

Эта статья — вольный пересказ доклада, который я посетил на конференции GOTO Berlin 2017: A Crystal Ball to Prioritize Technical Debt.
Изображения из доклада и права на них принадлежат автору @AdamTornhill.
Каждый разработчик в принципе понимает, что такое технический долг. Что в его проекте этот долг наверняка присутствует. Если повезет, он вспомнит несколько кусков кода, которые давно просятся быть переписанными.
Но как формализовать понятие технического долга, чтобы объяснить его другим? И, тем более, объяснить это менеджеру так, чтобы получить одобрение на рефакторинг? Как найти все места в проекте, которые нужно по-хорошему переписать, и как определить, какие из них должны быть переписаны в первую очередь?
Если эти вопросы неоднократно у вас возникали, прошу под кат.
Не весь коряво написанный код по определению является техническим долгом. Конечно, если есть такой код, то его лучше рано или поздно переписать. Но все мы знаем, что полировать код можно чуть ли не до бесконечности. Как же определить, какой код является техническим долгом?
Довольно хорошее описание технического долга дал Мартин Фаулер:
Like a financial debt, the technical debt incurs interest payments, which come in the form of the extra effort that we have to do in future development because of the quick and dirty design choice.То есть, чем больше усилий во время разработки мы затрачиваем из-за какого-то куска кода, тем большим техническим долгом он является. С этим сложно не согласиться, но все же этого недостаточно для того, чтобы четко определить, какие места должны быть переписаны.
Для того, чтобы оценить, насколько каждый конкретно файл/класс/функция затрачивает наши усилия при разработке, Адам вводит такое понятие, как горячие точки, Hotspots. И для поиска этих хотспотов нужен только один инструмент, который есть практически у каждого разработчика — система контроля версий.

Оценить количество усилий на поддержку файла с кодом можно, взглянув на то, как часто этот файл меняется, и на то, какая сложность у этого файла. С оценкой частоты изменений все однозначно и понятно. Сложность можно оценить разными способами, в зависимости от ваших предпочтений. В простейшем случае это может быть размер файла или количество строк кода. При прочих равных условиях поддерживать файл на 100 строк кода сильно проще, чем файл на 1000 строк кода. Если же размер файла в вашем случае не является критерием оценки сложности, можно воспользоваться различными утилитами для статической оценки сложности (например, цикломатической).
Тогда хотспоты можно будет выявить следующим образом:

Вот пример поиска горячих точек в проекте Tomcat:

Большие синие круги — это папки. Маленькие — файлы.
При всем этом, наличие хотспота совсем не означает, что этот файл проблемный (но чаще всего так и есть). Это означает, что в этих файлах вы проводите больше всего времени. И что при рефакторинге эти файлы должны быть первыми в списке, чтобы убедиться, что код там чистый, легко поддерживаемый и расширяемый.
Также в качестве примера приводятся графики анализа кода нескольких проектов, разных насколько это возможно. Разные языки, разное время жизни, разные компании-разработчики. По оси X у нас расположены файлы, по оси Y — частота их изменений.
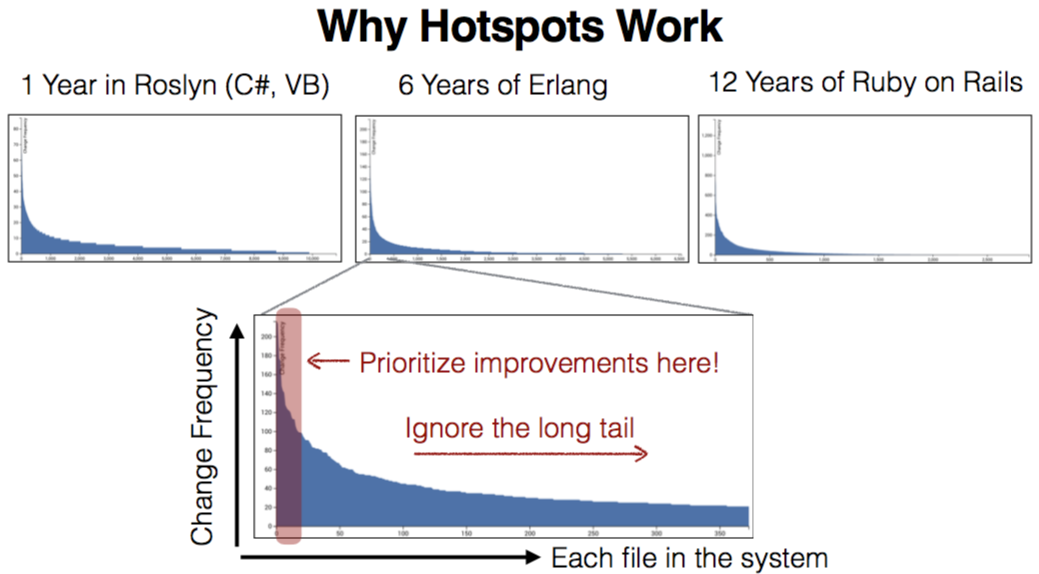
У всех проектов наблюдается один и тот же паттерн. Большая часть кода расположено в «хвосте» графика. И соответственно, есть очень небольшая часть файлов, которые изменяются очень часто. Эти файлы тоже являются первыми кандидатами для рефакторинга.
При поиске хотспотов можно пойти глубже. И в проблемных файлах искать хотспоты уже на уровне отдельных функций:

Инструмент, который был использован для поиска таких хотспотов — codescene.io
Также полезной практикой будет регулярной отслеживание сложности вашего кода. Анализ таких данных в виде графиков будет очень наглядно показывать, в какие моменты вы сбились с верного пути.

Итоги
Мне этот доклад показался полезным в первую очередь из-за четкого определения технического долга и его размера.
Понятно, что чтобы заниматься таким серьезным анализом кода с выявлением хотспотов, это нужно очень сильно увязнуть в технических долгах. Но даже на базовом уровне, в повседневной работе, я стал обращать внимание на классы, которые чаще всего затрагиваю, и стараюсь такие классы потихоньку рефакторить.
Также, в качестве бонуса (был вопрос из зала на докладе), Адам рассказал, как правильно доносить до менеджмента необходимость в рефакторинге. Чаще всего менеджеры — не технические люди, довольно далекие от кода, иначе бы проблем не возникло. Но что эти люди хорошо понимают — это цифры и графики. Чтобы правильно донести до них информацию, нужно говорить с ними на одном языке. И как раз графики с хотспотами и временной зависимостью сложности кода могут тут помочь. На графиках можно показать, что вот такой-то функционал, который мы добавили недавно, сильно усложнил добавление новых фич. Следовательно, если мы в дальнейшем хотим ускорить темпы разработки, нужно потратить сколько-то времени на рефакторинг.
Полезные ссылки:
- Новая книга Адама про анализ кода и архитектуры
- Статья, в которой понятие хотспотов тоже описано, но, как мне показалось, описано побочно. Мне же хотелось сделать упор на поиск проблемных мест и их связь с техническим долгом
- Видеозапись самого доклада
Комментарии (22)
VolCh
14.02.2018 17:33+1В качестве наблюдения: Пробовал анализировать по частоте изменения и цикломатической сложности. Выявилось, что чаще изменяются не куски с большой сложностью, а их клиенты, причём с нарастанием сложности. Проще говоря, сложные непонятные, но точечные куски кода начинают обрастать не менее сложными обёртками, основное назначение которых обычно сводится к обработке особых случаев или новых кейсов. Причём есть тенденция к многослойности таких обёрток, зачастую с повторением во внешних слоях логики, которая уже есть на внутреннем слое, но к которой не пробиться через уже существующие обёртки.
Грубо (псевдокод):function someComplex(a, b, c) { // some very complex code } function someComplexWithSimpleCase (a, b, c) { if (a === 0 ) { // some simple code } else { someComplex(a, b, c); } } function adminComplex(user, a, b, c) { if (user !=== 'admin' ) { if (a === 0) { // another simple code } else { someComplexWithSimpleCase(a, b, c); } } else { // the same very complex code } }
Singaporian
16.02.2018 11:11Люто-бешенно плюсую.
Пример: у нас есть огромный монстр на несколько десятков тысяч строк кода, где внутри ant вызывает maven через bash, а тот в свою очередь обратно ant с помощью десятка захардкоженных паролей (и это, на минуточку, банк). Этот код творил сам Сатана.
Он не меняется, но является стандартом. Все, что он делает — «автоматизирует» работу maven, curl и прочих простых инструментов. Он никому совершенно не нужен.
Все, чем мы заняты круглые сутки — мы привинчиваем свой maven так, чтобы он делал свою работу, но передавал этому монстру пустышку и якобы тот работал тоже.
При этом монстра никто не меняет. Он по всем метрикам идеальный код…
Я вчера уволился к черту со словами: «я не могу больше делать непрофессиональную работу». Ничего не изменилось. Идеальный монстр все равно не был признан техническим долгом. Он будет там, даже когда человечество сбежит из-за него на Марс.

Mishiko
14.02.2018 18:08+2Тоже поделюсь наблюдением: имеется некий продукт с большим количеством не документированных классов и частой сменой команды разработчиков. Новые разработчики не имея времени и желания исследовать чужой код, при внедрении фич, лепили собственный код, дублирующий уже имеющийся функционал. Потребность в рефакторинге очевидна, но предложенная метрика, основанная на частоте изменений в файлах, ничего подозрительного не покажет.
Можно даже предположить, что там где часто изменяют одни и те же файлы, фактически происходит рефакторинг, а там, где старый код долго остается неизменным, есть какая то проблема)
amakhrov
15.02.2018 09:15+1Потребность в рефакторинге очевидна
А вот неочевидна, кстати. Потребность эта появится тогда, когда при дальнейшей поддержке придется вносить изменения в несколько мест сразу. И когда пойдут ошибки из-за того, что частенько забывают изменить везде.
А вот если этот дублирующий код изменяться в дальнейшем будет редко (или вообще никогда), то и рефакторить его по большому счету незачем. Ну, разве что из чувства прекрасного.
Mishiko
15.02.2018 11:16Очевидно)
- Повторное написание кода — лишние трудозатраты
- Дублирование кода — усложнение продукта, ухудшение его понятности
- Дублирование кода — путь к труднообнаружимым ошибкам, которые сложно устранять (в разных ситуациях работает разный код с одними и теми же данными)
amakhrov
15.02.2018 11:25Не-не-не :)
- Повторный код УЖЕ написан. Оставить его как есть — ноль трудозатрат. Рефакторинг — лишние трудозатраты.
- Усложнение продукта. Ну и ладно, работает — не трогай :)
- Путь к ошибкам. Будут ошибки — рассмотрим необходимость рефакторинга. Рефакторинг тоже может быть источником ошибок (я уверен, что нездоровая ситуация, описанная выше, также подразумевает недостаточное покрытие тестами).
VolCh
15.02.2018 11:36С большой вероятностью, если повторный код уже написан второй раз, то он будет писаться и третий, и четвёртый. Причём с бОльшей чем второй: кроме факторов "вроде этого ещё нет" и "что-то похожее есть, но не разобрался, поэтому напишу своё", появляется фактор "кажется тут принято каждый раз писать заново вместо изменения"
amakhrov
15.02.2018 11:50Кстати, на третий раз выделить повторяющийся код в абстракцию проще, чем во второй.
Точнее говоря, выделить, может и не проще. Но сама абстракция, скорее всего, будет более правильная.
При втором написании того же кода совсем не всегда понятно, что же все-таки является общим случаем решаемой проблемы.
Я в ряде случаев предпочитаю на второй раз скопировать, а на третий уже отрефакторить.

Kane
15.02.2018 11:57Это не так очевидно.
- Иногда скопировать кусок кода и внести небольшую правку проще, чем добавить новую функциональность к существующему коду.
- Очень часто добавление новой функциональности к существующему коду усложняет и ухудшает его понятность.
В целом мне кажется, что дублирование допустимо, если продублированный код опирается на общий код нижележащего уровня.
Mishiko
15.02.2018 12:11Когда я вижу дублирование кода, я занимаюсь рефакторингом) Лично для меня дублирование кода противоестественно, хотя Вашу аргументацию я понимаю.
Kane
15.02.2018 13:16Есть мнение, что неправильная абстракция хуже чем дублирование кода. Проблема в том, что заметить правильную абстракцию может быть сложно пока дублирования не достаточно много.
VolCh
15.02.2018 11:33Не только для изменений нужен рефакторинг. Вовремя проведенный и удачный рефакторинг предотвратит появление дублирующегося кода. Проще говоря, не будет дважды, трижды и более раз тратиться время разработчиков на разработку одного и того же, лишь потому что они не поняли, что это уже реализовано или догадывались, что реализовано, но не нашли.
Есть такой метод добавления и даже изменения фич, при котором изменения практически не вносятся — внедряемся в интересующий флоу на самом нижнем месте, которое мы понимаем и пишем там новый с нуля, обходя старый при некоторых условиях. Фича доставлена, изменено несколько строк, добавлен несколько тысяч из которых большинство дублируют имеющийся код. И хорошо если дублируют так, что этот дубль вылавливается методами автоматизированного статического анализа. А если дублируется только функциональность, а реализована она совсем разными способами и обнаружить дублирование можно только путём полного анализа кодовой базы, то, скорее всего, дублирование будет идти дальше.
amakhrov
15.02.2018 11:46Вовремя проведенный и удачный рефакторинг предотвратит появление дублирующегося кода
Вопрос только в том, был ли данном сценарии технический долг вообще? Написали код без оглядки на повторное использование — и все было хорошо, повторно использовать не надо. Поменялись требования, надо использовать повторно — рефакторим, переиспользуем. В какой момент у нас имел место технический долг?
не поняли, что это уже реализовано или догадывались, что реализовано, но не нашли
А это даже не всегда определяется качеством кода. Это может быть результатом документации / процессов (или их отсутствия).
Ну и наконец можно дискутировать о вреде дублирующегося кода в общем случае :)
VolCh
15.02.2018 12:00В какой момент у нас имел место технический долг?
Самое позднее — в момент появления новых требований. Если следовать принципу "разработчик должен предвидеть изменения требований", то в момент когда написали код без оглядки на повторное использование.
А это даже не всегда определяется качеством кода.
Одна из основных целей рефакторинга — увеличение самодокументируемости кода.
Mishiko
15.02.2018 11:50- «Повторный код уже написан» — плохо, но еще хуже если его еще раз продублировать (т е написать то же самое в третий, четвертый раз)
- «работает — не трогай» — каждая новая фича дается все тяжелей, устранение простых, на первый взгляд, багов требует много времени
- Отсутствие тестов или их низкое качество, также можно отнести к техническому долгу. Автотесты (на прктике) не могут выявить все ошибки. Естественно, что найденную ошибку придется устранить, но никто не гарантирует, что устраняя ошибку в одном месте, тем самым не создаешь ее в другом.
Обо всем этом много уже написано: Роберт Мартин «Чистый код», Мартин Фаулер «Рефакторинг» и т д. Думаю, что в этих книгах можно найти гораздо больше аргументов на тему «почему» надо писать чистый код. Хотя, конечно, все зависит от продукта и установок в команде — если команда слышит что продукт никому не нужен, а самих программистов завтра выгонят, ну и конечно незабываемое — «это надо было сделать вчера», то все это не стимулирует разработчиков писать качественный код. Часто менеджер однодневка своим общением с командой закладывает мину в продукт.
zenkz
15.02.2018 18:13На мой взгляд необходимость рефакторинга — понятие очень субъективное и если какой-то кусок кода вызывает боль у разработчика, то его задача поднять вопрос о рефакторинге этого куска кода.
Количество изменений в системе контроля версий не всегда является корректным показателем.
Я бы скорее смотрел на:
— Количество строк в файле/классе (если больше 2000, то скорее всего нужен рефакторинг)
— Количество условий и циклов (чем больше, тем больше вероятность, что нужен рефакторинг)
— Количество дублирующихся блоков кода (часто идёт вместе с предыдущим пунктом)
— Для добавления нового функционала необходимо исправлять код во многих местах (не всегда очевидных)
— Количество обращений от поддержки на исправление ошибок в одной фиче.
Mishiko
Критерий «количество усилий на поддержку файла с кодом» мне кажется частным случаем в оценке технического долга и слабым аргументом для менеджера с которым придется эту проблему обсуждать.
Более существенно количество паразитных трудозатрат (отношение объема нового кода к объему переписанного кода, объем регрессионного тестирования) при добавлении фич. В продукте с большим техническим долгом внедрение фич вызывает непропорционально большие трудозатраты и чем дольше копится этот долг, тем выше сложность/цена внедрения нового функционала.
esin Автор
Не совсем понимаю разницу между «усилиями на поддержку» и «паразитными трудозатратами» применительно к конкретному файлу при добавлении нового функционала. Разве это не одно и то же?
Mishiko
Я имел в виду, что оценка основанная на "файлах" это частный случай (взгляд программиста), а "продукт" (взгляд менеджера) — это не только код, но и тестирование, и интеграционные решения. Например, изменив тип аргумента в одном из методов web-сервиса я произведу малозаметные, с точки зрения «файла» изменения, с чудовищными последствиями для «продукта» — типа труднообнаружимых ошибок (если мы не побеспокоились заранее об интеграционных тестах) и необходимости доработок в приложениях интегрирующихся с нашим API. Этот пример не удачен с точки зрения темы рефакторинга, но он показывает что объем трудозатрат при внедрении фичи для продукта в целом может слабо коррелироваться с количеством измененных файлов или строк кода. Т е сама методика оценки объема технического долга, основанная на подсчете количества изменений в коде и частоте изменений в файлах может быть верной для некоторых продуктов, а для других продуктов эта методика не даст реальной картины.
amakhrov
При взшляде со стороны продукта правильными метриками могут служить:
Mishiko
— фичу добавили и забыли про нее, больше с ней не работают. Разве что какие то ошибки вылезут. Но добавление каждой новой фичи требует все больше усилий со стороны команды.
— добавил код, который меняет данные, ошибка вылезла совсем в другом месте, где раньше все нормально работало (ужас еще в том, что поскольку это место совсем другое, то проблем там не ждешь и это место не тестируется — тут спасет только полный регресс тест, а это время и деньги).
amakhrov
Согласен. Но все же уточню.
При такой трактовке, правда, область проблемного кода определяется более широко. Может служить, скорее, как руководство для долгосрочного планирования, нежели решение по тактическому локальному рефакторингу.