
Аннотация
В этой статье мы представляем методологию для начального освоения научной информатики, базирующейся на моделировании в обучении. Мы предлагаем многофазные системы массового обслуживания, как базис для изучаемых объектов. Мы используем Python и параллельные вычисления для реализации моделей, с предоставлением программного кода и результатов стохастического моделирования.
1. Ввведение и предистория
В нашем исследовании мы понимаем значение термина “научная информатика” как использование компьютеров для анализа и решения научных и инженерных проблем. Мы отличаем их от простых численных вычислений. Использование научной информатики в обучении всегда является сложной задачей, как для учащегося, так и для преподавателя. Такой процесс изучения имеет дело с многими техническими и междисциплинарными вопросам, а также требует синхронизации математических знаний с информатикой. Для преодоления этих сложностей мы предлагаем набор обучающих принципов и методологию, которая основывается на конструктивистском подходе к обучению и обеспечивает соответствующий структурный базис для преподавателя. Всё это даёт возможность учащимся провести серию вычислительных экспериментов с компьютерными моделями. Такой подход связан со знанием математики и программирования, которые, в свою очередь, преподаются в процессе основного учебного курса и тесно с ним связаны. Мы рассмотрим раздел вычислительной статистики, как вступительный раздел научной информатики и как возможную область применения данного исследования. Ниже представлена предыстория данной методологии.
1.1. Научная информатика
Карниадакс и Кирби II дали определение “компьютерной информатики, как `сердца` имитационных исследований”. Авторы предлагают “целостный подход численных алгоритмов, современные методы программирования и параллельные вычисления … Часто такие концепции и подобный инструментарий переодически изучаются в различных, смежных по тематике, курсах и учебниках, и взаимосвязь между ними становится сразу очевидна. Необходимость интеграции концепций и инструментов обычно становится явной после завершения курса, например в процессе первой поствузовой работы или при написании тезисов к диссертации, тем самым заставляя учащегося синтезировать понимание трёх независимых областей в одно, для получения требуемого решения. Хотя этот процесс, несомненно, очень ценен, на него уходит много времени, и, во многих случаях, он может не дать эффективного сочетания концепций и инструментов. С педагогической точки зрения, для усиления понимания тем научной информатики, целостный интегрированный подход может стимулировать учащегося сразу к нескольким дисциплинам. На рисунке 1 представлено определение научной информатики как пересечение численной математики, информатики и моделирования [16].

Рис. 1. Научная информатика.
1.2. Конструктивизм в обучении
Кейн и Кейн в их фундаментальных исследованиях [6] предложили основные принципы конструктивизма в обучении. Одним из важнейших для нас является следующий: “Мозг обрабатывает части и целое одновременно”.
Таким образом, хорошо организованный обучающий процесс демонстрирует лежащие в основе детали и идеи. Используя подход, базирующийся на моделировании, после создания имитационной модели становятся очевидными цели исследования. Это позволяет нам наблюдать результаты и формировать соответствующие выводы.
1.3. Обучение на основе моделирования: почему модели?
Гиббонс вводит, базирующуюся на моделировании, программу обучения в 2001 [9]. Выделяя следующие основополагающие принципы:
- Обучающийся получает опыт путём взаимодействия с моделями;
- Обучающийся решает научные и инженерные проблемы путём экспериментов с моделью;
- Рассмотрение и постановка проблем;
- Определение конкретных учебных целей;
- Представление всей необходимой информации в контексте решения.
Миллард и др. [30] предлагают модель облегчённого обучения используя “интерактивное моделирование”. Авторы представляют современные компьютерные технологии, базирующиеся на “многообещающей методологии” основанной на “динамике системы”. “Практический опыт включает конструирование интерактивных … моделей, а также их использование для проверки гипотез и экспериментов”.
Лерер и Шаубле [25] заостряют внимание на экспериментах с различными представлениями модели: “Обучение студента усиливается, когда у студента есть возможность создания и пересмотра нескольких вариантов моделей, а затем сравнения адекватности описания этих различных моделей”.
1.4. Научная информатика в основе образования: эксперименты с моделями
Сюэ [40] предлагает “реформы преподавания в обучении на основе “научной информатики” путём моделирования и имитаций”. Он советует “… использовать моделирование и имитации для решения актуальных проблем программирования, моделирования и анализа данных…”. Обучение, базирующееся на моделировании, используется в математическом образовании. Множество моделей построено с использованием программного обеспечения «Geogebra» [33]. Модели играют главную роль в Научном Образовании [7,18].
1.5. Стохастическое моделирование систем массового обслуживания
Мы предлагаем использование систем массового обслуживания в связи с простотой их начальных определений и из-за широких возможностей моделирования и имитаций. Теория Массового Обслуживания хорошо известна и моделирование Cистем Массового Обслуживания (СМО) широко используется в науке [4,19] и образовании [13,36]. Мультифазные системы массового обслуживания являются хорошей платформой для экспериментов учащегося, как и использование параллельных вычислений. Также существует ряд интересных теоретических результатов для изучения и исследования [12].
1.6. Python в образовании, основанном на научной информатике
Python один из популярнейших языков программирования учёных и педагогов [21–23]. Python широко используется в промышленных научных вычислениях [14]. Лангтанген докладывает о долгосрочном опыте использования Python как первичного языка для обучения Научной Информатике в Университете Осло [24]. Python продвигается как первый язык для изучения программирования [38], а также для углублённого изучения вычислительных методов [3,20,34].
2. Основы
Прежде, чем приступить к моделированию, определим ключевые подходы, которые мы будем использовать в процессе. В этой главе затронем вопросы генерация случайных чисел и вероятностных распределений, стохастического моделирования. Рассмотрим элементарную теорию вероятностей. Основной задачей этих экспериментов будет экспериментальное доказательство Центральной Предельной Теоремы. Модели и эксперименты с этими моделями проясняют принцип генераторов псевдо- и квази-случайных чисел, а также понимание экспоненциального распределения. Это может обеспечить основу для более детальных экспериментов с моделями СМО.
2.1. Случайные величины и распределения
Все элементы теории вероятностей традиционно считаются трудными для понимания и всегда находятся в сфере интересов международных образовательных учреждениях [15]. В тоже время эти вопросы занимают немаловажную роль и в научных исследованиях [10]. Подход, базирующийся на моделировании, делает более легким понимание этого материала. Модель, которую рассмотрим в этой статье, является простой моделью бросания одного или нескольких игральных кубиков, начиная с одного и заканчивая несколькими.
Задача этих вводных экспериментов является довольно сложной. Мы не только рассмотрим вероятностные распределения, но также затронем моделирование и параллельные вычисления. Мы также сделаем один шаг вперёд в научном исследовании: экспериментально докажем Центральную Предельную Теорему.
Мы начнём с генерации случайных чисел (не затрагивая распределения). Затем объясним равномерно распределённые случайные величины. Обсуждения об истинной случайности и квази случайности представлены авторами [26, 35]. Для продвинутых учеников будет представлен ряд экспериментов с генератором псевдослучайных величин Python. На начальном этапе, для наглядности изучения, будем повышать количество испытаний, наблюдая результат моделирования. На последующем этапе мы перейдём к более сложным экспериментам и параллельным вычислениям. Будем использовать для моделирования модуль случайных величин Python, а для параллельных вычислений — библиотеку mpi4py. Модуль случайных величин Python основан на псевдослучайном генераторе чисел для различных распределений. Для примера: random.randint(a,b) возвращает случайное целое число N, где a ? N ? b и random.expovariate(lambd) возвращает экспоненциально распределенные случайные величины с параметром ‘lambd’. Для получения более подробной информации обратитесь к документации Python. Программирование модели подбрасывания кубика представлено на рис.2.
import pylab
import random
number_of_trials =100
## Here we simulate the repeated throwing of a single six-sided die
list_of_values = []
for i in range(number_of_trials):
list_of_values.append(random.randint( 1,6))
print "Trials =", number_of_trials, "times."
print "Mean =", pylab.mean(list_of_values)
print "Standard deviation =", pylab.std(list_of_values)
pylab.hist(list_of_values, bins=[0.5,1.5,2.5,3-5,4.5,5.5,6.5])
pylab.xlabel('Value')
pylab.ylabel('Number of times')
pylab.show()
Рис. 2. Программирование модели подбрасывания одного кубика на Python
Результаты моделирования подбрасывания одного кубика представлены на рисунке 3.

Рис. 3. Результаты моделирования подбрасывания одного кубика
Далее рассмотрим случай подбрасывания двух игральных кубиков. Главная идея на данном этапе – это объяснение ЦПТ с помощью эксперимента с разным количеством кубиков. Рисунок 4 демонстрирует эту идею.

Рис. 4. Сравнение функций плотности вероятности
Процесс изучения продолжается путём изменения кода для моделирования подбрасывания двух кубиков таким образом, чтобы начать рассматривать случай с несколькими кубиками. Код аналогичен коду с одним кубиком, за исключением двух строк кода, представленных ниже:
...
list_of_values.append(random.randint(1, 6) + random.randint(1, 6))
...
pylab.hist(list_of_values, pylab.arange(1.5, 13.5, 1.0))
...
Результат вычислений в случае двух кубиков представлен на рисунке 5.

Рис. 5. Случай двух кубиков
Теперь можем рассмотреть нормальное распределение. Задача, на данном этапе, показать как предыдущий случай с несколькими кубиками коррелирует с нормальным распределением. Следующая задача познакомит нас со средней величиной и среднеквадратическим отклонением. Код остаётся такой же, как в случае одного кубика, за исключением инструкции, приведённой ниже:
...
list_of_values.append(random.normalvariate(7, 2.4))
...
Результаты моделирования для нормального распределения представлены на рисунке 6.
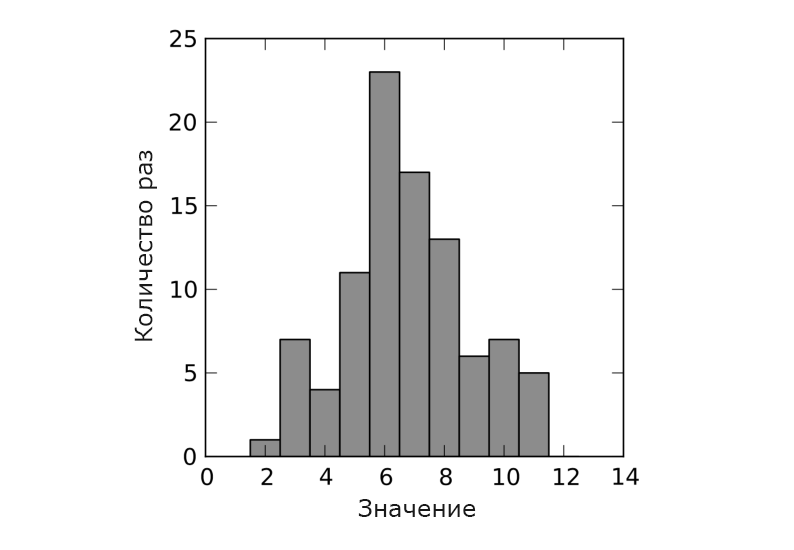
Рис. 6. Результат моделирования для нормального распределения
Финальным шагом является демонстрация экспоненциального распределения. Экспоненциальное распределение используется для моделирования распределения (длительности) интервалов между моментами поступления требований в системах разного типа. Результаты их моделирования представлены на рис 7 и 8.
import pylab
import random
number_of_trials = 1000
number_of_customer_per_hour = 10
## Here we simulate the interarrival time of the customers
list_of_values = []
for i in range(number of trials):
list_of_values.append(random.expovariate(number_of_customer_per_hour))
mean=pylab.mean(list_of_values)
std=pylab.std(list_of_values)
print "Trials =", number_of_trials, "times"
print "Mean =", mean
print "Standard deviation =", std
pylab.hist(list_of_values,20)
pylab.xlabel('Value')
pylab.ylabel('Number of times')
pylab.show()
Рис. 7. Модель Python для экспоненциального распределения
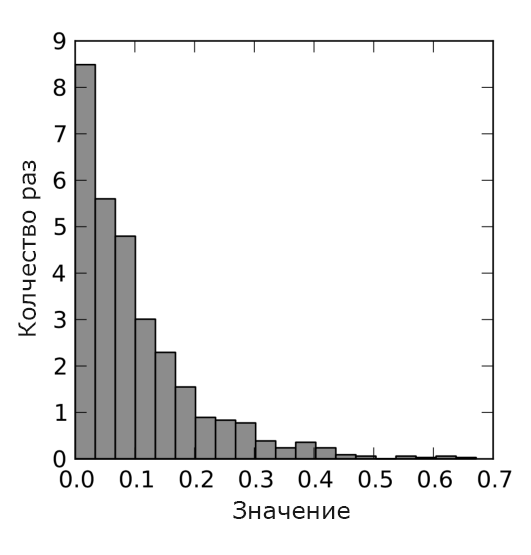
Рис. 8. Результат моделирования для экспоненциального распределения
2.2. Стохастическое моделирование
Стохастическое моделирование является важным элементом научной информатики. Мы сосредоточимся на методе Монте-Карло [10,11,27]. После того, как модель была построена, мы можем генерировать случайные переменные и экспериментировать с различными параметрами системы. В рамках этой статьи ключевым моментом экспериментов Монте-Карло является повторения испытаний много раз с целью накопления и интегрирования результатов. Простейшее приложение было описано в предыдущем разделе. Увеличивая количество испытаний мы будем увеличивать точность результатов моделирования.
Здесь учащийся должен провести определённое количество экспериментов используя эту простую модель путём увеличения количества испытаний. За счёт увеличения числа кубиков и числа испытаний, учащийся столкнётся с относительно долгим временем вычисления. Это прекрасный повод для использования параллельных вычислений. Модель Python для нескольких игральных кубиков представлена на рисунке 9. И результаты моделирования представлены на рисунке 10. Следующим шагом будет рассмотрение более общих вопросов, связанных с различными системами массового обслуживания. Краткое введение в классификацию СМО представлено в следующей части этой статьи. Начнём изучение с системы М/М/1 системы и более сложных систем массового обслуживания. Основные понятия стохастических процессов будут подробно освещены в этой части статьи. В качестве возможного примера можно предложить задачу исследования выходного потока. Докажем, что вывод М/М/1 системы является Пуассоновским потоком. Таким образом собранные данные будут представлены в виде построенной выходной эмпирической гистограммы.
import pylab
import random
number_of_trials = 1000
number_of_customer_per_hour = 10
## Here we simulate the interarrival time of the customers
list_of_values = []
for i in range(number of trials):
list_of_values.append(random.expovariate(number_of_customer_per_hour))
mean=pylab.mean(list_of_values)
std=pylab.std(list_of_values)
print "Trials =", number_of_trials, "times"
print "Mean =", mean
print "Standard deviation =", std
pylab.hist(list_of_values,20)
pylab.xlabel('Value')
pylab.ylabel('Number of times')
pylab.show()
Рис. 9. Модель моделирования Python для расширенного нормального распределения

Рис. 10. Результат моделирования для расширенного нормального распределения
3. Многофазные системы массового обслуживания и стохастическое моделирование
Ниже приведено вводное описание СМО, учитывающие нюансы моделирования и стохастики.
3.1. Системы Массового Обслуживания
Простая система массового обслуживания состоит из одного обслуживающего устройства, которое обрабатывает прибывающие заявки. Общая схема простой системы массового обслуживания представлена на рисунке 11. В общем, СМО состоит из одного или нескольких обслуживающих устройств, которые обрабатывают прибывающие заявки. Также возможен вариант одного или нескольких этапов обслуживания с одним или несколькими обслуживающими устройствами в каждой фазе. Приходящие клиенты, которые обнаружили все сервера занятыми, присоединяются к одному или нескольким очередям перед обслуживающими устройствами. Существует множество приложений, с помощью которых можно моделировать СМО, такие как производственные системы, системы связи, системы технического обслуживания и другие. Общую СМО можно охарактеризовать тремя основными компонентами: поток поступления заявок, процесс обслуживания и метод обслуживания очереди. Поступление заявок может приходить из нескольких ограниченных или неограниченных источников.

Рис. 11. Простая СМО.
Процесс поступления заявок описывает как заявки приходят в систему. Определим
как временной интервал между прибытием заявок между и -ой заявкой, ожидаемое (среднее) время между поступлениями заявок как и частоту поступления заявок как
Также определим как количество обслуживающих устройств. Механизм обслуживания определяется этим числом. Каждое обслуживающее устройство имеет свою собственную очередь, а также вероятностное распределение времени обслуживания заявки.
Определим как время обслуживание -ой заявки, как среднее время обслуживания заявки и .
Правило, которое использует обслуживающее устройство для выбора следующей заявки из очереди называется дисциплиной очереди СМО. Наиболее частые дисциплины очереди: Приоритетная – клиенты обслуживаются в порядке их важности. FIFO – первый пришёл первый обслужен; LIFO – стек, последний пришёл первым обслужен. Расширенная классификация систем по Кендаллу использует 6 символов: A/B/s/q/c/p, где А – распределение интервалов между приходящими заявками, В – распределение интервалов обслуживания, s – количество серверов, q – дисциплин обслуживания (опущена для FIFO), с – вместимость системы (опущено для бесконечных очередей), p – количество возможных заявок (опущено для открытых систем) [17,37]. Для примера М/М/1 описывает Пуассоновский поток на входе, одно экспоненциальное обслуживающее устройство, одну бесконечную FIFO очередь, и бесконечное число заявок.
СМО используются для моделирования и исследования различных областей науки и техники. Для примера: мы можем моделировать и изучать производственные или транспортные системы с использованием теории массового обслуживания. Причём запросы на обслуживание рассматриваются в качестве заявок, а процедуры технического обслуживания в качестве механизма обслуживания. Следующий пример такой: вычислительные машины (терминальные запросы и серверные ответы соответственно), компьютерные многодисковые системы памяти (запросы на запись/чтение данных, общий дисковый контроллер), транкинговая радиосвязь (телефонные сигналы, повторители), компьютерные сети (запросы, каналы) [39]. В биологии можно использовать теорию массового обслуживания для моделирования энзимных систем (белки, общие энзимы). В биохимии можно использовать модель сети массового обслуживания для изучения регуляторной цепи ЛАК оперона.
3.2. Почему многофазные?
Рассмотрим многофазную СМО, которая состоит из нескольких обслуживающих устройств, которые соединены последовательно и имеют неограниченное количество заявок. Время между заявками и время обработки независимы и экспоненциально распределены. Очередь бесконечна с дисциплиной обслуживания FIFO. Многофазная СМО естественным образом отражает топологию многоядерных компьютерных систем. Как мы увидим в дальнейшем, каждая модель может быть легко написана на языке программирования, изучена и модифицирована. Модель также позволяет провести сравнительное исследование различных подходов многопроцессорной обработки. Модель мультифазной СМО представлена на рисунке 12.

Рис. 12. Мультифазная СМО.
3.3. Теоретическая основа
В случае статистического моделирования, мы всегда сталкиваемся с проблемой верификации компьютерного кода. Всегда остаётся открытым вопрос ошибок в нашей программе или алгоритме. Модель не полностью является аналитической и каждый раз запуская программу мы имеем различные данные на входе/выходе. Таким образом, для проверки корректности кода или алгоритма, необходимы различные подходы (от того, который мы используем в случае полностью детерминированных входных данных). Для решения этого вопроса мы должны применить теоретические результаты некоторых исследований, которые можно найти в научной литературе. Эти результаты дают нам базу для для верификации и анализа выходных данных, а также для решения проблемы корректности результатов моделирования [31,32].
Мы будем исследовать время пребывания заявки в многофазной СМО. Обозначим как время пребывания заявки в системе, как время обслуживания n-ой заявки j-ой фазы. Рассмотрим как для k-ой фазы.
Существует такая константа такая, что
Теорема. Если условия (1) и (2) выполнены, тогда
3.4. Статистическое моделирование
После того как модель построена, мы могли бы провести ряд экспериментов с этой моделью. Это позволит изучить некоторые характеристики системы. Мы можем эмитировать случайные величины с ожидаемым среднем значением и посчитать (используя рекуррентное уравнение, представленное ниже) нужные значения для изучения. Эти значения также будут случайными (мы имеем есть стохастичность входных данных нашей модели – случайное временн между приходом заявок и случайное время обслуживания). В итоге, мы можем вычислить некоторые параметры этих случайных величин (переменных): среднее значение и вероятностное распределение. Мы называем этот метод статистическим моделированием из-за случайности, представленной в модели. Если нужны более точные результаты, мы должны повторить эксперименты с нашей моделью и затем интегрировать результаты, то вычислить интегральные характеристики: средние значение или среднеквадратическое отклонение. Это называется методом Монте Карло и он был описан в статье немного выше.
3.5. Рекуррентное уравнение
Для разработки алгоритма моделирования ранее описанной СМО, нужно разобрать некоторые математические конструкции. Основная задача – исследование и вычисление времени пребывания заявки с номером n в многофазной СМО, состоящей из фаз. Мы можем привести следующие рекуррентное уравнение [12], обозначим: — время прибытия -ой заявки; как время обслуживания -ой заявки -ой фазы; . Следующее рекуррентное уравнение справедливо для времени ожидания для -ой заявки -ой фазы:
Предположение. Рекуррентное уравнение для расчёта времени пребывания заявки в многофазной СМО.
Доказательство. Это правда, что если время , тогда время ожидания в -ой фазе -ой заявки является 0. В этом случае , время ожидания в -ой фазе -ой заявки и . Принимая во внимание два вышеупомянутых случая, мы в итоге имеем предполагаемый результат.
Теперь мы можем начать реализовывать необходимые алгоритмы на основе всех полученных теоретических результатов.
4. Python для многопроцессорной обработки
Python как язык программирования очень популярен среди учёных и педагогов и может быть очень привлекательным для решения научно-ориентированных задач [3]. Python предоставляет мощную платформу для моделирования и имитаций, включая графические утилиты, широкое количество математических и статистических пакетов, а также пакетов для мультипроцессорной обработки. Для уменьшения времени выполнения, необходимо совместить код Python и Си. Всё это даёт нам мощную платформу моделирования для получения статистических данных и обработки результатов. Ключевые концепции в Python, которые также является важными в моделировании, это: декораторы, сопрограммы, yield выражения, многопроцессорная обработка и очереди. Очень хорошо рассмотрены эти моменты у Бизли в его книге [2]. Не смотря на это, существуют несколько путей организации межпроцессного взаимодействия, и мы начнём с использования очередей, потому что это очень естественно в свете изучения СМО.
Приведём ниже простой пример преимущества использования многопроцессорной обработки для увеличения эффективности и результативности программного кода. Изучающий может улучшить результаты моделирования, путём использования параллельных вычислений на суперкомпьютерах или кластерных системах [28, 29]. С одной стороны, многопроцессорность позволит нам сопоставить мультифазную модель с ресурсами многоядерного процессора, а с другой стороны, мы можем использовать мультипроцессорность чтобы выполнить ряд параллельных испытаний Монте – Карло. Мы рассмотрим два этих подхода в следующем разделе. Для мотивированных учеников далее будет представлено краткое введение в мультипроцессорную обработку с помощью Python.
Мы начнём с использования модуля mpi4py. Это важно для представления главной идеи о том, как работает MPI. Он просто копирует предоставленную программу одному из процессорных ядер, определяемых пользователем, и интегрирует результаты после использования метода gather(). Пример Python кода (рис. 13) и результаты моделирования (рис. 14) представлены ниже.
#!/usr/bin/python
import pylab
import random
import numpy as np
from mpi4py import MPI
dice=200
trials= 150000
rank = MPI.COMM_WORLD.Get_rank()
size = MPI.COMM WORLD.Get_size()
name = MPI.Get_processor_name()
random.seed(rank)
## Each process - one throwing of a number of six-sided dice
values= np.zeros(trials)
for i in range(trials):
sum=0
for j in range(dice): sum+=random.randint(l,6)
values[i]=sum
data=np.array(MPI.COMM_WORLD.gather(values, root=0))
if rank == 0:
data=data.flatten()
mean=pylab.mean(data)
std=pylab.std(data)
print "Number of trials =", size*trials, "times."
print "Mean =", mean
print "Standard deviation =", std
pylab.hist(data,20) pylab.xlabel('Value') pylab.ylabel('Number of times')
pylab.savefig('multi_dice_mpi.png')
Рис. 13. Python модель для расширенного нормального распределения с применением MPI.
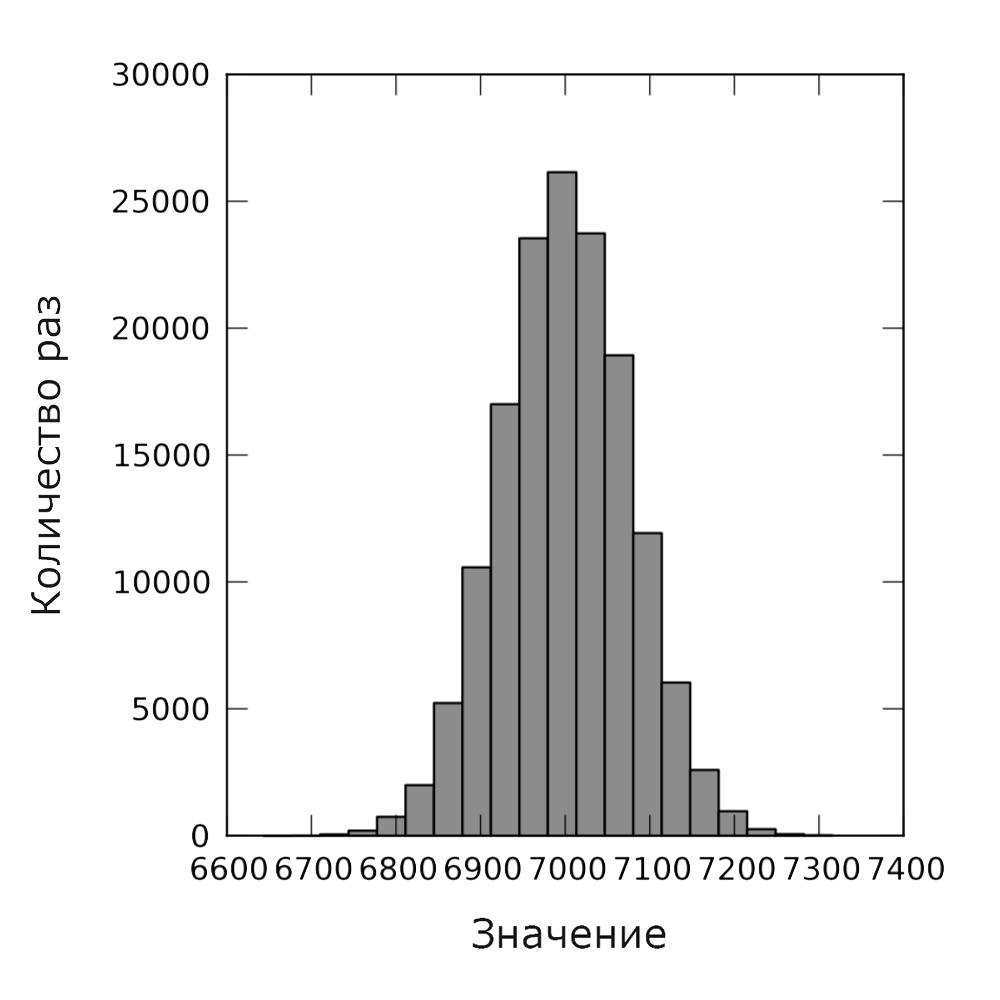
Рис. 14. Нормальное распределение с применением MPI.
5. Образовательный подход, основанный на моделировании
Многофазные СМО дают нам ядро для разработки соответствующего подхода, основанного на моделировании. Такой подход включает в себя базовые понятия, описанные в предыдущих разделах, а также более сложные теоретические результаты и методы. Основные идеи носят стохастический характер: случайные величины, случайные числовые распределения, генераторы случайных чисел, Центральная Предельная Теорема; конструкции программирования Python:
декораторы, сопрограммы и yeild выражения. Более сложные результаты включают следующее теоретические понятия: время пребывания заявки в системе, рекуррентное уравнение для вычисления времени пребывания заявки в СМО, методы стохастического моделирования и мультипроцессорные технологии. На рисунке 15 представлена главная схема, описывающая образовательную основу.

Рис. 15. Образовательный подход, основанный на моделировании
Все эти теоретические и программные структуры дают учащемуся проводить эксперимент с различными моделями многофазных СМО. Цель таких экспериментов двояка. Во-первых, это даёт учащимися понять следующую последовательность, которая важна в любых научных исследованиях: необходимые для изучения теоретические факты, математические модели, программные конструкции, компьютерные модели, стохастические модели и наблюдение результатов моделирования. Это даст учащемуся полную картину общих научных исследований (рис 16).
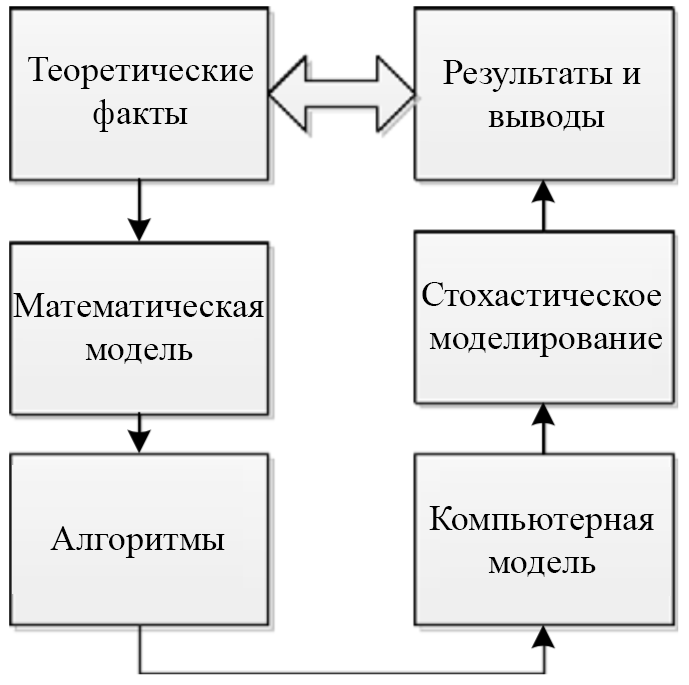
Рис. 16. Область научных исследований
Такой подход позволит глубже понять стохастическое моделирование и базовые программные конструкции, такие как многопроцессорная обработка и параллельное программирование. Эти положения имеют первостепенное значение в области научных вычислений.
5.1. Эксперименты с моделями
В этом разделе мы рассмотрим три компьютерные модели многофазных СМО. Все эти модели различны по своим философским и ключевым особенностям. Несмотря на то, что целью экспериментов является создание статистической модели и исследование главных параметров многофазных систем, концептуальные идеи этих моделей совершенно различны. Сравнение этих основных идей поможет ученику понять фундаментальные положения, которые лежат в основе параллельных вычислений, многопроцессорного статистического и имитационного моделирования.
Первая модель, представленная нами, основана на записи в реальном времени и мы называем это имитационной моделью. Она использует мультипроцессорный модуль Python. Точность этой модели зависит от точности и разрешающей способности метода времени time(). Она может быть довольно низкой, в случае различных операционных систем общего назначения, и довольно высокой, в случае систем реального времени. Учащийся может изменять эту модель используя ранее предложенное рекуррентное уравнение (для вычисления времени пребывания заявки в системе) и сравнивать результаты в обоих случаях.
Следующая модель вычисляет время пребывания заявки в системе и основана на стохастическоом моделировании. Модель не использует много-процессорность напрямую. Мультипроцессорная обработка эмулируется при помощи использования yield выражениями Python.
Последняя модель представлена здесь с использованием Python MPI mpi4py модулем. Здесь используется настоящий MPI (мультипроцессорный) подход для статистического моделирования и можем, за счёт этого, увеличивается количество испытаний в методе Монте Карло.
В общем, задача учащегося заключается в создании серии экспериментов с предоставленными моделями и получение экспериментального доказательства закона повторного логарифма (law of the iterated logarithm) для времени пребывания заявки в многофазной СМО.
5.2. Имитационная модель, использующая мультипроцессорный сервис
Ниже представлена имитационная модель. Основной вопрос для изучения – это разница между имитационной моделью и статистической моделью. Другой важный вопрос это корректность и точность имитационной модели. Также важным является вопрос правильности и точности представленной модели. Учащийся может изучить и сравнить результаты моделирования, зависящие от различных параметров, таких как интервал и частота обработки, количество заявок и количество обслуживающих узлов. Общая схема модели представлена на рисунке 17.

Рис. 17. Имитационная модель
Программный код код состоит из двух главных частей. Первый предназначен непосредственно для расчётов, а следующий – для построения результатов. Модуль для вычисления содержит три главные функции: producer() – для получения заявок и помещения их в первую очередь; server() – для обслуживания заявок; consumer() – для получения результатов. Эта программная модель основана на реальной симуляции и не использует математические выражения для вычислений. Её точность зависит от точности временного модуля Python и, как правило, зависит от операционной системы. Вычисление работы обслуживающих устройств распределяются между различными процессами внутри мультипроцессорной системы. Компьютерный код для реализации, указанной выше модели, представлен на рисунке 18.
import multiprocessing
import time
import random
import numpy as np
def server(input_q,next_q,i):
while True:
item = input_q.get()
if i==0:item.st=time.time() ## start recording time
## (first phase)
timc.sleep(random.expovariate(glambda|i]))
##stop recording time (last phase)
if i==M-1 :item.st=time.time()-item.st
next_q.put(item)
input_q.task_done()
print("Server%d stop" % i) ##will be never printed why?
def producer(sequence,output_q):
for item in sequence:
time.sleep(random.expovariate(glambda[0]))
output_q.put(ilem)
def consumer(input_q):
"Finalizing procedures"
## start recording processing time
ptime=time.time()
in_seq=[]
while True:
item = input_q.get()
in_scq+=[item]
input_q.task_done()
if item.cid == N-1:
break
print_results(in_seq)
print("END")
print("Processing time sec. %d" %(time.time()-ptime))
## stop recording processing time
printf("CPU used %d" %(multiprocessing.cpu_count()))
def print_resulls(in_seq):
"Output rezults"
f=open("out.txt","w")
f.write("%d\n" % N)
for l in range(M):
f.write("%d%s" % (glambda[t],","))
f.write("%d\n" % glambda[M])
for t in range(N-1):
f.write("%f%s" % (in_seq[t].st,","))
f.write("%f\n" % (in_seq[N-1].st))
f.close()
class Client(object):
"Class client"
def __init__(self,cid,st):
self.cid=cid ## customer id
self.st=st ## sojourn time of the customer
###GLOBALS
N=100 ## total number of customers arrived
M=5 ## number of servers
### glambda - arrival + servicing frequency
### = customers/per time unit
glambda=np.array([30000]+[i for i in np.linspace(25000,5000,M)])
###START
if __name__ == "__main__":
all_clients=[Client(num,0) for num in range(0,N)]
q=[multiprocessing.JoinableQueue() for i in range(M+1)]
for i in range(M):
serv = multiprocessing.Process(target=server,args=(q[i],q[i+1],i))
serv.daemon=True
serv.start()
cons = multiprocessing.Process(target=consumer,args=(q[M],))
cons.start()
### start 'produsing' customers
producer(all_clients,q[0])
for i in q: i.join()
Рис. 18. Python код для имитационной модели, использующей мультипроцессорный сервис.
Вопросы для изучения:
- Как глобальные переменные предоставляются процессам и разделяются между ними?
- Как завершаться процессы, связанные с различными обслуживающими устройствами?
- Как передаётся информационный поток между различными процессами?
- Что насчёт корректности модели?
- Что насчёт эффективности модели. Сколько времени потребуется для обмена информацией различным процессам?
Теперь мы можем распечатать результаты, используя модуль matplotlib и можем визуально анализировать результаты, после предоставления диаграммы. Мы можем увидеть (рисунок 19) что модели необходимо дальнейшее совершенствование. Таким образом, мы можем перейди к более мощной модели.
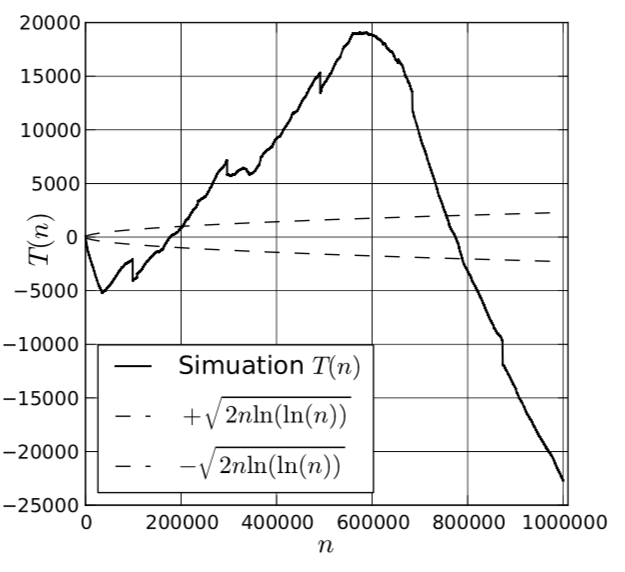
Рис. 19. Результаты моделирования имитационной модели мультипроцессорный сервис.
5.3. Единичный процесс статистической модели
Главной особенностью статистической модели является следующее: теперь мы используем рекуррентное уравнение для точного вычисления времени пребывания заявки в системе; мы обрабатываем все данные в единственном процессе используя специфическую сопрограммную функцию Python; мы осуществляем определённое число моделирований по методу Монте-Карло для лучшей достоверности расчётов. Эта модель даёт нам “точные” расчёты времени пребывания заявки в системе. Главная схема модели представлена на рисунке 20. Учащийся может изучить различия между имитационной и статистической моделью.

Рис. 20. Единичный процесс статистической модели
Программный код для реализации указанной выше модели представлен на рисунке 21. Результаты симуляции представлены на рисунке 22.
#!/usr/bin/python
import random
import time
import numpy as np
from numpy import linspace
def coroutine(func):
del start(*args,**kwargs):
g = func(*args,**kwargs)
g.next()
return g
return start
def print_header():
"Output rezults - header"
f=open("out.txt","w")
f.write("%d\n" % N)
##number of points in printing template
f.write("%d\n" % TMPN)
for t in range(M):
f.write("%d%s" % (glambda[t],","))
f.write("%d\n" % glambda[M])
f.close()
def print_results(in_seq):
"Output rezults"
f=open("out.txt","a")
k=()
for i in range(N-2):
if in_seq[i].cid==template[k]:
f.write("%f%s" % (in_seq[i].st,","))
k+=1
f.write("%f\n" % (in_seq[N-1 ].st))
f.close()
coroutine
def server(i):
ST=0 ##sojourn time for the previous client
item=None
while True:
item = (yield item) ##get item
if item == None: ##new Monte Carlo iteration
ST=0
continue
waiting_time=max(0.0,ST-item.st-item.tau)
item.st+=random.expovariate(glambda[i+1])+waiting_time
ST=item.st
def producer():
results=[]
i=0
while True:
if i == N: break
c=Client(i,0.,0.)
if i!=0: c.tau=random.expovariate(glambda[0])
i+= 1
for s in p: c=s.send(c)
results+=[c]
for s in p: c=s.send(None) ##final signal
return results
class Client(object):
def __init__(self,cid,st,tau):
self.cid=cid
self.st=st
self.tau=tau
def params(self):
return (self.cid,self.st,self.tau)
stt=time.time()
N=1000000 ## Clients
M=5 ## Servers
## Input/sevice frequency
glambda= [30000]+[i for i in linspace(25000,5000,M)]
MKS=20 ## Monte Carlo simulation results
## Number of points in the printing template
TMPN=N/10000
##printing template
template= map(int,linspace(0,N-1,TMPN))
print_header()
p=[]
for i in range(M):p +=[server(i)]
for i in range! MKS):
print_results(producer())
print("Step=%d" % i)
sys.stdout.write("Processing time:%d\n" % int(time.time()-stt))
Рис. 21. Python код для единичного процесса статистической модели
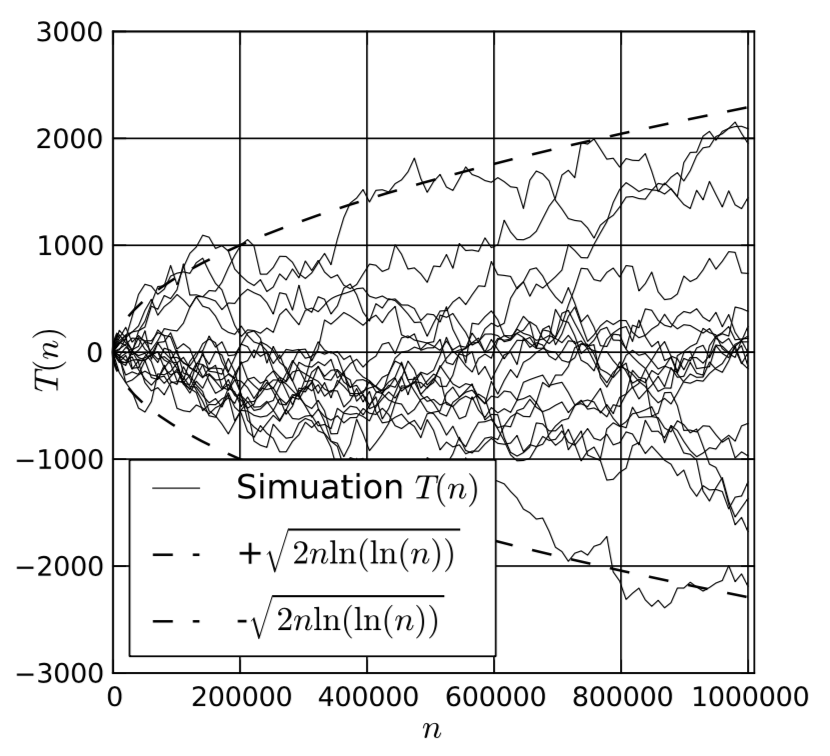
Рис. 22. Результаты моделирования для единичного процесса статистической модели
5.4. Статистическая модель на MPI
Следующим шагом развития нашей модели является использование Python MPI модуля – mpi4py. Это позволяет нам работать с большим количеством симуляций Монте Карло и использовать кластер для запуска и тестирования модели. Следующим шагом должно являться дальнейшее совершенствование модели на основе использования языка программирования Си, “реального” MPI или SWIG (https://ru.wikipedia.org/wiki/SWIG) технологии для Python. Эта модель в практически идентична предыдущей модели с той лишь разницей, что используется mpi4py для мультипроцессорной обработки и интеграции результатов (рисунок 23).

Рис. 23. Статистическая модель MPI
В дополнении к предыдущей модели, должны быть импортированы несколько дополнительных модулей. Функция print_results() также должна быть переписана, так как на данном этапе у нас больше испытаний. Мы должны также переписать главную часть программы. На рисунке 24 мы предоставили только ту часть программного кода, которая отличается от кода предыдущей модели. Результаты моделирования представлены на рисунке 25.
....................
import sys
from mpi4py import MPI
....................
def print_results(in_seq):
"Output rezults"
f=open("out.txt","a")
for m in range(int(size)):
for j in range(MKS):
for i in range(TMPN-l):
f.write("%f%s" % (in_seq[m][i+j*TMPN].st,","))
f.write("%f\n" % (in_seq[m][(TMPN-l)+j*TMPN].st))
f.close()
....................
stt=time.time() #start time for the process
rank = MPI.COMM_WORLD.Get_rank()
size = MPI.COMM_WORLD.Get_size()
name = MPI.Get_processor_name()
N= 10**3 ## Clients
M=5 ## Servers
## Input/sevice frequency
glambda=[30000]+[i for i in linspace(25000,5000,M)]
## Number of Monte-Carlo simulations for this particuar process
MKS=20
TMPN=200 ## Number of points in printing templat
template= map(int,linspace(0,N-1,TMPN)) ## points for printing
p=[]
results=[] ## this process results
total_results=[] ## overall results
for i in range(M):p +=[server(i)]
for i in range(MKS):results+=producer()
total_results=MPI.COMM_WORLD.gather(results,0)
random.seed(rank)
if rank == 0:
print_header()
print_results(total_results)
sys.stdout.write("Processing time: %d\n" % int(time.time()-stt))
Рис. 24. Python код для статистической модели на основе MPI
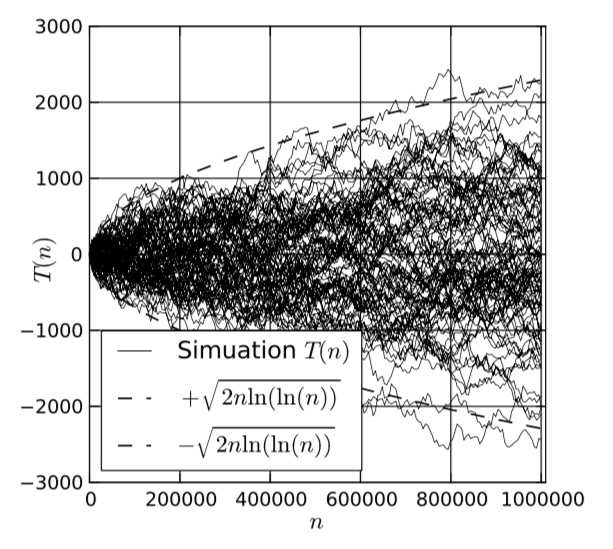
Рис. 25. Результаты моделирования статистической модели MPI
6. Выводы
В этой статье были рассмотрены несколько моделей для обучения на основе моделирования. Эти модели дают возможность учащемуся провести серию экспериментов и повысить понимание дисциплины Научной Информатики. Есть несколько уровней сложности представленных моделей и экспериментов с такими моделями. Первый уровень – базовый. Он подводит нас к пониманию случайных величин, а также даёт первичное понимание области научных исследований. Следующий уровень является более сложным и даёт более глубокое понимание параллельного программирования и стохастического моделирования. Соответсвующие теоретические знания представлены, и, по необходимости, могут быть использованы в качестве дополнительного материала. Это всё предоставляет базовый инструментарий для введения в Научную Информатику. И, в завершении, мы хотели бы дать рекомендации для дальнейшего изучения и совершенствования моделей.
6.1. Линейность модели и статистические параметры СМО
Модель мультифазной СМО, представленная в этой статье, не линейна [12]. Это становится очевидно из рекуррентного уравнения, так как она содержит нелинейную математическую функцию max. Если мы хотим получить правильные результаты моделирования, особенно в случае расчёта статистических параметров СМО, мы должны использовать частично линейную модель для расчёта. Эта особенно важно для ненагруженных транспортных систем, так как в противном случае мы можем получить довольно большую ошибочную разницу в расчётах.
6.2. Расширения модулей Python и параллельное программирование с Си
Для умелых учеников, может быть интересноым продолжить улучшение эффективности программного кода. Это можно сделать путём расширения модулей Python с имплементированными Си функциями используя технологию SWING. Возможно улучшить расчёты кода и ускорить вычисления используя Cython, языка программирования Си, “реальные” MPI технологиии HTC (высокопроизводительные вычисления) в кластерных системах [5, 28, 29].
6.3. Эффективность программных решений и дальнейшие разработки
В этом разделе учащийся может изучить эффективность различных программных решений. Этот топик важен для любых программных моделей, которые основаны на параллельных вычислениях. Учащийся может изучить эффективность различных программных моделей и попытаться шаг за шагом улучшать алгоритмы. Ключевым моментом здесь является исследование соотношения количества информационных потоков и вычислений для различных программных процессов. Так соотношение имеет важное значение при построении наиболее эффективной разработки программ с параллельными вычислениями. Другой интересный топик – это изучение возможности преобразование алгоритмической структуры на кластерную HTC структуру.
В качестве дополнительной задачи для проведения исследований авторы рассматривают моделирование СМО, которая должна быть смоделирована и проанализирована. Сравнительно сложный характер СМО и соответсвующий вид приложений требуют применения более обширных техник программирования. Таким образом, появляется хорошая базовая платформа для внедрения таких общих концепций программирования, как наследование, инкапсуляция и полиморфизм. С другой стороны базовые теоретические концепции информатики также необходимо осветить. Помимо всего этого, статистическое и имитационное моделирование СМО требуют более продвинутых знаний в области теории вероятностей, использования большего количества вычислительных ресурсов и предоставления реальной научной вычислительной среды, а также хорошей мотивации продвинутого учащегося.
Литература
[2] D.M. Beazley, Python Essential Reference, Addison-Wesley Professional, 2009.
[3] J. Bernard, Use Python for scientific computing, Linux Journal 175 (2008), 7.
[4] U.N. Bhat, An Introduction to Queueing Theory Modeling and Analysis in Applications, Birkhauser, Boston, MA, 2008.
[5] K.J. Bogacev, Basics of Parallel Programming, Binom, Moscow, 2003.
[6] R.N. Caine and G. Caine, Making Connections: Teaching andthe Human Brain, Association for Supervision and Curriculum Development, Alexandria, 1991.
[7] J. Clement and M.A. Rea, Model Based Learning and Instruction in Science, Springer, The Netherlands, 2008.
[8] N.A. Cookson, W.H. Mather, T. Danino, O. Mondragon- Palomino, R.J. Williams, L.S. Tsimring and J. Hasty, Queue- ing up for enzymatic processing: correlated signaling through coupled degradation, Molecular Systems Biology 7 (2011), 1. [9] A.S. Gibbons, Model-centered instruction, Journal of Structural Learning and Intelligent Systems 4 (2001), 511–540. [10] M.T. Heath, Scientific Computing an Introductory Survey, McGraw-Hill, New York, 1997.
[11] A. Hellander, Stochastic Simulation and Monte Carlo Meth- ods, 2009.
[12] G.I. Ivcenko, V.A. Kastanov and I.N. Kovalenko, Queuing System Theory, Visshaja Shkola, Moscow, 1982.
[13] Z.L. Joel, N.W. Wei, J. Louis and T.S. Chuan, Discrete–event
simulation of queuing systems, in: Sixth Youth Science Con- ference, Singapore Ministry of Education, Singapore, 2000, pp. 1–5.
[14] E. Jones, Introduction to scientific computing with Python, in: SciPy, California Institute of Technology, Pasadena, CA, 2007, p. 333.
[15] M. Joubert and P. Andrews, Research and developments in probability education internationally, in: British Congress for Mathematics Education, 2010, p. 41.
[16] G.E. Karniadakis and R.M. Kyrby, Parallel Scientific Comput- ing in C++ and MPI. A Seamless Approach to Parallel Al- gorithms and Their Implementation, Cambridge Univ. Press, 2003.
[17] D.G. Kendall, Stochastic processes occurring in the theory of queues and their analysis by the method of the imbedded Markov chain, The Annals of Mathematical Statistics 1 (1953), 338–354.
[18] M.S. Khine and I.M. Saleh, Models and modeling, cognitive tools for scientific enquiry, in: Models and Modeling in Science Education, Springer, 2011, p. 290.
[19] T. Kiesling and T. Krieger, Efficient parallel queuing system simulation, in: The 38th Conference on Winter Simulation, Winter Simulation Conference, 2006, pp. 1020–1027.
[20] J. Kiusalaas, Numerical Methods in Engineering with Python, Cambridge Univ. Press, 2010.
[21] A. Kumar, Python for Education. Learning Maths & Science Using Python and Writing Them in LATEX, Inter University Accelerator Centre, New Delhi, 2010.
[22] H.P. Langtangen, Python Scripting for Computational Science, Springer-Verlag, Berlin, 2009.
[23] H.P. Langtangen, A Primer on Scientific Programming with Python, Springer-Verlag, Berlin, 2011.
[24] H.P. Langtangen, Experience with using Python as a primary language for teaching scientific computing at the University of Oslo, University of Oslo, 2012.
[25] R. Lehrer and L. Schauble, Cultivating model-based reason- ing in science education, in: The Cambridge Handbook of the Learning Sciences, Cambridge Univ. Press, 2005, pp. 371–388.
[26] G. Levy, An introduction to quasi-random numbers, in: Nu- merical Algorithms, Group, 2012.
[27] J.S. Liu, Monte Carlo Strategies in Scientific Computing, Har- vard Univ., 2001.
[28] V.E. Malishkin and V.D. Korneev, Parallel Programming of Multicomputers, Novosibirsk Technical Univ., Novosibirsk, 2006.
[29] N. Matloff, Programming on Parallel Machines: GPU, Multi- core, Clusters and More, University of California, 2012.
[30] M. Milrad, J.M. Spector and P.I. Davidsen, Model facilitated ?learning, in: Instructional Design, Development and Evalua- ?tion, Syracuse Univ. Press, 2003.
[31] S. Minkevic?ius, On the law of the iterated logarithm in multi- phase queueing systems, Informatica II (1997), 367–376.
[32] S. Minkevic?ius and V. Dolgopolovas, Analysis of the law of the iterated logarithm for the idle time of a customer in multiphase ?queues, Int. J. Pure Appl. Math. 66 (2011), 183–190.
[33] Model-Centered Learning, Pathways to mathematical under- standing using GeoGebra, in: Modeling and Simulations for Learning and Instruction, Sense Publishers, The Netherlands, ?2011.
[34] C.R. Myers and J.P. Sethna, Python for education: Computa- tional methods for nonlinear systems, Computing in Science & Engineering 9 (2007), 75–79.
[35] H. Niederreiter, Random Number Generation and Quasi- Monte Carlo Methods, SIAM, 1992.
[36] F.B. Nilsen, Queuing systems: Modeling, analysis and simu- lation, Department of Informatics, University of Oslo, Oslo, 1998.
[37] R.P. Sen, Operations Research: Algorithms and Applications, PHI Learning, 2010.
[38] F. Stajano, Python in education: Raising a generation of native speakers, in: 8th International Python Conference, Washing- ton, DC, 2000, pp. 1–5.
[39] J. Sztrik, Finite-source queueing systems and their applica- tions, Formal Methods in Computing 1 (2001), 7–10.
[40] L. Xue, Modeling and simulation in scientific computing ed- ucation, in: International Conference on Scalable Computing and Communications, 2009, pp. 577–580.
Комментарии (7)
maslyaev
28.01.2018 14:14Перевод аспирантской публикации 2014-го года?

sattvadigit Автор
29.01.2018 18:53Перевод научной статьи 2014 года — всё верно. Насчёт научной степени авторов подсказать не смогу, возможно аспиранты, а возможно уже и имели научную степень при написании данной статьи.

xinQ
29.01.2018 18:57Система массового обслуживания требуют:
- сбора и анализа информации на основе знаний в области теории вероятностей с использованием большего количества вычислительных ресурсов для изначальной статистической модели базы данных;
- имитационной модели с применением концепций объектно-ориентированного программирования (в данном случае нам предлагают базовый курс ООП на Python на модели мульти-фазной не линейной СМО на основе решений рекуррентных соотношений по уравнению с функцией «max», но с ее граничной проверкой по фактическим параметрам статистической и линейной модели).
- программистов-техников с хорошей мотивацией.
Как итог: а еще теория вероятностей нужна для найма мотивированных программистов-техников по подгону решений рекуррентных уравнений под статистические данные?
sattvadigit Автор
29.01.2018 19:04Так как этот является переводом, я не делаю дальнейших выводов насчёт представленных исследований. Моя цель отличается, но средства схожи. И данную статью можно использовать в своих исследованиях, взяв за основу некоторые принципы и подходы, описанные в ней.
xinQ
30.01.2018 21:16А где еще более простые поведенческие модели?
Видимо их должны найти программисты-техники по теории вероятностей с подстановкой решений рекуррентных уравнений под статистические данные по теореме Байеса, то есть по принципу работы нейронных сетей, которые отсекают ненужный перебор вероятностей, то есть так находят поведенческих модели?
anger32
Более полувека назад придумана замечательная штука, которая называется Variance reduction. От ее классической трактовки произрастают такие не менее замечательные методы, как: Common Random Numbers, Antithetic variates, Control variates, Stratified sampling, Latin hypercube sampling (LHS) и многие другие.
На подавляющем большинстве реальных задач они сводят к нулю необходимость городить кластер или организовывать параллельные вычисления. В части стат. моделирования в статье раскрыт лишь инженерный подход, к сожалению.
sattvadigit Автор
Спасибо, это нужная информация, изучу и, возможно, применю эти подходы! А в части статистического моделирования в части «лишь инженерный подход» вы подразумеваете отсутсвие теоретических выкладок?