
 По статистике 1-4 % населения Земли подвержены дефекту речи, характеризующимся частой пролонгацией звуков (слогов, слов) и/или частыми остановками в речи, нарушающими ритмическое ее течение. В простонародье этот феномен известен как заикание.
По статистике 1-4 % населения Земли подвержены дефекту речи, характеризующимся частой пролонгацией звуков (слогов, слов) и/или частыми остановками в речи, нарушающими ритмическое ее течение. В простонародье этот феномен известен как заикание.На данный момент мир не знает панацеи, на 100 % избавляющей от заикания, однако существует преинтереснейший метод, позволяющий с тем или иным успехом купировать это речевое нарушение у большинства заикающихся. Метод основан на эффекте Ли, заключающемся во влиянии задержки акустической слуховой афферентации на плавность речи, и носит название DAF (Delayed Auditory Feedback).
Ниже рассмотрим пример построения на коленке простого генератора речевой обратной связи силами Python и PyQt. У-у-ух, it's gonna be fun!
Что к чему и почему
Эффект Ли, названный в честь инженера-подводника Бернарда Ли, (Lee, 1951 г.) проявляется в том, что у обычного человека прослушивание через наушники собственной речи, задержанной с помощью специальной аппаратуры на 80-200 мс, (непосредственно в момент разговора) вызывает запинки, очень напоминающие заикание. В то же время на человека, подверженного заиканию, эффект Ли оказывает прямо противоположное воздействие. На этом строится метод DAF. Смысл задержки воспроизведения речи в наушниках заключается в синхронизации работы речевых центров — слухового центра Вернике и речедвигательного центра Брока (криптометафора: задержка = функция генерации гаммы для самосинхронизирующегося шифра потока). Проведение различных исследований позволило выявить, что задержка в диапазоне 50-75 мс позволяет уменьшить заикание на 60-80% при нормальной и ускоренной речи. Задержка в 190 мс оказалась чуть более эффективной, чем 75 мс, однако оптимальная величина задержки выбирается индивидуально исходя из ощущений испытуемого.
Идея аппаратного подхода к нормализации речи стара как мир — первый прибор, работающий по принципу «регуляции обратной связи», был сконструирован в 1959 г. Будучи большим, проводным и неуклюжим, он представлялся малоэффективным для использования в повседневной жизни, однако технологии не стоят на месте, и сейчас существует целый ряд способов удобной генерации DAF: как с помощью отдельных мини-девайсов, так и в виде софтин для Ведроида, Аппле (поиск по ключевому слову «DAF» в своем магазине приложений покажет всю выборку таких решений) и ПК (тут сложнее, смотрим следующий абзац).
Зачем сей пост
Стоимость приложений для мобильных платформ варьируется в пределах нескольких долларов. Допустимо. Однако для Windows существует всего одна подобная программа стоимостью $30 за базовую версию для «personal needs only» (название приводить не буду — лежит по тому же ключевому слову на первой ссылке поисковика). Здесь мне стало интересно, во сколько строк кода встанет самопальная реализация столь тривиального функционала. Результатом этого интереса стало одинокое окно GUI-интерфейса, скрывающее под капотом простой DAF-генератор, которым хочу поделиться с окружающими — авось кому пригодится.
Trial. CLI-интерфейс
Для начала набросаем концепт в виде пробного CLI-приложения. Будем использовать связку "Python3 + PyAudio", где PyAudio — модуль для работы со звуком. Ядро будет выглядеть так:
CHANNELS = 2
RATE = 44100
def genDAF(delay):
bufferSize = floor(delay / 1000 * RATE)
device = PyAudio()
try:
streamIn = device.open(format=paFloat32,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=bufferSize)
streamOut = device.open(format=paFloat32,
channels=CHANNELS,
rate=RATE,
output=True,
frames_per_buffer=bufferSize)
except OSError:
print('genDAF: error: No input/output device found! Connect and rerun')
return
print('CTRL-C to stop capture')
while streamIn.is_active():
start = clock()
audioData = streamIn.read(bufferSize)
streamOut.write(audioData)
actualDelay = floor((clock() - start) * 1000)
print('Actual Delay: {} ms'.format(actualDelay))
Процедура genDAF принимает величину задержки в миллисекундах, вычисляет необходимый размер буфера (исходя из оптимального битрейта в 44,1 кГц) для записи голоса, после чего, если имеются подключения на ввод и вывод аудио (aka микрофон и динамики), создает два потока, входной и выходной соответственно. Далее в основном цикле начинается чтение и мгновенное воспроизведение записанного куска аудио данных, при этом на фоне подсчитывается реальная задержка, потребовавшаяся для выполнения пары операций read/write. На все ушло ~ 20 строк кода.
Полный исходник для CLI-приложения под спойлером:
dafgen_cli.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Run: python3 dafgen_cli.py <delay_in_ms>
from pyaudio import PyAudio, paFloat32
from math import floor
from time import clock
import sys
CHANNELS = 2
RATE = 44100
def genDAF(delay):
bufferSize = floor(delay / 1000 * RATE)
device = PyAudio()
try:
streamIn = device.open(format=paFloat32,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=bufferSize)
streamOut = device.open(format=paFloat32,
channels=CHANNELS,
rate=RATE,
output=True,
frames_per_buffer=bufferSize)
except OSError:
print('genDAF: error: No input/output device found! Connect and rerun')
return
print('CTRL-C to stop capture')
while streamIn.is_active():
start = clock()
audioData = streamIn.read(bufferSize)
streamOut.write(audioData)
actualDelay = floor((clock() - start) * 1000)
print('Actual Delay: {} ms'.format(actualDelay))
def main():
if len(sys.argv) != 2:
print('usage: python3 {} <delay_in_ms>'.format(sys.argv[0]))
sys.exit(1)
try:
delay = int(sys.argv[1])
except ValueError:
print('main: error: Invalid input type')
sys.exit(1)
if not 50 <= delay <= 200:
print('main: error: Delay must be in [50; 200] ms')
sys.exit(1)
print('Delay: {} ms\n'.format(delay))
try:
genDAF(delay)
except KeyboardInterrupt:
print('Stopped')
if __name__ == '__main__':
main()
Final. GUI-интерфейс
Зелёные буквы на чёрном фоне терминала — романтично, но не всегда удобно, мы можем лучше. Приплюсуем к нашей связки инструментов фреймворк для графики, получится "Python3 + PyAudio + PyQt5".
Набросаем в дизайнере пару-тройку кнопок, слайдер и 2 текстовых поля:
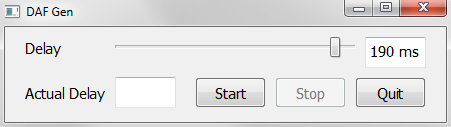
Добавим логики, распределив основной код генерации DAF по двум классам: управляющее приложение (MainApp) и класс для отдельного потока (Worker), ответственный за выполнение цикла while метода _genDAF, дабы не висло основное окно. Полный код приведен в конце параграфа, а сейчас только главная часть.
Управляющее приложение:
class MainApp(QMainWindow, Ui_DAFGen):
_CHANNELS = 2
_RATE = 44100
def __init__(self):
super().__init__()
self.setupUi(self)
# ...
# ...
def _startCapture(self):
bufferSize = floor(self.delaySlider.value() / 1000 * self._RATE)
device = PyAudio()
try:
streamIn = device.open(format=paFloat32,
channels=self._CHANNELS,
rate=self._RATE,
input=True,
frames_per_buffer=bufferSize)
streamOut = device.open(format=paFloat32,
channels=self._CHANNELS,
rate=self._RATE,
output=True,
frames_per_buffer=bufferSize)
except OSError:
QMessageBox.critical(self, 'Error', 'No input/output device found! Connect and rerun.')
return
self._workerThread = Worker(bufferSize, streamIn, streamOut)
self._workerThread._trigger.connect(self._updateActualDelay)
# ...
self._workerThread.start()
Второй поток:
class Worker(QThread):
_trigger = pyqtSignal(float)
def __init__(self, bufferSize, streamIn, streamOut):
QThread.__init__(self)
self._bufferSize = bufferSize
self._streamIn = streamIn
self._streamOut = streamOut
def __del__(self):
self.wait()
def _genDAF(self):
while self._streamIn.is_active():
start = clock()
audioData = self._streamIn.read(self._bufferSize)
self._streamOut.write(audioData)
actualDelay = clock() - start
self._trigger.emit(actualDelay)
def run(self):
self._genDAF()
Исходник для логики GUI-приложения под спойлером:
dafgen.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from PyQt5.QtWidgets import *
from PyQt5.QtCore import *
from ui_dafgen import Ui_DAFGen
from pyaudio import PyAudio, paFloat32
from math import floor
from time import clock
import sys
class Worker(QThread):
_trigger = pyqtSignal(float)
def __init__(self, bufferSize, streamIn, streamOut):
QThread.__init__(self)
self._bufferSize = bufferSize
self._streamIn = streamIn
self._streamOut = streamOut
def __del__(self):
self.wait()
def _genDAF(self):
while self._streamIn.is_active():
start = clock()
audioData = self._streamIn.read(self._bufferSize)
self._streamOut.write(audioData)
actualDelay = clock() - start
self._trigger.emit(actualDelay)
def run(self):
self._genDAF()
class MainApp(QMainWindow, Ui_DAFGen):
_CHANNELS = 2
_RATE = 44100
def __init__(self):
super().__init__()
self.setupUi(self)
self.stopButton.setEnabled(False)
self._updateDelay()
self.delaySlider.valueChanged.connect(self._updateDelay)
self.startButton.clicked.connect(self._startCapture)
self.stopButton.clicked.connect(self._stopCapture)
self.quitButton.clicked.connect(QApplication.quit)
def _updateDelay(self):
self.delayEdit.setPlainText(str(self.delaySlider.value()) + ' ms')
def _startCapture(self):
bufferSize = floor(self.delaySlider.value() / 1000 * self._RATE)
device = PyAudio()
try:
streamIn = device.open(format=paFloat32,
channels=self._CHANNELS,
rate=self._RATE,
input=True,
frames_per_buffer=bufferSize)
streamOut = device.open(format=paFloat32,
channels=self._CHANNELS,
rate=self._RATE,
output=True,
frames_per_buffer=bufferSize)
except OSError:
QMessageBox.critical(self, 'Error', 'No input/output device found! Connect and rerun.')
return
self._workerThread = Worker(bufferSize, streamIn, streamOut)
self._workerThread._trigger.connect(self._updateActualDelay)
self.startButton.setEnabled(False)
self.delaySlider.setEnabled(False)
self.stopButton.setEnabled(True)
self._workerThread.start()
def _stopCapture(self):
self._workerThread.terminate()
self.actualDelayEdit.clear()
self.startButton.setEnabled(True)
self.delaySlider.setEnabled(True)
self.stopButton.setEnabled(False)
def _updateActualDelay(self, t):
newValue = floor(t * 1000)
self.actualDelayEdit.setPlainText(str(newValue) + ' ms')
def main():
app = QApplication(sys.argv)
win = MainApp()
win.show()
sys.exit(app.exec_())
if __name__ == '__main__':
main()
Заключение и код
Собственно всё, что хотел рассказать. Feel free to use.
Также оставлю ссылку на проект целиком: в дополнение там лежат код графического интерфейса и шаблон для PyQt Designer.
Спасибо за внимание!
Литература
Миссуловин Л. Я., Юрова М. С. Преодоление заикания у подростков и взрослых с использованием аппаратов типа «АИР» // Научно-методический электронный журнал «Концепт». – 2015. – № S23. – С. 46–50. – URL: e-koncept.ru/2015/75287.htm.
ru1z
Вот это новость! Есть какое-нибудь исследование/видео с демонстрацией эффектов?
(имею в виду публикации в более известных журналах). Чересчур хорошо звучит.
snovvcrash Автор
В списке литературы неплохая статья + на англицкой вики есть публикация на эту тему. Даже вот еще одна.
ru1z
Спасибо! С вики уже можно дальше поискать.