

Начало истории вы можете вспомнить в первой статье, я же кратко напомню, что происходит.
Все началось с перевода монолитных приложений на микросервисы, когда налаженный процесс накатки новых релизов на тестовую среду начал сбоить из-за резко возросшей «детализации». Чтобы разработчики не ссорились из-за общих тестовых стендов и все работало быстро и гладко, мы запустили проект автоматизации.
Из-за управленческих сложностей проект показал результаты не сразу, поэтому предлагаю вашему вниманию продолжение истории.
Чем плохи схемы с ручным управлением
До недавнего времени в компании было несколько старых монолитных тестовых сред, каждая из которых содержит компоненты фронтэнда/бэкэнда/биллинга, и нужны они для разработки приложений и для интеграционных тестов. Тестовый стенд – это группа хостов с определенным набором приложений. Внутри мы называем их тестовыми схемами. Всего было несколько общих тестовых схем: интеграционная, нагрузочная и т.п, не соответствующих своей архитектурой продакшену.
То есть каждое приложение не всегда находилось в собственном контейнере, на тестовой схеме нельзя было протестировать конфигурацию nginx.
Нужно было установить и настроить будущий релиз для тестов, а после этого в отдельной таблице указать, какие хосты и для чего ты используешь, чтобы не было конфликтов. Во всем этом был следующий ряд проблем:
- Файл с занятыми хостами велся вручную и во многом зависел от человеческого фактора.
- На одной и той же тестовой схеме часто тестировалось одно и то же приложение, но с разными функциями. Причем каждая из них накладывала свои ограничения на конфигурацию и зависимые приложения. Разумеется, настройка и развертывание подобных конфигураций делались вручную и тоже зависели от человеческого фактора – точечная автоматизация была, но была скорее личной инициативой отдельных людей.
- Конфигурация тестовой среды и допустимые в ней взаимодействия компонент не соответствовали продакшену. То есть нельзя было в полной мере проверить работоспособность новой сборки приложения в реальных условиях.
- Самой большой проблемой был перенос настроек со старой схемы на новую. У каждого приложения свои настройки и привязки к БД, поэтому при ручном переносе что-то могло потеряться.
Около года назад в компании начался бурный рост команд, а количество тестовых схем не менялось – только увеличивалось количество ресурсов, требуемых для их сопровождения. То есть объем ручных операций и связанных с этим проблем росли экспоненциально и в какой-то момент стали серьезно тормозить процесс тестирования, а значит, и разработки.
Подводные камни автоматизации
В первую очередь решили исключить конфликты версий приложений в рамках одной схемы, а также гарантировать правильную доставку обратных вызовов, чтобы ответ одной компоненты пришел на какой-то определенный сервер, а не на тот, который был выбран ранее другим разработчиком. Лучшим решением было бы предоставить каждому разработчику собственную изолированную среду.
Эксплуатация поддерживает только одну эталонную схему, максимально повторяющую продакшен. Что касается других решаемых проблем, то для них появился следующий список требований к новым тестовым схемам:
- схема содержит набор заранее настроенных приложений, некоторые из которых настраиваются по желанию разработчика или исключаются из схемы;
- синхронизация версий приложений с «боевыми»;
- возможность обновлять или запрещать обновление приложения на схеме. Это для ситуаций, когда в тестовой среде нужны версии приложений, отличные от «боевых»;
- синхронизация данных некоторых БД с «боевыми»;
- клонирование БД с данными в процессе создания схемы;
- сбор логов, метрик с каждой схемы. Кроме того, нужно обеспечить доставку сервисных e-mail, SMS и Push-уведомлений на мобильные в каждой схеме;
- возможность получения доступа к определенным схемам со стороны внешних партнеров для взаимной отладки;
- внутри схемы должны поддерживаться компоненты на Windows/IIS/Microsoft SQL (BI). Тут надо пояснить, что в силу разных причин (включая исторические), аналитические инструменты у нас на .Net-стеке, а остальное – на Java.
При выборе решения основным ограничением было отсутствие автоматического развертывания приложений – пакет с приложением просто переносили через сетевую папку в тестовую среду. То есть перед тестовыми схемами нужно было выстроить систему автоматического развертывания либо смириться с тем, что первое время при создании новых схем происходит клонирование приложений с эталонной схемы (в основном Windows компоненты).
Как альтернатива – развертывание продакшен-версии приложения скриптами эксплуатации. Главным неудобством такого решения является то, что для получения новых версий компонент в схеме ее нужно пересоздать либо продумывать механизм обновлений и постоянной поддержки таких скриптов в отрыве от приложений.
Кстати, про долгий путь к автоматизации сборок и развертывания у нас есть отдельная статья, но там в основном рассказано про сборку.
Минимизировать изменение настроек при создании схемы можно в случае неизменности имен хостов, к которым идут вызовы. Таким образом, если эталонная схема будет настроена на взаимодействие, например по коротким именам, то при ее клонировании в новую схему настройки менять не нужно. Требуется только поднять отдельный DNS-сервер для новой схемы.
Таким образом, если опустить долгий и мучительный выбор, самым быстрым для нас решением оказалась связка из Openstack с приватными сетями для каждой схемы и Ansible в качестве средства развертывания.
Итоговое решение
Итоговое решение строится на Openstack + CEPH, в котором для каждого приложения выделена собственная VM. Для каждой тестовой схемы создается отдельный проект в Openstack и выделяется собственная приватная сеть, к которой подключаются машины с относящимися к схеме приложениями. А над всем этим стоит набор билдов Jenkins, который и выполняет все сервисные операции через Pipeline и Ansible: создание и удаление схем, подсхем, деплой приложений, периодические задачи по синхронизации БД.
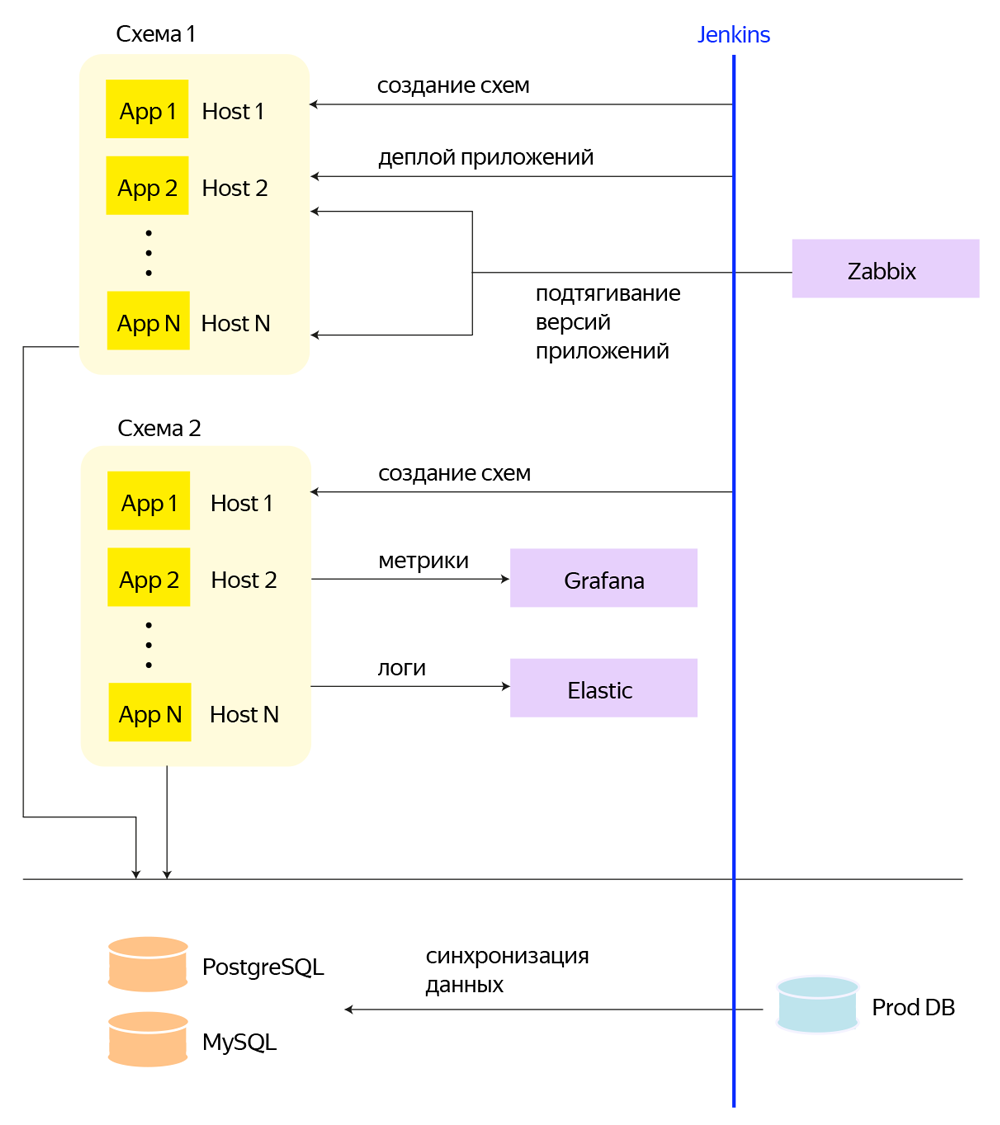
Вертикальная ось – это Jenkins, через который происходит создание схем, деплой приложений, создание БД и другие процессы.
Для визуализации всех процессов с тестовыми схемами используем Jenkins Pipeline и Blue Ocean, получается наглядная картина всех шагов, и легко увидеть сломаный этап. Большинство процессов у нас сделаны идемпотентными, и в случае ошибки достаточно просто перезапустить билд.
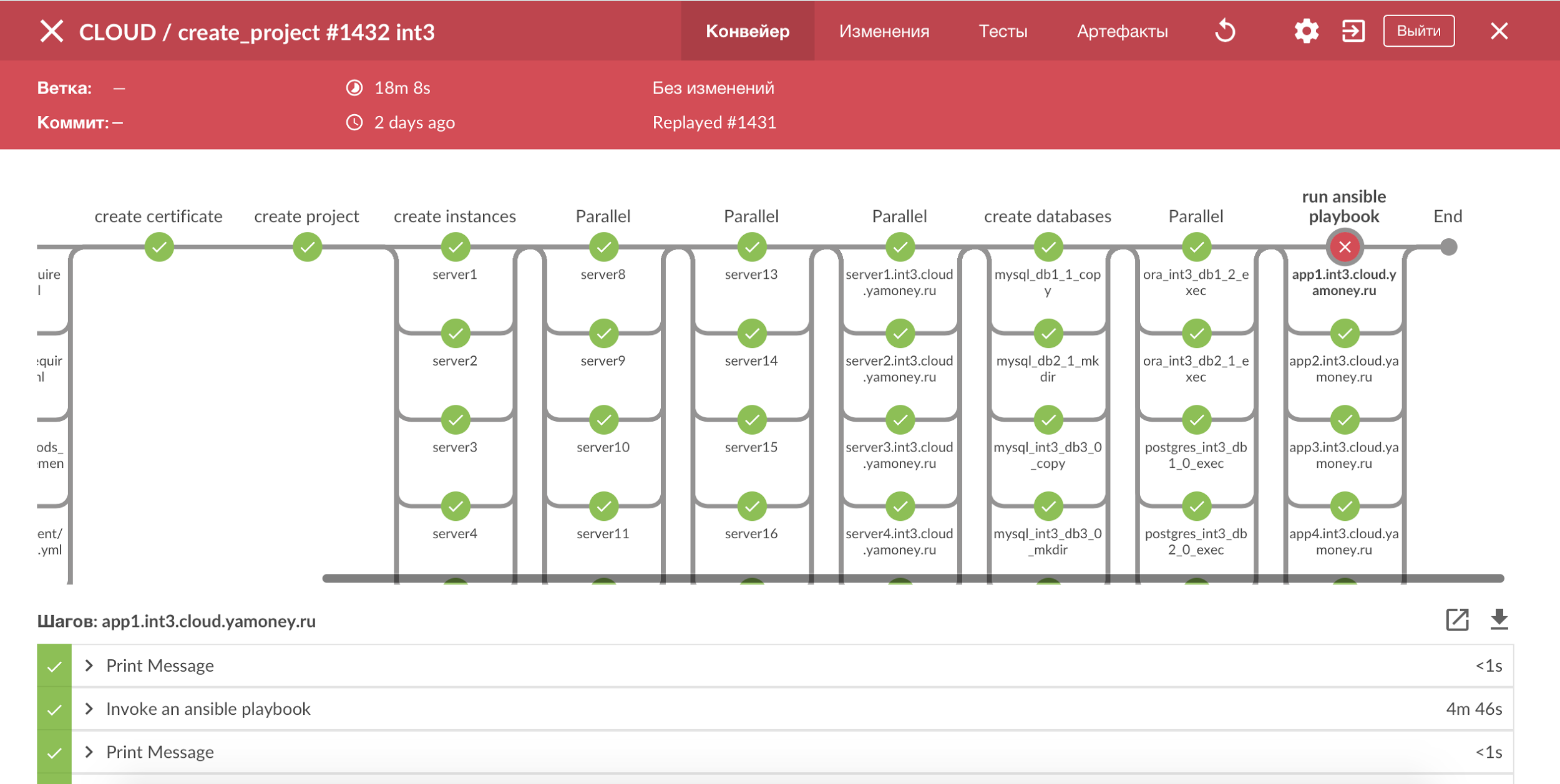
Визуализация процессов с помощью Jenkins Pipeline.
Все базы данных мы постарались вынести на отдельные физические машины, чтобы не создавать лишнюю дисковую нагрузку, оставив в тестовых схемах фактически сервера приложений, а все инстансы, которые еще не умеют автоматически деплоиться, мы клонируем. Инстансы с приложениями, которые представляют собой БД и не вынесены на отдельные физические машины, мы создаем на отдельном ssd пуле CEPH.
К слову о цифрах: ближе к завершению проекта одна средняя схема включала более 60 инстансов, которые используют около 180 ГБ памяти и 600 ГБ дискового пространства.
А я, наверное, отвечу:
- Во-первых, потому что у нас нет его в инфраструктуре – то есть пришлось бы разворачивать специально под этот проект, в том числе и на продакшене. С OpenStack можно практически полностью повторить боевую среду в тестовом сегменте.
- Во-вторых, у каждого приложения есть своя обвязка из Heka, Zabbix, HAproxy, Pgbouncer, необходимых для мониторинга и логов, балансировки трафика и переключения БД. То есть схема на Docker потребовала бы значительно больше рефакторинга имеющейся архитектуры.
- В-третьих, в Яндекс.Деньгах высокие требования к аптайму сервиса, а оценка совокупного уровня доступности Docker (с учетом необходимости его внедрения в боевой среде) и всех строящихся вокруг него сервисов потребовала бы отдельного изучения и массы времени.
- Но мы смотрим в сторону контейнеризации для изоляции сервисов на боевых системах и легковесной замены тяжелых виртуалок на тестовых средах. Изначально строилось максимально простое решение «одна компонента – одна виртуалка», с прицелом на дальнейший перенос в контейнеры. Внедрять параллельно контейнеры казалось слишком рискованным мероприятием.
Чтобы обеспечить применимость существующих ansible ролей и плейбуков для тестовых схем без каких-либо изменений, используется скрипт генерации динамического inventory, который по имени схемы, совпадающей с именем проекта в OpenStack, создает Inventrory такого же вида, как на продакшне. Вся необходимая информация для динамического inventory содержится в метаданных инстансов в OpenStack.
Что касается приложений, то мы перевели значительную часть своих компонент на деплой через ansible: приложение упаковывается в deb пакет вместе с шаблонами конфигов и значениями переменных для разных сред, а универсальный Ansible плейбук умеет шаблонизировать конфиги, переключать симлинки между разными версиями и проверять поднятие приложения. Таким образом, количество компонент, которые мы должны предварительно клонировать с эталонной схемы при создании новой, резко сократилось.
На самом деле, еще не все компоненты перевели на новый деплой – проект как раз к моменту написания статьи находится в стадии «переводим, что осталось».
Еще важной особенностью был процесс поддержания всех тестовых схем в актуальном состоянии, для этого мы реализовали подтягивание продакшн версий из нашего мониторинга и запуск обновления по ночам либо по требованию. При этом если на схеме стоит не продакшн версия приложения, а сборка из фича-ветки, то такая компонента автоматически исключается из ночного обновления.
А как же процессинг
Так как большинство приложений в тестовых схемах так или иначе участвует в процессе оплаты, то для него автоматически генерируется пул тестовых банковских карт. Создание карт, авторизации по ним и клиринг выполняются в модуле процессинга, который стоит отдельно от тестовых схем и общий для всех платежных компонентов. Несмотря на то, что процессинг специальный тестовый, ответ он может отправлять только на какой-то определенный сервер.
То есть у нас есть множество схем и сервер процессинга, который ничего не хочет знать про это множество. Кроме того, в тестовых схемах новые диапазоны карт добавляются динамически. В качестве логичного решения проблемы можно было бы просто клонировать процессинг для каждой схемы, но это повлекло бы чрезмерное увеличение ресурсов, а также автоматизацию настроек процессинга в каждой схеме. В общем, не похоже на оптимальный путь.
Чтобы существенно не допиливать имеющийся процессинг, мы решили поправить создающую карты компоненту в тестовой схеме и установить сервер nginx с модулем lua для проксирования запросов авторизаций от процессинга. После добавления диапазона карт в схему запускается процесс создания карт в процессинге, в результате которого для каждой карты в служебном поле добавляется имя выпустившей ее схемы.
Все обратные запросы от процессинга к тестовым схемам попадают на сервер с nginx, где скрипт lua ищет в теле запроса имя схемы и правильно проксирует запрос.
И вот прошел почти год с прошлой статьи про эту историю...
Как Дима писал еще в первой части нашего романа про тестовые среды, когда с системой работает несколько подразделений – проекты имеют свойство затягиваться.
Но все же некая финишная черта уже видна, и можно подвести итоги того, что удалось решить:
- Чтобы обновить приложения, которые разворачиваются клонированием инстансов, нужно было пересоздавать схему целиком. По итогам проекта проблема пока сохраняется, так как решить ее можно будет тогда, когда все наши компоненты будут переведены на стандартный процесс деплоя – в процессе.
- Высокая дисковая нагрузка от некоторых приложений и локальной записи логов снизилась до допустимых величин благодаря переходу на SSD диски и отдельные пулы в CEPH для таких инстансов.
- Сложно эффективно использовать оперативную память при работе с виртуальными машинами, так как память расходуется в том числе и на операционную систему внутри машины.
- С внедрением новой инфраструктуры OpenStack/CEPH потребовались дополнительные трудозатраты на тестирование новых версий, поиск и исправления багов и т.п. В общем, все, что сопутствует любому новому в инфраструктуре продукту.
- По итогам проекта запись логов приложений на нескольких тысячах инстансов создает заметную нагрузку на CEPH, поэтому думаем в направлении отказа от локальной записи логов.
На текущий момент мы уже сделали автообновление большинства компонентов на всех тестовых схемах до их продакшн версий и начали проект по созданию тестовых схем с выборочным набором компонент для экономии ресурсов. Теперь в планах использование контейнеров LXC в OpenStack.
А вообще, вся эта техника – только вершина айсберга. Самая боль – это уговорить разработку и тестировщиков перейти на новые схемы (наладить новые процессы). Как раз пошел второй квартал, как мы продолжаем потихоньку, по шажочку мигрировать со старых схем на новые.