
По закону Мерфи, если есть более одного проекта на выбор — я возьмусь за самый сложный из предложенных. Так случилось и с последним заданием курса о системах управления базами данных (СУБД).

Постановка задачи
Согласно ТЗ, требовалось создать СУБД с нуля на Vanilla Python 3.6 (без сторонних библиотек). Конечный продукт должен обладать следующими свойствами:
- хранит базу в бинарном формате в едином файле
- DDL: поддерживает три типа данных: Integer, Float и Varchar(N). Для упрощения, все они фиксированной длины.
- DML: поддерживает базовые SQL операции:
- INSERT
- UPDATE
- DELETE
- SELECT с WHERE и JOIN. С каким именно JOIN — указано не было, поэтому на всякий случай мы сделали и CROSS, и INNER
- выдерживает 100'000 записей
Подход к проектированию
Разработать СУБД с нуля казалось нетривиальной задачей (как ни странно, так оно и оказалось). Поэтому мы — ecat3 и @ratijas — подошли к этому делу научно. В команде нас только двое (не считая себя и мою персону), а значит распиливать задачи и координировать их выполнение в разы легче, чем, собственно, их выполнять. По окончании распила вышло следующе:
| Задача | Исполнитель(-и) |
|---|---|
| Парсер + AST + REPL | ratijas, написавший не один калькулятор на всяких lex/yacc |
| Структура файла базы | ecat3, съевший собаку на файловых системах |
| Движок (низкоуровневые операции над базой) |
ecat3 |
| Интерфейс (высокоуровневая склейка) |
Вместе |
Изначально времени было выделено две недели, поэтому предполагалось выполнить индивидуальные задачи за неделю, а оставшееся время совместно уделить склейке и тестированию.
С формальной частью закончили, перейдем к практической. СУБД должна быть современной и актуальной. В современном Иннополисе актуальным является месседжер Телеграм, чат-боты и общение в группах с помощью "/слештегов" (это как #хештеги, только начинаются со /слеша). Поэтому язык запросов, близко напоминающий SQL, мало того что не чувствителен к регистру, так ещё и не чувствителен к /слешу непосредственно перед любым идентификатором: 'SELECT' и '/select' это абсолютно одно и то же. Кроме того, подобно всякому студенту университета, каждая команда (statement) языка должна завершаться '/drop'. (Конечно же, тоже независимо от регистра. Кого вообще в такой ситуации волнует какой-то там регистр?)
Так родилась идея названия: dropSQL. Собственно /drop'ом называется отчисление студента из университета; по некоторым причинам, это слово получило широкое распространение у нас в Иннополисе. (Ещё один местный феномен: аутизм, или, более корректно, /autism. Но мы приберегли его на особый случай.)
Первым делом разложили грамматику dropSQL на BNF (и зря — левые рекурсии не подходят нисходящим парсерам).
/stmt
: /create_stmt
| /drop_stmt
| /insert_stmt
| /update_stmt
| /delete_stmt
| /select_stmt
;
/create_stmt
: "/create" "table" existence /table_name "(" /columns_def ")" "/drop"
;
existence
: /* empty */
| "if" "not" "exists"
;
/table_name
: /identifier
;
/columns_def
: /column_def
| /columns_def "," /column_def
;
/column_def
: /column_name type /primary_key
;
...
/create table t(a integer, b float, c varchar(42)) /drop
/insert into t (a, c, b) values (42, 'morty', 13.37), (?1, ?2, ?3) /drop
/select *, a, 2 * b, c /as d from t Alias /where (a < 100) /and (c /= '') /drop
/update t set c = 'rick', a = a + 1 /drop
/delete from t where c > 'r' /drop
/drop table if exists t /drop
Работаем на результат! Никаких исключений!
После нескольких месяцев с Rust в качестве основного языка, крайне не хотелось снова погрязнуть в обработке исключений. Очевидным аргументом против исключений является то, что разбрасываться ими дорого, а ловить — громоздко. Ситуация ухудшается тем, что Python даже в версии 3.6 с Type Annotations, в отличие от той же Java, не позволяет указать типы исключений, которые могут вылететь из метода. Иначе говоря: глядя на сигнатуру метода, должно стать ясно, чего от него ожидать. Так почему бы не объеденить эти типы под одной крышей, которая называется «enum Error»? А над этим создать ещё одну «крышу» под названием Result; о нём пойдёт речь чуть ниже. Конечно, в стандартной библиотеке есть места, которые могут «взорваться»; но такие вызовы в нашем коде надежно обложены try'ями со всех сторон, которые сводят любое исключение к возврату ошибки, минимизируя возникновение внештатных ситуаций во время исполнения.
Итак, было решено навелосипедить алгебраический тип результата (привет, Rust). В питоне с алгебраическими типами всё плохо; а модуль стандартной библиотеки enum больше напоминает чистую сишечку.
В худших традициях ООП, используем наследование для определения конструкторов результата: Ok и Err. И не забываем про статическую типизацию (Ну мааам, у меня уже третья версия! Можно у меня будет наконец статическая типизация в Python, ну пожаалуйста?):
import abc
from typing import *
class Result(Generic[T, E], metaclass=abc.ABCMeta):
"""
enum Result< T > {
Ok(T),
Err(E),
}
"""
# Сборище абстрактных методов и просто дефолтных значений
def is_ok(self) -> bool:
return False
def is_err(self) -> bool:
return False
def ok(self) -> T:
raise NotImplementedError
def err(self) -> E:
raise NotImplementedError
...
class Ok(Generic[T, E], Result[T, E]):
def __init__(self, ok: T) -> None:
self._ok = ok
def is_ok(self) -> bool:
return True
def ok(self) -> T:
return self._ok
...
class Err(Generic[T, E], Result[T, E]):
def __init__(self, error: E) -> None:
self._err = error
def is_err(self) -> bool:
return True
def err(self) -> E:
return self._err
...
Отлично! Приправим немного соусом из функциональных преобразований. Далеко не все понадобятся, так что возьмем необходимый минимум.
class Result(Generic[T, E], metaclass=abc.ABCMeta):
...
def ok_or(self, default: T) -> T:
...
def err_or(self, default: E) -> E:
...
def map(self, f: Callable[[T], U]) -> 'Result[U, E]':
# Ух-ты! Что это за одинарные кавычки тут у нас в типе возврата?
# Оказывается, так в Python делается своего рода "forward declaration".
# Даже называется немного по-другому. Почитать можно в PEP 484:
# https://www.python.org/dev/peps/pep-0484/#forward-references
...
def and_then(self, f: Callable[[T], 'Result[U, E]']) -> 'Result[U, E]':
...
def __bool__(self) -> bool:
# упрощает проверку через `if`
return self.is_ok()
И сразу пример использования:
def try_int(x: str) -> Result[int, str]:
try:
return Ok(int(x))
except ValueError as e:
return Err(str(e))
def fn(arg: str) -> None:
r = try_int(arg) # 'r' for 'Result'
if not r: return print(r.err()) # one-liner, shortcut for `if r.is_err()`
index = r.ok()
print(index) # do something with index
Писанина в таком стиле всё ещё занимает по 3 строчки на каждый вызов. Но зато приходит четкое понимание, где какие ошибки могли возникнуть, и что с ними произойдет. Плюс, код продолжается на том же уровне вложенности; это весьма важное качество, если метод содержит полдюжины однородных вызовов.
Парсер, IResult, Error::{Empty, Incomplete, Syntax}, REPL, 9600 бод и все-все-все
Парсер занял значительную часть времени разработки. Грамотно составленный парсер должен обеспечить пользователю удобство использования фронтэнда продукта. Важнейшими задачами парсера являются:
- Внятные репорты об ошибках
- Интерактивный инкрементальный построчный ввод, или, проще говоря, REPL
Располагая «не только лишь всей» стандартной библиотекой питона, но и своими скромными познаниями в написании парсеров, мы понимали, что придется закатать рукава, и наваять ручной рекурсивный нисходящий парсер (англ. Recursive descent parser). Дело это долгое, муторное, зато даёт высокий градус контроля над ситуацией.
Один из первых вопросов, требовавших ответа: как быть с ошибками? Как быть — выше уже разобрались. Но что вообще представляет собой ошибка? Например, после "/create table" может находиться «if not exists», а может и не находиться — ошибка ли это? Если да, то какого рода? где должна быть обработана? («Поставьте на паузу», и предложите свои варианты в комментариях.)
Первая версия парсера различала два вида ошибок: Expected (ожидали одно, а получили что-то другое) и EOF (конец файла) как подкласс предыдущего. Всё бы ничего, пока дело не дошло до REPL. Такой парсер не различает между частиным вводом (началом команды) и отсутствием чего-либо (EOF, если так можно сказать про интерактивный ввод с терминала). Только неделю спустя, методом проб и ошибок удалось найти схему, удовлетворяющую нашей доменной области.
Схема состоит в том, что всё есть поток, а парсер — лишь скромный метод next() у потока. А также в том, что класс ошибки должен быть переписан на алгебраический (подобно Result), и вместо EOF введены варианты Empty и Incomplete.

class Error(metaclass=abc.ABCMeta):
"""
enum Error {
Empty,
Incomplete,
Syntax { expected: str, got: str },
}
"""
def empty_to_incomplete(self) -> 'Error':
if isinstance(self, Empty):
return Incomplete()
else:
return self
class Empty(Error): ...
class Incomplete(Error): ...
class Syntax(Error):
def __init__(self, expected: str, got: str) -> None: ...
# stream-specific result type alias
IResult = Result[T, Error]
IOk = Ok[T, Error]
IErr = Err[T, Error]
class Stream(Generic[T], metaclass=abc.ABCMeta):
def current(self) -> IResult[T]: ...
def next(self) -> IResult[T]: ...
def collect(self) -> IResult[List[T]]: ...
def peek(self) -> IResult[T]: ...
def back(self, n: int = 1) -> None: ...
@abc.abstractmethod
def next_impl(self) -> IResult[T]: ...
Поток — это абстракция. Потоку всё-равно, какие элементы производить. Поток знает, когда остановиться. Всё, что требуется для реализации своего потока — переписать единственный абстрактный метод next_impl() -> IResult[T]. Что должен вернуть этот метод? Рассмотрим на примере потока токенов:
| Что там дальше | Пример (ввод) | Тип результата | Пример (результат) |
|---|---|---|---|
| Всё нормально, очередной элемент | /delete from t ... |
IOk(token) | IOk(Delete()) |
| Остались одни пробелы и комментарии | \n -- wubba -- lubba -- dub dub! |
IErr(Empty()) | IErr(Empty()) |
| Начало чего-то большего | 'string...(нет закрывающей кавычки) |
IErr(Incomplete()) | IErr(Incomplete()) |
| Ты втираешь мне какую-то дичь | #$% |
IErr(Syntax(...)) | IErr(Syntax(expected='token', got='#')) |
Потоки организованы в иерархию. Каждый уровень содержит свой буфер, что позволяет заглядывать вперёд (peek() -> IResult[T]) и откатываться назад (back(n: int = 1) -> None) при необходимости.
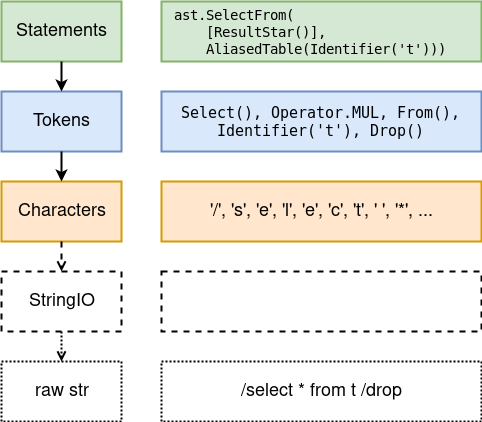
А самое приятное, что поток можно "собрать" в один большой список всех IOk(элементов), что выдает next() — до первой IErr(), разумеется. При чем список вернется лишь когда IErr содержала Empty; в противном случае, ошибка пробросится выше. Эта конструкция позволяет легко и элегантно построить REPL.
class Repl:
def reset(self):
self.buffer = ''
self.PS = self.PS1
def start(self):
self.reset()
while True:
self.buffer += input(self.PS)
self.buffer += '\n'
stmts = Statements.from_str(self.buffer).collect()
if stmts.is_ok():
... # execute one-by-one
self.reset()
elif stmts.err().is_incomplete():
self.PS = self.PS2 # read more
elif stmts.err().is_syntax():
print(stmts.err())
self.reset()
else: pass # ignore Err(Empty())
Characters
Этот поток проходит по символам строки. Единственный тип ошибки: Empty в конце строки.
Tokens
Поток токенов. Его второе имя — Лексер. Тут встречаются и ошибки, и строки без закрывающих кавычек, и всякое…
Каждый тип токенов, включая каждое ключевое слово по отдельности, представлен отдельным классом-вариантом абстрактного класса Token (или лучше думать про него как про enum Token?) Это для того, чтобы парсеру команд (statements) было удобно кастовать токены к конкретным типам.
def next_impl(self, ...) -> IResult[Token]:
...
char = self.characters.current().ok()
if char == ',':
self.characters.next()
return IOk(Comma())
elif char == '(':
self.characters.next()
return IOk(LParen())
elif ...
Statements
Кульминация, парсер собственной персоной. Вместо тысячи слов, пару сниппетов:
class Statements(Stream[AstStmt]):
def __init__(self, tokens: Stream[Token]) -> None:
super().__init__()
self.tokens = tokens
@classmethod
def from_str(cls, source: str) -> 'Statements':
return Statements(Tokens.from_str(source))
def next_impl(self) -> IResult[AstStmt]:
t = self.tokens.peek()
if not t: return Err(t.err())
tok = t.ok()
if isinstance(tok, Create):
return CreateTable.from_sql(self.tokens)
if isinstance(tok, Drop):
return DropTable.from_sql(self.tokens)
if isinstance(tok, Insert):
return InsertInto.from_sql(self.tokens)
if isinstance(tok, Delete):
return DeleteFrom.from_sql(self.tokens)
if isinstance(tok, Update):
return UpdateSet.from_sql(self.tokens)
if isinstance(tok, Select):
return SelectFrom.from_sql(self.tokens)
return Err(Syntax('/create, /drop, /insert, /delete, /update or /select', str(tok)))
class DeleteFrom(AstStmt):
def __init__(self, table: Identifier, where: Optional[Expression]) -> None:
super().__init__()
self.table = table
self.where = where
@classmethod
def from_sql(cls, tokens: Stream[Token]) -> IResult['DeleteFrom']:
"""
/delete_stmt
: "/delete" "from" /table_name /where_clause /drop
;
"""
# next item must be the "/delete" token
t = tokens.next().and_then(Cast(Delete))
if not t: return IErr(t.err())
t = tokens.next().and_then(Cast(From))
if not t: return IErr(t.err().empty_to_incomplete())
t = tokens.next().and_then(Cast(Identifier))
if not t: return IErr(t.err().empty_to_incomplete())
table = t.ok()
t = WhereFromSQL.from_sql(tokens)
if not t: return IErr(t.err().empty_to_incomplete())
where = t.ok()
t = tokens.next().and_then(Cast(Drop))
if not t: return IErr(t.err().empty_to_incomplete())
return IOk(DeleteFrom(table, where))
Важно отметить, что любые ошибки типа Empty, кроме самого первого, парсеры должны преобразовывать в Incomplete, для корректной работы REPL. Для этого есть вспомагательная функция empty_to_incomplete() -> Error. Чего нет, и никогда не будет, так это макросов: строка if not t: return IErr(t.err().empty_to_incomplete()) встречается в кодовой базе по меньшей мере 50 раз, и тут ничего не попишешь. Серъёзно, в какой-то момент захотелось юзать Сишный препроцессор.
Про бинарный формат
Глобально файл базы поделен на блоки, и размер файла кратен размеру блока. Размер блока по умолчанию равен 12 КиБ, но опционально может быть увеличен до 18, 24 или 36 КиБ. Если Вы дата сатанист на магистратуре, и у вас очень большие данные — можно поднять даже до 42 КиБ.
Блоки пронумерованы с нуля. Нулевой блок содержит метаданные обо всей базе. За ним 16 блоков под метаданные таблиц. С блока #17 начинаются блоки с данными. Указателем на блок называется порядковый номер блока
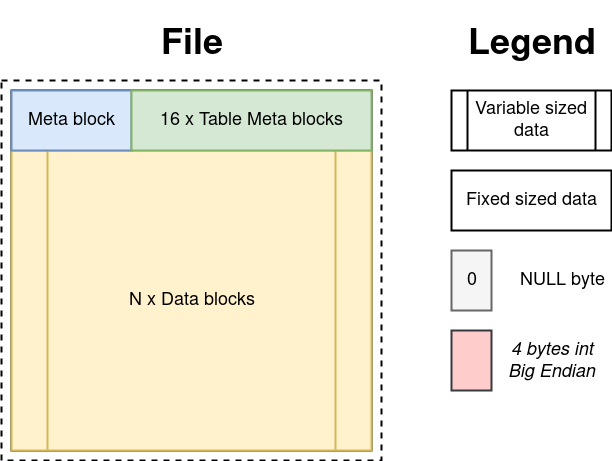
Метаданных базы на текущий момент не так много: название длиной до 256 байт и кол-во блоков с данными.
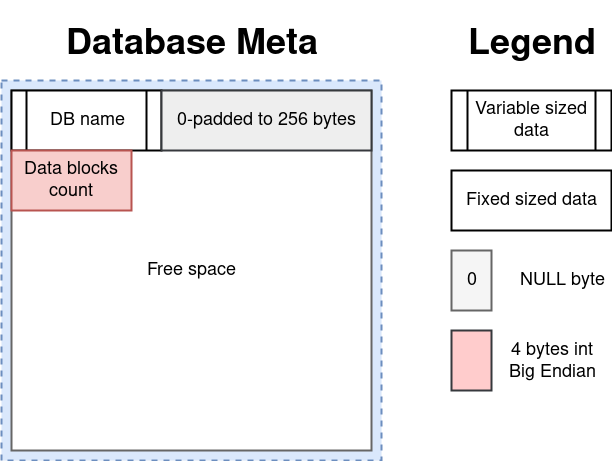
Мета-блок таблицы самый непростой. Тут хранится название таблицы, список всех колонок с их типами, количество записей и указатели на блоки данных.
Количество таблиц фиксировано в коде. Хотя это относительно легко может быть исправлено, если хранить указатели на мета-блоки таблиц в мета-блоке базы.
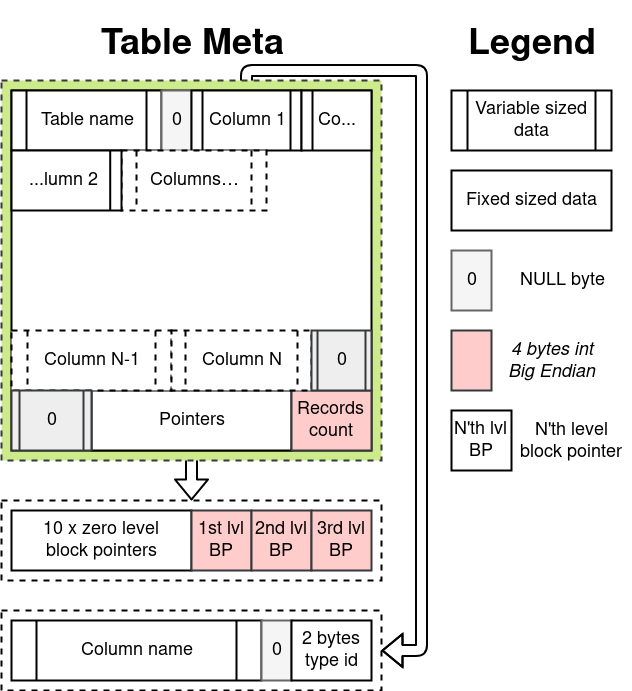
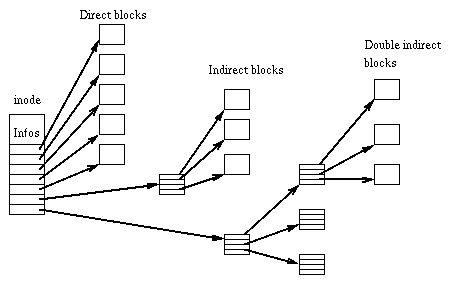
Указатели на блоки работают по принципу указателей в inode. Об этом прекрасно писал Таненбаум и дюжины других уважаемых людей. Таким образом, таблицы видят свои блоки с данными как «страницы». Разница в том, что страницы, идущие с точки зрения таблицы по порядку, физически располагаются в файле как бог на душу положит. Проводя аналогии с virtual memory в операционках, страница: virtual page number, блок: physical page number.
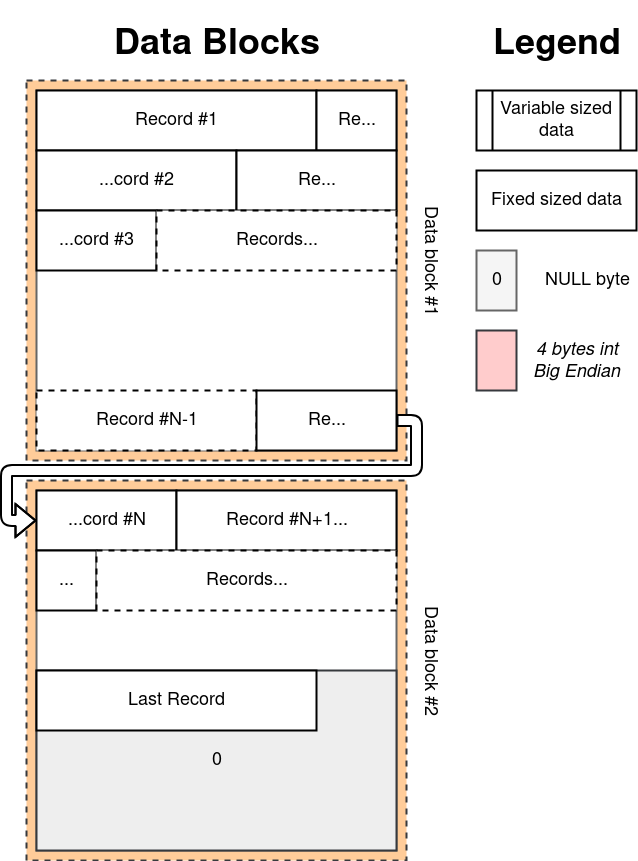
Блоки данных не имеют конкретной структуры сами по себе. Но когда их объеденить в порядке, продиктованном указателями, они предстанут непрерывным потоком записей (record / tuple) фиксированной длины. Таким образом, зная порядковый номер записи, извлечь или записать её — операция практически константного времени, O(1*), с амортизацией на выделение новых блоков при необходимости.
Первый байт записи содержит информацию о том, жива ли эта запись, или была удалена. Остальные работу по упаковке и распаковке данных берет на себя стандартный модуль struct.
Операция /update всегда делает перезапись «in-place», а /delete только подменяет первый байт. Операция VACUUM не поддерживается.
Про операции над таблицами, RowSet и джойны
Пришло время прочно скрепить лучшее из двух миров несколькими мотками скотча.
MC слева — AST узлы верхнего уровня (подклассы AstStmt). Их выполнение происходит в контексте соединения с базой. Также поддерживаются позиционные аргументы — "?N" токены в выражениях в теле запроса, например: "/delete from student /where name = ?1 /drop". Сами выражения рекурсивны, а их вычисление не представляет собой научного прорыва.
MC справа — драйвер БД, оперирующий над записями по одной за раз, используя порядковый номер внутри таблицы как идентификатор. Только он знает, какие таблицы существуют, и как с ними работать.
Поехали!
Их первый совместный сингл про креативность. Создать новую таблицу не сложнее, чем взять первый попавшийся пустой дескриптор из 16, и вписать туда название и список колонок.
Затем, трек с символическим названием /drop. В домашней версии демо-записи происходит следующее: 1) найти дескриптор таблицы по имени; 2) обнулить. Кого волнуют неосвобожденные блоки со страницами данных?
Insert снисходителен к нарушению порядка колонок, поэтому перед отправкой кортежа на запись, его пропускают через специальный фильтр transition_vector.
Далее речь пойдет про работу с записями таблиц, поэтому позвольте сразу представить нашего рефери: RowSet.
class RowSet(metaclass=abc.ABCMeta):
@abc.abstractmethod
def columns(self) -> List[Column]:
"""
Describe columns in this row set.
"""
@abc.abstractmethod
def iter(self) -> Iterator['Row']:
"""
Return a generator which yields rows from the underlying row stream or a table.
"""
Главный конкретный подвид этого зверя — TableRowSet — занимается выборкой всех живых (не удаленных) записей по порядку. Прочие разновидности RowSet в dropSQL реализуют необходимый минимум реляционной алгебры.
| Оператор реляционной алгебры | Обозначение | Класс |
|---|---|---|
| Проекция | ?(ID, NAME) expr | ProjectionRowSet |
| Переименование | ?a/b expr | ProjectionRowSet + RenameTableRowSet |
| Выборка | ?(PRICE>90) expr | FilteredRowSet |
| Декартово произведение | PRODUCTS ? SELLERS | CrossJoinRowSet |
| Inner Join (назовём это расширением) |
?(cond)( A x B ) | InnerJoinRowSet =
FilteredRowSet(
CrossJoinRowSet(...)) |
Кроме того ещё есть программируемый MockRowSet. Он хорош для тестирования. Также, с его помощью возможен доступ к мастер-таблице под названием "/autism".
Прелесть в том, что различные RowSet'ы можно комбинировать как угодно: выбрать таблицу «student», указать алиас «S», отфильтровать «/where scholarship > '12k'», выбрать другую таблицу «courses», соединить «/on (course/sid = S/id) /and (course/grade < 'B')», проецировать на «S/id, S/first_name/as/name» — это представляется следующей иерархией:
ProjectionRowSet([S/id, S/first_name/as/name])
FilteredRowSet((course/sid = S/id) /and (course/grade < 'B'))
CrossJoinRowSet
FilteredRowSet(scholarship > '12k')
RenameTableRowSet('S')
TableRowSet('student')
TableRowSet('courses')
Итак, вооружившись столь мощным инструментом, возвращаемся к лютневой музыке XVI века…
Про четвертый трек, /select, тут больше нечего добавить. Симфония из RowSet'ов такая, что душу завораживает. Благодаря этому, реализация получилась крайне лаконичной.
class SelectFrom(AstStmt):
...
def execute(self, db: 'fs.DBFile', args: ARGS_TYPE = ()) -> Result['RowSet', str]:
r = self.table.row_set(db)
if not r: return Err(r.err())
rs = r.ok()
for join in self.joins:
r = join.join(rs, db, args)
if not r: return Err(r.err())
rs = r.ok()
if self.where is not None:
rs = FilteredRowSet(rs, self.where, args)
rs = ProjectionRowSet(rs, self.columns, args)
return Ok(rs)
Два последних: /update и /delete используют наработки предшественника. При чем /update применяет технику, похожую на описанный выше «transition_vector».
Такой вот концерт! Спасибо за внимание! Занавес!..
Хотелки
Пока что не сбывшиеся мечты:
- Поддержка /primary key не только в парсере
- Унарные операторы
- Вложенные запросы
- Вывод типов для выражений
- Удобный API для Python
Так как это был учебный проект, мы не получили за него ни копейки. Хотя, судя по статистике sloc, могли бы сейчас кушать красную икорку.
Have a non-directory at the top, so creating directory top_dir
Creating filelist for dropSQL
Creating filelist for tests
Creating filelist for util
Categorizing files.
Finding a working MD5 command....
Found a working MD5 command.
Computing results.
SLOC Directory SLOC-by-Language (Sorted)
2764 dropSQL python=2764
675 tests python=675
28 util python=28
Totals grouped by language (dominant language first):
python: 3467 (100.00%)
Total Physical Source Lines of Code (SLOC) = 3,467
Development Effort Estimate, Person-Years (Person-Months) = 0.74 (8.85)
(Basic COCOMO model, Person-Months = 2.4 * (KSLOC**1.05))
Schedule Estimate, Years (Months) = 0.48 (5.73)
(Basic COCOMO model, Months = 2.5 * (person-months**0.38))
Estimated Average Number of Developers (Effort/Schedule) = 1.55
Total Estimated Cost to Develop = $ 99,677
(average salary = $56,286/year, overhead = 2.40).
SLOCCount, Copyright (C) 2001-2004 David A. Wheeler
SLOCCount is Open Source Software/Free Software, licensed under the GNU GPL.
SLOCCount comes with ABSOLUTELY NO WARRANTY, and you are welcome to
redistribute it under certain conditions as specified by the GNU GPL license;
see the documentation for details.
Please credit this data as "generated using David A. Wheeler's 'SLOCCount'."
Благодарности
- Университету Иннополис за уютное окружение и крутые знакомства.
- Профессору Евгению Зуеву за курс по компиляторам вообще, и за лекцию о парсерах в частности
- Профессору Manuel Mazzara и TA Руслану за курс по СУБД. /GodBlessMazzara
А в следующий раз мы заимплементим свою не-реляционку, с агрегейшн пайплайнами и транзакциями; и назовём её — /noDropSQL!
Комментарии (31)

mersinvald
22.01.2018 23:08Первая статья из Иннополиса, за которую я не испытываю испанский стыд :)
Мешок kudos вам, /autism

izzholtik
23.01.2018 00:21Так что со скоростью работы?

ratijas Автор
23.01.2018 00:49Ну скорость, она да. Спасибо, что есть. 10к записей в секунду делало при летной погоде. На детальные бенчмарки времени не осталось, к сожалению.
Есть много мест, которые можно оптимизировать. Например, если отдебажить доступы к блокам, можно заметить, что много излишних чтений приходится на дескрипторы таблиц, тогда как можно было бы их закешировать.izzholtik
23.01.2018 03:34Не, записи — это скучно. По выборкам как?
ratijas Автор
23.01.2018 17:05/select дает RowSet (выборку). Он ленивый (кроме MockRowSet, например, для мастер-таблицы /autism). Проходка по нему итератором достает из блоков по одной записи за раз. В памяти это никак специально не кешируется — и возможно, зря, но это уже другая история. В конце концов ещё есть кеш файла в операционной системе, и его размер равен 16 блокам.
veveve
23.01.2018 01:41Давайте аргументированно покритикую.
Очевидным аргументом против исключений является то, что разбрасываться ими дорого, а ловить — громоздко.
Как часто при типичной работе программы происходит выброс/ловля исключений?
Как много времени сэкономите, отказавшись от этого кол-ва исключений?
Ситуация ухудшается тем, что Python даже в версии 3.6 с Type Annotations, в отличие от той же Java, не позволяет указать типы исключений, которые могут вылететь из метода. Иначе говоря: глядя на сигнатуру метода, должно стать ясно, чего от него ожидать.
Добавление нового типа исключения в метод потребует изменения аннотации для всех других методов его вызывающих и далее вверх по цепочке вызовов. А вот компилятора, который будет следить, чтобы аннотированные исключения были обработаны, в Питоне нет. Так что польза от такой аннотации крайне сомнительна.
которые сводят любое исключение к возврату ошибки, минимизируя возникновение внештатных ситуаций во время исполнения.
И заодно заполоняя код бесконечными проверками возвращённых ошибок.t = tokens.next().and_then(Cast(Delete)) if not t: return IErr(t.err()) t = tokens.next().and_then(Cast(From)) if not t: return IErr(t.err().empty_to_incomplete()) t = tokens.next().and_then(Cast(Identifier)) if not t: return IErr(t.err().empty_to_incomplete()) table = t.ok() t = WhereFromSQL.from_sql(tokens) if not t: return IErr(t.err().empty_to_incomplete()) where = t.ok() t = tokens.next().and_then(Cast(Drop)) if not t: return IErr(t.err().empty_to_incomplete())mersinvald
23.01.2018 08:40Взяли бы Go
И остались бы без возможности строить красивые абстракции совершенно. Тогда уж раст, тем более что Result из него заимствовали, а возврат ошибок там не выглядит громоздко.
andewil
23.01.2018 09:19По поводу инструмента мои 5 копеек:
Выбрали тот инструмент, которым умели пользоваться. Время было ограничено (как я понял), поэтому выбор был сделан верно, поскольку изучение нового инструмента с большой вероятностью не позволило бы решить задачу в срок. Решение удовлетворяет установленным критериям.
Это не избавляет от того, что для более «серьезных» задач, ну скажем миллиард записей — это работать не будет. И нужен будет уже другой инструмент. Да, не масштабируемо — так и не требовалось.eCat3
23.01.2018 10:45+1Выбрали тот инструмент, которым умели пользоваться. Время было ограничено (как я понял), поэтому выбор был сделан верно, поскольку изучение нового инструмента с большой вероятностью не позволило бы решить задачу в срок
Инструмент был строго задан техническим заданием ( ratijas, к сожалению, не расписал это в статье). Мы в университете не мешки ворочаем, о разных инструментах знаем и пользоваться умеем. А изучение нового инструмента на ходу, по моему опыту, в университете не является проблемой.ну скажем миллиард записей
Обрабатывать будет долго, вероятно, но не развалится.

vanxant
23.01.2018 10:49Как часто при типичной работе программы происходит выброс/ловля исключений?
Вы статью читали? У них даже EOF при чтении команд идёт как ошибка. За исключение в этом месте надо расстреливать через тумба-юмбу.
anjensan
23.01.2018 17:19Я даже боюсь представить, что же надо делать за исключение при работе с каждым итератором.
Xandrmoro
23.01.2018 02:20Очень странная постановка задачи. СУБД на интерпретируемом языке? Серьёзно?
mersinvald
23.01.2018 08:42Учебная задача же, а не продукт для рынка. Задача, очевидно, была в разработке учебной СУБД для более глубокого осознания механизмов работы систем управления базами данных.

Levhav
23.01.2018 03:33А есть идеи и планы дальнейшего развития вашего проекта до чего то полезного на практике. А то тоже не раз меня посещала идея сделать свою субд правда на С++ но каждый раз я не мог найти ответа на вопросы ЗАЧЕМ и для КОГО?

kkirsanov2
23.01.2018 09:36+2Т.к. статья студенческая — выскажусь исходя из своего преподавательского опыта.
Если это квалификационная работа, когда вы показываете старшим товарищам что вы умеете, то смехуёчи и мемасики лучше опустить т.к. они раздражают. /autism
Причина раздражения очень проста — я уже всё это знаю и мне хочется быстрее выяснить что вы умеете и чему научились, а не рассматривать братуху-борцуху на мемичных картинках. По этой же причине длительное отступление про исключения совершенно излишне. Достаточно вскользь упомянуть. Если читающему\слушающему будет это интересно — он расспросит, не сомневайтесь. А то на ровном месте получили кучу вопросов про совершенно второстепенную в вашей задаче проблему.
Аналогично раздражают частые англицизмы и отсутствие единого стиля. Почему СУБД и КиБ, но AST и DDL? Очень много странных с т.з. русского языка конструкций, вроде "В команде нас только двое (не считая себя и мою персону)" и "С формальной частью закончили, перейдем к практической", ведь антагонистом практики является теория, а не формальность.
Пришлось заставлять себя читать статью, ведь буквально на первой странице:
Согласно ТЗ, требовалось создать
Очень плохое начало. Непонятно откудо взялось ТЗ — у читющих возникают вопросы https://habrahabr.ru/post/347274/#comment_10629794
https://habrahabr.ru/post/347274/#comment_10629754
выдерживает 100'000 записей
Что значит выдерживает? И подобное буквально в каждом абзаце. Я вижу что вы — молодцы и программируете (рамках курса, хе хе) на должном уровне. Но нужно тренироваться писать тексты и доносить мысль до слушателя. Это не просто.
Если же это не для квалификации, а просто рассказ коллегам о чём то новом и интересном для них то и тут масса проблем с теми же причинами.

foldr
23.01.2018 10:00Простите, но Ваша манера критики не очень уместна в публичном месте, будь Вы преподаватель или кто
Если это квалификационная работа, когда вы показываете старшим товарищам что вы умеете, то смехуёчи и мемасики лучше опустить т.к. они раздражают. /autism
И далее. Если Вы принимаете работу — тогда пожалучйста (и то не уверен). Лучше комментарии по делу
Аналогично раздражают частые англицизмы и отсутствие единого стиля. Почему СУБД и КиБ, но AST и DDL
СУБД — широко распространенное сокращение, DDL — не видел варианта на русском языке. Не вижу проблемы, т.к. это не квалификационная работа
В целом — не воспринимайте статью как реферат, иначе читать было бы невозможно
kkirsanov2
23.01.2018 10:30+1Простите, но Ваша манера критики не очень уместна в публичном месте, будь Вы преподаватель или кто
А мне нравится. Не вижу причин, почему у публичной статьи не может быть публичной критики. Я же исключительно про статью, а не про авторов которые, повторюсь, молодцы. Из текста видно что пишут студенты, причём трижды Иннополис вспоминают. И лучше я им здесь укажу на проблемы, чем на сдаче диплома член комиссии.
Может у автора спросим, что он думает про мои комментарии? А то мне кажется Вы защищаете того, кто в этом не нуждается.
DDL — не видел варианта на русском языке.
Язык описания данных, ЯОД.
Термин массово используется в русскоязычной литературе. Даже ГОСТ есть — "ГОСТ 20886-85 Организация данных в системе обработки данных. Термины и определения".
foldr
23.01.2018 10:35А мне нравится. Не вижу причин, почему у публичной статьи не может быть публичной критики.
Я про Вашу манеру, а не про критику. Критику хочется видеть конструктивную, без эмоций подобно Вашим
kkirsanov2
23.01.2018 10:41+1Вы не понимаете. Попробую объяснить другими словами.
Пишут студенты.
Студенты учатся программировать.
А ещё студенты учатся писать статьи ->
Написание статей автором подразумевает чтение статей читателем->
Читатель читая эту статью будет раздражаться ->
Я, имея опыт преподаваня и чтения статей, указываю на причины подобного раздражения ->
Студенты учатся писать более грамотные статьи ->
Я молодец
RomanArzumanyan
23.01.2018 16:20-1когда вы показываете старшим товарищам что вы умеете
Печально, когда люди начинают причислять себя к старшим товарищам.

SirEdvin
23.01.2018 11:53Иначе говоря: глядя на сигнатуру метода, должно стать ясно, чего от него ожидать.
В python это работает через doc string, в которых можно писать
raises, который можно получить напимер, так:a.c1.__doc__. Внешние либы часто грешат игнорированием этого правила, но стандартная библиотека python его отлично придерживается.
Ну и да, исключения в python не настолько дорогие.

Cubus
23.01.2018 15:58А зачем в метаданных базы поле с количеством блоков и поле Records Count в заголовках таблицы?
В случае большой OLTP-нагрузки будет конкуренция за заголовок у множества процессов. Может, лучше без них обойтись? Стоит ли быстрый select count(*) того?eCat3
23.01.2018 16:47Это костыль. В проекте много что можно улучшить, благодаря курсу по СУБД, ОС и набору курсов по программированию мы прекрасно знаем как это сделать.
Но проект сделан Just For Fun в последние три учебных недели, когда кроме всего прочего надо было готовиться к экзаменам и вообще.
ratijas Автор
23.01.2018 16:53А кстати, count(*), как и функции вообще, пока что не поддерживаются. Есть вероятность, что силами студентов к лету допилим.

{kind=link}
VeZooViY
Спасибо за статью. А можно ссылку на гитхаб?
ratijas Автор
Конечно! Как-то упустил этот момент :)
https://github.com/ratijas/dropSQL
VeZooViY
Большое спасибо ;)