
Так кто же был прав — мы или пользователи? Как оказалось — и мы, и они. Ну и вообще дело обстояло значительно серьёзнее, чем казалось на первый взгляд.
Наш точка зрения
Ещё в самом первом релизе нашего плеера в нём была функция случайного перемешивания плейлиста. Мы использовали для этого алгоритм Фишера-Йетса — и он давал идеально случайное перемешивание. Но что такое «идеально случайное»? Это значит, например, что мы можем получить один из двух нижеуказанных порядков песен с одинаковой вероятностью (разные цвета означают треки разных исполнителей):
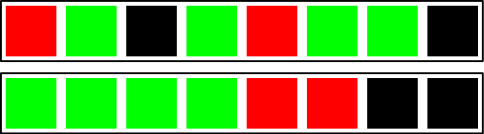
Кстати, личное мнение: алгоритм Фишера-Йетса является одним из наиболее элегантных из известных мне алгоритмов. Это просто поразительно, как столь непростая задача может быть решена в 3 строчки кода, дать при этом верный результат и выполнить минимально необходимое количество операций.
Заблуждение игрока
Сначала мы не понимали, что именно нам пытались сказать пользователи своими жалобами на «не случайность». Но после вдумчивого чтения комментариев мы поняли, что людям не нравится ситуация, когда подряд играют несколько песен одного и того же исполнителя. И даже не просто «подряд», а когда, например, на 5 воспроизведённых песен 3 принадлежат одному автору (даже если между ними играли другие песни). Люди считали это явным нарушением случайности.
Общеизвестно, что люди иногда серьёзно ошибаются в интуитивном восприятии вероятностей. Представьте, что каждый день на работе вы подбрасываете монетку, чтобы решить, что будете сегодня есть на обед — тайскую еду или индийскую. В первый 4 дня монетка выбрала тайскую. И вот в пятницу вы думаете «так, 4 дня монетка выбирала одно и тоже, ну, сегодня точно будет индийская еда!». И снова выпадает тайская. Дело в том, что у монетки нет памяти, она «не знает», что она выбирала вчера и совершенно не учитывает это при сегодняшнем своём «решении». Миллионный бросок имеет такие же шансы на выпадения орла или решки, как и первый — 50%.
Или вот другой пример: люди думают, что если сыграли несколько раз в лотерею и не выиграли, то в следующий раз у них больший шанс что-то выиграть. Этот феномен называется заблуждением игрока, и он применим и для лотереи, и для вышеописанного случая с монеткой и выбором еды.
Давайте вернёмся к нашим пользователям, которые тоже люди, а значит не менее остальных подвержены заблуждению игрока. Если вы только что прослушали песню какого-то исполнителя, а в вашем плейлисте есть и другие его песни, то у этих песен при случайном перемешивании плейлиста есть полное право попасть на следующую позицию в плейлисте. Они ничем не хуже других песен.
Но, как говорится — «клиент всегда прав». И мы решили подумать о том, как изменить наш алгоритм перемешивания таким образом, чтобы его «случайность» была достаточно хорошей не с математической, а с психологической точки зрения. Поскольку идеальная математическая случайность не выглядит для людей достаточно случайной.
Алгоритм
Задача выглядела как нечто, что уже должно было быть решено кем-то раньше. И действительно, мы нашли статью "Искусство перемешивания музыки", которую написал Martin Fiedler и где решается примерно та же проблема. Однако, описанный в ней алгоритм был переусложнён и иногда работал слишком медленно, так что мы модифицировали его в соответствии с нашими задачами:
Главная идея похожа на «встряхивание». Представьте, что у нас есть картинка, нарисованная в оттенках серого цвета (их несколько сотен):

Мы хотим упростить картинку, преобразовав её к черно-белому спектру (использовать только чисто чёрные и чисто белые пиксели). Это можно сделать так: если в сером пикселе более 80% чёрного — он получает шанс в 80% стать чисто чёрным и 20% стать чисто белым. Мы обрабатываем пиксели по одному и для каждого определяем новый цвет по вышеописанному правилу. Результат, конечно, будет чем-то напоминать оригинал, но всё же нельзя сказать, что получилось хорошо:
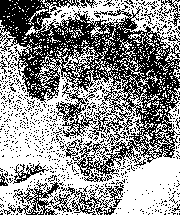
Как вы можете заметить, чёрные пиксели сбились в кластеры, плюс образовались большие белые промежутки между ними. Было бы лучше, если бы группы чёрных и белых пикселей были меньше и распределены более равномерно. Для этого можно использовать другой алгоритм, например, Флойда-Штейнберга:

Кластеры, хорошо заметные на предыдущей картинке, пропали. Мы можем использовать идеи данного алгоритма и в нашей задаче по перемешиванию песен. Это позволит нам избежать сбивания песен одного исполнителя в кластеры — мы постараемся распределить их по всему плейлисту. Давайте представим, что у нас есть плейлист, состоящий из песен таких исполнителей, как The White Stripes (красный цвет на рисунке), The xx (чёрный), Bonobo (зелёный), Britney Spears(розовый) и Jaga Jazzist (оранжевый). Мы возьмём песни каждого из исполнителей и постараемся «размазать» их по плейлисту. Картинка лучше тысячи слов:
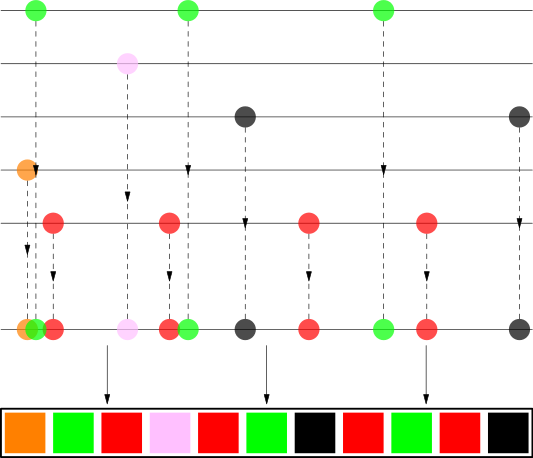
Как вы можете заметить, песни каждого исполнителя распределены достаточно далеко друг от друга и человеческому глазу такой порядок плейлиста выглядит идеально случайным (хотя таковым и не является). Давайте посмотрим детальнее на то, как работает алгоритм.
Пусть у нас есть 4 песни исполнителя The White Stripes (как на картинке выше). Это означает, что каждая из песен должна попасть примерно в каждые 25% общей продолжительности плейлиста. Мы распределяем 4 песни на расстоянии от 20% до 30% друг от друга (так выглядит «случайнее»). Видите, расстояния между красными кружками на линии не одинаковы. В начале мы добавляем случайный отступ, иначе первые песни каждого исполнителя попадут в точку 0 на линии. Вы можете заметить, что у Britney Spears и Jaga Jazzist есть всего по одной песне, но случайное стартовое смещение помещает их в случайное место плейлиста. Мы также перетасовываем песни одного исполнителя друг относительно друга (здесь сойдёт и старый алгоритм Фишера-Йетса, хотя можно и рекурсивно применить наш новый алгоритм если мы, например, захотим распределить песни из разных альбомов так же равномерно, как мы распределяем песни разных исполнителей).
Заключение
Сейчас алгоритм уже используется нашими плеерами на всех платформах. Спасибо всем пользователям, которые хорошо описали свои проблемы, касающиеся случайности плейлистов.
Что ещё можно почитать по этой теме
Комментарии (49)

4eyes
29.11.2017 15:03Теперь пользователи с математическим образованием начнут жаловаться на недостаточно случайное перемешивание.

Sirion
29.11.2017 21:02Если существует возможность применить перемешивание несколько раз подряд, то результат псевдослучайного шаффла, скорее всего, будет стремиться к случайному с увеличением эн.

KvanTTT
30.11.2017 04:16Поэтому нужно ввести опцию по выбору случайного алгоритма специально для математиков.

zigrus
29.11.2017 15:08перемешивать исполнителей. чем больше песен, тем с большей вероятностью его песня попадет на следующее место в списке.
оранжевый 1 раз
розовый 1 раз
черный 2 раза
зеленый 3 раза
красный 4 раза

edge790
29.11.2017 15:14Напомнило Сида Меера и про его фразу смысл которой: "Случайность не подходит для игр, потому что игрок считает, что его обманывают. Поэтому мы ей 'помогаем'".
когда игрок, которому предсказывали 33-процентный шанс выиграть в битве, трижды подряд проигрывал в ней, то он ощущал гнев и недоверие
Сама статья: https://habrahabr.ru/post/320296/mayorovp
30.11.2017 08:59Проблема его игр — не в восприятии случайности, а в том что у толпы копейщиков есть шанс заковырять танк, а отряд партизан с автоматами не способен выбить окопавшуюся фалангу без потерь личного состава :-)
KoMePcAHT
29.11.2017 15:14очень раздражает когда я переключил какой-то трек, не дослущав до конца, а плеер думает что мне не нравится этот трек и включает его заметно реже остальных, хотя я мог переключить его по другой причине
slonm
29.11.2017 17:54Еще треки стоит ранжировать по темпу, после этого задать мягкое правило выбора трека. Например один трек из каждого двадцатиминутного интервала будет медленным, а остальные быстрые.
Эфир с такими цикличными напряжениями и расслаблениями слушать приятнее
vics001
29.11.2017 18:25Боже мой… Это Spotify пишет? Достаточно погуглить сколько жалоб на то, что Random не проигрывает все песни из плейлиста!!!
Подарить им учебник программирования что ли или Кнута, как сгенерировать случайную перестановку?
Простите, но просто такие факапы в музыкальной платформе не ожидаешь.
Danik-ik
29.11.2017 20:58Пипл не читал Кнута. Пиплу нужны хлеб и зрелища. Желательно все. И так, как он хочет. Предложенное решение даёт именно все песни и именно так, как хотят люди — в "как бы равноменом" распределении. Именно такого результата ждёт тот, кто жмёт на кнопку рандома, и плевать на педантов и буквоедов, которые зацепились за слово "случайный". Я бы вообще предложил термин "вперемешку", но уже исторически сложилось, как сложилось.
Возвращаясь к Кнуту: теоретическая база — это хорошо, но если нужны семь перпендикулярных красных линий, часть из которых зелёная (и далее по тексту), не надо махать Кнутом. Надо пойти и обеспечить, ибо именно удовлетворённые пользователи формируют доходную часть бюджета. А классики — они для внутреннего употребления, чисто клубная фишка.

savostin
29.11.2017 19:20Я на своих радио не составляю плейлист, а получаю следующую песню из списка по параметрам (близкий к текущей песне BPM, например), отсортированного в порядке убывания времени последнего проигрывания песни, времени последнего проигрывания исполнителя и количества проигрываний.

Irker
29.11.2017 19:34Меня в мобильных плеерах психологически бесит несколько другое. Они обычно не составляют заранее «случайный» плейлист, а подбирают «случайную» следующую композицию. В результате психологически обычно выходит так, что есть песни, которые ты слышал уже тысячу раз, а есть те, что проигрываются очень редко.

postgres
29.11.2017 20:09Вспомнил историю с плеером Apple. Из-за жалоб пользователей на такую «случайность», Apple пришлось исправить алгоритм. «Мы сделали его менее случайным, чтобы он казался более случайным» — сказал Стив Джобс.
3dcryx
29.11.2017 22:37"В первый 4 дня монетка выбрала тайскую. И вот в пятницу вы думаете «так, 4 дня монетка выбирала одно и тоже, ну, сегодня точно будет индийская еда!». И снова выпадает тайская. Дело в том, что у монетки нет памяти, она «не знает», что она выбирала вчера и совершенно не учитывает это при сегодняшнем своём «решении». Миллионный бросок имеет такие же шансы на выпадения орла или решки, как и первый — 50%."
Тут непонятно о чем речь. Монета конечно не имеет никакой "памяти", но она есть у того кто ее бросает. Вероятность того что при N бросках хотябы один раз выпадет орел 1-2^(-N), т.е она экспоненциально стремится к единице. Так что утверждение "я 100 раз кидал — выпадала Тайская, значит сегодня уж точно Индиская будет" в целом, скажем так, верно.

marapper
29.11.2017 22:51Но нет. Броски монет же независимы.
3dcryx
30.11.2017 01:11Независимыми они будут только если палкой этого бросальщика по голове каждое утро бить так, что он прошлого дня вспомнить не сможет
fireSparrow
30.11.2017 08:41Как знание бросающего передастся монетке? Он что, будет подсознательно подкидывать её именно так, чтобы выпал вариант, который давно не выпадал?
Нужно различать вероятность выбросить серию из n одинаковых исходов и вероятность конкретного исхода каждого следующего броска.
Вероятность выбросить серию одинаковых исходов, действительно 2^(-N). Но только если вы ещё не начали бросать. Когда вы находитесь посреди серии, и сколько-то предыдущих исходов у вас УЖЕ были одинаковые — то вероятность нужно считать только для оставшейся части серии.
Если вы уже выбросили (N-1) решек, то в N-нном броске вероятность выпадения решки всё-равно 1/2. Потому что это один отдельный бросок, на который никак не влияет то, что было раньше.
Собственно, речь о статье именно о том, что реальные вероятности иногда могут быть контр-интуитивными. И человек ожидает, что в случайном перемешивании если один раз проиграла песня «Арии», то следующая песня скорее всего будет какой-то другой группы. Однако для действительно случайного перемешивания это не так — в ней встречаются идущие подряд серии, поэтому настоящая случайность кажется недостаточно случайной.

Germanets
30.11.2017 14:54+1Под каждой статьёй про вероятность должен быть как минимум один комментарий, в котором совершают такую ошибку.
3dcryx
30.11.2017 09:25В чем тут собсвенно противоречие?
Вероятность выпадения решки останется 1/2, а вероятность того что для некого человека эта решка выпадет N-ый раз подряд будет 2^(-N).
Как например если при случайном перемешивании у вас N раз подряд будет играть одна и тажа песня.
Утверждение статьи тут вообще непричем, перемешивание случайное по песням а не по группам. Не вижу тут контр-инуитивности.
kogemrka
30.11.2017 09:41Вероятность выпадения решки останется 1/2, а вероятность того что для некого человека эта решка выпадет N-ый раз подряд будет 2^(-N).
Что такое «вероятность для некого человека»?
Я подбрасываю монетку. Вероятность выпадения орла равна 1/2.
Я подбросил монетку десять раз и решка выпала десять раз. Я подбрасываю монетку ещё раз. Вероятность выпадения орла равна 1/2.
DS28
30.11.2017 10:36Вероятность выпадения решки останется 1/2, а вероятность того что для некого человека эта решка выпадет N-ый раз подряд будет 2^(-N).
Вот так надо выделить, а про человека вообще можно опустить…
Вероятность выпадения серии 00000001 и серии 00000000 одинаковая, но до начала бросков они обе довольно невероятны, если сравнивать со всеми остальными возможными сериями))mayorovp
30.11.2017 10:55Тем не менее, если серия 0000000 уже выпала, то серии 00000001 и 00000000 становятся довольно вероятными.
3dcryx
30.11.2017 11:31Это абсалютно верно, и абсалютно бессмысленно. Вопрос не "Какая вероятность выпадения на N-ый бросок?" (она то естественно не меняется и равно 0.5, иначебы не было никаких 2^(-N)), а "Какова вероятность что при N бросках у меня не разу не выпадет решка?". Именно об этом пример с едой ("Какова вероятность что 5 раз подряд буду есть Тайскую еду?").
DS28
30.11.2017 11:44+1Вопрос не «Какая вероятность выпадения на N-ый бросок?»
Как раз в этом и вопрос — какова вероятность выпадания на 5-ый бросок:И вот в пятницу вы думаете «так, 4 дня монетка выбирала одно и тоже, ну, сегодня точно будет индийская еда»
И ответ:она то естественно не меняется и равно 0.5
и поэтому
утверждение «я 100 раз кидал — выпадала Тайская, значит сегодня уж точно Индиская будет» в целом, скажем так,
неверно…верно.
серия 0--00 и 0--01 — равновероятны, сколько нулей не подставляй вместо "--"

viktprog
30.11.2017 13:11Вероятность того, что за N бросков выпадет только решка, равна 2^(-N). Вероятность того, что за N бросков выпадет только решка, когда N-1 бросков уже сделаны и выпадала только решка, равна 2^(-1),
ProLimit
30.11.2017 13:44+1«Какова вероятность что 5 раз подряд буду есть Тайскую еду?»
Если вы уже 4-е дня едите ее, как в примере в статье, то вероятность 1/2. Но люди интуитивно ждут другой вероятности. Ваши комментарии говорят о том, что даже если все разжевать, люди все равно этого не понимают и не меняют своих ожиданий. Проще подогнать реальность под их ожидания, тем самым повысив степень удовлетворения. Об этом и статья.

andersong
30.11.2017 11:51Есть ещё один момент.
Вот вы слушаете трек, нажали кнопку «следующий трек» — заиграл другой случайный трек.
А если нажали кнопку «предыдущий трек», какой трек заиграет: который играл до этого или случайный, но «в другую сторону»?tangro
30.11.2017 12:10Который играл до этого, конечно. Для чего же ещё юзеру нажимать кнопку «предыдущий трек»?

Steed
30.11.2017 12:31Вы можете заметить, что у Britney Spears и Jaga Jazzist есть всего по одной песне, но случайное стартовое смещение помещает их в случайное место плейлиста.
Судя по всему, не в случайное место плейлиста, а в случайное место начала плейлиста.
В таком алгоритме получается, что Бритни и Джага будут всегда играться в начале.
Пусть пользователь за один раз прослушивает не больше N песен. Если у него M (скажем, 100) песен Арии и 1 песня Бритни, то в итоге он будет их слушать не в соотношении M:1, а в соотношении N-1:1. Т.е. любителю Арии будет постоянно попадаться Бритни. Упс.
Ситуация останется той же, если исполнителей больше — исполнители с одной песней будут играться гораздо чаще. Плюс появится проблема, что при 100 исполнителях послушать две песни одного исполнителя будет проблематично.
kogemrka
30.11.2017 15:18Судя по всему, не в случайное место плейлиста, а в случайное место начала плейлиста.
В таком алгоритме получается, что Бритни и Джага будут всегда играться в начале.
Что означает «в начале плейлиста»?
У них случайный отступ как-то хитро распределён, чтобы выдавать именно в начале? Я не вижу указаний на это в этом материале.
Пусть пользователь за один раз прослушивает не больше N песен. Если у него M (скажем, 100) песен Арии и 1 песня Бритни, то в итоге он будет их слушать не в соотношении M:1, а в соотношении N-1:1. Т.е. любителю Арии будет постоянно попадаться Бритни. Упс.
Вроде как результат работы описываемого алгоритма — некоторая перестановка набора всех песен.
Было M белых шариков и один розовый.
Стало M белых шариков и один розовый — но уже с заданным порядком, обладающим интересующими нас свойствами.
В какой момент розовых шариков стало больше одного и в какой момент у алгоритма «перемешивания» возникла зависимость от количества песен, которые пользователь планирует послушать?Steed
01.12.2017 11:33Цитата из статьи:
В начале мы добавляем случайный отступ, иначе первые песни каждого исполнителя попадут в точку 0 на линии.
Т.е. все первые песни всех исполнителей соберутся в начале плейлиста в пределах этого отступа.
Про зависимость от количества прослушиваемых песен подумайте — вы ведь за раз слушаете не всю коллекцию? Значит — только первые N песен с начала плейлиста. Ниже вкомментариях человек пишет, что у него N=2. А завтра уже будет другой плейлист и вы начнете слушать его опять с начала. А в начале у нас всегда по одной песне каждого исполнителя. Т.е. 1 Ария и 1 Бритни — или 1 Бритни и 1 Ария;)
Другими словами, к рамках каждой перестановки количество шариков не изменилось, но пользователь реально слышит исполнителей непропорционально из доле в коллекции.kogemrka
01.12.2017 12:08Т.е. все первые песни всех исполнителей соберутся в начале плейлиста в пределах этого отступа.
Я так понял, что случайный отступ свой для каждого отдельного исполнителя. Иначе бы оранжевая и розовая точка находились в одной точки прямой (положение каждой из них определяется исключительно этим случайным отступом же) — а они — в разных.Steed
01.12.2017 12:13Случайный отступ, конечно, для каждого исполнителя свой (иначе нафиг он нужен), но судя по картинке, диапазон его значений — небольшой отрезок из начала плейлиста, а не весь плейлист.
Впрочем, есть один вариант сделать это правильно — если для каждого исполнителя отступ выбирается случайно в диапазоне [0, длина_плейлиста/количество_песен_исполнителя].
Но как именно реализовано у авторов, только они могут ответить;)
kogemrka
01.12.2017 12:18Случайный отступ, конечно, для каждого исполнителя свой (иначе нафиг он нужен), но судя по картинке, диапазон его значений — небольшой диапазон из начала плейлиста, а не весь плейлист.
Не очень понятно, зачем так делать. Кажется — брать случайный отступ из равномерного распределения на весь отрезок — самое логичное и очевидное.
Мне, в общем-то, даже в голову не пришло, что отступ из какого-то маленького подмножества браться.
И проблема, которую вы описываете при таком подходе вроде как не возникает.
Lissov
01.12.2017 01:38Я правильно понимаю, что если в моем плейлисте 3 песни одного исполнителя и 2 другого, то я точно знаю на каком месте окажется какой исполнитель? При том, что за поездку я часто успеваю прослушать всего пару песен, будет некомфортно всегда начинать с одного исполнителя.
Я бы предложил другой алгоритм — я не утверждаю что он лучше, просто интересно Ваше мнение, возможно вы его тоже рассматривали. Можно менять вероятности для расчёта следующей песни. То есть понижать вероятность песен, похожих на предыдущую (того же исполнителя, того же стиля и т.д.), и выбирать таки случайно. В таком случае иногда таки будут попадаться 2 подряд песни одного исполнителя, реже чем случайно, но при этом не будет заметно что они не рядом никогда. Наверное, это будет чуть медленнее, если надо рассчитать и показать сразу весь перемешанный плейлист, но можно ведь просто выбирать одну следующую песню. Зато возможно будет чуть лучше работать с короткими плейлистами. Если при этом увеличивать веротность песен, которые давно не играли, то можно получить выглядящий достаточно случайно бесконечный плейлист. И для фанатов математики будет даже ненулевая вероятность получить одну песню 2 раза подряд.kogemrka
01.12.2017 08:58Я правильно понимаю, что если в моем плейлисте 3 песни одного исполнителя и 2 другого, то я точно знаю на каком месте окажется какой исполнитель? При том, что за поездку я часто успеваю прослушать всего пару песен, будет некомфортно всегда начинать с одного исполнителя.
Я из статьи понял, что при таком алгоритме вы получите чередование этих двух исполнителей.
При том, что за поездку я часто успеваю прослушать всего пару песен, будет некомфортно всегда начинать с одного исполнителя.
Я никогда не пользовался их сервисом, они всегда выдают одну и ту же «случайную» последовательность песен?
Если перестраивать «случайный» плейлист каждый раз, то вроде бы первый исполнитель должен быть разным. Или я чего-то не понял.
kogemrka
01.12.2017 09:19Я правильно понимаю, что если в моем плейлисте 3 песни одного исполнителя и 2 другого, то я точно знаю на каком месте окажется какой исполнитель?
Пусть у исполнителя A две песни, у исполнителя B — три песни.
Шаг 1: Расположили песни каждого из исполнителей по отрезку [0;1] равномерно. (хотя, судя по этой фразе располагают с какими-то случайными смещениями от равномерного)
Мы распределяем 4 песни на расстоянии от 20% до 30% друг от друга (так выглядит «случайнее»).
A_1 = 0
A_2 = 0.5
B_1 = 0
B_2 = 0.33
B_3 = 0.66
Шаг два — добавили к A и B случайные смещения:
В начале мы добавляем случайный отступ, иначе первые песни каждого исполнителя попадут в точку 0 на линии. Вы можете заметить, что у Britney Spears и Jaga Jazzist есть всего по одной песне, но случайное стартовое смещение помещает их в случайное место плейлиста.
Пусть случайные отступы: dA = 0, dB = 0.1 — получаем порядок A B B A B
Пусть случайные отступы: dA = 0.3, dB = 0 — получаем порядок B A B B A
будет некомфортно всегда начинать с одного исполнителя.
Почему с одного-то?
В этом конкретном примере алгоритм запрещает идти подряд двум песням исполнителя A или трём песням исполнителям B, все остальные порядки вполне себе могут возникнуть. В каких-то из них на первом месте A, в каких-то — на первом месте B.
A B B A B — начало с исполнителя A.
B A B B A — начало с исполнителя B.Lissov
01.12.2017 16:02Спасибо за развернутый ответ.
Вопрос спрятан тут:
Шаг два — добавили к A и B случайные смещения
Из какого интервала? Если из того же [0; 1], то с большой вероятностью получите ААВВВ или ВВВАА, а именно этого хотели избежать. Значит этот интервал должен быть сильно меньше. Но при «псевдоравномерном» распределении на первом шаге, первая песня В всегда будет ближе к началу, чем первая песня А, и если эта разница будет больше, чем смещение на шаге 2, то начинать всегда будет В.
Либо же на шаге 1 первую песню всегда ставить в «координату» 0, и распределять остальные. Тогда не совсем ясно почему для 4 песен интервал 25% (20%-30%), тогда логично 33%, хотя это и не принципиально.
Наверное, там вся магия в подборе правильных «случайных» расстояний (шаг 1) и смещений (шаг 2). И наверное эти значения должны зависеть от количества песен. Не зная их трудно представить, как оно сработает.
A B B A B — начало с исполнителя A.
B A B B A — начало с исполнителя B.
У меня сложилось впечатление, что алгоритм постарается не допускать ВВ, то есть сгенерирует единственно возможный вариант ВАВАВ. Надо будет поставить spotify и проверить.kogemrka
01.12.2017 16:58Из какого интервала? Если из того же [0; 1], то с большой вероятностью получите ААВВВ или ВВВАА, а именно этого хотели избежать. Значит этот интервал должен быть сильно меньше.
Либо же на шаге 1 первую песню всегда ставить в «координату» 0, и распределять остальные. Тогда не совсем ясно почему для 4 песен интервал 25% (20%-30%), тогда логично 33%, хотя это и не принципиально.
Представьте, что [0;1) — это координаты на кольце, где точка 1 тождественна 0.
SystemXFiles
Интересная тема. Давно уже задумывался над тем, как плееры выдают треки в «случайном порядке».
Не редко замечал разницу между различными плеерами, как они это делают. Не знаю как это объяснить, но чисто интуитивно понимаешь, что «случайность» разная.
Недавно купил плеер и обнаружил такой момент у него.
Обычно песни идут именно так, как описано в статье: повторов одной группы почти никогда не происходит, только крайне редко и то видимо из-за ошибки в метаданных внутри аудио-файла.
Если начать листать песни подряд в поисках той, что тебе сейчас по настроению, то после нее, на которой ты остановился, очень вероятно будет песня той же группы. Т.е. плеер «понимает», что меня данная группа «зацепила» и предлагает следующим трек этой же группы. Порой конечно раздражает это поведение, но чаще на пользу.
Averrin
Хорошо вам, а у меня в машине порядок «случайных» чисел зашит в железо. Я уже наизусть помню, какая будет следующая песня в «случайном» порядке=((