
Уважаемые хабровчане, у меня родилась публикация — вопрос. С удовольствием выслушаю вашу критику в комментариях.
В проекте пришлось набросать небольшую обертку над существующей системой логирования и помимо ее основного предназначения захотелось ее использовать в стиле работы с потоком вывода.
Опуская ненужные детали, обертка выглядит так:
class LoggerWrap: public RequiredInterface
{
public:
void write(const std::string& str) const; //запись в существующую систему логирования
/*
... прочие методы и поля класса реализующие RequiredInterface ...
*/
};А хочется еще использовать как-нибудь так:
LoggerWrap log;
log << "значение 1: " << std::setw(10) << someValue << "; значение 2:" << std::setw(15) << anotherValue;В процессе размышлений мне пришло в голову несколько решений которые я и хочу обсудить.
Вариант 1
Перегрузить operator<<, данные полученные им направлять в локальный для потока ostringstream. В конце писать в лог специальный объект — признак конца строки.
Решение может выглядеть примерно так:
class LoggerWrap
{
public:
void write(const std::string& str) const
{
//просто для примера
std::cout << "[Log]: " << str << std::endl;
}
/*
... прочие методы и поля класса ...
*/
struct Flush {}; //признака конца строки
template<typename T>
LoggerWrap& operator<< (const T& data)
{
buf << data;
return *this;
}
LoggerWrap& operator<< (const Flush&)
{
write(buf.str());
buf.str("");
buf.flags(defFmtFlags);
return *this;
}
private:
thread_local static std::ostringstream buf;
const thread_local static std::ios::fmtflags defFmtFlags;
};
thread_local std::ostringstream LoggerWrap::buf;
const thread_local std::ios::fmtflags LoggerWrap::defFmtFlags(buf.flags());Использование:
LoggerWrap logger;
logger << "#" << 1 << ": " << 1.2 << ", text again" << LoggerWrap::Flush();
logger << "#" << 2 << ": " << std::scientific << 2.3 << ", text again" << LoggerWrap::Flush();
logger << "string #" << 3 << ": " << 10.5 << LoggerWrap::Flush();в консоли будет напечатано:
[Log]: #1: 1.2, text again
[Log]: #2: 2.300000e+00, text again
[Log]: #3: 10.5Для меня, недостатком этого варианта является необходимость писать LoggerWrap::Flush(). Его можно забыть написать и потом долго пытаться понять, а что за чертовщина происходит в логе.
Вариант 2
Как определить, что строка для логирования завершена, без явного указания на это? Я решил опереться на время жизни временного объекта. Когда функция возвращает объект, то он живет пока на него есть ссылка. Таким образом можно создать временный объект со своим operator<<, возвращающим ссылку на этот объект, а его деструктор будет вызывать метод LoggerWrap::write.
Получается следующее:
class LoggerWrap
{
public:
void write(const std::string& str) const
{
//просто для примера
std::cout << "[Log]: " << str << std::endl;
}
/*
... прочие методы и поля класса ...
*/
class TmpLog
{
friend class LoggerWrap;
public:
~TmpLog()
{
if (flush)
{
logger.write(buf.str());
buf.str("");
}
}
template<typename T>
TmpLog& operator<< (const T& data)
{
buf << data;
return *this;
}
TmpLog(const TmpLog&) = delete;
private:
TmpLog(const LoggerWrap& logger, std::ostringstream& buf) :
logger(logger),
buf(buf)
{
}
TmpLog(TmpLog&& that):
logger(that.logger),
buf(that.buf),
flush(that.flush)
{
that.flush = false;
}
const LoggerWrap& logger;
std::ostringstream& buf;
bool flush = true;
};
template<typename T>
TmpLog operator<< (const T& data)
{
buf.flags(defFmtFlags);
TmpLog tmlLog(*this, buf);
return std::move(tmlLog << data);
}
private:
thread_local static std::ostringstream buf;
const thread_local static std::ios::fmtflags defFmtFlags;
};
thread_local std::ostringstream LoggerWrap::buf;
const thread_local std::ios::fmtflags LoggerWrap::defFmtFlags(buf.flags());и использование:
LoggerWrap logger;
logger << "#" << 1 << ": " << 1.2 << ", text again";
logger << "#" << 2 << ": " << std::scientific << 2.3 << ", text again";
logger << "#" << 3 << ": " << 10.5;вывод в консоли будет аналогичен первому решению.
Итоги
Здесь не задаются уровни логирования (Warning, Error, Info и т.п.) так как наша система логирования их не различает, но добавить это в обертку не сложно. Например определить LoggerWrap::operator(), принимающий в качестве аргумента желаемый уровень для строки, которая будет выведена.
Мне больше нравится второе решение, так как не нужно дописывать после каждой строки некоторое магическое слово. А при добавлении уровней логирования, во временном объекте можно будет хранить эту информацию для текущей строки.
Спасибо, что дочитали, надеюсь увидеть ваше мнение в комментариях.
Комментарии (53)
hdfan2
11.11.2017 14:44А есть ли вообще смысл флашить строковый поток? С файловым всё понятно — flush гарантирует запись данных на диск. А для строкового?
Кстати, для потока обычно перегружают вывод в него функции типа void f(ostingstream&), в которой делают всё что нужно с потоком. А в операторе перегрузки просто вызывают эту функцию для текущего потока. Это позволяет писать свои собственные функции-манипуляторы.
Hokum Автор
11.11.2017 16:08Мне кажется, если просто использовать для создания форматированой строки, то нет смысла, в других вариантах — не знаю.
Спасибо за замечание про функции, не задумывался об этом, да и не приходилось как-то раньше писать что-то, что ведет себя как поток.

SinsI
11.11.2017 15:48Чем именно то, что вы хотите сделать, отличается от QDebug из QT?
Hokum Автор
11.11.2017 16:13В проекте QT не используется. Возможно, что ничем и не отличается (QT не использую активно и подзабыл, что там есть такое). Мне был нужен логгер реализующий специальный интерфейс — он требуется для создания объекта из сторонней библиотеки.Ну а дальше захотелось чуть-чуть его приукрасить.

waiwnf
11.11.2017 19:07+1Посмотрите на glog, вполне возможно не придётся писать свой велосипед. Там как раз через << всё сделано.
Hokum Автор
11.11.2017 20:31Спасибо за совет. Но велосипед писать все равно надо по нескольким причинам:
- Мне нужно реализовать интерфейс который требует библиотека (внутренний продукт компании).
- Наша текущая система логирования не поддерживает многопоточность, а упомянутая библиотека пишет в лог из нескольких потоков. Т.е. обертка еще и синхронизирует доступ к нашей подсистеме логирования.
- Мне нужно писать в лог информацию из места где я использую библиотеку и так, чтобы мои записи были в правильном порядке относительно записей библиотеки.
А так у нас решили попробовать использовать P7 library, но уже в другом проекте :)
waiwnf
11.11.2017 20:45Ясно, успеха! Единственное по многопоточности — glog НЯП синхронизирован на уровне каждого LOG вызова. То есть логать можно из нескольких потоков спокойно, и строчки перемешиваться не будут (в отличие от cout). Про порядок на 100% не уверен, но в пределах одного потока я бы очень удивился, если он может нарушиться. А между разными потоками в любом случае гарантий нет.
Hokum Автор
11.11.2017 21:11Спасибо. P7 тоже поддерживает многопоточность и есть возможность вести лог на сервер. А cout для лога мы не используем, это я здесь только для примера.

lalaki
11.11.2017 19:29Я бы настойчиво рекомендовал не использовать операторы вообще — даже если на самом деле "красивее" на первый взгляд, все только ухудшается:
- это никак не выразительнее банального
logger.warn(...) - логгер "притворяется" потоком, хотя в этом нет никакой необходимости
- солидный кусок нетривиального кода без серьезной отдачи
waiwnf
11.11.2017 19:46+2С операторами всё же удобнее, разнотипные компоненты легко конкатенируются. Например с glog в одну строчку банально написать что-то типа
LOG(WARN) << «Unexpected blah: » << blah << " instead of " << expected_blah;
А с logger.warn() надо же сначала сформировать строку, то есть либо stringstream с теми же операторами, либо snprintf() и пляски с выделением буфера нужного размера.
Отдача соответственно в повышении читаемости клиентского кода.lalaki
11.11.2017 20:21Каюсь, забыл, что в плюсах конкатенация нетривиальна.
Но все равно, разве так уж плохо
logger.warn("Unexpected blah: %s instead of %s"), что оправданы кастомные операторы?waiwnf
11.11.2017 20:30+2Не очень понял, как в вашем примере значения вместо %s будут подставляться. Если бы можно было
logger.warn("Unexpected blah: %s instead of %s", blah, expected_blah);
то конечно да. Но это же надо как-то через varargs (или как оно в c++ называется) blah и expected_blah внутрь логгера форвардить, а внутри там опять snprintf (?) и ещё веселее с выделением буфера, т.к. заранее размер строк мы теперь не знаем…
Сам ненавижу любую возню с перегрузкой операторов, но когда кто-то добрый уже всё сделал, то пользоваться удобно.
qw1
11.11.2017 20:41+2Но это же надо как-то через varargs (или как оно в c++ называется) blah и expected_blah внутрь логгера форвардить, а внутри там опять snprintf (?) и ещё веселее с выделением буфера, т.к. заранее размер строк мы теперь не знаем…
Или писать функцией, которая умеет <...>:
Но, конечно, если цель — отправить строку в произвольную библиотеку, то 2 вызова vsnprintf — сначала с буфером на стеке, скажем 2КБ, а если не хватило, то с выделением нового буфера и повторным вызовом.void Logger::logwrite(char level, const char* format, ...) { SYSTEMTIME st; GetLocalTime(&st); // write prefix... fprintf(stream, "%04d-%02d-%02d %02d:%02d:%02d [%c] ", st.wYear, st.wMonth, st.wDay, st.wHour, st.wMinute, st.wSecond, level); // write message { va_list argptr; va_start(argptr, format); vfprintf(stream, format, argptr); va_end(argptr); } fprintf(stream, "\n"); fflush(stream); }

Serge78rus
12.11.2017 11:54Не очень понял, как в вашем примере значения вместо %s будут подставляться. Если бы можно было
logger.warn(«Unexpected blah: %s instead of %s», blah, expected_blah);
то конечно да. Но это же надо как-то через varargs (или как оно в c++ называется) blah и expected_blah внутрь логгера форвардить, а внутри там опять snprintf (?) и ещё веселее с выделением буфера, т.к. заранее размер строк мы теперь не знаем…
У Вас же не C, C++ и есть шаблоны. Вполне можно написать безопасный аналог printf. Как отправную точку, можно рассмотреть пример из Википедии:
void printf(const char *s) { while (*s) { if (*s == '%' && *(++s) != '%') throw std::runtime_error("invalid format string: missing arguments"); std::cout << *s++; } } template<typename T, typename... Args> void printf(const char *s, T value, Args... args) { while (*s) { if (*s == '%' && *(++s) != '%') { std::cout << value; ++s; printf(s, args...); // продолжаем обработку аргументов, даже если *s == 0 return; } std::cout << *s++; } throw std::logic_error("extra arguments provided to printf"); }Serge78rus
12.11.2017 16:19Приношу извинения, опечатался, вместо «У Вас же не C, C++ ...», следует читать «У Вас же не C, а C++ ...»
qw1
11.11.2017 20:54+2разве так уж плохо logger.warn(«Unexpected blah: %s instead of %s»), что оправданы кастомные операторы?
Приходится следить за соответствием аргумента и спецификатора формата, а если хочешь включить в сообщениеstd::string, не забывать.c_str(), что частенько приводит к ошибкам
Всякие статические анализаторы свободно ловят ошибки в таком коде:
но не ловят в таком:std::string msg; snsprintf(buf, _countof(buf), "message: %s", msg); snsprintf(buf, _countof(buf), "message: %s, length=%d", msg.c_str());
Учитывая ситуации, когда лог пишется только при нештатных сценариях, опечатка в логировании может жить незамеченной очень долго. В случае возникновения нештатной ситуации, полез в лог разгребать — а ничего и не записалось (а то и вовсе приложение упало).std::string msg; applog.logwrite('W', "message: %s, isEmpty=%s, length=%d", msg, msg.empty());lalaki
11.11.2017 21:44Да, аргумент.
Коллеги, спасибо, понял, что в плюсах есть дополнительные причины для использования операторов, с их учетом уже минимум не так однозначно выглядит ситуация.
khim
11.11.2017 23:02но не ловят в таком:
Я, наверное, ничего не понимаю в колбасных обрезках, но вы, разумеется, добавили к опиcанию
std::string msg; applog.logwrite('W', "message: %s, isEmpty=%s, length=%d", msg, msg.empty());logwrite__attribute__ ((format (printf, 2, 3))), да? И какой же у вас дрянной анализатор после этого не словил ошибку?qw1
12.11.2017 10:51Спасибо. Даже не представлял, что это можно починить.
Для Visual C++
stackoverflow.com/questions/2354784/attribute-formatprintf-1-2-for-msvcqw1
12.11.2017 12:36+1Поигрался с этим, разметку понимает встроенный анализатор в Visual Studio, но не понимают такие инструменты, как PVS-Studio и ReSharper for C++.
Причём, в первом случае это можно понять — диагностики, входящие в стандартый /analyze, не в приоритете.
Но вот R# позиционируется как визуальный ассистент, поэтому подсветка форматных параметров в кастомных функциях, как и в printf, была бы полезной.
Скрытый текст
R# в стандартном#include <cstdarg> #include <cstdio> void my_printf(_Printf_format_string_ const char* format, ...) { va_list argptr; va_start(argptr, format); vprintf(format, argptr); va_end(argptr); } int main() { int v = 5, d = 6; my_printf("v=%d, d=%s\n", v, d); printf("v=%d, d=%s\n", v, d); return 0; }printfподкрашивает спецификаторы и подчёркивает ошибки, а в кастомном — нет:
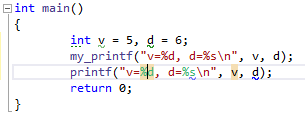
Hokum Автор
11.11.2017 22:56Вспомнил еще один аргумент в пользу потоков. Если поток только очищается перед выводом, а не создается каждый раз, то получается быстрее, чем с использованием функции sprintf. Точных цифр не помню — давно дело было.

Siddthartha
11.11.2017 20:36прикольно. в 99-м игрался с перегрузкой операторов, написал себе библиотечку для строк, списков и деревьев с симпатичным синтаксисом типа "на операторах") но до такого трюка не додумался.))
vvvanin
11.11.2017 21:13return std::move(tmlLog << data);
move здесь не нужен и даже вреден, может помешать задействовать copy ellision.Hokum Автор
11.11.2017 21:25Если бы было просто:
return TmpLog(*this, buf);
то да, не нужен.
Но оператор TmpLog::opertaor<< возвращает ссылку на TmpLog, а для того, чтобы его создать нужен конструктор копирования (без него ошибка компиляции), но он удален, чтобы избежать случайного сохранения объекта. Можно сделать конструктор копирования приватным, но он полностью повторит конструктор перемещения. Так что, если я правильно понимаю, то здесь copy ellision не будет работать. А виноват во всем TmpLog::operator<< — он возвращает ссылку на объект, а не новый объект.

batyrmastyr
11.11.2017 22:07Уж простите что напоминаю необходимости знать русский язык с его правилами (да и правилами хабра впридачу):
- не «в консоле», а «в консоли»
- «Здесь уровня логирования» — «Здесь не задаются уровни логирования» (на самом деле журналирования)
- «дополнительное желаемое использование» — ошибки нет, но сочетание жуткое
Cfyz
11.11.2017 22:43+1По-моему, логгирование в таком виде это один из немногих случаев, когда оправдано применение макроса:
LOG(Info, "Message " << with << " some " << data);
Где LOG выглядит, грубо говоря, так:
#define LOG(level, what) do { if (level <= currentLoggerLevel) { std::ostringstream ss__; ss__ << what; WriteSomewhere(ss__.str()); } } while (false)
Конкретное исполнение, конечно, адаптируется с учетом наличия уровней и целей логгирования, инструментария форматирования и метода вывода сформированного сообщения.
Нередко важным плюсом является отсутствие собственно форматирования строки, если уровень логгирования недостаточен и сообщение выводиться все равно не будет.Hokum Автор
11.11.2017 22:51Макросы дело хорошее и, при необходимости, логирование можно еще быстро убрать из всего проекта. Если бы разговор шел именно о системе логирования в целом, то я воспользовался макросами. Но в данном, локальном кусочке, мне этого не хотелось.
Кстати, создание строкового потока довольно затратное мероприятие. Точных цифр я не помню, но как-то доводилось сравнивать. В итоге если создавать ostringstream каждый раз, то вывод при помощи printf был быстрее, а если при выводе только очищать, то через потоки быстрее.
TargetSan
11.11.2017 22:56Мне не нравятся оба варианта, по нескольким причинам
- Завязано на операторы вывода в поток
- Требуется явно плодить объекты.
- Энергичное вычисление всего, что отправляется в лог. Даже если сообщение будет отфильтровано по уровню.
Почему мне не нравятся большинство нынешних библиотек журналирования — они как минимум некомпактные, а как максимум монструозны. И все без исключения рассчитаны на то, что только Их Высочеств будут использовать по всему проекту. Надо скрестить несколько проектов, использующих разные библиотеки журналирования — развлекайтесь с их "скрещиванием".
Мои попытки причесать собственный велосипед: https://github.com/target-san/log_facade.
Hokum Автор
11.11.2017 23:25Спасибо за мнение.
А по поводу скрещивания различных систем журналирования — я как раз с попыткой разрешить это и столкнулся. Обертка писалась для реализации интерфеса журналирования, который требуется библиотеке (внутрений продукт компании, но делается другим отделом), сама по себе библиотека писать лог не умеет. Непосредственно у авторов не спрашивал, но подозреваю, что такой подход был выбран из-за использования библиотеки в разных проектах с различными системами журналирования.TargetSan
11.11.2017 23:35+1Моё уважение вашим коллегам из другого отдела за то, что они об этом подумали. Особенно если интерфейс журналирования компактный и понятный.

AxisPod
12.11.2017 06:04Как логгер для проекта на коленке покатит, но для серьезного проекта я бы так делать не стал. Зачем же перегружать оператор << и иметь кучу проблем с этим, может лучше перегрузить std::ostream?
Hokum Автор
12.11.2017 12:27Мне не нужен был логер. Я неудачно выбрал название публикации.
Мне нужно было реализовать интерфейс логгера, требуемый сторонней библиотекой (ее делает соседний отдел). И синхронизовать обращение к нашей подсистеме логирования, так как она не расчитана на работу в многопоточном режиме, а библиотека пишет в лог из нескольких потоков. Чтобы процесс синхронизации не поломал порядок вывода логов библиотеки и логов кода, который ее использует, то я стал писать в лог через обертку и в своем коде. А мне удобнее форматировать при помощи оператора <<, чем писать sprintf.
А что вы подразумеваете под "перегрузить std::ostream"?
AxisPod
12.11.2017 12:35У себя в реализации отнаследовал std::ostream, отнаследовал std::streambuf. std::ostream для удобства использования наследовал, можно был и без этого пережить. В конечном итоге есть некий менеджер который возвращает logstream, с logstreambuf.
Hokum Автор
12.11.2017 12:59Думаю, если делать систему логирования, то да наследоваться было бы проще. Но мне нужно, чтобы последовательность вызовов << сформировала строку, которая как единое целое была бы передана в систему логировани, в примере — вызов функции LoggerWrap::write. И я не понимаю, как мне наследование упростило бы задачу?
AxisPod
12.11.2017 13:21Тут плюс в том, что всё что работает для ostream, то же работает и для данного логгера.
Hokum Автор
13.11.2017 14:29Я понял. Мы, видимо, говорим о разных вещах. У меня не полноценный логгер, а просто обертка. Я не хотел писать каждый раз что-то типа:
std::ostringstream os; os << "Something happened: value1 = " << value1 << "; value2 = " << value2; logger.write(os.str());
а просто написать:
logger << "Something happened: value1 = " << value1 << "; value2 = " << value2;

Akon32
12.11.2017 13:14"Явное лучше, чем неявное".
На первый взгляд, вариант 2 удобнее. Но что, если нужно вызывать flush() не в каждой строке, а например 1 раз после нескольких циклов? Если не ошибаюсь, в этом случае можно получить экземпляр TmpLog и работать с ним. Но, вероятно, некоторые разработчики будут забывать это делать, и ваша система логгирования начнёт тормозить из-за слишком частых flush(). А ещё с несколькими экземплярами TmpLog (при неправильном применении RAII) можно сильно перепутать порядок вывода лога.
Hokum Автор
12.11.2017 15:14Спасибо за замечания. Мне как-то в голову не пришло, что можно захотеть сохранить ссылку и потом еще раз создать TmpLog. Я у себя в голове видел только одно применение. Так как нет конструктора копирования, а конструктор перемещения приватный, то экземпляр TmpLog за пределы области видимости, где он был создан — не вывести. Это позволяет локализовать перемешивание лога одной областью видимости, но проблема все равно остается.
Чтобы не перепутались потоки при одновременной работе с несколькими экземплярами, можно хранить в каждом TmpLog свой ostringstream. Еще, как вариант, завести счетчик TmpLog и создавать новый поток только, если существует больше одного TmpLog.
TmpLog нужен, чтобы сформировать одну строку и передать ее система логирования. Flush, здесь, и явлется такми сигналом. На то как строка будет буфферезирована системой логирования это никак не влияет. С названиями у меня здесь, конечно, беда получилась. В целом оператор << нужен, что не писать каждый раз, что-то типа:
std::ostringstream os; os << "Something happened: value1 = " << value1 << "; value2 = " << value2; logger.write(os.str());
Так как это не система логирования, а небольшая обертка, которая будет иметь ограниченное применение, я надеюсь, что не случится казусов с созданием нескольких объектов TmpLog.

bibmaster
13.11.2017 12:23Потоковый wrapper c push message в деструкторе, см. boost logger, там же поверх навороты для автоматических атрибутов и завернутый в макросы анализ severity.
Hokum Автор
13.11.2017 14:14У меня не было задачи написать полноценный логгер. Мне нужна была обертка над существующей системой логирования, которая бы реализовала необходимый для сторонней библиотеки интерфейс.
bibmaster
13.11.2017 15:22Это не мешает посмотреть как там сделан этот helper. Точно так же формируется строка и передается сервису. Опять таки как правильно написать макрос условный, хотя есть и более красивый на мой взгляд вариант вместо for.
Hokum Автор
13.11.2017 19:11Извините, не так Вас понял. Посмотреть, конечно, ничего не мешает. Да и в комментариях, уже предлагали нечто похожее.

LazyMechanic
13.11.2017 13:53Вопрос, а зачем нужно знать конец этого лога? Для '\n'? Я просто имею 2 объекта — логгер и помощник. Логгер помещает в начале std::endl, а помощник уже докладывает все остальные параметры, поэтому при каждом новом вызове логгера он будет сам автоматически делать отступ и flush для предыдущего. Пример реализации *тут*.
Hokum Автор
13.11.2017 14:10Я, к сожаления, очень не удачно выбрал названия. У меня здесь не логгер, а обертка над нашей весьма специфичной системой логирования. Делается не flush, а строка передается в нашу внутреннюю систему логирования, она не умеет работать с потоками, а просто принимает строку (даже не строку а указатель на массив символов). К этой строке будет дописана временная метка при выводе в лог.
И небольшое дополнение к вашему коду: если помечаете конструкторы как удаленные, то делайте это в публичной секции, тогда при попытке их использовать в ошибке компиляции будет указано, что этот конструктор удален, а если в приватной секции, то компилятор пишет, что нет доступа, так как он приватный. По крайней мере у меня так было.
- это никак не выразительнее банального
rafuck
Вот тут наверное ссылку надо возвращать?
Hokum Автор
Нет, метод
должен возвращать объект по значению, в противном случае ссылка будет на объект который был создан стеке и уже разрушен.
Ravager
Hokum Автор
Будет ошибка компиляции, так как нет приведения типа LoggerWrap к TmpLog. А если Вы имели ввиду:
то здесь все нормально, так как возвращаемая методом ссылка находится вне тела метода и при завершении метода объект разрушен не будет.
Ravager
пардон, не заметил что нет приведения.