
Конфигурация: ASP.NetCore на Linux позволила не только использовать существующую on-premise платформу, но и принесла еще несколько дополнительных плюсов, в частности, в виде полноценных Docker и Kubernetes, которые сильно упрощают жизнь.
О сервисе
С 1 апреля 2017 года в продуктах 2ГИС появилась иконка, на которую можно нажать и начнет проигрываться видео. Рекламодатели, которые размещаются в справочнике, теперь могут купить новый способ размещения рекламы, а все продукты нашей компании (мобильные, онлайн, API), ходят на сервис, про который я буду сегодня рассказывать.
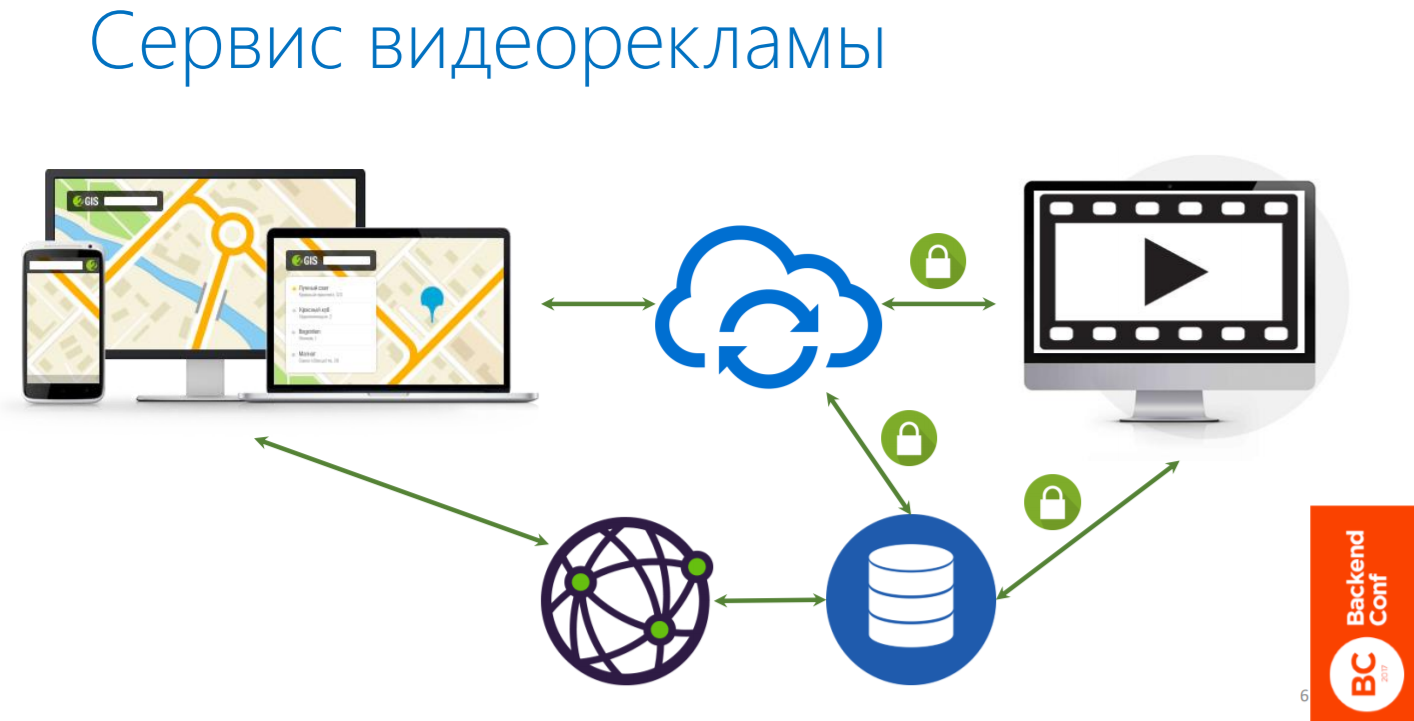
Топология этого сервиса примерно представлена на картинке ниже. Сервис помечен облачком в центре, он, по сути дела, является бэкендом для продуктов. Когда продукт приходит и говорит: «Дай мне для этого рекламодателя всю информацию о видеорекламе», сервис ему послушно ее отдает. Это информация такого плана: такая-то обложка лежит на таком-то CDN, такой-то видеофайл в таких-то разрешениях лежит там-то и там-то, само видео длится такое количество времени и прочее.
Осторожно: много информации и кода.
О спикере: Денис Иванов работает в компании 2ГИС и является MVP (Most Valuable Professional) в области Visual Studio and Development Technologies, его основной стек технологий — от Microsoft.
Содержание
- Коротко о сервисе
- On-premise платформа
- .NET Core, ASP.NET Core и базовые фичи
- Build
- Deploy
- Нагрузочное тестирование
- Средства повышения производительности, в том числе:
Итак, продолжим… На основании этой информации наши конечные продукты принимают решение, какой видеофайл отобразить: если это онлайн, у пользователя большой экран и широкий канал связи, то проигрывается видео большего разрешения; если мобильное устройство — меньшего.
Для того, чтобы раздавать видеоролики и их транскодить, мы используем отдельный API. Про него сегодня говорить не будем, также, как и про все, что касается обработки медиа файлов, их размещения на CDN, их доступность. Пока что это делает наш партнер, но возможно потом мы начнем делать это сами.
У нашего сервиса есть еще другая составляющая (то, что помечено на схеме замочками), для которой тоже есть свой API и он закрыт для внешнего доступа. Это внутренние процессы в компании, которые нужны для того, чтобы пользователи — наши менеджеры по продажам — продавали эту рекламу: загружали видео, изображения, выбирали обложки, то есть полностью настраивали то, как это будет выглядеть в конечном продукте. Там есть тоже свой API для таких процессов. Он закрыт для внешнего доступа.
Требования к сервису видеорекламы:
- 99.99% доступность по миру
Когда мы приступали к разработке сервиса первым требованием была высокая доступность, причем по всему миру. У нас есть пользователи в России, в странах СНГ и есть несколько международных проектов, даже в Чили.
- Время ответа 200ms
Время ответа должно быть настолько мало, насколько это возможно, в том числе, насколько это предоставляет API, которую мы используем. Мы выбрали цифру в 200 ms просто потому, что не хотим иметь никаких проблем — отвечать нужно очень быстро.
Почему Linux

Наша команда разработки в 2ГИС, занимается как раз рекламными сервисами и делаем систему продаж внутри компании. Этот проект — наш первый опыт разработки сервисов именно для публичного доступа. Мы, как команда разработки, очень хорошо знаем .NET, поскольку занимаемся этим 10 лет (я в компании 7 лет) и давно делаем приложения на этом стеке.
Для этого проекта мы выбрали ASP.Net Core. Из-за требований высокодоступности, о которых я уже говорил, нам нужно размещать сервис именно там, где размещаются наши конечные продукты, то есть использовать ту же самую платформу. Кроме того, что мы смогли использовать существующую on-premise платформу, которая есть в 2ГИС, мы еще получили несколько дополнительных плюсов:
- GitLab CI
На мой взгляд, это неплохой решение, которое помогает запускать процессы continuous integration и continuous deployment и хранить всю инфраструктуру, как код. Там есть YAML файл, в котором можно описать все шаги сборки.
- CI starting kit на основе make
В компании существует CI starting kit. Он, кстати, опенсорсный. На основе make ребята внутри компании написали много разных скриптов, которые просто позволяют облегчить рутинные задачи.
- Docker hub & docker images
Мы в полном объеме можем использовать Docker, поскольку это Linux. Понятно, что Docker существует также и на Windows, но технология довольно новая, и пока примеров продакшен-применения мало.
- Компоненты на любом технологическом стеке
Кроме того, если использовать Linux, можно делать свои приложения, используя любой технологический стек, микросервисный подход и т.д. Мы можем одни компоненты делать на .Net, другие — на иных платформах. Это преимущество мы использовали для того, чтобы выполнить нагрузочное тестирование своего приложения.
- Kubernetes
Kubernetes можно тоже использовать просто потому, что Linux.
Поэтому образовалась такая конфигурация: ASP.Net Core на Linux. Мы начали изучать, что для этого есть от Microsoft и от сообщества. На начало прошлого года все с этим вопросом было уже хорошо: .Net был зарелижен в 1 версии, библиотеки, которые нам понадобились бы, тоже были. Поэтому мы стартанули.
The Twelve-Factor App
Мы пришли к нашим ребятам, которые занимаются платформой для хостинга приложений, и спросили каким требованиям должно удовлетворять приложение, чтобы потом его было удобно эксплуатировать. Они сказали, что оно должно быть, как минимум, 12-факторным. Расскажу про это более подробно.
Есть свод из 12 правил. Считается, что если вы будете следовать им, то ваше приложение будет хорошее, изолированное, и его можно будет поднимать, используя все инструменты, которые касаются Docker и пр.
The Twelve-Factor App:
- Одно приложение — один репозиторий;
- Зависимости — вместе с приложением;
- Конфигурация через окружение;
- Используемые сервисы как ресурсы;
- Фазы билда, создания образов и исполнения разделены;
- Сервисы — отдельные stateless процессы;
- Port binding;
- Масштабирование через процессы;
- Быстрая остановка и запуск процессов;
- Среды максимально похожи;
- Логирование в stdout;
- Административные процессы.
Я хотел бы остановиться на некоторых из них.
Зависимости — вместе с приложением. Это значит, что приложение не должно требовать от среды, куда мы его развертываем, какой-либо преднастройки. Например, там не должно быть .Net определенной версии, как мы это любим на Windows. Мы должны таскать и приложение, и runtime, и те библиотеки, которые мы используем, вместе с самим приложением так, чтобы можно было просто его скопировать и запустить.
Конфигурация через окружение. Мы все используем Config-файлы для того, чтобы сконфигурировать приложение для его работы в runtime. Но хотелось бы, чтобы у нас были некие предустановленные значения в этих Config-файлах, и мы могли бы передавать через переменные окружения какие-то дополнительные параметры именно самого окружения так, чтобы заставить приложение работать в определённых режимах: это dev среда, либо staging среда, либо production.
Но код приложения и разные конфигурационные параметры не должны от этого меняться. В классическом .Net, который на Windows, есть такая штука, как трансформация конфигов (XDT-трансформация), которая здесь становится не нужна, и все сильно упрощается.
Еще одна важная особенность, которую привносит 12-факторность: мы должны уметь быстро останавливать и запускать новые процессы. Если мы используем приложение в какой-то среде, и вдруг с ним что-то случилось, мы не должны ждать. Лучше, чтобы среда сама погасила наше приложение и запустила его заново. В том числе, могут быть переконфигурации самой среды, на приложение это никак не должно влиять.
Логирование в stdout — еще одна важная вещь. Все логи, которые производит наше приложение, должны логироваться в консоль, а дальше уже та платформа, на которой работает приложение, разберется: взять эти логи, и положить их в файл, или в ELK в Elasticsearch или просто на консоль показать дополнительно.
.NET Core
У Microsoft уже давно есть старый добрый .NET, который на Windows, у которого есть WPF, Windows Forms, ASP.Net, под ним есть Base Class Library, Runtime и прочее.

Но, с другой стороны, всегда существовал альтернативный подход — взять mono и запускать по факту код, написанный на C# на других платформах. Microsoft сделали еще один стек под названием .NET Core, где как раз реализовали возможность писать приложения, которые будут изначально кроссплатформенными.
Они сделали довольно много для того, чтобы создать общую инфраструктуру: компиляторы, языки и рантаймы — все кроссплатформенно.
На .NET Core есть блок UWP — это отдельный мир. Он позволяет запускать .NET-приложения под разными платформами, от IoT-девайсов до десктопа. Например, я видел людей, которые запускают .NET Core-приложения на Raspberry Pi.
Существовало несколько базовых библиотек: Base Class Library, Core Library и Mono Class Library. С этим жить было довольно тяжело. Тогда же появилась Portable Class Library и т.д. Поэтому Microsoft пошел в сторону того, чтобы унифицировать API, которые являются кроссплатформеными и работают на всех этих стеках, и сделали .Net Standard Library.
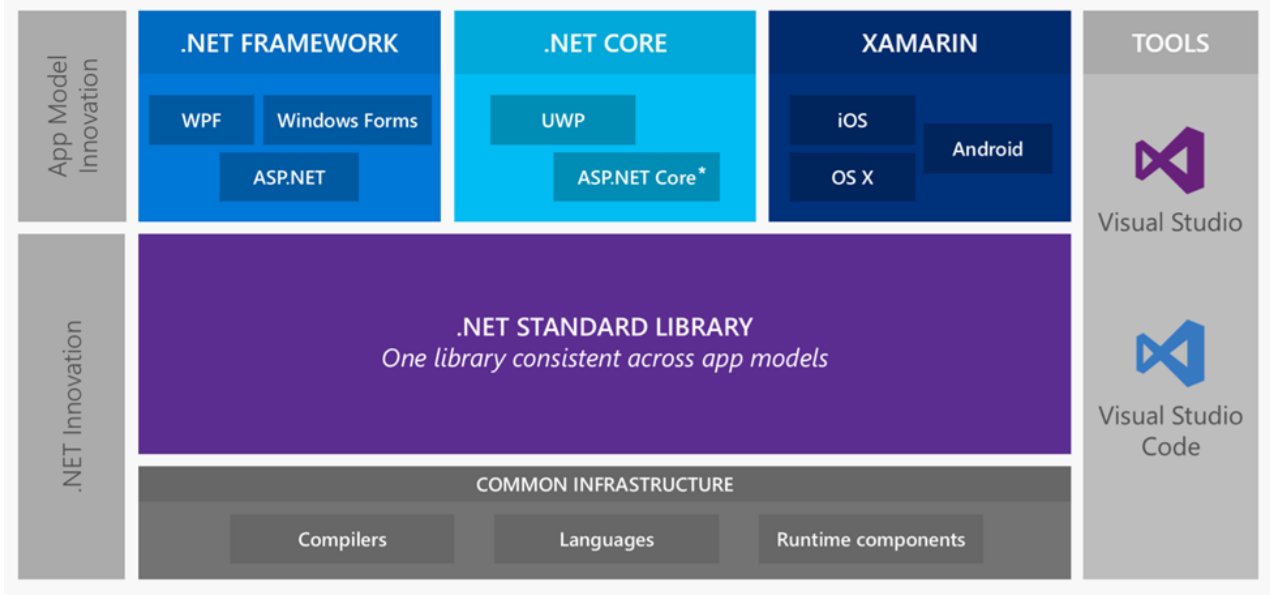
На текущий момент это .Net Standard версии 2.0, в которой практически все, что было в старом классическом .NET, работает кроссплатформенно.
Мы будем говорить про .NET Core и про его часть, которая касается ASP.Net Core.
.Net Core Self-contained deployment
Что же .Net Core дает нам с точки зрения 12-факторности? На самом деле 12-факторность реализуется здесь довольно хорошо.
Есть полный контроль зависимостей, т.е. мы имеем возможность собрать приложение и полностью контролировать его зависимости.
Мы можем сконфигурировать .NET-приложение таким образом, чтобы платформа была явно указана (win10-x64 / ubuntu.16.04-x64 / osx.10.12-x64) при билде, и в конечной папке артефактов получим все, что касается приложения, рантайма, библиотек, то есть все-все-все, собранное под определённую платформу. Для этого нам просто нужно ее выбрать — будь это Windows, Linux или OSX.
Как я уже говорил, нам нужно выбрать фреймворк (на текущий момент это netstandard1.6) и включить 2 библиотеки:
- Microsoft.NETCore.Runtime.CoreCLR для того, чтобы исполнять код приложения.
- Microsoft.NETCore.DotNetHostPolicy для того, чтобы запускать приложение на конечной системе.
Как работает ASP.Net Core
Вся идеология ASP.Net Core построена на принципах Middleware. У нас есть какое-то количество слоев, когда запрос приходит в наше приложение, на его пути становится первый Middleware, который выполняет свою логику, и передает этот запрос следующему. Следующий выполняет, пробрасывает следующему, и так далее до тех пор, пока конвейер не закончился. Обратно мы отправляем Response пользователю.
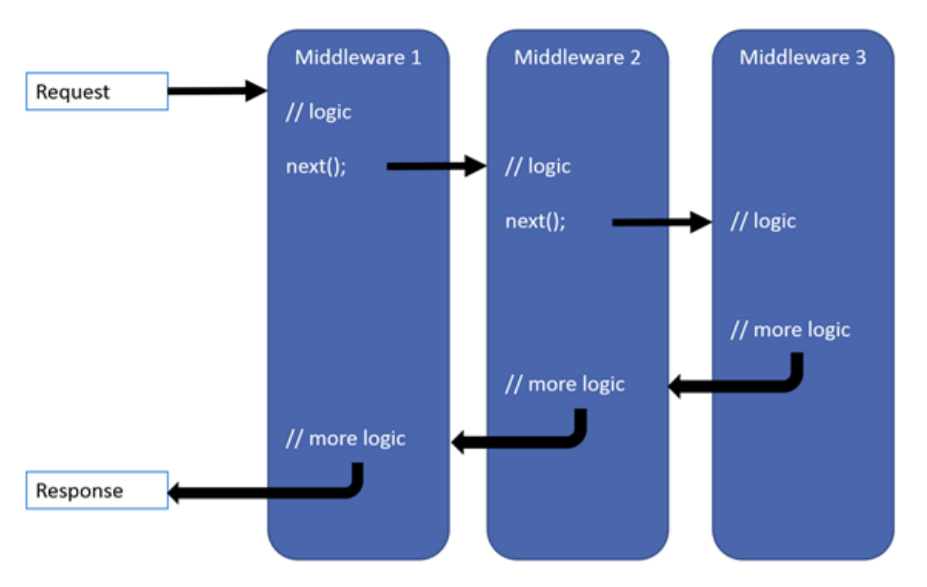
Если говорить о прикладных аспектах этого всего, то:
- На первом этапе можем вставить Exception handler для того, чтобы все исключения полностью отслеживались, логировались и прочее.
- Вторым Middleware может быть модуль безопасности.
- Третьим может быть MVC-фреймворк, который занимается роутингом и отдает либо данные (в случае REST сервисов), либо странички.
Это простейший пример Middleware, примерно такой мы и делали для того, чтобы хостить приложение в Kubernetes. Давайте подробно посмотрим на то, что здесь есть.
public sealed class HealthCheckMiddleware
{
private const string Path = "/healthcheck";
private readonly RequestDelegate _next;
public HealthCheckMiddleware(RequestDelegate next)
{
_next = next;
}
public async Task Invoke(HttpContext context)
{
if (!context.Request.Path.Equals(Path,
StringComparison.OrdinalIgnoreCase))
{
await _next(context);
}
else
{
context.Response.ContentType = "text/plain";
context.Response.StatusCode = 200;
context.Response.Headers.Add(HeaderNames.Connection, "close");
await context.Response.WriteAsync("OK");
}
}
}
Здесь в конструкторе есть RequestDelegate next. Это следующий Middleware, который вставляется в конструктор, и у нас появляется возможность отправить ему запрос. Конкретно этот Middleware занимается тем, что отвечает на все запросы, которые пришли по /healthcheck.
Если запрос пришел не на этот путь (path), тогда мы отдаем управление следующему Middleware, то есть пробрасываем его дальше. Если на этот, то мы говорим 200, все хорошо, предложение работает, и выводим в консоль ОК. Дальше запрос не продолжает выполняться. На этом все и заканчивается.
Это очень быстрая штука. В наших тестах весь этот код работает буквально за 2-3 мс.
Базовые фичи REST-сервисов
Вот базовые фичи REST-сервисов, которые обычно нужны, когда мы делаем такие приложения:
- Логирование нужно всем и было бы замечательно, чтобы оно было структурным.
- Версионирование API (SemVer, DateTime) — хорошо бы, чтобы оно было прямо из коробки.
- Также замечательно иметь формальное описание API (Swagger).
Структурное логирование
Если его визуализировать, то оно выглядит примерно так.
Здесь есть консоль с разноцветными строчками. На самом деле, если посмотреть более детально, мы увидим, что у каждого сообщения, которое выводится в log, есть Data, уровень (error, warning, info) и так далее. Но, кроме того, есть некоторые параметры, которые как раз и подсвечены разными цветами.
Кроме текста логов, у нас еще могут быть какие-то пары ключ/значение, которые можно явным образом индексировать. Если мы хотим, допустим, логировать полностью все, что отдает наше приложение по определенному запросу, мы можем в лог добавить request id именно, как пара ключ/значение: request id равно столько-то. Потом есть возможность по этому request id наши логи где-то проиндексировать. В конечном итоге, просто отфильтровав все логи по этому request id, мы можем найти все сообщения, которые были сгенерированы этим запросом. Эту замечательную штуку нам дает структурное логирование.
Для того, чтобы выполнять логирование, в ASP.Net Core есть замечательные библиотеки Serilog, log4net и NLog. Мы остановились именно на Serilog, потому что там все есть из коробки, в том числе возможность выводить логи в любом формате, не только в любые консоли или в подсвеченную консоль, но и сразу, если вдруг вам понадобится, в Эластик или в файл.
appsettings.json
{
"Serilog": {
"MinimumLevel": "Debug",
"WriteTo": [
{
"Name": "Console",
"Args": {
"formatter":
"Serilog.Formatting.Compact.RenderedCompactJsonFormatter,
Serilog.Formatting.Compact"
}
}
],
"Enrich": [ "FromLogContext", "WithThreadId" ]
}
}
Таким образом она настраивается. У нас есть уровень логирования. Дальше мы говорим о том, что хотим выводить логи в консоль, и то, в каком виде эти логи должны выводиться в консоль. Если же у нас приложение работает на staging или в production-среде, хотелось бы, чтобы эти все логи выводились в Json формате, чтобы потом среда могла их забирать и каким-то образом индексировать. Опять же все это есть из коробки и есть возможность обогащать все эти логи какими-то дополнительными параметрами, например, выводить ThreadId, RequestId и прочее таким декларативным образом.
Версионирование API
Нам хотелось бы, чтобы API сервиса, который мы делаем, поддерживало версионирование из коробки. Когда мы работаем именно с публичными клиентами и не знаем, сколько их и какие они в принципе, версионирование очень полезная штука.
В нашем случае это как раз было важно, потому что у нас есть разные клиенты. Жизненный цикл работы конкретной версии мобильного приложения 2GIS может достигать полугода, а то и больше. То есть пользователи могут не обновлять приложение на устройстве больше, чем полгода.
Но, тем не менее, если эта конкретная версия приложения приходит на бэкенд, мы должны отдать данные именно по тому контракту, который предполагается для этого устройства и для этой версии приложения. Если потом с течением времени (это обычно бывает) мы взяли и поменяли что-то в API — добавили, или, еще хуже, удалили какие-то данные из ответа, или в принципе поменяли контракт взаимодействия, не хотелось бы, чтобы это сломало старое приложение.
Есть замечательная библиотека ASP.NET API versioning от Microsoft. Она полностью опенсорсная, работает по тем гайд-лайнам, которые Microsoft публично сформулировал для своих сервисов, и дает возможность версионировать API в разных вариантах, в том числе, с помощью SemVer или по датам, как делает, например, Netflix.
Опять же есть разные варианты передачи информации о версии API: через query string, URL path, header — все поддерживается из коробки.
Допустим, у нас есть такой контроллер.
[ApiVersion("1.0")]
[Route("api/medias")] // /api/medias
[Route("api/{version:apiVersion}/medias")] // /api/1.0/medias
public sealed class MediasController : Controller
{
// /api/medias/id?api-version=1.0 or /api/1.0/medias/id
[HttpGet("{id}")]
public async Task<IActionResult> Get(long id)
{
...
}
}
Все, что мы должны сделать, это вначале указать, что версия API, которую предоставляет контроллер — 1.0. Дальше мы должны написать наши запросы так, чтобы включить информацию о версии API.
В такой конфигурации есть два способа включить версию API в запрос — через URL path, либо через query string. Клиенты могут выбрать удобный для них способ, но все запросы будут приходить на один и тот же endpoint.
Если с течением времени у нас появляется вторая версия API, нам нужно сделать немногое — прийти в этот же самый контроллер и сказать, что у нас появилась вторая версия у этого же самого API.
[ApiVersion("1.0")]
[ApiVersion("2.0")]
[Route("api/medias")]
[Route("api/{version:apiVersion}/medias")]
public sealed class MediasController : GatewayController
{
// /api/medias/id?api-version=1.0 or /api/1.0/medias/id
[HttpGet("{id}")]
public async Task<IActionResult> Get(long id)
{
...
}
// /api/medias/id?api-version=2.0 or /api/2.0/medias/id
[MapToApiVersion("2.0")]
[HttpGet("{id}")]
public async Task<IActionResult> GetV2(long id)
{
...
}
}
На самом деле все, что нам нужно сделать, это оставить тот метод, который был, также ничего в нем не изменив. Он отдает данные для клиентов, которые знали об этой версии API на тот момент,
Мы можем добавить новый метод контроллера и сказать, чтобы все запросы, которые приходят на API 2.0, перенаправлялись сюда. Тем самым, мы не поломаем старых клиентов, и добавим функциональность для новых клиентов.
Это не обязательно делать в одном контроллере. Мы можем создать новый контроллер и сказать, что это контроллер для API версии 2.0 (строка
[MapToApiVersion("2.0")]). В-общем, есть много разных вариантов, и все делается очень просто.Swagger
Еще хочу рассказать о библиотеке Swashbuckle.AspNetCore, которая позволяет включить Swagger.
Про Swagger многие наслышаны, поэтому единственное, о чем хотелось бы сказать, что подключив Swashbuckle.AspNetCore для ASP.Net Core, мы получаем эту функциональность опять же из коробки, и она умеет дружить с версионированием API.
services.AddSwaggerGen(
x =>
{
IApiVersionDescriptionProvider provider;
foreach (var description in provider.ApiVersionDescriptions)
{
x.SwaggerDoc(description.GroupName, new Info { ... });
}
});
...
app.UseSwagger();
app.UseSwaggerUI(
c =>
{
IApiVersionDescriptionProvider provider;
foreach (var description in provider.ApiVersionDescriptions)
{
options.SwaggerEndpoint(
$"/swagger/{description.GroupName}/swagger.json",
description.GroupName.ToUpperInvariant());
}
});
То есть, сконфигурировав таким образом приложение, сказав, что у нас есть некий VersionDescriptionProvider, и просто пробежавшись foreach по ApiVersionDescriptions, мы можем добавить Swagger-документы, то есть те самые формальные описания наших API.
После этого мы можем добавить SwaggerUI, сказав, что у нас есть SwaggerEndpoint на таких- то json’ах, опять же в зависимости от версии API, которая у нас есть. Тем самым мы получим версионирование API, про которое знает Swagger, есть переключалка и возможность посмотреть, какие в той или иной версии API есть эти методы. Все круто и все это есть в демке, можете посмотреть.
Build
Плавно переходим дальше. Мы написали приложение, в котором есть вся необходимая функциональность, написали туда даже бизнес-логику. Как нам это все сбилдить? Да так, чтобы потом задеплоить!
На самом деле все довольно просто. Я говорил, что мы используем GitLab CI. Рассмотрим на примере одного из фрагментов GitLab CI файла один шаг сборки.
build:backend-conf-demo:
image: $REGISTRY/microsoft/aspnetcore-build:1.1.2
stage: build:app
script:
- dotnet restore --runtime ubuntu.16.04-x64
- dotnet test Demo.Tests/Demo.Tests.csproj
--configuration Release
- dotnet publish Demo --configuration Release
--runtime ubuntu.16.04-x64 --output publish/backend-conf
tags: [ 2gis, docker ]
artifacts:
paths:
- publish/backend-conf/
У нас есть некий билд степ, на котором мы хотим собрать приложение. Для этого нам опять нужно не так много: базовый образ, который предоставляется Microsoft. В этом образе есть все, что нужно: все инструменты, командная строка .Net, сам .Net определенной версии, runtime и т.д. Этот образ довольно большой, поэтому, конечно, тянуть его в продакшн ни в коем случае нельзя. Его нужно использовать только для того, чтобы собрать приложение.
Это как раз про ту самую 12-факторность, когда в стадии сборки и эксплуатации приложения должны быть разделены.
Используем этот образ, говорим: «Собери нам, пожалуйста, все зависимости, которые есть в этом приложении именно для этой платформы, под которую мы хотим собрать!»
Дальше, конечно же, мы хотим выполнить юнит-тесты перед тем, как собрать приложение. Если юнит-тесты не прошли, то ничего собирать уже не нужно потому, что приложение не работает. Если же все хорошо, говорим
dotnet publish и указываем как раз тот самый runtime, который нас интересует.Говорим о том, куда нужно все это развернуть с точки зрения тех артефактов, которые получатся. В папке
publish/backend-conf в этом примере будет лежать все, что касается приложений и его зависимостей.После того, как мы собрали приложение, нам нужно собрать Docker-образ, причем собирать образ прямо на каждое изменение, т.к. у нас есть тот самый CI_TAG на уровне Gitlub CI. На самом деле это уже шаг к Continuous deployment режиму.
build:backend-conf-demo-image:
stage: build:app
script:
- IMAGE=my-namespace/backend-conf TAG=$CI_TAG
DOCKER_FILE=publish/backend-conf/Dockerfile
DOCKER_BUILD_CONTEXT=publish/backend-conf
make docker-build
- IMAGE=my-namespace/backend-conf TAG=$CI_TAG
make docker-push
tags: [ docker-engine, io ]
dependencies:
- build:app
Далее конфигурируем другие параметры, берем артефакты, которые сгенерировали на прошлом шаге, и вызываем docker-build. После того, как docker-build прошел, мы получили образ локально и можем разместить его на docker-hub — локальный, глобальный — куда угодно.
Таким образом, у нас есть приложение, собранное под необходимую нам ОС и есть образ этого приложения на docker-hub.
Deploy
Все, что нам дальше нужно сделать, это развернуть его, и настало время поговорить про Kubernetes.
Kubernetes
Это средство оркестрации контейнеров, которое позволяет особо не заморачиваться в вопросах того, как эти контейнеры запускать, поднимать, следить за их логами и т.д. В нашей компании развернуто целых четыре кластера Kubernetes, которые можно использовать.
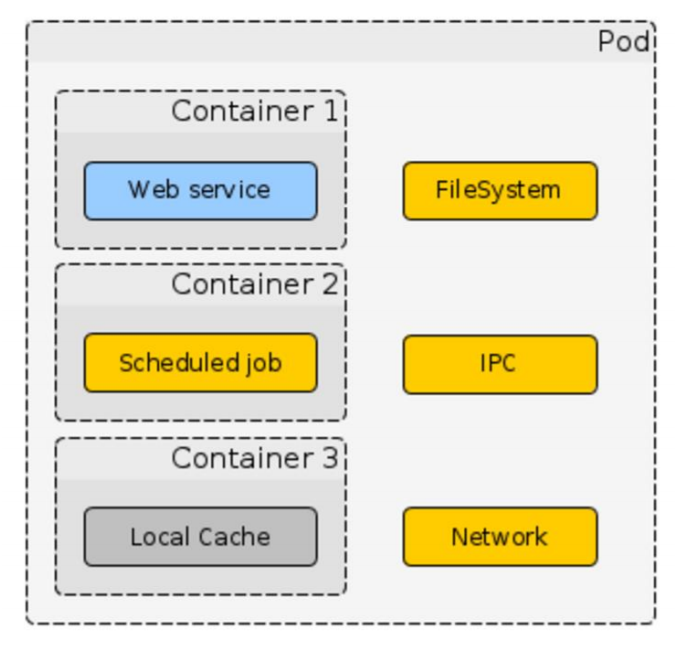
В Kubernetes есть базовые понятия.
Pod
Это логическое объединение контейнеров. Там может быть один контейнер, может быть несколько, и предполагается, что все контейнеры, которые лежат в Pod’е, жестко связаны между собой и используют какие-то общие ресурсы.
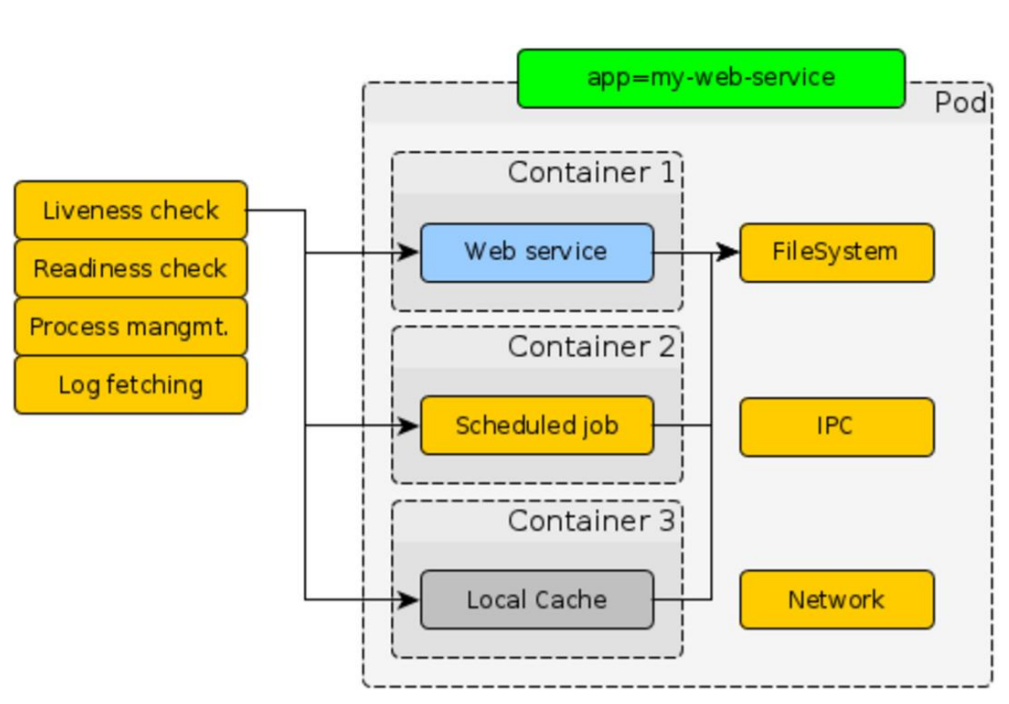
Kubernetes из коробки проверяет наше приложение: liveness check, readiness check, log fetching и так далее. Все эти вопросы, которые касаются управления контейнером, Kubernetes решает за нас.
Service
Вторая штука, которую важно знать, когда мы работаем с Kubernetes — это service. Она позволяет получать внешний трафик на Kubernetes и говорить, куда этот трафик перенаправить уже внутри Kubernetes — на какие Pod’ы, в какие контейнеры.
Для этого ему нужно 2 вещи:
- Selector. Label, который был проставлен для Pod’а как раз нужен, чтобы узнать все Pod’ы, которые есть для этого приложения;
- Ports Mapping предоставляет возможность перенаправлять контейнеры на разные порты.
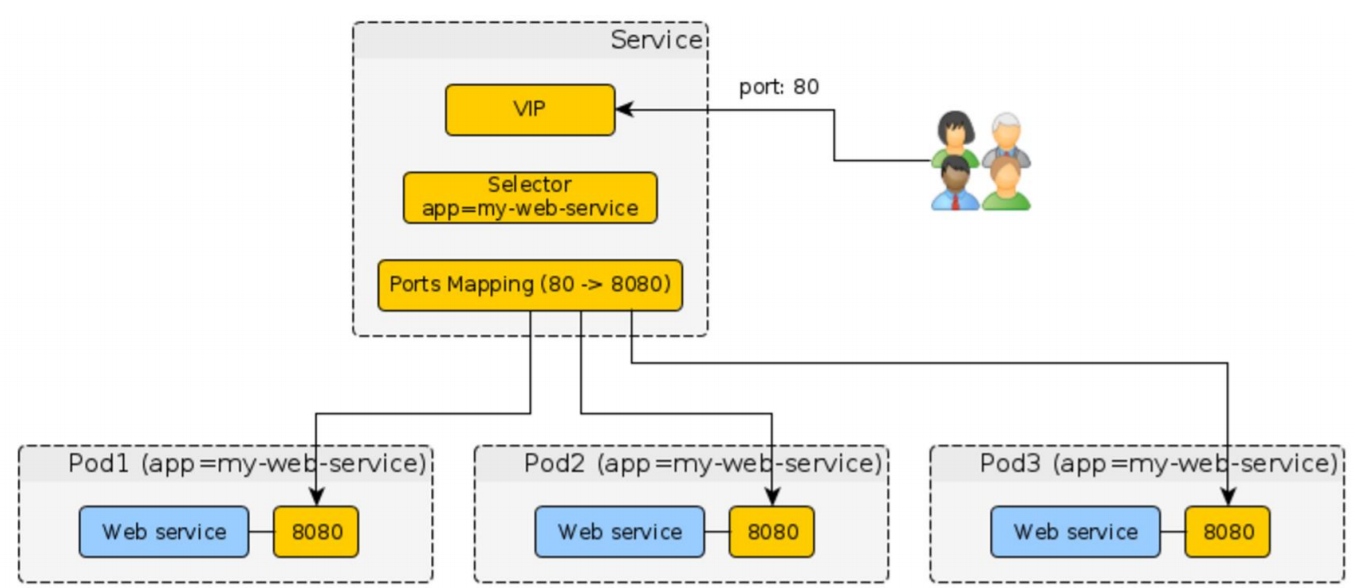
Общая картина на рисунке сверху: есть пользователи, которые приходят на кластер Kubernetes извне; мы получаем этот трафик, понимаем по доменному имени, кому он нужен; по селектору находим те Pod’ы; отправляем этот трафик на соответствующие порты в контейнерах.
Deployment
Позволяет развертывать Pod’ы автоматически на всем кластере Kubernetes. Вся картинка выглядит так.
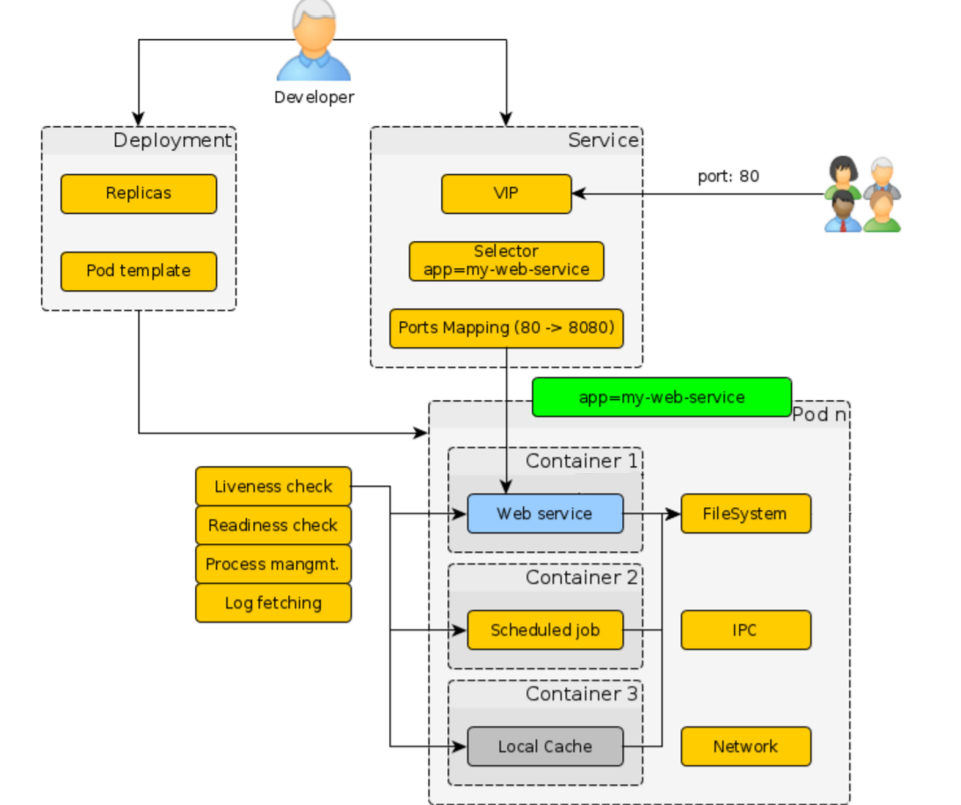
Как разработчики мы должны написать Deployment’ы, сказать, сколько нам нужно реплик, по какому шаблону, и т.д. Далее выставить все label для того, чтобы связать их с сервисом. Дальше написать сервис, который как раз будет стоять на входе в Kubernetes.
По сути дела, все — путь пользователя определен.
Единственное, чего нет в самом Kubernetes, и что нам пришлось добавить самостоятельно для того, чтобы задеплоить приложение конкретной версией на Kubernetes, это написать конкретные Deployment-файлы с указанием конкретной версией нашего приложения и конкретной версией образа. Это нужно для того, чтобы встроить все это в continuous deployment pipeline. Думаю, что не только мы этим занимались, поскольку пока Kubernetes не предоставляет такую возможность.
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: {{ app_name }}
spec:
replicas: {{ replicas_count }}
template:
metadata:
labels:
app: {{ app_name }}
spec:
containers:
- name: backend-conf
image: {{ image_path }}:{{ image_version }}
ports:
- containerPort: {{ app_port }}
readinessProbe:
httpGet: { path: '{{ app_probe_path }}', port: {{ app_port }} }
initialDelaySeconds: 10
periodSeconds: 10
env:
- name: ASPNETCORE_ENVIRONMENT
value: {{ env }}
Пример Deployment выше, и в нем есть:
- Label, про который я говорил, и который мы можем указывать где-то сверху через шаблонизатор.
- Указание, где лежит образ нашего приложения и его версия.
- CI_TAG.
- Указание, по какому порту нужно ходить к нашему приложению в этом контейнере.
- Проверку readiness для того, чтобы Kubernetes знал, работает ли наше приложение, все ли с ним хорошо или не очень.
- Переменные окружения.
Сервис выглядит таким образом.
apiVersion: v1
kind: Service
metadata:
name: {{ app_name }}
annotations:
router.deis.io/domains: "{{ app_name }}"
router.deis.io/ssl.enforce: "{{ ssl_enforce | default('False') }}"
spec:
ports:
- name: http
port: 80
targetPort: {{ app_port }}
selector:
app: {{ app_name }}
Мы говорим о том, что внешний порт у нас 8080, а внутренний мы передадим через шаблон. И, собственно, селектор.
Вот и весь сервис.
Дальше нам нужно указать параметры, чтобы собрать по этим шаблонизаторам файлы для Kubernetes.
common:
replicas_count: 1
max_unavailable: 0
k8s_master_uri: https://master.staging.dc-nsk1.hw:6443
k8s_token: "{{ env='K8S_TOKEN_STAGE' }}"
k8s_ca_base64: "{{ env='K8S_CA' }}"
k8s_namespace: my-namespace
ssl_enforce: true
app_port: 5000
app_probe_path: /healthcheck
image_version: "{{ env='CI_TAG' }}"
image_path: docker-hub.2gis.ru/my-namespace/backend-conf
env: Stage
backend-conf-demo:
app_name: "backend-conf-demo"
app_limits_cpu: 500m
app_requests_cpu: 100m
app_limits_memory: 800Mi
app_requests_memory: 300Mi
kubectl:
- template: deployment.yaml.j2
- template: service-stage.yaml.j2
Указываем, какой кластер Kubernetes мы будем использовать; порт приложения 5000;
app_probe_path: /healthcheck (тот самый Middleware); image version берется из переменной окружения; лежат эти образы там-то и окружение env, например, Stage. Для production будет другая переменная. Дальше прописываем ресурсы для приложения и шаблоны, которые я дал выше.После того, как мы все это сделали, пишем для gitlub CI еще один билд степ.
deploy:backend-conf-demo-stage:
stage: deploy:stage
when: manual
image: $REGISTRY/2gis-io/k8s-handle:latest
script:
- export ENVIRONMENT=Stage
- k8s-handle deploy
--config config-stage.yaml
--section backend-conf —sync-mode True
only:
- tags
tags: [ 2gis, docker ]
По факту, мы говорим о том, что у нас есть такой-то config-файл, поднимаем контейнер из образа на Docker hub и вызываем в нем утилиту k8s-handle.
Этого достаточно для того, чтобы развернуть любое, а не только ASP.Net Core приложение на Kubernetes. Так это работает в 2ГИС и особых проблем не доставляет.
Кстати, k8s-handle тоже опенсорсная штука.
Нагрузочное тестирование
Теперь нужно удостоверимся, что приложение, которое мы сделали, действительно отрабатывает нагрузки, является отказоустойчивым и отдается за определенное время.
Мы — разработчики, и особо в тестировании не соображаем, но в 2ГИС есть отдельная команда нагрузочного тестирования. Мы пришли к ним и сказали:
— Ребята, мы сделали приложение. У нас есть такие-то требования. МыКогда они к нам пришли, то спросили, что мы вообще хотим протестировать, мы ответили, что самое критичное для нас — это публичный endpoint, а нагрузочный контур у нас вот такой:
локально протестировали, все хорошо. Давайте его нагрузим!
— Да не проблема! Завтра придем и все сделаем!
— А как вы это делаете вообще?
— У нас есть свои инструменты. Вы на чем развертываете приложение?
— На Kubernetes.
— Замечательно! Значит, все будет круто!
- Есть некие продукты, которые генерируют нагрузку.
- Есть сервис.
- Есть провайдер — API, которая лежит под нашим сервисом.
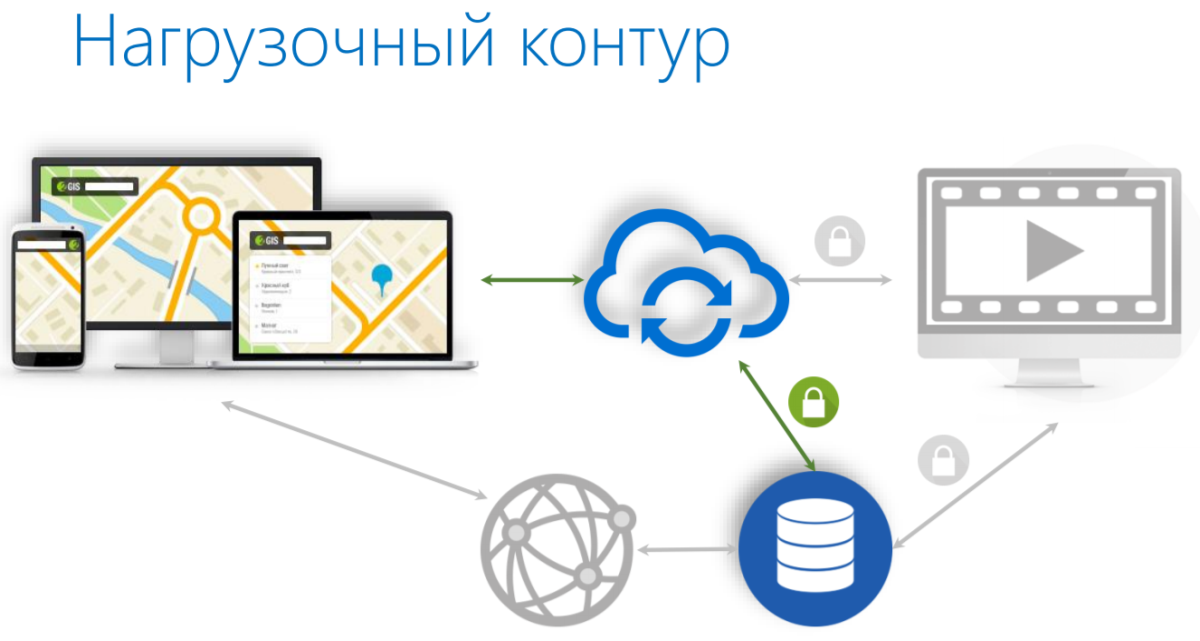
Тестировщики написали нам тесты на Scala. Они используют Gatling для того, чтобы выполнять нагрузочные тесты.

Здесь все просто. Написано, что у нас есть некоторые asserts, мы хотим, чтобы количество запросов в секунду было больше или меньше стольки-то. Мы хотим, чтобы не было непрошедших запросов, чтобы responseTime был столько-то.
После этого мы говорим, как нагрузочный тест нам проводить:
- Поднимать нагрузку с 1 до 20 пользователей, например, в течении 30 с.
- В течении еще двух минут держать постоянную нагрузку в 20 пользователей.
В конце нужно указать, что есть такой-то тест, с такими-то шагами, HTTP, время выполнения 180 с в нашем случае и вот такие-то asserts.
Это один из примеров нагрузочного теста.
После этого они нам написали template в gitlub CI.
.perf:template: &perf_template
stage: test:perf
environment: perf
only:
- master
- /^perf.*$/
variables:
PERF_TEST_PATH: "tests/perf"
PERF_ARTIFACTS: "target/gatling"
PERF_GRAPHITE_HOST: "graphite-exporter.perf.os-n3.hw"
PERF_GRAPHITE_ROOT_PATH_PREFIX: "gatling.service-prefix"
image: $REGISTRY/perf/tools:1
artifacts:
name: perf-reports
when: always
expire_in: 7 day
paths:
- ${PERF_TEST_PATH}/${PERF_ARTIFACTS}/*
tags: [perf-n3-1]
Здесь код, который касается конфигурирования тулзы, но сама тулза (
image: $REGISTRY/perf/tools:1) как раз находится в этом образе.perf:run-tests:
<<: *perf_template
script:
- export PERF_GRAPHITE_ROOT_PATH_PREFIX PERF_GRAPHITE_HOST
- export PERF_APP_HOST=http://${APP_PERF}.web-staging.2gis.ru
- cd ${PERF_TEST_PATH}
- ./run_test.sh --capacity
- ./run_test.sh --resp_time
after_script:
- perfberry-cli logs upload --dir ${PERF_TEST_PATH}/${PERF_ARTIFACTS} --env
${APP_PERF}.web-staging.2gis.ru gatling ${PERFBERRY_PROJECT_ID}
Мы запускали тест в 2 вариантах:
- Capacity тест, когда мы отправляли запросы по очереди: ждали, когда придет ответ, и только потом отправляли следующий запрос. Таким образом мы вычисляли емкость нашего приложения, то есть сколько запросов в секунду оно может отработать.
- Настоящий нагрузочный тест, когда мы не ждали ответов, а запускали эти запросы параллельно.
В первой итерации у нас результаты были не очень хорошие — не те, которые мы ждали. И мы пошли в сторону Performance.
Performance
Кэширование
Первое, что приходит в голову для повышения количества запросов, которые мы можем отрабатывать, и уменьшения ResponseTime, это кэширование. Если у нас есть ресурсы, которые мы можем сохранять в кэше, зачем ходить за ними заново каждый раз.
[AllowAnonymous]
[HttpGet("{id}")]
[ResponseCache(
VaryByQueryKeys = new[] { "api-version" },
Duration = 3600)]
public async Task<IActionResult> Get(long id)
{
...
}
Для этого у нас в ASP.Net есть старый добрый атрибут ResponseCache, но в ASP.Net Core он приобрел дополнительную функциональность.
Если мы выставляем просто ResponseCache и указываем его Duration, то получаем по умолчанию кэширование на клиенте. То есть клиент на своей стороне сохраняет те данные, которые ему отдали, и больше к нам запросов не шлет.
Но в ASP.Net Core также добавили серверное кэширование. Есть такая штука Response Caching Middleware, которая позволяет довольно хорошо управлять именно серверным кэшированием, то есть кэшировать прямо ответы от сервисов в памяти процесса. Причем мы можем выставить, как мы хотим разделять эти ответы. В нашем случае, если есть версионирование, хорошо бы, конечно же, отдавать разные ответы на каждую версию API.
После того, как мы включили кэширование на стороне сервера и на стороне клиента и запустили свой тест, все полегло, потому что как-то быстро все стало приходить. Поэтому потом на стороне нагрузочных тестов мы отключили клиентское кэширование, чтобы все было более-менее похоже на реальные условия, когда у нас есть разные клиенты.
Асинхронность и многопоточность
Вторая вещь, которая приходит в голову, когда мы говорим про производительность, это работа с потоками. Да, у нас .Net, в котором с точки зрения потоков все замечательно, поэтому почему бы это не использовать.
Здесь есть 2 вещи — асинхронность и многопоточность, и это не одно и то же.
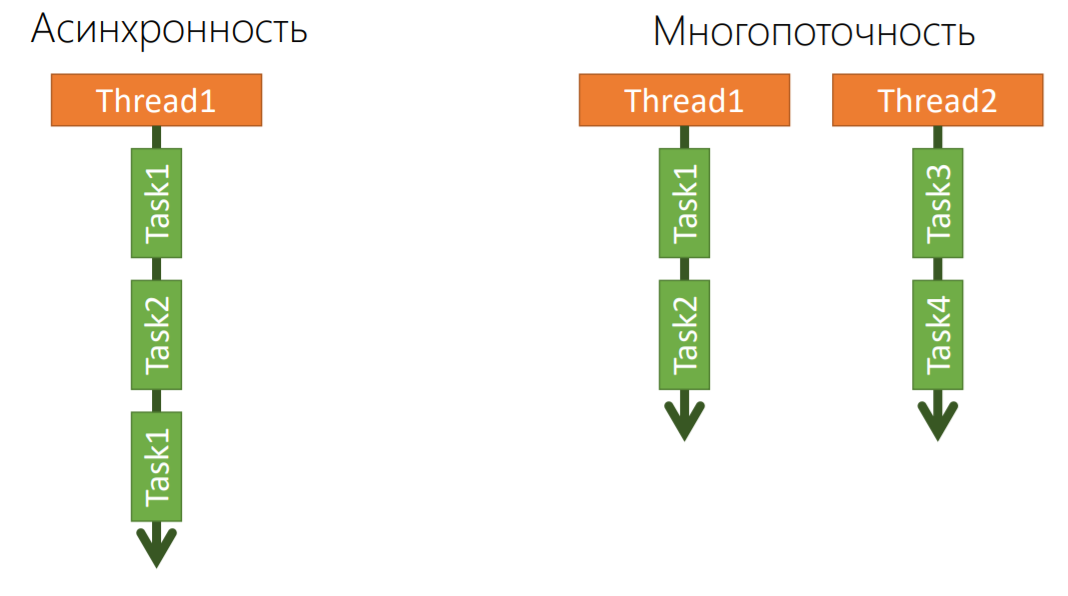
Асинхронность — это когда есть один поток, один ресурс ОС, на котором можно можем выполнять последовательно ряд задач. Если Task1 отправил запрос в базу данных и ждет чего-то, мы можем этот поток отдать в пул, чтобы следующий запрос от клиента отработать (Task2). Если он тоже задумался, мы можем сменить контекст потока и выполнять Task1, если к нему уже пришел ответ от базы данных, и т.д.
То есть на одном физическом ресурсе ОС мы можем выполнять несколько асинхронных задач. Async, Await в C#— это как раз про асинхронность.
Многопоточность — это когда есть много разных потоков, много ресурсов ОС, никто не мешает запускать какие-то процессы параллельно, но никто и не говорит, что эти параллельные процессы внутри себя не могут быть асинхронными.
Поэтому Async/Await — это не только про асинхронность, но еще и про многопоточность, но нужно правильно ее использовать.
Ниже простой пример, когда можно прямо из коробки использовать многопоточность в .Net.
var data =
await _remoteService.IOBoundOperationAsync(timeoutInSec: 1);
var result = new List<string>[data.Count];
foreach (var item in data)
{
var detailed =
await _remoteService.IOBoundOperationAsync(timeoutInSec: 5);
result.Add(string.Join(", ", detailed));
}
Допустим, у нас есть сервис, который отдает нам данные в виде коллекции, на основе этих данных нужно еще проитерировать, обратиться в цикле к другим сервисам для того, чтобы получить дополнительные данные на основе уже имеющихся.
Это пример прямо из нашей жизни. У нас есть видео реклама, и она может быть в нескольких форматах, нужно узнать, какие в этих всех форматах есть разделения, битрейд и т.д.
Наш первый запрос к API: «Скажи-ка нам, пожалуйста, какие есть медиа-файлы на твоей стороне?» Она отвечает, что есть коллекция данных. Дальше по каждому из них мы получаем уже детальную информацию.
Разрабатывая это все, мы конечно же особо не думали о производительности. Наши нагрузочные тесты нам показали, что ответ от нашего сервиса был порядка секунды, что не сильно хорошо.
Поэтому мы переписали. Это уже правильная версия.
var data =
await _remoteService.IOBoundOperationAsync(timeoutInSec: 1);
var result = new string[data.Count];
var tasks = data.Select(
async (item, index) =>
{
var detailed =
await _remoteService.IOBoundOperationAsync(timeoutInSec: 5);
result[index] = string.Join(", ", detailed)
});
await Task.WhenAll(tasks);
К сожалению, не всегда получается с первого раза написать правильный, эффективный многопоточный код, чтобы еще и дедлоков не было.
Здесь мы делаем практически то же самое, но запускаем запросы к API уже параллельно, причем еще и асинхронно.
Мы получаем на выход коллекцию Task’ов, и запускаем еще одну, которая будет ждать их выполнения. Тем самым мы получаем ускорение во столько раз, сколько у нас есть видео-файлов.
Если, допустим, на каждую видео рекламу есть 3 разрешения файла, мы получаем сокращение времени аж в 4 раза. Нам нужно сделать 1 запрос на то, чтобы получить все метаданные, а дальше еще 3, 4 или 5 запросов. Они выполняются параллельно, поэтому общее время их исполнения примерно одинаково, и мы можем получить серьезный выигрыш по производительности.
Тестирование
После того, как мы это реализовали, нагрузочное тестирование показало другие результаты.
Мы поняли, что у нас есть некоторые лимиты по памяти и процессору, которые, с одной стороны, диктуются runtime, .Net, с другой стороны, тем кодом, который мы написали. Это конкретные цифры из продакшена:
- 384Mb и 1,5 CPU — столько наше приложение может потреблять в пике.
- Синхронный (capacity) тест показал ~24 RPS (без кэша).
- С применением серверного кэширования ~400 RPS, т. е. время отклика порядка 2,5 мс.
- Асинхронный (load) тест пройден.
Вместо заключения
На основе нашего опыта можно сказать, что .NET Core на текущий момент в продакшне использовать можно. У нас не было никаких зависаний, непонятных нюансов с работой garbage коллектора или проблем с оркестрированием потоков и т.д. Все то, что есть в обычном .Net на текущий момент есть такого же качества в ASP.NET Core, и бояться его использовать, судя по нашему опыту, не стоит.
Не было проблем, которые касаются именно Linux. Если есть какие-то проблемы, они, скорее всего ваши. У нас были дедлоки как раз с использованием потоков, но они зависели не от Linux, а от программистов.
Как я уже показал, Docker и Kubernetes сильно упрощают жизнь в плане разработки .Net приложений, и, в принципе, в плане разработки приложений, и использования разных стековых технологий.
Последнее, что хотел бы сказать, что оптимизировать приложения нужно. Все это есть из коробки, но думать все равно надо, чтобы не получать интересных эффектов.

Контакты:
Код и презентация здесь.
E-mail: denis@ivanovdenis.ru
— Мы с .Net Core давно живем и наелись с ним много проблем. Вы говорите, что перешли на Linux — а как вы профилировали его? Как живете без eventTracing, без PerformanceCounter и прочих вещей?На самом деле все, что касается PerformanceCounter, в Windows тоже реализовано не очень хорошо. Мы в свое время этим тоже занимались. Как эту проблему решаем мы?
С точки зрения профилирования в Linux есть некоторые тулзы, которые касаются .Net Core. Саша Гольштейн занимается разработкой тулзов для профилирования под Linux именно для таких приложений. Но нам не приходилось до этого доходить, чтобы прямо посмотреть, какие там дампы памяти и пр.
— Нет, но вы профилировали как раз, говорите, дедлоки у вас были, анализировали и улучшали Performance. Вы же под Linux это делали?Да. Для того, чтобы поймать дедлоки, нам хватило логов. Просто мы выводили в логи номера потоков и смотрели их количество. Оно же в тред-пуле ограничено. Если мы хорошо нагрузим наше приложение или искусственно выставим ограничение в тред-пуле, то можем получить такую ситуацию, что все потоки получают запросы, но никогда из них не выходят. То есть в логах мы очень хорошо видим, что этот поток начал исполнение, этот начал исполнение, и все! Дальше мы не видим никакого вывода от приложения — оно не принимает больше никаких запросов.
— То есть вы на более сложные сценарии выявления Performance еще не попадали? То есть не просто дедлоки, а где-то, возможно, криво написанный код и еще какие-то вещи, которые именно профилируются, как зачастую бывает, на отдельной машине в продакшене, под нагрузкой. И ты только там понимаешь, что оно есть.На самом деле я об этом не рассказал, но мы это делаем просто потому, что в сервис продакшене, и этим заниматься необходимо. С каждой новой версией сервиса мы можем получить деградацию производительности сервиса. Мы используем метрики, но метрики не на основе PerformanceCounter или чего-то, что касается ОС.
Мы используем, скажем так, логические метрики на основе Prometheus Server. Мы можем публиковать эти метрики в runtime, дальше выставить endpoint для Prometheus сервиса. Он будет приходить какое-то количество раз в минуту или секунду, забирать эти метрики и складывать у себя.
Эти метрики могут быть любыми. Мы смотрим: какое количество памяти у нас на текущий момент кушается приложением: сколько раз запускается сборщик мусора; сколько потоков используется и пр.
— А вы изначально ASP.Net Core проектировали под Linux или же у вас был перенос проекта с другой платформы?Изначально мы сразу же ориентировались на Linux. Платформа, на которой нам предстояло развертываться, требовала от нас, чтобы приложение работало под Linux. Поэтому именно этот сервис мы изначально планировали делать под Linux.
Опыт переноса у нас сейчас есть. У нас есть много проектов, которые мы сделали за это время внутри компании на .Net, который под Windows. Получив все эти плюсы, в том числе ускорение разработки с использованием Docker, мы начали, конечно же, смотреть в сторону того, чтобы переносить часть сервисов туда. Но они продакшен и бизнес-критичные — поэтому мы относимся к этому аккуратно процесс движется потихоньку.
В этом году мы решили объединить программы HighLoad++ Junior и Backend Conf — теперь темы обеих конференций будут рассматриваться в рамках Backend Conf РИТ++. Так что вам не нужно думать, куда именно подать доклад, просто отправьте заявку в Программный комитет до 9 апреля. Тезисы уже поданных докладов есть на сайте конференции, к ним можно присматриваться и планировать свой визит на РИТ++ в качестве слушателя.
Комментарии (11)
musuk
03.04.2018 01:09Интересно, а как правильно счётчики делать в Asp.NET Core? Пока ничего умнее, чем вот это не придумал:
public class Counter { private long _counterValue = 0; public void Increment() { Interlocked.Increment(ref _counterValue); } } public class GlobalStatisticsCollector { private static ConcurrentDictionary<string, Counter> _counters = new ConcurrentDictionary<string, Counter>(); public static void IncrementCounter(string key) { if (!_counters.TryGetValue(key, out var counter)) { lock (SyncRoot) { if (!_counters.TryGetValue(key, out counter)) { counter = new Counter() { }; counter.Increment(); _counters.TryAdd(key, counter); return; } } } counter.Increment(); } }
VanKrock
04.04.2018 06:00Зачем реализовывать свой Singleton если можно воспользоваться встроенным DI контейнером?
Просто в методеConfigureServicesклассаStartupдобавляете singleton вашегоcounter
services.AddSingleton<ICounter, Counter>();
И теперь можете получать
ICounterкак зависимость через конструктор контроллера например.

novikovag
03.04.2018 04:302ГИС появилась иконка, на которую можно нажать и начнет проигрываться видео.
ИТ мертв, похоронен смузихлебами.
Piteryo
03.04.2018 05:45Можно чуть подробнее про пример с многопоточностью? Не могу понять, почему именно там async/await становятся "многопоточными инструментами".
aikixd
03.04.2018 12:30Из-за этой строки
await Task.WhenAll(tasks);
Все таски будут запущены параллельно и исполнение продолжится когда все будут окончены.
byme
04.04.2018 06:00В С# async/await не такой как в JS. Здесь есть Dispatcher, который решает как запускать и когда отпускать таски. Например в WPF диспатчер запускает все таски в threadpoоl-e, но таким образом чтобы один поток всегда занимался только UI. Если расмотреть серверный вариант диспатчера, то тут все таски работают паралельно. Если очень хочеться(а может иногда и нужно), можно написать диспатчер который будет выполнять все таски в одном потоке как в JS…
dremlin2000
03.04.2018 05:45Мне статья понравилась. Как раз сейчас смотрю в сторону контейнеров, сравниваю Azure Service Fabric vs Azure Containers Service.
Есть вопрос по поводу этого кода.
var data = await _remoteService.IOBoundOperationAsync(timeoutInSec: 1); var result = new string[data.Count]; var tasks = data.Select( async (item, index) => { var detailed = await _remoteService.IOBoundOperationAsync(timeoutInSec: 5); result[index] = string.Join(", ", detailed) }); await Task.WhenAll(tasks);
К сожалению, не всегда получается с первого раза написать правильный, эффективный многопоточный код, чтобы еще и дедлоков не было.
Здесь мы делаем практически то же самое, но запускаем запросы к API уже параллельно, причем еще и асинхронно.
На сколько я понимаю, Вы запускаете этот код асинхронно (конкурентно) в одном потоке, но не параллельно (не много пототочно, если хотите). Так как метод IOBoundOperationAsync говорит сам за себя, что он IO bound, а не CPU bound. Соотвественно, он не создает новых потоков. Так же Task.WhenAll не создает новых потоков.
Я бы еще добавил throttling, таким образом распределив нагрузку CPU context switching при конкурентной обработке запросов к сервису. Иначе есть риск спайков под 100%, что CPU будет настолько загружен при обработке определенных запросов, что просто не сможет обрабатывать другие новые запросы пришедшие позже.
Hixon10
03.04.2018 21:38Добрый день.
Спасибо за отличный рассказ.
Можете, пожалуйста, рассказать, как выглядил процесс внедрения k8s в вашу компанию? С точки зрения программистов? С точки зрения эксплуатации (если она у вас есть)?
Сначала всё пробовали на тестовом окружении, а потом на прод? Или наняли каких-то людей в команду, кто уже имел опыт?
Кто был инициатором внедрения? Программисты, или эксплуатация?

QtRoS
04.04.2018 12:24Как с локализацией обстоят дела? У меня есть довольно странная потребность (да, мсье знает толк) получать исключения на русском языке.
Притом основной спектр исключений мало интересует, а именно XmlSchemaValidationException — чтобы дешево и сердито показать пользователям, что не так в XML при валидации. Если отбросить в сторону все высокосветские беседы о том, что все сообщения об ошибках должны быть на английском (едином?) языке, и сфокусироваться именно на решении проблемы бизнеса, то все складывается нормально — проблема решается установкой русской локали для приложения, все исключения (в том числе нужные) на русском языке, задача решена. Однако такой подход не сработал в .NET Core. Сначала экспериментировал с проектом типа WebAPI, потом упростил тест до консольного. В итоге получается, что тот же самый код в консольном приложении .NET Framework дает один результат (исключения на русском), а в консольном приложении .NET Core — другой (исключения без локализации).
Изучение исходников реализации привело в файлы ресурсов. Получается, что оригинальный фреймворк берет локализованные ресурсы, а коре — нет. Никто случайно не знает, как можно заставить кору действовать как фреймворк?
robert_ayrapetyan
~400 RPS на 1.5 ядра как-то очень скромно. Это ж сколько вам серверов нужно для реальной нагрузки?