
Меня зовут Евгений Жиров, я разработчик в инфраструктурной команде Контур.Экстерна. Этот пост — текстовая версия моего доклада с недавнего митапа Perm Tech Talks.
У нас в команде 200 микросервисов, которые должны быть отказоустойчивыми, чтобы пользователи не замечали никаких проблем. А проблемы, конечно, возникают. Поэтому мы собираем метрики, чтобы знать, как дела у конкретных сервисов и у системы в целом. Метрики помогают вовремя среагировать и всё починить.
Метрики можно собирать, хранить и визуализировать. И есть много способов собрать метрики неправильно, нарисовать с ошибками и сделать неверные выводы.
Я расскажу о нескольких примерах из своей работы и поделюсь советами.
Какие бывают метрики?
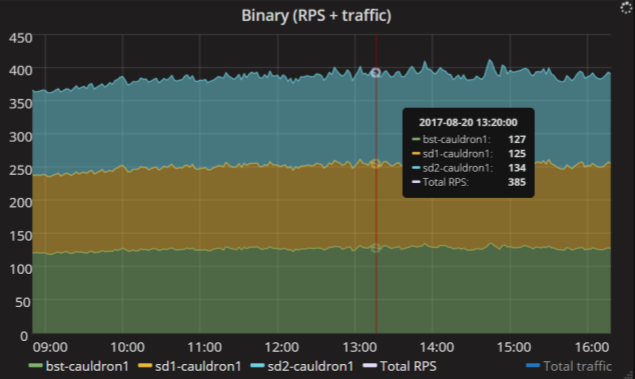
Метрика requests.count.byhost.*
Количественные метрики. Самая простая метрика для любого веб-сервиса — это число запросов, которые влетают в него в единицу времени. Обычно эту метрику называют RPS, requests per second.
Вот пример. У этого сервиса три реплики, и суммарно в них влетает почти 400 запросов в секунду. Этот график очень простой, но даёт много информации. Видно, что нагрузка равномерно распределяется по репликам сервиса, каждая реплика получает примерно равное количество запросов. Значит, с настройками балансировщиков всё в порядке.
Интервалы времени. Это более интересные метрики. Обычно их отображают в перцентилях. Например, этот график читается так: 99% запросов на поиск выполняются быстрее, чем 25 мс; а 95% запросов — быстрее, чем 3 мс.
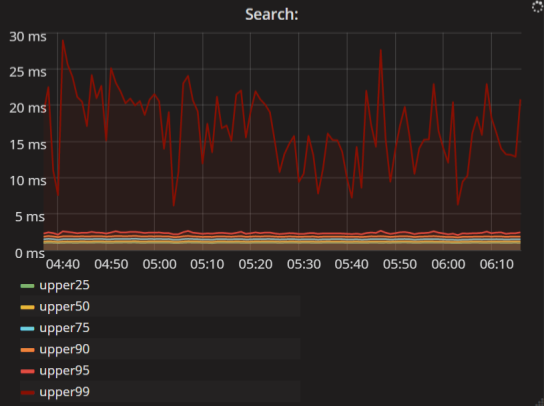
Метрика client.requests.search.latency.*
Системные метрики. Это отдельный класс метрик. Они не связаны с самим приложением, но позволяют диагностировать состояние ресурсов, которые оно использует.

Метрика system.loadavg.*
На графике метрики одного из кластеров Cassandra — значение load average, поделённое на количество процессорных ядер. По ним можно определить, проседает ли наш кластер по CPU и нужно ли добавить больше железа. Здесь видно, что сейчас значение около 12% и пока CPU хватает.
Ещё на графике виден профиль нагрузки. Здесь день, ночь, снова дневной пик активности и спад к вечеру. Важно знать, когда у приложения пиковая нагрузка. Часто бывает, что приложение в среднем не нагружено, а потом в него прилетает 10 000 запросов, и всё тормозит.
Зачем нужны метрики?
Метрики — это наши «глаза». Без метрик невозможно судить о нагрузках, производительности и отказоустойчивости приложения.
- Можно быстро реагировать на проблемы. На каждый график вешается оповещение, и когда значение превышает заданный порог, приходит уведомление.
- Можно следить, как кластер справляется с нагрузкой и вовремя добавлять железо.
- Можно сравнивать по графикам производительность приложения до и после релиза.
Как начать собирать метрики?
Предположим, вы пишете под .NET. Ищете в интернете «metrics for .NET apps» и получаете много библиотек с открытым кодом: например, Metrics.NET или App Metrics. Они помогают собирать метрики приложения.
Чтобы хранить собранные метрики, вам нужна база данных. А чтобы рисовать графики — интерфейс для визуализации метрик. Мы в Контуре используем общепринятые Graphite и Grafana.
Вы всё настраиваете, разворачиваете своё приложение, но однажды понимаете, что облажались. Например, не смогли предвидеть поломку. Или просто не понимаете, что значат числа, которые вы собираете. Вот несколько примеров из моей работы.
Пример 1. Cargo programming
Все истории начинаются одинаково. Утром, примерно в 2 часа дня, я прихожу на работу. Смотрю на графики и внезапно вижу ошибки от любимого сервиса.

Огромный пик! Хотя нет. Высота пика по вертикальной оси — всего 4?10–17 ошибок в минуту. При этом с сервисом всё в порядке, в логах чисто. Начинаю разбираться.

Смотрю, что было с сервисом 15 часов назад. Здесь пик побольше и значения более адекватные. Но какая метрика отображается на графике? Errors per minute. Только вдумайтесь: 0,4 ошибки в минуту. Это немножко странно, потому что приложение отправляет количество ошибок каждую минуту. Это должно быть целое число: 0, 1, 2 или 100, но никак не 0,4. Здесь что-то не так. Как часто бывает при первой встрече с чем-то странным, решаю проигнорировать. Иду дальше писать код.
Правда, проблема не отпускает и преследует на других графиках.

Вот график с временем чтения и записи в Cassandra. Синие линии — ошибки записи в базу данных. Эти метрики отправляет даже не мой код, а сама Cassandra. Получается, что в 10:10 начались ошибки и кончились в 10:35. Целых 25 минут Cassandra не работала.
А сколько минут на самом деле была проблема? Вот клиентские метрики, то есть метрики сервисов, которые пишут в эту базу. Совершенно другая картина: в одну минуту было 50 тыс. проваленных записей, а потом всё снова стало хорошо.

Когда что-то происходит во второй, третий, четвёртый раз — пора разобраться, что происходит. Как проще всего сделать? Нужен лабораторный эксперимент. Пишем тривиальный счётчик, который потокобезопасно считает количество событий, а потом в бесконечном цикле отправляет значение в Graphite и спит минуту.
class Counter
{
private long value;
public void Add(long amount)
{
Interlocked.Add(ref value, amount);
}
public void Start()
{
while (true)
{
var result = Interlocked.Exchange(ref value, 0);
SaveToStorage(result);
Thread.Sleep(1000 * 60);
}
}
}Пишем два теста. В одном используем свой Counter, который работает понятным образом. В другом используем счётчик из популярной библиотеки. В моём случае это Meter из Metrics.NET, у него похожий интерфейс.
Какую нагрузку считаем? Пусть 2 минуты будет 10 RPS, потом в течение 10 секунд — 100 RPS, а потом снова 10 RPS в течение 2 минут. Вот график:

Зелёная линия — то, что на самом деле происходило с сервисом. А жёлтое — то, что даёт популярная библиотека. Не очень-то похоже.
Что тут происходит? Экспоненциальное сглаживание.
Вот ещё один пример. Для реального значения метрики 100 получается 54 путём взвешенного сложения всех предыдущих точек. Коэффициенты уменьшаются в геометрической прогрессии, и получается странное сглаженное значение.
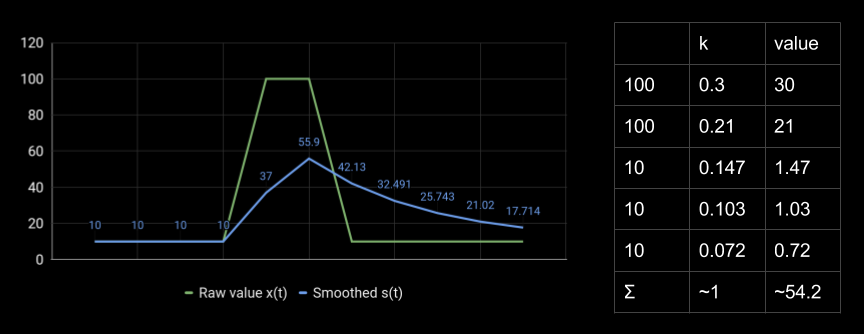
Мы хотим померять количество запросов в секунду или количество ошибок в минуту, но получаем какие-то странные значения. Обидно, что такое поведение есть во многих популярных библиотеках для сбора метрик под .NET и Java. Изменить его довольно сложно.
Какая причина? Я думаю, что дело в cargo programming, когда разработчики используют определённую технологию или пишут код определённым образом, потому что так делали деды. Исходные причины забыты, но все продолжают так делать, потому что все так делают.
При подсчёте метрик веб-сервисов экспоненциальное сглаживание только мешает. Оно не позволяет увидеть точные значения, врёт в пиках и даёт длинный хвост, который приводит к ложным срабатываниям оповещений. Оно скрывает реальный профиль нагрузки, потому что вместо одного пика мы видим совершенно другую фигуру, которая потом затухает ещё 15 часов.
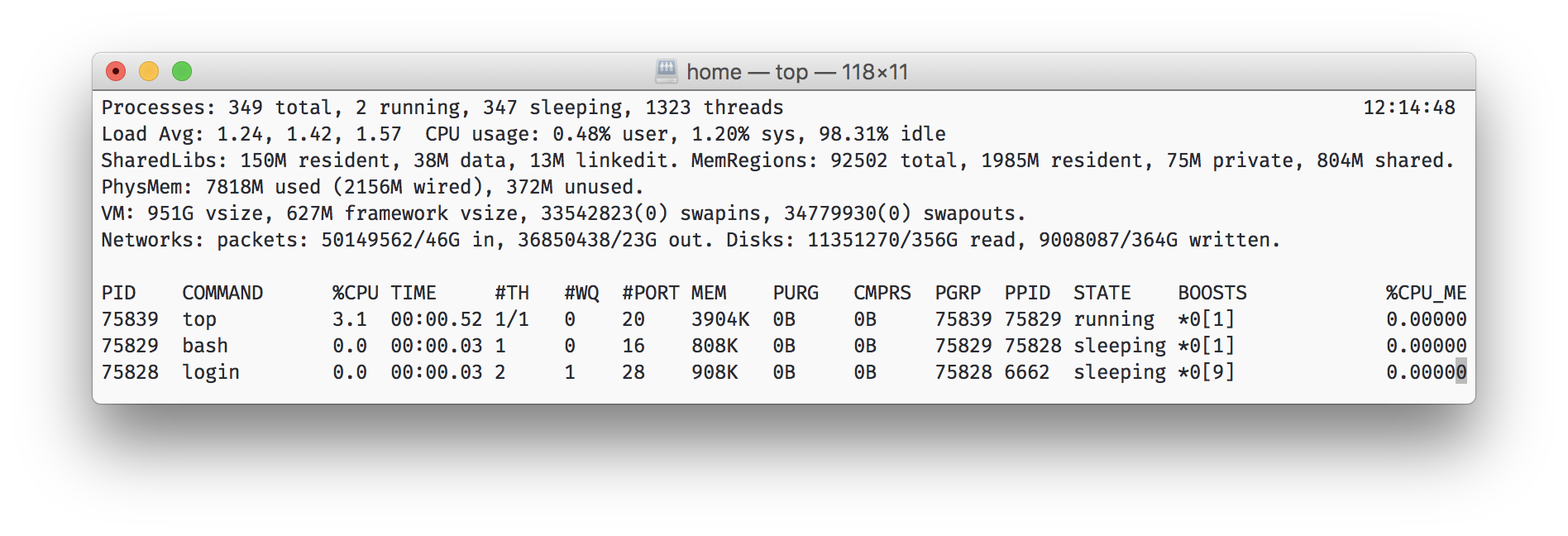
Наверняка многие из вас видели утилиту top в *nix. Она показывает три числа load average (за 1 минуту, 5 минут и 15 минут), сглаженные похожим образом. По ним нельзя судить о точном значении, но хорошо виден тренд. Например, можно увидеть, что за 15 минут нагрузка процессора серьёзно выросла. Тут сглаживание помогает, потому что с ним шумная метрика меняется гладко, а не болтается от 0 до 100.
Пример 2. Сonsolidation
Ещё бывают проблемы с визуализацией метрик.

Прихожу я опять на работу, смотрю на графики. Вот 95-й перцентиль времени поиска. Видно, что утром поиск тормозил: 550 мс у одной из точек, есть и другие пики. Может быть, это нормальное поведение сервиса? Надо изменить масштаб и посмотреть, сколько таких пиков было за неделю.
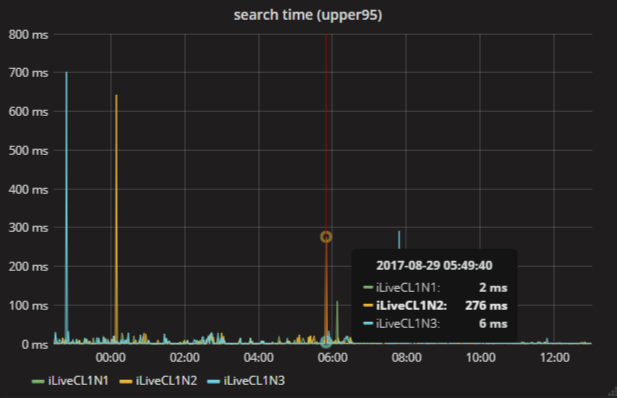
Здесь тоже много пиков. Но тот самый, в 6 утра, поменял своё значение! Теперь 276 мс. Как такое может быть?
Причина в стратегии объединения точек — consolidate by в Graphite. Когда вы изменяете временной масштаб, и все точки не помещаются на экран, Graphite объединяет их с помощью выбранной функции. Бывают разные, но по умолчанию это среднее, которое плохо подходит для этого графика. Обычно в случае перцентилей интересуют максимумы, иногда хочется взять сумму.
Если забыть о консолидации точек, выбрать неверную функцию или оставить ту, что по умолчанию, легко сделать неверные выводы из графиков.
Пример 3. Графики врут
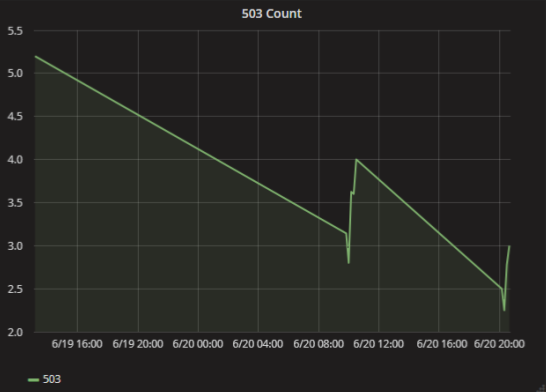
Опять прихожу на работу, открываю график, а там совсем всё плохо. Уже сутки сервис стабильно возвращает 503 ошибки каждую минуту. Здесь-то в чём проблема? Она очень простая и забавная: просто недостаточно данных для визуализации.
В Graphite есть настройка о том, как нужно соединять точки на графике, если в какое-то время не было данных. Если выбрать бездумно, то легко сделать неверный вывод. На самом-то деле ошибок было всего несколько в паре случаев.

Что делать? Писать в метрики нули, если ошибок не было, или использовать другой тип графика — например, столбики.
Пример 4. Физический смысл метрик
Известно, что приложения при работе используют оперативную память. Если приложение выделило много памяти и не может выделить ещё больше, оно начинает падать со странными ошибками.
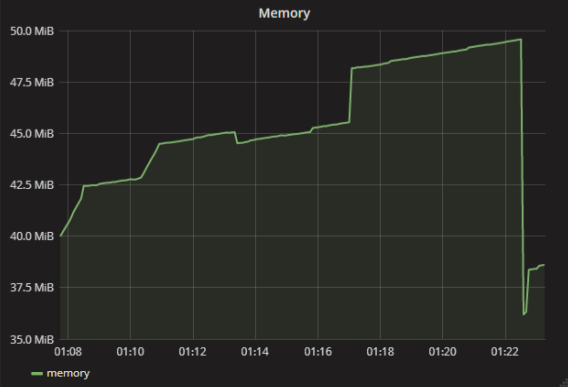
В моём случае одно из приложений начало падать из-за access violation. Я понял, что причина именно в нехватке памяти, но по метрикам всё было отлично — подумаешь, 40 МБ, ничего страшного.
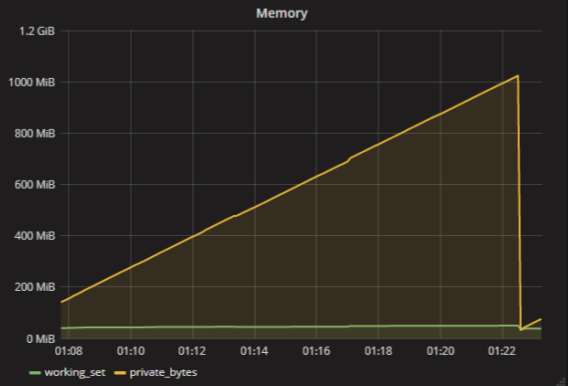
На самом деле, конечно, нет такой метрики — «сколько памяти использует приложение». Метрик для оперативной памяти много. Например, у каждого процесса в Windows есть working set и private bytes. Если грубо, working set — это объём занятой физической памяти, а private bytes — сколько памяти вообще выделило приложение. У приложения может быть куча данных в файле подкачки, но почти ничего в физической памяти. Приложению будет плохо, и оно развалится.
Надо помнить, что нет таких простых метрик как «память» или «загрузка процессора». Метрик больше, и они все значат что-то конкретное.
Выводы
- Нужно понимать, что измеряешь. Если мерять просто «память», то полученные значения не будут значить практически ничего.
- Нужно понимать, как работают инструменты. Например, помнить, что библиотека для сбора метрик сделает экспоненциальное сглаживание, а база данных консолидирует точки по какому-то алгоритму.
- Нужно задумываться, если метрики не соответствуют другим данным (например, логам) или наблюдаемому поведению системы. Нельзя проходить мимо. Если не можете объяснить несоответствие, то полученные метрики для вас бесполезны.
А как вы собираете и визуализируете метрики? Какие сложности со сбором метрики и их отображением были у вас?
Комментарии (6)

KSILAR
31.10.2017 15:06Мы в банке мониторим zabbix все возможные сервисы по ДБО и трафику смс. Вполне удобное ПО для сбора статистики, уведомлений и отображения графиков.

SobakaRU
31.10.2017 19:04+1Посыл и выводы в статье, безусловно, правильны.
Только складывается ощущение, что кое-где автор специально через пень-колоду настраивал отображение метрик в grafana чтобы набрать иллюстративного материала)
И об акцентах:
На мой взгляд, если пользователь осознанно выбирает неподходящий способ отрисовки «Null value» в метриках, то такой кейс никак нельзя озаглавливать «Графики врут». Скорее следует сделать сделать упор на то, что нужно изучать инструмент (grafana в этом случае) прежде чем ставить галочки в настройках. Иначе получается, что это не юзер откровенно накосячил, а что злобные машины ополчились против человеков.

alexkbs
01.11.2017 05:45Правильный вывод из статьи должен быть такой: метрики нужны для учёта того, что меняется. Для учёта единичных событий метрики не подходят.
Дело не в cargo programming, а в том, что вы используете спидометр для учёта пробега. Уже чувствуете бессмыслицу, так ведь? Все те библиотеки написаны так именно потому что они предназначены для измерения скорости, а не пробега. Для графика скорости имеет смысл и экспоненциальное сглаживание, и алиасинг. Для пробега эти методы не имеют никакого смысла. Для учёта пробега следует использовать другие методы и средства, будь это одометр или Elastic Stack какой.

igan
01.11.2017 19:31+1Спасибо за статью. Grafana прекрасный инструмент но вот consolidation совершенно не очевидный аспект. Приходится каждому пользователю отдельно объяснять почему его метрика при зуммировании меняется в два раза. Многие отказываются от использования графаны потому что не хотят об этом постоянно думать и переходят на другие графики когда есть возможность (вместо jmx смотрят jvm метрики в аппдинамикс например). Очень неудачно.
Ещё раз отличная статья. Хотелось бы чтобы попалась раньше, до того как набил своих шишек.
NobleD5
Тоже использовал раньше связку Graphite + Grafana для сбора метрик от нашей инженерной инфраструктуры. Сейчас перенес все это на Prometheus + Grafana. Вызвано это было тем, что Prometheus позиционирует себя как инструмент для мониторинга и имеет систему оповещения, что для нас плюс. Ну и его многомерная модель данных мне пришлась больше по душе.
ezsilmar Автор
Мы для оповещений используем Moira. Модель с тэгами мне тоже больше нравится, но на наших масштабах не сменить так просто технологию.