

Данная статья была представлена на конференции SECR2017, где получила премию Бертрана Мейера за лучший исследовательский доклад.
В этом материале руководитель исследовательской лаборатории «Рэйдикс» Светлана Лазарева рассказывает о новом алгоритме заполнения параллельного кэша в СХД, который основан на алгоритме машинного обучения.
Оригинал статьи и презентация.
Гибридные системы
Основные требования, предъявляемые клиентами к системам хранения данных это высокая производительность операций ввода-вывода, обеспечиваемая твердотельными накопителями (SSD), и низкая цена за операцию, которую гарантируют дисковые накопители (HDD). Причина различий между жесткими дисками и твердотельными накопителями кроется в их внутреннем устройстве работы. HDD для доступа к определенному блоку данных требуется передвинуть головку и прокрутить магнитные диски, что в случае множества случайных запросов ведет к большим издержкам, в то время как SSD не имеет механических частей и может обслуживать как последовательные, так и случайные запросы с одинаково высокой скоростью.
Но высокая производительность твердотельных накопителей имеет и обратные стороны. Во-первых, это ограниченный срок службы. Во-вторых, это цена, которая в расчете на единицу емкости оказывается заметно выше, чем у традиционных HDD. По этой причине системы хранения данных, построенные исключительно из SSD, получили ограниченное распространение и используются для особо нагруженных систем, в которых дорого время доступа к данным.
Гибридные системы являют собой компромисс между дешевыми, но медленными СХД на HDD и производительными, но дорогими СХД на SSD. В таких системах твердотельные накопители играют роль дополнительного кэша (помимо оперативной памяти) или тиринга. В данной статье мы приводили аргументы по выбору той или иной технологии.
Использование твердотельных накопителей в качестве кэш-устройств в совокупности с ограниченным количеством циклов перезаписи может значительно ускорить их износ из-за логики традиционных алгоритмов кэширования, ведущей к интенсивному использованию кэша. Таким образом, гибридные СХД требуют особых алгоритмов кэширования, берущих во внимание особенности используемого кэш-устройства — SSD.
Простейшей реализацией идеи гибридного массива является кэш- второго уровня (см. рис 1), когда все запросы после оперативной памяти попадают на SSD. В основе данного подхода лежит свойство временной локальности — вероятность запросить те же данные тем, выше, чем меньше время последнего обращения. Таким образом, используя SSD-кэш, как кэш второго уровня, мы как бы увеличиваем объем оперативной памяти. Но если оперативной памяти достаточно на обработку временной локальности, то этот способ не эффективен. Другой подход заключается в том, чтобы использовать SSD-кэш, как параллельный (см. рис 2). Т.е. какие-то запросы идут в оперативную память, какие-то сразу в SSD-кэш. Это более сложное решение, нацеленное на то, что разные кэши обрабатывают разные локальности. И одним из самых важных моментов реализации кэша параллельного уровня является выбор техники заполнения SSD- кэша. В данной статье описывается новый алгоритм заполнения параллельного кэша – фейс-контроль, основанный на алгоритме машинного обучения.
В основе предлагаемого решения лежит использование данных историй запросов к системам хранения данных, записанным на протяжении длительных отрезков времени. Решение основано на двух гипотезах:
- Истории запросов описывают типичную нагрузку к СХД по крайней мере за какой-то ограниченный промежуток времени.
- Нагрузка СХД сохраняет какую-то внутреннюю структуру, которая определяет то, какие блоки и с какой частотой запрашиваются.
В то время как первая гипотеза почти не вызывает сомнений и остается допущением, вторая требует экспериментальной проверки.
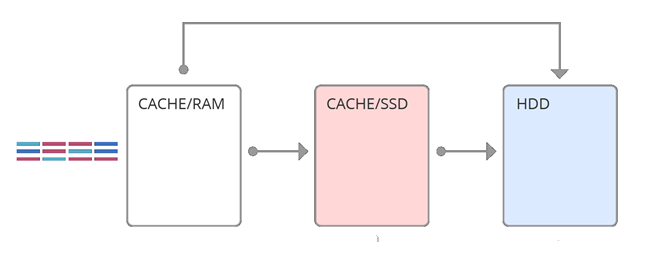
Рис. 1. Кэш второго уровня
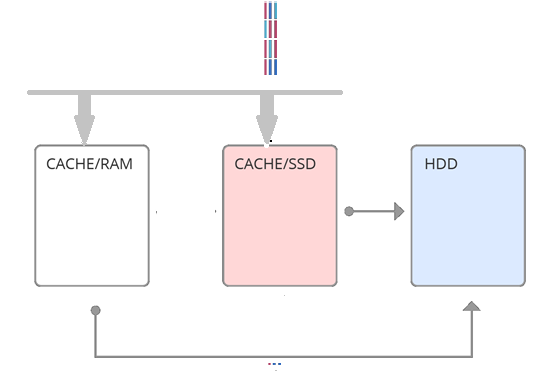
Рис. 2. Параллельный кэш
Архитектура решения
Архитектура предлагаемого решения представлена на рис. 3. Все запросы, приходящие от клиентов, сначала проходят через анализатор. Его функция — это обнаружение множеств последовательных запросов к системе.
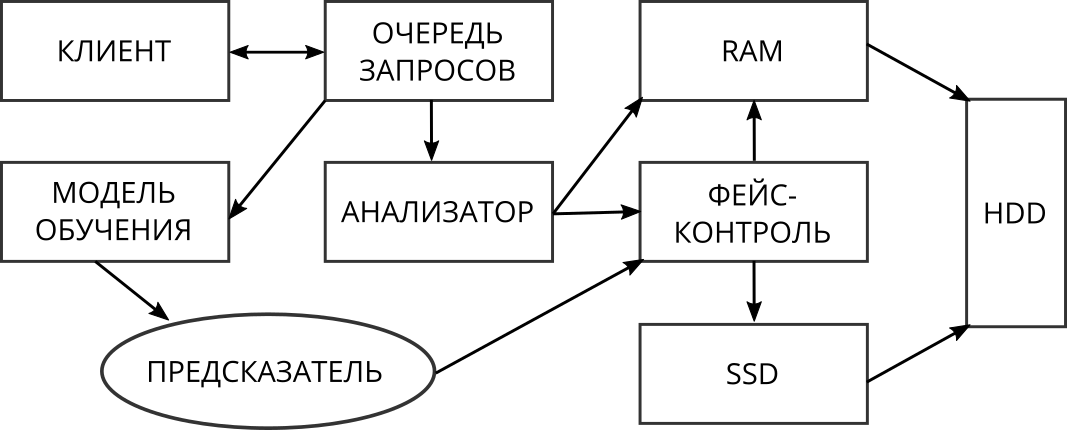
Рис. 3. Архитектура решения
В зависимости от типа они обрабатываются различно:
- Последовательная запись. Запросы этого типа не вызывают проблем и обрабатываются быстро, поэтому данные, к которым они обращаются, не попадают в SSD кэш.
- Последовательное чтение. Запросы этого типа обрабатываются быстро за счёт алгоритмов упреждающего чтения, обычно такие запросы уникальны(т.е. повторное последовательное чтение тех же данных маловероятно), поэтому такие данные нет необходимости кэшировать в SSD.
- Случайная запись. Такие запросы вызывают заметные издержки и при сквозной записи, и при попадании в оперативную память, т.к. данные при выталкивании из кэш-памяти все равно будут требовать записи на жесткие диски. Поэтому они сразу, минуя RAM, отправляются в SSD кэш на запись, где хранятся лог-структурировано и вытесняются по возможности последовательно для более эффективной дальнейшей записи в массив жестких дисков.
- Случайное чтение. Данные кэшируются в RAM или в SSD в зависимости от алгоритма фейс-контроля.
В данной системе на износ SSD влияют только случайные запросы. Запросы на случайную запись не поддаются оптимизации. Таким образом, единственная возможность для увеличения срока службы SSD — оптимизация обработки запросов типа случайное чтение. Если располагать способом оценки потенциального эффекта от кэширования конкретных данных, то можно избавиться от необходимости кэшировать “ненужные” данные.
Работы, предлагающие решения увеличения срока службы SSD в гибридных системах хранения данных в целом можно разделить на две группы. Первая группа рассматривает возможности улучшения эффективности кэширования на базе твердотельных накопителей за счет использования внутренней логики работы и технических особенностей [5, 1]. Такие алгоритмы сильно зависят от специфики конкретных устройств и поэтому не будут далее освещены.
Работы второй группы фокусируют свое внимание на создании новых алгоритмов кэширования. Идея у всех является общей: редко используемые данные не должны попадать в кэш. Это, во-первых, уменьшает число записей по сравнению с традиционными алгоритмами и, во-вторых, увеличивает число кэш-попаданий за счет меньшего засорения кэш-памяти мало используемыми блоками.
- LARC — Lazy Adaptive Replacement Cache [4]. Алгоритм использует простую логику: если блок был запрошен как минимум дважды за определенный промежуток времени, то он, вероятно, окажется нужен и в будущем и попадает в SSD кэш. Отслеживание блоков кандидатов ведется с помощью дополнительной LRU-очереди в оперативной памяти. К преимуществам этого алгоритма можно отнести относительно низкие требования к ресурсам.
- WEC — Write-Efficient Caching Algorithm [6]. Стандартные алгоритмы кэширования не позволяют часто используемым блокам непрерывно находиться в кэше. Этот алгоритм призван выделить такие блоки и обеспечить нахождение в кэше на время активного доступа к ним. В данной работе также используется дополнительная кэш-очередь, но с более сложной логикой определения блоков-кандидатов.
- Elastic Queue [2]. Указывает на недостаток всех ранее предложенных алгоритмов кэширования: отсутствие адаптивности к различной нагрузке. Рассматривает работу с приоритетной очередью как общую основу, а различия — в логике присваивания приоритетов и предлагает обобщенное улучшение очереди с этой точки зрения.
В корне рассмотренных выше алгоритмов лежит естественный в компьютерных науках метод — разработка алгоритмов, зачастую имеющих эвристическую природу, на основе анализа имеющихся условий и допущений. Данная работа предлагает принципиально иной подход, основанный на том, что рабочая нагрузка к системе хранения данных самоподобна. Т.е. анализируя прошлые запросы, мы можем предсказывать будущее поведение.
Алгоритмы машинного обучения
К данной задаче можно подходить с двух сторон: используя традиционные методы машинного обучения либо обучение представлению (representational learning). Первые сначала требуют обработки данных для извлечения из них релевантных признаков, которые затем используются для обучения моделей. Методы второго подхода могут напрямую использовать изначальные данные, прошедших минимальную предобработку. Но, как правило, эти методы имеют большую сложность.
Примером обучения представлению могут послужить глубокие нейронные сети (более подробно см. [3]). В качестве простой базовой модели можно опробовать деревья принятия решений. Признаками, на которых будет производиться обучение, могут быть:
- Среднее время нахождение блока в стеке (mean stack time)
- Отношение количества чтений и записей
- Отношение количества случайных и последовательных запросов, которые вычисляются на фиксированных отрезках истории запросов.
Многообещающими являются методы обучения представлению. Имеющиеся данные представляют собой временные ряды, что можно учитывать при выборе подходящих алгоритмов. Единственной группой алгоритмов, которые при вычислениях используют информацию о последовательной структуре данных, являются рекуррентные нейронные сети [3]. Поэтому модели такого типа являются основными кандидатами для решения поставленной задачи.
Данные
Данные — это истории запросов к СХД. О каждом запросе известна следующая информация:
- Время поступления запроса;
- Логический адрес первого блока (logical block address — lba);
- Размер запроса (len);
- Тип запроса — запись или чтение;
- Тип запроса — последовательный или случайный.
Эксперименты и анализ данных проводились на реальных нагрузках, полученных от разных клиентов. Файл с историей запросов от клиентов в дальнейшем назовем логом.
Чтобы анализировать эффективность того или иного алгоритма кэширования, надо ввести метрику. Стандартные метрики, такие как число кэш-попаданий и среднее время доступа к данным не подходят, т.к. они не берут в расчет интенсивность использования кэш-устройства. Поэтому в качестве метрики эффективности кэширования будем использовать Write Efficiency [6,2]:
Истории запросов разобъем на блоки последовательных запросов. Размер блока обозначим как blocksize. Для одного запроса метрика вычисляется следующим образом: в истории просматриваются ближайшие windowsize запросов и подсчитывается количество запросов к тем же данным, что и в исходном. Для блока из blocksize запросов подсчитывается среднее значение метрики по блоку.
Потом блоки делятся на два класса: “хороший” и “плохой” (см. рис 4). «Плохой» (красный) обозначает, что не рекомендуется посылать блок запросов в SSD-кэш (он направляется в оперативную память), «хороший» (зеленый) соответственно, что этот блок запросов направляется в SSD-кэш. Те блоки, у которых коэффициент WE больше параметра m, будем считать «хорошими». Остальные блоки будем считать «плохими».
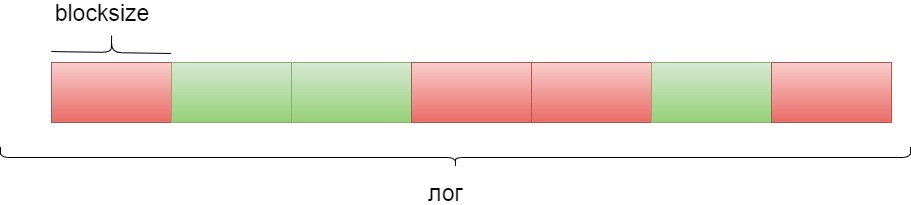
Рис. 4. Разбиваем логи на блоки
Вычисление метрики для больших значений windowsize может занять значительное количество времени. Накладываются вычислительные ограничения на то, насколько далеко можно подсчитывать переиспользование блока. Возникают два вопроса:
- Каким выбрать параметр windowsize?
- Является ли переиспользование блоков в пределах windowsize репрезентативным значением для суждения о переиспользовании этих блоков вообще?
Для ответа на них был проведен следующий эксперимент:
- Взята случайная выборка запросов;
- Подсчитано переиспользование этих блоков в пределах значительно большего windowsizemax;
- Подсчитан коэффициент корреляции Пирсона между переиспользованием блоков в пределах windowsizemax и windowsize, где windowsize — различные тестируемые значения.
На рис. 5 показано изменение коэффициента корреляции на выборке во времени. В таблице 1 представлено значение коэффициента корреляции для всей выборки. Результат значимый (P-значение близко к нулю). Его можно интерпретировать следующим образом: блоки, которые востребованы в ближайшие windowsize запросов, также, вероятно, востребованы в ближайшие windowsizemax запросов.
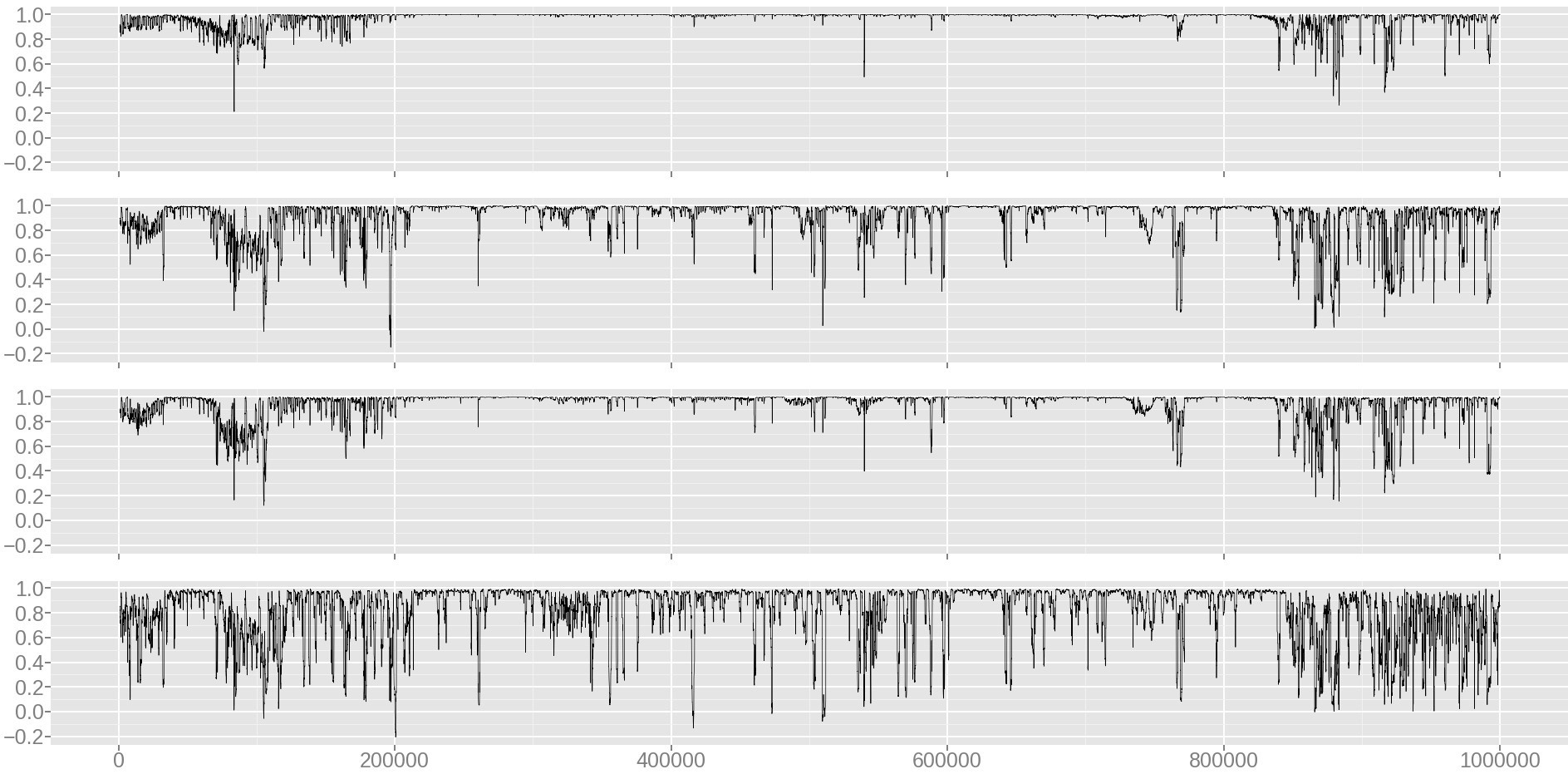
Рис. 5. Динамика коэффициента корреляции между windowsize и windowsizemax
Комментарий к рис. 5. Сверху вниз, windowsize: 100000, 10000, 30000, 3000. Размер выборки: 1000000 запросов. Ось x: номер бегущего окна размера 1000 запросов; ось y: значение коэффициента корреляции для бегущего окна.
Таблица 1. Коэффициент корреляции Пирсона для различных windowsize.
| windowsize | 3000 | 10000 | 30000 | 100000 |
|---|---|---|---|---|
| 1000000 | 0.39 | 0.61 | 0.82 | 0.87 |
Таким образом, для вычисления метрики берется значение windowsize, равное 100000.
Для построения вероятностных моделей набор данных стандартно [3, с. 120] делился на три части:
- Тренировочная выборка: 80%;
- Тестовая выборка: 10% (для итогового тестирования модели);
- Валидационная выборка: 10% (для подбора параметров и отслеживания прогресса модели во время обучения независимо от тренировочной выборки).
Стоит отметить, что в случае моделей глубокого обучения выборки нельзя делать случайными, так как в таком случае будут разрушены временные связи между запросами.
Модели глубокого обучения
Построение модели глубокого обучения требует принятия множества решений. Привести подробное разъяснение каждого из них в данной работе не представляется возможным. Часть из них выбрана согласно рекомендациям, в литературе [3] и оригинальных статьях. В них можно найти подробные мотивацию и пояснения.
Общие параметры:
- Целевая функция — перекрестная энтропия (стандартный выбор для задачи классификации) [3+, с. 75];
- Оптимизационный алгоритм — Adam [7];
- Метод инициализации параметров — Glorot [8];
- Метод регуляризации — Dropout [9] с параметром 0.5.
Опробованные параметры:
- Количество рекуррентных слоев нейронной сети: 2, 3, 4;
- Количество выходных нейронов в каждом lstm unit: 256, 512;
- Количество временных шагов рекуррентной нейронной сети: 50,100;
- Размер блока (количество запросов в блоке): 100, 300, 1000.
Базовый метод глубокого обучения — LSTM RNN
Было опробованы модели различной сложности. Для всех результат отрицательный. Динамика обучения представлена на рис. 6.

Рис 6. LSTM RNN. Изменение значения функции потерь на протяжении обучения
Комментарий к рис. 6. Красный — тренировочная выборка, зеленый — тестовая. График для модели средней сложности с тремя рекуррентными слоями.
Предобучение и LSTM RNN
Было опробовано предобучение на задаче моделирования потока запросов (прогнозирования следующего запроса). В качестве целевой функции использовалась среднеквадратичная ошибка между спрогнозированным значением lba и настоящим. Результат отрицательный: процесс обучения на побочной задаче не сходится. Динамика обучения представлена на рис. 7.
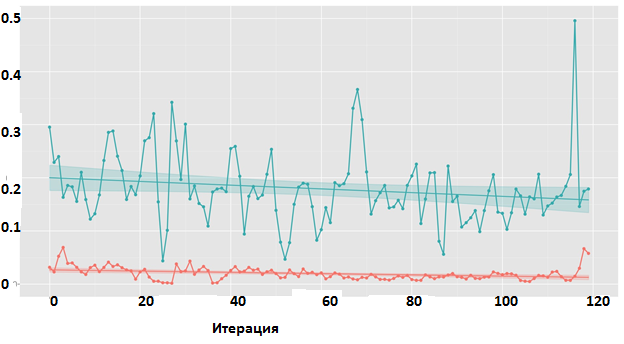
Рис 7. Предобучение на задаче предсказания lba следующего запроса Изменение среднеквадратичной ошибки на протяжении обучения.
Комментарий к рис. 7. Красный — тренировочная выборка, зеленый — тестовая. График для модели с двумя рекуррентными слоями.
HRNN
Были опробованы модели для различных наборов параметров, с двумя уровнями: первый для каждого блока, второй для множества блоков. Результат эксперимента отрицательный. Динамика обучения представлена на рис. 8.
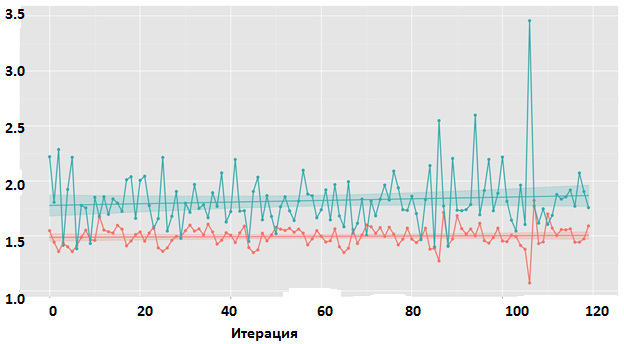
Рис 8. HRNN. Изменение значения функции потерь на протяжении обучения.
Комментарий к рис. 8. Красный — тренировочная выборка, зеленый — тестовая. График для модели средней сложности с двумя рекуррентными слоями на втором уровне.
Как видим, нейронные сети не дали хороших результатов. И мы решили попробовать традиционные методы машинного обучения.
Традиционные методы машинного обучения. Аттрибуты и признаки.
Частотные характеристики и производные от них
Введем следующие обозначения:
- count_lba — количество использований lba в пределах блока;
- count_diff_lba — частоты встречаемости разностей между lba текущего запроса и предыдущего;
- count_len — частоты встречаемости запросов к блокам данной длины len;
- count_diff_len — частоты встречаемости разностей между len текущего и предыдущего запросов.
Далее для каждого признака подсчитываются статистики — моменты: среднее, стандартное отклонение, коэффициент ассиметрии и коэффициент эксцесса.
Разностные характеристики и производные от них
Разность между lba текущего и i-предыдущего по счету блока (назовем ее diff_lba_i) может послужить в качестве основы нового признака. Каждая такая разность diff_lba_i распределена симметрично и имеет среднее, равное нулю. Поэтому различия между распределениями diff_lba_i для различных i можно описывать с помощью единственного числа — стандартного отклонения этой величины. Таким образом, для каждого блока получается набор из n значений std_diff_lba_i, где i = 1..10 (назовем этот набор lba_interdiffs). Гипотеза состоит в том, что для хороших блоков запросов эти значения будут отличаться меньше, иначе говоря, будут более концентрированы, чем для плохих блоков. Концентрированность значений можно охарактеризовать с помощью среднего и стандартного отклонения. Различия между ними можно увидеть на рис. 9,10, который показывает, что гипотеза подтверждается.
Аналогично подсчитываются признаки для длин, запрошенных данных.
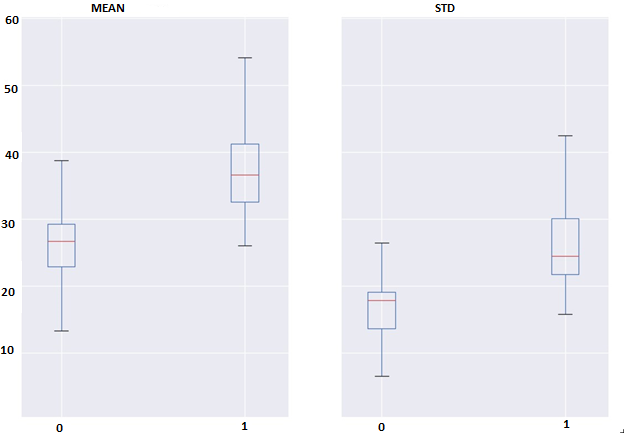
Рис. 9. Различия для классов между средними и стандартными отклонениями признака count_lba

Рис. 10. Различия для классов между средними и стандартными отклонениями признака lba_interdiffs
Анализ признаков
Для анализа различия между классами относительно признаков были построены диаграммы размаха (boxplots). Например, на рис. 9. отображены различия 1 и 2 моментов признака count_lba, и на рис. 10 представлены различия 1 и 2 моментов признака lba_interdiffs между классами.
Диаграммы размаха показывают, что ни один признак не проявляет достаточно значимых различий между классами для определения только на его основе. В то же время, совокупность слабых не коррелирующих признаков может позволить различать классы блоков.
Важно отметить, что при вычислении признаков требуется взять большое значение параметра blocksize, так как на небольших блоках запросов многие признаки обращаются в ноль.
Ансамбли деревьев решений
Примером традиционных методов машинного обучения являются ансамбли деревьев решений. Одна из его эффективных реализаций — библиотека XGBoost [10], которая показала хорошие результаты во многих соревнованиях по анализу данных.
Динамику процесса обучения можно наблюдать на рис. 11. На тестовой выборке достигается ошибка классификации около 3.2%. На рис. 12 можно увидеть прогноз модели на тестовой выборке.
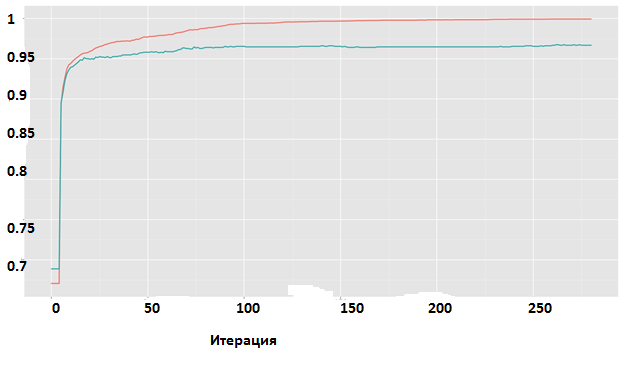
Рис. 11. XGBoost. Изменение точности классификации на протяжении обучения. Красный — тренировочная выборка, зеленый — тестовая.
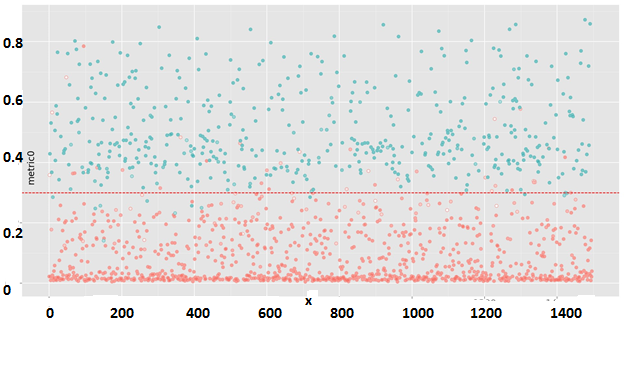
Рис 12. XGBoost. Прогноз модели на случайной тестовой выборке
Комментарий к рис. 12. Цветом обозначен прогноз модели: красный — плохо кэшируемый блок, зеленый — хорошо кэшируемый. Степень насыщенности цвета — это вероятность, выведенная моделью. Ось x: номер блока в тестовой выборке, ось y: исходное значение метрики. Пунктирная линия — барьер метрики, по которому блоки были разделены на два класса для обучения модели. Ошибка классификации 3.2%.
Ошибки 1 рода
В задаче кэширования важно не допускать ошибок 1 рода, то есть ложных положительных прогнозов. Другими словами, лучше пропустить блок, подходящий для кэширования, чем записать в кэш-память
невостребованные данные. Для балансирования между вероятностью выдачи ложного положительного и ложного отрицательного прогнзов можно изменять барьер вероятности, после которого прогноз будет считаться положительным. Зависимость этих величин показана на рис. 13.
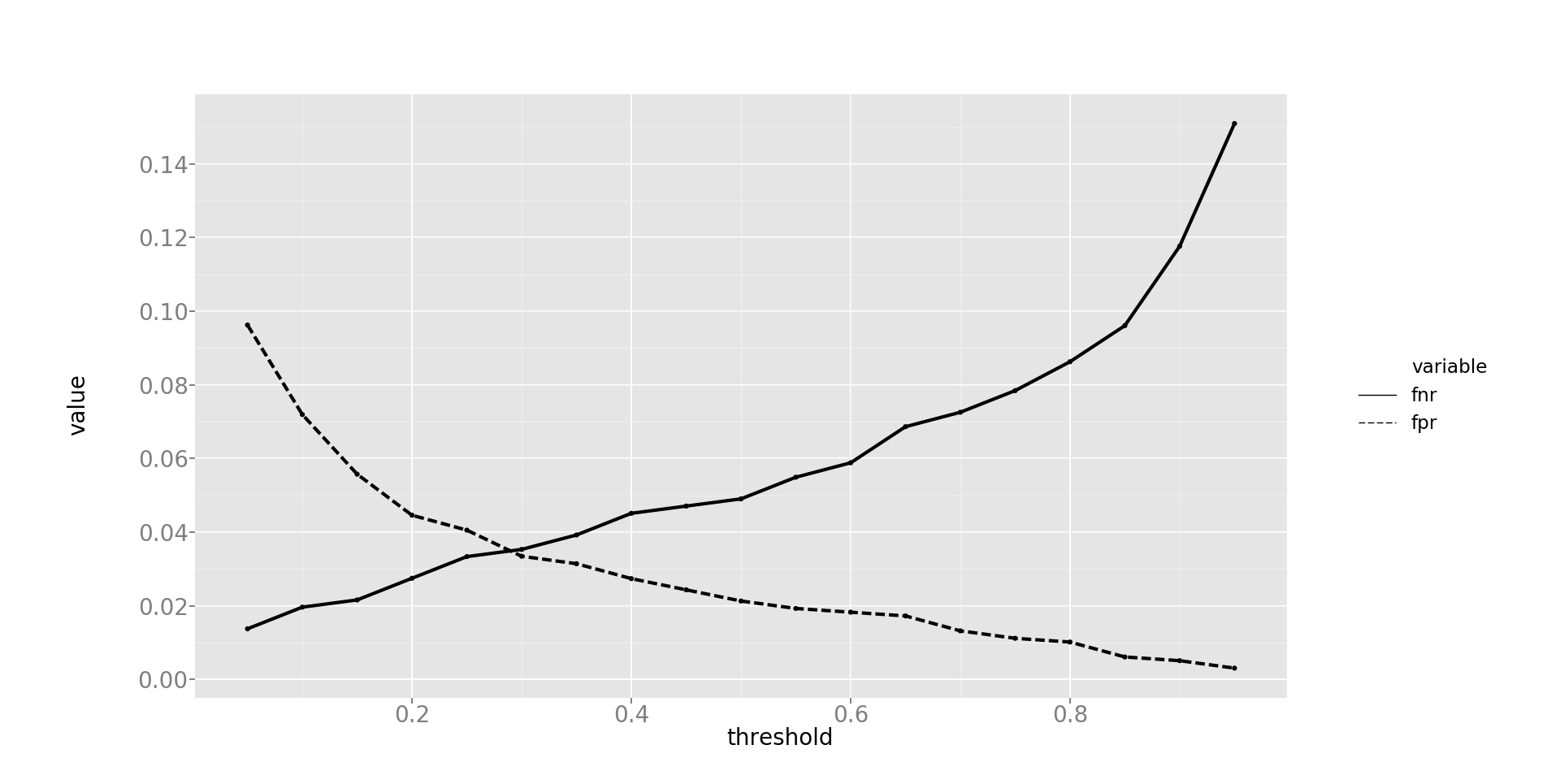
Рис. 13. Зависимость вероятности выдачи ложного положительного и ложного отрицательного прогнозов в зависимости от барьера вероятности, после которого прогноз считается положительным.
Комментарий к рис. 13. Ось x: барьер вероятности, ось y: вероятность совершения ошибки. Пунктирная линия — вероятность совершения ложной положительной ошибки, сплошная линия — вероятность совершения ложной отрицательной ошибки.
Итоговый алгоритм — фейс-контроль
Опишем итоговый алгоритм, описывающий технику заполнения SSD-кэша. Он состоит из трех частей: алгоритма, который формирует обучающее множество из логов клиента, алгоритма, который формирует модель предсказания (алгоритм 2) и итогового онлайн-алгоритма, который классифицирует приходящие блоки запросов на “хорошие” и “плохие”.
Алгоритм 1. Формирование обучающего множества
- Имеющуюся выборку делим на блоки размера blocksize.
- Для каждого блока считаем признаки из пунктов 3.3.1 и 3.3.2.
- Для каждого блока считаем коэффициент WE.
- Для каждого блока с помощью коэффициента WE определяем класс блока: плохой или хороший.
- Составляем пары (признаки — класс). Признакам одного блока в соответствие ставится класс следующего блока.
Алгоритм 2. Учитель
Вход: список (признаки-класс) из алгоритма 1.
Основной цикл: алгоритм XGBoost.
Выход: предсказатель.
Алгоритм. Фейс-контроль
Вход: блок запросов длины blocksize, m.
Основной цикл: предсказатель из алгоритма-учителя.
Выход: Если блок определился как хороший, то следующий блок запросов идет на SSD. Если блок определился, как плохой, то следующий блок запросов идет в RAM.Если не удалось определить- то запросы из следующего блока идут на SSD, если их частота больше единицы (используется метод LRU- очереди из алгоритма LARC).
Сравнение алгоритма с фейс-контролем и популярных реализаций SSD-кэша
Алгоритм фейс-контроль был апробирован в математической модели, где он сравнивался с известными реализациями SSD-кэша. Результаты представлены в таблице 2. В оперативной памяти RAM везде алгоритм вытеснения LRU. В SSD-кэше техники вытеснения LRU, LRFU, LARC. Hits — это количество попаданий в миллионах. Фейс-контроль был реализован вместе с техникой вытеснения LRFU, она показала наилучшие результаты совместно с фейс-контролем.
Как мы видим, при реализации фейс-контроля существенно снижается количество записей на SSD, тем самым увеличивается срок службы твердотельного накопителя и по метрике WE алгоритм с фейс-контролем является самым эффективным.
Таблица 2. Сравнение различных реализаций SSD-кэша
| LRU | LRFU | LARC | Фейс-контроль+ LRFU | |
|---|---|---|---|---|
| RAM hits | 37 | 37 | 37 | 36.4 |
| RRC hits | 8.9 | 8 | 8.2 | 8 |
| HDD hits | 123.4 | 124.3 | 124.1 | 124.9 |
| SSD writes | 10.8 | 12.1 | 3.1 | 1.8 |
| WE | 0.8 | 0.66 | 2.64 | 4.44 |
Заключение
Гибридные системы хранения данных очень востребованы на рынке из-за оптимальной цены на 1 гигабайт. Более высокие показатели производительности достигаются за счет использования твердотельных накопителей в качестве буфера.
Но SSD имеют ограниченное число записей — перезаписей, соответственно использовать стандартные техники для реализации буфера экономически не выгодно см. таблицу 2, так как SSD быстро изнашиваются и требуют замены.
Предложенный алгоритм увеличивает срок службы SSD в 6 раз по сравнению с простейшей техникой LRU.
Фейс-контроль анализирует входящие запросы, используя методы машинного обучения и не пускает “ненужные” данные в SSD-кэш, тем самым улучшая метрику эффективности кэширования в несколько раз.
В дальнейшем планируется оптимизировать параметр blocksize и улучшить технику вытеснения, а также попробовать другие комбинации техники вытеснения в SSD-кэше и оперативной памяти.
Список литературы
- Caching less for better performance: balancing cache size and update cost of flash memory cache in hybrid storage systems. / Yongseok Oh, Jongmoo Choi, Donghee Lee, Sam H Noh // FAST. –– Vol. 12. –– 2012.
- Elastic Queue: A Universal SSD Lifetime Extension Plug-in for Cache Replacement Algorithms / Yushi Liang, Yunpeng Chai, Ning Bao et al. // Proceedings of the 9th ACM International on Systems and Storage Conference / ACM. –– 2016. –– P. 5.
- Goodfellow Ian, Bengio Yoshua, Courville Aaron. Deep Learning. –– 2016. –– Book in preparation for MIT Press. URL
- Improving flash-based disk cache with lazy adaptive replacement /Sai Huang, Qingsong Wei, Dan Feng et al. // ACM Transactions on Storage (TOS). –– 2016. –– Vol. 12, no. 2. –– P. 8.
- Kgil Taeho, Roberts David, Mudge Trevor. Improving NAND flash based disk caches // Computer Architecture, 2008. ISCA’08. 35th International Symposium on / IEEE. –– 2008. –– P. 327–338.
- WEC: Improving Durability of SSD Cache Drives by Caching WriteEfficient Data / Yunpeng Chai, Zhihui Du, Xiao Qin, David A Bader //IEEE Transactions on Computers. –– 2015. –– Vol. 64, no. 11. –– P. 3304– 3316.
- Kingma Diederik, Ba Jimmy. Adam: A method for stochastic optimization // arXiv preprint arXiv:1412.6980. –– 2014.
- Glorot Xavier, Bengio Yoshua. Understanding the difficulty of training deep feedforward neural networks. // Aistats. –– Vol. 9. –– 2010. –– P. 249–256.
- Graves Alex. Supervised sequence labelling // Supervised Sequence Labelling with Recurrent Neural Networks. –– Springer, 2012. –– P. 5– 13.
- Chen Tianqi, Guestrin Carlos. XGBoost: A Scalable Tree Boosting System // CoRR. –– 2016. –– Vol. abs/1603.02754. –– URL