
Сегодня мы расскажем об одном из сервисов SAP, который характеризует наш новый подход к созданию продуктов и работе с клиентами. Это решение SAP Cloud Platform Big Data Services, которое предлагает клиентам возможность работать с большими данными в Hadoop по модели подписки на облачное приложение.
В первой статье мы сделаем обзор того, как анализ Big Data может пригодиться бизнесу на практике, как отличаются облачного и on-premise размещения Hadoop, а про основные функции, сервисы и технологии в SAP Cloud Platform Big Data Services. В следующих статьях мы подробнее разберём технологические особенности и отдельные сервисы внутри данного решения.
Big Data в бизнесе

Все знают, что среди клиентов SAP есть многие крупные российские и мировые компании из промышленности, металлургии, нефтегаза и других «консервативных отраслей», для них мы разрабатываем и внедряем ИТ-решения и системы. Сейчас эти компании всё активнее инвестируют в новые технологии – в интернет вещей, машинное обучение или работу с Big Data (в частности, стремясь извлечь новую ценность из этих больших данных). Например, для металлургических компаний в текущих экономических и геополитических условиях критически важно найти новые источники прибыли или способы сокращения расходов. Один из таких способов кроется в поиске новых идей в больших данных, говорящих нам о бизнесе, о рабочих процессах и внешнем мире в целом.
На рынке существует множество решений для хранения и работы с большими данными – как бесплатные open source, так и коммерческие продукты. Самое популярное решение – это Hadoop и его дополнительные компоненты. Среди причин его востребованности:
Популярность бесплатных open source-решений очевидна. Однако при разворачивании Hadoop для промышленного использования, как правило, бесплатные open source версии не используются в чистом виде. В мире бизнеса получили популярность коммерческие версии open source-продуктов Hadoop. Их распространяют компании Cloudera, Hortonworks и другие разработчики. В этом случае провайдеры отвечают за надёжность программного обеспечения и взаимодействие всех компонентов. Также есть и альтернативные сервисы, которые предоставляют возможность работы с большими данными через облака, по подписке.
Бизнес зачастую сталкивается с дилеммой – какой из подходов к работе с большими данными выбрать, on-premise (локальный) или в облаке. Безусловно, большинство внутренних ИТ-департаментов компаний голосуют за первый вариант, из-за традиционных опасений по поводу облаков.
Исследовательская компания Forrester провела опрос среди компаний, которые работают с Big Data, о том, как они используют свои Hadoop-решения – в облаке или on-premise. 37% респондентов ответили, что планируют увеличить инвестиции в облачные сервисы для Big Data от 5% до 10%. Ещё 14% участников исследования сказали, что повысят затраты на облачные Hadoop-решения больше, чем на 10%. Почему они делают выбор в пользу облаков?
Запуск Hadoop на собственных серверах – это просто на начальном этапе работы с Big Data, при проведении экспериментов с данными и проверке гипотез. Другая история – если вам нужно запустить решение в промышленную эксплуатацию, где есть определённые требования: SLA по доступности 99,9%, обеспечение высокой надёжности хранения огромных массивов данных, а также выполнение целевых KPI по производительности.
Если вы выбрали размещение Hadoop on-premise в продуктиве, вам предстоит решить следующие задачи:
Необходимо учитывать, что этот подготовительный этап занимает значительное время. Поэтому компании делают выбор между on-premise и облачным сервисом.
В одном из отчётов консалтинговой фирмы Bain & Co. приводится пример Netflix. В 2016 году компания заявляла о том, что для обработки Big Data им приходится работать с тысячами узлов данных под огромной нагрузкой. Ежедневно они обрабатывают 350 миллиардов пользовательских событий и петабайты данных из своих сервисов. Конечно, в этом случае нельзя справиться только силами собственных серверов – или придётся непрерывно строить свои дата-центры.
Другой пример, из более «традиционных отраслей» – это компания General Electric. В 2013 году они начали переход из собственных дата-центров в облака. Сначала на новый сервис перешли нефтяное и газовое подразделение, затем начался перенос более 9000 тысяч инфраструктурных приложений компании. В итоге General Electric сумели сократить количество собственных дата-центров с 30 до 4, а вместе с этим и затраты на персонал, оборудование и т.п.
SAP не остался в стороне от облачного тренда. В 2016 году к нам присоединилась команда компании Altiscale – одного из ведущих мировых провайдеров услуг по модели Big Data As-a-Service. Их решение стало новым продуктом SAP Cloud Platform Big Data Services, который доступен клиентам SAP по модели облачной подписки, а также был интегрирован в общую облачную структуру SAP.
Разработчики этого решения – бывший Chief Technology Officer (технический директор) компании Yahoo и его коллеги, занимавшиеся развитием Hadoop в компании. За 7 лет работы в Yahoo они превратили свой небольшой Hadoop-проект в продуктивную систему в объёме более 42 000 узлов данных.
Что такое SAP Cloud Platform Big Data Services – облачный Hadoop-сервис от SAP
SAP Cloud Platform Big Data Services – это набор инструментов для работы с большими данными по модели SaaS (Software-as-a-Service).
Рассмотрим архитектуру SAP Cloud Platform Big Data Services.
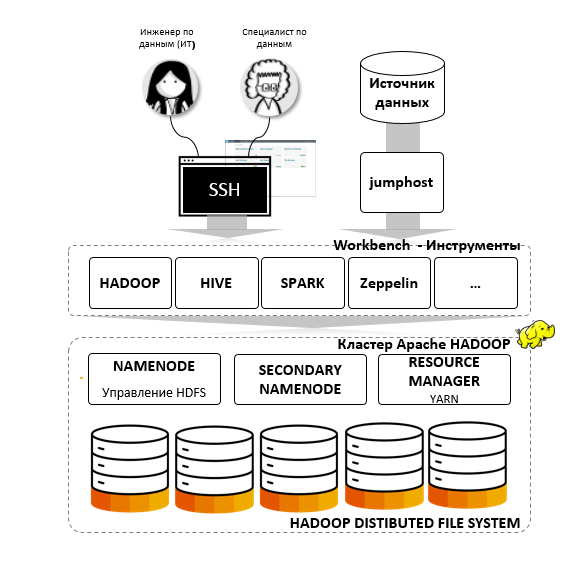
Сервис включает в себя три основные части:
Кластер Apache Hadoop
Для кластера используется компиляция Hadoop, сертифицированная ODPi. Это означает, что приложения и скрипты, работающие в ODPi-средах других сервисов, будут успешно выполняться на SAP Big Data Services.
*Для справки, ODPi (Open Data Platform initiative) – это некоммерческая организация, которая занимается стандартизацией Hadoop и его компонентов. В ODPi кроме SAP входят такие известные вендоры, как Hortonworks, IBM, SAS и многие другие.
Кластер включает в себя три вида узлов управляющие, обслуживающие и узлы с данными: namenode, secondary namenode, resource manager (YARN включен в начальную конфигурацию сервиса).
При этом дублирующий name node поддерживает дополнительными сервисы Oozie, Hive Metastore и др. При подключении клиенту выдается отдельный кластер с необходимыми ресурсами. Ресурсы описываются объемом хранилища и количеством машино-часов. При необходимости ресурсы кластера могут гибко расширяться на время выполнения критичных расчетов или на постоянной основе.
Workbench – это единая точка доступа к Big Data Service.
По соображениям безопасности прямой доступ к кластеру Hadoop ограничен до круга обслуживающего персонала и Workbench. Клиент получает доступ только к Workbench, который включает в себя локальный Hadoop, а также Hive, Spark, Oozie, Pig и другие необходимые компоненты для data science и data engineering, в том числе SAP Lumira и SAP Predictive Analytics:.

Более подробную информацию о составе сервиса вы можете найти на сайте.
С помощью Workbench клиент может запускать скрипты, исследовать данные с помощью инструментов Business Intelligence и решать другие задачи. В свою очередь Workbench тесно взаимодействует с кластером Hadoop по высокоскоростному каналу.
Портал Big Data Service
Он используется для ведения пользователей, генерации ключей доступа к Big Data Service, просмотра статистики использования кластера и выполнения других операционных задач, возникающих у клиента.
Для подключения Big Data Service к внешнему миру используется jumphost-сервер. Все сетевое взаимодействие осуществляется в пространстве локальных ip-адресов – virtual private cloud. Стандартный способ доступа к Big Data Service – SSH. По запросу клиента доступны другие опции подключения. Big Data Service также поддерживает kerberos-аутентификацию, что позволяет пользоваться Single Sign-On (SSO).
Big Data Service может взаимодействовать как с другими облачными сервисами SAP, так и с on-premise решениями. Для интеграции доступны следующие опции:
Каналы связи, подключенные к Big Data Service, организованы таким образом, чтобы загружать данные из клиентских систем-источников с высокой скоростью.
В роадмапе Big Data Service на следующий год – интеграция решениями SAP для работы с «большими» данными Vora и SAP Data Hub. О них мы расскажем поподробнее в одной из следующих статей.
Отличие SAP Cloud Platform Big Data Services от других облачных Hadoop-решений
Главное отличие решения SAP от других состоит в том, что оно может быть органично встроено в бизнес-процессы за счёт интеграции с сервисами и другими системами SAP. Это ключевой фактор, который помогает на практике монетизировать большие данные. Если при работе с Hadoop результаты анализа данных видят только data scientist’ы, то им ещё предстоит убедить бизнес-пользователей в необходимости применить новые идеи на практике – и нет гарантии, что гипотезы будут применяться на практике. SAP Cloud Platform Big Data Services может быть напрямую интегрировано с внутренними ИТ-системами компании, как один из шагов бизнес-процесса. Подробнее об отличиях решения SAP от других, о том, как на практике встраивать результаты работы специалистов по большим данным в бизнес-процессы, мы расскажем в следующей статье.
Клиентские кейсы использования SAP Cloud Platform Big Data Services
Glu Mobile
Glu Mobile – это один из крупных глобальных разработчиков мобильных игр, включая успешные проекты Cooking Dash, Deer Hunter, Contract Killer, Kim Kardashian: Hollywood, Frontline Commando. У компании есть студии разработки по всему миру, одна из которых находится в Москве.
Glu Mobile разрабатывает и поддерживает free-to-play игры-сервисы, которые бесплатны для скачивания и монетизируются через внутренние микротранзакции. Для таких игр-сервисов важно, чтобы игроки не уходили из них в течение долгого времени.
Ежедневная аудитория проектов Glu Mobile – более 5 миллионов активных пользователей, всего игры компании установили более 1,3 миллиардов раз. Учитывая такую масштабную аудиторию, перед компанией стоят следующие задачи – сделать так, чтобы игроку было удобно и интересно играть, при этом повышая показатель прибыли LTV (lifetime value) одного игрока.
Для этого компания в режиме реального времени собирает огромные данные из своих проектов:
Изначально в Glu Mobile пытались использовать on-premise решение Hadoop, но столкнулись со следующими сложностями:
В результате перехода на SAP Cloud Platform Big Data Services команда Glu Mobile получила следующие результаты:
Как Glu Mobile использует SAP Cloud Platform Big Data Services:
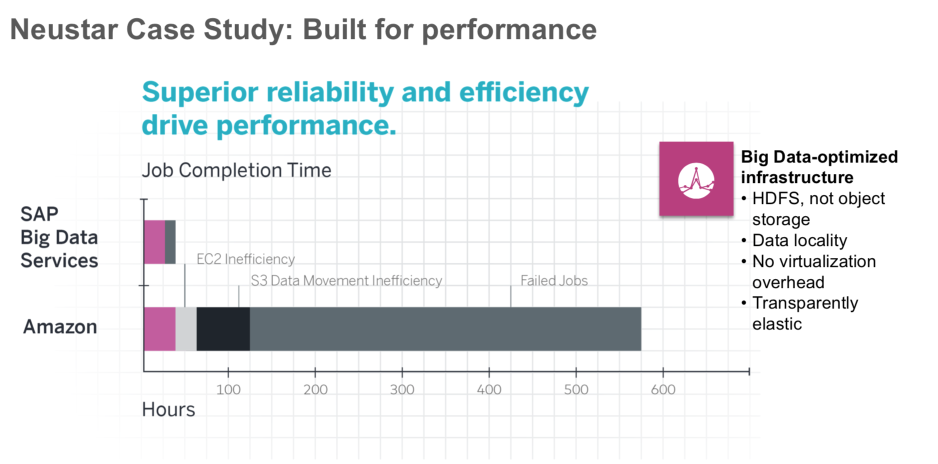
Кейс Neustar MarketShare DecisionCloud
Neustar – это компания, которая предоставляет клиентам сервисы для аналитики результатов маркетинговых кампаний, а также анализа пользовательских действий. Компания собирает самые разные данные во многих индустриях – ритейл, финансы, фармацевтика, автомобильная промышленность, технологические компании.
На текущий момент объем данных, размещённых на сервисных мощностях SAP Cloud Big Data Service, составляет порядка 2,5 Петабайт.
Когда Neustar использовала предыдущую платформу для работы Big Data, у них возникали следующие проблемы:
После перехода на решение SAP Cloud Platform Big Data Services компания получила следующие преимущества:

Компания First Data
First Data – это компания, которая занимается обработкой операций по банковским картам. Это крупнейший американский сервис процессинга банковских карт (до 45% рынка).
На первом этапе внедрения в 2015 году решение SAP Cloud Platform Big Data Services позволило расширить функциональность First Data для малого бизнеса, а также сократило издержки на 500 тысяч долларов США. На втором этапе, в 2017 году решение помогло внедрить обнаружение фрода по банковским картам, а также сэкономило компании ещё два миллиона долларов США ACV.
Использование решения SAP также позволило клиентам First Data получить следующую информацию:
Проблемы, связанные с предыдущей инфраструктурой для работы с Big Data:
При выборе решения SAP компания First Data руководствовалась следующими целями:
Какую пользу принёс переход на решение SAP:
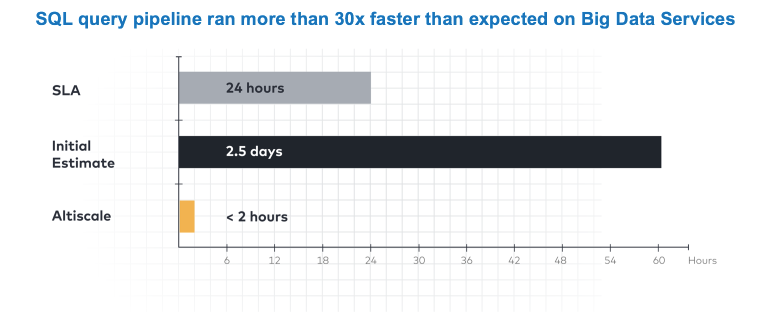
Один из результатов перехода на решение SAP – исполнение SQL-запросов на новом решении проходит в 30 раз быстрее ожидаемого.
Небольшое резюме статьи про SAP Cloud Platform Big Data Services :

В следующем материале мы подробнее расскажем о планах по развитию SAP Cloud Platform Big Data Service: про интеграцию с другими сервисами и решениями SAP, про новые функции и приложения и т.д.
Если вы дочитали этот материал до конца и хотите самостоятельно протестировать на практике работу с SAP Cloud Platform Big Data Services, напишите нам, чтобы получить бесплатный тестовый доступ к сервису.
В первой статье мы сделаем обзор того, как анализ Big Data может пригодиться бизнесу на практике, как отличаются облачного и on-premise размещения Hadoop, а про основные функции, сервисы и технологии в SAP Cloud Platform Big Data Services. В следующих статьях мы подробнее разберём технологические особенности и отдельные сервисы внутри данного решения.
Big Data в бизнесе
Все знают, что среди клиентов SAP есть многие крупные российские и мировые компании из промышленности, металлургии, нефтегаза и других «консервативных отраслей», для них мы разрабатываем и внедряем ИТ-решения и системы. Сейчас эти компании всё активнее инвестируют в новые технологии – в интернет вещей, машинное обучение или работу с Big Data (в частности, стремясь извлечь новую ценность из этих больших данных). Например, для металлургических компаний в текущих экономических и геополитических условиях критически важно найти новые источники прибыли или способы сокращения расходов. Один из таких способов кроется в поиске новых идей в больших данных, говорящих нам о бизнесе, о рабочих процессах и внешнем мире в целом.
На рынке существует множество решений для хранения и работы с большими данными – как бесплатные open source, так и коммерческие продукты. Самое популярное решение – это Hadoop и его дополнительные компоненты. Среди причин его востребованности:
- Надежность
- Масштабируемость
- Оптимальная стоимость хранения информации
- Большое количество дополнительных программных компонентов с открытым кодом для обработки данных в Hadoop – Spark, Hive и другие
- На рынке доступно большое количество специалистов, которые умеют работать с Hadoop
Популярность бесплатных open source-решений очевидна. Однако при разворачивании Hadoop для промышленного использования, как правило, бесплатные open source версии не используются в чистом виде. В мире бизнеса получили популярность коммерческие версии open source-продуктов Hadoop. Их распространяют компании Cloudera, Hortonworks и другие разработчики. В этом случае провайдеры отвечают за надёжность программного обеспечения и взаимодействие всех компонентов. Также есть и альтернативные сервисы, которые предоставляют возможность работы с большими данными через облака, по подписке.
Бизнес зачастую сталкивается с дилеммой – какой из подходов к работе с большими данными выбрать, on-premise (локальный) или в облаке. Безусловно, большинство внутренних ИТ-департаментов компаний голосуют за первый вариант, из-за традиционных опасений по поводу облаков.
Исследовательская компания Forrester провела опрос среди компаний, которые работают с Big Data, о том, как они используют свои Hadoop-решения – в облаке или on-premise. 37% респондентов ответили, что планируют увеличить инвестиции в облачные сервисы для Big Data от 5% до 10%. Ещё 14% участников исследования сказали, что повысят затраты на облачные Hadoop-решения больше, чем на 10%. Почему они делают выбор в пользу облаков?
Запуск Hadoop на собственных серверах – это просто на начальном этапе работы с Big Data, при проведении экспериментов с данными и проверке гипотез. Другая история – если вам нужно запустить решение в промышленную эксплуатацию, где есть определённые требования: SLA по доступности 99,9%, обеспечение высокой надёжности хранения огромных массивов данных, а также выполнение целевых KPI по производительности.
Если вы выбрали размещение Hadoop on-premise в продуктиве, вам предстоит решить следующие задачи:
- Найти и нанять опытных ИТ-специалистов
- Закупить необходимое оборудование
- Закупить нужные дистрибутивы, установить и наладить ПО
- Запустить решение в продуктиве
- Поддерживать работу решения с регулярными операционными затратами (зарплата персонала, обслуживание оборудования и т.п.)
Необходимо учитывать, что этот подготовительный этап занимает значительное время. Поэтому компании делают выбор между on-premise и облачным сервисом.
В одном из отчётов консалтинговой фирмы Bain & Co. приводится пример Netflix. В 2016 году компания заявляла о том, что для обработки Big Data им приходится работать с тысячами узлов данных под огромной нагрузкой. Ежедневно они обрабатывают 350 миллиардов пользовательских событий и петабайты данных из своих сервисов. Конечно, в этом случае нельзя справиться только силами собственных серверов – или придётся непрерывно строить свои дата-центры.
Другой пример, из более «традиционных отраслей» – это компания General Electric. В 2013 году они начали переход из собственных дата-центров в облака. Сначала на новый сервис перешли нефтяное и газовое подразделение, затем начался перенос более 9000 тысяч инфраструктурных приложений компании. В итоге General Electric сумели сократить количество собственных дата-центров с 30 до 4, а вместе с этим и затраты на персонал, оборудование и т.п.
SAP не остался в стороне от облачного тренда. В 2016 году к нам присоединилась команда компании Altiscale – одного из ведущих мировых провайдеров услуг по модели Big Data As-a-Service. Их решение стало новым продуктом SAP Cloud Platform Big Data Services, который доступен клиентам SAP по модели облачной подписки, а также был интегрирован в общую облачную структуру SAP.
Разработчики этого решения – бывший Chief Technology Officer (технический директор) компании Yahoo и его коллеги, занимавшиеся развитием Hadoop в компании. За 7 лет работы в Yahoo они превратили свой небольшой Hadoop-проект в продуктивную систему в объёме более 42 000 узлов данных.
Что такое SAP Cloud Platform Big Data Services – облачный Hadoop-сервис от SAP
SAP Cloud Platform Big Data Services – это набор инструментов для работы с большими данными по модели SaaS (Software-as-a-Service).
Рассмотрим архитектуру SAP Cloud Platform Big Data Services.
Сервис включает в себя три основные части:
Кластер Apache Hadoop
Для кластера используется компиляция Hadoop, сертифицированная ODPi. Это означает, что приложения и скрипты, работающие в ODPi-средах других сервисов, будут успешно выполняться на SAP Big Data Services.
*Для справки, ODPi (Open Data Platform initiative) – это некоммерческая организация, которая занимается стандартизацией Hadoop и его компонентов. В ODPi кроме SAP входят такие известные вендоры, как Hortonworks, IBM, SAS и многие другие.
Кластер включает в себя три вида узлов управляющие, обслуживающие и узлы с данными: namenode, secondary namenode, resource manager (YARN включен в начальную конфигурацию сервиса).
При этом дублирующий name node поддерживает дополнительными сервисы Oozie, Hive Metastore и др. При подключении клиенту выдается отдельный кластер с необходимыми ресурсами. Ресурсы описываются объемом хранилища и количеством машино-часов. При необходимости ресурсы кластера могут гибко расширяться на время выполнения критичных расчетов или на постоянной основе.
Workbench – это единая точка доступа к Big Data Service.
По соображениям безопасности прямой доступ к кластеру Hadoop ограничен до круга обслуживающего персонала и Workbench. Клиент получает доступ только к Workbench, который включает в себя локальный Hadoop, а также Hive, Spark, Oozie, Pig и другие необходимые компоненты для data science и data engineering, в том числе SAP Lumira и SAP Predictive Analytics:.
Более подробную информацию о составе сервиса вы можете найти на сайте.
С помощью Workbench клиент может запускать скрипты, исследовать данные с помощью инструментов Business Intelligence и решать другие задачи. В свою очередь Workbench тесно взаимодействует с кластером Hadoop по высокоскоростному каналу.
Портал Big Data Service
Он используется для ведения пользователей, генерации ключей доступа к Big Data Service, просмотра статистики использования кластера и выполнения других операционных задач, возникающих у клиента.
Для подключения Big Data Service к внешнему миру используется jumphost-сервер. Все сетевое взаимодействие осуществляется в пространстве локальных ip-адресов – virtual private cloud. Стандартный способ доступа к Big Data Service – SSH. По запросу клиента доступны другие опции подключения. Big Data Service также поддерживает kerberos-аутентификацию, что позволяет пользоваться Single Sign-On (SSO).
Big Data Service может взаимодействовать как с другими облачными сервисами SAP, так и с on-premise решениями. Для интеграции доступны следующие опции:
- Сбор и обработка данных сенсоров с помощью Kafka Streaming
- Экстракция данных из реляционных баз данных с помощью Kafka Connectors или SAP Data Services
- Взаимодействие с SAP-системами на платформе SAP HANA посредством Smart Data Access и Smart Data Integration
- Взаимодействие с on-premise Hadoop на уровне Hadoop Distributed File System (HDFS)
Каналы связи, подключенные к Big Data Service, организованы таким образом, чтобы загружать данные из клиентских систем-источников с высокой скоростью.
В роадмапе Big Data Service на следующий год – интеграция решениями SAP для работы с «большими» данными Vora и SAP Data Hub. О них мы расскажем поподробнее в одной из следующих статей.
Отличие SAP Cloud Platform Big Data Services от других облачных Hadoop-решений
Главное отличие решения SAP от других состоит в том, что оно может быть органично встроено в бизнес-процессы за счёт интеграции с сервисами и другими системами SAP. Это ключевой фактор, который помогает на практике монетизировать большие данные. Если при работе с Hadoop результаты анализа данных видят только data scientist’ы, то им ещё предстоит убедить бизнес-пользователей в необходимости применить новые идеи на практике – и нет гарантии, что гипотезы будут применяться на практике. SAP Cloud Platform Big Data Services может быть напрямую интегрировано с внутренними ИТ-системами компании, как один из шагов бизнес-процесса. Подробнее об отличиях решения SAP от других, о том, как на практике встраивать результаты работы специалистов по большим данным в бизнес-процессы, мы расскажем в следующей статье.
Клиентские кейсы использования SAP Cloud Platform Big Data Services
Glu Mobile
Glu Mobile – это один из крупных глобальных разработчиков мобильных игр, включая успешные проекты Cooking Dash, Deer Hunter, Contract Killer, Kim Kardashian: Hollywood, Frontline Commando. У компании есть студии разработки по всему миру, одна из которых находится в Москве.
Glu Mobile разрабатывает и поддерживает free-to-play игры-сервисы, которые бесплатны для скачивания и монетизируются через внутренние микротранзакции. Для таких игр-сервисов важно, чтобы игроки не уходили из них в течение долгого времени.
Ежедневная аудитория проектов Glu Mobile – более 5 миллионов активных пользователей, всего игры компании установили более 1,3 миллиардов раз. Учитывая такую масштабную аудиторию, перед компанией стоят следующие задачи – сделать так, чтобы игроку было удобно и интересно играть, при этом повышая показатель прибыли LTV (lifetime value) одного игрока.
Для этого компания в режиме реального времени собирает огромные данные из своих проектов:
- Более 30 тысяч пользовательских действий каждую секунду
- Около 2 миллиардов отчётов о действиях пользователей каждый день
- Более 100 миллионов событий от различных метрик
- 2 триллиона пользовательских событий хранятся на базе решения SAP Cloud Platform
Изначально в Glu Mobile пытались использовать on-premise решение Hadoop, но столкнулись со следующими сложностями:
- Чем больше становились объёмы данных, тем сложнее было с ними работать
- Слабая внутренняя команда Hadoop
- Слабая надёжность системы, периодические падения серверов
- Слабые результаты при выполнении запросов к базам данных
В результате перехода на SAP Cloud Platform Big Data Services команда Glu Mobile получила следующие результаты:
- Решение отвечает нуждам компании по обработке данных
- Способность работать с огромными объёмами быстро появляющихся новых данных
- Одно из лучших решений на рынке с точки зрения производительности и надёжности
- Внутренняя команда была освобождена от необходимости тратить время на Hadoop и переключилась на Data Science
- Простая масштабируемость решения в зависимости от нужд бизнеса
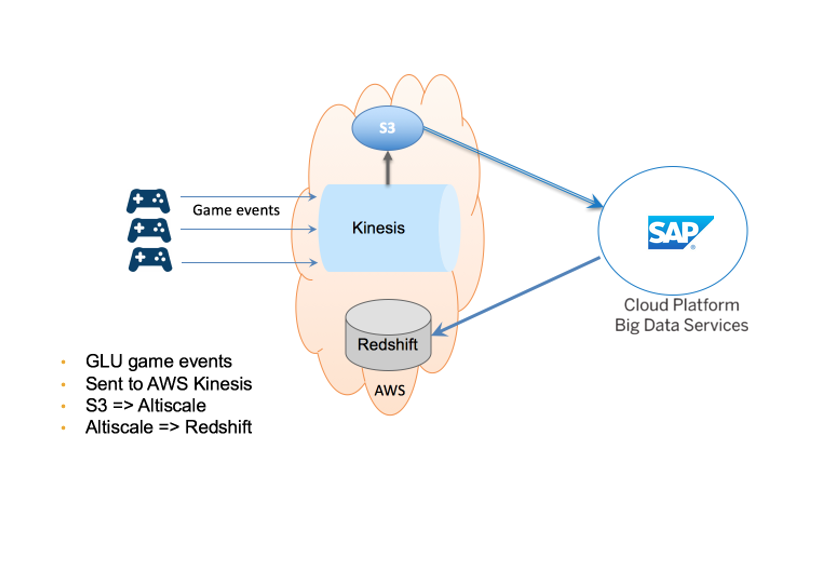
Как Glu Mobile использует SAP Cloud Platform Big Data Services:
Кейс Neustar MarketShare DecisionCloud
Neustar – это компания, которая предоставляет клиентам сервисы для аналитики результатов маркетинговых кампаний, а также анализа пользовательских действий. Компания собирает самые разные данные во многих индустриях – ритейл, финансы, фармацевтика, автомобильная промышленность, технологические компании.
На текущий момент объем данных, размещённых на сервисных мощностях SAP Cloud Big Data Service, составляет порядка 2,5 Петабайт.
Когда Neustar использовала предыдущую платформу для работы Big Data, у них возникали следующие проблемы:
- Слишком много времени уходит на выполнение операций
- Слабая надёжность сервиса
- Затруднения при разработке продукта
- Рост затрат на поддержание инфраструктуры
- Возможность работы лишь с ограниченным числом клиентов
После перехода на решение SAP Cloud Platform Big Data Services компания получила следующие преимущества:
- Высокая производительность и надёжность сервиса
- Возможность сфокусироваться на аналитике вместо оперирования Hadoop
- Более эффективное распределение ресурсов и управление расходами
- Рост конкурентоспособности решения на рынке
Компания First Data
First Data – это компания, которая занимается обработкой операций по банковским картам. Это крупнейший американский сервис процессинга банковских карт (до 45% рынка).
На первом этапе внедрения в 2015 году решение SAP Cloud Platform Big Data Services позволило расширить функциональность First Data для малого бизнеса, а также сократило издержки на 500 тысяч долларов США. На втором этапе, в 2017 году решение помогло внедрить обнаружение фрода по банковским картам, а также сэкономило компании ещё два миллиона долларов США ACV.
Использование решения SAP также позволило клиентам First Data получить следующую информацию:
- Связать воедино информацию о транзакциях и данные сторонних подрядчиков
- Получить анализ данных о клиентах и результатах промо-кампаний в зависимости от географии или демографических факторов
- Сравнивать свои результаты с результатами схожих бизнесов
- Получение рекомендаций по улучшению продаж, маркетинговых активностей и повышению лояльности клиентов на основе больших данных
Проблемы, связанные с предыдущей инфраструктурой для работы с Big Data:
- Неподъёмный размер необходимых инвестиций для того, чтобы масштабировать использование проприетарного решения
- Неспособность к детальному изучению информации
- Ограниченное количество доступных вариантов визуализации
- Слабая поддержка со стороны вендора
При выборе решения SAP компания First Data руководствовалась следующими целями:
- Расширить использование продукта среди большего количества клиентов
- Поддержка анализа более детализированных данных и больший набор визуализаций
- Возможность добавления в продукт новых функций и большей интерактивности с течением времени
Какую пользу принёс переход на решение SAP:
- Значительное сокращение расходов
- Выполнение поставленных продуктивных целей
- Гибкость в анализе детализированной информации
- Широкие возможности для визуализации данных
- Широкая поддержка со стороны вендора, включая технических специалистов
- Продуктивная платформа для работы с Big Data
Один из результатов перехода на решение SAP – исполнение SQL-запросов на новом решении проходит в 30 раз быстрее ожидаемого.
Небольшое резюме статьи про SAP Cloud Platform Big Data Services :
- Быстрый старт проекта
- Готовность оборудования к промышленному запуску в течение дней, а не месяцев
- Быстрый возврат инвестиций от использования облачного сервиса (подтверждается мнениями экспертов и аналитиков)
- Надёжность и SLA 99,99% по доступности сервиса, что соответствует требованиям промышленных решений
- Высокая скорость обработки данных за счет инновационной архитектуры и специально разработанных версий программного обеспечения
- Облачный Hadoop-сервис успешно сосуществует с уже имеющимися on-premise Hadoop-кластерами и другими системами
- Клиенту не нужно беспокоиться о “железе”, администрировании Hadoop, обновлении компонентов – эти задачи берёт на себя провайдер
- SAP Big Data Service предлагает своим клиентам сервис по поддержке, сравнимый с широко известным сервисом премиальной поддержки SAP Max Attention. Клиент может обратиться за помощью к команде профессионалов по различным вопросам и в том числе за рекомендациями по производительности расчетов и тп.
В следующем материале мы подробнее расскажем о планах по развитию SAP Cloud Platform Big Data Service: про интеграцию с другими сервисами и решениями SAP, про новые функции и приложения и т.д.
Если вы дочитали этот материал до конца и хотите самостоятельно протестировать на практике работу с SAP Cloud Platform Big Data Services, напишите нам, чтобы получить бесплатный тестовый доступ к сервису.
Yo1
все здорово, но где такое кроме как в сша юридически прокатает? что Россия, что ЕС запрещают обрабатывать персональные данные на стороне.
SAP Автор
Производственные, промышленные предприятия по большей части используют обезличенные данные — об инфраструктуре, производственных процессов. Поэтому разработчики, которые хотят протестировать сервис на данном типе данных, могут смело пользоваться им.
Пока что Big Data Service установлен в двух дата-центрах в Германии и США. Если в России будет интерес к работе с этим решением с использованием персональных данных, он появится и в нашем сегменте SAP Cloud Platform — в центрах обработки данных, расположенных на территории РФ.