ресурсов CPU» считаются все процессы, находящиеся в состоянии RUNNING и UNINTERRUPTIBLE. А существенных скачков Load Average при продолжительном мониторинге мы не наблюдаем, поскольку затухающая экспонента играет роль сглаживающей функции (хотя при рассмотрении периода в 1 минуту их можно заметить).
3) А вот тут один из самых интересных выводов. Дело в том, что указанная выше функция Load Average при любых значениях n монотонно возрастает к этому значению, если же n<L — экспоненциально затухает к нему же. Таким образом LA=1 говорит о том, что в любой момент времени CPU занят одним единственным процессом и очереди никакой нет, что в целом можно считать 100% загрузкой, не больше, не меньше. В то же время LA<1 говорит о том, что CPU простаивает, а если у вас есть множество процессов, которые стучатся на нерабочий nfs то можно увидеть и
Однако помимо ответов на имевшиеся изначально вопросы разбор кода ставит и новые. Например, применима ли затухающая экспонента к сокращению числа ожидающих процессов? Если мы рассматриваем радиоактивный распад, то его скорость ограничена лишь количеством ядер, в нашем же случае, при большом количестве процессов все все упрется в пропускную способность CPU. Так же, если сравнить полученную формулу с экспоненциальным законом, становится видно, что
, где T — продолжительность интервала набора данных (1, 5 или 15 минут). Таким образом разработчики ядра считают, что скорость уменьшения Load Average обратно пропорциональна продолжительности измерений, что несколько неочевидно, по крайней мере для меня. Ну и не сложно смоделировать ситуации, когда огромные значения LA не будут реально отображать загрузку системы, или наоборот.В конечном счете складывается впечатление, что для расчета Load Average была выбрана сглаживающая функция, максимально быстро уменьшающая свое значение, что в целом логично для получения конечно числа, но не отображает реально происходящего процесса. И если кто-нибудь мне объяснит, почему именно экспонента и почему именно в таком виде, буду весьма признателен.
Комментарии (34)

AxisPod
16.06.2015 18:22+2Как-то без собеседования захотелось узнать что это такое, почитал официальный ман и всё понял. С другой стороны подобные вопросы, это не способ найти кандидата, а способ повыпендриваться перед ним, в самом лучшем случае это психологический вопрос не влияющий на результат собеседования, в худшем как и сказал — повыпендриваться. Но разбор данного вопроса хорош. Ябвзял на работу :-)

amarao
16.06.2015 18:31+6Это зависит от настроения, с которым кандидат пришёл. Я первый раз почувствовал на собеседовании интерес, когда меня не спрашивали общеобтекающими фразами про моё видение меня в их компании, а задали крайне каверзный вопрос, ответа на который я не знал и который мне пришлось срочно придумывать в режиме мозгового штурма.
Каверзные вопросы (не вида «чему равен FIXED_1 на 64-битных системах?»), а подразумевающий некие тонкие процессы в системе — это отличный повод поговорить по теме. Гипотезы (в т.ч. неверные), которые высказывает кандидат позволяют лучше оценить его ход мысли и способности, чем готовый ответ (42).
Другое дело, если кандидат воспринимает вопрос на который он не знает ответа как «всё пропало, собеседование провалено». Ещё хуже, если его таковым воспринимает кто-то из собеседующих. Но это вопрос корпоративной культуры, и лучше не пройти на собеседовании, чем обнаружить эту «культуру» в полной красе спустя пару месяцев потраченного времени на освоение никому не полезных особенностей жизни компании.AxisPod
16.06.2015 18:44Ну как я и сказал, это уже скорее психологический вопрос, правильный ответ не требуется, а требуется ход размышления соискателя. Тоже задаю подобные вопросы, но просто не на столько каверзные.

Rondo
16.06.2015 18:41+2Во второй части статьи в PDF больше объяснений, а мне уже не удобно самого себя цитировать дважды:
Процитирую свой же комментарий в статье "CPU Load: когда начинать волноваться?"
В старом посте про load average давали ссылку на замечательную статью, где я и прочитал про это самое «экспоненциально взвешенное скользящее среднее»,
Очень рекомендую к прочтению, можно даже добавить в пост.
Часть 1 www.teamquest.com/pdfs/whitepaper/ldavg1.pdf
Часть 2 www.teamquest.com/pdfs/whitepaper/ldavg2.pdfZloyHobbit Автор
16.06.2015 19:01+1На самом деле цитировать подобные вещи надо везде, где только можно, а лучше прикреплять к постам. Поскольку если бы я сходу нашел содержимое этих статей на Хабре, то не пришлось бы ломать голову и разбираться в материале самостоятельно. Хотя последнее в конечном итоге весьма интересно.

foxmuldercp
16.06.2015 19:22Почему-то вспомнилось.
дано 8xXeon сервер 16G RAM
небольшой шаредхостинг под DDoS.
на LA= 1024 он у меня отвалился по ssh.
Я, к сожалению, не очень дружу с высшей математикой. но какое количество процессов там могло быть…
AlanDrakes
16.06.2015 19:52Дело было скорее не в количестве собственно процессов, а в очереди на обработку. SSH — сервис, чаще всего, имеет средний приоритет, в то время, как на сервере под DDoS будет большое количество процессов, требующих «немедленной» обработки большого количества ресурсов (а это как раз куча PHP и иже с ними). В таком случае, отклик системы будет очень большим, а иногда и просто начнут теряться пакеты (уже по таймауту обработки).
И как раз Load Average в Вашем случае указывал на то, что многим процессам необходимо обработать множество данных, но в настоящее время они ждутвторого пришествиясамой медленной части — диска.
Допустим, 100 процессов обратились к базе данных (например, MySQL), та ответила «Жди, я сейчас» и ушла на диск… 100 раз. В разные места. Диск в тихом шоке, и не может определить что считать ранее… потому читает частички из случайных мест… в итоге, все стоят и ждут. А фактически, в этот момент процессор не занят, ожидая появления флага «Дисковая операция завершилась».
У нас была аналогичная ситуация при проблеме с базой данных. Процессор 8 ядер (не Xeon, но серверный) был загружен на 30-50% (из 800 возможных), а вот диск…
«sar -d» неизменно выводил 99.99% активности диска.
SSH работал, процессы жили… но плохо. Load Average рос до 10-20.foxmuldercp
16.06.2015 20:04debian 7.8
#sar
Linux 3.2.0-4-amd64 (server.loc) 16.06.2015 _x86_64_ (8 CPU)
и весь вывод (


romka777
16.06.2015 19:43Наводящий вопрос:
А Вы не встречали такую ситуацию, когда LA на сервере около сотни, а нагрузка на каждое ядро меньше 10%?
vagran
16.06.2015 22:12+2в стандартной архитектуре intel этот промежуток равен 10мс
Вообще это определяется ОС, какой она выберет период для системного таймера, по которому контексты переключаются. От железа это особо не зависит.
Про экспонету — так работает rolling average.
en.wikipedia.org/?title=Moving_average
Там даже есть этот конкретный пример про длину очереди планировщика.ZloyHobbit Автор
16.06.2015 22:54+1Про 10мс, на самом деле не все так понятно. В первой из указанных мной статей сказано:
If the process uses its fully allotted CPU time of 10ms, an interrupt is raised by the hardware, and the kernel regains control from the process.
Что больше всего похоже на описание хардварного watchdog timer, вставленного на 10мс.
Так же есть описание от автора второй статьи, где сказано:
It is the name of a number. The actual value of that number is machine-
dependent. The following platforms use HZ == 100:
•Intel Pentium
•Power PC
•Ultra-SPARC
whereas the HP Alpha uses HZ == 1024 or HZ == 1200, depending on the CPU model. We’ll
assume HZ represents 100 in the subsequent explanation.
На сколько я понимаю, есть два параметра, которые в результате принимают одно значение, один из них хардварный, а другой — системный:
Every computer platform has a clock implemented in hardware that has a constant ticking
rate by which everything else in the system is synchronized. To make this ticking rate known
to the system, the hardware sends an interrupt to the Linux kernel on every clock tick. A HZ
value of 100 means that one second of wall-clock time corresponds to 100 CPU ticks.
Но если вы знаете как, это устроено на самом деле, то мне было бы интересно узнать подробное объяснение. Пока что мне кажется странным прерывание каждые 10мс, независимо от состояния системы, поскольку они с большой вероятностью попадут на нормально работающий процесс. А если они зависят от состояния системы, тогда 500 таких прерываний вовсе не гарантируют 5 секундного интервала.
Про экспоненту почитаю, спасибо.
INSTE
17.06.2015 01:44+8Ядро Linux разрабатывается как легко переносимое, потому у него нет жестких завязок на хардварные таймеры (если вы их сами не прикрутите).
То, что здесь названо CONFIG_HZ — это исторический системный таймер, к которому привязан счетчик jiffies, планировщик и классические struct timer. Он платформонезависим, а изменение значения jiffies с изменением реального времени связно при помощи соотношения dT (sec) = djiffies / CONFIG_HZ.
Да, исторически ядро всегда дергалось аппаратным прерыванием с константным рейтом раз в 1/CONFIG_HZ миллисекунд чтобы вызвать планировщик, произвести необходимые отложенные операции (например с RCU), а также обработать сработавшие struct timer, потому что это просто и переносимо. Плюс раньше процессоры были слабые, и обработка прерывания даже раз в 1 мс уже была слишком дорогой, а перепрограммировать системный таймер раз в прерывание тоже было дорого.
Но мощь ЦПУ роста, и со временем некоторым (как и вам) все больше и больше не нравилась постоянная обработка бесполезных прерываний аппаратного таймера (а заметная часть их бесполезна, особенно при малом количестве процессов в системе и отсутствии необходимости в обработке множества bottom-halves, tasklets и workqueues при низкой нагрузке на систему), потому придумали так называемый tickless-режим, задаваемый опцией CONFIG_NO_HZ (а старый обозвали FULL_HZ соответственно), в котором прерывания от аппаратного таймера включаются тогда, когда они нужны и хардварный таймер регулярно меняет рейт (подробное описание всех вариаций режима займет много времени, проще погуглить по «linux kernel tickless», идеальное начало тут: git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/Documentation/timers/NO_HZ.txt ); другим же товарищам стало мало точности в 1/CONFIG_HZ (реально, по меркам большинства подсистем ядра, особенно при современной мощности ЦПУ и сетевых картах в 40 GBps это целая вечность), потому ввели поддержку High-Precision Event Timers и новых struct hrtimer (High-Resolution Timers) с точностью вплоть до 1 нс.
Так что все течет, все меняется, и утверждения из комментария можно считать справедливыми разве что для ядер < 2.6 (и соответственно для 2003 года и раньше). Ну и на 2.4 вообще имхо сейчас стоит смотреть разве что с археологическими целями — тот же планировщик процессов в цикле разработки 2.6 был переписан неоднократно, его разработка постоянно приковывала к себе внимание и вызывала жаркие дискуссии.
vagran
17.06.2015 07:42+1Что больше всего похоже на описание хардварного watchdog timer, вставленного на 10мс.
Нет, это не watchdog, это именно таймер. Если быть точным в архитектуре IBM PC используется 8253 (точнее некое его обратно совместимое подобие в глубинах чипсета). Его частота настраивается, и может быть выбрана ОС. Кроме того ОС вообще вольна выбирать, что будет источником тиков для переключения контекстов, необязательно даже, что этот таймер (даже будучи запущенным на архитектуре IBM PC), и, конечно, необязательно на этой частоте.
Пока что мне кажется странным прерывание каждые 10мс, независимо от состояния системы, поскольку они с большой вероятностью попадут на нормально работающий процесс.
Никакой проблемы в этом нет. Если очень упрощённо, то когда срабатывает прерывание, ядро смотрит на текущий активный процесс (точнее поток, если ОС поддерживает потоки на уровне ядра). Если он работал непрерывно с предыдущего прерывания (а чтобы за этим следить, достаточно флаг выставлять в прерывании и сбрасывать при переключении контекста), то при наличии других процессов в очереди, контекст переключается, чтобы дать возможность поработать другим (в таком случае говорят, что процесс исчерпал свой time slot). Иначе он будет продолжать работать до следующего прерывания, или пока сам не отдаст контекст другим (зайдёт в ожидание). В реальности, конечно, всё намного сложнее, у процессов и потоков есть приоритеты, влияющие на этот процесс, которые к тому же могут динамически меняться, в зависимости от поведения процесса. Как написал товарищ выше, частота прерывания в современных ОС тоже может меняться динамически. А логика планировщика постоянно эволюционирует.

parpalak
17.06.2015 00:33+21,5 или 15 минут
Я прочитал половину текста, пока не понял, что после запятой пропущен пробел. Никак не мог понять, откуда взялись «полторы и пятнадцать минут» :) Добавьте пробел, пожалуйста: «1, 5 или 15 минут».
lexore
17.06.2015 01:40+1На мой взгляд, в статье не до конца раскрыто значение TASK_UNINTERRUPTIBLE.
Если вспомнить про машинки из этой статьи, то грубо говоря, LA показывает, сколько машинок едут, или стоят в ожидании ресурсов.
Ресурсы — это не столько CPU, сколько I/O.
Чаще всего это жесткий или сеть.
Приведу короткую цитату отсюда:
Thus the 3 factors that drive the Load Average on a Linux system are processes that are on the run-queue because they:
Таким образом, при хорошей нагрузке легко получить высокий LA при затупах дисковой или сетевой подсистемы (как из за аппаратных проблем, так и из за программных).
* Run on, or are waiting for, the CPU
* Perform disk I/O
* Perform network I/O
По своему опыту — на обычных задачах современный процессор редко становится причиной роста LA

simbajoe
17.06.2015 12:17-1сколько всего процессов находится в состоянии RUNNING и UNINTERRUPTIBLE
Вроде там написано не «и», а «или». То есть RUNNING или UNINTERRUPTIBLE.
632 if ((p->state == TASK_RUNNING || 633 (p->state & TASK_UNINTERRUPTIBLE))) 634 nr += FIXED_1;ZloyHobbit Автор
17.06.2015 13:07Это условный оператор на состояние процесса. Процесс не может быть одновременно и RUNNING, и UNINTERRUPTIBLE. Соответсвенно логическое ИЛИ дает нам выбор всех процессов, которые находятся в одном из двух состояний. Посчитаны будут и те и другие.
tsvetkovpa
17.06.2015 12:43Интересно, похоже на Exponentially Weighted Moving Average во всю применяющийся в эконометрике
ZloyHobbit Автор
17.06.2015 13:10Судя по всему, это именно оно и есть. Во второй части статьи в PDF это сглаживание называется «exponentially-damped moving average», или, как мне подсказали выше «rolling average».

alexxz
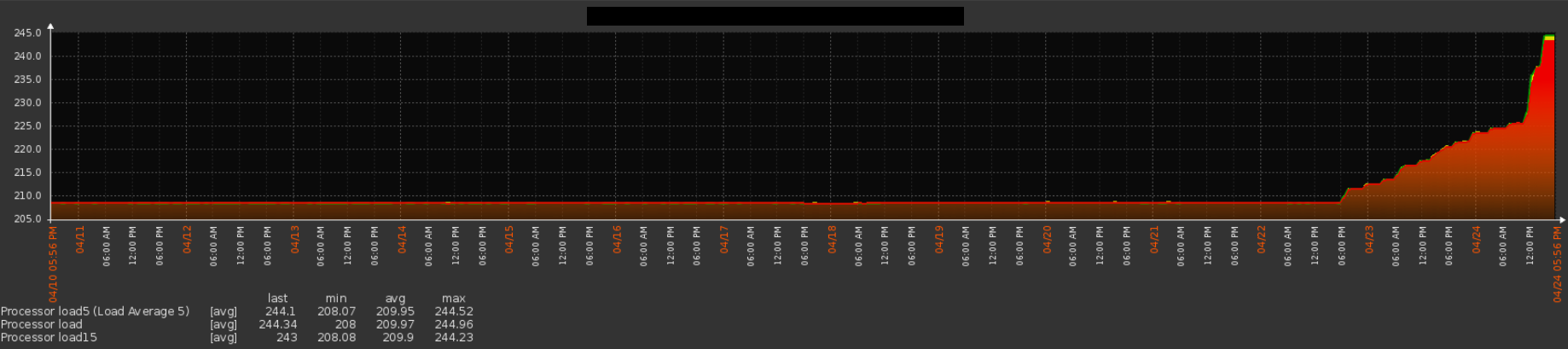
18.06.2015 10:26Ситуация, когда la > cpu, как правило, связана с IO. То есть в силу разных причин процессы висят в D стейте. Я недавно заприметил обратную ситуацию — когда la < cpu и вот это меня очень заинтриговало. Вот пример
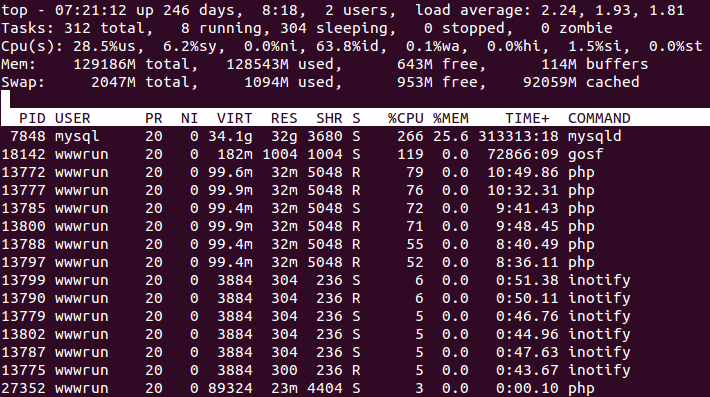
Я, конечно, догадываюсь, что виной всему S Interruptible sleep (waiting for an event to complete). Может кто подскажет, прав ли я?
alexbers
20.06.2015 09:58+1Построил график, поясняющий статью. Если запустить один процесс, который будет 100% времени что-то делать, то la будет выглядеть так(через пол часа процесс завершили):
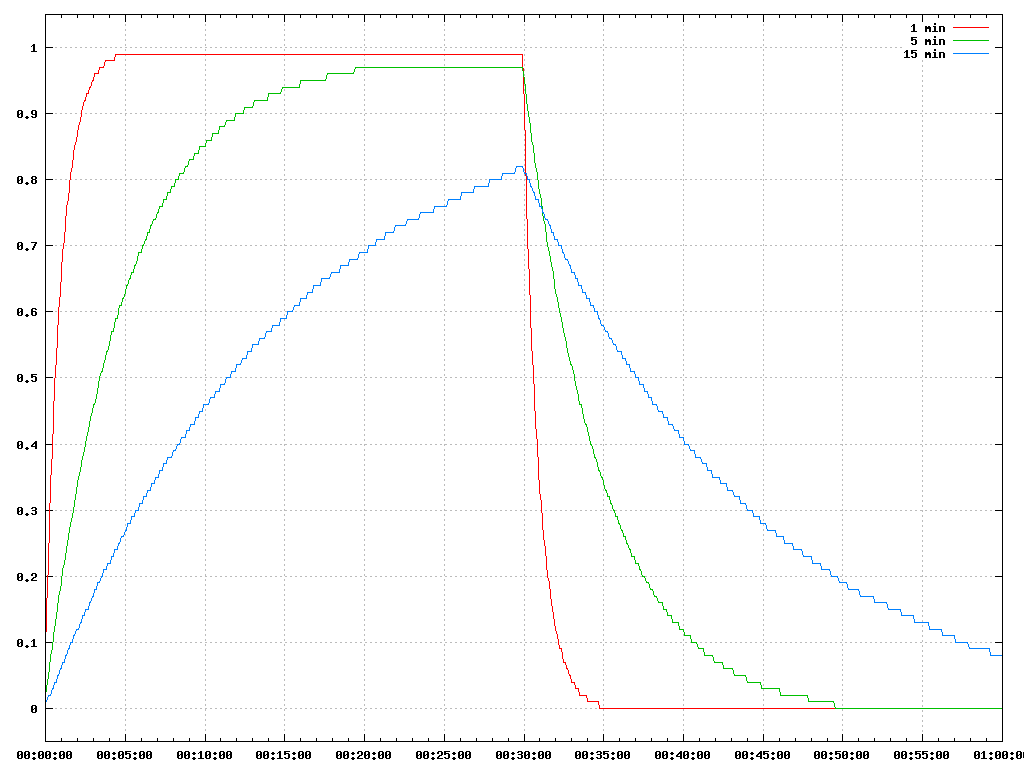
Даже через пол-часа 15-минутный la достиг отметки только 0.8.
Скрипт для построения: alexbers.com/load_average/la.py
В соответствии теории практике можно убедиться, запустив perl -e 'while(1){}' на любом свободном сервере.
gorlov
А вы прошли собеседование?
ZloyHobbit Автор
Пока не знаю, но испытываю определенные сомнения =)