

В этой статье мы продолжаем рассказывать о том, как можно хранить метаданные в СХД при помощи баз данных key-value.
На этот раз в центре нашего внимания выделенные БД: Aerospike и RocksDB. Описание значимости метаданных в СХД, а также результаты тестирования встроенных БД можно посмотреть тут.
Параметры тестирования key-value БД
Кратко напомним основные параметры, по которым мы проводили тестирование (подробности в предыдущей статье).
Основной workload — Mix50/50. Дополнительно оценивали: RR, Mix70/30 и Mix30/70.
Тестирование проводили в 3 этапа:
- Заполнение БД — заполняем в 1 поток БД до необходимого количества ключей.
1.1 Сбрасываем кэши! Иначе тесты будут нечестными: БД обычно пишут данные поверх файловой системы, поэтому срабатывает кэш операционной системы. Важно сбрасывать его перед каждым тестом. - Тесты на 32 потока — прогоняем workload'ы
2.1 Random Read
• Сбрасываем кэши!
2.2 Mix70/30
• Сбрасываем кэши!
2.3 Mix50/50
• Сбрасываем кэши!
2.4 Mix30/70
• Сбрасываем кэши! - Тесты на 256 потоков.
3.1 То же самое, что и на 32 потока.
Измеряемые показатели
- Пропускная способности/throughput (IOPS/RPS — кто какие обозначения больше любит).
- Задержки/latency (msec):
• Min.
• Max.
• Среднее квадратическое значение — более показательное значение, чем среднее арифметическое, т.к. учитывает квадратичное отклонение.
• Перцентиль 99.99.
Тестовое окружение
Конфигурация:
| CPU: | 2x Intel Xeon E5-2620 v4 2.10GHz |
| RAM: | 16GB |
| Disk: | [2x] NVMe HGST SN100 1.5TB |
| OS: | CentOS Linux 7.2 kernel 3.11 |
| FS: | EXT4 |
Объем доступной RAM регулировался не физически, а программно — часть заполнялась искусственно скриптом на Python, а остаток был свободен для БД и кэшей.
Выделенные БД. Aerospike
Чем Aerospike отличается от движков, которые мы до этого тестировали?
- Индекс в RAM
- Использование RAW дисков (= нет ФС)
- Не дерево, а хэш.
Так сложилось, что в индексе Aerospike на каждый ключ хранится 64Б (а сам ключ у нас всего 8Б). При этом индекс всегда полностью должен быть в RAM.
Это означает, что при нашем количестве ключей индекс не поместится в памяти, которую мы выделяем. Надо уменьшить количество ключей. И наши данные это позволяют!

Рис. 1. Схема упаковки 1
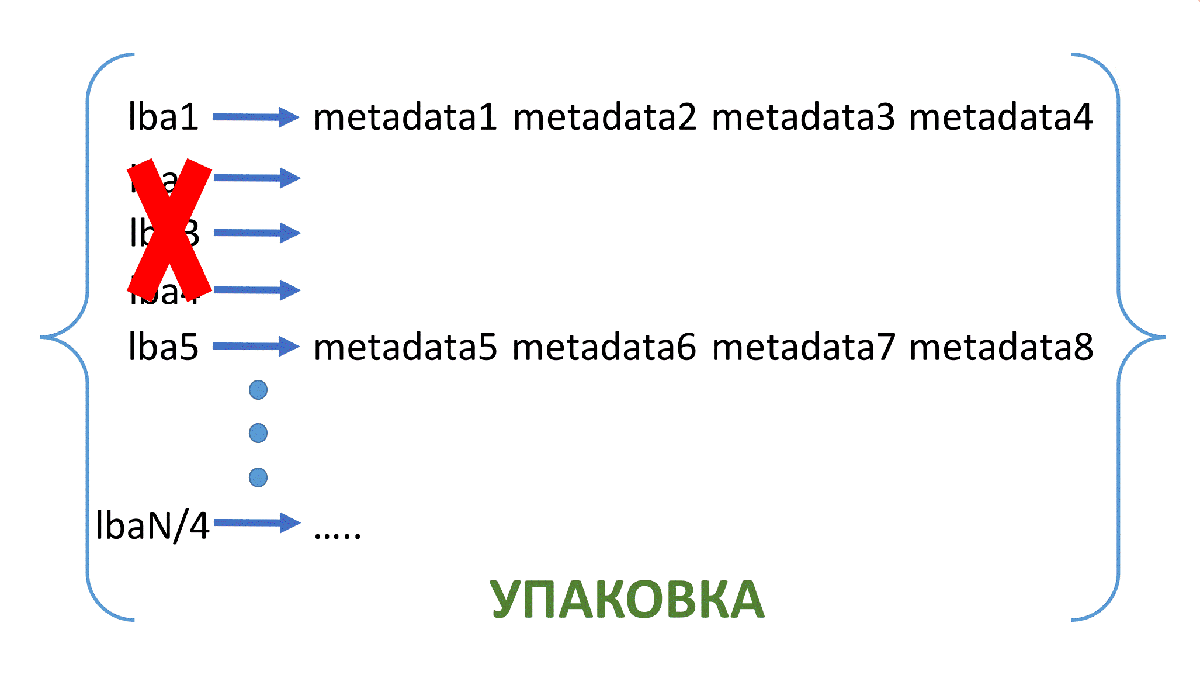
Рис. 2. Схема упаковки 2
Итак, с помощью такой упаковки мы уменьшили количество ключей в 4 раза. Таким же образом можем уменьшить их количество в k раз. Тогда размер значения будет 16*k Б.
Тестирование. 17 млрд ключей
Чтобы индекс Aerospike на 17 млрд ключей (17 млрд сопоставлений lba->metadata) поместился в RAM, надо упаковать это всё в 64 раза.
В итоге получим 265 625 000 ключей (каждому из ключей будет соответствовать значение размером 1024Б, содержащее 64 экземпляра метаданных).
Тестировать будем с помощью YCSB. Он не выдаёт среднюю квадратическую задержку, поэтому её не будет на графиках.
Заполнение
Aerospike показал неплохой результат на заполнение. Ведёт себя очень стабильно.
Но заполнение проводилось в 16 потоков, а не в один, как было с движками. В один поток Aerospike выдавал около 20k IOPS. Скорее всего, дело в бенчмарке (т.е. в один поток бенчмарк просто не «выжимает» БД). Либо же Aerospike любит много потоков, а в один не готов выдавать большую пропускную способность.
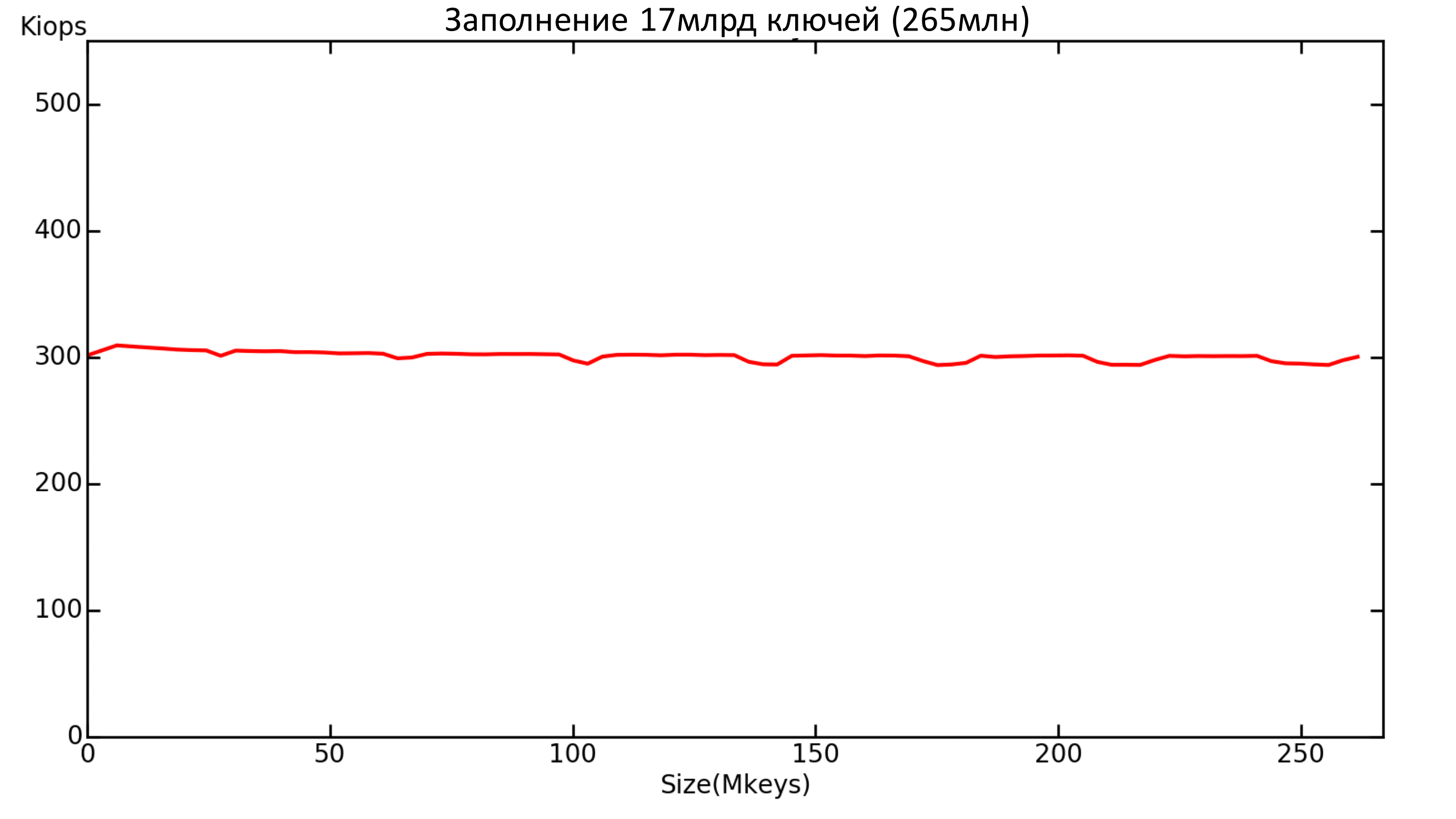
Рис. 3. Производительность заполнения базы
Максимальная задержка также держалась на примерно одинаковом уровне на протяжении всего заполнения.

Рис. 4. Latency заполнения базы
Тесты
Здесь важно отметить, что на этих графиках нельзя напрямую сравнивать Aerospike и RocksDB, т.к тесты проводились в разных условиях и разными бенчмарками – Aerospike использовался «с упаковкой», а RocksDB — без.
Также стоит учесть, что 1 IO у Aerospike = извлечение 64 значений (экземпляров метаданных).
Результаты RocksDB здесь приведены в качестве опорных.

Рис. 5. Сравнение Aerospike и RocksDB.100% Read

Рис. 6. Сравнение Aerospike и RocksDB. Mix 70%/30%

Рис. 7. Сравнение Aerospike и RocksDB Mix 50%/50%

Рис. 8. Сравнение Aerospike и RocksDB Mix 30%/70%
В итоге запись на малом количестве потоков получилась медленнее, чем у RocksDB (при этом следует помнить, что в случае Aerospike за один раз записывается сразу 64 значения).
Но на большом количестве потоков Aerospike всё же выдаёт более высокие значения.

Рис. 9. Aerospike. Latency Read 100%
Тут мы, наконец-то, смогли получить приемлемый уровень задержки. Но только в тесте на чтение.

Рис. 10. Aerospike.Latency Mix 50%/50%
Теперь можно обновить список выводов:
- Запись + мало потоков => WiredTiger
- Запись + много потоков => RocksDB
- Чтение + DATA > RAM => RocksDB
- Чтение + DATA < RAM => MDBX
- Много потоков + DATA > RAM + Упаковка => Aerospike
Итоговый вывод по выбору БД для метаданных: в таком виде ни один из претендентов не достигает нужных нам показателей. Ближе всех Aerospike.
Ниже мы расскажем о том, что с этим можно делать, и что нам дает хранение данных в прямой адресации.
Прямая адресация. 137 млрд ключей
Рассмотрим системы хранения объемом 512 ТВ. Метаданные такой системы хранения как раз помещаются на одну NVME и соответствуют 137 млрд ключей для key-value базы данных.
Рассмотрим простейшую реализацию прямой адресации. Для этого на одном узле создадим SPDK NVMf таргет, на другом узле возьмем локальную NVMe и этот NVMf таргет и объединим их в логический RAID1.
Такой подход позволит записывать метаданные и защищать их репликой на случай отказа.
При тестировании производительности в несколько потоков каждый поток будет писать в свою область и эти области не будут пересекаться.
Тестирование проводилось с помощью бенчмарка FIO в 8 потоков с глубиной очереди 32. В таблице ниже представлены результаты тестирования.
Таблица 1. Тестирование прямой адресации
| rand read 4k (IOPS) | rand write 4k (IOPS) | rand r/w 50/50 4K(IOPS) | rand r/w 70/30 4K(IOPS) | rand r/w 30/70 4K(IOPS) | |
|---|---|---|---|---|---|
| spdk | 760 — 770 K | 350 — 360 K | 400 — 410 K | 520 — 540 K | 410 — 450 K |
| lat (ms) avg/max | 0.3 / 5 | 0.4 / 23 | 0.3 / 19 | 0,5 / 21 | 1,2 / 28 |
Теперь протестируем Aerospike в аналогичной конфигурации, где 137 млрд ключей как раз также помещаются на одну NVMe и реплицируются на другую NVMe.
Тестируем с помощью «родного» бенчмарка Aerospike. Берем два бенчмарка – каждый на своем узле – и 256 потоков, чтобы выжать максимальную производительность.
Получаем следующие результаты:
Таблица 2. Тестирование Aerospike c репликацией
| R/W | IOPS | >1ms | >2ms | >4ms | 99.99 lat <= |
|---|---|---|---|---|---|
| 100/0 | 635000 | 7% | 1% | 0% | 50 |
| 70/30 | 425000 | 8% | 3% | 1% | 50 |
| 50/50 | 342000 | 8% | 4% | 1% | 50 |
| 30/70 | 271000 | 8% | 4% | 1% | 40 |
| 0/100 | 200000 | 0% | 0% | 0% | 36 |
Ниже приведены результаты тестирования без репликации, один бенчмарк в 256 потоков.
Таблица 3. Тестирование Aerospike без репликации
| R/W | IOPS | <=1ms | >1ms | >2ms | 99.99 lat <= |
|---|---|---|---|---|---|
| 100/0 | 413000 | 99% | 1% | 0% | 5 |
| 70/30 | 376000 | 95% | 5% | 2% | 7 |
| 50/50 | 360000 | 92% | 8% | 3% | 8 |
| 30/70 | 326000 | 93% | 7% | 3% | 8 |
| 0/100 | 260000 | 94% | 6% | 2% | 5 |
Заметим, что Aerospike c репликацией работает не хуже, а даже лучше. При этом возрастает latency по сравнению с тестированием Aerospike без репликации.
Также приведем результаты тестирования RocksDB без репликации (у RocksDB нет родной встроенной репликации) своим бенчмарком в 256 потоков, 137 млрд ключей с упаковкой.
Таблица 4. Тестирование RocksDB без репликации
| R/W | IOPS | <=1ms | >1ms | >2ms | 99.99 lat <= |
|---|---|---|---|---|---|
| 100/0 | 444000 | 93% | 7% | 2% | 300 |
| 70/30 | 188000 | 86% | 14% | 4% | 2000 |
| 50/50 | 107000 | 75% | 25% | 3% | 1800 |
| 30/70 | 73000 | 85% | 15% | 0% | 1200 |
| 0/100 | 97000 | 74% | 26% | 17% | 2500 |
Выводы
- RocksDB «c упаковкой» не проходит тесты по latency
- Aerospike c репликацией почти удовлетворяет критериям
- Простейшая реализация прямой адресации соответствует всем критериям по производительности и задержкам.
Постскриптум. Ограничения
Отметим важные параметры, которые остались за рамками данного исследования:
- Файловая система (ФС) и её настройки
- Настройки виртуальной памяти
- Настройки БД.
1. ФС и её настройки
- Есть мнение, что для RocksDB, например, хорошо подходит F2FS или XFS
- Также выбор ФС зависит от того, какие накопители используются в системе
- Размер страницы (блока) ФС
2. Настройки виртуальной памяти
- Можно почитать тут.
3. Настройки БД
- MDBX. От разработчика этого движка была получена рекомендация попробовать другой размер страниц в движке: 2 килобайта или размер кластера в NVME. В целом этот параметр важен и у других БД (даже в Aerospike).
- WiredTiger. Кроме параметра cache_size, который мы меняли, есть ещё масса параметров. Читать тут.
- RocksDB.
• Можно попробовать Direct IO: т.е. общение с диском, минуя page cache. Но тогда, скорее всего, надо будет увеличить block cache, встроенный в RocksDB. Об этом тут.
• Есть информация о том, как настроить RocksDB для NVME. Тут, кстати, используется XFS. - Aerospike. Также имеет много настроек, но их тюнинг за несколько часов не принёс ощутимых результатов.