

Классическими средствами защиты от brute-force являются утилиты типа fail2ban, работающие по принципу: много запросов — один источник. Это не всегда может помочь заблокировать нарушителя, а также может привести к ложным (false-positive блокировкам). В этой статье я напишу про плюсы и минусы классических средств защиты и о возможностях интеллектуальной блокировки атак.
Brute-force
«Brute-force» атака базируется на одноимённом математическом методе («brute force»), в котором правильное решение — конечное число или символьная комбинация находится посредством перебора различных вариантов. Фактически каждое значение из заданного множества потенциальных ответов (решений) проверяется на правильность.
«Brute-force» атака или атака «перебором по словарю», это такой тип атаки на веб-приложение, при котором атакующий перебором значений учетных записей, паролей, сессионных данных и т.д. пытается получить доступ к веб-приложению либо данным.
Основные минусы классических средств защиты
Я ни в коей мере не хочу преуменьшить значение fail2ban, но на мой взгляд такие решения обладают рядом существенных недостатков.
1. Один источник атаки — множество запросов. Такая политика даст предотвратить «атаку в лоб», но в то же время пропустит распределенный brute-force со множества IP-адресов (например с использованием proxy-листов). Также такая политика может заблокировать излишне «ретивого» поискового бота и т.д.
2. Не учитывается контекст запроса: обычные системы защиты не учитывают направление запроса — множественные запросы GET-запросы /somefile, POST-запросы к форме авторизации, либо парсинг каталога товаров — блокировка произойдет при превышении выставленного лимита запросов за промежуток времени из одного источника, что с большей долей вероятности приведет к false-positive блокировкам.
Интеллектуальное выявление атак
Для того, чтобы минимизировать количество ложных срабатываний и выявления реальных brute-force атак были реализованы два механизма: первый позволяет выявлять input-поля веб-приложения для выявления точных зон, подверженных brute-force атакам (это позволяет более точно настроить защиту веб-приложения). Второй модуль выявляет схожесть запросов, отправленных к веб-приложению.
Например brute-force атака с помощью burp suite со словарем 10k_most_common.txt (10.000 наиболее популярных паролей) покажет 88% схожести запросов и будет заблокирована:
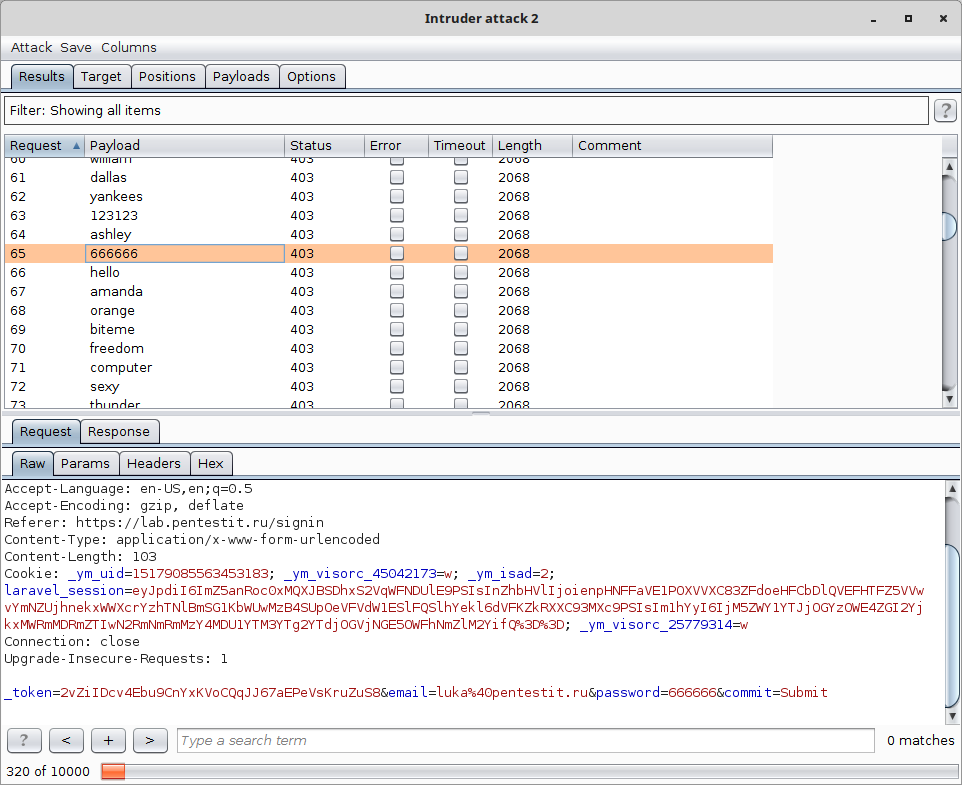
Подход к выявлению атак перебора пароля базируется на расчете взаимного расстояния между запросами, поступающими к веб-приложению (через Nemesida WAF), а также производится учет источников и зон. В качестве метрики для расчета меры близости было выбрано расстояние Левенштейна. Настраивается интервал наблюдения, минимально необходимое количество запросов и пороговое значение меры близости этих запросов.

Расстояние Левенштейна (также редакционное расстояние или дистанция редактирования) между двумя строками в теории информации и компьютерной лингвистике — это минимальное количество операций вставки одного символа, удаления одного символа и замены одного символа на другой, необходимых для превращения одной строки в другую.
Консолидация классических принципов блокировок с использованием принципов интеллектуального выявления атак даст возможность защитить веб-приложение от атак с использованием автоматизированных систем (как наиболее эффективных в brute-force атаках). Защиту от «ручного» перебора паролей, который подвержен большой доле энтропии такими средствами обеспечить нельзя, в данном случае необходимо настраивать веб-приложение, учитывая количество неверно введенных паролей за разумную единицу времени.
Комментарии (10)
pansa
06.02.2018 21:31Если хост отвечает по ipv6, то для " распределенной" атаки и ботнет не нужен, благо при желании получаем /48 и поехали. Как показывает практика, даже алгоритмы антибрутфорса яндекса легко соглашаются, что запрос пришел с нового адреса. :)

Frankenstine
07.02.2018 09:35Разбавляем брутфорс нормальными запросами и обходим защиту.

LukaSafonov Автор
07.02.2018 10:14Расстояние Левенштейна рассчитывается не между соседними запросами, а за интервал времени, который позволит выявить brute-force атаку.
Frankenstine
07.02.2018 12:24То есть, если за этот интервал пороговое количество пользователей с слабыми паролями опечатаются при вводе, система распознает их как атаку? :)
И как насчёт DDoS атаки за счёт большого количества запросов за время этого интевала?

TrllServ
07.02.2018 10:05А старое доброе увеличение интервала ввода на каждый следующий пароль для аккаунта после 3й ошибки — сильно устарело?
LukaSafonov Автор
07.02.2018 10:05К сожалению не все веб-разработчики следуют лучшим практикам защиты веб-приложений.
Antislovoblud
07.02.2018 14:07? Про интеллектуальность, цитата: «…интеллектуальная защита от brute-force атак…».
> Термин «интеллектуальный» происходит от ново-латинского intellectualis – понимать.
Основные характерные свойства интеллекта:
- наличие познания – изучение внешнего и внутреннего мира, осознавая его
- синтез алгоритмов – действия не по пред заданной логике
- синтез знаний – выведение новых знаний из уже имеющихся
Ваша статья об интеллектуальной системе есть дезинформация, а выражаясь обывательски – маркетинговое блаблабла.
Техническое неинтересна – нет информационно ценностного контекста.
Я таки пожелаю Вам удачи: продуцируйте квази-деятельность генерируя подобные статьи.
PS: Можно ли попугая Жако научить говорить E=mc2? Можно. Это знания? Да. А он осознаёт? Нет.
Loki3000
08.02.2018 17:06базируется на расчете взаимного расстояния между запросами, поступающими к веб-приложению (через Nemesida WAF), а также производится учет источников и зон.
Вы же в самом начале сказали что атака у нас распределенная и никакой связи между атакующими узлами нет? Если связь есть, то и fail2ban справится…
trigun117
А если будет пауза, скажем через каждые 100 запросов с разных источников, и словари будут генерироваться, а не готовые которые по интернету гуляют.
LukaSafonov Автор
Он будет заблокирован при старте brutt-force атаки, а не к 100 запросам. От типа и вида словарей блокировка не зависит.