
Примерно год назад, мне довелось работать в одной компании, где я натолкнулся на интересную проблему. Представим себе массивный поток данных об использовании мобильных приложений (десятки миллиардов событий в день), который содержит в себе такую интересную информацию, как дату установки приложения, а также рекламную акцию, которая повлекла за собой эту установку. Имея подобные данные, можно легко разбить пользователей на группы по датам установки и по рекламным акциям, чтобы понять какая из коих была наиболее успешна с точки зрения ROI (return of investment).
Рассмотрим визуальный пример (картинка найдена на просторах интернета):
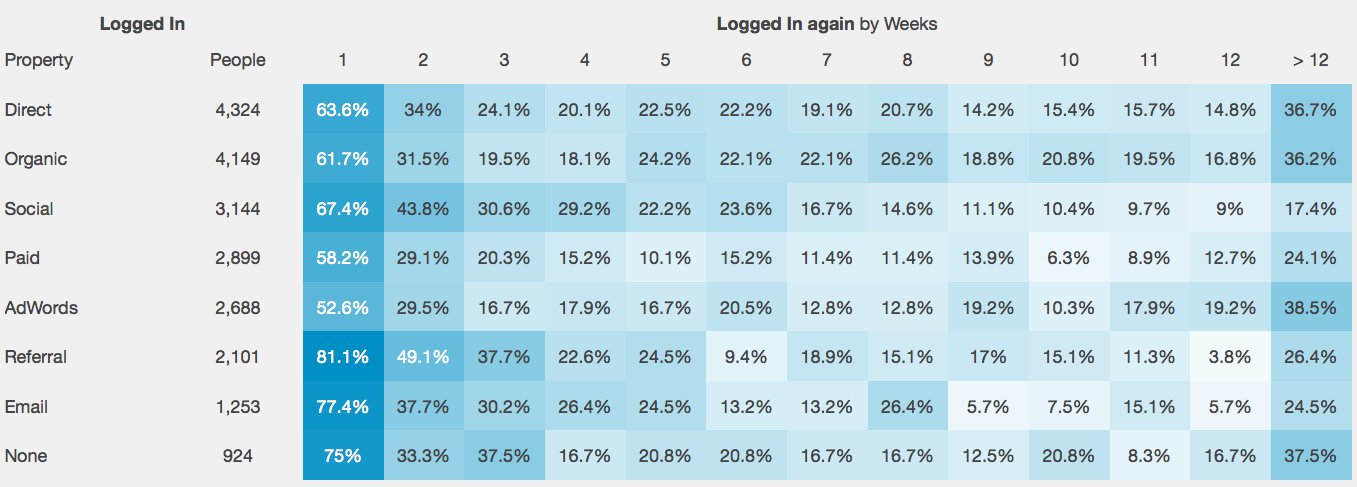
Как мы видим, пользователи пришедшие с "рекламных щитов" AdWords оказались наиболее лояльными к этому конкретному приложению (продолжали активно пользоваться приложением).
Нет сомнений, что подобные методы невозможно переоценить, когда речь идет о маркетинговой оптимизации, но рассмотрим эту проблему с точки зрения нас — инженеров по работе с данными.
Все запросы такого плана, как правило, заключают в себе условие связанное с датой установки приложения, которая не является временным рядом: в нашем потоке данных присутствуют события как с приложений установленных вчера, так и с приложений установленных 2 года назад. В переводе на язык баз данных, это означает полное сканирование данных начиная с заданной точки и вплоть до текущего времени.
Эволюция решений
Проблема усугублялась тем, что от выбранного решения требовалась поддержка множества параллельных запросов, поэтому аналитические базы данных не рассчитанные на сотни пользователей, работающих одновременно с аналитической панелью нашей компании, пришлось исключить изначально.
Поначалу, для хранения подобных данных использовался MongoDB, но очень скоро мы достигли пределов этой замечательной БД, как во время запросов, так и во время записи. Можно было, конечно, "расшардировать" все это безобразие, но из-за оперативной сложности шардирования MongoDB было решено попробовать другие решения.
Второй попыткой стал Druid, но так, как эта база данных работает с данными сортированными по времени, то это нам мало чем помогло. На самом деле, если пренебречь информацией, поступающей в реальном времени, и каждый день перестраивать базу сортируя данные по дате установки, то это может работать очень даже неплохо.
Базами данных типа Cassandra, которые требуют построения таблицы "под запрос" также пришлось пренебречь из-за желания поддерживать так называемые ad-hoc запросы, когда список полей запроса может варьироваться от пользователя к пользователю.
В итоге, все закончилось выбором MemSQL — базой данных нового поколения (NewSQL), сочетающей в себе поддержку как OLTP, так и OLAP нагрузок, благодаря современной архитектуре, а также благодаря тому, что данные находятся в памяти. Но, как мы понимаем, идеального решения не существует, а потому оставались две проблемы:
1) Скорость записи оставляла желать лучшего из-за использования WAL (write-ahead log), а нам это не особо-то и нужно было, так, как данные сохранялись на S3, и мы были готовы пожертвовать быстрым восстановлением данных ради огромной скорости записи.
2) Цена
Изобретение колеса
Тогда и задумалось написать что-нибудь свое, попроще… Например держать вектор последовательных записей статического размера в памяти, обеспечивая тем самым быстрый по ним проход и фильтрацию по заданному критерию. А еще, разбить все это на процессы, и каждому процессу присвоить свою партицию данных. Так родился ViyaDB. По сути, это аналитическая база данных, которая держит агрегированные данные в памяти в колоночном формате, что позволяет довольно быстро по ним "пробегать". Запросы транслируются в машинный код, что дает избежать ненужных ветвлений и правильнее использовать кэш процессора, при повторном запросе похожего типа.
Так выглядит архитектура ViyaDB с высоты птичьего полета:

Ниже приведен пример использования этой простенькой базы данных.
Тест драйв
Первым делом устанавливаем Consul, который координирует компоненты ViyaDB кластера. Затем, добавляем в Consul необходимую конфигурации кластера.
В ключ "viyadb/clusters/cluster001/config" пишем:
{
"replication_factor": 1,
"workers": 32,
"tables": ["events"]
}В ключ "viyadb/tables/events/config" пишем:
{
"name": "events",
"dimensions": [
{"name": "app_id"},
{"name": "user_id", "type": "uint"},
{
"name": "event_time", "type": "time",
"format": "millis", "granularity": "day"
},
{"name": "country"},
{"name": "city"},
{"name": "device_type"},
{"name": "device_vendor"},
{"name": "ad_network"},
{"name": "campaign"},
{"name": "site_id"},
{"name": "event_type"},
{"name": "event_name"},
{"name": "organic", "cardinality": 2},
{"name": "days_from_install", "type": "ushort"}
],
"metrics": [
{"name": "revenue" , "type": "double_sum"},
{"name": "users", "type": "bitset", "field": "user_id", "max": 4294967295},
{"name": "count" , "type": "count"}
],
"partitioning": {
"columns": [
"app_id"
]
}
}(последнее значение представляет собой DDL для нашей таблицы)
Устанавливаем ViyaDB на четыре амазоновских машины типа r4.2xlarge (за основу взят Ubuntu Artful образ от Canonical):
apt-get update
apt-get install g++-7
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60 --slave /usr/bin/g++ g++ /usr/bin/g++-7
cd /opt
curl -sS -L https://github.com/viyadb/viyadb/releases/download/v1.0.0-beta/viyadb-1.0.0-beta-linux-x86_64.tgz | tar -zxf -Создаем файл конфигурации на каждой из машин (/etc/viyadb/store.json):
{
"supervise": true,
"workers": 8,
"cluster_id": "cluster001",
"consul_url": "http://consul-host:8500",
"state_dir": "/var/lib/viyadb"
}(consul-host — адрес машины, на которой установлен Consul)
Стартуем базу данных на всех машинах:
cd /opt/viyadb-1.0.0-beta-linux-x86_64
./bin/viyadb /etc/viyadb/store.jsonЗагрузка данных
В базе данных присутствует базовая поддержка языка SQL. Запустим утилиту, позволяющую посылать SQL запросы в базу:
/opt/viyadb-1.0.0-beta-linux-x86_64/bin/vsql viyadb-host 5555(viyadb-host — один из четырех хостов на которых мы установили ViyaDB)
1 миллиард событий лежит на S3 в формате TSV; для их загрузки запустим команду:
COPY events (
app_id, user_id, event_time, country, city, device_type, device_vendor, ad_network, campaign, site_id, event_type, event_name, organic, days_from_install, revenue, count
)
FROM 's3://viyadb-test/events/input/'Запросы
Справедливости ради, все последующие запросы были запущены во второй раз, чтобы не учитывать время их компиляции в общее время запроса.
1) Типы сообщений и их количество для заданного приложения:
ViyaDB> SELECT event_type,count FROM events WHERE app_id IN ('com.skype.raider', 'com.adobe.psmobile', 'com.dropbox.android', 'com.ego360.flatstomach') ORDER BY event_type DESC
event_type count
---------- -----
session 117927202
install 263444
inappevent 200466796
impression 58431
click 297
Time taken: 0.530 secs2) Пять самых активных городов в штатах по количеству установок приложения:
ViyaDB> SELECT city,count FROM events WHERE app_id='com.dropbox.android' AND country='US' AND event_type='install' ORDER BY count DESC LIMIT 5;
city count
---- -----
Clinton 28
Farmington 20
Madison 18
Oxford 18
Highland Park 18
Time taken: 0.171 secs3) Десять самых активных рекламных агенств по количеству установок, опять же:
ViyaDB> SELECT ad_network, count FROM events WHERE app_id='kik.android' AND event_type='install' AND ad_network <> '' ORDER BY count DESC LIMIT 10;
ad_network count
---------- -----
Twitter 1257
Facebook 1089
Google 904
jiva_network 96
yieldlove 79
i-movad 66
barons_media 57
cpmob 50
branovate 35
somimedia 34
Time taken: 0.089 secs4) Ну и самое главное, ради чего и затевался весь этот сыр бор, это отчет о лояльности пользователей на основе индивидуальных сессий пользователей:
ViyaDB> SELECT ad_network, days_from_install, users FROM events WHERE app_id='kik.android' AND event_time BETWEEN '2015-01-01' AND '2015-01-31' AND event_type='session' AND ad_network IN('Facebook', 'Google', 'Twitter') AND days_from_install < 8 ORDER BY days_from_install, users DESC
ad_network days_from_install users
---------- ----------------- -----
Twitter 0 33
Google 0 20
Facebook 0 14
Twitter 1 31
Google 1 18
Facebook 1 13
Twitter 2 30
Google 2 17
Facebook 2 12
Twitter 3 29
Google 3 14
Facebook 3 11
Twitter 4 27
Google 4 13
Facebook 4 10
Twitter 5 26
Google 5 13
Facebook 5 10
Twitter 6 23
Google 6 12
Facebook 6 9
Twitter 7 22
Google 7 12
Facebook 7 9
Time taken: 0.033 secsЗаключение
Иногда, решая какую-нибудь очень специфическую задачу, изобретение колеса может быть оправдано. Тестирование похожего решения показало, что можно сократить расходы примерно в четыре раза по сравнению с MemSQL, при этом не теряя ничего из функционала базы. Конечно, взять и перевести многомиллионный бизнес на базу данных, написанную одним человеком совершенно неоправданно на данном этапе, а поэтому контракт с MemSQL было решено не прерывать. Код, выложенный в Github — это проект, который был начат мной с нуля, уже после ухода из вышеуказанной компании.
Комментарии (14)

NYM
28.02.2018 12:07Рассматривали ли clickhouse? Если да, то по каким причинам не стали его использовать?
spektom Автор
28.02.2018 12:30+1Насколько мне известно, в данный момент рассматривают именно его. По слухам, показатели хорошие при использовании AggregatingMergeTree. ИМХО, если его не выберут, то по одной из причин:
— Сложность настройки.
— Компании, предоставляющие техподдержку (вроде Altinity), слишком мало времени находятся на рынке.
— Недостаток программеров в компании, способных понять код С++.
— Недоверие к продуктам российской компании (пусть даже и с открытым исходным кодом).NYM
28.02.2018 13:00Спасибо.
Рассматривал clickhouse как C++ разработчик.
Современные программные продукты для работы с ними имеют клиентские библиотеки на многих современных языках. Поддержка библиотек на C++ минимальна или ее нет. Можно найти низкоуровневое решение на C. Для работы с clickhouse есть C++ библиотека. Это меня и заинтересовало.
Попробовав поработать с clickhouse, осталось много разных впечатлений как от СУБД, так и от клиентской C++ библиотеки. Скорость выполнения запросов на выборку данных — оставшееся хорошее впечатление после рассмотрения clickhouse.

VioletGiraffe
28.02.2018 12:26Запросы транслируются в машинный код
Как это реализовано?
И ещё: ваша БД хранится на диске, или исключительно в памяти?spektom Автор
28.02.2018 12:35— Генерируется код запроса на С++, который затем компилируется с помощью GCC (в будущем планируется использовать LLVM)
— Исключительно в памяти. Партиции реплицированы между нодами (и дата центрами). Данные хранятся также на каком-нибудь S3, главное обеспечить их быстрое восстановление.Hixon10
28.02.2018 22:38То есть, всё работает так?
SQL-like query -> AST -> generated c++ code -> compilation of c++ code with GCC -> binary file. А потом для данного запроса вы просто запускаете этот бинарник?
Naglec
Аппликации — это которые в детском саду делают? А мобильные аппликации на смартфонах в детском саду?
spektom Автор
Поправил, спасибо.