
Мы продолжаем публиковать материалы Школы мобильной разработки 2017 года. На очереди — большая лекция Android-разработчика Дмитрия Никитина из команды Яндекс.Почты. Дмитрий рассказывает, как подойти к созданию проекта с нуля, не потеряться среди множества библиотек и на что обратить внимание при выборе того или иного решения.
— Все вы как минимум пару месяцев программируете под Android. Возможно, кто-то программирует пару лет и уже от корки до корки прочитал developer.android.com. А возможно, нет. Но вы все наверняка знаете, как можно сделать многие вещи как минимум одним из способов. Но не секрет, что этих способов может быть много, у каждой команды они могут быть свои, и часто тот или иной способ выбран исключительно по историческим причинам.
Сегодня я хочу сделать небольшой обзор того, какие вообще есть альтернативы и средства разработки и на чем стоит акцентировать внимание при выборе той или иной библиотеки.
О каких средствах мы будем сегодня говорить? В первую очередь о тех, которые помогут реализовать непосредственные функции приложения: именно этого от нас обычно требует проджект-менеджер.
Во-вторых, то, что поможет нам контролировать качество кода, делать его более гибким и расширяемым. И далее рассмотрим вещи, которые также связаны с разработкой, но не имеют непосредственно отношения к предыдущим двум пунктам.

Насколько эффективно это средство с точки зрения скорости работы, а также с точки зрения потребляемой оперативной и дисковой памяти.
Как мы будем выбирать, что лучше, а что хуже? Во-первых, будем смотреть на удобство использования, насколько просто нам будет решить ту или иную задачу при помощи данного средства.
Как правило, известные библиотеки уже покрыты тестами, и баги чаще появляются уже при ее интеграции, поэтому чем лаконичнее и проще наш клиентский код, тем меньше вероятность допустить ошибку.
С другой стороны, нам с нашей подчас не самой прямой бизнес-логикой может понадобиться столько что-то специфичное, и здесь будет огромным плюсом, если выбранное нами средство достаточно гибкое, что позволит это сделать без костылей.
Следующий критерий относится к исключительно к внешним библиотекам — это лицензия. Так как часто мы пишем именно коммерческий код, то лицензия должна позволять не только использовать программное обеспечение, но и не должна заставлять нас раскрывать свои исходники.
Самая популярная лицензия — это Apache 2.0 и MIT. Как правило, они, по большому счету, не накладывают на нас никаких ограничений. А другие лицензии стоит использовать с осторожностью.
Кроме того, желательно, чтобы все, что нужно для подключения, было уже собрано и распространялось если не вместе с Android SDK, то лежало где-нибудь на JCenter либо Maven central.
Если нам будет что-то непонятно, то мы бы могли обратиться к документации либо задать вопрос к тем, кто этот продукт поддерживает.
И последний пункт по порядку, но не по степени значимости — это то, сколько за собой данное средство привносит количество методов.
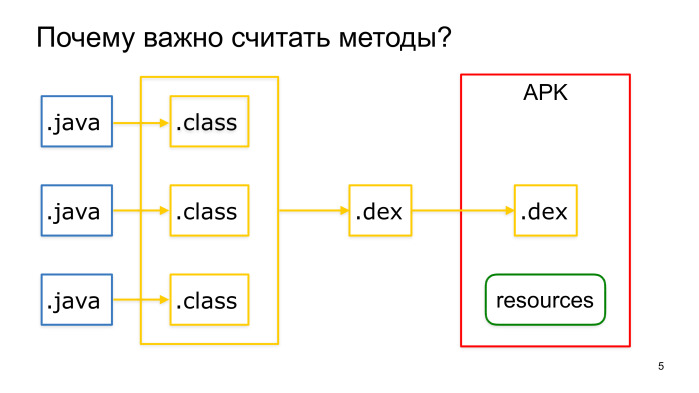
Почему это важно? Если наше приложение поддерживает API меньше Lollypop (а это большинство приложений), на этих устройствах наш код выполняется на виртуальной машине Dalvik, и при сборке APK Java-файлы компилируются в байт-код, а затем упаковываются в Dalvik executable файлы. Каждый такой файл может содержать не более 65 тыс. методов, и если мы достигнем этого предела, то мы встретим при сборке такую ошибку.

Как при этом быть? По-хорошему, нужно следить за тем, какие классы сколько занимают, и стараться избегать лишнего. То есть всегда нужно оценивать, какой положительный вклад нам дает та или иная зависимость в соотношении с количеством методов, которые она привносит.
К примеру, если мы используем Guava исключительно для того, чтобы безопасно закрывать курсоры, то стоит написать свой утилитный метод и отказаться от такой большой зависимости.
Если что-то используется по большей части в тестах, то мы можем добавить эту зависимость в test compile, чтобы не включать ее непосредственно в проект.
Также нужно обратить внимание, насколько дорого нам обходится различный синтаксический сахар, например, лямбда-выражение или метод-референс. Подробнее на эту тему можете посмотреть классный доклад Джейка Уортона «Exploring Hidden Java Costs».
Кроме лямбд важно смотреть и на другой генерируемый код. Например, Butter Knife начиная с одной из версий стал генерировать на 40% меньше методов.

Как можно отследить, какие классы сколько занимают в проекте? Для этого подойдет Dexcount-плагин. Он генерирует такую красивую диаграмму, по которой мы можем смотреть, кто сколько методов привнес.
Перед тем, как добавить зависимость, мы можем оценить, насколько дорого она нам обойдется, что сайте methodscount.com. Также можем там увидеть, сколько методов привносят его транзитивные зависимости.
Если ничего не помогло, мы все же можем использовать несколько dex-файлов, но это приносит дополнительные проблемы. Помимо того, что такие приложения, как правило, дольше стартуют и потребляют больше памяти, в некоторых случаях они могут еще и падать. При сборке с MultiDex происходит анализ того, какие классы понадобятся для успешного старта приложения для того, чтобы положить их в первичный dex-файл.
Если зависимости сложные, например, происходит вызов из нативного кода, то такие классы могут попасть в другие dex-файлы, и мы получим при старте NoClassDefFoundError. Чтобы этого избежать, мы будем вынуждены указывать такие классы в отдельном конфиге.
Кроме того, этот анализ нам существенно замедляет сборку, и начиная с Lollypop версии на смену Dalvik пришел Android Runtime, который уже самостоятельно поддерживает MultiDex, и сборка с ним SDK 21 происходит значительно быстрее.

Поэтому в качестве хака мы можем воспользоваться тем, что, несмотря на то, что реальная минимальная версия SDK у нас значительно меньше, для локальной сборки мы указываем 21 версию.
Это значение мы берем из параметра командной строки в студии, и это даст нам возможность локально собираться быстрее. При этом не сломаются лентовые проверки уровня API внутри студии.
Подведем итог. Что нам нужно делать с количеством методов? Способ здорового человека — это считать и уменьшать их естественным путем. Также можно использовать proguard, чтобы убрать то, что мы подключили, но не используем. В релиз-сборе мы и так включаем proguard, поэтому может быть нормальной практикой для нас, если нам потребуется включить MultiDex только в дебаге. Но если ничего не вышло, то остается лишь включить MultiDex, слегка скрасив себе жизнь быстрой локальной сборкой.
Какие задачи нам, как правило, нужно сделать в приложении? Часто мы получаем данные с сервера, определенным образом их обрабатываем, показываем на экране, и если, к примеру, нам понадобится работа в офлайн, то мы должны их каким-то определенным образом их сохранить. Например, в базу данных, shared preference либо файл.
Давайте рассмотрим все эти стадии на примере приложения, которое показывает данные пользователя с GitHub.
Сами данные пользователя лежат на сервере, и нам нужно их оттуда забрать. Как мы можем это сделать? Например, есть HttpUrlConnection.

Мы идем на StackOverflow, берем пример get-запроса, подставляем свой URL. Открываем Connection. Получаем InputStream. Читаем нужные нам данные здесь в виде строки. И не забываем закрыть соединение. С этим запросом все просто. Сложности начинаются, если нам нужно сделать что-то менее тривиальное, например, загрузить на сервер файл с ReadMe. Для этого потребуется написать свою обертку.

И уже такого размера, хотя, казалось бы, задача не такая редкая.
Еще нам потребуется написать на это тесты, чего не хочется делать для, по сути, чужого кода.
Есть немало библиотек, которые работают поверх HttpUrlConnection, в которых упрощена в данном случае отправка файлов, также добавлены другие возможности, например, асинхронный вызов и т. д.
Например, есть библиотека HttpClient от Кевина Савински. Но есть и альтернатива, которая из коробки лишена всех этих недостатков — это OkHttp.

Вот как выглядит та же отправка файла при помощи OkHttp. Мы просто указываем URL. Создаем RequestBody. И выполняем запрос.
Начиная с Kitkat HttpUrlConnection на сетевом уровне сам использует OkHttp. Таким образом, если мы выберем этот вариант, то мы обезопасим себя от того, что на разных версиях Android библиотека будет вести себя по-разному.
А представим, если мы захотим добавить для части запросов useragent, или поменять поведение в случае переадресации. Мы также довольно быстро сможем это сделать при помощи интерсепторов OkHttp.

Переопределим метод intercept. Получим исходный request. Можем каким-то образом его изменить и передать дальше по цепочке. А дальше просто добавляем этот Interceptor клиенту. При этом мы можем вызвать не addInterceptor, а addNetworkInterceptor, если захотим повторно перехватывать запросы в случае редиректа.
Помимо этого OkHttp может выполнять запросы асинхронно, работать с вебсокетами и делать многие другие хорошие вещи.

Но есть один недостаток. Все же, это сторонняя библиотека, и она тянет за собой 2,5 тыс. методов. Есть ли какое-то встроенное решение, которое нас от этого убережет?
На заре Android был ApacheHttpClient, он был более стабильным на ранних версиях, но команда Google решила, что его API слишком большое для дальнейшего развития, и объявила его deprecated.

Мы по-прежнему можем использовать его в своих проектах, явно указав useLibrary “org.apache.http.legacy”, но тогда он уже будет упакован в APK, и мы нашей цели не достигнем.
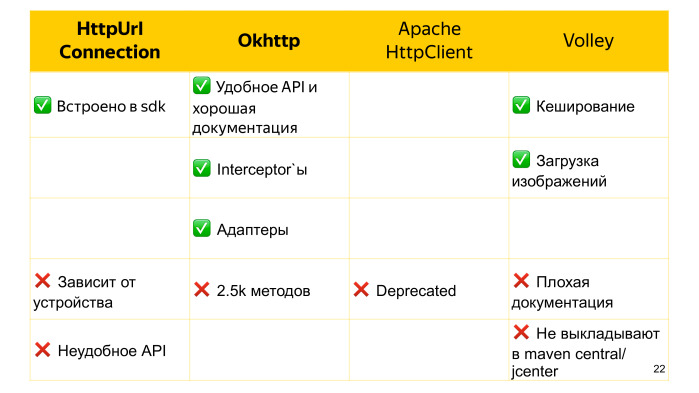
Кроме рассмотренных вариантов есть еще поддерживаемая Google библиотека Voley. Она более высокоуровневая, чем предыдущие альтернативы. Так же, как OkHttp может выполнять запросы асинхронно. У нее хорошее внутреннее кэширование, и она даже умеет загружать изображения, только для этого наш imageview должен наследовать network imageview, что довольно сильное ограничение.
Voley, к сожалению, не выкладывается на JCenter и Maven Central, импортируется в проект исходным кодом, что, если нам не повезет, то этот исходный код будет также изменен в том же самом коммите, что очень плохо.
Еще Voley не может похвастаться хорошей документацией, в отличие того же OkHttp.

Таким образом, что нам лучше взять? Если у нас есть жесткое ограничение на количество методов, или работа с сетью не такая сложная, чтобы требовались какие-либо нетривиальные вещи, то можно взять HttpUrlConnection или какую-либо из его оберток. В противном случае лучшим вариантом выглядит OkHttp. (Вопросы и ответы см. в видео — прим. ред.)
Мы закончили на том, что скачали данные. Сейчас это JSON-строка. И как теперь мы можем получить удобное с точки зрения Java представление?

Если данных немного, то мы вполне можем взять нужное нам значение, используя встроенный JSONObject. Мы последовательно обходим всю структуру, пока не встретим интересующие нас поля. Читаем значение, и идем дальше.
Если данных много, то эту рутинную работу становится поддерживать довольно сложно, и есть смысл использовать определенную библиотеку.
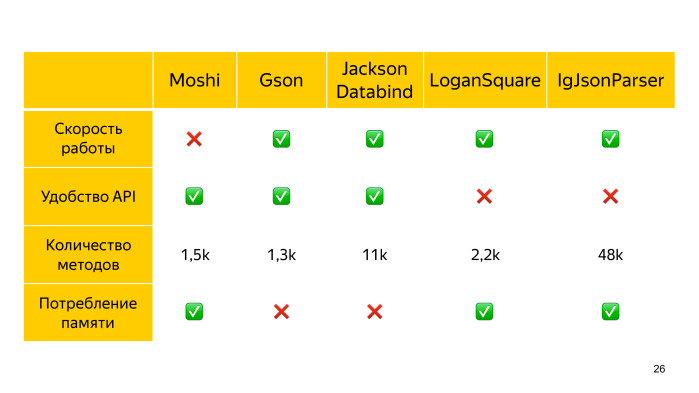
Например, есть Moshi от Square, который изначально создавался для Android, и за счет этого он более бережлив к потреблению памяти. Но он довольно медленный.
Также есть Gson от Google, он быстрее, но потребляет больше оперативной памяти, хотя и по количеству методов несколько привлекательнее.
И еще есть Jackson, который самый быстрый из reflection-аналогов. У него поставляется отдельно стриминговая его часть и Databing для непосредственного мапинга. Но при этом он самый толстый.
Кроме того, есть LoganSquare (ссылка на GitHub), который генерирует адапторы для парсинга при компиляции. Она использует Jackson streaming API, и за счет compile time генерации существенно обгоняет конкурентов по скорости.

Сравнение можно посмотреть на бенчмарках его создателей. Видно, что LoganSquare из представленных вариантов самый быстрый.

Но compile time генерация накладывает определенные ограничения на структуру. Сами entity не могут наследовать что-либо. Также есть проблема с дженериками.
Есть еще один парсер без reflection от Instagram — IgJsonParcer. Он нас обязывает при этом аннотировать все поля непосредственно, которые мы должны обработать. Эта библиотека еще не имеет стабильной версии, и есть проблемы с количеством методов, так как она зависит и от Guava, и от Apache Commons.
Таким образом, из представленных решений самый быстрый — это LoganSquare, и если нам исключительно важна скорость, то можем использовать его. В противном случае выбираем из предыдущих вариантов, исходя из того, что нам требуется больше: скорость, потребление памяти либо количество методов.

Мы выбрали средство. Не забываем его протестировать, причем парсинг как нельзя кстати подходит для test-driven development. Мы копируем JSON из документации, пишем на это тест, а потом пишем сам парсинг, пока тест не станет зеленым.
Часто в API могут добавить дополнительные поля.
Чтобы наш парсинг при этом не упал, можно добавить в тестах неизвестные поля заранее. Тем самым мы гарантированно будем готовы к такому изменению.

Если мы, наоборот, хотим отправить данные на сервер или сохранить их в виде строки, то нам потребуется обратный процесс — сериализация, и проверить ее правильность нам также помогут тесты.
К примеру, здесь использована библиотека JsonUnit. Она использована для того, чтобы мы не сравнивали голые строки, потому что такое сравнение неустойчиво к порядку, к отступам и т. д. А так, мы сравниваем непосредственно значения, полученные нами.
Таким образом, мы выбрали, как пойдем в сеть, выбрали, чем парсить, как мы теперь можем это совместить при помощи библиотеки Retrofit (ссылка на GitHub).

Так у нас будет единая точка доступа, где мы задаем базовый URL. В случае чего мы можем довольно быстро его тут сменить, к примеру, для QA окружения. Можем выбрать конвертер между Moshi, Gson, Jackson либо Protobuf. И способ, как мы будем осуществлять вызовы. Мы можем это делать синхронно.

Или асинхронно.

Либо с использованием Rx. Для этого нам всего нужно указать, что наш метод API возвращает single completable либо observable. И выберем соответствующий CallFactory.

Мы остановились на том, что десериализовали данные пользователя. Как мы теперь представим их в Java?

Мы можем сделать это вот так. Но чем это плохо может быть? Предположим, у нас в будущем поле логина будет вычисляться непосредственно при обращении, либо мы будем логгировать все эти обращения.
Поэтому меняем их видимость на privateв, и добавляем геттеры и сеттеры.
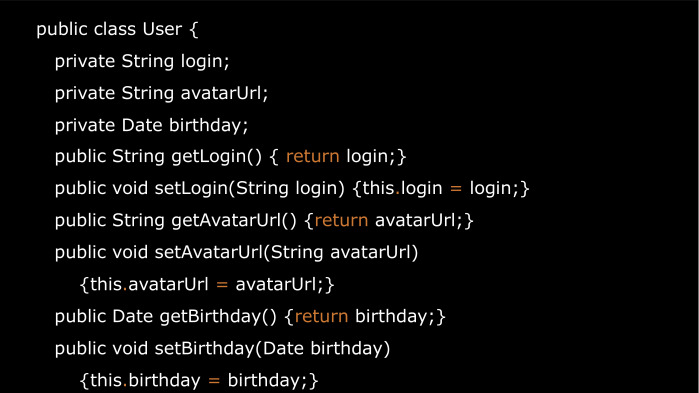

Если мы захотим добавить его в HashMap, нам понадобится equals и hashCode.
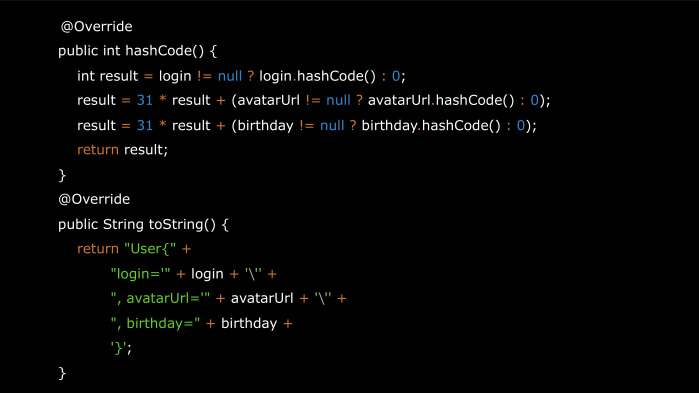

Добавим сюда еще красивый to String. И если мы решим передать его в intent в другое activity, или сохранить в bundle при перевороте экрана, то нам потребуется, чтобы этот объект был Parcelable.
И когда мы узнаем, что в классе добавляется новое поле, нам нужно будет повторить эти круги, и ничего при этом не забыть. К счастью, есть библиотеки, которые способны решить эту проблему.

Например, AutoValue (ссылка на GitHub). Мы пишем аннотацию AutoValue и абстрактные методы доступа к полям. Непосредственно сами поля при сборке сгенерирует библиотека. Также она сгенерирует все эти методы, которые мы перечисляли до этого.
Киллер-фичей AutoValue является то, что достаточно легко использовать расширения. Например, есть Gson и Jackson расширения, которые позволяют генерировать compile time адаптеры, и за счет этого они могут догнать по скорости тот же самый LoganSquare. Таким образом, мы убиваем сразу двух зайцев: решаем проблемы и парсинга, и внутреннего представления моделей.
Есть еще расширение AutoValue Parcel. Если мы его подключим, то мы можем просто писать implements Parcelable, и методы поддержки парселизации будут сгенерированы за нас. При этом, если одно из полей класса не сериализуемо, мы получим ошибку при компиляции.

Есть другое расширение AutoValue — это Auto-Parcel, которое также делает парселизацию, но оно, в отличие от AutoValue Parcel проверяет, что объект сериализуется исключительно в Runtime, и у него также менее популярная лицензия EPL 1.0.
Есть альтернатива AutoValue — это Immutables. У него также есть адаптеры для Moshi и Gson, но нет расширения для Parcelable.
И еще есть Lombok, который, в отличие остальных, не генерирует наследника, а подменяет исходный класс.
Для поддержки всей этой магии нам понадобится IDE плагин и терпение, потому что все это может довольно сильно глючить.
Таким образом, из рассмотренных вариантов наиболее выгодно смотрится AutoValue и расширение для него Auto-Parcel. (Вопросы и ответы см. в видео — прим. ред.)
Представим, что нам нужно согласно возраста пользователя показывать ему различные виды баннеров. Вроде бы все просто. Мы берем текущую дату, вычисляем дату рождения и получаем возраст.

Но если мы при этом используем и джавовые date и календарь стандартные, то нам нужно ожидать сюрпризов. К примеру, что мы получим, если вызовем getYear? Правильный ответ — 117, потому что это не просто год.
Потому что это не просто год.

А как видно из Java.doc, это год за вычетом 1900. Отчасти мы сами виноваты, что не прочитали Java.doc заранее, да и метод этот deprecated, но вообще количество deprecated методов у этого API слишком велико.
Или, например, не самый очевидный момент, что самый известный метод у календаря GetInstance, на самом деле, каждый раз создает новый календарь.

Одна из самых популярных библиотек Java — это JodaTime (ссылка на GitHub). С ее использованием мы можем так легко решить нашу задачу с пользователем. Также мы можем, к примеру, посчитать число дней до Нового года.
Кроме того, JodaTime включает в себя актуальную версию файла Tzdata. Этот файл содержит историю того, как со временем менялись таймзоны различных регионов, и как получить местное время, исходя из UTC.
Этот файл инкапсулирует в себе решения для целой горы может быть. Подробнее о них вы можете узнать из ролика Тома Скотта. Файл Tzdata есть и в самой системе, но если мы зашьем его в APK, то мы обезопасим себя от проблемы, если вендор не выпустит обновление для своих старых устройств. Вместо этого, например, вендоры могут делать красивую трехмерную модель выбора часового пояса для своих новых клиентов, как это часто делает HTC.
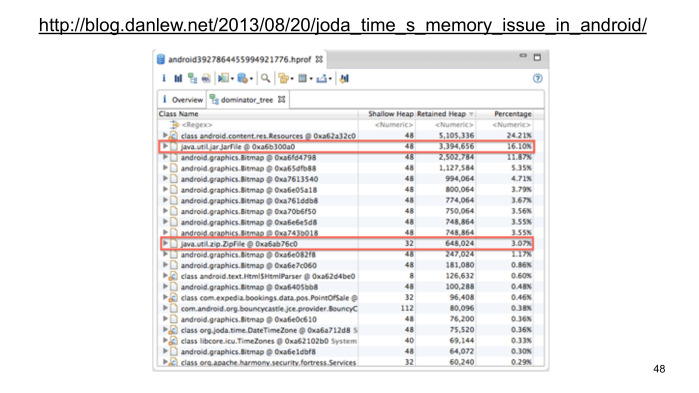
Но включение файла Tzdata в APK не проходит даром. Помимо того, что увеличивается его размер, мы еще начинаем расходовать в больших объемах оперативную память — до 5 МБ. Ден Лью заметил это еще четыре года назад. Дело было в том, что библиотека предназначалась исключительно для Java, и мы, используя ClassLoader.getResourceAsStream при обращении к этому файлу, как раз кэшируем такое огромное количество данных.
Он заменил этот вызов на использование AssetManager, и выпустил библиотеку, которая называется Joda Time Android.
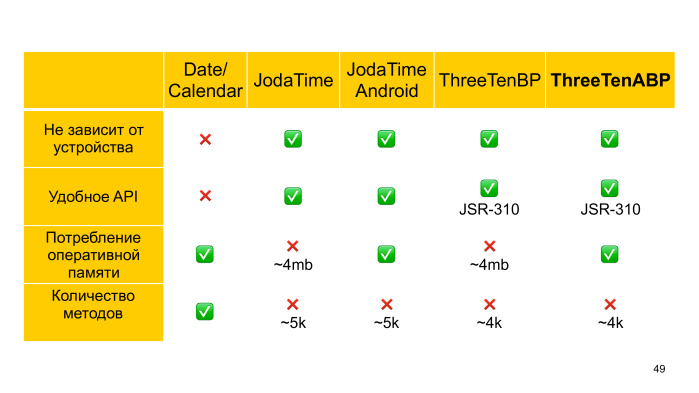
Команда JDK сама, что с классами работы со временем в Java нужно что-то делать, они все переписали, и с разработчиком Joda Time создали новый стандарт JSR 310. Сейчас этого в API в Android нет, но мы можем использовать back-port ThreeTenBP, а если быть более точным, ThreeTenABP, в котором Джейк «Наше все» Уортон сделал аналогичные махинации при работе с файлом Tzdata.

Подведем итог. Что нам взять для работы со временем? Если у нас есть жесткое ограничение на количество методов и размер APK, то мы вынуждены использовать стандартный API. Если же мы можем позволить подключить ThreeTenABP то лучше взять его, так как по сравнению с тем же самым Joda Time когда-нибудь в Android наверняка появится официальная поддержка нового стандарта, и тогда мы сможем легко отказаться от зависимости, всего лишь обновив импорт.
Представим, что нам нужно загрузить аватарку пользователя.

В UI-потоке пойти в сеть мы себе позволить не можем, поэтому берем AsyncTask. Чем это решение плохо? Нам нужно самостоятельно заботиться о кэшировании как в память, так и на диск, отменять неактуальные запросы и многое-многое другое.

Можем взять Picasso. С ним мы можем сделать все это очень просто, плюс добавить placeholders, состояние ошибки, сжать изображение и многое другое.
Но представим, что у нас сейчас нет непосредственного адреса картинки, есть только некий идентификатор, с которым мы должны изначально сходить на сервер, тогда мы получим этот URL, и уже по следующим запросам мы загрузим само изображение. С Picasso это будет сделать проблематично.

Но есть Glide, который внешне от Picasso неотличим, но он более гибкий, что позволит нам сделать эти ухищрения.

Мы можем создать Fetcher, который сначала синхронно скачает URL, а затем само изображение.

Кроме того, Glide поддерживает загрузку по нашим собственным моделям. Для этого мы создадим StreamModelLoader, который принимает нашего пользователя в качестве аргумента.

И дальше нужно зарегистрировать Loader в Module, Module в Manifest, яйцо в утке, утку в зайце. Ну, на самом деле, все не так сложно. Нужно просто не забыть добавить наш класс в список исключений proguard.

Итак, мы можем передавать объект нашего пользователя непосредственно в Glide, дальше он все сделает за нас.
Важно заметить, что кроме контекста мы можем передавать еще и activity либо фрагмент, и тогда Glide подпишется на наш жизненный цикл, и будет вовремя отменять запросы, когда нам это уже не нужно.
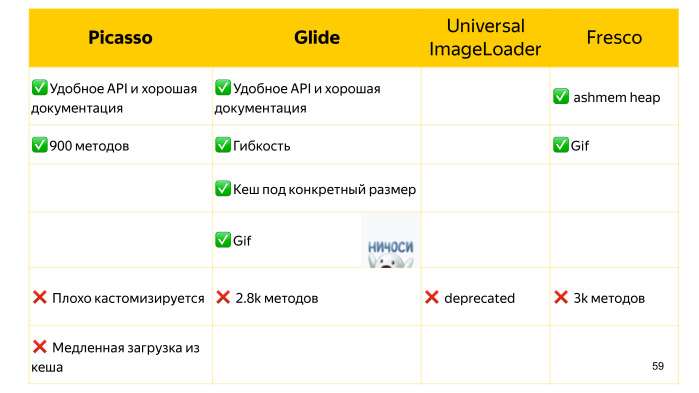
Кроме того, Glide кэширует изображения, исходя из того, в какой ImageView оно загружено. Это несколько замедляет изначальную загрузку по сравнению с тем же Picasso, но последующее использование кэша происходит гораздо быстрее, и мы потребляем меньше памяти.
Также Glide умеет загружать гифки.
Кроме этих двух библиотек еще раньше был Universal ImageLoader, но сейчас он, к сожалению, deprecated.
И есть Fresco, который использует ashmem, в отличие обычной кучи, за счет этого у нас в приложении может быть все лучше в плане используемой памяти.
А также она может загружать gif. Методов у него чуть больше, чем у Glide.

Итак, что лучше для загрузки изображений? Если мы не ждем ничего сложного от загрузки изображений как таковой, то либо у нас жесткий дефицит методов, то мы должны выбрать, наверное, Picasso. Если нужно что-то нетривиальное либо поддержка gif, то это будет Glide. В любом случае с Picasso на Glide достаточно просто мигрировать, так как у них схожи API. (Вопросы и ответы см. в видео — прим. ред.)
Из чего строится архитектура? Как правило, это dependency injection, MVP, MVVM и т. д.
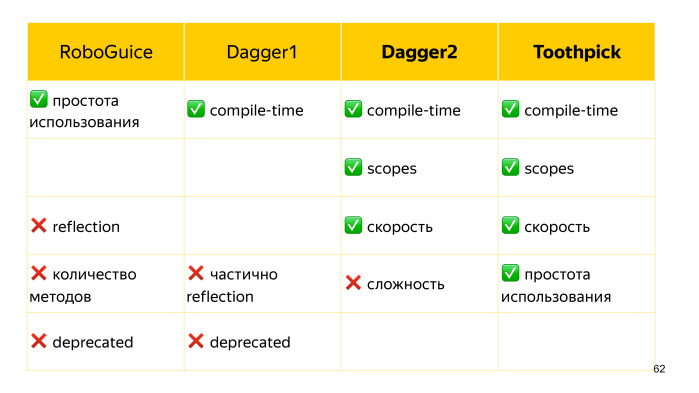
Что касается dependency injection, изначально был reflection-based решение RoboGuice, которое было довольно простым в использовании, но, пожалуй, на этом его плюсы заканчивались. Для инджектов оно использовало рефлексию. Если для серверной Java это, возможно, имеет право на жизнь, так как процесс довольно долго не выгружается из памяти, и reflection обращение успевает закэшироваться, то у Android жизненный цикл сильно короче, и до такого кэша часто дело может не дойти, и поэтому мы получаем тормоза.
RoboGuice уже как год deprecated. Ему на смену в какое-то время приходил Dagger1, который во многом решал все свои проблемы кодогенерацией, но определенное количество reflection вызовов, тем не менее, происходило. На сегодняшний день он также устарел и заменен Dagger2. У него все происходит в процессе компиляции, за счет чего он эффективный в плане скорости.
Еще он привнес новое понятие скоупов, когда мы можем удобно компоновать зависимости, у которых общий жизненный цикл. Например, заводим какой-то аккаунт scope, который содержит все нужные нам данные для текущего аккаунта. И буквально год назад появился Toothpick, который, судя по названию, видит, кто его главный конкурент. Он также reflection free, и тоже имеет scope. У него нет такого понятия, как компонент, за счет этого его использование несколько проще.
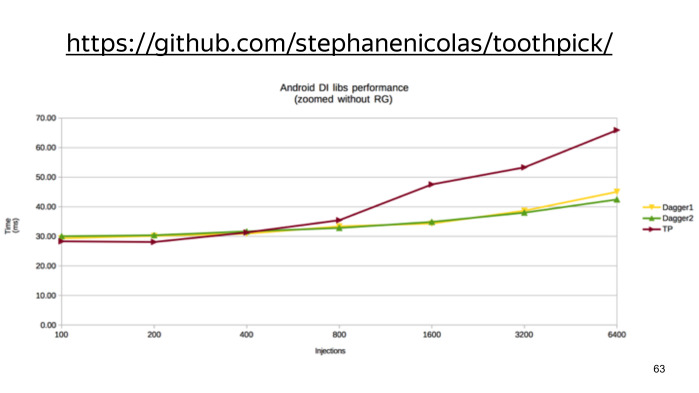
По скорости на малом числе инжектов он несколько быстрее Dagger, и проигрывать начинает лишь при большом количестве. (Ссылка на GitHub.)
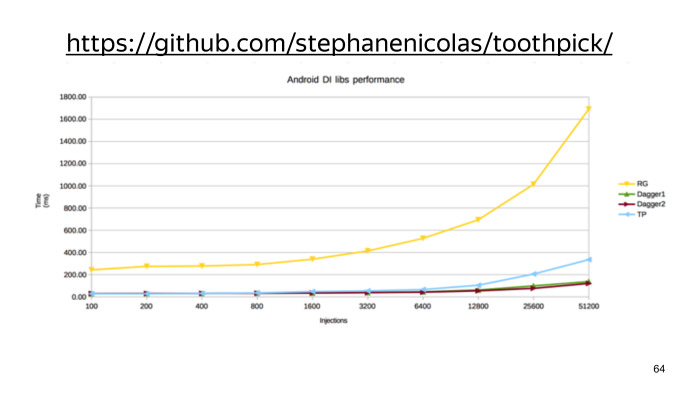
На этом графике видно, насколько все же RoboGuice плох.

Таким образом, есть всего два конкурента, которые друг с другом практически неотличимы. Они практически одинаково быстры, привносят порядка всего пары сотен методов, что порою несущественно, у обоих библиотек достаточно удобный API, и у TootрPick даже чуть более лаконичное. Единственный минус при их использовании — это то, что они ломают инкрементальную сборку.
По MVP и MVVM у вас уже была лекция, и я лишь добавлю, что, делая выбор фреймворка, отдавайте себе отчет, что, как правило, это именно фреймворк, а не библиотека. Он накладывает на вас достаточно серьезные ограничения, а польза от его использования может быть не всегда ощутимой. Поэтому порою лучшим решением здесь могут быть и пара самописных классов, которые мы в будущем легко сможем подстроить под какие-либо новые задачи.

Аналогично коротко о работе с базами данных. Фреймворков и библиотек также огромное множество со своими плюсами и минусами, но стоит с осторожностью выбирать те решения, которые выступают именно как фреймворки, делая за вас все. Такие, как GreenDAO, ORMLite или NoSQL решение Realm.
Как правило, при нестандартных ситуациях у нас не будет гибкости — решить это без костылей.
Есть более легковесные решения, которые только оказывают нам помощь, избавляя от некрасивого шаблонного кода. Это они делают в большинстве случаев, а в редких случаях, когда мы можем сделать что-то нетривиальное, мы можем сделать это руками.
Например, SQLDelight, он генерирует нам маппинг и Java-классы по написанному SQL-коду. Дальше мы можем делать все руками, либо подключив другие обвязки, которые позволят нам общаться с базой, к примеру, с использованием Rx, например, StorIO или SQLBrite.
Также стоит обратить внимание на Room, так как кажется, он решает многие текущие проблемы, и, возможно, в будущем станет стандартом.
Как проверить качество того, что мы написали? В первую очередь это тесты, но по тестам у вас уже была лекция, и во-вторых, тесты нужно писать. А есть средства, которые даются нам практически даром — это различные статистические анализаторы.

Первый из них — это checkstyle (ссылка на SourceForge). Он не находит непосредственно багов, но следит за тем, чтобы у всех разработчиков был общий стиль написания кода. Это касается случайно пропущенных аннотаций Override и излишних модификаций, к примеру, у интерфейса, размера строк, методов и т. д. Полный список можно посмотреть по ссылке.

Чтобы подключить checkstyle, нужно добавить его в зависимость. Нужно также указать конфигурационный файл, и те файлы, которые мы будем анализировать.

В конфиге мы можем задать правила игнорирования некоторых проблем, которые, к примеру, свойственны для всего проекта, либо изменить параметр некоторых проверок, например, установить свою длину строк.
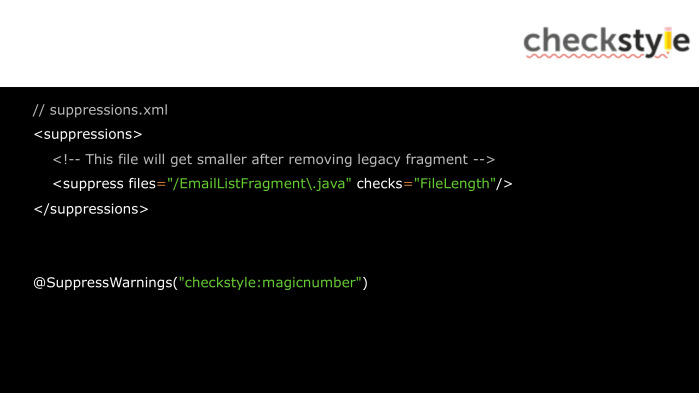
Так выглядит файл с фильтром для общих проблем проекта. А вот так мы можем игнорировать конкретную проблему непосредственно в Java-коде.

Следующий анализатор кода Lint, он находит Android-специфичные проблемы, такие, как отсутствие перевода для одной из локалий или отсутствие изображения для одного из разрешений экрана, а также многое другое.

Также он хорош во взаимодействии с аннотациями из саппорта. Мы можем определять такие проблемы, как nullability, некорректное использование интов, которое ссылается, на самом деле, на различные ресурсы, и вызов из неверного потока, а также многое другое.

Таким образом он подключается. Стоит обратить внимание на baseline. Lint дает нам возможность быстрого входа в уже существующий проект. Запустив его с такой строкой, мы временно будем игнорировать существующие проблемы, чтобы фокусировать внимание на новых проблемах.
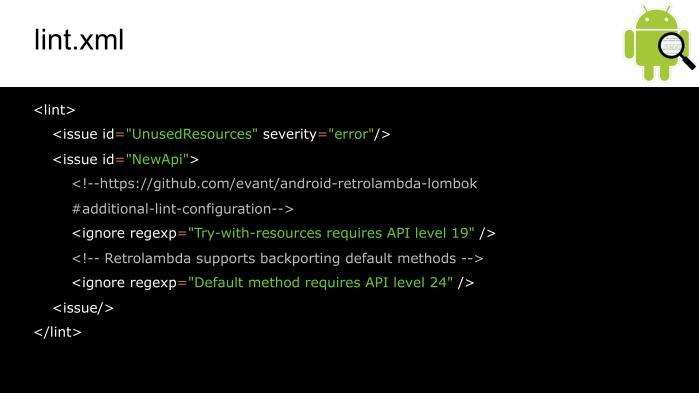
Так выглядит конфиг Lint. Здесь мы можем менять приоритет проблем либо игнорировать их.

А так мы можем игнорировать проблемы в коде и XML.

Еще один статический анализатор — PMD (ссылка на SourceForge). Он больше нацелен на поиск проблем непосредственно в Java. Полный список проблем можете также посмотреть по ссылке.

Настраивается он таким образом.
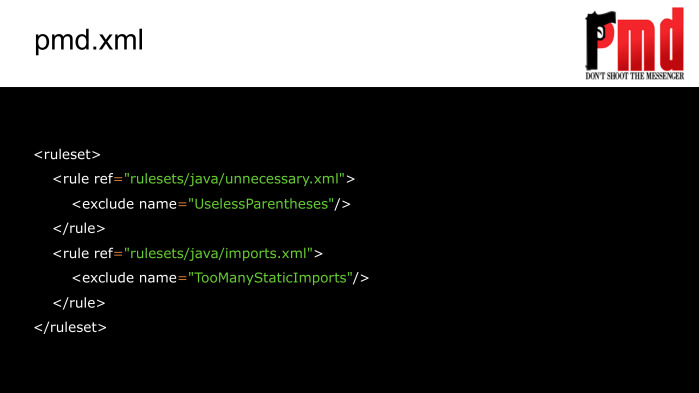
А так выглядит его конфиг.

Есть еще одно средство, похожее на PMD, которое анализирует не сами Java-файлы, а уже байт-код. Это FindBugs (ссылка на SourceForge). Одну из проблем, которую он решает, можем посмотреть на примере.
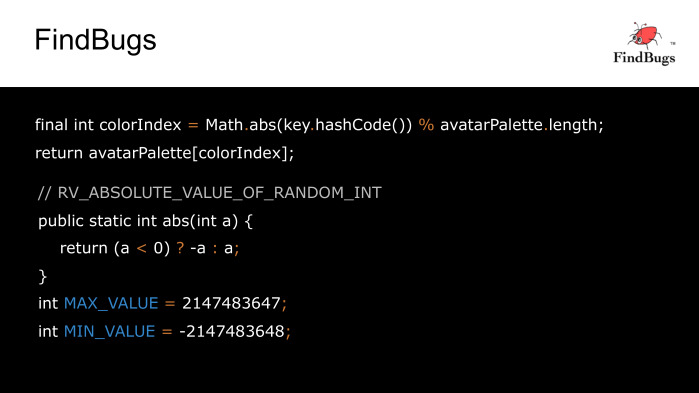
Допустим, у нашего пользователя нет аватарки, и мы хотим поставить ему определенного цвета фон. Чтобы цвета из палитры были разные для разных пользователей, мы берем модуль от hashCode, его идентификатора, и после деления с остатком определяем нужный цвет. Что тут может пойти не так?
FindBugs говорит, что если hashCode у нас будет равен минимальному int, то из-за переполнения функция abs нам вернет то же самое отрицательное значение, и мы получим ошибку IndexOutOfBounds.
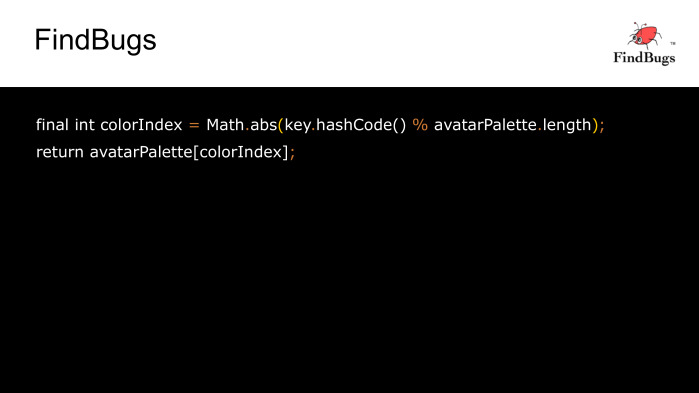
Исправим эту ошибку, исключив такую ситуацию, и поблагодарим FindBugs за подсказку.

Это пример настройки FindBugs. Следует отметить, что он может за один раз генерировать либо XML, либо HTML-отчет, поэтому, чтобы посмотреть отчет в другом виде, нам нужно пересобирать заново.

А так мы можем игнорировать какие-либо проблемы для всего проекта, а в конкретном месте мы можем добавить аннотацию из Findbugs:annotations.
К сожалению, FindBugs с недавних пор не развивается, ему на смену пришел SpotBugs, который, правда, пока имеет проблемы при интеграции с Android, но тем не менее.

До этого мы рассматривали анализаторы, которые делают перманентный анализ, но есть ПО, которое позволяет, используя внутри все те же самые средства, собрать все данные в единый dashboard. В этом dashboard мы можем посмотреть также историю изменения качества кода.
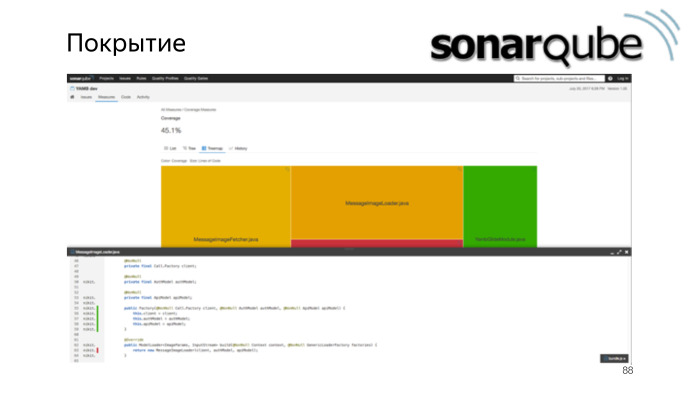
Можем легко следить за покрытием.
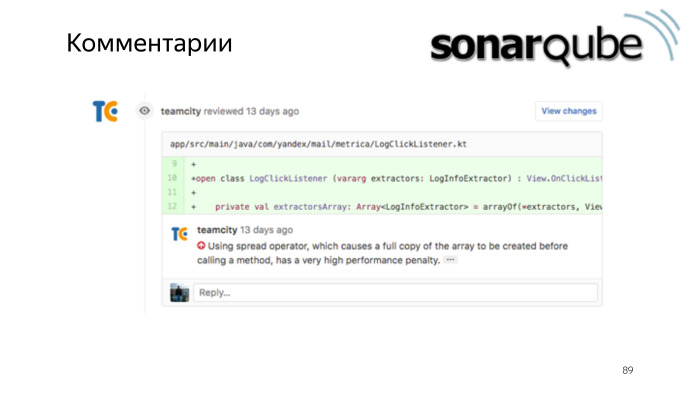
Или даже настроить, чтобы новые проблемы репортились непосредственно комментариями в пул-реквест.

Подведем итог. Какие из представленных средств взять на вооружение? Правильный ответ — все. Хоть правила и могут частично перекрываться, все равно есть уникальные, и если мы будем использовать все из них, то вероятность пропущенной ошибки будет существенно меньше. (Ссылка на GitHub.)
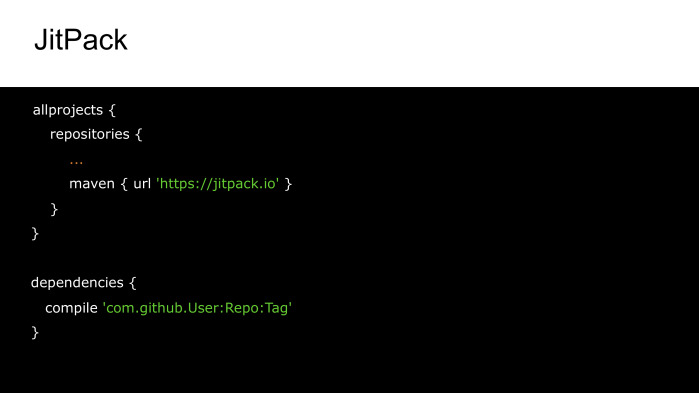
Мы рассмотрели достаточном много библиотек, но как быть, если мы исправили в одной из них ошибку, а возможности дождаться релиза этого исправления нет? Нам может помочь JitPack, который позволяет добавить в качестве зависимости не опубликованный вариант, а сборку из какого-либо fork, конкретной ветки или тега.

В заключение — пару слов про Kotlin. Google наконец признал его официальным языком, и это язык, который действительно помогает избавиться от многих проблем. Уже на стадии компиляции мы практически защищены от NullPointerException и ClassCastException. Есть встроенная поддержка data-классов, которая, к сожалению, восполняет не весь функционал того же AutoValue, то есть у него нет расширения, и будут проблемы с сериализацией. Например — с тем, чтобы получить из объекта Parcelable.
Еще есть pattern matching, делегаты и многое другое. Судя по тем замерам, которые мы проводили, подключение Kotlin практически никак не влияет на скорость сборки, и количество методов увеличивается исключительно в релизе, потому что proguard довольно хорошо выпиливает лишние методы.
Есть и другие проблемы, такие как final everywhere, когда каждый класс по умолчанию final, и мы не можем от него наследоваться. Это вставляет грабли в Mockito — другими словами, мы не можем замокать наш объект для тестов. Но это — хоть и в экспериментальном виде — решено в Mockito 2.
Еще есть проблема с any. Например, если мы используем такой matcher, он по умолчанию возвращает null в Mockito. И если Kotlin-класс примет параметр на null, у нас сломается компиляция. Но эта проблема решается через Mockito Kotlin. Кроме того, есть Spek — фреймворк для написания тестов в виде специфики от JetBrains. Только, к сожалению, он пока не работает с Roboelectric. Постепенно заполняется и пробел с точки зрения статистических анализаторов — развивается утилита Detekt и плагин к ней для интеграции с SonarQube. На этом у меня все. Спасибо за внимание.
Контакты автора: почта, Telegram
— Все вы как минимум пару месяцев программируете под Android. Возможно, кто-то программирует пару лет и уже от корки до корки прочитал developer.android.com. А возможно, нет. Но вы все наверняка знаете, как можно сделать многие вещи как минимум одним из способов. Но не секрет, что этих способов может быть много, у каждой команды они могут быть свои, и часто тот или иной способ выбран исключительно по историческим причинам.
Сегодня я хочу сделать небольшой обзор того, какие вообще есть альтернативы и средства разработки и на чем стоит акцентировать внимание при выборе той или иной библиотеки.
О каких средствах мы будем сегодня говорить? В первую очередь о тех, которые помогут реализовать непосредственные функции приложения: именно этого от нас обычно требует проджект-менеджер.
Во-вторых, то, что поможет нам контролировать качество кода, делать его более гибким и расширяемым. И далее рассмотрим вещи, которые также связаны с разработкой, но не имеют непосредственно отношения к предыдущим двум пунктам.
Насколько эффективно это средство с точки зрения скорости работы, а также с точки зрения потребляемой оперативной и дисковой памяти.
Как мы будем выбирать, что лучше, а что хуже? Во-первых, будем смотреть на удобство использования, насколько просто нам будет решить ту или иную задачу при помощи данного средства.
Как правило, известные библиотеки уже покрыты тестами, и баги чаще появляются уже при ее интеграции, поэтому чем лаконичнее и проще наш клиентский код, тем меньше вероятность допустить ошибку.
С другой стороны, нам с нашей подчас не самой прямой бизнес-логикой может понадобиться столько что-то специфичное, и здесь будет огромным плюсом, если выбранное нами средство достаточно гибкое, что позволит это сделать без костылей.
Следующий критерий относится к исключительно к внешним библиотекам — это лицензия. Так как часто мы пишем именно коммерческий код, то лицензия должна позволять не только использовать программное обеспечение, но и не должна заставлять нас раскрывать свои исходники.
Самая популярная лицензия — это Apache 2.0 и MIT. Как правило, они, по большому счету, не накладывают на нас никаких ограничений. А другие лицензии стоит использовать с осторожностью.
Кроме того, желательно, чтобы все, что нужно для подключения, было уже собрано и распространялось если не вместе с Android SDK, то лежало где-нибудь на JCenter либо Maven central.
Если нам будет что-то непонятно, то мы бы могли обратиться к документации либо задать вопрос к тем, кто этот продукт поддерживает.
И последний пункт по порядку, но не по степени значимости — это то, сколько за собой данное средство привносит количество методов.
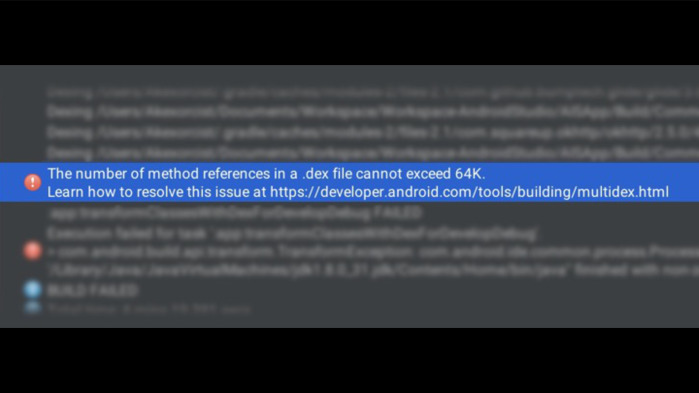
Почему это важно? Если наше приложение поддерживает API меньше Lollypop (а это большинство приложений), на этих устройствах наш код выполняется на виртуальной машине Dalvik, и при сборке APK Java-файлы компилируются в байт-код, а затем упаковываются в Dalvik executable файлы. Каждый такой файл может содержать не более 65 тыс. методов, и если мы достигнем этого предела, то мы встретим при сборке такую ошибку.
Как при этом быть? По-хорошему, нужно следить за тем, какие классы сколько занимают, и стараться избегать лишнего. То есть всегда нужно оценивать, какой положительный вклад нам дает та или иная зависимость в соотношении с количеством методов, которые она привносит.
К примеру, если мы используем Guava исключительно для того, чтобы безопасно закрывать курсоры, то стоит написать свой утилитный метод и отказаться от такой большой зависимости.
Если что-то используется по большей части в тестах, то мы можем добавить эту зависимость в test compile, чтобы не включать ее непосредственно в проект.
Также нужно обратить внимание, насколько дорого нам обходится различный синтаксический сахар, например, лямбда-выражение или метод-референс. Подробнее на эту тему можете посмотреть классный доклад Джейка Уортона «Exploring Hidden Java Costs».
Кроме лямбд важно смотреть и на другой генерируемый код. Например, Butter Knife начиная с одной из версий стал генерировать на 40% меньше методов.
Как можно отследить, какие классы сколько занимают в проекте? Для этого подойдет Dexcount-плагин. Он генерирует такую красивую диаграмму, по которой мы можем смотреть, кто сколько методов привнес.
Перед тем, как добавить зависимость, мы можем оценить, насколько дорого она нам обойдется, что сайте methodscount.com. Также можем там увидеть, сколько методов привносят его транзитивные зависимости.
Если ничего не помогло, мы все же можем использовать несколько dex-файлов, но это приносит дополнительные проблемы. Помимо того, что такие приложения, как правило, дольше стартуют и потребляют больше памяти, в некоторых случаях они могут еще и падать. При сборке с MultiDex происходит анализ того, какие классы понадобятся для успешного старта приложения для того, чтобы положить их в первичный dex-файл.
Если зависимости сложные, например, происходит вызов из нативного кода, то такие классы могут попасть в другие dex-файлы, и мы получим при старте NoClassDefFoundError. Чтобы этого избежать, мы будем вынуждены указывать такие классы в отдельном конфиге.
Кроме того, этот анализ нам существенно замедляет сборку, и начиная с Lollypop версии на смену Dalvik пришел Android Runtime, который уже самостоятельно поддерживает MultiDex, и сборка с ним SDK 21 происходит значительно быстрее.
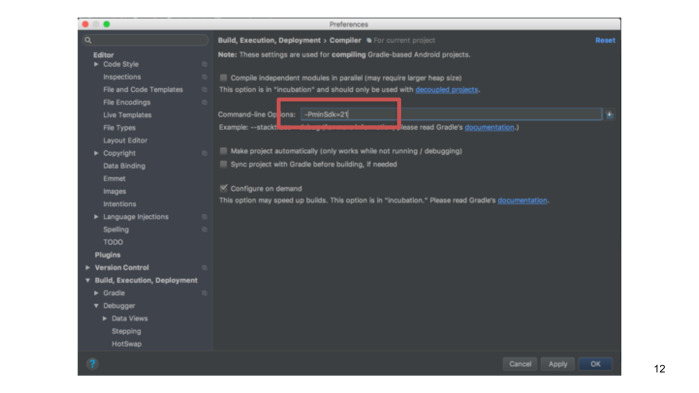
Поэтому в качестве хака мы можем воспользоваться тем, что, несмотря на то, что реальная минимальная версия SDK у нас значительно меньше, для локальной сборки мы указываем 21 версию.
Это значение мы берем из параметра командной строки в студии, и это даст нам возможность локально собираться быстрее. При этом не сломаются лентовые проверки уровня API внутри студии.
Подведем итог. Что нам нужно делать с количеством методов? Способ здорового человека — это считать и уменьшать их естественным путем. Также можно использовать proguard, чтобы убрать то, что мы подключили, но не используем. В релиз-сборе мы и так включаем proguard, поэтому может быть нормальной практикой для нас, если нам потребуется включить MultiDex только в дебаге. Но если ничего не вышло, то остается лишь включить MultiDex, слегка скрасив себе жизнь быстрой локальной сборкой.
Какие задачи нам, как правило, нужно сделать в приложении? Часто мы получаем данные с сервера, определенным образом их обрабатываем, показываем на экране, и если, к примеру, нам понадобится работа в офлайн, то мы должны их каким-то определенным образом их сохранить. Например, в базу данных, shared preference либо файл.
Давайте рассмотрим все эти стадии на примере приложения, которое показывает данные пользователя с GitHub.
Сами данные пользователя лежат на сервере, и нам нужно их оттуда забрать. Как мы можем это сделать? Например, есть HttpUrlConnection.
Мы идем на StackOverflow, берем пример get-запроса, подставляем свой URL. Открываем Connection. Получаем InputStream. Читаем нужные нам данные здесь в виде строки. И не забываем закрыть соединение. С этим запросом все просто. Сложности начинаются, если нам нужно сделать что-то менее тривиальное, например, загрузить на сервер файл с ReadMe. Для этого потребуется написать свою обертку.
И уже такого размера, хотя, казалось бы, задача не такая редкая.
Еще нам потребуется написать на это тесты, чего не хочется делать для, по сути, чужого кода.
Есть немало библиотек, которые работают поверх HttpUrlConnection, в которых упрощена в данном случае отправка файлов, также добавлены другие возможности, например, асинхронный вызов и т. д.
Например, есть библиотека HttpClient от Кевина Савински. Но есть и альтернатива, которая из коробки лишена всех этих недостатков — это OkHttp.
Вот как выглядит та же отправка файла при помощи OkHttp. Мы просто указываем URL. Создаем RequestBody. И выполняем запрос.
Начиная с Kitkat HttpUrlConnection на сетевом уровне сам использует OkHttp. Таким образом, если мы выберем этот вариант, то мы обезопасим себя от того, что на разных версиях Android библиотека будет вести себя по-разному.
А представим, если мы захотим добавить для части запросов useragent, или поменять поведение в случае переадресации. Мы также довольно быстро сможем это сделать при помощи интерсепторов OkHttp.
Переопределим метод intercept. Получим исходный request. Можем каким-то образом его изменить и передать дальше по цепочке. А дальше просто добавляем этот Interceptor клиенту. При этом мы можем вызвать не addInterceptor, а addNetworkInterceptor, если захотим повторно перехватывать запросы в случае редиректа.
Помимо этого OkHttp может выполнять запросы асинхронно, работать с вебсокетами и делать многие другие хорошие вещи.
Но есть один недостаток. Все же, это сторонняя библиотека, и она тянет за собой 2,5 тыс. методов. Есть ли какое-то встроенное решение, которое нас от этого убережет?
На заре Android был ApacheHttpClient, он был более стабильным на ранних версиях, но команда Google решила, что его API слишком большое для дальнейшего развития, и объявила его deprecated.
Мы по-прежнему можем использовать его в своих проектах, явно указав useLibrary “org.apache.http.legacy”, но тогда он уже будет упакован в APK, и мы нашей цели не достигнем.
Кроме рассмотренных вариантов есть еще поддерживаемая Google библиотека Voley. Она более высокоуровневая, чем предыдущие альтернативы. Так же, как OkHttp может выполнять запросы асинхронно. У нее хорошее внутреннее кэширование, и она даже умеет загружать изображения, только для этого наш imageview должен наследовать network imageview, что довольно сильное ограничение.
Voley, к сожалению, не выкладывается на JCenter и Maven Central, импортируется в проект исходным кодом, что, если нам не повезет, то этот исходный код будет также изменен в том же самом коммите, что очень плохо.
Еще Voley не может похвастаться хорошей документацией, в отличие того же OkHttp.
Таким образом, что нам лучше взять? Если у нас есть жесткое ограничение на количество методов, или работа с сетью не такая сложная, чтобы требовались какие-либо нетривиальные вещи, то можно взять HttpUrlConnection или какую-либо из его оберток. В противном случае лучшим вариантом выглядит OkHttp. (Вопросы и ответы см. в видео — прим. ред.)
Мы закончили на том, что скачали данные. Сейчас это JSON-строка. И как теперь мы можем получить удобное с точки зрения Java представление?
Если данных немного, то мы вполне можем взять нужное нам значение, используя встроенный JSONObject. Мы последовательно обходим всю структуру, пока не встретим интересующие нас поля. Читаем значение, и идем дальше.
Если данных много, то эту рутинную работу становится поддерживать довольно сложно, и есть смысл использовать определенную библиотеку.
Например, есть Moshi от Square, который изначально создавался для Android, и за счет этого он более бережлив к потреблению памяти. Но он довольно медленный.
Также есть Gson от Google, он быстрее, но потребляет больше оперативной памяти, хотя и по количеству методов несколько привлекательнее.
И еще есть Jackson, который самый быстрый из reflection-аналогов. У него поставляется отдельно стриминговая его часть и Databing для непосредственного мапинга. Но при этом он самый толстый.
Кроме того, есть LoganSquare (ссылка на GitHub), который генерирует адапторы для парсинга при компиляции. Она использует Jackson streaming API, и за счет compile time генерации существенно обгоняет конкурентов по скорости.
Сравнение можно посмотреть на бенчмарках его создателей. Видно, что LoganSquare из представленных вариантов самый быстрый.
Но compile time генерация накладывает определенные ограничения на структуру. Сами entity не могут наследовать что-либо. Также есть проблема с дженериками.
Есть еще один парсер без reflection от Instagram — IgJsonParcer. Он нас обязывает при этом аннотировать все поля непосредственно, которые мы должны обработать. Эта библиотека еще не имеет стабильной версии, и есть проблемы с количеством методов, так как она зависит и от Guava, и от Apache Commons.
Таким образом, из представленных решений самый быстрый — это LoganSquare, и если нам исключительно важна скорость, то можем использовать его. В противном случае выбираем из предыдущих вариантов, исходя из того, что нам требуется больше: скорость, потребление памяти либо количество методов.
Мы выбрали средство. Не забываем его протестировать, причем парсинг как нельзя кстати подходит для test-driven development. Мы копируем JSON из документации, пишем на это тест, а потом пишем сам парсинг, пока тест не станет зеленым.
Часто в API могут добавить дополнительные поля.
Чтобы наш парсинг при этом не упал, можно добавить в тестах неизвестные поля заранее. Тем самым мы гарантированно будем готовы к такому изменению.
Если мы, наоборот, хотим отправить данные на сервер или сохранить их в виде строки, то нам потребуется обратный процесс — сериализация, и проверить ее правильность нам также помогут тесты.
К примеру, здесь использована библиотека JsonUnit. Она использована для того, чтобы мы не сравнивали голые строки, потому что такое сравнение неустойчиво к порядку, к отступам и т. д. А так, мы сравниваем непосредственно значения, полученные нами.
Таким образом, мы выбрали, как пойдем в сеть, выбрали, чем парсить, как мы теперь можем это совместить при помощи библиотеки Retrofit (ссылка на GitHub).
Так у нас будет единая точка доступа, где мы задаем базовый URL. В случае чего мы можем довольно быстро его тут сменить, к примеру, для QA окружения. Можем выбрать конвертер между Moshi, Gson, Jackson либо Protobuf. И способ, как мы будем осуществлять вызовы. Мы можем это делать синхронно.
Или асинхронно.
Либо с использованием Rx. Для этого нам всего нужно указать, что наш метод API возвращает single completable либо observable. И выберем соответствующий CallFactory.
Мы остановились на том, что десериализовали данные пользователя. Как мы теперь представим их в Java?
Мы можем сделать это вот так. Но чем это плохо может быть? Предположим, у нас в будущем поле логина будет вычисляться непосредственно при обращении, либо мы будем логгировать все эти обращения.
Поэтому меняем их видимость на privateв, и добавляем геттеры и сеттеры.
Если мы захотим добавить его в HashMap, нам понадобится equals и hashCode.
Добавим сюда еще красивый to String. И если мы решим передать его в intent в другое activity, или сохранить в bundle при перевороте экрана, то нам потребуется, чтобы этот объект был Parcelable.
И когда мы узнаем, что в классе добавляется новое поле, нам нужно будет повторить эти круги, и ничего при этом не забыть. К счастью, есть библиотеки, которые способны решить эту проблему.
Например, AutoValue (ссылка на GitHub). Мы пишем аннотацию AutoValue и абстрактные методы доступа к полям. Непосредственно сами поля при сборке сгенерирует библиотека. Также она сгенерирует все эти методы, которые мы перечисляли до этого.
Киллер-фичей AutoValue является то, что достаточно легко использовать расширения. Например, есть Gson и Jackson расширения, которые позволяют генерировать compile time адаптеры, и за счет этого они могут догнать по скорости тот же самый LoganSquare. Таким образом, мы убиваем сразу двух зайцев: решаем проблемы и парсинга, и внутреннего представления моделей.
Есть еще расширение AutoValue Parcel. Если мы его подключим, то мы можем просто писать implements Parcelable, и методы поддержки парселизации будут сгенерированы за нас. При этом, если одно из полей класса не сериализуемо, мы получим ошибку при компиляции.
Есть другое расширение AutoValue — это Auto-Parcel, которое также делает парселизацию, но оно, в отличие от AutoValue Parcel проверяет, что объект сериализуется исключительно в Runtime, и у него также менее популярная лицензия EPL 1.0.
Есть альтернатива AutoValue — это Immutables. У него также есть адаптеры для Moshi и Gson, но нет расширения для Parcelable.
И еще есть Lombok, который, в отличие остальных, не генерирует наследника, а подменяет исходный класс.
Для поддержки всей этой магии нам понадобится IDE плагин и терпение, потому что все это может довольно сильно глючить.
Таким образом, из рассмотренных вариантов наиболее выгодно смотрится AutoValue и расширение для него Auto-Parcel. (Вопросы и ответы см. в видео — прим. ред.)
Представим, что нам нужно согласно возраста пользователя показывать ему различные виды баннеров. Вроде бы все просто. Мы берем текущую дату, вычисляем дату рождения и получаем возраст.
Но если мы при этом используем и джавовые date и календарь стандартные, то нам нужно ожидать сюрпризов. К примеру, что мы получим, если вызовем getYear? Правильный ответ — 117, потому что это не просто год.
Потому что это не просто год.
А как видно из Java.doc, это год за вычетом 1900. Отчасти мы сами виноваты, что не прочитали Java.doc заранее, да и метод этот deprecated, но вообще количество deprecated методов у этого API слишком велико.
Или, например, не самый очевидный момент, что самый известный метод у календаря GetInstance, на самом деле, каждый раз создает новый календарь.
Одна из самых популярных библиотек Java — это JodaTime (ссылка на GitHub). С ее использованием мы можем так легко решить нашу задачу с пользователем. Также мы можем, к примеру, посчитать число дней до Нового года.
Кроме того, JodaTime включает в себя актуальную версию файла Tzdata. Этот файл содержит историю того, как со временем менялись таймзоны различных регионов, и как получить местное время, исходя из UTC.
Этот файл инкапсулирует в себе решения для целой горы может быть. Подробнее о них вы можете узнать из ролика Тома Скотта. Файл Tzdata есть и в самой системе, но если мы зашьем его в APK, то мы обезопасим себя от проблемы, если вендор не выпустит обновление для своих старых устройств. Вместо этого, например, вендоры могут делать красивую трехмерную модель выбора часового пояса для своих новых клиентов, как это часто делает HTC.
Но включение файла Tzdata в APK не проходит даром. Помимо того, что увеличивается его размер, мы еще начинаем расходовать в больших объемах оперативную память — до 5 МБ. Ден Лью заметил это еще четыре года назад. Дело было в том, что библиотека предназначалась исключительно для Java, и мы, используя ClassLoader.getResourceAsStream при обращении к этому файлу, как раз кэшируем такое огромное количество данных.
Он заменил этот вызов на использование AssetManager, и выпустил библиотеку, которая называется Joda Time Android.
Команда JDK сама, что с классами работы со временем в Java нужно что-то делать, они все переписали, и с разработчиком Joda Time создали новый стандарт JSR 310. Сейчас этого в API в Android нет, но мы можем использовать back-port ThreeTenBP, а если быть более точным, ThreeTenABP, в котором Джейк «Наше все» Уортон сделал аналогичные махинации при работе с файлом Tzdata.
Подведем итог. Что нам взять для работы со временем? Если у нас есть жесткое ограничение на количество методов и размер APK, то мы вынуждены использовать стандартный API. Если же мы можем позволить подключить ThreeTenABP то лучше взять его, так как по сравнению с тем же самым Joda Time когда-нибудь в Android наверняка появится официальная поддержка нового стандарта, и тогда мы сможем легко отказаться от зависимости, всего лишь обновив импорт.
Представим, что нам нужно загрузить аватарку пользователя.
В UI-потоке пойти в сеть мы себе позволить не можем, поэтому берем AsyncTask. Чем это решение плохо? Нам нужно самостоятельно заботиться о кэшировании как в память, так и на диск, отменять неактуальные запросы и многое-многое другое.
Можем взять Picasso. С ним мы можем сделать все это очень просто, плюс добавить placeholders, состояние ошибки, сжать изображение и многое другое.
Но представим, что у нас сейчас нет непосредственного адреса картинки, есть только некий идентификатор, с которым мы должны изначально сходить на сервер, тогда мы получим этот URL, и уже по следующим запросам мы загрузим само изображение. С Picasso это будет сделать проблематично.
Но есть Glide, который внешне от Picasso неотличим, но он более гибкий, что позволит нам сделать эти ухищрения.
Мы можем создать Fetcher, который сначала синхронно скачает URL, а затем само изображение.
Кроме того, Glide поддерживает загрузку по нашим собственным моделям. Для этого мы создадим StreamModelLoader, который принимает нашего пользователя в качестве аргумента.
И дальше нужно зарегистрировать Loader в Module, Module в Manifest, яйцо в утке, утку в зайце. Ну, на самом деле, все не так сложно. Нужно просто не забыть добавить наш класс в список исключений proguard.
Итак, мы можем передавать объект нашего пользователя непосредственно в Glide, дальше он все сделает за нас.
Важно заметить, что кроме контекста мы можем передавать еще и activity либо фрагмент, и тогда Glide подпишется на наш жизненный цикл, и будет вовремя отменять запросы, когда нам это уже не нужно.
Кроме того, Glide кэширует изображения, исходя из того, в какой ImageView оно загружено. Это несколько замедляет изначальную загрузку по сравнению с тем же Picasso, но последующее использование кэша происходит гораздо быстрее, и мы потребляем меньше памяти.
Также Glide умеет загружать гифки.
Кроме этих двух библиотек еще раньше был Universal ImageLoader, но сейчас он, к сожалению, deprecated.
И есть Fresco, который использует ashmem, в отличие обычной кучи, за счет этого у нас в приложении может быть все лучше в плане используемой памяти.
А также она может загружать gif. Методов у него чуть больше, чем у Glide.
Итак, что лучше для загрузки изображений? Если мы не ждем ничего сложного от загрузки изображений как таковой, то либо у нас жесткий дефицит методов, то мы должны выбрать, наверное, Picasso. Если нужно что-то нетривиальное либо поддержка gif, то это будет Glide. В любом случае с Picasso на Glide достаточно просто мигрировать, так как у них схожи API. (Вопросы и ответы см. в видео — прим. ред.)
Из чего строится архитектура? Как правило, это dependency injection, MVP, MVVM и т. д.
Что касается dependency injection, изначально был reflection-based решение RoboGuice, которое было довольно простым в использовании, но, пожалуй, на этом его плюсы заканчивались. Для инджектов оно использовало рефлексию. Если для серверной Java это, возможно, имеет право на жизнь, так как процесс довольно долго не выгружается из памяти, и reflection обращение успевает закэшироваться, то у Android жизненный цикл сильно короче, и до такого кэша часто дело может не дойти, и поэтому мы получаем тормоза.
RoboGuice уже как год deprecated. Ему на смену в какое-то время приходил Dagger1, который во многом решал все свои проблемы кодогенерацией, но определенное количество reflection вызовов, тем не менее, происходило. На сегодняшний день он также устарел и заменен Dagger2. У него все происходит в процессе компиляции, за счет чего он эффективный в плане скорости.
Еще он привнес новое понятие скоупов, когда мы можем удобно компоновать зависимости, у которых общий жизненный цикл. Например, заводим какой-то аккаунт scope, который содержит все нужные нам данные для текущего аккаунта. И буквально год назад появился Toothpick, который, судя по названию, видит, кто его главный конкурент. Он также reflection free, и тоже имеет scope. У него нет такого понятия, как компонент, за счет этого его использование несколько проще.
По скорости на малом числе инжектов он несколько быстрее Dagger, и проигрывать начинает лишь при большом количестве. (Ссылка на GitHub.)
На этом графике видно, насколько все же RoboGuice плох.
Таким образом, есть всего два конкурента, которые друг с другом практически неотличимы. Они практически одинаково быстры, привносят порядка всего пары сотен методов, что порою несущественно, у обоих библиотек достаточно удобный API, и у TootрPick даже чуть более лаконичное. Единственный минус при их использовании — это то, что они ломают инкрементальную сборку.
По MVP и MVVM у вас уже была лекция, и я лишь добавлю, что, делая выбор фреймворка, отдавайте себе отчет, что, как правило, это именно фреймворк, а не библиотека. Он накладывает на вас достаточно серьезные ограничения, а польза от его использования может быть не всегда ощутимой. Поэтому порою лучшим решением здесь могут быть и пара самописных классов, которые мы в будущем легко сможем подстроить под какие-либо новые задачи.
Аналогично коротко о работе с базами данных. Фреймворков и библиотек также огромное множество со своими плюсами и минусами, но стоит с осторожностью выбирать те решения, которые выступают именно как фреймворки, делая за вас все. Такие, как GreenDAO, ORMLite или NoSQL решение Realm.
Как правило, при нестандартных ситуациях у нас не будет гибкости — решить это без костылей.
Есть более легковесные решения, которые только оказывают нам помощь, избавляя от некрасивого шаблонного кода. Это они делают в большинстве случаев, а в редких случаях, когда мы можем сделать что-то нетривиальное, мы можем сделать это руками.
Например, SQLDelight, он генерирует нам маппинг и Java-классы по написанному SQL-коду. Дальше мы можем делать все руками, либо подключив другие обвязки, которые позволят нам общаться с базой, к примеру, с использованием Rx, например, StorIO или SQLBrite.
Также стоит обратить внимание на Room, так как кажется, он решает многие текущие проблемы, и, возможно, в будущем станет стандартом.
Как проверить качество того, что мы написали? В первую очередь это тесты, но по тестам у вас уже была лекция, и во-вторых, тесты нужно писать. А есть средства, которые даются нам практически даром — это различные статистические анализаторы.
Первый из них — это checkstyle (ссылка на SourceForge). Он не находит непосредственно багов, но следит за тем, чтобы у всех разработчиков был общий стиль написания кода. Это касается случайно пропущенных аннотаций Override и излишних модификаций, к примеру, у интерфейса, размера строк, методов и т. д. Полный список можно посмотреть по ссылке.
Чтобы подключить checkstyle, нужно добавить его в зависимость. Нужно также указать конфигурационный файл, и те файлы, которые мы будем анализировать.
В конфиге мы можем задать правила игнорирования некоторых проблем, которые, к примеру, свойственны для всего проекта, либо изменить параметр некоторых проверок, например, установить свою длину строк.
Так выглядит файл с фильтром для общих проблем проекта. А вот так мы можем игнорировать конкретную проблему непосредственно в Java-коде.
Следующий анализатор кода Lint, он находит Android-специфичные проблемы, такие, как отсутствие перевода для одной из локалий или отсутствие изображения для одного из разрешений экрана, а также многое другое.
Также он хорош во взаимодействии с аннотациями из саппорта. Мы можем определять такие проблемы, как nullability, некорректное использование интов, которое ссылается, на самом деле, на различные ресурсы, и вызов из неверного потока, а также многое другое.
Таким образом он подключается. Стоит обратить внимание на baseline. Lint дает нам возможность быстрого входа в уже существующий проект. Запустив его с такой строкой, мы временно будем игнорировать существующие проблемы, чтобы фокусировать внимание на новых проблемах.
Так выглядит конфиг Lint. Здесь мы можем менять приоритет проблем либо игнорировать их.
А так мы можем игнорировать проблемы в коде и XML.
Еще один статический анализатор — PMD (ссылка на SourceForge). Он больше нацелен на поиск проблем непосредственно в Java. Полный список проблем можете также посмотреть по ссылке.
Настраивается он таким образом.
А так выглядит его конфиг.
Есть еще одно средство, похожее на PMD, которое анализирует не сами Java-файлы, а уже байт-код. Это FindBugs (ссылка на SourceForge). Одну из проблем, которую он решает, можем посмотреть на примере.
Допустим, у нашего пользователя нет аватарки, и мы хотим поставить ему определенного цвета фон. Чтобы цвета из палитры были разные для разных пользователей, мы берем модуль от hashCode, его идентификатора, и после деления с остатком определяем нужный цвет. Что тут может пойти не так?
FindBugs говорит, что если hashCode у нас будет равен минимальному int, то из-за переполнения функция abs нам вернет то же самое отрицательное значение, и мы получим ошибку IndexOutOfBounds.
Исправим эту ошибку, исключив такую ситуацию, и поблагодарим FindBugs за подсказку.
Это пример настройки FindBugs. Следует отметить, что он может за один раз генерировать либо XML, либо HTML-отчет, поэтому, чтобы посмотреть отчет в другом виде, нам нужно пересобирать заново.
А так мы можем игнорировать какие-либо проблемы для всего проекта, а в конкретном месте мы можем добавить аннотацию из Findbugs:annotations.
К сожалению, FindBugs с недавних пор не развивается, ему на смену пришел SpotBugs, который, правда, пока имеет проблемы при интеграции с Android, но тем не менее.
До этого мы рассматривали анализаторы, которые делают перманентный анализ, но есть ПО, которое позволяет, используя внутри все те же самые средства, собрать все данные в единый dashboard. В этом dashboard мы можем посмотреть также историю изменения качества кода.
Можем легко следить за покрытием.
Или даже настроить, чтобы новые проблемы репортились непосредственно комментариями в пул-реквест.
Подведем итог. Какие из представленных средств взять на вооружение? Правильный ответ — все. Хоть правила и могут частично перекрываться, все равно есть уникальные, и если мы будем использовать все из них, то вероятность пропущенной ошибки будет существенно меньше. (Ссылка на GitHub.)
Мы рассмотрели достаточном много библиотек, но как быть, если мы исправили в одной из них ошибку, а возможности дождаться релиза этого исправления нет? Нам может помочь JitPack, который позволяет добавить в качестве зависимости не опубликованный вариант, а сборку из какого-либо fork, конкретной ветки или тега.
В заключение — пару слов про Kotlin. Google наконец признал его официальным языком, и это язык, который действительно помогает избавиться от многих проблем. Уже на стадии компиляции мы практически защищены от NullPointerException и ClassCastException. Есть встроенная поддержка data-классов, которая, к сожалению, восполняет не весь функционал того же AutoValue, то есть у него нет расширения, и будут проблемы с сериализацией. Например — с тем, чтобы получить из объекта Parcelable.
Еще есть pattern matching, делегаты и многое другое. Судя по тем замерам, которые мы проводили, подключение Kotlin практически никак не влияет на скорость сборки, и количество методов увеличивается исключительно в релизе, потому что proguard довольно хорошо выпиливает лишние методы.
Есть и другие проблемы, такие как final everywhere, когда каждый класс по умолчанию final, и мы не можем от него наследоваться. Это вставляет грабли в Mockito — другими словами, мы не можем замокать наш объект для тестов. Но это — хоть и в экспериментальном виде — решено в Mockito 2.
Еще есть проблема с any. Например, если мы используем такой matcher, он по умолчанию возвращает null в Mockito. И если Kotlin-класс примет параметр на null, у нас сломается компиляция. Но эта проблема решается через Mockito Kotlin. Кроме того, есть Spek — фреймворк для написания тестов в виде специфики от JetBrains. Только, к сожалению, он пока не работает с Roboelectric. Постепенно заполняется и пробел с точки зрения статистических анализаторов — развивается утилита Detekt и плагин к ней для интеграции с SonarQube. На этом у меня все. Спасибо за внимание.
Контакты автора: почта, Telegram