

В этой серии статей я хочу описать наш опыт создания полностью автоматизированной стратегии тестирования (без QA) веб приложения Nielsen Marketing Cloud, которую мы создавали последние несколько лет.
В центре разработки Nielsen Marketing Cloud мы работаем без какого-либо ручного тестирования как новой функциональности, так и регрессий. И это дает нам большое количество преимуществ:
- ручное тестирование дорогое. Автоматический тест пишется один раз, а запускать его можно миллионы раз
- каждый разработчик чувствует больше ответственности, так как никто не будет проверять его новые фичи
- уменьшается время релиза, можно выкладывать новый функционал каждый день без необходимости ждать других людей или команд
- уверенность в коде
- самодокументация кода
В длительной перспективе хорошая автоматизация тестирования дает лучшее качество и уменьшает количество регрессий для старой функциональности.
Но тут возникает вопрос на миллион долларов — как эффективно автоматизировать тестирование?
Часть 1 — Как делать не надо
Когда большинство разработчиков слышат «автоматизированное тестирование» они думают «автоматизация поведения пользователя» (end to end тесты с помощью Selenium) и мы тоже не были исключением из этого правила.
Конечно, мы знали про важность юнит и интеграционных тестов, но «Давайте просто пойдем в систему, нажмем на кнопку и таким образом проверим все части системы вместе» казалось довольно логичным первым шагом в автоматизации.
В итоге решение было принято — давайте писать кучу end to end тестов через Selenium!
Это казалось хорошей идеей. Но результат, к которому мы в итоге пришли был не таким радостным. Вот проблемы, с которыми мы столкнулись:
1. Нестабильные тесты
В какой-то момент, когда мы написали довольно большое количество end to end тестов, они начали падать. И падения были не постоянными.
Что делают разработчики, когда они не понимают почему случайно упал тест? Правильно — они добавляют sleep.
Начинается это с добавлением sleep'а на 300мс в одном месте, потом на 1 секунду в другом, затем на 3 секунды.
В какой-то момент мы находим в тестах что-то вроде этого:
sleep(60000) //wait for action to be completedЯ думаю, что достаточно очевидно почему добавление sleep'ов плохая идея, да?*
*если все таки нет — sleep'ы замедляют работу тестов и они постоянные, что означает что если что-то пойдет не так, и какая-то операция займет больше времени чем планировалось — ваши тесты упадут, то есть они будут не стабильными и не детерменированными.
2. Тесты работают медленно
Потому что автоматизированные end to end тесты проверяют реальную систему с настоящим сервером и базой данных, прогон таких тестов достаточно медленный процесс.
Когда что-то работает медленно — разработчики обычно будут избегать этого, так что никто не будет запускать тесты на локальном окружении и код будет пушиться в систему контроля версий с надеждой, что CI будет зеленым. Но это не так. И CI красный. И разработчик уже ушел домой. И…
3. Падение тестов не информативно
Одна из самых больших проблем наших end to end тестов, что если с ними что-то не так, мы не можем понять в чем проблема.
И проблема может быть ГДЕ УГОДНО: окружение (помним, что ВСЕ части системы являются частью уравнения), конфигурация, сервер, фронтенд, данные или просто не стабильный тест (не достаточно sleep'ов).
И единственная вещь, которую вы увидите:

В итоге — определение того что же действительно пошло не так занимает кучу времени и быстро начинает надоедать.
4. Данные для тестов
Так как мы проверяем всю систему со всеми слоями вместе, порой очень сложно сымитировать или создать сложный сценарий. Например, если мы хотим проверить как пользовательский интерфейс будет реагировать когда сервер не доступен или данные в базе данных повреждены — это совсем не тривиальная задача, так что большинство разработчиков пойдут по пути наименьшего сопротивления и просто будут тестировать только позитивные сценарии. И никто не будет знать как же система поведет себя в случае возникновения проблем (а они обязательно возникнут).
Но это лишь пример, часто вам нужно проверить какой-либо специфический сценарий когда какая-то кнопка должна быть не активной, и построить целую вселенную для этого специфического сценария требует реального больших усилий. И это не говоря о том, что бы очищать данные после тестов, что бы не оставлять мусор для следующих тестов.
5. Динамический пользовательский интерфейс
В модных одно-страничных (SPA) приложениях — пользовательский интерфейс очень динамичен, элементы появляются и пропадают, анимации прячут элементы, возникают всплывающие окна, части экрана асинхронно меняются в зависимости от данных в других частях и т.д.
Это делает автоматизацию сценариев значительно более сложной, так как в большинстве случаев очень трудно определить условие, которое означает что действие было выполнено успешно
6. Давайте построим наш собственный фреймворк
В какой-то момент мы начали понимать, что наши тесты довольно сильно повторяют друг друга, так как разные части пользовательского интерфейса используют одни и те же элементы (поиск, фильтрация, таблицы, и т.д.).
Мы не очень хотели копи-пастить код тестов, потому мы начали строить наш собственный тестовый фреймворк с некоторыми обобщенными сценариями, которые могли бы использоваться в других сценариях.
После этого мы поняли, что некоторые элементы могут использоваться по разному, иметь разные данные и т.д. Так что наши обобщенные части стали обрастать конфигурациями, наследованием, фабриками и другими шаблонами проектирования.
В конце концов наш тестовый код стал реально сложным и только несколько человек в команде понимали как работает эта магия.
Итог
Конечно, некоторые проблемы могут быть частично решены (паралельный запуск тестов, снятие скриншотов при падении тестов, и т.д.), но в результате этот набор end to end тестов стал очень проблематичным, сложным и дорогим в поддержке.
Более того, в какой-то момент у нас было столько ложных падений и проблем со стабильностью, что разработчики просто перестали рассматривать красные тесты серьезно. А это еще хуже, чем вообще не иметь никаких тестов!
В результате у нас:
- тысячи end to end тестов
- 1.5 часа на один запуск (20 минут при параллельном запуске)
- падают почти каждый день и когда они красные — нам приходиться тестировать вручную
- затрачивается куча времени разработчика для воспроизведения и исправления проблем с тестами
- 30 тысяч строк кода в end to end тестах
Итоговый результат, который мы получили известен как "Антипаттерн рожка мороженного".
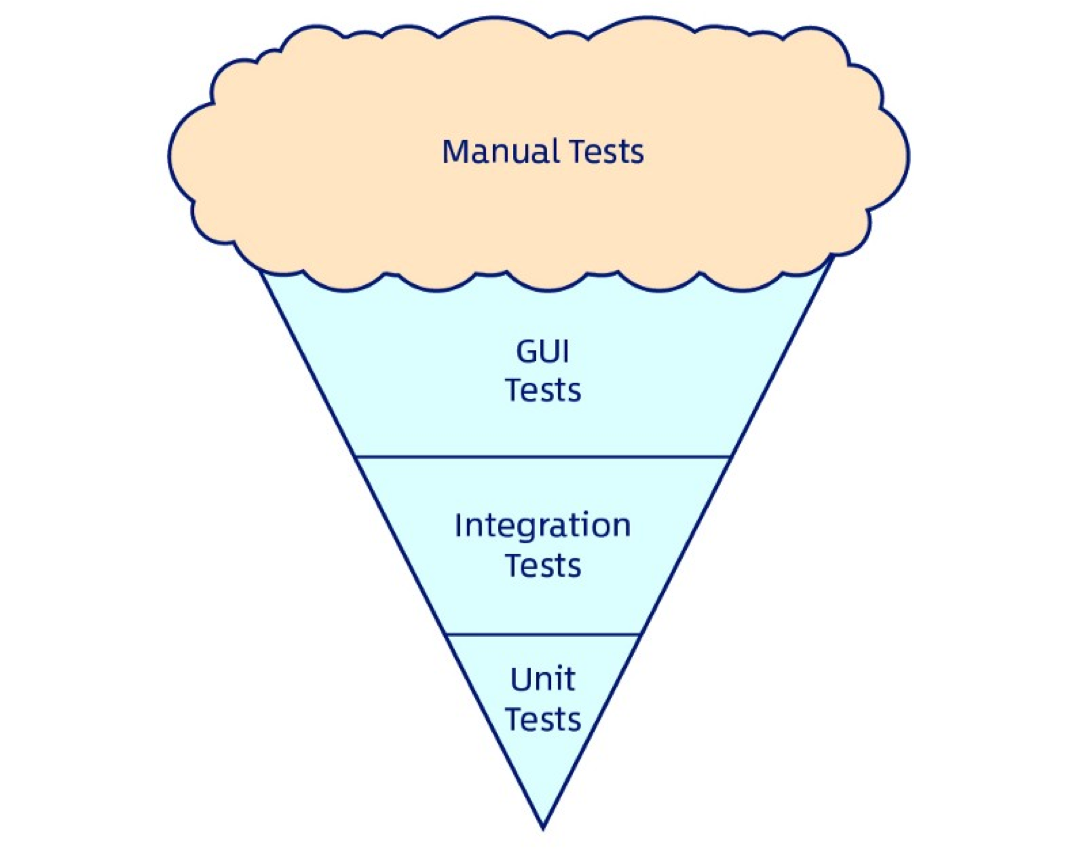
В общем мы решили значительно уменьшить количество наших end to end тестов и использовать вместо них кое-что значительно более крутое. Но об этом в следующей части нашего повествования.
Комментарии (12)

Mabusius
19.03.2018 12:09«В конце концов наш тестовый код стал реально сложным и только несколько человек в команде понимали как работает эта магия.» — Я попадал в похожую ситуацию. Все стало настолько сложным, что тестам были нужны свои собственные тесты. В следующий раз хочу попробовать другой подход — никаких гераторов данных, а только готовые дампы базы.

jetexe
19.03.2018 13:41С дампами данных можно прийти в другую крайность. Синтетически всё выглядит работоспособным, а на деле падает.
А вообще у тестов должна быть своя архитектура, DRY, KISS и прочее.
Ну и разумеется Unit -> Feature -> Поведенческие.
pae174
19.03.2018 21:11Синтетически всё выглядит работоспособным, а на деле падает.
Такое часто происходит если база пришла из продакшена в тесты без промежуточной статической проверки. То есть никто не убедился в том, что там на самом деле всё правильно и нет намеков на то, что какие-либо проверки или ограничения на самом деле почему-то не соблюдаются.
jetexe
20.03.2018 17:46Даже если дампы просмотреть под лупой, то это не гарантирует покрытия всеми возможными тестами.
Эти дампы придется накатывать после каждого теста. Дороговато выходит.
Без генераторов Unit-тестирование тоже становится адом.
А в чем польза-то в заключении?
MiKXMan Автор
19.03.2018 13:48Мы пришли к тому, что использовать дампы — плохая стратегия.
Во-первых, если «делить» дамп между тестами, то тесты начинают менять глобальное состояние и прямо или косвенно влиять друг на друга (задизейблил один тест и пять других упало, потому что они были зависимы от измененного состояния этого теста).
Поднимать чистый дамп для каждого теста в больших системах не представляется возможным с точки зрения быстродействия.
Мы пошли по пути того, что каждый тест обязан приготовить данные перед своим началом и полностью очистить их после себя. Не всегда это сделать просто, но в большинстве случаев это оправдано и в таком случае тесты становятся полностью независимыми и идемпотентными.
jadorvski
19.03.2018 19:49Начинается это с добавлением sleep'а на 300мс в одном месте, потом на 1 секунду в другом, затем на 3 секунды.
На каком именно фреймворке писались тесты? sleep — действительно очень плохое решение. Нужно ожидать результата асинхронного действия по таймауту. В Nightwatch.js это делается с помощью waitForElementVisible или waitForElementPresent.MiKXMan Автор
19.03.2018 19:51Мы используем Protractor, и конечно же использование слипов плохая идея. Но по нашему опыту в некоторых случаях очень сложно отследить когда операция выполнена успешно.
И поскольку тесты не стабильны, разработчики думают «ну, что-то происходит слишком быстро, поставлю ка я тут слип, оно станет стабильнее». Сначала это происходит в одном месте, потом в еще одном, потом в еще одном. И дальше как снежный ком.
3vi1_0n3
20.03.2018 08:44После использования Protractor'а около года у меня начали периодически возникать мысли о том, что использование Protractor'а в целом идея не очень. Очень тяжело давалась стабилизация. В итоге удалось заметно стабилизировать тесты максимально избегая sleep'ов, правда для этого пришлось перелопатить весь фреймворк. Сейчас всё еще не идеально, но false negative не более 3% за 4 часа ночных прогонов на Grid'е. И, к сожалению, тут уже сложно что-то существенное сделать.
P.S.: Фреймворк с самого начала писал не я, поэтому на Grid'е он с самого начала давал около 80% failed
VolCh
Кажется, не имело смысла разбивать на несколько частей. Или хотя бы, надо было кратко раскрыть содержание второй части.
DSLow
Согласен. Не очень приятно читать текст типа «Вот тут у нас проблема, и тут проблема, тут криво, тут долго». Окей, какие варианты решения? Их нет, ждите дальше.
MiKXMan Автор
Согласен, следующие части выйдут очень скоро. Но я считаю что путь чужих ошибок и «как не нужно делать» тоже достаточно интересен, кроме того тут описаны проблемы самого классического пути автоматизации тестирования.
VolCh
Путь интересен, проблема в том, что данная часть выглядит просто механически обрезанной на полуслове, как будто задача была "5 частей по 10000 знаков, выкладывать по мере готовности".