
Обработкой естественного языка (NLP) называется активно развивающаяся научная дисциплина, занимающаяся поиском смысла и обучением на основании текстовых данных.
Как вам может помочь эта статья
За прошедший год команда Insight приняла участие в работе над несколькими сотнями проектов, объединив знания и опыт ведущих компаний в США. Результаты этой работы они обобщили в статье, перевод которой сейчас перед вами, и вывели подходы к решению наиболее распространенных прикладных задач машинного обучения.
Мы начнем с самого простого метода, который может сработать — и постепенно перейдем к более тонким подходам, таким как feature engineering, векторам слов и глубокому обучению.
После прочтения статьи, вы будете знать, как:
- осуществлять сбор, подготовку, и инспектирование данных;
- строить простые модели, и осуществлять при необходимости переход к глубокому обучению;
- интерпретировать и понимать ваши модели, чтобы убедиться, что вы интерпретируете информацию, а не шум.
Пост написан в формате пошагового руководства; также его можно рассматривать в качестве обзора высокоэффективных стандартных подходов.
К оригинальному посту прилагается интерактивный блокнот Jupyter, демонстрирующий применение всех упомянутых техник. Мы призываем вас воспользоваться им по мере того, как вы будете читать статью.
Применение машинного обучения для понимания и использования текста
Обработка естественного языка позволяет получать новые восхитительные результаты и является очень широкой областью. Однако, Insight идентифицировала следующие ключевые аспекты практического применения, которые встречаются гораздо чаще остальных:
- Идентификация различных когорт пользователей или клиентов (например, предсказание оттока клиентов, совокупной прибыли клиента, продуктовых предпочтений)
- Точное детектирование и извлечение различных категорий отзывов (позитивные и негативные мнения, упоминания отдельных атрибутов вроде размера одежды и т.д.)
- Классификация текста в соответствии с его смыслом (запрос элементарной помощи, срочная проблема).
Невзирая на наличие большого количества научных публикаций и обучающих руководств на тему NLP в интернете, на сегодняшний день практически не существует полноценных рекомендаций и советов на тему того, как эффективно справляться с задачами NLP, при этом рассматривающих решения этих задач с самых основ.
Шаг 1: Соберите ваши данные
Примерные источники данных
Любая задача машинного обучения начинается с данных — будь то список адресов электронной почты, постов или твитов. Распространенными источниками текстовой информации являются:
- Отзывы о товарах (Amazon, Yelp и различные магазины приложений).
- Контент, созданный пользователями (твиты, посты в Facebook, вопросы на StackOverflow).
- Диагностическая информация (запросы пользователей, тикеты в поддержку, логи чатов).
Датасет «Катастрофы в социальных медиа»
Для иллюстрации описываемых подходов мы будем использовать датасет «Катастрофы в социальных медиа», любезно предоставленный компанией CrowdFlower.
Авторы рассмотрели свыше 10 000 твитов, которые были отобраны при помощи различных поисковых запросов вроде «в огне», «карантин» и «столпотворение». Затем они пометили, имеет ли твит отношение к событию-катастрофе (в отличие от шуток с использованием этих слов, обзоров на фильмы или чего-либо, не имеющего отношение к катастрофам).
Поставим себе задачу определить, какие из твитов имеют отношение к событию-катастрофе в противоположность тем твитам, которые относятся к нерелевантным темам (например, фильмам). Зачем нам это делать? Потенциальным применением могло бы быть эксклюзивное уведомление должностных лиц о чрезвычайных ситуациях, требующих неотложного внимания — при этом были бы проигнорированы обзоры последнего фильма Адама Сэндлера. Особая сложность данной задачи заключается в том, что оба этих класса содержат одни и те же критерии поиска, поэтому нам придется использовать более тонкие отличия, чтобы разделить их.
Далее мы будем ссылаться на твиты о катастрофах как «катастрофа», а на твиты обо всём остальном как «нерелевантные».
Метки (Labels)
Наши данные имеют метки, так что мы знаем, к каким категориям принадлежат твиты. Как подчеркивает Ричард Сочер, обычно быстрее, проще и дешевле найти и разметить достаточно данных, на которых будет обучаться модель — вместо того, чтобы пытаться оптимизировать сложный метод обучения без учителя.
Вместо того, чтобы тратить месяц на формулирование задачи машинного обучения без учителя, просто потратьте неделю на то, чтобы разметить данные, и обучите классификатор.
Шаг 2. Очистите ваши данные
Правило номер один: «Ваша модель сможет стать лишь настолько хороша,
насколько хороши ваши данные»
Одним из ключевых навыков профессионального Data Scientist является знание о том, что должно быть следующим шагом — работа над моделью или над данными. Как показывает практика, сначала лучше взглянуть на сами данные, а только потом произвести их очистку.
Чистый датасет позволит модели выучить значимые признаки и не переобучиться на нерелевантном шуме.
Далее следует чеклист, который используется при очистке наших данных (подробности можно посмотреть в коде).
- Удалить все нерелевантные символы (например, любые символы, не относящиеся к цифро-буквенным).
- Токенизировать текст, разделив его на индивидуальные слова.
- Удалить нерелевантные слова — например, упоминания в Twitter или URL-ы.
- Перевести все символы в нижний регистр для того, чтобы слова «привет», «Привет» и «ПРИВЕТ» считались одним и тем же словом.
- Рассмотрите возможность совмещения слов, написанных с ошибками, или имеющих альтернативное написание (например, «круто»/«круть»/ «круууто»)
- Рассмотрите возможность проведения лемматизации, т. е. сведения различных форм одного слова к словарной форме (например, «машина» вместо «машиной», «на машине», «машинах» и пр.)
После того, как мы пройдемся по этим шагам и выполним проверку на дополнительные ошибки, мы можем начинать использовать чистые, помеченные данные для обучения моделей.
Шаг 3. Выберите хорошее представление данных
В качестве ввода модели машинного обучения принимают числовые значения. Например, модели, работающие с изображениями, принимают матрицу, отображающую интенсивность каждого пикселя в каждом канале цвета.
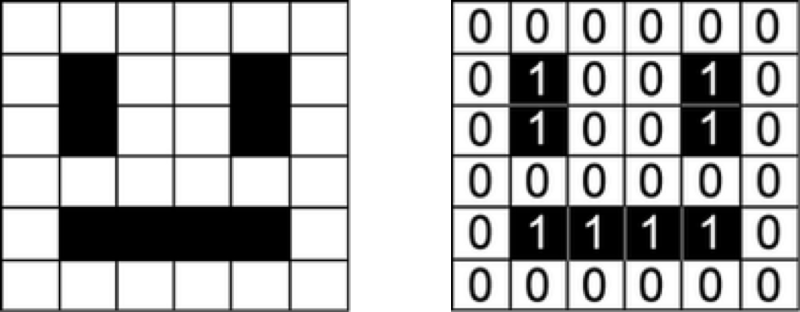
Улыбающееся лицо, представленное в виде массива чисел
Наш датасет представляет собой список предложений, поэтому для того, чтобы наш алгоритм мог извлечь паттерны из данных, вначале мы должны найти способ представить его таким образом, чтобы наш алгоритм мог его понять.
One-hot encoding («Мешок слов»)
Естественным путем отображения текста в компьютерах является кодирование каждого символа индивидуально в виде числа (пример подобного подхода — кодировка ASCII). Если мы «скормим» подобную простую репрезентацию классификатору, он будет должен изучить структуру слов с нуля, основываясь лишь на наших данных, что на большинстве датасетов невозможно. Следовательно, мы должны использовать более высокоуровневый подход.
Например, мы можем построить словарь всех уникальных слов в нашем датасете, и ассоциировать уникальный индекс каждому слову в словаре. Каждое предложение тогда можно будет отобразить списком, длина которого равна числу уникальных слов в нашем словаре, а в каждом индексе в этом списке будет хранится, сколько раз данное слово встречается в предложении. Эта модель называется «Мешком слов» (Bag of Words), поскольку она представляет собой отображение полностью игнорирущее порядок слов предложении. Ниже иллюстрация такого подхода.
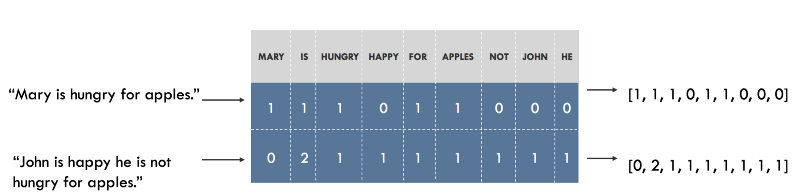
Представление предложений в виде «Мешка слов». Исходные предложения указаны слева, их представление — справа. Каждый индекс в векторах представляет собой одно конкретное слово.
Визуализируем векторные представления
В словаре «Катастрофы в социальных медиа» содержится около 20 000 слов. Это означает, что каждое предложение будет отражено вектором длиной 20 000. Этот вектор будет содержать преимущественно нули, поскольку каждое предложение содержит лишь малое подмножество из нашего словаря.
Для того, чтобы выяснить, захватывают ли наши векторные представления (embeddings), релевантную нашей задаче информацию (например, имеют ли твиты отношение к катастрофам или нет), стоит попробовать визуализировать их и посмотреть, насколько хорошо разделены эти классы. Поскольку словари обычно являются очень большими и визуализация данных на 20 000 измерений невозможна, подходы вроде метода главных компонент (PCA) помогают спроецировать данные на два измерения.

Визуализация векторных представлений для «мешка слов»
Судя по получившемуся графику, не похоже, что два класса разделены как следует — это может быть особенностью нашего представления или просто эффектом сокращения размерности. Для того, чтобы выяснить, являются ли для нас полезными возможности «мешка слов», мы можем обучить классификатор, основанный на них.
Шаг 4. Классификация
Когда вы в первый раз принимаетесь за задачу, общепринятой практикой является начать с самого простого способа или инструмента, который может решить эту задачу. Когда дело касается классификации данных, наиболее распространенным способом является логистическая регрессия из-за своей универсальности и легкости толкования. Ее очень просто обучить, и ее результаты можно интерпретировать, поскольку вы можете с легкостью извлечь все самые важные коэффициенты из модели.
Разобьем наши данные на обучающую выборку, которую мы будем использовать для обучения нашей модели, и тестовую — для того, чтобы посмотреть, насколько хорошо наша модель обобщается на данные, которые не видела до этого. После обучения мы получаем точность в 75.4%. Не так уж и плохо! Угадывание самого частого класса («нерелеватно») дало бы нам лишь 57%.
Однако, даже если результата с 75% точностью было бы достаточно для наших нужд, мы никогда не должны использовать модель в продакшне без попытки понять ее.
Шаг 5. Инспектирование
Матрица ошибок
Первый шаг — это понять, какие типы ошибок совершает наша модель, и с какими видами ошибок нам в дальнейшем хотелось бы встречаться реже всего. В случае нашего примера, ложно-положительные результаты классифицируют нерелевантный твит в качестве катастрофы, ложно-отрицательные — классифицируют катастрофу как нерелевантный твит. Если нашим приоритетом является реакция на каждое потенциальное событие, то мы захотим снизить наши ложно-отрицательные срабатывания. Однако, если мы ограничены в ресурсах, то мы можем приоритезировать более низкую частоту ложно-отрицательных срабатываний для уменьшения вероятности ложной тревоги. Хорошим способом визуализации данной информации является использование матрицы ошибок, которая сравнивает предсказания, сделанные нашей моделью, с реальными метками. В идеале, данная матрица будет представлять собой диагональную линию, идущую из левого верхнего до нижнего правого угла (это будет означать, что наши предсказания идеально совпали с правдой).

Наш классификатор создает больше ложно-отрицательных, чем ложно-положительных результатов (пропорционально). Другими словами, самая частая ошибка нашей модели состоит в неточной классификации катастроф как нерелевантных. Если ложно-положительные отражают высокую стоимость для правоохранительных органов, то это может стать хорошим вариантом для нашего классификатора.
Объяснение и интерпретация нашей модели
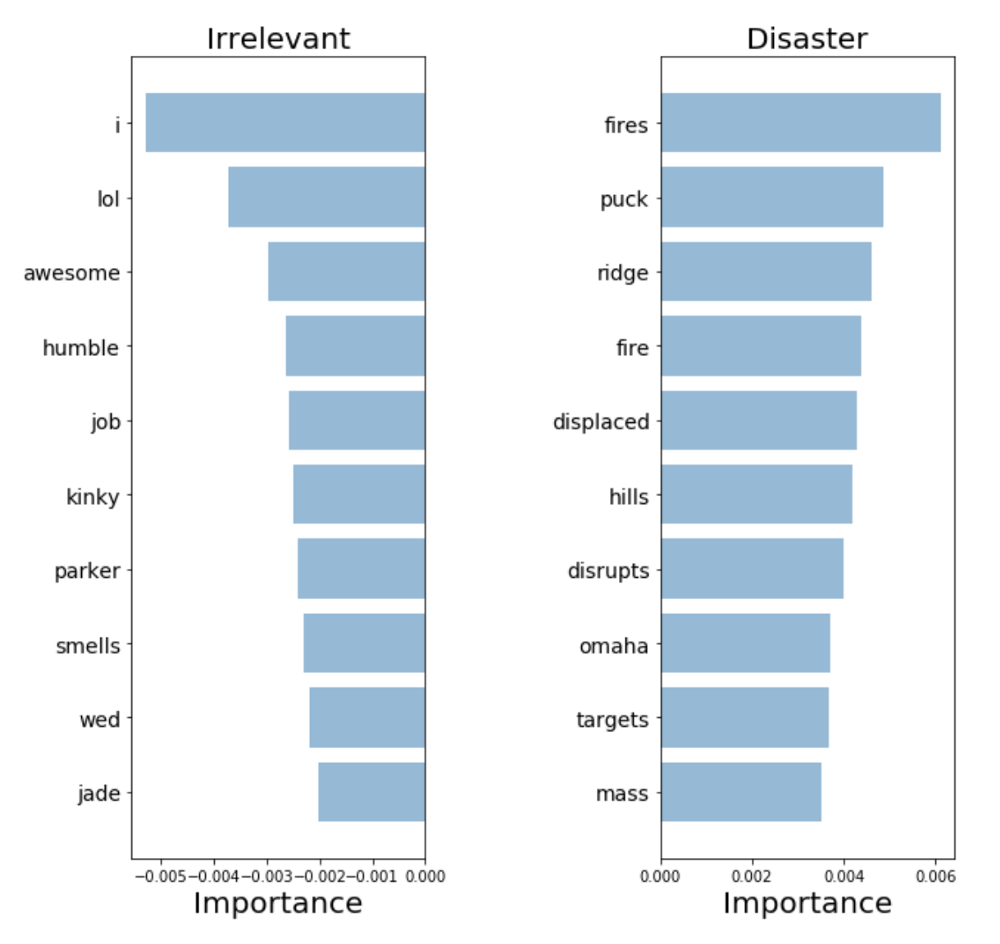
Чтобы произвести валидацию нашей модели и интерпретировать ее предсказания, важно посмотреть на то, какие слова она использует для принятия решений. Если наши данные смещены, наш классификатор произведет точные предсказания на выборочных данных, но модель не сможет достаточно хорошо обобщить их в реальном мире. На диаграмме ниже показаны наиболее значимые слова для классов катастроф и нерелевантных твитов. Составление диаграмм, отражающих значимость слов, не составляет трудностей в случае использования «мешка слов» и логистической регрессии, поскольку мы просто извлекаем и ранжируем коэффициенты, которые модель использует для своих предсказаний.
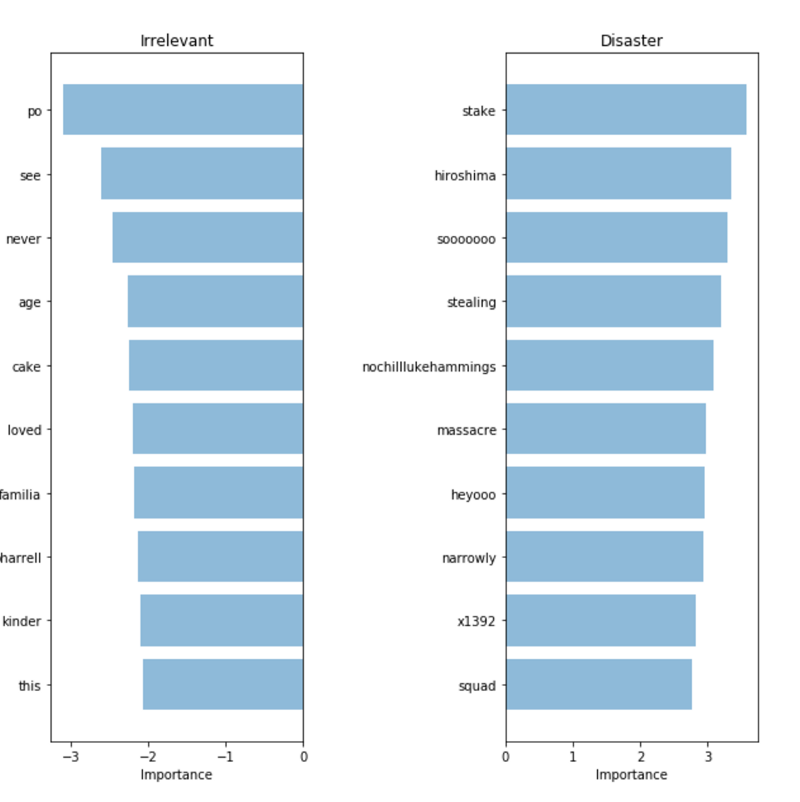
«Мешок слов»: значимость слов
Наш классификатор верно нашел несколько паттернов (hiroshima — «Хиросима», massacre — «резня»), но ясно видно, что он переобучился на некоторых бессмысленных терминах («heyoo», «x1392»). Итак, сейчас наш «мешок слов» имеет дело с огромным словарем из различных слов и все эти слова для него равнозначны. Однако, некоторые из этих слов встречаются очень часто, и лишь добавляют шума нашим предсказаниям. Поэтому далее мы постараемся найти способ представить предложения таким образом, чтобы они могли учитывать частоту слов, и посмотрим, сможем ли мы получить больше полезной информации из наших данных.
Шаг 6. Учтите структуру словаря
TF-IDF
Чтобы помочь нашей модели сфокусироваться на значимых словах, мы можем использовать скоринг TF-IDF (Term Frequency, Inverse Document Frequency) поверх нашей модели «мешка слов». TF-IDF взвешивает на основании того, насколько они редки в нашем датасете, понижая в приоритете слова, которые встречаются слишком часто и просто добавляют шум. Ниже приводится проекция метода главных компонент, позволяющая оценить наше новое представление.

Визуализация векторного представления с применением TF-IDF.
Мы можем наблюдать более четкое разделение между двумя цветами. Это свидетельствует о том, что нашему классификатору должно стать проще разделить обе группы. Давайте посмотрим, насколько улучшатся наши результаты. Обучив другую логистическую регрессию на наших новых векторных представлениях, мы получим точность в 76,2%.
Очень незначительное улучшение. Может, наша модель хотя бы стала выбирать более важные слова? Если полученный результат по этой части стал лучше, и мы не даем модели «мошенничать», то можно считать этот подход усовершенствованием.
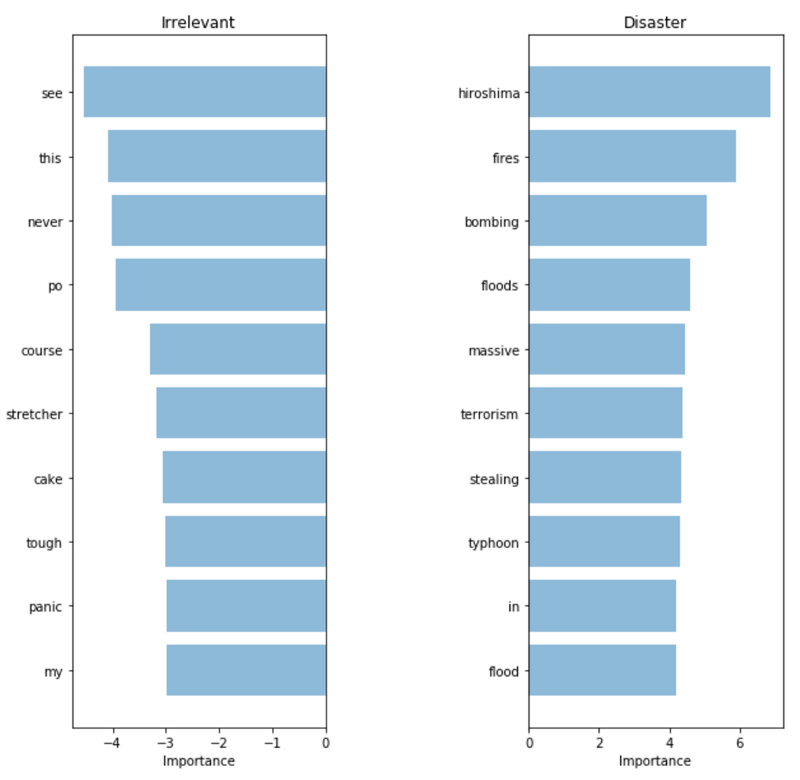
TF-IDF: Значимость слов
Выбранные моделью слова действительно выглядят гораздо более релевантными. Несмотря на то, что метрики на нашем тестовом множестве увеличились совсем незначительно, у нас теперь гораздо больше уверенности в использовании модели в реальной системе, которая будет взаимодействовать с клиентами.
Шаг 7. Применение семантики
Word2Vec
Наша последняя модель смогла «выхватить» слова, несущие наибольшее значение. Однако, скорее всего, когда мы выпустим ее в продакшн, она столкнется со словами, которые не встречались в обучающей выборке — и не сможет точно классифицировать эти твиты, даже если она видела весьма похожие слова во время обучения.
Чтобы решить данную проблему, нам потребуется захватить семантическое (смысловое) значение слов — это означает, что для нас важно понимать, что слова «хороший» и «позитивный» ближе друг к другу, чем слова «абрикос» и «континент». Мы воспользуемся инструментом Word2Vec, который поможет нам сопоставить значения слов.
Использование результатов предварительного обучения
Word2Vec — это техника для поиска непрерывных отображений для слов. Word2Vec обучается на прочтении огромного количества текста с последующим запоминанием того, какое слово возникает в схожих контекстах. После обучения на достаточном количестве данных, Word2Vec генерирует вектор из 300 измерений для каждого слова в словаре, в котором слова со схожим значением располагаются ближе друг к другу.
Авторы публикации на тему непрерывных векторных представлений слов выложили в открытый доступ модель, которая была предварительно обучена на очень большом объеме информации, и мы можем использовать ее в нашей модели, чтобы внести знания о семантическом значении слов. Предварительно обученные векторы можно взять в репозитории, упомянутом в статье по ссылке.
Отображение уровня предложений
Быстрым способом получить вложения предложений для нашего классификатора будет усреднение оценок Word2Vec для всех слов в нашем предложении. Это все тот же подход, что и с «мешком слов» ранее, но на этот раз мы теряем только синтаксис нашего предложения, сохраняя при этом семантическую (смысловую) информацию.
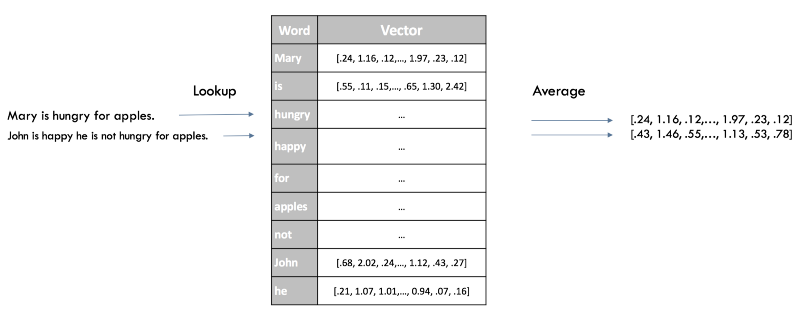
Векторные представления предложений в Word2Vec
Вот визуализация наших новых векторных представлений после использования перечисленных техник:
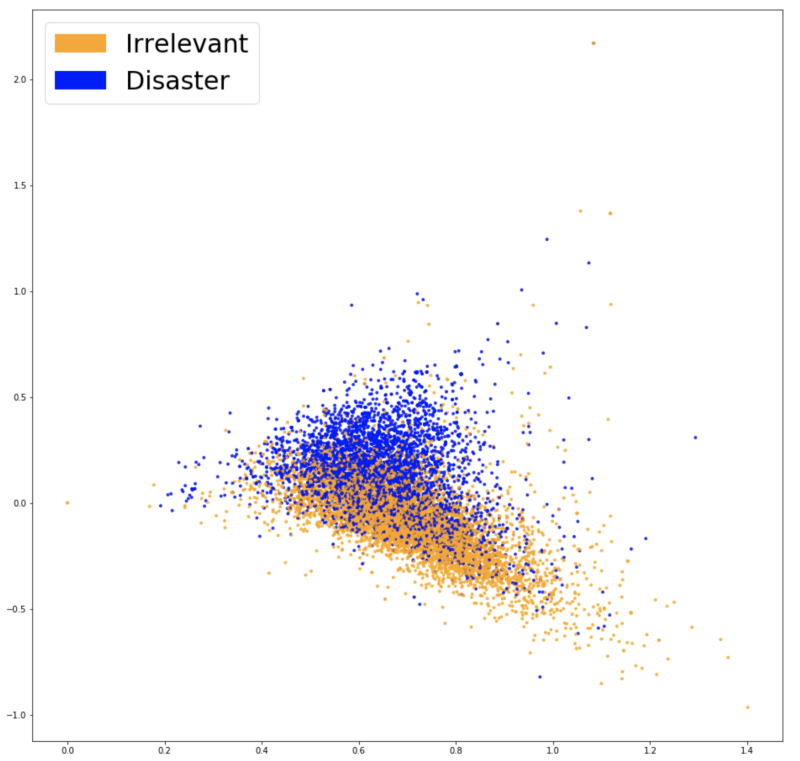
Визуализация векторных представлений Word2Vec.
Теперь две группы цветов выглядят разделенными еще сильнее, и это должно помочь нашему классификатору найти различие между двумя классами. После обучения той же модели в третий раз (логистическая регрессия), мы получаем точность в 77,7% — и это наш лучший результат на данный момент! Настало время изучить нашу модель.
Компромисс между сложностью и объяснимостью
Поскольку наши векторные представления более не представлены в виде вектора с одним измерением на слово, как было в предыдущих моделях, теперь тяжелее понять, какие слова наиболее релевантны для нашей классификации. Несмотря на то, что мы по-прежнему обладаем доступом к коэффициентам нашей логистической регрессии, они относятся к 300 измерениям наших вложений, а не к индексам слов.
Для столь небольшого прироста точности, полная потеря возможности объяснить работу модели — это слишком жесткий компромисс. К счастью, при работе с более сложными моделями мы можем использовать интерпретаторы наподобие LIME, которые применяются для того, чтобы получить некоторое представление о том, как работает классификатор.
LIME
LIME доступен на Github в виде открытого пакета. Данный интерпретатор, работающий по принципу черного ящика, позволяет пользователям объяснять решения любого классификатора на одном конкретном примере при помощи изменения ввода (в нашем случае — удаления слова из предложения) и наблюдения за тем, как изменяется предсказание.
Давайте взглянем на пару объяснений для предложений из нашего датасета.

Правильные слова катастроф выбраны для классификации как «релевантные».
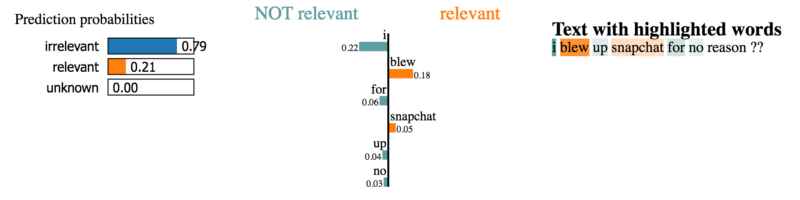
Здесь вклад слов в классификацию выглядит менее очевидным.
Впрочем, у нас нет достаточного количества времени, чтобы исследовать тысячи примеров из нашего датасета. Вместо этого, давайте запустим LIME на репрезентативной выборке тестовых данных, и посмотрим, какие слова встречаются регулярно и вносят наибольший вклад в конечный результат. Используя данный подход, мы можем получить оценки значимости слов аналогично тому, как мы делали это для предыдущих моделей, и валидировать предсказания нашей модели.
Похоже на то, что модель выбирает высоко релевантные слова и соответственно принимает понятные решения. По сравнению со всеми предыдущими моделями, она выбирает наиболее релевантные слова, поэтому лучше будет отправить в продакшн именно ее.
Шаг 8. Использование синтаксиса при применении end-to-end подходов
Мы рассмотрели быстрые и эффективные подходы для генерации компактных векторных представлений предложений. Однако, опуская порядок слов, мы отбрасываем всю синтаксическую информацию из наших предложений. Если эти методы не дают достаточных результатов, вы можете использовать более сложную модель, которая принимает целые выражения в качестве ввода и предсказывает метки, без необходимости построения промежуточного представления. Распространенный для этого способ состоит в рассмотрении предложения как последовательности индивидуальных векторов слов с использованием или Word2Vec, или более свежих подходов вроде GloVe или CoVe. Именно этим мы и займемся далее.

Высокоэффективная архитектура обучения модели без дополнительной предварительной и последующей обработки (end-to-end, источник)
Сверточные нейронные сети для классификации предложений (CNNs for Sentence Classification) обучаются очень быстро и могут сослужить отличную службу в качестве входного уровня в архитектуре глубокого обучения. Несмотря на то, что сверточные нейронные сети (CNN) в основном известны своей высокой производительностью на данных-изображениях, они показывают превосходные результаты при работе с текстовыми данными, и обычно гораздо быстрее обучаются, чем большинство сложных подходов NLP (например, LSTM-сети и архитектуры Encoder/Decoder ). Эта модель сохраняет порядок слов и обучается ценной информации о том, какие последовательности слов служат предсказанием наших целевых классов. В отличии от предыдущих моделей, она в курсе существования разницы между фразами «Лёша ест растения» и «Растения едят Лёшу».
Обучение данной модели не потребует сильно больше усилий по сравнению с предыдущими подходами (смотрите код), и, в итоге, мы получим модель, которая работает гораздо лучше предыдущей, позволяя получить точность в 79,5%. Как и с моделями, которые мы рассмотрели ранее, следующим шагом должно быть исследование и объяснение предсказаний с помощью методов, которые мы описали выше, чтобы убедиться в том, что модель является лучшим вариантом, который мы можем предложить пользователям. К этому моменту вы уже должны чувствовать себя достаточно уверенными, чтобы справиться с последующими шагами самостоятельно.
В заключение
Итак, краткое содержание подхода, который мы успешно применили на практике:
- начинаем с быстрой и простой модели;
- объясняем ее предсказания;
- понимаем, какие разновидности ошибок она делает;
- используем полученные знания для принятия решения о следующем шаге — будь то работа над данными, или над более сложной моделью.
Данные подходы мы рассмотрели на конкретном примере с использованием моделей, заточенных на распознавание, понимание и использование коротких текстов — например, твитов; однако, эти же идеи широко применимы к множеству различных задач.
Как уже отмечалось в статье, кто угодно может извлечь пользу, применив методы машинного обучения, тем более в мире интернета, со всем разнообразием аналитических данных. Поэтому темы искусственного интеллекта и машинного обучения непременно обсуждаются на наших конференциях РИТ++ и Highload++, причем с совершенно практической точки зрения, как и в этой статье. Вот, например, видео нескольких прошлогодних выступлений:
- Поиск признаков мошенничества в убытках по медицинскому страхованию / Василий Рязанов (Allianz)
- Ранжирование откликов соискателей с помощью машинного обучения / Сергей Сайгушкин (Superjob)
- Машинное обучение в электронной коммерции / Александр Сербул (1С-Битрикс)
- Применение машинного обучения для генерации структурированных сниппетов / Никита Спирин (Datastars)
А программа майского фестиваля РИТ++ и июньского Highload++ Siberia уже в пути, за текущим состоянием можно следить на сайтах конференций или подписаться на рассылку, и мы будем периодически присылать анонсы одобренных докладов, чтобы вам ничего не пропустить.
Комментарии (10)

novikovag
05.04.2018 17:13+1Более примитивного языка чем английский не нашли? Все ваши свистелки на нормальных языках с флексией и свободным порядком слов не работают.
Nick_mentat
06.04.2018 10:11Но ведь мешок слов игнорирует порядок. А разные спряжения приводятся к одному варианту при предобработке датасета. Данному методу должно быть пофиг на эти особенности языков.
elingur
05.04.2018 20:31объясняем ее предсказания
— а не могли бы поподробнее, какие предсказания на дискриминационных моделях можно делать?
molnij
05.04.2018 21:02А поясните, как это работает:
переход от 75.4% к 76.2% — «очень незначительное улучшение»
переход от 77.7% к 79.5% — «гораздо лучше предыдущей»
e_finkel Автор
06.04.2018 07:02Возможно, последнее сравнение применимо к переходу от 75,4 до 79,5. А возможно, это просто оценочное суждение автора, которое складывается и из косвенных признаков. А конкретные значения позволяют вам самостоятельно решить, стоит ли игра свеч.
Nick_mentat
06.04.2018 10:12+1В случае с катастрофами эти 2-4 процента могут быть критичными, и обеспечить спасение человеческой жизни. Так что я бы назвал все улучшения существенными.
crazy_llama
06.04.2018 11:17Недавно на kaggle проходило соревнование по определению токсичных комментариев. Победители опубликовали свое решение:
www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge/discussion/52557
almaredan
Может вы хотели написать Bag of Words?
e_finkel Автор
Словосочетание «мешок слов» более или менее устоялось, поэтому показалось разумно его использовать с указанием исходного выражения. А вот для one-hot encoding можно предложить разве что one-hot-кодирование, поэтому в заголовке получилось смешение.
Спасибо за замечание, интересно мнение о переводе или использовании терминологии на английском.
crazy_llama
В любом случае, мешок слов и one-hot кодирование — это совершенно разные термины. Это может спутать тех, кто только знакомится с темой. Например, можно одновременно использовать one-hot кодирование слов и использовать CNN/RNN без bag of words.