
Привет, Хабр! Меня зовут Дмитрий Самсонов, я работаю ведущим системным администратором в Одноклассниках. Основные сферы моей компетенции — Zabbix, CFEngine и оптимизация Linux. У нас более 8 тыс. серверов и 200 приложений, которые в различной конфигурации формируют 700 различных кластеров. Тема этой статьи исчерпывающе описана в заголовке.
Сразу хочу оговориться:
- Я буду предвзят, потому что участвовал во внедрении CFEngine в Одноклассниках.
- Я пользовался CFEngine только версий 3.3—3.4.
- Я не питаю никаких иллюзий по поводу CFEngine, это значимый игрок, но не лидер рынка и не его аутсайдер. В статье не будет сравнений работы CFEngine с другими системами.
- Из систем конфигурации у меня есть опыт использования только CFEngine и Ansible.
Классические средства конфигурации
Для начала поговорим о классических системах, которые вам хорошо знакомы: ssh, scp, mstsc, winexe — все они хороши, но не подходят для конфигурирования большого количества серверов и управления ими.
Когда у нас в проекте серверов стало больше пары десятков, мы написали свою оболочку над утилитами dssh-command + dscp + dwinexe-command, которые в начале имеют букву d — distributed. Они умеют делать всё то же самое, но на большом количестве серверов одновременно.
Ещё один инструмент в нашем арсенале — образ операционной системы. Если нам нужно было поменять какой-нибудь конфиг в ОС, то мы проходили с помощью dssh по всему production, а затем изменяли образ операционной системы, чтобы новые серверы могли сразу получить этот конфиг, и считали работу выполненной.
Первым делом хочу остановиться на утилите dssh-command, потому что изначально она не содержала в себе абсолютно никакой защиты: что ей сказали сделать — то она и сделает, никаких дополнительных проверок.
# cqn feeds-portlet-cdb | dssh-command -t 300 "date"Cqn — это CLI-команда, которая позволяет получить список серверов из CMDB. Мы получаем список, отдаем его на стандартный вход dssh-command и просим выполнить на этих серверах команду date. Оператор -t 300 — это тайм-аут, по которому убивается как запущенная команда, так и все порождённые ею команды.
Зачем это нужно? Был интересный инцидент, сервер работал-работал, потом — бац! — на нём упало приложение. Стали расследовать: в этот момент ни один из системных администраторов с сервером не взаимодействовал, но за некоторое время до этого было подключение, администратор запустил без каких-либо параметров команду lsof, а в этом случае она начинает сканировать абсолютно все файловые дескрипторы, то есть соединения, файлы и так далее. Причем одно из запущенных приложений требовало огромное количество потоков выполнения и открывало множество соединений. В результате одна команда lsof сожрала много гигабайт памяти, после чего запустился OOM Killer и всех поубивал.
Затем нужно подтвердить ввод команды. В большинстве подобных инструментов обычно спрашивают лишь «Да/Нет», причём «Да» — зачастую выбор по умолчанию. Так что, по сути, такая защита не спасает нас от проблем. Но здесь в качестве подтверждения нужно ввести правильный результат математической операции:
How much is 5 + 8 =У нас есть шанс задуматься ещё раз, действительно ли мы хотим сделать именно то, что написали в командной строке. Причем этот калькулятор появляется не единожды, а при каждом двукратном увеличении объёма серверов.
Мы ввели правильный ответ, команда начинает выполняться.
Correct
srvd1352:O:0:Fri Oct 14 13:17:52 MSK 2016
Executing: "date"Но выполняется она тоже не на всех серверах сразу. Сначала на одном. Дело в том, что команда может быть просто неправильной. Если это oneliner, то очень легко ошибиться, поэтому убедимся на одном сервере, что в командную строку введено именно то, что нужно, и получен ожидаемый результат.
Далее команда будет выполняться на одном дата-центре. Весь production у нас находится в нескольких дата-центрах, причем все они независимы друг от друга. Мы можем потерять тысячи серверов в одном дата-центре — и пользователи этого не заметят.
Тем не менее потерять целый ДЦ никто не хочет. Чтобы этого не произошло, в дополнение к упомянутым механизмам защиты команда будет выполняться одновременно максимум на 50 серверах.
Дальше пользователю задаётся вопрос, хочет ли он продолжить на следующем ДЦ, и так — пока все сервера не будут охвачены. В конце можно посмотреть лог выполнения, standard output, standard error, exit status и так далее.
Do you want to execute the command on servers in DL? [Yes/No]: Yes
srvd1353:O:0:Fri Oct 14 13:17:53 MSK 2016
Executing: "date"
Do you want to execute the command on servers in M100? [Yes/No]: Yes
srve1993:O:0:Fri Oct 14 13:17:54 MSK 2016
srve2765:O:0:Fri Oct 14 13:17:54 MSK 2016
...
Full output saved in /tmp/dsshFullOutput_29606_2016-10-14_13-17.log
file.Однако всё это не дает никакой гарантии, что наши серверы настроены правильно. Самый банальный пример: сервер в данный момент выключен, потому что он просто перезагружается — или администраторы меняют сбойную память, диски. Есть миллион причин, по которым эти изменения могут не попасть на сервер. И чтобы такого не случалось, были придуманы системы управления конфигурациями.
Выбор системы
В 2012 году мы решили, что пора внедрить какую-то из этих систем, и сначала написали список критериев:
- интеграция с CMDB;
- установка пакетов;
- работа с файлами (копирование/редактирование/атрибуты);
- контроль файлов (содержимое/атрибуты);
- управление процессами и сервисами;
- ручной запуск политик/рецептов/манифестов;
- контроль версий, логирование изменений, отчёты;
- масштабирование, резервирование;
- поддержка Linux и Windows;
- проверка на наличие серверов без работающего CM.
Но в результате мы выбирали только по трём основным критериям.
Первый — производительность. Вот график нагрузки на CFEngine-хаб, который обслуживает 3000 серверов:
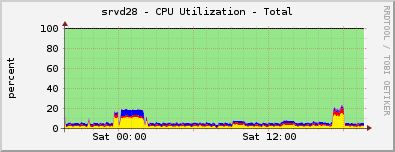
Здесь ещё море свободного процессорного времени, один сервер может спокойно обслужить десятки тысяч клиентов. С памятью всё то же самое.
Следующий критерий — зрелость. Это шкала появления современных средств управления конфигурацией.
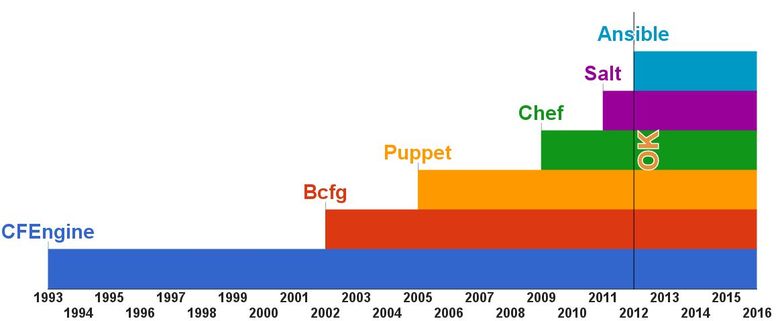
Как видите, CFEngine как минимум на 10 лет старше всех существующих на сегодня систем, и это даёт некоторую уверенность в его возможностях и надёжности. Кстати, два других популярных продукта, Puppet и Chef, появились так: разработчик Puppet использовал CFEngine, но он ему не нравился, поэтому он сделал Puppet; потом другому разработчику не понравился Puppet, и он сделал Chef.
Последний критерий — популярность. CFEngine совсем не распространён в России, но за её пределами использовался такими крупными компаниями, как NASA, IBM, LinkedIn. Давайте посмотрим на исторические данные в Google Trends.
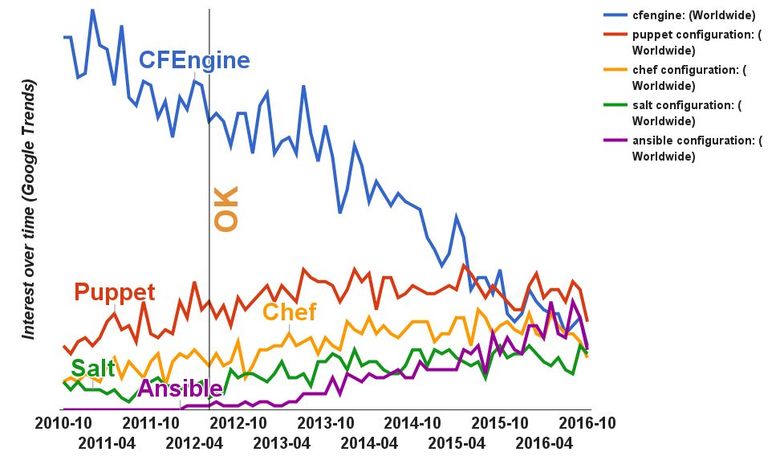
CFEngine был невероятно популярен, долгое время оставался лидером рынка, когда другие системы управления конфигурацией ещё были не очень распространены. В 2012-м CFEngine лучшим образом отвечал всем нашим требованиям. Многие демонизируют этот инструмент из-за специфичности его возможностей, логики и организации языка. Но можно его привести в такое состояние, когда его будет достаточно просто использовать.
CFEngine в Одноклассниках
Вот пример политики настройки типичного приложения в production.
"app_ok_feed" or => {"cmdb_group_feeds_proxy",
“cmdb_group_feeds_cache};
...
bundle agent app_ok_feed
{
vars:
"application" string => "ok-feed";
methods:
"app_ok" usebundle => app_ok("$(application)");
}Название политики — app_ok_feed, она применяется на две группы серверов — feeds_proxy и feeds_cache, в ней есть название приложения и запускаемый метод app_ok. Даже если вы не знаете синтаксиса CFEngine, трудностей с пониманием не возникнет.
Перейдём к следующему уровню абстракции — непосредственно политике метода app_ok.
bundle agent app_ok(application)
{
vars:
"file[/ok/bin/$(application)][policy]" string => "copy";
"file[/ok/bin/$(application)][mode]" string => "0755";
"file[/ok/conf/$(application).conf][policy]" string => "copy";
"file[/root/ok/ok.properties][policy]" string => "edit";
"file[/root/ok/ok.properties][suffix]" string => "$(application)";
"file[/root/ok/ok.properties][type]" string => "file";
methods:
"files" usebundle => files_manage("$(this.bundle).file");
}Здесь мы берём название приложения, копируем какие-то конфиги, выставляем им необходимые разрешения и переходим к следующему уровню абстракции: вызываем метод files_manage. То есть CFEngine позволяет упростить создание уровней абстракции.
Ещё несколько совсем коротких примеров:
- Добавить пользователя:
"user[git][policy]" string => "add"; - Запустить сервис:
"service[mysql][policy]" string => "start"; - Добавить крон:
"cron[do_well][cron]" string => "* * * * * do_well"; - Установить пакет:
"package[rsyslog][policy]" string => "add";
Распределение по типам наших политик:
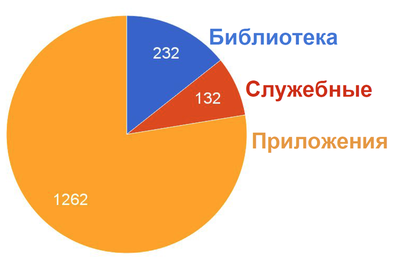
Всего их порядка 1500, самая большая политика занимает 27 Кб — как ни странно, это политика настройки Zabbix-сервера. Там описаны абсолютно все аспекты, можно взять голый сервер и запустить политику, в результате будет настроена БД и фронтенд со всеми нужными патчами.
Ещё несколько примеров специфических вещей, которые системы конфигурации зачастую не настраивают:
- IP-маршруты;
- кеш-записи HW RAID;
- SELinux;
- IPMI SOL;
- kernel-модули;
- RSS/RPS/RFS.
У нас это всё автоматизировано с помощью CFEngine. Достаточно сказать, какой режим вы хотите и на каком сервере, а система сделает всё остальное.
Недостатки
Тем не менее у CFEngine есть недостатки. В первую очередь это высокий порог вхождения. Самая большая боль для новых сотрудников и тех, кто их обучает, — объяснение всей внутренней логики. Конечно, есть высокие уровни абстракции. Тем не менее системному администратору, который хочет с этим работать, важно понимать, как инструмент работает под капотом.
Следующая проблема — CFEngine сильно отстаёт от конкурентов. Я не питаю иллюзий, знаю возможности современных систем, и CFEngine от них достаточно далёк.
У CFEngine нет возможности расширять функционал. Он написан на C. Другие популярные системы в основном имеют плагины, которые пишутся на более простых языках вроде Python.
Плохие шаблоны. Они слабы по возможностям, специфические вещи в них сделать нельзя, приходится создавать несколько разных файлов.
4 апреля
Чем примечательно 4 апреля? Это день веб-разработчика. Но не только. В 2013 году 4 апреля проект Одноклассники стал недоступен для всех пользователей, и мы пытались починить его трое суток. Проблема была сложная, все серверы стали недоступны для пользователей и системных администраторов, и ребут не помогал. Этот случай вошёл в мировую историю даунтаймов. Подробнее можно почитать в посте «Три дня, которые потрясли нас в 2013».
Можно ли было этого избежать? Естественно, у нас работали средства защиты:
- проверка синтаксиса;
- тестовые окружения;
- ревью;
- мониторинг.
Тем не менее дьявол кроется в мелочах. Тот же ревью хоть и существовал, но был необязательным. Что касается коммита, который всё сломал, то он прошёл ревью, его посмотрели как минимум два администратора — и это не спасло. В коммите в конфиг было добавлено несколько символов, и случилось трагическое стечение обстоятельств: баг одной системы наложился на баг другой, и всё рухнуло.
Когда несколько тысяч серверов перестали работать из-за CFEngine, то мы его первым делом остановили. Нам пришлось сесть и очень серьёзно подумать о том, как же существовать дальше, будут ли системные администраторы использовать какую-то систему конфигурации, а если да, то как. Кроме того надо было по возможности исключить человеческий фактор, физически ограничив возможность повторения катастрофы.
В первую очередь хочется отметить, что в конце концов мы оставили CFEngine. Более того, до сих пор он запускается раз в пять минут на каждом сервере. Это важно, потому что системы управления конфигурацией в первую очередь гарантируют, что сервер сконфигурирован именно так, как вы хотите. И это справедливо для всех наших серверов. На них стоят те конфиги, которые мы хотим, всё сделано абсолютно точно, мне не нужно это проверять — за меня это делает CFEngine или любая другая система управления конфигурацией.
Хочу отметить, что CFEngine вообще не участвует в развёртывании Java-приложений. Мы его используем скорее для подготовки к развёртыванию, которое у нас делает отдельная самописная система. Мы раскатываем сервер, CFEngine доводит его до состояния готовности, и можно другой системой спокойно устанавливать основное Java приложение.
Какие мы предприняли меры, чтобы подобная ситуация не повторилась?
Первый уровень защиты — git. Там есть хуки, а все исходники CFEngine-политик находятся в git. В git-хуках проверяется синтаксис и автоматом корректируется стиль, автозаполняется и проверяется commit message. Последнее не совсем относится к безопасности, но в случае каких-то проблем можно по номеру задачи или имени датацентра быстро найти все коммиты, которые к ним относятся. При создании коммита админ пишет в начале номер тикета и сам комментарий, а хук анализирует какие файлы изменились и добавляет в сообщение затронутые окружения. В результате типичное сообщение коммита выглядит как «Номер таска: [список окружений] комментарий». Например:
ADMODKL-54581: [D,E,G,K,P] add some cloud-minion-ec to stableСледующий шаг защиты — проверка в тестовом окружении. Тестовое окружение состоит из нескольких частей. Первая часть — unstable, это виртуальные машины, которые любой желающий может использовать, может их ломать любым доступным ему способом, нам их абсолютно не жалко. Обновляются они раз в пять минут. Дальше идёт testing-окружение — проверка на физических серверах (некоторые политики на физических серверах выполняются по-другому). И в отличие от виртуалок, физические серверы у нас есть в CMDB, там тоже по-другому могут применяться политики. Тем не менее этот слой тоже можно полностью терять, он обновляется раз в пять минут.
Следующая защита — проверка на части production-серверов с автоматизированным контролем нагрузки. Это уже реальные рабочие серверы, БД, фронтенды и т. д., где сидят реальные пользователи. Мы берём один сервер из каждого нового кластера, который мы устанавливаем в production, если он отказоустойчив и добавляем его к stable окружению. Таким образом, там есть абсолютно все виды железа (RAID-контроллеры, материнские платы, сетевые карты и т.д.), все виды приложений, их различные конфигурации. Всё, что только возможно у нас в production.
Т.к. в stable попадает только по 1 серверу из кластера и только если этот сервер можно терять без эффекта для пользователя, то даже фатальная ошибка в политиках stable окружения не ведёт к эффекту для пользователей, они продолжат использовать портал без каких-либо перебоев.
В stable могут коммитить все системные администраторы и они могут его поломать, но здесь уже обновление политик происходит не за пять минут, а за час. Всё-таки, никто не хочет лишний раз чинить сотню серверов, поэтому мы плавно проводим их обновление в течение часа.
Также для production-серверов автоматически контролируется нагрузка. Естественно, у нас есть мониторинг всего, но конкретно для этих серверов мы дополнительно в течение хотя бы двух часов следим, чтобы на них не появились аномалии. Может быть банальная утечка памяти. Если подобное сразу отдать в production, то последствия могут оказаться самые плачевные. При серьезных изменениях политики держатся в stable сутки.
Следующий механизм защиты — ревью. Мы проверяем стиль (то что не было автоматически скорректировано git-хуком), использование последних версий методов, «адекватность» кода.

Но перед тем как политики пойдут в production, ревьювер обязательно должен убедиться, что на всех предыдущих окружениях они не вызывают никаких ошибок, что нет аномалий с нагрузкой и прошло как минимум два часа. Только после этого ревьюер отправляет коммит в production.
Естественно, бывают проблемы, которые нужно быстро решить, и для этого можно обойти механизмы защиты. Это мы тоже предусмотрели. Если, допустим, на пяти серверах нужно быстро провести коммит, то вы можете зайти на пять серверов и обновить руками. Но на всех серверах вы так делать не будете. Для работы с большим количеством серверов есть специальные инструменты со своими механизмами защиты.
Сначала ревью занимались только 3 админа, которые внедряли CFEngine, лучше всех разбирались в нём и имели больше всего опыта.
Затем мы ввели двухуровневый ревью. Заревьювить мог любой админ. Это значительно ускорило работу, не нужно было ждать нескольких человек. Можно было пойти к своему соседу, он проревьюит, а вот постревью выполнял уже старший системный администратор.
Сейчас все админы набрали достаточный уровень компетенции, и мы отменили повторный ревью для всех, кто проработал в компании достаточно долго.
И последний уровень защиты — защита от распространения политик по production. Это так называемый «дартс».
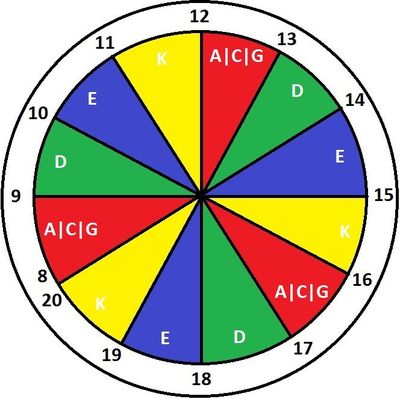
Буквы — аббревиатуры наших ДЦ. Дата-центр Data Line на букву D, он обновляется три раза в день: с 9 до 10, с 13 до 14 и с 17 до 18. Дата-центры независимы, благодаря этой схеме у нас есть время, чтобы заметить проблемы. Если политики обновляются по ДЦ и ДЦ начинает падать, то мы это вовремя увидим, а остальные ДЦ останутся незатронутыми. И даже если мы не успели заметить за целый час, то есть ещё как минимум три часа до падения всего production.
Если мы говорим, что «зелёный» Data Line начинает обновляться в 9 утра, это не значит, что 100 % его серверов сразу выкачали новые политики. Это делается постепенно. Мы же не хотим потерять целый ДЦ в один момент, поэтому одномоментно обновляться политики будут на ограниченном количестве серверов, это стандартная функциональность CFEngine — splay class. Руками ничего делать не надо, всё автоматизировано.
Дополнительная защита заключается в том, что политики обновляются только с 8 до 20. Никто не хочет сюрпризов по ночам, да и рабочего времени вполне достаточно для всех дел.
Если ошибка раскатилась на весь Data Line, то порядок действий зависит от того, насколько серьёзна проблема. Если нужно починить здесь и сейчас, то мы по-прежнему можем вмешаться руками через уже знакомый dssh или обычный ssh. Что бы при этом не возникло конфликта с CFEngine у нас есть механизмы временного отключения CFEngine для отдельных политик или даже для отдельных файлов. Забыть об этих временных изменениях тоже не получится, т.к. по истечению таймаута (3 дня) все изменения, которых нет в CFEngine будут откачены.
Если проблема возникла на большом количестве серверов, то и здесь можно действовать по-разному, в зависимости от тяжести ситуации. В целом мы стараемся ничего не делать в ручном режиме. Если проблема может ждать, то станем действовать по стандартной процедуре: коммит, потом stable, ревью — и в течение четырех часов фикс будет ползти до этих серверов. Если же всё плохо и есть заметные проблемы в работе сервиса, то оперативно откатываем коммит.
Итак, у нас есть пять уровней защиты, когда политики готовятся и отправляются в production. Но мы решили, что этого недостаточно. Что делать, если плохая политика всё-таки прорвалась в production?

У нас есть план Б. Это ещё один git-репозиторий, в котором тоже есть политики, но они очень простые, их очень мало, и мы туда очень редко вносим изменения. Если всё сломалось, то CFEngine переключается на альтернативный набор политик, и это позволяет в первую очередь сохранить работоспособность самого CFEngine как нашего основного инструмента. И после переключения мы можем использовать его для починки чего-то более серьёзного.
 Но и этого нам показалось мало, так что мы написали небольшой скрипт, который позволяет очень быстро, за десятки секунд остановить CFEngine на всем production. С 2013 года мы этим инструментом ни разу не воспользовались! Но периодически проверяем его работоспособность
Но и этого нам показалось мало, так что мы написали небольшой скрипт, который позволяет очень быстро, за десятки секунд остановить CFEngine на всем production. С 2013 года мы этим инструментом ни разу не воспользовались! Но периодически проверяем его работоспособность
Почему нет автоматического отката изменений? Потому что в CFEngine нет транзакций и логов. Естественно, конфиги можно бекапить, и мы это делаем. Но мы не можем знать весь объём работ, который привел к этой проблеме. Может, это был конфиг. Может, обновление пакета. Может, рестарт сервиса. Может, сочетание действий или их последовательность. И чтобы их откатить, нужно знать, что конкретно было сделано. Это можно посмотреть по логу, но это не автоматическая операция.
Утилита, которая позволяет в ускоренном режиме обновить большое количество серверов, тоже может всё поломать, поэтому мы решили туда встроить защиту. Мы не просто обновляем серверы, но проверяем, что они выполняются без ошибок, и делаем это как минимум два раза: обновили серверы, запустили политики, проверили, что всё в порядке, потом ещё раз запустили политики и ещё раз проверили.
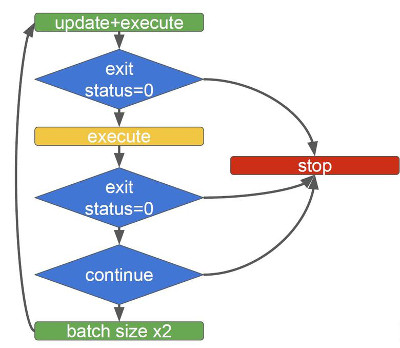
Если между двумя запусками сервер стал недоступен или вылетела ошибка, то выполнение скрипта остановится. Сколько бы серверов вы ни дали на исполнение, команда будет выполняться на ограниченном количестве машин, каждый раз это число станет увеличиваться: 50, 100, 200, 400 и т. д.
Краткие итоги
Тестирование — очевидно необходимая вещь, но важно делать его правильно. Инструменты для системного администрирования должны учитывать специфику задач:
- тестирование политик должно проводиться на разных серверах,
- оно должно продолжаться какое-то время, достаточное для выявления долговременных проблем
Ревью нужно проводить обязательно. Когда политики отправляются в production, это не должно происходить скопом на всех серверах, делайте независимые друг от друга части production и обновляйте их по очереди и плавно. И какую бы защиту вы ни сделали — у вас всегда должен быть план на случай аварии, а лучше два, если первый план не подошёл.
Статья подготовлена на основе одноимённого доклада на Highload++ 2016.
Комментарии (8)

amarao
21.11.2017 17:20Никогда не щупал cfengine, рядом есть ребята из соседней компании (в одном холдинге), они переходят с cfengine на ansible и писают кипятком от восторга.
Наблюдаю рядом сверхсложные инсталляции на chef'е (106000 строк) и ansible'е (14000 строк).
Мои наблюдения: как система управления конфигурациями chef куда более продуман на уровне абстракций и переиспользования кода, а так же работы в большой команде (когда каждый видит и трогает маленький кусочек, а на выходе большой и необъятный продакшен). Однако, у него есть гигантский, неподъёмный техдолг: омерзительные worst practice по пакетированию и сопровождению самого chef. Те «deb'ки», которые предоставляет chef — это гигантские бандлы где вендорят всё (включая базы данных и реббит, в некоторых дебках beam.smp запакетирован два-три раза, потому что его тоже вендорят).
Второе возражение — руби. Кому-то это большой плюс, но меня альтернативное сознание руби совершенно не радует, так же как и не радует состояние ruby в смысле пакетирования в debian/ubuntu.
Ansible: туман в голове. С его помощью можно описывать совершенно нереально сложные сценарии и творить чудеса, но все эти чудеса держатся на самодисциплине. Ансибл не предоставляет никакой разумной policy (и это редкий случай, когда я говорю, что софт должен предоставлять полиси), а значит, все методы выстрелить в ногу оставлены пользователю as is, многие без предупреждения.
При этом ансибл написан на питоне и живёт разумно как в качестве хост-софта, так и в качестве virtualenv'а. Довольно разумная система lookup плагинов даёт возможность делать кульбиты на питоне, зато всё остальное — довольно дуболомный и простой линейный код на ямле, в котором даже include_role не вызывает особой боли (кроме ситуации, когда переопределяются handler'ы, но я могу сказать «не делайте так»).
При этом инфраструктура chef'а куда более заточена на тестирование и модульность.
При этом chef пишется товарищами с прицелом на энтерпрайз-пользователей (винды), так что примерно половина хорошего, которая могла бы быть, у них отсутствует.
По поводу поста:
DARTS выглядит и звучит крайне любопытно.
erthad
22.11.2017 00:34Chef в виде бандла не сразу появился, а как ответ на постоянную боль с установкой гемов.
Какой у нас на хосте руби? Системный 1.8? Завернутый в магию RVM? Зашимленный в rbenv? Какой-нибудь странный самосбор в /usr/local? А на маке? А на винде?
С контролем этого хозяйства раньше были реальные проблемы. Сейчас просто притаскивает с собой все что нужно и работает. Лишние 200Мб на диске проблемой редко когда будут.amarao
22.11.2017 11:33Именно. По этой причине я и говорю, что ruby — это одна из pain point для chef'а. Почему? Потому что ruby'сты говорят, что их система управления зависимостями (с гемами) самая хорошая и ничего слаще они не едали. А потом начинается, что нужно ruby-dev не той версии, да и сишные header'ы в системе из ниоткуда не берутся.
В этом смысле питон куда более разумно интегрирован, и умудряется успешно избегать вендоринга (не запрещая его в то же самое время).

blexeyaykov
22.11.2017 00:06Кроме open-source систем управления конфигурациями не забывайте и о том, что существуют ещё и коммерческие продукты, такие как, например, BMC|Bladelogic Server Automation (BSA).
amarao
22.11.2017 11:3599%, что они дохлые с точки зрения реального продакшена. Причина? Комьюнити нет, опенсорсных кукбук (ролей и т.д.) нет, оно решает боль только конкретных заказчиков, которых, очевидно, меньше, чем у opensource-проектов.
А главное, я не знаю какая у них лицензия, но я точно знаю, что ими нельзя пойти и сделать что-то прикольное за 5 минут на виртуалочке в лаборатории. Лицензии, и всё такое.blexeyaykov
22.11.2017 11:48Ответ из серии: Я Бродского не читал, но осуждаю…
amarao
22.11.2017 12:21Ответ из серии: у них есть критический недостаток, и никакой объём усилий коммерческой компании не сможет его скомпенсировать.
inkvizitor68sl
Ого, хоть кто-то использует CFe в России )