

Привет, Хабр! Меня зовут Дина, и я занимаюсь разработкой игрового хранилища данных для решения задач аналитики в Mail.Ru Group. Наша команда для разработки batch-процессов обработки данных использует Apache Airflow (далее Airflow), об этом yuryemeliyanov писал в недавней статье. Airflow — это opensource-библиотека для разработки ETL/ELT-процессов. Отдельные задачи объединяются в периодически выполняемые цепочки задач — даги (DAG — Directed Acyclic Graph).
Как правило, 80 % проекта на Airflow — это стандартные DAG’и. В моей статье речь пойдёт об оставшихся 20 %, которые требуют сложных ветвлений, коммуникации между задачами — словом, о DAG’ах, нуждающихся в нетривиальных алгоритмах.
Управление потоком
Условие перехода
Представьте, что перед нами стоит задача ежедневно забирать данные с нескольких шардов. Мы параллельно записываем их в стейджинговую область, а потом строим на них целевую таблицу в хранилище. Если в процессе работы по какой-то причине произошла ошибка — например, часть шардов оказалась недоступна, — DAG будет выглядеть так:
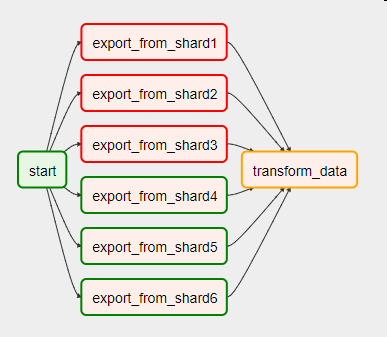
Для того чтобы перейти к выполнению следующей задачи, нужно обработать ошибки в предшествующих. За это отвечает один из параметров оператора — trigger_rule. Его значение по умолчанию — all_success — говорит о том, что задача запустится тогда и только тогда, когда успешно завершены все предыдущие.
Также trigger_rule может принимать следующие значения:
- all_failed — если все предыдущие задачи закончились неуспешно;
- all_done — если все предыдущие задачи завершились, неважно, успешно или нет;
- one_failed — если любая из предыдущих задач упала, завершения остальных не требуется;
- one_success — если любая из предыдущих задач закончилась успешно, завершения остальных не требуется.
Ветвление
Для реализации логики if-then-else можно использовать оператор ветвления BranchPythonOperator. Вызываемая функция должна реализовывать алгоритм выбора задачи, который запустится следующим. Можно ничего не возвращать, тогда все последующие задачи будут помечены как не нуждающиеся в исполнении.
В нашем примере выяснилось, что недоступность шардов связана с периодическим отключением игровых серверов, соответственно, при их отключении никаких данных за нужный нам период мы не теряем. Правда, и витрины нужно строить с учётом количества включённых серверов.
Вот как выглядит этот же DAG со связкой из двух задач с параметром trigger_rule, принимающим значения one_success (хотя бы одна из предыдущих задач успешна) и all_done (все предыдущие задачи завершились), и оператором ветвления select_next_task вместо единого PythonOperator’а.
# Запускается, когда все предыдущие задачи завершены
all_done = DummyOperator(task_id='all_done', trigger_rule='all_done', dag=dag)
# Запускается, как только любая из предыдущих задач успешно отработал
one_success = DummyOperator(task_id='one_success', trigger_rule='one_success', dag=dag)
# Возвращает название одной из трёх последующих задач
def select_next_task():
success_shard_count = get_success_shard_count()
if success_shard_count == 0:
return 'no_data_action'
elif success_shard_count == 6:
return 'all_shards_action'
else:
return 'several_shards_action'
select_next_task = BranchPythonOperator(task_id='select_next_task',
python_callable=select_next_task,
dag=dag)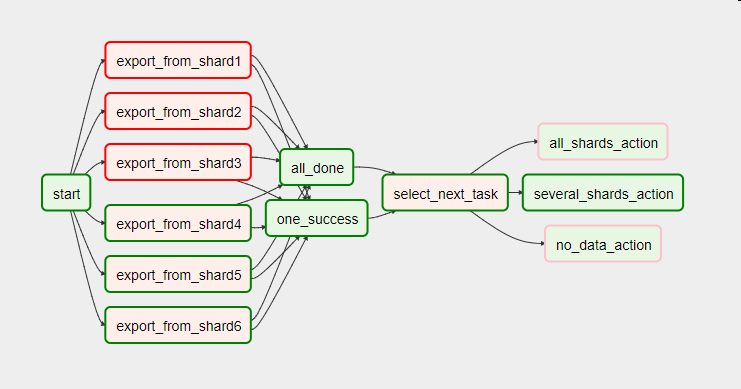
Документация по параметру оператора trigger_rule
Документация по оператору BranchPythonOperator
Макросы Airflow
Операторы Airflow также поддерживают рендеринг передаваемых параметров с помощью Jinja. Это мощный шаблонизатор, подробно о нём можно почитать в документации, я же расскажу только о тех его аспектах, которые мы применяем в работе с Airflow.
Шаблонизатор обрабатывает:
- строковые параметры оператора, указанные в кортеже template_field;
- файлы, переданные в параметрах оператора, с расширением, указанным в template_ext;
- любые строки, обработанные функцией task.render_template сущности task, переданной через контекст. Пример функции PythonOperator’а с переданным контекстом (
provide_context=True):
def index_finder(conn_id, task, **kwargs):
sql = "SELECT MAX(idtransaction) FROM {{ params.billing }}"
max_id_sql = task.render_template("", sql, kwargs)
...Вот как мы применяем Jinja в Airflow:
- Конечно же, это работа с датами. {{ ds }}, {{ yesterday_ds }}, {{ tomorrow_ds }} — после препроцессинга эти шаблоны заменяются датой запуска, днём до него и следующим днём в формате YYYY-MM-DD. То же самое, но только цифры, без дефисов: {{ ds_nodash }}, {{ yesterday_ds_nodash }}, {{ tomorrow_ds_nodash }}
- Использование встроенных функций. Например, {{ macros.ds_add(ds, -5) }} — это способ отнять или добавить несколько дней; {{ macros.ds_format(ds, “%Y-%m-%d”, “%Y”) }} — форматирование даты.
- Передача параметров. Они передаются в виде словаря в аргументе params, а получаются так: {{ params.name_of_our_param }}
- Использование пользовательских функций, точно так же переданных в параметрах. {{ params.some_func(ds) }}
- Использование встроенных библиотек Python:
{{ (macros.dateutil.relativedelta.relativedelta(day=1, months=-params.retention_shift)).strftime("%Y-%m-%d") }} - Использование конструкции if-else:
{{ dag_run.conf[“message”] if dag_run else “” }} - Организация циклов:
{% for idx in range(params.days_to_load,-1,-1) %}
{{ macros.ds_add(ds, -idx) }}
{% endfor %}
Приведу несколько примеров рендеринга параметров в интерфейсе Airflow. В первом мы удаляем записи старше количества дней, передаваемого параметром cut_days. Так выглядит sql c использованием шаблонов jinja в Airflow:
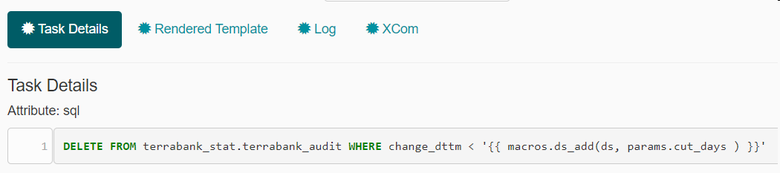
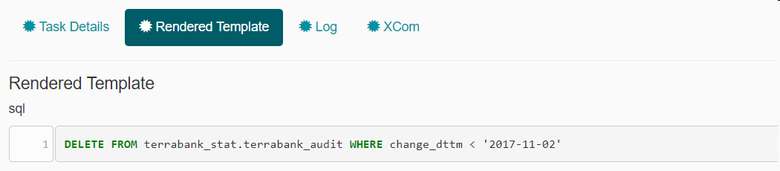
В обработанном sql вместо выражения уже подставляется конкретная дата:
Второй пример посложнее. В нём используется преобразование даты в unixtime для упрощения фильтрации данных на источнике. Конструкция "{:.0f}" используется, чтобы избавиться от вывода знаков после запятой:
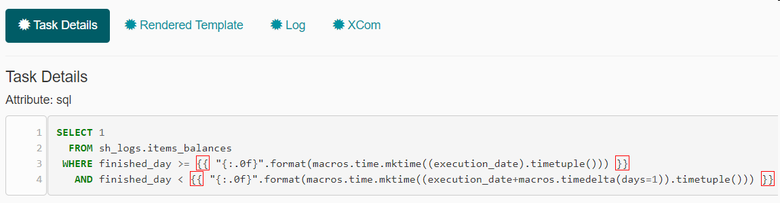
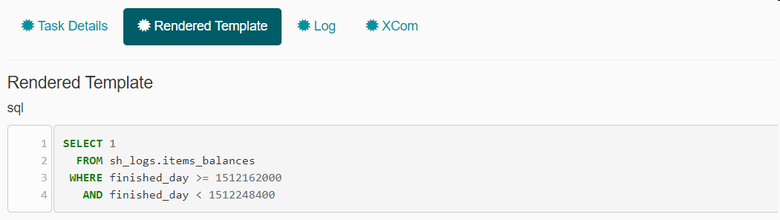
Jinja заменяет выражения между двойными фигурными скобками на unixtime, соответствующий дате исполнения DAG’а и следующей за ней дате:
Ну и в последнем примере мы используем функцию truncshift, переданную в виде параметра:
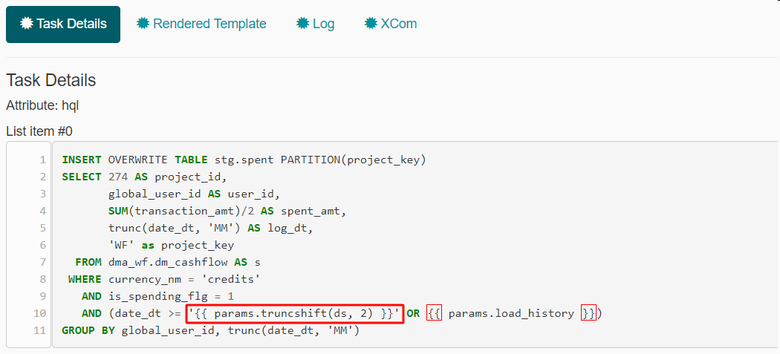
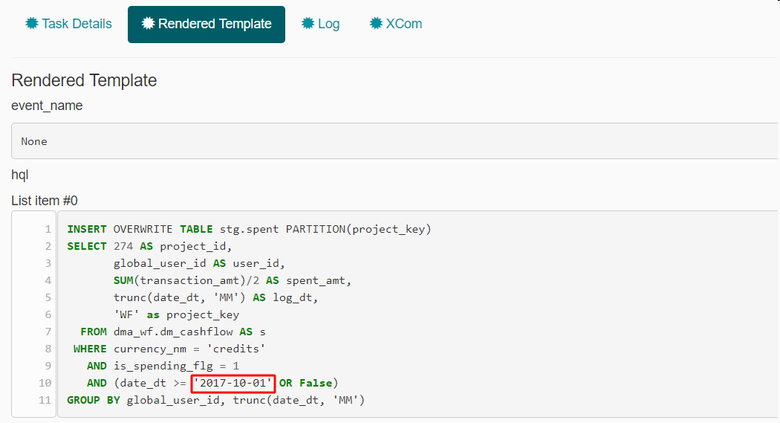
Вместо этого выражения шаблонизатор подставляет результат работы функции:
Документация по шаблонизатору jinja
Коммуникация между задачами
В одном из наших источников интересная система хранения логов. Каждые пять дней источник создаёт новую таблицу такого вида: squads_02122017. В её названии присутствует дата, поэтому возник вопрос, как именно её высчитывать. Какое-то время мы использовали таблицы с названиями из всех пяти дней. Четыре запроса падали, но trigger_rule=’one_success’ спасал нас (как раз тот случай, когда выполнение всех пяти задач необязательно).
Спустя какое-то время мы стали использовать вместо trigger_rule встроенную в Airflow технологию для обмена сообщениями между задачами в одном DAG’е — XCom (сокращение от cross-communication). XCom’ы определяются парой ключ-значение и названием задачи, из которой его отправили.

XCom создаётся в PythonOperator’е на основании возвращаемого им значения. Можно создать XCom вручную с помощью функции xcom_push. После выполнения задачи значение сохраняется в контексте, и любая последующая задача может принять XCom функцией xcom_pull в другом PythonOperator’е или из шаблона jinja внутри любой предобработанной строки.
Вот как выглядит получение названия таблицы сейчас:
def get_table_from_mysql(**kwargs):
"""
Выбирает существующую из пяти таблиц и пушит значение
"""
hook = MySqlHook(conn_name)
cursor = hook.get_conn().cursor()
cursor.execute(kwargs['templates_dict']['sql'])
table_name = cursor.fetchall()
# Посылаем XCom с названием ‘table_name’
kwargs['ti'].xcom_push(key='table_name', value=table_name[0][1])
# Второй вариант отправления XCom’а:
# return table_name[0][1]
# Можно получить по названию задачи-отправителя без ключа
# Запрос, вынимающий из метаданных PostgreSQL название нужной таблицы
select_table_from_mysql_sql = '''
SELECT table_name
FROM information_schema.TABLES
WHERE table_schema = 'jungle_logs'
AND table_name IN
('squads_{{ macros.ds_format(ds, "%Y-%m-%d", "%d%m%Y") }}',
'squads_{{ macros.ds_format( macros.ds_add(ds, -1), "%Y-%m-%d", "%d%m%Y") }}',
'squads_{{ macros.ds_format( macros.ds_add(ds, -2), "%Y-%m-%d", "%d%m%Y") }}',
'squads_{{ macros.ds_format( macros.ds_add(ds, -3), "%Y-%m-%d", "%d%m%Y") }}',
'squads_{{ macros.ds_format( macros.ds_add(ds, -4), "%Y-%m-%d", "%d%m%Y") }}')
'''
select_table_from_mysql = PythonOperator(
task_id='select_table_from_mysql',
python_callable=get_table_from_mysql,
provide_context=True,
templates_dict={'sql': select_table_from_mysql_sql},
dag=dag
)
# Получаем XCom из задачи 'select_table_from_mysql' по ключу 'table_name'
sensor_jh_squad_sql = '''
SELECT 1
FROM jungle_logs.{{ task_instance.xcom_pull(task_ids='select_table_from_mysql',
key='table_name') }}
LIMIT 1
'''Ещё один пример использования технологии XCom — рассылка email-уведомлений с текстом, отправленным из PythonOperator’а:
kwargs['ti'].xcom_push(key='mail_body', value=mail_body)А вот получение текста письма внутри оператора EmailOperator:
email_notification_lost_keys = EmailOperator(
task_id='email_notification_lost_keys',
to=alert_mails,
subject='[airflow] Lost keys',
html_content='''{{ task_instance.xcom_pull(task_ids='find_lost_keys',
key='mail_body') }}''',
dag=dag
)Документация по технологии XCom
Заключение
Я рассказала о способах ветвления, коммуникации между задачами и шаблонах подстановки. С помощью встроенных механизмов Airflow можно решать самые разные задачи, не отходя от общей концепции реализации DAG’ов. На этом интересные нюансы Airflow не заканчиваются. У нас с коллегами есть идеи для следующих статей на эту тему. Если вас заинтересовал этот инструмент, пишите, о чём именно вам хотелось бы прочитать в следующий раз.
Комментарии (17)

ssheremeta
12.12.2017 10:34Подскажите, как вы решаете задачу версионирования дагов/тасков? И как сбрасываете кеш дагов?
diiina Автор
12.12.2017 10:48У нас код дагов лежат в гите, мы их разрабатываем локально и после внесения изменений обновляем на сервере.
Что касается сбрасывания кеша, я не поняла, что имеется ввиду. Если обновление дага по свежему коду, то пользуемся кнопкой «Обновить» в веб-интерфейсе.Protan
13.12.2017 10:52+1Я так понимаю, что речь идёт об устаревших данных. Например когда ДАГ переименовывается, по факту файла уже нет, а в вебсервесе он ещё висит и в базе есть. Мы в таком случае идём в базу Postgres airflow и там запросами вручную чистим устаревшие ДАГи.
seidzi
14.12.2017 09:52где то читал что в новой версии должны для этого сделать кнопку в web интерфейсе, но пока что да другого решения кроме как удалять руками нет, можно так же сделать свою тулзу по чистке старых дагов

wildraid
12.12.2017 16:11А можно ли вообще не делать сложной логики внутри Airflow, а вместо этого делать параллельную загрузку и все проверки внутри Python скрипта?
DAG при этом будет выглядеть так:
START -> export_from_all_shards_and_action -> FINISH
Внутри скрипта запускаем 3-6-10-400-1000 потоков и загружаем данные. Сразу после загрузки проверяем результат и, если были фатальные ошибки, то отправляем на рестарт. Иначе делаем какое-то полезное действие.
Со временем образуется 5-7 стандартных загрузчиков из принципиально разных источников. И можно эту логику в отдельные классы вынести, и просто запускать с разными параметрами.
Логика ETL склонна усложнятся со временем. Есть риск, что через годик во всех хитросплетениях и костыликах уже сложно будет разобраться.diiina Автор
12.12.2017 16:38Это вполне себе вариант, но тогда Airflow вырождается в планировщик задач на Питоне.
Основное преимущество использования всех встроенных возможностей Airflow на мой взгляд — это простая локализация ошибки. Можно с одного взгляда понять, что пропал доступ к источнику или задача в соседнем таске никак не может просчитаться и после починки перезапустить только эту часть.
Что же касается костыликов и хитросплетений, во-первых, у нас есть регламент, согласно которому мы называем задачи и используем те или иные сенсоры и операторы, а во-вторых, тяжёлую повторяющуюся логику мы инкапсулируем в самописные операторы.
Nashev
13.12.2017 21:45Было б интересно про этот регламент и прочие know how почитать, позволяющие не утонуть.
diiina Автор
14.12.2017 17:06На понимание темы на уровне рекомендаций в разных ситуациях я пока не претендую.
А если рассматривать конкретно наш регламент, это достаточно скучное чтиво вроде чтения ГОСТ'ов. Два главных момента — удобство и последовательное их соблюдения — кажутся очевидными. Можно при случае обсудить.
Nashev
13.12.2017 21:36Вот бы жаргонизмы типа «шарды», «стеджинговый сервер» и т.п. были б вкратце раскрыты через более широко известные словечки при первом упоминании…
Protan
15.12.2017 10:00У нас недавно возникла небольшая проблема, может подскажите как из неё лучше выйти?
Есть DAG, где находится 120 задач, 60 из них на первом уровне, т.е. зависимостей никаких нет. Выполняются, в основном, довольно быстро (от 5 секунд до 120 секунд). Когда мы делаем backfill на этот DAG на 30 дней, то получается 30*120 = 3600 задач, из которых сразу в очередь встаёт 1800. При этом, если попадаются лёгкие задачи, airflow worker быстро его отрабатывает и потом долго перебирает все задачи из пула. В итоге вместо 15 worker, которые положены по конфигу, успевает отработать только 1-2. Это можно решить дополнительной оберткой bash скриптом, где будут задаваться начальные и конечные даты, но, кажется, должен быть вариант получше.
Под airflow у нас отдельная машина (24 CPU, 64Gb памяти), работает с помощью LocalExecutor. Celery пока не прикуритили. Конфиги airflow.cfg у нас следующие:
[core]
parallelism = 16
dag_concurrency = 15
max_active_runs_per_dag = 16
[scheduler]
max_threads = 10
LMnet
Мы используем у себя AirFlow для запуска периодических задач. И с ним постоянно какие-то проблемы. Регулярно видим "ядерный гриб". Сабдаги просто не работают. Старые issue закрываются, новые открываются. Давно уже хотим съехать с AirFlow на какой-то другой сервис. Но вот на какой — непонятно. Может кто-то посоветует?
diiina Автор
Согласна с seidzi, airflow очень гибкий. Хотя и без недочётов.
У нас гриб появляется в трёх случаях:
— когда в даге что-то не в порядке и тогда мы используем консольную команду list_dags, чтобы выяснить, что именно;
— при маркировке mark success за большое количество дней;
— при большом или неправильном запросе при работе с источниками напрямую, через интерфейс Ad Hoc Query.
Про сабдаги я сказать ничего не могу, мы ими ещё не пользовались.
Что касается альтернативы, из предложенных open source продуктов слышала хорошие отзывы о Luigi. Он попроще, чем airflow, но для некоторых задач подходит лучше.
LMnet
Смотрели и на Luigi и на Oozie, но они выглядят почти такими же. Не хочется менять шило на мыло.
Protan
Можете ещё Azkaban попробовать. Мы сначала его юзали, но потом из-за того, что не хватало функционала перешли на Airflow.
yuryemeliyanov
Есть ещё не очень сильно популярный Pinball github.com/pinterest/pinball
Вот интересное, для общего понимания, сравнение Airflow, Luigi и Pinball — bytepawn.com/luigi-airflow-pinball.html#luigi-airflow-pinball
seidzi
а мы используем Oozie и хотим перейти с него на Airflow, сейчас тестирую его возможности и по моим наблюдениям он очень гибкий и нужно уметь его «готовить»
Protan
Сабдаги отлично работают. Мы их используем для:
У них есть свои минусы в том, что появляется дополнительная сущность сабдага, которая одновременно является задачей в главном ДАГе и также является ДАГом для внутренних тасков. Т.е. при чистке и повторном прогоне например, надо не забывать и то и другое вычищать из базы.