

Обслуживая множество инсталляций Kubernetes в проектах разного масштаба, мы столкнулись с проблемой сбора и просмотра логов со всех контейнеров кластера. Изучив имеющиеся решения, пришли к необходимости создания нового — разумного в потреблении ресурсов и дискового пространства, а также предлагающего удобный интерфейс для просмотра логов в реальном времени с возможностью их фильтрации по нужным критериям.
Так родился проект loghouse, и я рад представить его альфа-версию DevOps-инженерам и системным администраторам, которым знакомы обозначенные проблемы.
В основу loghouse была взята замечательная столбцовая СУБД с открытым кодом — ClickHouse, — за что отдельное спасибо коллегам из компании Яндекс. Как легко догадаться, это же обстоятельство стало причиной для названия нового проекта. Ориентированность ClickHouse на Big Data и соответствующие оптимизации в производительности и подходе к хранению данных — жизненно необходимое условие для сборщика логов Kubernetes, в котором мы нуждались.
Другим важным компонентом текущей реализации loghouse является fluentd — Open Source-проект при фонде CNCF, который, обеспечивая хорошую производительность (10 тысяч записей в секунду при занятых в памяти 300 Мб), помогает в сборе и обработке логов, а также их последующей отправке в ClickHouse.
Наконец, поскольку решение ориентировано на Kubernetes, в нём используются его базовые механизмы, позволяющие интегрировать различные компоненты loghouse в единую систему, которую легко и быстро разворачивать в кластере.
Возможности
- Эффективный сбор и хранение логов в Kubernetes. Про fluentd уже написано, а вот примеры по месту, занимаемому логами в ClickHouse: 3,7 млн записей — 1,2 Гб, 300 млн — 13 Гб, 5,35 млрд — 54 Гб.
- Поддержка логов в формате JSON.
- Простой язык запросов для отбора записей с сопоставлением ключей с конкретными значениями и регулярными выражениями, поддержкой множества условий через AND/OR.
- Возможность выбора записей по дополнительным данным о контейнерах из Kubernetes API (пространство имён, лейблы и т.п.).
- Простой деплой в Kubernetes с помощью готовых Dockerfile и Helm-чартов.
Как это работает?
Русскоязычная документация проекта объясняет суть:

На каждый узел кластера Kubernetes устанавливается под с fluentd для сбора логов. Технически для этого в Kubernetes создается DaemonSet, который имеет tolerations для всех возможных taints и попадает на все узлы кластера. Каталоги с логами со всех хост-систем монтируются в поды fluentd из этого DaemonSet, где за ними «наблюдает» служба fluentd. Для всех логов Docker-контейнеров применяется фильтр kubernetes_metadata, который собирает дополнительную информацию о контейнерах из Kubernetes API. После этого данные преобразуются с помощью фильтра record_modifier. После преобразования данных они попадают в fluentd output plugin, который вызывает расположенную в контейнере с fluentd консольную утилиту clickhouse-client для записи данных в ClickHouse.
Важное архитектурное замечание состоит в том, что на данный момент поддерживается запись в единственный экземпляр СУБД ClickHouse — Deployment, который по умолчанию попадает на случайный узел K8s. Выбрать конкретный узел для его размещения можно с помощью nodeSelector и tolerations. В дальнейшем мы планируем реализовать и другие варианты инсталляции (с экземплярами ClickHouse на каждом узле кластера и в виде кластера ClickHouse).
Веб-интерфейс
Пользовательская часть loghouse, которую мы называем loghouse-dashboard, состоит из двух компонентов:
- frontend — nginx с базовой авторизацией (используется для разграничения пользовательских прав);
- backend — приложение на Ruby, в котором можно просматривать логи из ClickHouse.
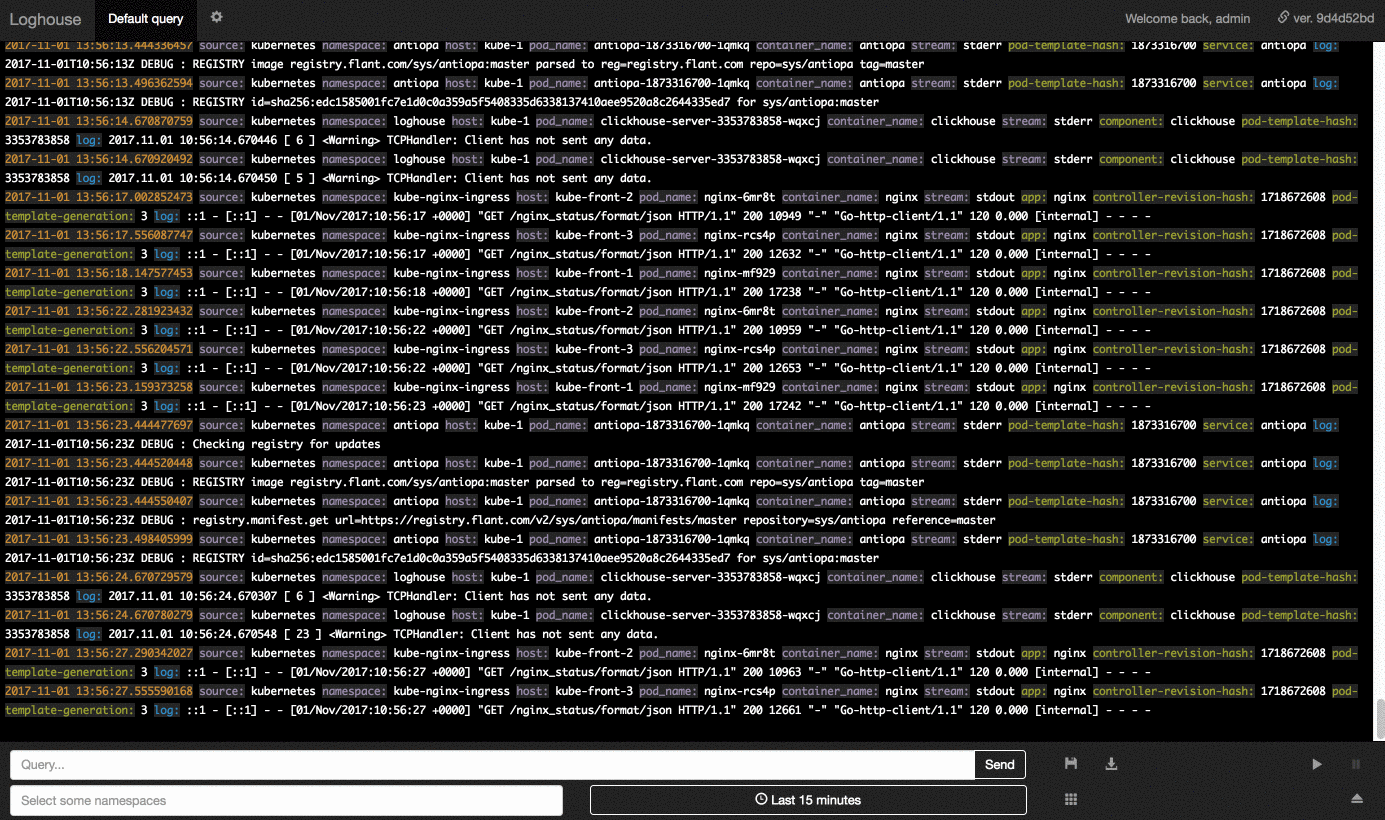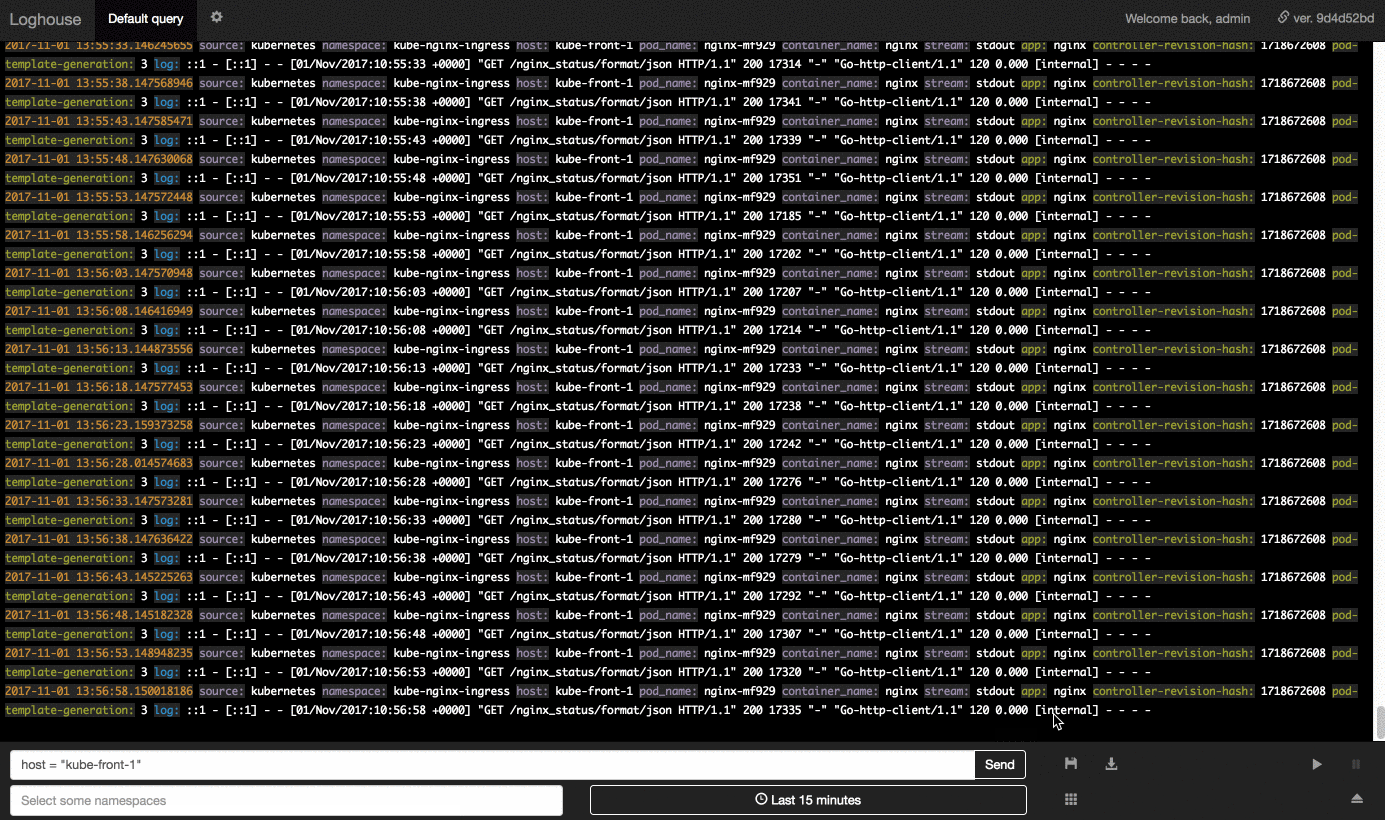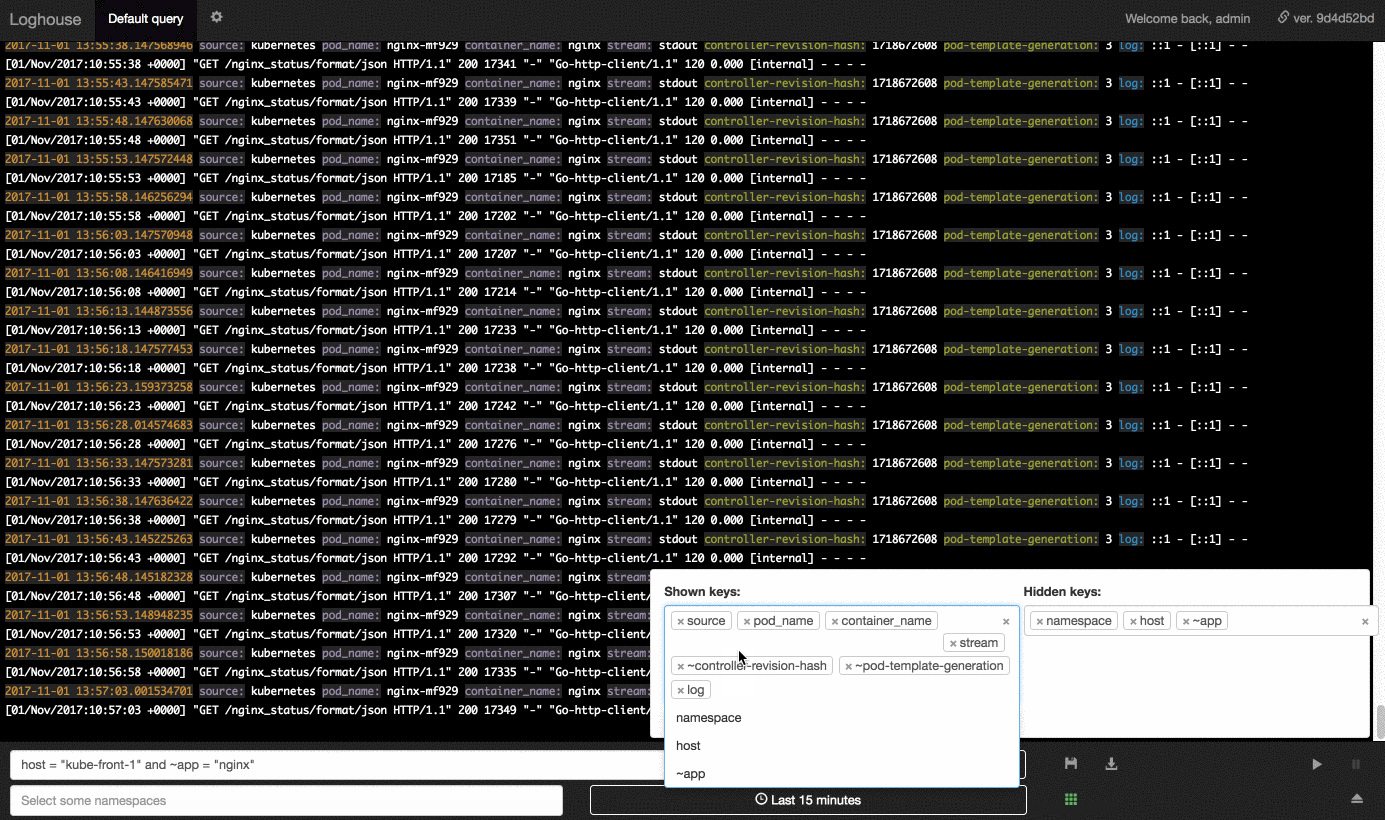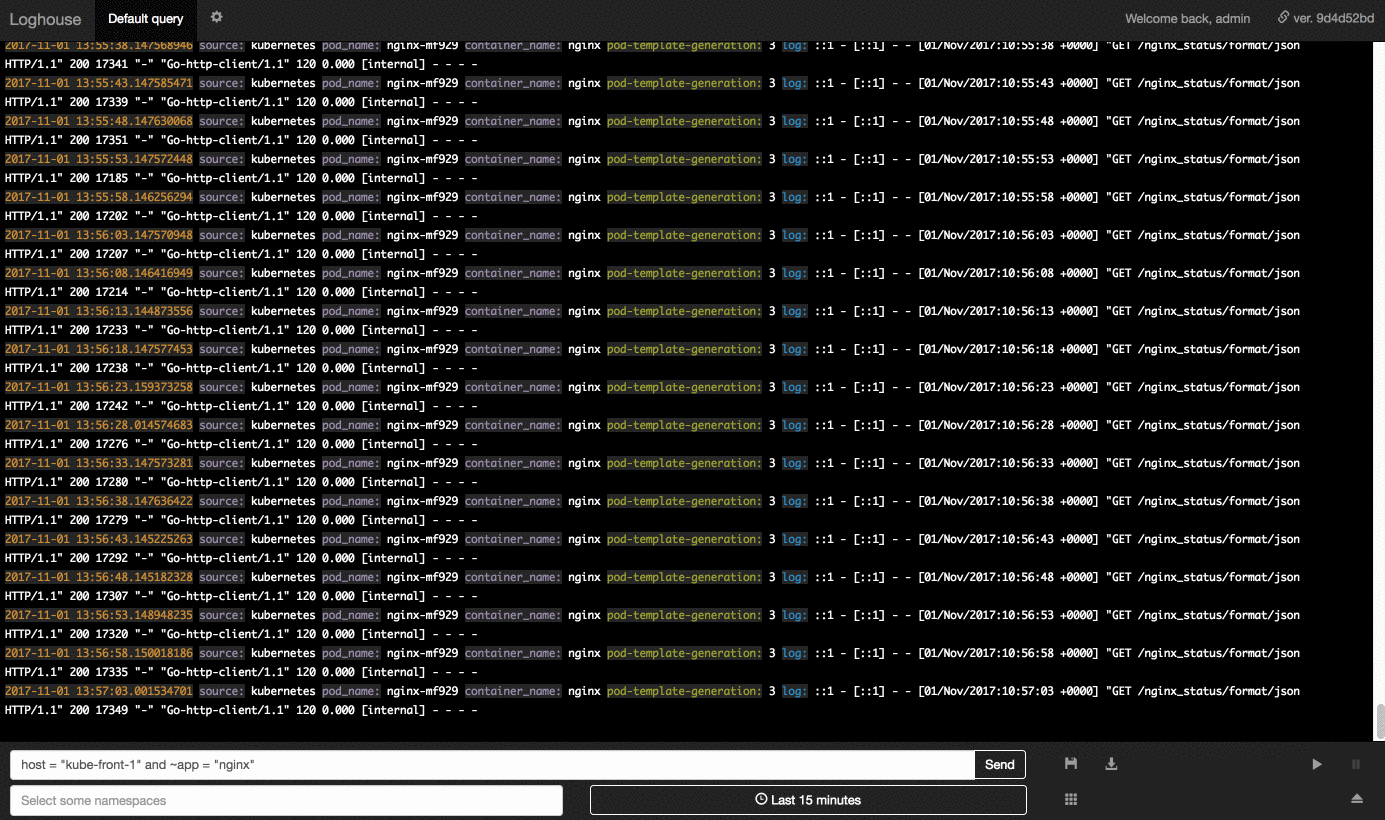
Интерфейс оформлен в стиле Papertrail:

Небольшое видео с интерфейсом в действии можно посмотреть здесь (Gif на 3 Мб).
{kind=link}
Среди имеющихся фич — выбор периода (за указанные «от и до» или последний час, день и т.п.), бесконечная прокрутка записей, сохранение произвольных запросов, ограничение доступа пользователям по заданным пространствам имен Kubernetes, экспорт результатов текущего запроса в CSV.
Установка и использование
Официальный статус — альфа-версия, а сами мы используем loghouse в production второй месяц. Для установки loghouse потребуется наличие Helm и в простейшем случае:
# helm repo add loghouse https://flant.github.io/loghouse/charts/
# helm fetch loghouse/loghouse --untar
# vim loghouse/values.yaml
# helm install -n loghouse loghouse(Подробнее см. в документации.)
После установки будет поднят веб-интерфейс, доступный по заданному в конфиге
values.yaml адресу (loghouse_host) с базовой аутентификацией в соответствии с параметром auth из того же values.yaml.План развития
Среди запланированных улучшений в loghouse:
- дополнительные варианты инсталляции: экземпляры ClickHouse на каждом узле, кластер ClickHouse;
- поддержка скобок в языке запросов;
- выгрузка данных в другие форматы (JSON, TSV) и в сжатом виде;
- выгрузка архивов с логами в S3;
- миграция фронтэнда веб-интерфейса на AngularJS;
- миграция бэкенда веб-интерфейса на Go;
- консольный интерфейс;
- …
Более подробный план появится в ближайшее время в виде issues проекта на GitHub.
Заключение
Исходный код loghouse опубликован на GitHub под свободной лицензией Apache License 2.0. Как и в случае с dapp, мы приглашаем DevOps-инженеров и Open Source-энтузиастов к участию в проекте — тем более, что он ещё очень молод и посему вдвойне нуждается в «активном» взгляде со стороны. Задавайте вопросы (можно прямо здесь в комментариях), указывайте на проблемы, предлагайте улучшения. Спасибо за внимание!
P.S.
Читайте также в нашем блоге:
- «Официально представляем dapp — DevOps-утилиту для сопровождения CI/CD»;
- «Собираем Docker-образы для CI/CD быстро и удобно вместе с dapp (обзор и видео)»;
- «Наш опыт с Kubernetes в небольших проектах» (видео доклада, включающего в себя знакомство с техническим устройством Kubernetes).
Комментарии (37)

SirEdvin
01.11.2017 11:58А почему не https://github.com/Vertamedia/clickhouse-grafana + grafana?

past
01.11.2017 12:20или fluentd + ELK/Graylog?
SirEdvin
01.11.2017 12:21Ну, почему clickhouse, а не elasticsearch на самом деле можно понять. Он довольно тяжелый бывает и для очень простых случаев хотелось бы чего-то по легче, по крайне мере, мне так кажется)

Wimbo Автор
01.11.2017 12:29Мы протестировали несколько вариантов, но они оказалось либо очень ресурсоемкими (как CPU, RAM так и дисковое пространство), либо крайне не удобными и не соответствовали нашим требованиям.
Elasticsearch оказался слишком «толстым».

distol
01.11.2017 12:55+1fluentd + ELK/Graylog — ну так основная проблема в ELK и Graylog это ELK. Точнее сам Elastic. Мы долго и упорно пытались на разных проектах использовать Elastic, но с ним постоянные проблемы в эксплуатации (разваливающийся кластер при любом чихе) и он употребляет не меренно ресурсов. Бонус ClickHouse в том, что он практически не использует ресурсов. Разница с Elastic где-то на порядок. По сути, ClickHouse при записи создает такую же нагрузку, как простой gzip без параметров.
Wimbo Автор
01.11.2017 12:26Формат отображения логов и возможностей было крайне недостаточно для нас в grafana.
Пришлось сделать свое решение.SirEdvin
01.11.2017 12:39Хм, а не разумнее ли было сделать свой дашбоард? Или уперлись в сам datasource плагин?
distol
01.11.2017 13:48Даже не думали об этом. Это совершенно другое решение. В grafana его пихать смысла нет совсем. Мы делаем OpenSource клон http://papertrailapp.com/ для Kubernetes.
distol
01.11.2017 12:50Потому что это рисователь графиков, а не утилита для мониторинга логов. Однако, у нас стоит в средне-дальнем беклоге план по grafana (и в частности по этому плагину), чтобы можно было делать визуализации по логам.

dernasherbrezon
01.11.2017 12:29А loghouse может оказывать обратное давление? Что случится если одно приложение сойдёт с ума и начнёт генерировать миллион строчек логов в секунду? Как быстро закончится место в clickhouse?
Wimbo Автор
01.11.2017 12:39В данный момент loghouse не обработает миллион строчек логов в секунду.
В таком случае мы получим дикую нагрузку на диск, так как лог пишется в логи, а после чего fluentd их пишет в clickhouse. Сколько эти логи занимают места — столько они и будут занимать.
Зависит от того, сколько эти логи занимают пространства.distol
01.11.2017 12:57Как не обработает? Обработает! ClickHouse такое может даже на одном узле (правда на совсем простых данных). Цитирую:
We recommend inserting data in packets of at least 1000 rows, or no more than a single request per second. When inserting to a MergeTree table from a tab-separated dump, the insertion speed will be from 50 to 200 MB/s. If the inserted rows are around 1 Kb in size, the speed will be from 50,000 to 200,000 rows per second. If the rows are small, the performance will be higher in rows per second (on Yandex Banner System data -> 500,000 rows per second, on Graphite data -> 1,000,000 rows per second). To improve performance, you can make multiple INSERT queries in parallel, and performance will increase linearly.
distol
01.11.2017 12:49Да, конечно поддерживает обратное давление! Это штатный функционал fluentd, который на данный момент используется как коллектор.
Поток данных выглядит следующим образом:
- приложения пишут логи в stdout (12 factor, принято в kubernetes),
- kubernetes (и docker) все это складывают в файлики локально на каждой ноде, и на этом их ответственность заканчивается,
- fluentd запущеный на каждом узле читает файл и шлет данные каждую секунду в ClickHouse.
Соответственно, в описаном вами кейсе, скорей всего раньше ляжет нода, на которое такое приложение (забьется место на диске, там логи не жатые), чем ClickHouse в котором есть сжатие. Но в любом случае, если ClickHouse ляжет по любой причине — логи будут ждать локально, до тех пор пока он не вернется.
dernasherbrezon
01.11.2017 15:07Неплохо!
Но непонятна связка: kubernetes — локальный файлики. "Нода" на которой хранятся файлы это kubernetes node? Получается, что если мой компонент, который сошёл с ума забивает диск на ноде, то все остальные kubernetes pod перестают писать туда логи?
Еще непонятно что будет если pod будет перемещён на другой node. Согласно документации файлик будет удален. Это правда? Логи все таки можно будет потерять? Или у вас используется PVC для этого?
distol
01.11.2017 20:52Но непонятна связка: kubernetes — локальный файлики. "Нода" на которой хранятся файлы это kubernetes node? Получается, что если мой компонент, который сошёл с ума забивает диск на ноде, то все остальные kubernetes pod перестают писать туда логи?
Да, все так. Это штатное поведение Kubernetes, и оно никак не относится к loghouse. Kubernetes штатно кладет лог контейнера всегда в файл в /var/log/containers (подробнее об этом тут). В Kubernetes сейчас это никак не изолировано. Наше решение занимается другой задачей — собирает логи всех контейнеров в одном месте, чтобы можно было удобно централизованно искать.
Еще непонятно что будет если pod будет перемещён на другой node. Согласно документации файлик будет удален. Это правда? Логи все таки можно будет потерять? Или у вас используется PVC для этого?
Под не может быть перемещен на другой узел в Kubernetes. Может быть удален старый под и создан новый. Логи контейнеров удаленных подов хранятся некоторое время до того, как быть удаленными.
dernasherbrezon
02.11.2017 01:05Спасибо! А есть какой нибудь способ заставить kubernetes разграничивать логи для pod более жестко?
distol
02.11.2017 02:18На практике у нас таких проблем не было. Ответ искать где-то здесь: https://docs.docker.com/engine/admin/logging/overview/. Вот даже тут: https://docs.docker.com/engine/admin/logging/json-file/. Там всякие max-size, max-file и решает вопрос с размером штатно. А вот по интенсивности — мне не известно.

vaniaPooh
01.11.2017 13:31А почему на бекенде Ruby? Насколько мне известно практика крупных компаний показывает, что для высокой производительности он не очень подходит.

shurup
01.11.2017 13:47Это бэкенд именно у веб-интерфейса (не каких-то системных компонентов типа сборщика/обработчика логов), поэтому не так критично. А Ruby, потому что с него нам было проще начинать воплощать задумки в жизнь.
distol
01.11.2017 13:47Я бы ответил кратко — для быстрого прототипирования. До конца года перепишем на Go.

tetramin
01.11.2017 14:26Есть ли в loghouse уведомления (в Slack или Telegram) при появлении определённых событий? А авторотация за определённый период?
distol
01.11.2017 21:12Спасибо за вопросы!
Что касается уведомлений — думали об этом, обязательно будет, но по срокам пока совсем нет никакого понимания. Во многом это сейчас зависит от спроса. Если мы не ошиблись и с проблемами простого и удобного логирования сталкиваемся не только мы, и если loghouse пойдет в массы, думаю можно ждать эту фичу весной.
Что касается авторотации за определенный период — пока нет, но это будет буквально на днях. Можете начинать использовать, а обещаем выкатить новую версию с ротацией до того, как у вас закончится место. В структуре данных все возможности для ротации заложены (есть партиционирование по дням, можно выбрать партиционирование по меньшему периоду). Для начала будет две настройки — сколько дней хранить и какой максимальный размер занимаемого места на диске. Можно будет указывать любую или обе одновременно. Отпишем тут, когда будет готово.
sublimity
02.11.2017 00:47Как разработчик Tabix ( может слышали ), смотрите в сторону React, но только не angular))
distol
02.11.2017 02:25Привет, разработчик Tabix. Мы не просто слышали, а ставим вместе с loghouse везде Tabix, чтобы можно было посчитать что-то сложное. Типа, сколько в среднем таких-то сообщений в час с распределением по pod'ам. Ну или коды ответа HTTP, или сколько уникальных пользователей. Большое спасибо вам за Tabix!!
Что касается react/angular — ничего в этом не понимаю, но нам нужно быть максимально совместимыми со стеком Kubernetes. В перспективе хочется сделать бекенд плагином к api-серверу kubernetes, консольный интерфейс плагином к kubectl, а gui плагином к kuberentes dashboard. Последний, кстати, на angular и go — так что мы должны быть на них же, чтобы было проще получить поддержку сообщества kubernetes.
Frank59
02.11.2017 12:18вопрос: есть ли в clickhouse полнотекстовый поиск по текстовым полям?
distol
02.11.2017 22:00Нет. Классического полнотекстового поиска (токенизация, стемминг, индекс по словам) в ClickHouse, на сколько мне известно, нет. Однако ClickHouse позволяет прогнать данные через простую регулярку, и он может это сделать ооочень быстро. Поиск регуляркой среди 7 млрд записей занимает 6 ядер (12 тредов) на десяток секунд, а если локализовать (указать диапазон времени в несколько часов) — несколько сотен миллисекунд. Соответственно для логов самый раз — индексировать для настоящего полнотекстового поиска очень дорого (это куча места и вычислительных ресурсов, да и большие сложности с ротацией), запросов на запись несоизмеримо больше запросов на чтение (поэтому лучше съесть иногда чуть больше ресурсов на поиск, нежели постоянно на индексацию). Как-то так.
GDApsy
02.11.2017 22:16А минимальные требования по железу более подробно не проясните? Объем ОЗУ, место на диске и т.д.
Logout_90
03.11.2017 11:17Добрый день!
Посмотрел на ваш проект после неуспешного опыта эксплуатации ELK стека.
Действительно, ELK очень требователен к ресурсам и падает чуть больше, чем постоянно с ошибкой OutOfMemory.
Я весьма признателен за инструмент, который вы выпустили, поскольку, все что я нашел на просторах интернета в плане логов, использует elasticsearch.
Однако, после ознакомления с helm пакетом, возникло несколько вопросов:
1. Чем продиктовано использование отдельного файла namespace.yaml? Ведь helm создает namespace при инсталляции пакета.
2. Почему используется .Values.namespace вместо .Release.namespace? Ведь чем больше переменных нужно изменить, тем больше вероятность ошибки при развертывании.
3. Почему Вы используете alpha k8s API в файле loghouse-cronjob.yaml? Вроде бы возможности, которые описаны у вас в CronJob, не альфа, а установить без включения alpha feature gate ваш пакет невозможно.
4. Вы не учли возможность указания ресурсов в ингрессе и полагаете, что каждый ингресс будет отдавать приложение из корня, а это может быть не так, если используется один хост на всё. Также отсутствует возможность увказания имен секретов.
Я склонировал репозиторий и пилю сейчас helm пакет по вышеозначенным вопросам.
Но, возможно, я что-то упустил и не прав. Прошу пояснить, мои вопросы это баги, которые я нашел или фичи которые я принял за баги?Wimbo Автор
03.11.2017 15:56+1Добрый день…
Спасибо большое за интерес к нашему проекту и мы очень рады, что есть люди, которые испытывают те же потребности, что и мы.
Это все баги, связанные с тем, что это PoC. Мы будем очень рады, если вы пришлете PR или создадите Issue по любым улучшениям или вопросам.
distol
03.11.2017 18:38Огромное спасибо за фидбек. Выглядит так, как буд-то вы правы по каждому пункту. Будем благодарны за pull-request или сделаем сами чуть позже.
siroco
Так а почему не построить отказоустойчивый clickhouse-кластер в Kubernetes? C load balancer(ами) и autoscaling(ом). Именно как отдельный сервис (и даже в отдельном Kubernetes-кластере), а не в рамках проекта loghouse?
distol
Конечно так и сделаем. Планируем три основных архитектуры: standalone clickhouse (быстро и просто), clickhouse на каждой ноде (логи индексируются в локальный инстанс, подходит только для bare metal, где ноды статичны) и clickhouse cluster. Просто не все сразу.
siroco
> подходит только для bare metal, где ноды статичны
Почему ТОЛЬКО? В том же AWS(e) все можно сделать, просто записи для service discovery хранятся снаружи, например, в Route53 private zone. Ну и lifecycle_hook на «autoscaling:EC2_INSTANCE_LAUNCHING».
distol
Слишком кратко сказал и был неверно понят. Сценарий "ClickHouse на каждой ноде" означает, что он стоит на каждой ноде Kubernetes. И fluentd читает данные из /var/log/containers и пишет в локально расположенный на этой же машине ClickHouse. Запросы делаются к распределенной таблице, которая собирает данные со всех инстансов. Бонус такого сценария — снижение нагрузки на сеть (практически до нуля) и возможность использовать дешевые локальные диски (которые часто есть в bare metal, но обычно нет в cloud). Если вероятность выхода из строя железки не высокая и логи можно терять в такой (редкой) ситуации, то этот сценарий позволяет сильно сэкономить. И по моему мнению он может быть особенно удобен для небольших кластеров на 3-7 железках, где еще не настал момент выделять отдельные ноды под логирование.
Почему я считаю, что такой сценарий не подходит для aws? Очень просто. Облака есть динамичность. Автоскейлинг. Например, у нас во всех кластерах Kubernetes в aws сейчас работает автоскейлер — днем кластер подростает, ночью сдувается. Если ставить ClickHouse на каждый узел, то при даунскейлинге надо будет пересохранять куда-то данные с этого узла. И в этом случае проще и удобней сделать отдельную (автоскейлинг) группу для кластера ClickHouse.