
Я не люблю читать статьи, сразу иду на GitHub
Заранее прошу прощения за это неудобство.
Все, что будет описано в данной статье тем или иным образом затронет несколько сфер computer science, но погрузиться в каждую отдельную сферу не представляется возможным. Заранее прошу прощения за это неудобство.
Рассказывать о том, что такое машинное обучение и искусственный интеллект, в 2017 году наверное нет необходимости. На эту тему уже написано большое количество как публицистических статей, так и серьезных научных работ. Поэтому предполагается, что читатель уже знает, что это такое. Говоря о машинном обучении, сообщество data scientist и software engineers, как правило подразумевает глубокие нейронные сети, которые приобрели большую популярность по причине своей производительности. На сегодняшний день в мире существует большое количество различных программных решений и комплексов для решения задачи искусственных нейронных сетей: Caffe, TensorFlow, Torch, Theano(rip), cuDNN etc.
Swift
Swift — инновационный, protocol — oriented, open source язык программирования, выращенный в стенах компании Apple Крисом Латнером (недавно покинувшим компанию Apple, после SpaceX и обосновавшимся в Google).
В Apple’s OSs уже были различные библиотеки для работы с матрицами и векторной алгеброй: BLAS, BNNS, DSP, впоследствии объединенные под крышей одной библиотеки Accelerate.
В 2015 появились небольшие решения для реализации математики на основе графической технологии Metal.
В 2016 появился CoreML:
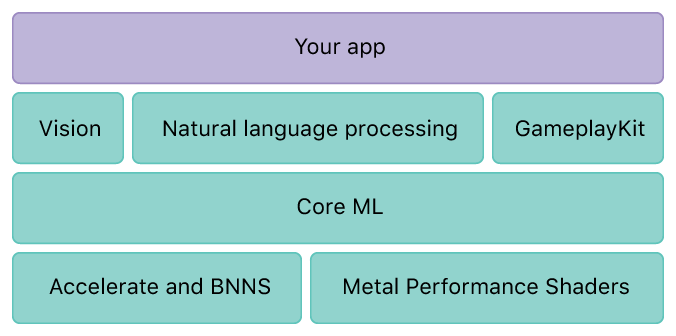
CoreML способен импортировать готовую, натренированную модель (CaffeV1, Keras, scikit-learn) и далее предоставить разработчику возможность экспортировать ее в приложение.
То есть, вам необходимо: Собрать модель на другой платформе, на языке Python или C++, используя сторонние фреймворки. Далее обучить ее на стороннем аппаратном решении.
И только после этого вы можете импортировать и работать на языке Swift. На мой взгляд очень нагромождено и сложно.
TensorFlow
TensorFlow, как и другие программные пакеты, реализующие искусственные нейронные сети, имеет множество готовых абстракций и механик для работы с нейронами, связями между ними, вычислением ошибок и обратным распределением ошибки. Но в отличии от других пакетов, Джеф Дин (сотрудник компании Google, создатель распределенной файловой системы, TensorFlow и множества других замечательных решений) решил заложить в TensorFlow идею разделения модели выполнения данных и процесса выполнения данных. Это значит, что сперва вы описываете так называемый граф вычислений, а уже после запускаете его вычисление. Данный подход позволяет разделять и очень гибко работать с моделью выполнения данных и непосредственно с процессом выполнения данных, распределяя выполнения по разным узлам (процессорам, видеокартам, компьютерам и кластерам).
TensorFlowKit
Для решения всего цикла задач от разработки модели до работы с ней в конечном приложении, в рамках одного языка я написал интерфейс доступа и работы с TensorFlow.
Архитектура решения выглядит как два уровня средний и высокий.
- На низком уровне C модуль позволяет обращаться к libtensorflow из языка swift.
- Средний уровень позволяет уйти от С указателей и оперировать “красивыми ошибками”.
- Высокий уровень реализует различные абстракции для доступа к элементам модели и различные утилиты для экспорта, импорта и визуализации графа.
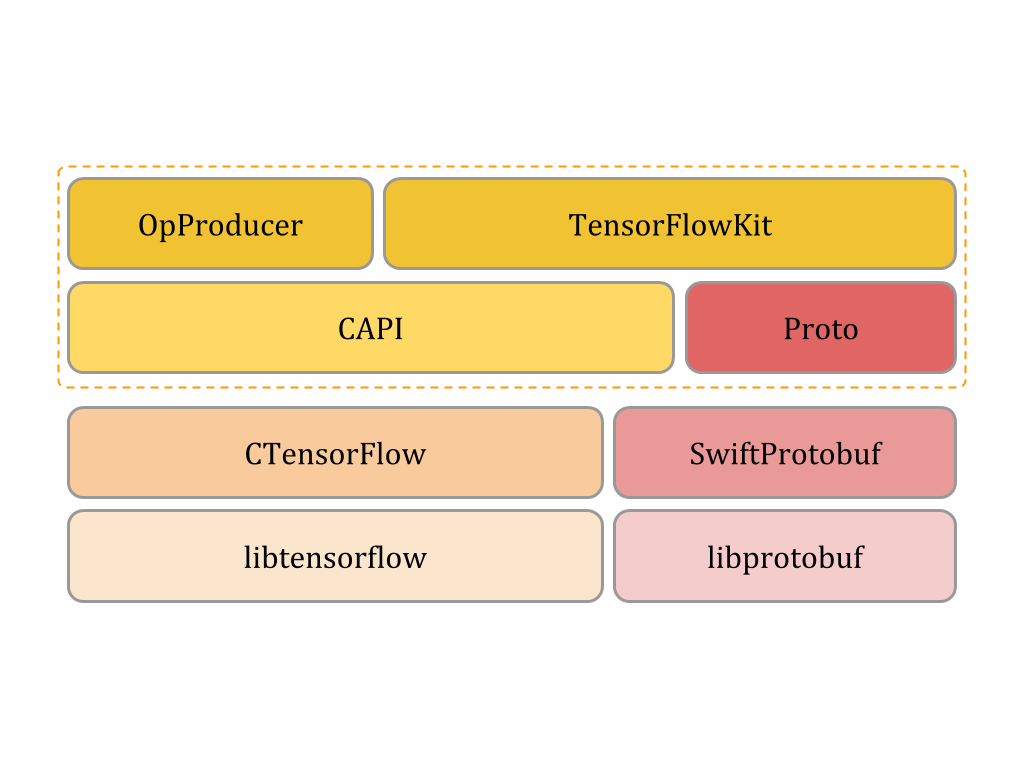
Таким образом, вы можете создать модель (Graph вычислений) на языке swift, обучить ее на сервере под управление ОС Ubuntu, используя несколько видеокарт и после без труда открыть в вашей программе на macOS или tv OS. Разработка может вестись в привычном Xcode со всеми его достоинствами и недостатками.
Документация и API находится по этой ссылке.
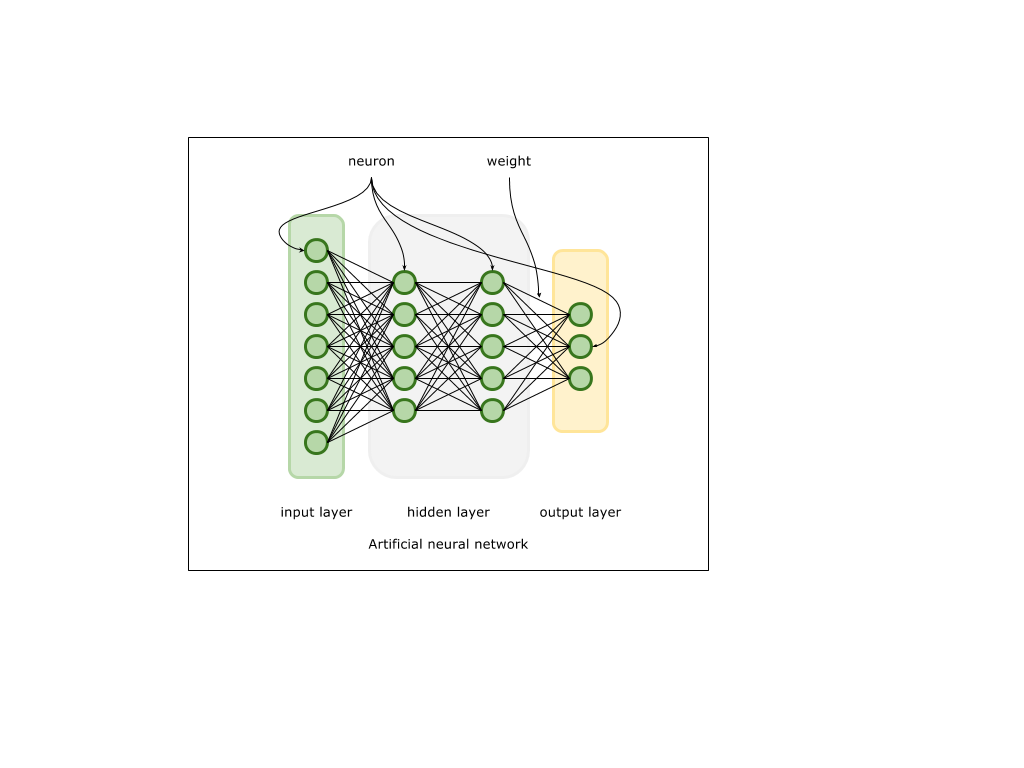
Очень кратко о теории нейронных сетей.
Искусственные нейронные сети реализуют некую (очень упрощенную) модель связей нейронов в тканях нервной системы. Входной сигнал в виде вектора большой размерности поступает на входной слой, состоящий из нейронов. Далее каждый входной нейрон передает этот сигнал в следующий слой, трансформируя его, исходя из свойств связей ( весов ) между нейронами и свойств нейронов последующих слоев. В процессе обучения на выходном слое формируется выходной сигнал, который сравнивается с ожидаемым. На основании разницы между выходным сигналом и сигналом образцом формируется величина ошибки. Далее эта ошибка используется для вычисления так называемого градиента — вектора, в направлении которого необходимо произвести коррекцию связей между нейронами, чтобы в будущем нейросеть выдавала сигнал более схожий с ожидаемым. Сам процесс называется обратным распределением ошибки или backpropagation. Таким образом, нейроны и связи между ними аккумулируют информацию, необходимую для обобщения свойств модели данных, которой обучается данная нейронная сеть. Техническая реализация упирается в различные математические операции над матрицами и векторами, которые в свою очередь уже были в той или иной степени реализованы такими решениями как BLAS, LAPACK, DSP, etc.
MNIST

Для примера я взял “Hello world!” в мире нейронных сетей: задачу классификации изображений MNIST. MNIST датасет — это тысячи изображений рукописных цифр размером 28 x 28 пикселя. Таким образом мы имеем десять классов, которые аккуратно распределены в 60 000 изображений для обучения и 10 000 изображений для теста. Наша задача — создать нейросеть, способную классифицировать изображение и определить принадлежность к одному из десяти классов.
Перед работой с самим TensorFlowKit необходимо установить TensorFlow. На macOS можно воспользоватся менеджером пакетов brew:
brew install libtensorflowСборка для linux доступна тут.
Создаем swift проект, подключаем к нему зависимость
dependencies: [
.package(url: "https://github.com/Octadero/TensorFlow.git", from: "0.0.7")
]Подготавливаем MNIST датасет.
Пакет для работы с MNIST датасетом напиcан и доступен по ссылке. Пакет самостоятельно скачает датасет во временную директорию, распакует его и представит в виде готовых классов.
dataset = MNISTDataset(callback: { (error: Error?) in
print("Ready")
})
Собираем необходимый граф операций.
Все пространство и подпространство графа вычислений называется Scope и может обладать своим именем.
На вход нашей сети мы будем подавать два вектора. Первый — это непосредственно картинки представленные в виде вектора большей размерности 784 (28x28 px).
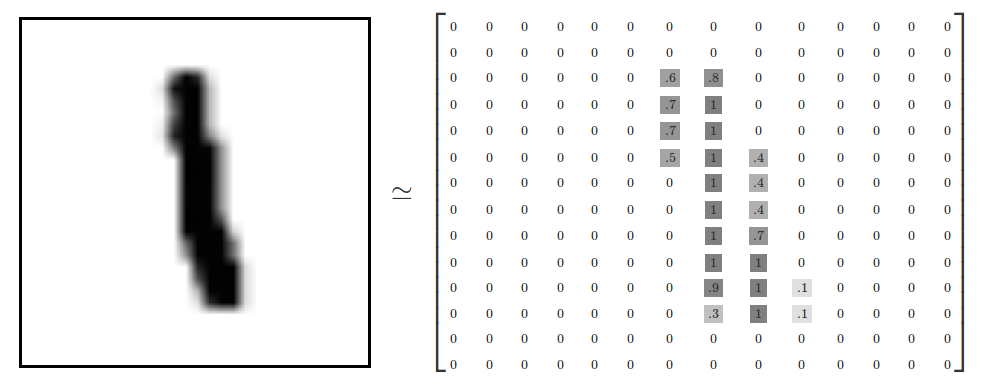
То есть, в каждом компоненте вектора x будет находится значение Float от 0-1, соответствующее окрашенности пикселя картинки.
Второй вектор будет соответствующим ей классом, зашифрованным в виде (см. ниже) где соответствующая 1 компонента соответствует номеру класса. В данном примере класс — 2
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0 ]
Так как входные параметры будут меняться в процессе обучения, мы создаем Placeholder для ссылки на них.
//Input sub scope
let inputScope = scope.subScope(namespace: "input")
let x = try inputScope.placeholder(operationName: "x-input", dtype: Float.self, shape: Shape.dimensions(value: [-1, 784]))
let yLabels = try inputScope.placeholder(operationName: "y-input", dtype: Float.self, shape: Shape.dimensions(value: [-1, 10]))
Для визуализации графа, я использовал TensorBoard. О том, как создавать графы и визуализировать процесс обучения средствами TensorFlowKit я расскажу в другой статье.
На графе Input выглядит следующим образом:
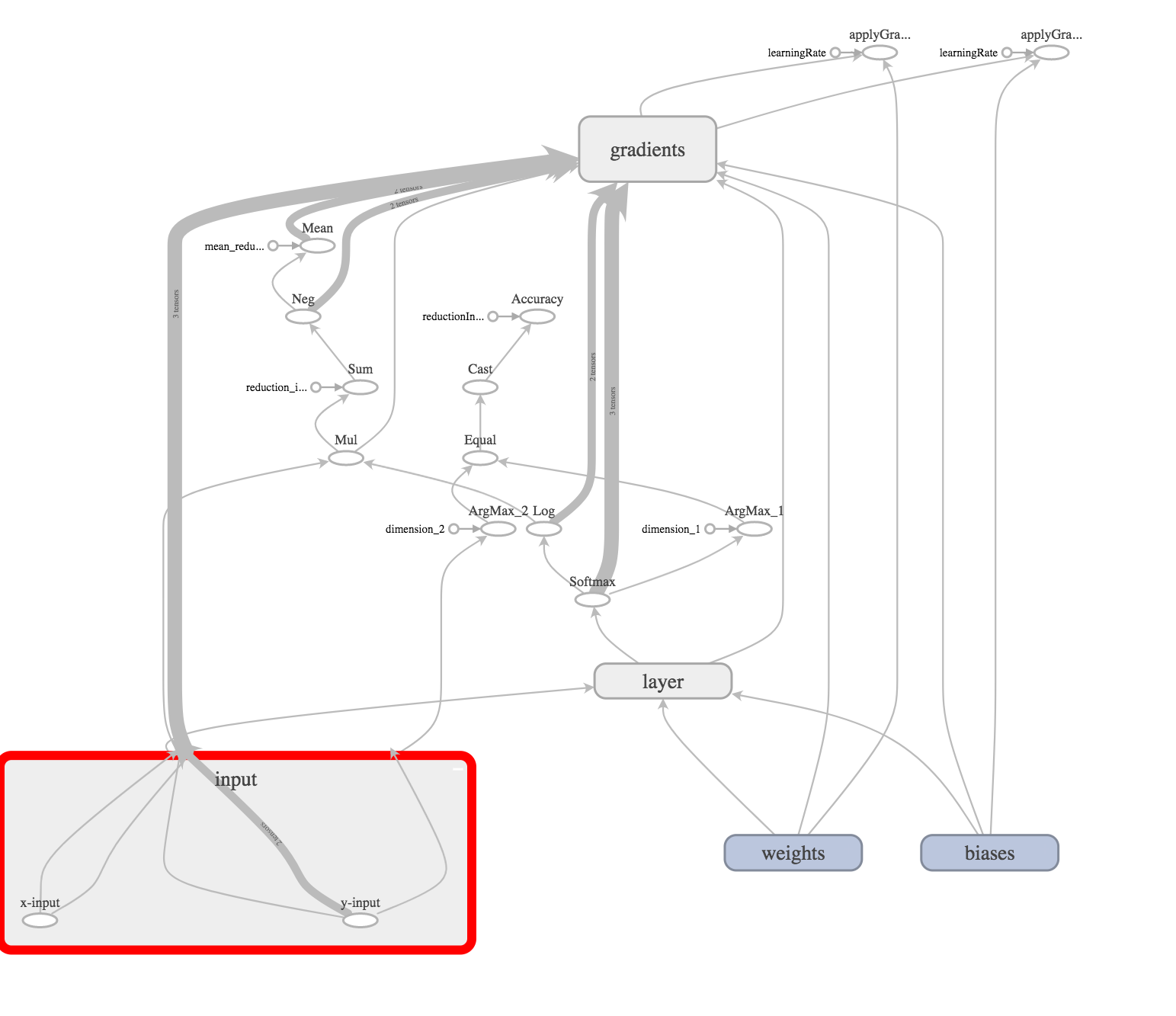
Это и есть наш входной слой.
Далее создаем веса (связи) между входным слоем и спрятанным слоем.
let weights = try weightVariable(at: scope, name: "weights", shape: Shape.dimensions(value: [784, 10]))
let bias = try biasVariable(at: scope, name: "biases", shape: Shape.dimensions(value: [10]))
Так как веса и базисы будут изменяться (настраиваться) в процессе обучения сети, мы создаем операцию переменных (variable) в графе.
И инициализируем их тензором заполненным нулями.
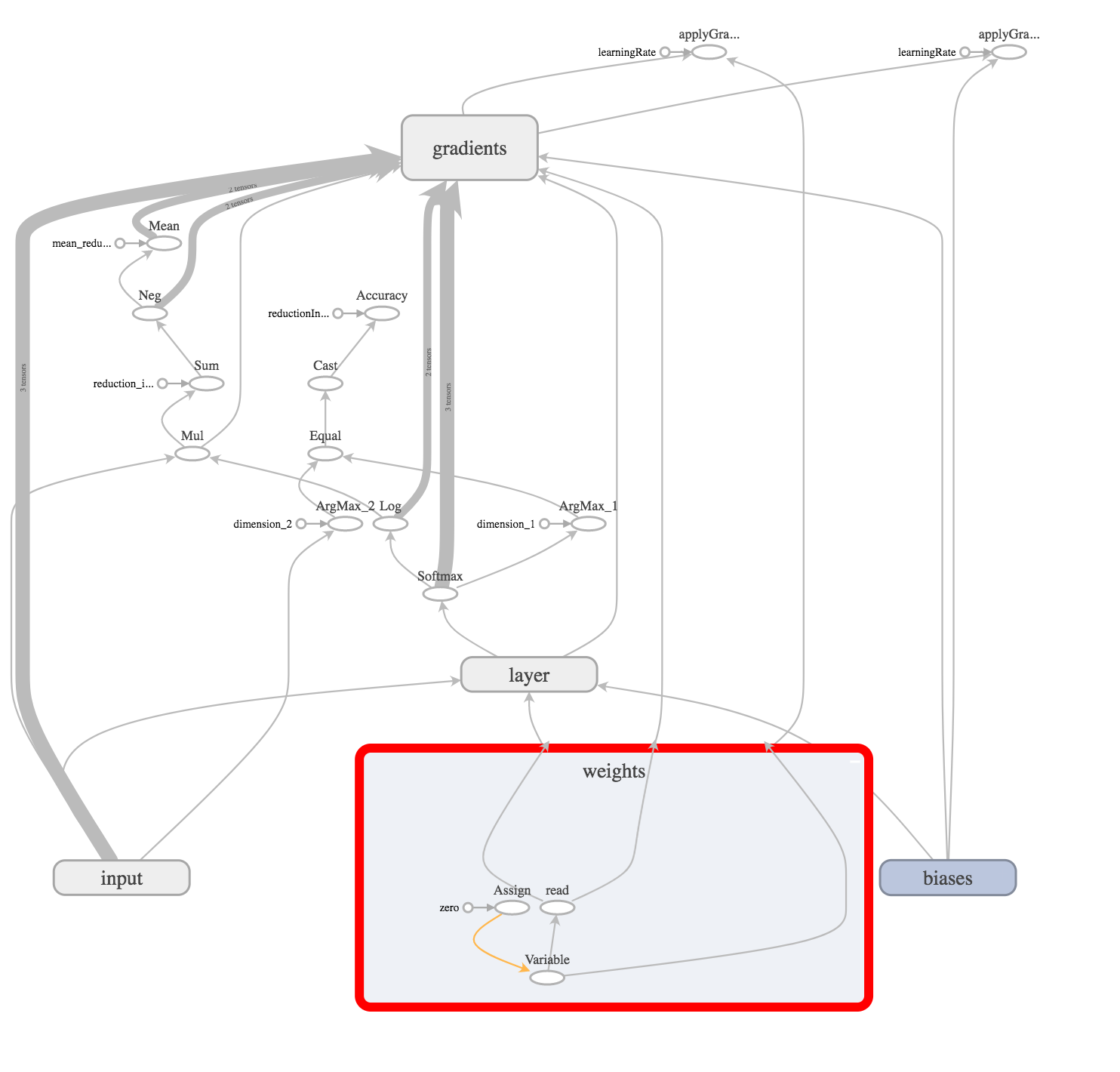
Теперь создаем скрытый слой, который произведет простейшую операцию (x * W) + b
Это операция умножения вектора x (размерностью 1x784) на матрицу W (размерностью 784x10) и прибавления базиса.
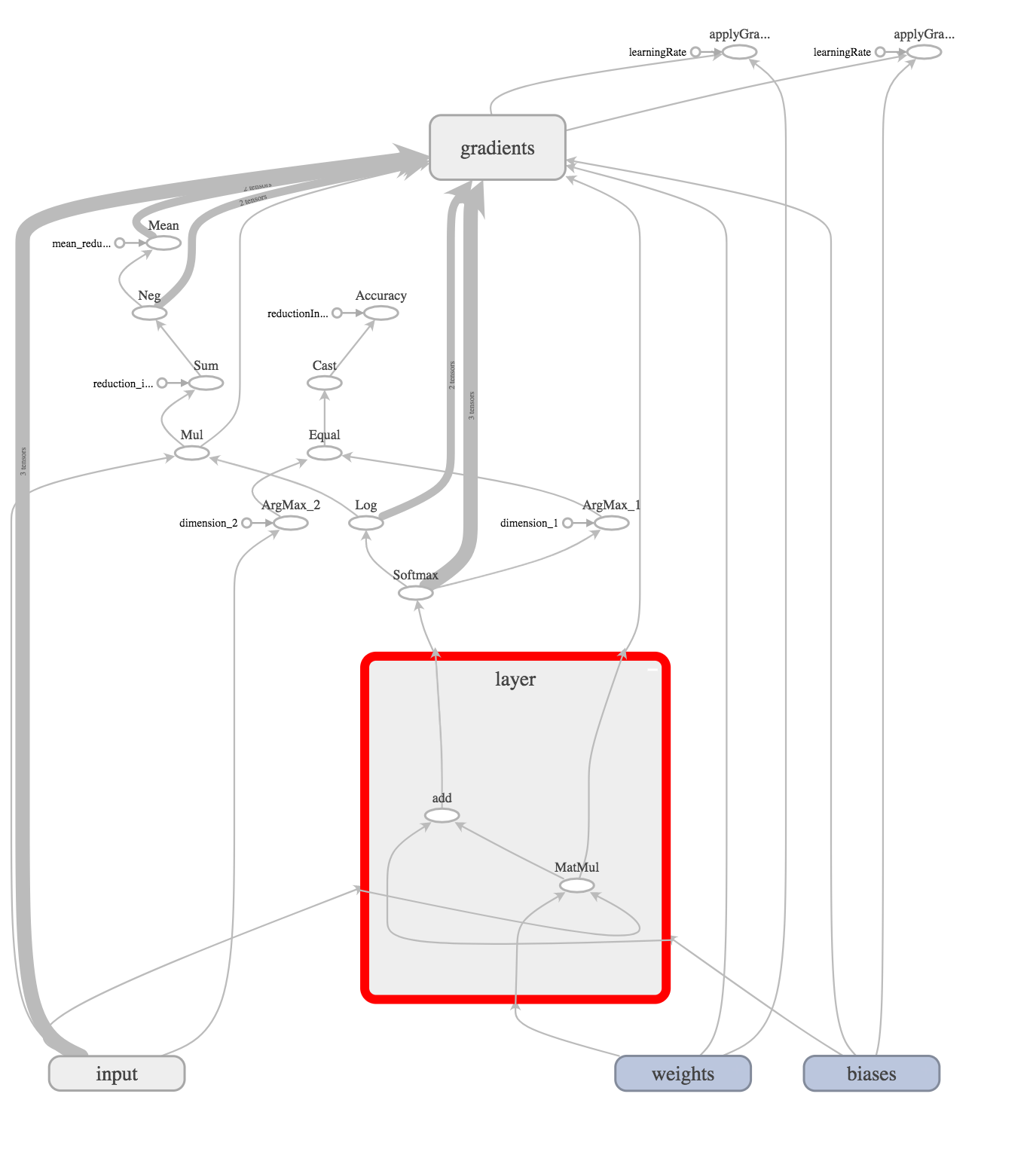
В нашем случае скрытый слой уже является выходным (задача уровня “Hello World!”), поэтому мы должны проанализировать выходной сигнал и выбрать победителя. Для этого используем softmax операцию.
Для лучшего понимания, того, что я опишу ниже, предлагаю, рассматривать нашу нейросеть как сложную функцию. На вход нашей функции поступает вектор x (представляющий картинку). На выходе мы получаем вектор говорящий на сколько функция уверена, в том, что входной вектор принадлежит к каждому из классов.
Далее берем натуральный логарифм от величины полученных предсказаний в каждом из классов и умножаем его на значение вектора правильного класса, аккуратно переданного в самом начале (yLabel).
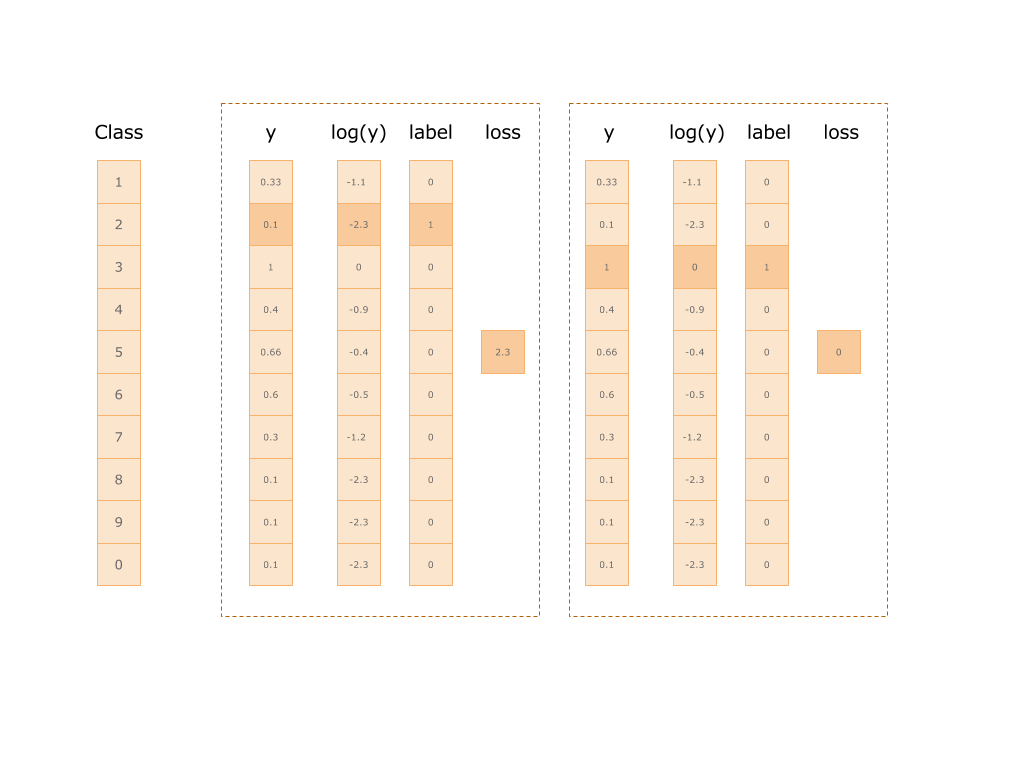
Таким образом мы получим значение ошибки и можем использовать его для “осуждения” нейросети. Ниже приведена картинка двух примеров. На первой класс 2: ошибка составила 2.3, на второй класс 1: ошибка равна нулю.
let log = try scope.log(operationName: "Log", x: softmax)
let mul = try scope.mul(operationName: "Mul", x: yLabels, y: log)
let reductionIndices = try scope.addConst(tensor: Tensor(dimensions: [1], values: [Int(1)]), as: "reduction_indices").defaultOutput
let sum = try scope.sum(operationName: "Sum", input: mul, reductionIndices: reductionIndices, keepDims: false, tidx: Int32.self)
let neg = try scope.neg(operationName: "Neg", x: sum)
let meanReductionIndices = try scope.addConst(tensor: Tensor(dimensions: [1], values: [Int(0)]), as: "mean_reduction_indices").defaultOutput
let cross_entropy = try scope.mean(operationName: "Mean", input: neg, reductionIndices: meanReductionIndices, keepDims: false, tidx: Int32.self)
Что же делать дальше?
Говоря математическим языком мы должны минимизировать целевую функцию. Один из подходов — метод градиентного спуска. О нем я постараюсь рассказать в следующей статье, если в этом будет необходимость.
Таким образом мы должны рассчитать, на сколько надо подправить каждый из весов (компонентов матрицы W) и вектора базисов b, чтобы в подобных входных данных нейросеть допускала меньшую ошибку.
Математически мы должны найти частные производные выходного узла по значениям всех наши промежуточных узлов. Полученные символические градиенты позволят нам “сдвинуть” значения наших компонентов переменных W и b согласно того, как каждый из них повлиял на результат предыдущих вычислений.
Магия TensorFlow.
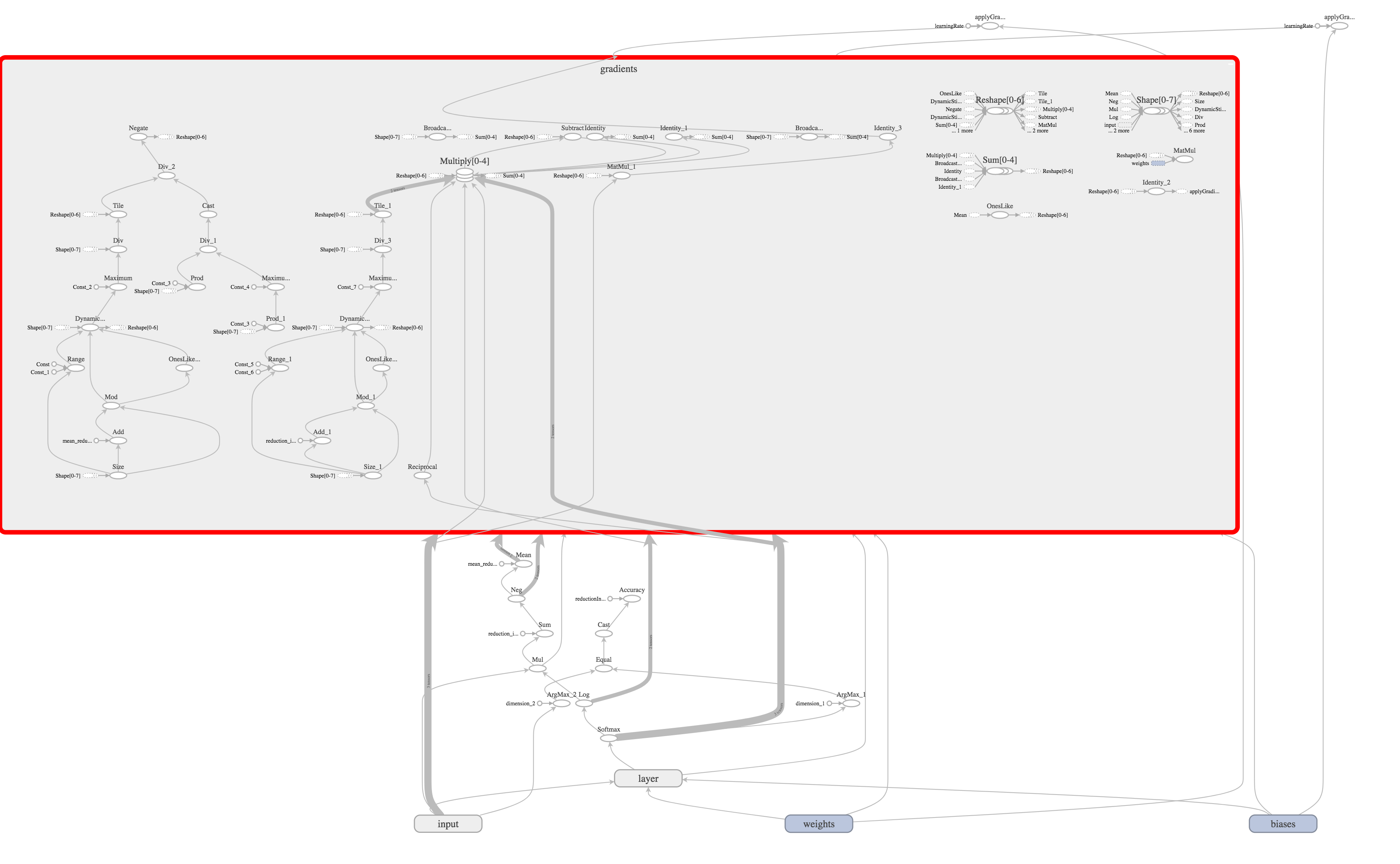
Дело в том, что все (на самом деле пока еще не все) эти сложные вычисления TensorFlow способен произвести самостоятельно, проанализировав граф, который мы построили.
let gradientsOutputs = try scope.addGradients(yOutputs: [cross_entropy], xOutputs: [weights.variable, bias.variable])
После вызова данной операции, TensorFlow самостоятельно построит еще пол сотни операций.
Теперь достаточно добавить операцию обновления наших весов на значение рассчитанное ранее методом градиентного спуска.
let _ = try scope.applyGradientDescent(operationName: "applyGradientDescent_W",
`var`: weights.variable,
alpha: learningRate,
delta: gradientsOutputs[0],
useLocking: false)
Все, граф готов!
Как я уже говорил, TensorFlow разделяет модель и вычисления. По этому построенный нами граф — это только модель выполнения вычислений.
Запустить вычисления мы можем с помощью Session.
Подготовив данные из датасета и поместив их в тенсоры, запускаем сессию.
guard let dataset = dataset else { throw MNISTTestsError.datasetNotReady }
guard let images = dataset.files(for: .image(stride: .train)).first as? MNISTImagesFile else { throw MNISTTestsError.datasetNotReady }
guard let labels = dataset.files(for: .label(stride: .train)).first as? MNISTLabelsFile else { throw MNISTTestsError.datasetNotReady }
let xTensorInput = try Tensor(dimensions: [bach, 784], values: xs)
let yTensorInput = try Tensor(dimensions: [bach, 10], values: ys)
for index in 0..<1000 {
let resultOutput = try session.run(inputs: [x, y],
values: [xTensorInput, yTensorInput],
outputs: [loss, applyGradW, applyGradB],
targetOperations: [])
if index % 100 == 0 {
let lossTensor = resultOutput[0]
let gradWTensor = resultOutput[1]
let gradBTensor = resultOutput[2]
let wValues: [Float] = try gradWTensor.pullCollection()
let bValues: [Float] = try gradBTensor.pullCollection()
let lossValues: [Float] = try lossTensor.pullCollection()
guard let lossValue = lossValues.first else { continue }
print("\(index) loss: ", lossValue)
lossValueResult = lossValue
print("w max: \(wValues.max()!) min: \(wValues.min()!) b max: \(bValues.max()!) min: \(bValues.min()!)")
}
}
Данный код можно найти на GitHub.
Каждые 100 операций, выводим, размер ошибки.
В следующей статье я покажу как посчитать Accuracy (что это, какие бывают и как их считают) нашей сети и визуализировать ее средствами TensorFlowKit.
Комментарии (7)

aparesidam
15.11.2017 12:13Спасибо за статью. А каким образом возможно экспортировать натренированную модель в модель формата Core ML (.mlmodel)?

Roaming Автор
15.11.2017 12:26На сколько мне известно этого сделать нельзя.
TensorFlow (на мой взгляд) самая перспективная библиотека машинного обучения. По этой причине я пошел по пути написания интерфейса на языке swift, что бы использовать все возможности библиотеки в swift приложениях.
griboedov-pro
15.11.2017 16:35А пробовал кто на ubuntu запустить этот пример?
Roaming Автор
15.11.2017 16:36Конечно, сборку тестировал на:
$ name -a Linux kraken 4.4.0-98-generic #121-Ubuntu SMP Tue Oct 10 14:24:03 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux $ swift -v Swift version 4.0 (swift-4.0-RELEASE) Target: x86_64-unknown-linux-gnu
$ swift build -Xlinker -rpath -Xlinker /server/repository/tensorflow/bazel-bin/tensorflow
$ ./.build/x86_64-unknown-linux/debug/01_MNIST
j_wayne
Сразу прошу прощения за нубские вопросы, но для меня пока это все темный лес.
Повороты такая сеть обрабатывает?
Если нет, то как сделать? Написать скрипт, который поворачивает эталоны и обучить еще и на этом наборе?
Roaming Автор
Спасибо за вопрос.
Вы правы, — простейший вариант поворачивать.
Данный пример сети крайне прост. Для обработки более сложных изображений нужна сеть с несколькими CNN слоями.
Даже она не способна будет распознавать повороты на >~ 25*.
Существуют более сложные сети, способные «видеть объект в 3D»
AlexPupyshev
Недавно вышли Capsule Networks, которая прям про повороты:
www.youtube.com/watch?v=VKoLGnq15RM
Думаю в самое ближайшее время появятся реализации на TF/pyTorch, если уже не вышли