
Полнотекстовый поиск даёт возможность искать документы по текстовому содержимому. Такая необходимость может возникнуть, когда система содержит много текстовых сущностей, а пользователям требуется учитывать эти данные во время поиска. Мы столкнулись с подобной ситуацией при разработке решения для документооборота*. Данные системы хранятся в MS SQL Server или PostgreSQL, а гибкий атрибутивный поиск позволяет находить документы по различной мета-информации. Однако со временем этого стало недостаточно. Перед нами встала задача: научиться искать документы по текстовым свойствам и приложенным файлам.

Проблема в том, что полнотекстовый поиск поддерживается SQL сервером только за отдельную плату и не предоставляет нужной нам гибкости. В этот момент на сцену выходят поисковые движки. Существуют разные системы полнотекстового поиска, например: Sphinx, Solr или Elasticsearch; но наш выбор остановился на последнем из них. В общем, у нас есть большая динамичная база документов, Elasticsearch и желание заказчиков иметь web-интерфейс для полнотекстового поиска. А также автодополнение, подсказки, фасеты и другие возможности, близкие к функциональности интернет-магазина. Статья о том, как мы решали эту задачу.
*Система документационного управления "Приоритет" на платформе Docsvision
Архитектура
В базе данных Elasticsearch таблицы называются индексами, а процесс загрузки документов — индексированием. Для индексирования данных из основного хранилища в Elasticsearch был написан специальный сервис. Он представляет собой Windows-службу, в дополнение к которой идет утилита администратора. В утилите устанавливаются необходимые настройки, создаются индексы и запускается загрузка документов в базу данных.
Однако, на этапе индексирования данных мы столкнулись с проблемой. Система динамична, и ежеминутно в документах происходят тысячи изменений. Сервис индексирования должен поддерживать данные Elasticsearch в состоянии, максимально близком к текущему положению дел. Поэтому в SQL базе данных появляется новая сущность — очередь документов для индексирования. Каждые N минут специальный job находит все документы, которые были изменены после предыдущего выполнения и добавляет их идентификаторы в очередь. Как следствие, сервис обновит в индексах только требующие того документы.
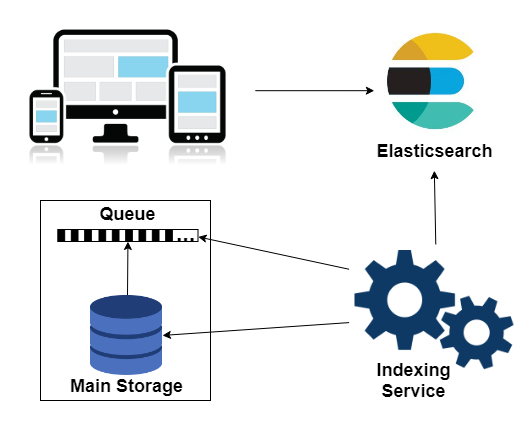
Технологический стек
Поисковый движок. Elasticsearch 5.5
Плагины. analysis-morphology и ingest-attachment
Сервис. Написан на C#. Библиотеки для взаимодействия с движком: NEST и ElasticsearchNET.
Frontend. Angular 4
Загрузка настроек
Утилита администратора — часть сервиса, с помощью которой выбираются виды документов и поля, которые надо индексировать. После этого в Elasticsearch загружаются схемы данных (в экосистеме ES они называются маппингами). Это необходимо для того, чтобы установить разным полям свои настройки, которые будут учитываться при индексировании документов. Кроме того, утилита сохраняет результаты выбора в базу данных.
Формирование маппингов
Маппинги формируем динамически с помощью библиотеки NEST. Каждому типу данных системы поставлен в соответствие тип данных Elasticsearch. В базе данных также поддерживается иерархическая структура документов. Этому соответствуют типы данных object и nested (для массивов).
var sectionProperty = section.SectionType == SectionType.Struct ?
new ObjectProperty { Name = section.Name } :
new NestedProperty { Name = section.Name };Анализ текстовых полей
Elasticsearch предоставляет большие возможности для полнотекстового поиска. Он может учитывать словоформы, пропускать стоп-слова, использовать морфологию языка. Для этого на этапе формирования маппинга нужно указать правильный анализатор для текстовых полей, которые этого требуют. Эти настройки также указываются в утилите администратора.
Анализатор включает в себя три этапа: преобразование отдельных символов, разбиение символов на токены и обработка этих токенов. В нашем случае фильтрация символов не требуется. В качестве токенизатора используем стандартный, который из коробки работает для большинства случаев. Ключевым звеном анализатора русского языка является официальный плагин analysis-morphology. Он предоставляет фильтр токенов, который позволяет искать с учетом словоформ. Также мы приводим все слова к нижнему регистру и используем свой набор стоп-слов.
var stopFilter = new StopTokenFilter { StopWords = new StopWords(StopWordsArray) };
var filters = new TokenFilters { { "my_stopwords", stopFilter } };
var rusAnalyzer = new CustomAnalyzer
{
Tokenizer = "standard",
Filter = new[] { "lowercase", "russian_morphology", "my_stopwords" }
};
var analazyers = new Analyzers { { "rus_analyzer", rusAnalyzer } };
var analyzis = new Analysis { Analyzers = analazyers, TokenFilters = filters };Настройки для файлов
В Elasticsearch версии 5.0 появилась новая сущность — узел Ingest. Такие узлы используются для обработки документов перед их индексированием. Для этого нужно создать конвейер (pipeline) и добавить в него процессоры (processor). Любой из ваших узлов может использоваться как ingest. Или же можно выделить под первичную обработку отдельный узел.
Многие документы нашей системы содержат текстовые файлы. Полнотекстовый поиск должен уметь работать по их содержимому. Для реализации этого мы использовали плагин Ingest Attachment, в котором применяется недавно появившаяся технология конвейера. Определим процессор, который для каждого файла документа применяет процессор, доступный благодаря плагину. Суть этого процессора в том, чтобы из Base64 строки извлекать текст в отдельное поле. Все, что нам останется: во время индексирования получить Base64 строку по файлу и попасть в маппинг. В процессоре укажем, в каком поле содержится файл (Field) и в куда нужно поместить текст (TargetFiled). Настройка IndexedCharacters ограничивает длину обрабатываемого файла (-1 снимает ограничения).
new PutPipelineRequest(pipelineName)
{
Processors = new List<ProcessorBase>
{
new ForeachProcessor
{
Field = "Files",
Processor = new AttachmentProcessor
{
TargetField = "_ingest._value.attachment",
Field = "_ingest._value.RawContent",
IndexedCharacters = -1
}
}
}
};Индексирование
Задача сервиса — непрерывно извлекать новые объекты из очереди и индексировать соответствующие документы. В этом процессе мы используем не объектную модель NEST, а низкоуровневую библиотеку ElasticsearchNet. Она предоставляет интерфейс взаимодействия с базой данных через JSON. Объекты формируем динамически обходом в глубину иерархической структуры документа. Для этого используется всем известная библиотека NewtonsoftJson.
client.LowLevel.IndexPut<string>(indexName, typeName, documentId, json);Индексирование реализовано многопоточно с параллельной обработкой каждого документа. Процесс формирования JSON занимает на порядок больше времени, чем его индексирование. Поэтому используется API для индексирования отдельных документов, а не Bulk API, при котором за один вызов в ES загружается массив документов. В таком случае индексирование бы происходило со скоростью формирования JSON для самого большого документа.
Индексирование файлов
Файлы индексируются вместе с остальными данными как часть JSON-объекта. Всё, что для это нужно — преобразовать поток байтов в Base64 строку. Это делается средствами стандартной библиотеки. Кроме того, необходимо, чтобы файлы попали под определение процессора. Иначе магии не произойдет, и они так и останутся обычной Base64 строкой. Чтобы при индексировании использовать конвейер, изменим вызов метода.
client.LowLevel.IndexPut<string>(indexName, typeName, documentId, json, parameters => parameters.Pipeline(pipelineName));Автодополнение
Автодополнение (autocomplete) подсказывает возможное продолжение строки по мере ее ввода пользователем.

В нашем случае автокомплит должен работать по тем текстовым полям, которые были отмечены соответствующим флагом в утилите администратора. На этапе загрузки маппингов создаётся отдельный индекс для всех дополняющих строк. Это связано с тем, что поиск должен работать на нескольких индексах. Маппинг формируется с полем особого типа completion.
var completionProperty = new CompletionProperty
{
Name = "autocomplete",
Analyzer = "simple",
SearchAnalyzer = "simple"
};При индексировании документов текст, который нужен для автодополнения, разбивается на наборы термов и загружается в индекс. Термы должны удовлетворять регулярному выражению — для нас важно выделять не слишком короткие и состоящие только из букв слова. Наборы последовательно сдвигаются на один терм, поэтому для каждого слова будет строка в индексе, которая начинается с него. Длина набора ограничена сверху, мы используем completeSize, равный четырем.
var regex = new Regex(pattern, RegexOptions.Compiled);
var words = regex.Matches(text);
for (var i = 0; i < words.Count; i++)
{
var inputWords = words.OfType<Match>().Skip(i).Take(completeSize).ToArray();
var wordValues = inputWords.Select(x => x.Value).ToArray();
var output = string.Join(" ", wordValues);
// запись в JSON
}Во время поиска для получения автодополнения работает отдельный запрос. При каждом введенном символе происходит обращение к базе данных с соответствующей подстрокой. Запросы к Elasticsearch представляют собой json-объекты. Чтобы получить автокомплит, нам нужен только блок suggest. В него входит Completion Suggester, который позволяет быстро искать по префиксу. Он работает только для completion полей. С другими саджестерами мы ещё встретимся, когда будем обсуждать опечатки.
{
"suggest": {
"completion_suggest": {
"text": "подстрока для запроса",
"completion": {
"field": "autocomplete",
"size": 10
}
}
}
}Поиск
Базовая часть интерфейса — поисковая строка. При вводе пользователем символов отрабатывают два запроса: для автодополнения и для поиска. По результатам первого из них появляются подсказки для продолжения печати, а по второму — строится выдача документов. Поисковый запрос состоит из нескольких блоков, каждый из которых отвечает за разные свойства.
Полнотекстовый поиск
Блок query соответствует поисковой части запроса. Благодаря ему выбираются документы, которые попадут в выдачу. К этим результатам применяются другие важные блоки запроса. query может иметь подзапросы, соединяющиеся с помощью булевых операций. Для этого определяем блок bool. Он может включать в себя четыре типа условий: must, filter, must_not, should. В нашем запросе используется условие should, которое соответствует логическому ИЛИ. Оно объединяет несколько полнотекстовых подзапросов. К блоку filter вернемся немного позже, а пока считаем, что ищем по всему множеству документов.
{
"query": {
"bool": {
"filter": [],
"should": [
// полнотекстовые подзапросы
]
}
}
// остальные блоки
}Для полнотекстового поиска используется блок multi_match. Текст из параметра query ищется сразу в нескольких полях, которые указаны в параметре fields. В ответ на запрос возвращается список документов, каждому из которых принадлежит некоторый score. Чем лучше документ соответствует запросу, тем выше это число. Запрос multi_match не рассматривает текст как единую фразу, а производит поиск по отдельным термам. Добавим аналогичный блок, но с параметром phrase, который реализует нужную функциональность. Для того, чтобы документы с совпадением по фразе ценились выше, укажем параметр boost. Он умножает score документа на указанное число.
{
"multi_match": {
"query": "текст запроса",
"fields": [
"FieldName"
]
}
},
{
"multi_match": {
"query": "текст запроса",
"fields": [
"FieldName"
],
"type": "phrase",
"boost": 10
}
}Среди подводных камней можно отметить поиск среди объектов в массиве. При создании маппинга некоторые поля мы пометили как nested. Это означает, что они являются массивами объектов. Чтобы искать по каким-либо полям этих объектов, нужен отдельный подзапрос, который называется nested. В нем нужно указать путь до массива (path) и сам запрос. Если вы ищете по одному индексу, то этого будет достаточно. Однако, в нашем случае поиск работает одновременно по нескольким индексам, и, если такого пути не будет в каком-либо из них, ES вернет ошибку. Поэтому nested запрос нужно заключать в блок indeces и указывать, в каком индексе производить поиск. Чтобы явно показать, что по остальным индексам поиск не нужен, прописываем "no_match_query": "none".
{
"indices": {
"index": "indexName",
"query": {
"nested": {
"path": "PathToArray",
"query": {
"multi_match": {
"query": "текст запроса",
"fields": [
"PathToArray.FieldName"
]
}
}
}
},
"no_match_query": "none"
}
}Хайлайты
Elasticsearch предоставляет приятную возможность выделения текста, найденного в документе по запросу.

Для этого нужно добавить новый блок запроса: highlight. В fields перечисляем поля, для которых должен возвращаться хайлайт. В параметрах pre_tags и post_tags указываем, какими символами нужно выделить слова. Если поиск работает по большому текстовому полю (например — файл), Elasticsearch вернет хайлайты не вместе со всем полем, а внутри небольшого отрывка. В результате движок выполнил всю работу за нас: и подсветил совпадения жирным шрифтом, и выделил контекст.
{
"highlight": {
"pre_tags": [
"<b>"
],
"post_tags": [
"</b>"
],
"fields": {
"FieldName": {}
}
}
}Несмотря на все удобство этой фичи, мы столкнулись с серьезной проблемой при работе с ней. Если хайлайт отработал по объекту в массиве, то по ответу на запрос нельзя определить, какому объекту он принадлежит. Файлы хранятся в массиве, а хайлайт по файлам — одно из ключевых требований заказчика. Логичное решение этой проблемы — создать набор полей вида File_i, где i покроет разумное количество прилагаемых файлов. Тогда по хайлайту станет понятно, какой индекс имеет файл, а из результатов поиска можно взять имя файла по этому индексу.
Тем не менее, оказалось, что не все так просто. Процессор преобразования Base64 строк в текст может работать только по массиву с одноименными полями. Благодаря помощи на форуме discuss.elastic.co было найдено решение: добавить еще один процессор, который после преобразования в текст переименует поля в нужный вид. Код процессора:
"script": {
"lang": "painless",
"inline": """for (def i = 0; i < ctx.Files.length; i++)
{
def f = 'File' + (i+1);
ctx.Files[i][f] = ctx.Files[i].attachment;
ctx.Files[i][f].Name = ctx.Files[i].Name;
for (def rf : ['attachment', 'Name'])
{
ctx.Files[i].remove(rf);
}
}"""
}Саджесты
Иногда пользователь допускает опечатки при вводе запроса. В таком случае результаты поиска будут пустыми. Однако, Elasticsearch может подсказать о возможной ошибке.

Эта функциональность реализуется за счёт блока suggest. Мы уже встречались с ним, когда обсуждали автодополнение, но для обработки опечаток используется другой тип саджестеров. Он называется phrase и ищет ошибки, учитывая всю фразу, а не отдельные слова. Укажем количество подсказок в результатах (size), поля для поиска (field) и число возможных опечаток во фразе (max_errors). Чтобы отсечь нежелательные результаты, добавим вложенный запрос (collate), который проверяет, что полученный саджест содержится хотя бы в одном поле индекса. Также подсказки поддерживают встроенный хайлайт, который выделяет слово с ошибкой.
{
"suggest": {
"my_suggest": {
"text": "текст запроса",
"phrase": {
"size": 1,
"field": "_all",
"max_errors": 4,
"collate": {
"query": {
"inline": {
"match": {
"{{field_name}}": {
"query": "{{suggestion}}",
"operator": "and"
}
}
}
},
"params": {
"field_name": "_all"
}
},
"highlight": {
"pre_tag": "<b>",
"post_tag": "</b>"
}
}
}
}
}Фасеты
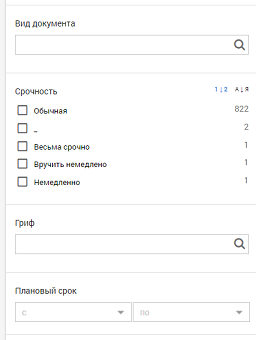
Ещё одна интересная фича, которую можно реализовать с помощью Elasticsearch. Фасетами называются блоки агрегации, которые можно часто увидеть в интернет-магазинах. Добавим в запрос блок aggs. Наиболее распространённый тип агрегаций, который можно добавить в этот блок, называется terms. В результатах будут содержаться все уникальные значения соответствующего поля и количества документов, в которых они встречаются. Важно, что агрегации применяются не ко всему множеству документов, а только к тем, которые удовлетворяют поисковому запросу. Поэтому при вводе текста содержимое фасетов будет динамически меняться.
{
"aggs": {
"types": {
"terms": {
"field": "TypeField"
}
},
"min_date": {
"min": {
"field": "DateField"
}
}
}
}Для полноценной реализации фасетов осталось добавить блок фильтрации в поисковый запрос. Этим мы ограничим поиск только теми параметрами документов, которые были выбраны в фасетах. В блок filter добавим по подзапросу для каждого блока фильтрации.
{
"terms" : {
"TypeField" : [ /* перечисление типов */]
}
},
{
"range" : {
"DateField" : {
"gte" : /* минимальная дата */
}
}
}Итог
Так выглядит картина в целом.
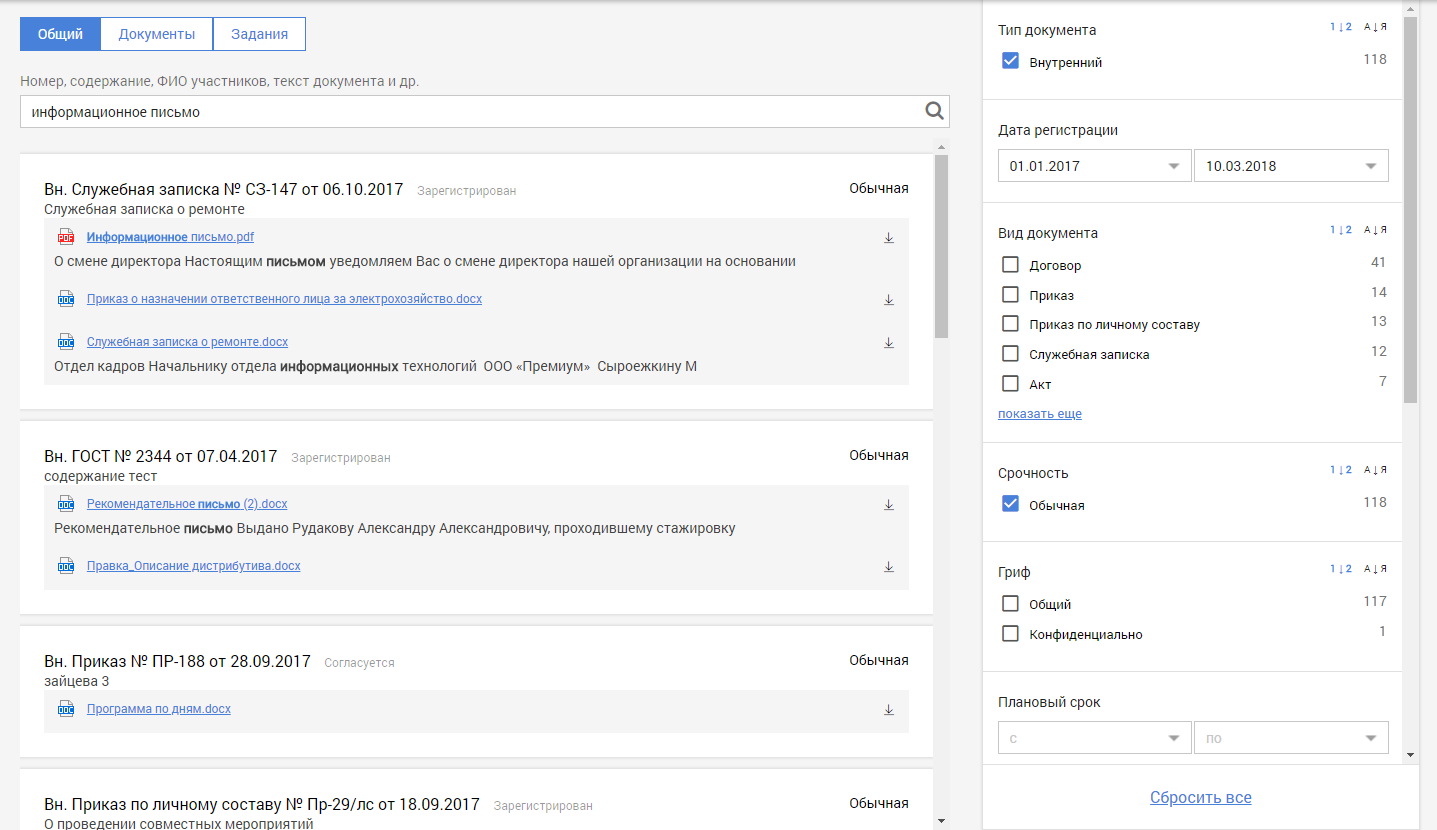
Статистика индексирования
На текущий момент в пилотном варианте используется конфигурация:
2 сервера:
CPU: intel Xeon Platinum 8160 (10 ядер)
Оперативная память: 40 Гб
Объем индексов: 260 Гб
Число документов в индексах: 600 тыс.
Скорость индексирования: 5000 док/ч
Комментарии (9)

sloniki
13.03.2018 08:11+1В качестве конвеера можно задействовать Logstash, который мощнее по функциональности и производительности встроенного в ingest node.
Я для управления и базового мониторинга использую ElasticHQ.
Ну и кластер конечно должен иметь нечётное количество нод.

Edc
13.03.2018 12:43+1Насколько я понимаю вопрос разделеления прав пока не рассматривали? Ведь при таком количестве документов наверняка найдётся информация с ограничением по доступности
kalina_alexey Автор
13.03.2018 12:54Да, действительно такая проблема есть.
В рамках пилотного проекта проверка прав не требуется, но в дальнейшем план решения такой:
- Дофильтровывать результаты поиска уже на уровне приложения: вырезать хайлайт, если нет прав на файлы.
- По умолчанию отображать общедоступные данные, а при переходе в документ проверять права (сейчас так и есть, кроме хайлайта).
Edc
13.03.2018 13:22Мы в Apache SOLR использовали дополнительные таги со списком групп. И соответственно на уровне приложения использовали filter query. Но при добавлении/удалении прав доступа к документу была боль, так как SOLR не поддерживал атомарное изменение документа
Ababagalamaga
13.03.2018 23:20А FSCrawler не пробовали. Недавно делал POC для подобного проекта и на намного более скромной виртуальной машине (всего 4GB для эластика) проиндексировал 1GB или 3000 файлов за 10 минут. Он использует TIKA для извлечения текста, как и эластик, плюс есть поддержка OCR, плюс извлекает кучу полезных метаданных.
Есть еще один проект Ambar, но что-то мне там не понравилось. Видимо, активность разработчиков…kalina_alexey Автор
14.03.2018 07:41Как я понял, FSCrawler индексирует файлы как отдельные документы. В нашем случае важно хранить файлы внутри документа, к которому они прикреплены (вместе с другой информацией, не связанной с файлами).
Для подходящей задачи обязательно попробуем, спасибо.Ababagalamaga
14.03.2018 16:28FSCrawler, помимо текстовой и мета информации, может отправить и сам оригинальный файл и сохранить его в индексе в бинарном формате. У меня тоже была задача хранить дополнительную информацию вместе с файлами в индексе. Так можно настроить mapping под свои бизнес задачи.
В любом случае ingest-attachment plugin тоже хорошее решение, просто я был немного удивлен столь малой скоростью. Я бы поигрался с настройками индекса, типа refresh interval, количеством реплик и нод.
olku
Вишенка на Ваш торт — когда надоест админить схемы и документы из командной строки
kalina_alexey Автор
Спасибо, попробуем.
Кстати говоря: для мониторинга индексов используем Cerebro, а для поиска, конечно, Kibana.